Содержание
1. Постановка задачи
2. Форматы команд и их кодировка
3. Структурная схема процессора
4. Регистры
5. АЛУ
6. Формат микрокоманд
7. Микрокод
8. Кодировка микрокода
9. Примеры выполнения команд
10. Основные сигналы и регистры процессора
11. Примеры программ
12. Определение производительности
Постановка задачи
Синтезировать структуру простого магистрального процессора с одним АЛУ, выполняющего 8 заданных команд. Разработать формат команд, кодировку команд. Разработать структурную схему процессора, функциональные схемы всех блоков процессора, функциональную схему процессора в целом с указанием всех шин и управляющих сигналов.
Разработать формат микрокоманд, организацию управления всеми устройствами процессора, микрокод для каждой из заданных команд. Привести примеры выполнения каждой команды с указанием значения всех основных сигналов и содержимого основных регистров на каждом такте. Привести 2 примера небольших программ с указанием значения основных сигналов и содержимого основных регистров на каждом такте.
Определить максимальную тактовую частоту процессора. Определить производительность процессора в операциях в секунду (IPS), а также выраженную в числе выполняемых тестовых программ в секунду. Указать способы повышения производительности процессора.
Характеристика процессора
Простой процессор магистрального типа с одноблочным универсальным АЛУ.
Разрядность регистров РОН и АЛУ процессора - 8 бит.
Число РОН - 4.
Адресуемая память - 256 слов.
Устройство управления - микропрограммное с ПЗУ микропрограмм.
Способ выполнения команд – последовательное выполнение или JMP или JC.
Адресация памяти - прямая.
Арифметика в дополнительном коде.
Вариант: 54 = «2 2 2 3»
Без использования непосредственной адресации.
3х-адресные команды.
Операции АЛУ: NOP, ADD + SHRA, NAND.
Состав команд: LD, ST, ADD, SHR + JC, DEC, SUB, NAND.
Форматы команд и их кодировка
Коды команд
| КОП | Команда | Действие | |
| 000 | ADD Rx,Ry,Rz | Rx=Ry+Rz | сложение |
| 001 | NAND Rx,Ry,Rz | Rx=!(Ry&Rz) | И-НЕ |
| 010 | SHR Rx,Ry | Rx=Ry/2 | арифметический сдвиг вправо |
| 011 | JC address | jmp on carry | условный переход по переносу |
| 100 | DEC Rx,Ry | Rx=Ry-1 | декремент (уменьшение на 1) |
| 101 | SUB Rx,Ry,Rz | Rx=Ry-Rz | вычитание |
| 110 | LD Rx,address | Rx=Mem(address) | загрузка из ОЗУ в регистр |
| 111 | ST Ry,address | Mem(address)=Rx | запись из регистра в ОЗУ |
Формат команд
| ADD Rx,Ry,Rz |
| ||||||||||||||||
| КОП | Rx | Ry | Rz | не используется | ||||||||||||
| 0 | 0 | 0 | x | x | y | y | z | z | ||||||||
| NAND Rx,Ry,Rz |
| |||||||||||||||
| КОП | Rx | Ry | Rz | не используется | ||||||||||||
| 0 | 0 | 1 | x | x | y | y | z | z | ||||||||
| SHR Rx,Ry |
| |||||||||||||||
| КОП | Rx | Ry | не используется | |||||||||||||
| 0 | 1 | 0 | x | x | y | y | ||||||||||
| JC address |
| |||||||||||||||
| КОП | не использ. | address | ||||||||||||||
| 0 | 1 | 1 | a | a | a | a | a | a | a | a | ||||||
| DEC Rx,Ry | |||||||||||||||
| КОП | Rx | Ry | не используется | ||||||||||||
| 1 | 0 | 0 | x | x | y | y | |||||||||
| |||||||||||||||||
| КОП | Rx | Ry | Rz | не используется | |||||||||||||
| 1 | 0 | 1 | x | x | y | y | z | z | |||||||||
| LD Rx,address | |||||||||||||||
| КОП | Rx | не исп. | address | ||||||||||||
| 1 | 1 | 0 | x | x | a | a | a | a | a | a | a | a | |||
| ST Rx,address | |||||||||||||||
| КОП | не исп | Ry | address | ||||||||||||
| 1 | 1 | 1 | y | y | a | a | a | a | a | a | a | a | |||
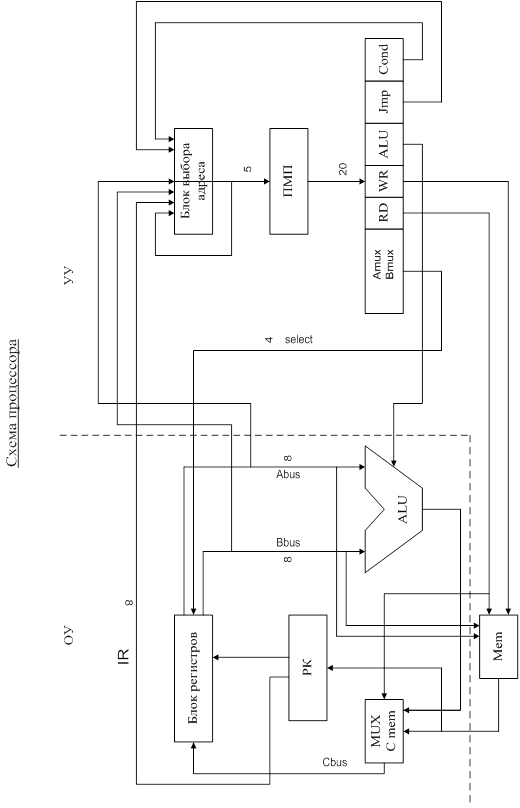
Регистры
| Номер | При записи (по шине С) | При чтении (по шине A и B) | ||||
| 000 | 0 | Rg0 | программно-доступные регистры | Rg0 | программно-доступные регистры | |
| 001 | 1 | Rg1 | Rg1 | |||
| 010 | 2 | Rg2 | Rg2 | |||
| 011 | 3 | Rg3 | Rg3 | |||
| 100 | 4 | Temp0 | Temp0 | |||
| 101 | 5 | PC | PC | |||
| 110 | 6 | IR_HI (старшая часть IR) | IR | константа 1 | ||
| 111 | 7 | IR_LO (младшая часть IR) | IR_LO | |||
При чтении старшей части регистра команд, на шину A или B поступает единичная константа (00000001). Это вполне допустимо, т.к. старшая часть регистра команд имеет свои выходы из блока регистров: (КОП, Rx, Ry, Rz). Младшая часть регистра команд поступает на шины A или B в неизменном виде, т.к. в некоторых командах процессора в младшей части регистра команд находиться 8-битный адрес. Единичная константа применяется при инкрементировании счетчика команд, а также для получения константы -1 = 11111111 (см. микрокод для команды DEC).
Разрядность РОН (регистры общего назначения) – 8 бит
Разрядность PC (program counter) – 8 бит
Разрядность IR (регистр команд) – 16 бит (доступно два регистра по 8 бит)
АЛУ
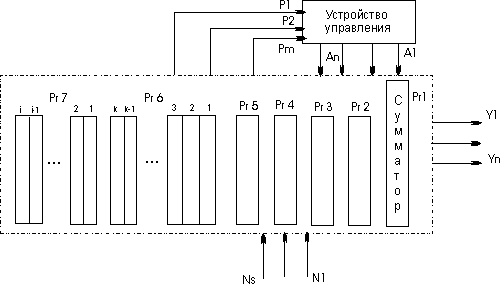
Структурная схема АЛУ и его связь с другими блоками машины показаны на рисунке. В состав АЛУ входят регистры Рг1 - Рг7, в которых обрабатывается информация , поступающая из оперативной или пассивной памяти N1, N2, ...NS; логические схемы, реализующие обработку слов по микрокомандам, поступающим из устройства управления.
Закон переработки информации задает микропрограмма , которая записывается в виде последовательности микрокоманд A1,A2, ..., Аn-1,An. При этом различают два вида микрокоманд: внешние, то есть такие микрокоманды, которые поступают в АЛУ от внешних источников и вызывают в нем те или иные преобразования информации (на рис. 1 микрокоманды A1,A2,..., Аn), и внутренние, которые генерируются в АЛУ и воздействуют на микропрограммное устройство, изменяя естественный порядок следования микрокоманд. Например, АЛУ может генерировать признаки в зависимости от результата вычислений: признак переполнения, признак отрицательного числа, признак равенства 0 всех разрядов числа др. На рис. 1 эти микрокоманды обозначены р1, p2,..., рm.
Результаты вычислений из АЛУ передаются по кодовым шинам записи у1, у2, ...,уs, в ОЗУ.
Функции регистров, входящих в АЛУ:
Рг1 - сумматор (или сумматоры) - основной регистр АЛУ, в котором образуется результат вычислений;
Рг2, РгЗ - регистры слагаемых, сомножителей, делимого или делителя (в зависимости от выполняемой операции);
Рг4 - адресный регистр (или адресные регистры), предназначен для запоминания (иногда и формирования) адреса операндов и результата;
Ргб - k индексных регистров, содержимое которых используется для формирования адресов;
Рг7 - i вспомогательных регистров, которые по желанию программиста могут быть аккумуляторами, индексными регистрами или использоваться для запоминания промежуточных результатов.
Формат микрокоманд
| MIR – Microinstruction register – регистр микрокоманд (24 bit) | |||||||||||||||||||||||
| A | A MUX | B | B MUX | C | C MUX | RD | WR | ALU | COND | JMP ADDRESS | |||||||||||||
A, B, C – номер регистра для осуществления чтения (A, B) или записи (C)
A MUX, B MUX, C MUX – откуда брать номер регистра
(0 – из команды IR, 1 – из микрокоманды MIR)
RD – чтение из ОЗУ
При этом адрес памяти берется с шины А, а результат подается на шину С
WR – запись в ОЗУ
При этом адрес памяти берется с шины А, а данные - с шины B
ALU – код операции АЛУ
| КОП АЛУ | Операция АЛУ |
| 00 | NOP |
| 01 | ADD |
| 10 | SHRA |
| 11 | NAND |
COND – условие для определения адреса следующей выполняемой микрокоманды
| COND | Куда переходим | |
| 00 | NEXT | на следующую микрокоманду |
| 01 | DECODE | декодирование команды, Address = [KOP]100 |
| 10 | JMP | безусловный переход |
| 11 | JC | условный переход по переносу (Carry Flag) |
JMP ADDRESS – адрес в памяти микропрограмм, куда осуществляется переход
Микрокод
| Адрес | Микрокоманда | Пояснение |
| 0 1 2 3 | IR_HI = NOP(PC); READ PC = ADD(PC, IR_HI) IR_LO = NOP(PC); READ DECODE | чтение старшего слова команды переход к следующему слову (PC = PC + 1) чтение младшего слова команды декодирование считанной команды |
| ADD Rx, Ry, Rz | ||
| 4 | Rx = ADD(Ry, Rz); JMP 62 | сложение содержимого регистров |
| NAND Rx, Ry, Rz | ||
| 12 | Rx = NAND(Ry,Rz); JMP 62 | И-НЕ для содержимого регистров |
| SHR Rx, Ry | ||
| 20 | Rx = SHR(Ry); JMP 62 | арифметич. сдвиг содержимого регистра |
| JC address | ||
| 28 29 30 | Temp0 = NOP(Temp0); JC 30 JMP 62 PC = NOP(IR_LO); JMP 0 | организация условного перехода если условие не выполнилось, то завершить иначе записать в PC новый адрес из IR_LO |
| DEC Rx, Ry | ||
| 36 37 38 | Temp0 = SHR(IR_HI) Temp0 = NAND(Temp0, Temp0) Rx = ADD(Ry,Temp0); JMP 62 | Temp0 = 0 (00000001 à 00000000) Temp0 = -1 (11111111) Rx = Ry + Temp0 = Ry + (-1) |
| SUB Rx, Ry, Rz | ||
| 44 45 46 47 48 | Temp0 = SHR(IR_HI) Temp0 = ADD(Temp0, Rz) Temp0 = NAND(Temp0, Temp0) Temp0 = ADD(Temp0, IR_HI) Rx = ADD(Ry, Temp0); JMP 62 | Temp0 = 0 (00000001 à 00000000) Temp0 = 0 + Rz = Rz инвертировать Temp0 = Rz Temp0 = ( ! Rz) + 1 Rx = Ry + (-Rz) |
| LD Rx, address | ||
| 52 | Rx = NOP(IR_LO); READ; JMP 62 | чтение из ОЗУ (шина A – адрес) |
| ST Ry, address | ||
| 60 61 | Temp0 = NOP(Ry) Temp0 = NOP(IR_LO, Temp0); WRITE; JMP 62 | Temp0 = Ry (данные на шину B) запись в ОЗУ (шина A – адрес, шина B - данные) |
| End: | ||
| 62 | PC = ADD(PC, IR_HI); JMP 0 | увеличение счетчика команд (PC=PC+1) |
Кодировка микрокода
DEPTH = 64; % количество слов %
WIDTH = 24; % размер слова в битах %
ADDRESS_RADIX = DEC; % система счисления для адреса %
DATA_RADIX = BIN; % система счисления для данных %
CONTENT
BEGIN
[0..63] : 0; % по умолчанию везде нули %
% Инициализация %
0: 101100011101100000000000; % IR_HI = NOP(PC); READ %
1: 101111011011000100000000; % PC = ADD(PC, IR_HI) %
2: 101100011111100000000000; % IR_LO = NOP(PC); READ %
3: 000100011001000001000000; % DECODE %
% ADD Rx, Ry, Rz %
4: 000000000000000110111110; % Rx = ADD(Ry, Rz); JMP 62 %
% NAND Rx, Ry, Rz %
12: 000000000000001110111110; % Rx = NAND(Ry,Rz); JMP 62 %
% SHR Rx, Ry %
20: 000000000000001010111110; % Rx = SHR(Ry); JMP 62 %
% JC address %
28: 100110011001000011011110; % Temp0 = NOP(Temp0); JC 30 %
29: 100110011001000010111110; % JMP 62 %
30: 111110011011000010000000; % PC = NOP(IR_LO); JMP 0 %
% DEC Rx, Ry %
36: 110100011001001000000000; % Temp0 = SHR(IR_HI) %
37: 100110011001001100000000; % Temp0 = NAND(Temp0, Temp0) %
38: 000010010000000110111110; % Rx = ADD(Ry,Temp0); JMP 62 %
% SUB Rx, Ry, Rz %
44: 110100011001001000000000; % Temp0 = SHR(IR_HI) %
45: 100100001001000100000000; % Temp0 = ADD(Temp0, Rz) %
46: 100110011001001100000000; % Temp0 = NAND(Temp0, Temp0) %
47: 100111011001000100000000; % Temp0 = ADD(Temp0, IR_HI) %
48: 000010010000000110111110; % Rx = ADD(Ry, Temp0); JMP 62 %
% LD Rx, address %
52: 111100010000100010111110; % Rx = NOP(IR_LO); READ; JMP 62%
% ST Ry, address %
60: 000000011001000000000000; % Temp0 = NOP(Ry) %
61: 111110011001010010111110; % Temp0 = NOP(IR_LO, Temp0);
WRITE; JMP 62 %
62: 101111011011000110000000; % PC = ADD(PC, IR_HI); JMP 0 %
END ;
Примеры выполнения команд
Примеры выполнения каждой команды с указанием значения всех основных сигналов и содержимым основных регистров на каждом такте выполнения приведены на электронном носителе.
Основные сигналы и регистры
| Сокращение | Примечание |
| CLOCK | синхронизирующий сигнал |
| C_SEL[2..0] | номер регистра выбранного в качестве приемника |
| A_SEL[2..0] | номер регистра выбранного в качестве источника 1 |
| B_SEL[2..0] | номер регистра выбранного в качестве источника 2 |
| Rx[2..0] | номер регистра приемника из IR (регистра команд) |
| Ry[2..0] | номер регистра источника 1 из IR (регистра команд) |
| Rz[2..0] | номер регистра источника 2 из IR (регистра команд) |
| MIR_A[2..0] | номер регистра приемника из MIR (р-ра микрокоманд) |
| MIR_B[2..0] | номер регистра источника 1 из MIR (р-ра микрокоманд) |
| MIR_C[2..0] | номер регистра источника 2 из MIR (р-ра микрокоманд) |
| AMUX | Откуда брать номер регистра (0 – из IR, 1 – из MIR) Эти сигналы управляют соответствующими мультиплексорами. |
| BMUX | |
| CMUX | |
| A_bus[7..0] | Данные на шинах источниках, выходящих из блока регистров |
| B_bus[7..0] | |
| C_ALU[7..0] | Результат выходящий из АЛУ |
| C_RAM[7..0] | Данные, считанные из ОЗУ |
| C_bus[7..0] | Выбранные данные для записи (С_ALU или C_RAM) |
| RD | сигнал чтения из ОЗУ |
| WR | сигнал записи в ОЗУ |
| KOP_ALU[1..0] | код операции АЛУ (поступает из MIR) |
| COND[1..0] | определение следующей микрокоманды (из MIR) |
| CBL_SEL[1..0] | результат работы Control Branch Logic (логика управления ветвлением) – определяет следующую микрокоманду |
| CF | флаг переноса, поступающий из АЛУ в Control Branch Logic |
| JMP_ADR[5..0] | адрес следующей микрокоманды (из MIR) |
| MIR[23..0] | полное значение регистра микрокоманд (24 бит) |
| PC | программный счетчик (адрес в ОЗУ) |
Примеры программ
ПРИМЕР 1
DEPTH = 256; % Memory depth and width are required %
WIDTH = 8; % Enter a decimal number %
ADDRESS_RADIX = DEC; % Address and value radixes are optional %
DATA_RADIX = BIN; % Enter BIN, DEC, HEX, or OCT; unless %
CONTENT
BEGIN
%-------------------%
0: 11001000; % LD Rg1, [6] %
1: 00000110;
2: 11010000; % LD Rg2, [7] %
3: 00000111;
4: 00011011; % ADD Rg3, Rg1, Rg2 %
5: 00000000;
6: 00010110; % const 22 (DEC) %
7: 00100001; % const 33 (DEC) %
END ;
ПРИМЕР 2
DEPTH = 256; % Memory depth and width are required %
WIDTH = 8; % Enter a decimal number %
ADDRESS_RADIX = DEC; % Address and value radixes are optional %
DATA_RADIX = BIN; % Enter BIN, DEC, HEX, or OCT; unless %
CONTENT
BEGIN
%-----------------%
0: 11001000; % LD Rg1, [10] %
1: 00001010;
2: 01010010; % SHR Rg2, Rg1 %
3: 00000111;
4: 01100000; % JC 8 %
5: 00001000;
6: 10010010; % DEC Rg2, Rg1 %
7: 00000000;
8: 11100010; % ST Rg1, [10] %
9: 00001010;
10: 00000001; % const = 1 %
END ;
Значения основных сигналов и содержимое основных регистров на каждом такте выполнения данных примеров программ приведены в виде временных диаграмм на электронном носителе.
Определение производительностиСреднее количество микрокоманд при выполнении команды процессора можно приблизительно оценить как 4 + 17/8 + 1 = 7 микрокоманд на команду процессора. Таким образом, при максимальной тактовой частоте в 33,3 МГц средняя производительность процессора составит 4, 7 MOPS (или 33,3 М μops / сек).
| Тестовая программа | Количество команд процессора | Количество микрокоманд | Время выполнения, нс | N / сек |
| ПРИМЕР 1 | 3 | 18 | 540 | 1851851 |
| ПРИМЕР 2 | 5 | 34 | 1020 | 980398 |
Повысить производительность процессора можно одним из следующих способов:
- Увеличить разрядность шины-приемника с 8 до 16 бит, и считывать команду из ОЗУ не за три такта, а за один;
- Увеличить функциональность АЛУ, при этом можно будет сократить длину микрокода для некоторых команд (особенно для SUB и DEC);
- Перейти от микропрограммного управления к управлению на основе жесткой логики;
- Применить конвейеризацию;
- Что-нибудь распараллелить.
Похожие работы
... положит в такой симплекс-таблице текущие базисные переменные равными Ai,0, а свободные - нулю, то будет получено оптимальное решение. Практика применения симплекс метода показала, что число итераций, требуемых для решения задачи линейного программирования обычно колеблется от 2m до 3m, хотя для некоторых специально построенных задач вычисления по правилам симплекс метода превращаются в прямой ...
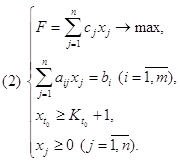
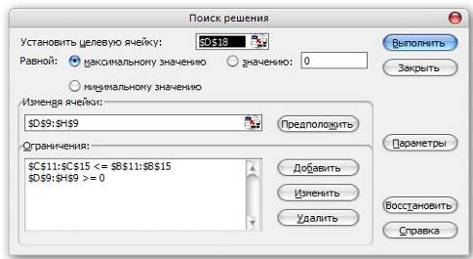
... 0 505/103 0 792/103 669/103 500/103 Анализ Таблицы 6 позволяет сделать вывод о допустимости и оптимальности базиса XБ4=(x5, x7, x1, x2, x4)T. 3.4 Результат решения задачи планирования производства В результате решения поставленной задачи симплекс-методом получили набор производимой продукции x=(x1, x2, x3, x4, x5)=( 15145/103, 8910/103, 0, 1250/103, 3255/103), который удовлетворяет всем ...
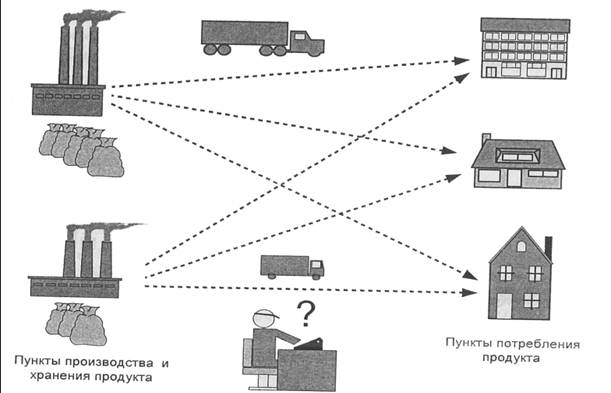
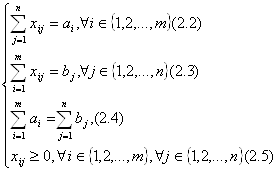

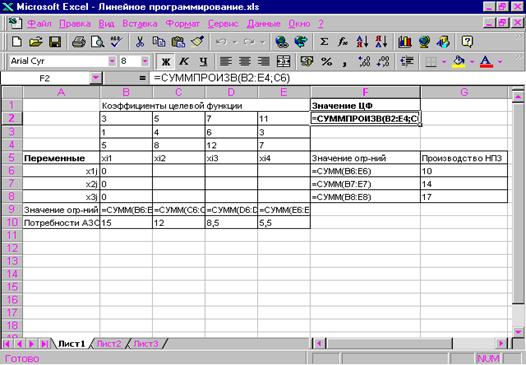
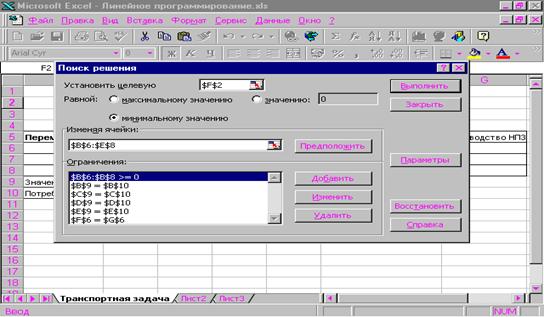
... . При этом значения cij соответствуют коэффициентам целевой функции исходной замкнутой транспортной задачи (1) и в последующем не изменяются. Элементы xij соответствуют значениям переменных промежуточных решений транспортной задачи линейного программирования и изменяются на каждой итерации алгоритма. Если в некоторой ячейке xij=0, то такая ячейка называется свободной, если же xij>0, то такая ...
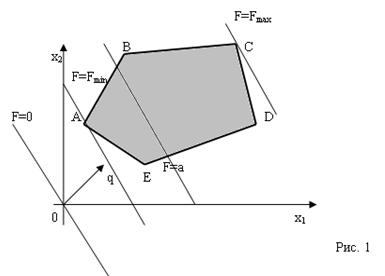

... предложен в середине 1940-х годов Джорджем Данцигом, одним из основателей линейного программирования, еще до того, как компьютеры были использованы для решения линейных задач оптимизации. Формулировка задачи линейного программирования Нужно максимизировать при условиях при i = 1, 2, 3, . . ., m.. Иногда на xi также накладывается некоторый набор ограничений в виде равенств, но от ...
0 комментариев