План
1. Базы данных: определение
2. Основные модели данных
3. Связывание таблиц
4. Нормализация отношений
5. Языки запросов SQL и QBE
1. Базы данных: определение
Основной проблемой, обусловившей развитие теории и практики баз данных, является обеспечение надежного контролируемого хранения необходимых данных между сеансами работы, их передачи между рабочими местами и эффективного их извлечения по мере необходимости.
По мере роста требований к объему хранимой, искомой и передаваемой информации, к скорости и точности выполнения соответствующих операций, работа с данными стала узким звеном в деятельности практически всех организаций, независимо от рода деятельности. В соответствии с этим, начали создаваться и использоваться аппаратные и программные средства автоматизированной обработки информации.
В процессе развития средств обработки данных были выявлены следующие характерные черты "идеальных" информационных систем обработки информации.
Обработка постоянных (перманентных) данных.
Централизованная обработка данных на основе стандартов.
Интеграция данных.
Независимость (самодостаточность) данных от программ обработки.
Целостность хранимых данных (при хранении данных необходимо обеспечить контроль их непротиворечивости (особенно в случае дублирования части данных) и корректности связей между элементами данных).
Эффективность обработки данных.
Язык управления данными.
Наиболее полно удовлетворяют представлению о "идеальной" информационной системе обработки данных именно системы с базами данных.
База данных (БД) - поименованная совокупность структурированных данных, хранимых в памяти вычислительной системы стандартным способом и отображающих состояние объектов и их взаимосвязей в рассматриваемой предметной области.
Рассмотрим подробно данное определение и его элементы:
а) предметная область - фрагмент реального мира, подлежащий автоматизации.
Предметная область содержит только те сущности, их взаимосвязи и процессы изменения сущностей и взаимосвязей, которые необходимы для корректной работы рассматриваемой (разрабатываемой) автоматизированной системы.
Сущностью или информационным объектом предметной области называется некоторое понятие, общее для ряда объектов реального мира. Сущность характеризуется набором признаков, важных для рассматриваемой предметной области, состав которых позволяет отделить объекты (экземпляры) одной сущности от объектов (экземпляров) другой сущности предметной области, а значения которых позволяют отличить различные экземпляры одной сущности. Так, автоматизированная система контроля успеваемости студентов университета содержит списки студентов и академических групп университета (студент и группа - сущности предметной области), информацию о разбиении студентов по группам (связи сущностей группа и студент), правила определения текущего и итогового рейтинга студентов (процессы).
Сущность "студент" характеризуется следующим набором признаков (атрибутов), важных для предметной области "Контроль успеваемости студентов университета": Фамилия, имя, отчество, номер зачетной книжки, номер академической группы, текущий рейтинг по каждому из предметов. Номер зачетной книжки (а также имя, фамилия, отчество) позволяет различить студентов как экземпляров сущности "студент". Академическая группа включает набор признаков: наименование группы, наименование факультета. Состав наборов признаков отличают сущности "группа" и "студент".
б) состояние объектов и их взаимосвязей - под состоянием объекта (как экземпляра сущности) подразумевается набор значений признаков, определяющих объект. Значения признаков могут меняться со временем (т.е. меняется состояние объектов). Так у студента может измениться академическая группа (при переходе на следующий курс) и текущий рейтинг. При переходе на следующий курс также меняется и взаимосвязь объектов - академических групп и студента (был связан с одной группой, стал связан с другой).
в) структурированные данные - данные, элементы которых упорядочены в соответствии с некоторыми соглашениями. К каждому элементу структурированных данных можно обратиться непосредованно, используя информацию о структуре. Например, если данные хранятся в таблице, то имя пятого ученика мы можем получить из ячейки, находящейся на пересечении столбца "Имя" и пятой строки таблицы, если данные структурированы с помощью таблицы. Кроме определения правила расположения элементов данных в общем хранилище данных структурирование часто подразумевает определение типа данных - то есть способа их представления и объема требуемой для их хранения памяти.
г) хранимых в памяти вычислительной машины - подразумевается использование вычислительной техники для хранения данных, в отличие от данных, хранимых не автоматизировано, например библиотечных каталогов.
д) стандартным способом - должно существовать описание правил структурирования данных для того формата, в котором представлена рассматриваемая база данных. В соответствии с этими правилами любое приложение может получить к этим данным доступ независимо от приложения, с помощью которого рассматриваемая база данных была создана.
е) поименованная - совокупность данных должна быть явно определена и фиксирована заданием структуры хранимых данных и имени этой структуры. Каждое приложение работает с определенной базой данных, используя ее имя для доступа к ней.
2. Основные модели данныхХранимые в базе данные имеют определенную логическую структуру, иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД. К числу классических относятся следующие модели данных:
иерархическая,
сетевая,
реляционная.
Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных:
постреляционная,
многомерная,
объектно-ориентированная.
Разрабатываются также всевозможные системы, основанные на других
моделях данных, расширяющих известные модели. В их числе можно назвать
объектно-реляционные, дедуктивно-объектно-ориентированные, семантические, концептуальные модели. Некоторые из этих моделей служат для интеграции баз данных, баз знаний и языков программирования.
В некоторых СУБД поддерживается одновременно несколько моделей
данных.
Рассмотрим реляционную и объектно-ориентированную модель данных.
Потребность в создании простой, универсальной, эффективно реализуемой модели данных привели к созданию реляционной модели. В 1970 году американский математик Кодд предложил схему представления данных на основе реляционных таблиц (отношений, реляций) и набор формальных операций, обеспечивающих решение большинства стандартных задач обработки данных за счет преобразования таблиц.
Реляционная модель данных некоторой предметной области представляет собой набор отношений, изменяющихся во времени.
В свою очередь отношение представляет собой двумерную таблицу с данными, удовлетворяющую требованиям реляционной модели и соответствующую некоторой сущности предметной области.
Атрибуты представляют собой свойства, характеризующие сущность.
В структуре таблицы каждому атрибуту соответствует заголовок некоторого столбца таблицы.
Каждому экземпляру сущности соответствует строка таблицы - кортеж.
Домен представляет собой множество всех возможных значений определенного атрибута отношения.
Схема отношения (заголовок отношения) представляет собой список имен атрибутов. Множество кортежей отношения часто называют содержимым (телом) отношения.
Первичным ключом (ключом отношения, ключевым атрибутом) называется атрибут отношения, однозначно идентифицирующий каждый из его кортежей. Ключ может быть составным (сложным), т.е. состоять из нескольких атрибутов.
Если отношение имеет несколько комбинаций атрибутов, каждая из которых однозначно определяет все кортежи отношения, то все эти комбинации атрибутов являются возможными (потенциальными) ключами отношения. Любой из возможных ключей может быть выбран как первичный.
Если выбранный первичный ключ состоит из минимально необходимого набора атрибутов, говорят, что он является компактным или не избыточным.
Ключи используют для достижения следующих целей:
1) исключения дублирования значений в ключевых атрибутах;
2) упорядочения кортежей. Возможно упорядочение по возрастанию или по убыванию значений всех ключевых атрибутов, а также смешанное упорядочивание - по одним - возрастание, по другим - убывание;
3) ускорения работы с кортежами отношения;
4) организации связывания таблиц.
Пусть в отношении R1 имеется не ключевой атрибут А, значения которого являются значениями ключевого атрибута В другого отношения R2. Тогда говорят, что атрибут А отношения R1 есть внешний ключ.
Реляционная модель накладывает на внешние ключи ограничение для обеспечения целостности данных, называемое ссылочной целостностью. Это означает, что каждому значению внешнего ключа должны соответствовать строки в связываемых отношениях.
Поскольку не всякой таблице можно поставить в соответствие отношение, приведем условия, выполнение которых позволяет таблицу считать отношением.
1. Все строки таблицы должны быть уникальны, т.е. не может быть строк с одинаковыми первичными ключами.
2. Имена столбцов таблицы должны быть различны, а значения их простыми, т.е. недопустима группа значений в одном столбце одной строки.
З. Все строки одной таблицы должны иметь одну структуру, соответствующую именам и типам столбцов.
4. Порядок размещения строк в таблице может быть произвольным.
3. Связывание таблицПри проектировании реальных БД информацию обычно размещают в нескольких таблицах. При этом обычно данные в таблицах логически связаны.
В реляционных СУБД для задания таких связей выполняют операцию их связывания.
Связывание таблиц позволяет:
а) средствами СУБД автоматически выполнять контроль целостности вводимых в базу данных;
б) упростить доступ к данным при выполнении операций поиска, просмотра, редактирования, выборки и подготовки отчетов за счет автоматического обращения к произвольным полям связанных записей.
Связывание выполняется по полям связи, которые могут быть обычными или ключевыми.
Используются следующие основные типы связей:
а) один ко многим (1: M);
б) много к одному (M:
1):
в) один к одному (1:
1);
г) много ко многим (M: M).
Из перечисленных видов связи наиболее широко используется связь вида 1: М. Связь вида 1: 1 можно считать частным случаем связи 1: М, когда одной записи главной таблицы соответствует одна запись вспомогательной таблицы. Связь М: 1 по сути, является "зеркальным отображением" связи 1: М. Оставшийся вид связи М: М характеризуется как слабый вид связи или даже как отсутствие связи. Поэтому в дальнейшем рассматривается связь вида 1: М.
При образовании связи вида 1: М одна запись главной таблицы (главная, родительская запись) оказывается связанной с несколькими записями дополнительной (дополнительные, подчиненные записи).
Контроль целостности связей обычно означает анализ содержимого двух таблиц на соблюдение следующих правил:
каждой записи основной таблицы соответствует нуль или более записей дополнительной таблицы;
каждая запись дополнительной таблицы имеет ровно одну родительскую запись основной таблицы.
Контроль целостности осуществляется при выполнении следующих основных операций над данными двух таблиц:
ввод новых записей,
модификацию записей,
удаление записей.
При вводе данных новых записей возникает вопрос определения такой последовательности ввода записей в таблицы, чтобы не допустить нарушение
целостности.
Исходя из приведенных правил, логичной является схема, при которой данные сначала вводятся в основную таблицу, а потом - в дополнительную. Очередность ввода может быть установлена на уровне целых таблиц или отдельных записей (случай одновременного ввода в несколько открытых таблиц). При этом контроль целостности может заключаться как в запрете выполнения нарушающих целостность действий (режим запрета добавления записи в дочернюю таблицу, если нет соответствующей записи в родительской), так и на обновление связанных записей с целью сделать корректным изменение данных (обработка обновления - исправление значения внешнего ключа во всех дочерних записях при изменении значения первичного ключа в родительской записи).
Таким образом, реляционный метод структурирования данных является одним из наиболее простых для восприятия и эффективных для реализации методов. В соответствии с ним каждая сущность предметной области представляется таблицей. Каждый столбец такой таблицы содержит значения одного из атрибутов сущности.
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом (например, строковым - string) или типом, конструируемым пользователем (определяется как class).
Пример логической структуры объектно-ориентированной БД библиотечного дела приведен на рис.1.
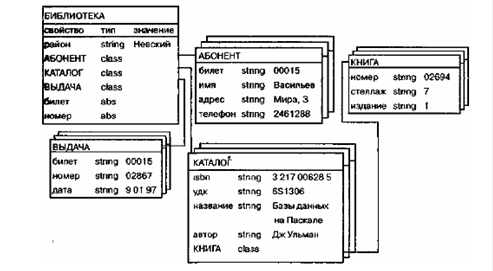
Рис.1. Логическая структура БД библиотечного дела
Здесь объект типа БИБЛИОТЕКА является родительским для объектов-экземпляров классов АБОНЕНТ, КАТАЛОГ и ВЫДАЧА. Различные объекты типа КНИГА могут иметь одного или разных родителей. Объекты типа КНИГА, имеющие одного и того же родителя, должны различаться по крайней мере инвентарным номером (уникален для каждого экземпляра книги), но имеют одинаковые значения свойств isbn, удк, название и автор.
Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма. Ограниченно могут применяться операции, подобные командам SQL (например, для создания БД). Создание и модификация БД сопровождается автоматическим формированием и последующей корректировкой индексов (индексных таблиц), содержащих информацию для быстрого поиска данных.
Рассмотрим кратко понятия инкапсуляции, наследования и полиморфизма применительно к объектно-ориентированной модели БД.
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа КАТАЛОГ добавить свойство, задающее телефон автора книги и имеющее название телефон, то мы получим одноименные свойства у объектов АБОНЕНТ и КАТАЛОГ. Смысл такого свойства будет определяться тем объектом, в который оно инкапсулировано.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа КНИГА, являющимся потомками объекта типа КАТАЛОГ, можно приписать свойства объекта - родителя: isbn, идк, название и автор. Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство типа abs. Так, определение абстрактных свойств билет и номер в объекте БИБЛИОТЕКА приводит к наследованию этих свойств всеми дочерними объектами АБОНЕНТ, КНИГА и ВЫДАЧА. Не случайно поэтому значения свойства билет классов АБОНЕНТ и ВЫДАЧА, показанных на рисунке, будут одинаковыми - 00015.
Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к нашей объектно-ориентированной БД полиморфизм означает, что объекты класса КНИГА, имеющие разных родителей из класса КАТАЛОГ, могут иметь разный набор свойств. Следовательно, программы работы с объектами класса КНИГА могут содержать полиморфный код.
Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД.
Определяемый пользователем объект, называемый объектом-целью (свойство объекта имеет тип goal), в общем случае может представлять собой подмножество всей хранимой в БД иерархии объектов. Объект-цель, а также результат выполнения запроса могут храниться в самой базе. Пример запроса о номерах читательских билетов и именах абонентов, получавших в библиотеке хотя бы одну книгу, показан на рис.2.
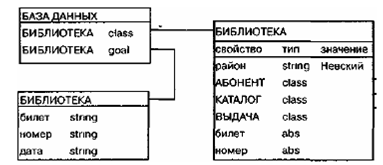
Рис 2. Фрагмент БД с объектом-целью
Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
4. Нормализация отношенийВажным критерием качества разрабатываемой схемы БД является скорость выполнения операций обновления данных (вставки, модификации, удаления записей).
Выбор схемы БД определяет возникновение в процессе ее эксплуатации тех или иных аномалий обновления.
Аномалия обновления - появление в базе данных несогласованности данных при выполнении операций вставки, удаления, модификации записей.
Аномалии модификации - возникновение несогласованности записей в
таблице при изменении данных в одной записи.
Для отношения "Студент" (ФИО, Группа, Староста), где в столбце "Группа" хранится полное название группы, а столбец "Староста" содержит ФИО старосты группы, изменение значения "Староста" (например, для устранения ошибки) может привести к существованию более одного старосты одной и той же группы.
Аномалии удаления - удаление лишней информации при удалении записи.
Для отношения "Студент" (ФИО, Группа, Староста), удаление студента может привести к удалению из БД и ФИО старосты группы (в том случае, если для данной группы запись - единственная).
Аномалии вставки - добавление лишней информации или возникновение противоречащих значений в некоторых столбцах при вставке новой записи
Для отношения "Студент" (ФИО, Группа, Староста), где в столбце "Группа" хранится полное название группы, а столбец "Староста" содержит ФИО старосты группы, добавление названия новой группы повлечет обязательное определение ФИО студента и старосты, в то время как эти данные могут быть пока не известны. В то же время, при добавлении нового студента значение поля "Староста" в новой записи может не совпадать со значением данного поля для другого студента этой же группы.
Для сохранения корректности БД необходимо устранять данные аномалии, выполняя дополнительные операции по просмотру и модификации данных.
Потери в производительности, вызванные выполнением действий по устранению аномалий, могут быть весьма существенными, при этом данные потери, в большинстве случаев, не являются неизбежными, а определяются неудачным выбором схемы БД.
Указанные аномалии связаны с избыточностью (дублированием) данных в БД.
Определить дублирование данных в БД, а значит и предсказать возможность возникновения аномалий обновления можно на этапе проектирования структуры базы данных.
Одним из наиболее алгоритмически и понятийно простых методов устранения избыточности хранения данных является метод нормальных форм, который основан на анализе функциональных зависимостей (ФЗ) атрибутов отношений.
Если даны два атрибута X и Y некоторого отношения, то говорят, что Y функционально зависит от X, если в любой момент времени каждому значению X соответствует ровно одно значение Y. Функциональная зависимость обозначается X◊Y.
Обратимый пошаговый процесс замены данной совокупности отношений другой схемой с устранением избыточных функциональных зависимостей называется нормализацией.
Процесс проектирования БД с использованием метода нормальных форм (нормализация) заключается в последовательном переводе отношений из первой нормальной формы в нормальные формы более высокого порядка по определенным правилам. Каждая следующая нормальная форма ограничивает определенный тип функциональных зависимостей, устраняет соответствующие аномалии при выполнении операций над отношениями БД и сохраняет свойства предшествующих нормальных форм.
Процесс формального построения нормализованных отношений проектируемой базы данных может быть начат с формирования одной таблицы, содержащей все атрибуты всех сущностей предметной области.
Рассмотрим предметную область - распределение учебной нагрузки по
преподавателям одной кафедры. Предположим, что у каждой группы каждый
предмет ведет только один преподаватель. Помимо личных данных преподавателя необходимо хранить данные по группе (Наименование, Староста) и для пары (Преподаватель, Группа) необходимо хранить список предметов, которые данный преподаватель преподает в данной группе.
В качестве исходной таблицы возьмем:
| А | В | С |
| Личные данные преподавателя: ФИО, Должность, Оклад | Данные группы: Наименование, Староста | Предметы |
В качестве первичного ключа таблицы возьмем столбцы "Личные данные Преподавателя" и "Данные группы", поскольку существует только одна ФЗ: AB◊C.
Отношение находится в первой нормальной форме (1НФ), если значения всех его атрибутов атомарны.
Выполним преобразование для таблицы примера:
1. Столбец личных данных преобразуем в четыре столбца:
"Преподаватель" (ФИО), "Табельный №", "Должность", "Оклад". Теперь ключ - "Табельный №" и "Данные группы".
2. Столбец "Данные группы" преобразуем в два столбца: "Группа" (Наименование), "Староста". Теперь ключ - "Табельный №" и "Группа".
3. Столбец "Предметы" преобразуем в столбец "Предмет". Как альтернатива, можно создать новую таблицу "Предметы", которая будет содержать первичный ключ исходного отношения ("Табельный №", "Группа") и столбец "Предмет".
В результате получено отношение А В С D E F
Преподаватель Должность Оклад Группа Староста Предмет
Выявленные функциональные зависимости:
А◊В, С; В◊С; D◊Е; DF◊А.
Первичный ключ: DF, так как от DF зависят остальные атрибуты.
Вторая нормальная форма позволяет устранить избыточность данных, связанную с хранением информации различного типа в одном отношении.
Отношение находится во второй нормальной форме (2НФ), если оно находится в 1НФ и каждый неключевой атрибут функционально полно зависит от ключа.
Другими словами отношение во второй нормальной форме - отношение без атрибутов, находящихся в частичной функциональной зависимости от ключевых атрибутов.
Отношения, не во 2НФ допускают аномалии обновления, заключающиеся в необходимости обновлений (удалений, модификаций, вставки) строк со значением атрибута, функционально неполно зависящего от ключа, во всех строках, где он встречается с соответствующим значением части ключа, потребуется выполнить контроль соответствия нового сочетания (часть ключа - атрибут) и уже существующих, а при удалении строк может теряться и нужная информации о имеющем место факте вида "часть ключа - атрибут".
Для атрибутов, функционально полно зависящих от ключа, каждое изменение затрагивает только одну строку - строку с изменяемым значением. Приведение отношения ко 2НФ позволяет исключить данный тип аномалий обновления.
Пример:
Отношение
А В С D E F
Преподаватель Должность Оклад Группа Староста Предмет
находится в 1НФ.
При этом отношение допускает следующие аномалии обновления:
а) аномалия вставки - при изменении старосты группы необходимо будет изменить соответствующее значение во всех строках с таким же значением группы;
б) аномалия удаления - при удалении информации о предмете, читаемом преподавателем в некоторой группе, может потеряться и другая информация - о старосте группы;
в) аномалия модификации - при изменении старосты в группе следует обновить все записи с таким же значением "Группы".
Преобразуем отношение из примера из 1НФ во 2НФ:
В зависимости D◊E атрибут E функционально зависит от части ключа DF.
Таким образом формируем:
а) новое отношение без частичной зависимости:
ПК: DF, ФЗ: А◊B,C; B◊C; DF◊A.
б) новое отношение для бывшей частичной зависимости
D E
Руководство Группы (Группа, Староста)
ПК: D, ФЗ: D◊E.
Теперь в обоих отношениях отсутствуют частичные зависимости от ключа.
Благодаря данной декомпозиции мы предотвратили аномалии обновления, возникающие из-за дублирования значений "Староста" в исходной таблице.
Важным моментом является возможность восстановления исходной схемы естественным соединением полученных отношений (по атрибуту "Группа")
Отношение находится в третьей нормальной форме (3НФ), если оно находится во 2НФ и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Транзитивная зависимость наблюдается в том случае, если один из двух описательных реквизитов зависит от ключа, а другой описательный реквизит зависит от первого описательного реквизита.
Пример:
Отношение
A B C D F
(Преподаватель, Должность, Оклад, Группа, Предмет)
ПК: DF, ФЗ: DF◊А◊B◊C.
находится во второй нормальной форме.
При этом оно допускает следующие аномалии обновления:
а) аномалия модификации - при изменении значения должности преподавателя, необходимо будет выполнить изменение значения должности
для всех строк с данным преподавателем и изменение значение оклада в соответствии с новой должностью;
б) аномалия удаления - заключается в потере информации об окладе преподавателя в некоторой должности при удалении единственного преподавателя, занимающего данную должность;
в) аномалия добавления - заключается в необходимости назначения хотя бы одного сотрудника на новую должность добавлении в БД оклада по должности.
Преобразуем данное отношение из примера из 2НФ в 3НФ:
A B C D F
(Преподаватель, Должность, Оклад, Группа, Предмет)
ПК: DF, ФЗ: DF◊А◊В◊C.
I. Cпроецируем отношение на атрибуты A, B, C
A B C
(Преподаватель, Должность, Оклад)
ПК: A, ФЗ: А◊B◊C.
II. Заметим, что полученное отношение вновь содержит транзитивную зависимость, снова декомпозируем его на два отношения:
B C
Зарплата (Должность, Оклад)
ПК: B, ФЗ: B◊C.
A B
Обязанность (Преподаватель, Должность,)
ПК: A, ФЗ: A◊B.
б) спроецируем отношение на атрибуты, кроме B, C
A D F
План (Преподаватель, Группа, Предмет)
ПК: DF, ФЗ: DF◊A.
К исходной схеме без потери кортежей и функциональных зависимостей можно вернуться естественным соединением отношений "Зарплата" и "Обязанность", затем - естественным соединением полученного отношения и отношения "План".
5. Языки запросов SQL и QBEХранимые в базе данные можно обрабатывать вручную, последовательно просматривая и редактируя данные в таблицах с помощью имеющихся в СУБД средств. Для повышения эффективности обработки данных применяют запросы, позволяющие производить множественную обработку данных, т, е. одновременно вводить, редактировать и удалять множество записей, а также выбирать данные из таблиц.
Запрос представляет собой специальным образом описанное требование, определяющее состав производимых над БД операций по выборке, удалению или модификации хранимых данных.
Для подготовки запросов с помощью различных СУБД чаще всего используются два основных языка описания запросов:
QBE (Query By Example) - язык запросов по образцу;
SQL (Structured Query Language) - структурированный язык запросов.
Мир баз данных становится все более и более единым, что привело к необходимости создания стандартного языка, который мог бы использоваться, чтобы функционировать в большом количестве различных видов компьютерных сред. Стандартный язык позволит пользователям, знающим один набор команд, использовать их, чтобы создавать, отыскивать, изменять и передавать информацию, независимо от того, работают ли они на персональном компьютере, сетевой рабочей станции, или на универсальной ЭВМ.
SQL - это язык, который дает возможность создавать и работать в реляционных базах данных, которые являются наборами связанной информации, сохраняемой в таблицах. Он устраняет много работы, которую вы должны были бы сделать если бы вы использовали универсальный язык программирования.
Стандарт SQL определяется ANSI (American National Standard Institute - Американским Национальным Институтом Стандартов.
Имеются два SQL: Интерактивный (Interactive) и Встроенный (Embedded). Большей частью, обе формы работают одинаково, но используются различно.
Интерактивный SQL используется для функционирования непосредственно в базе данных, чтобы производить вывод для использования его заказчиком. В этой форме SQL, когда вы введете команду, она сейчас же выполнится, и вы сможете увидеть вывод (если он вообще получится) - немедленно.
Встроенный SQL состоит из команд SQL, помещенных внутри программ, которые обычно написаны на некотором другом языке. Это делает эти программы более мощными и эффективным.
И в интерактивной, и во встроенной формах SQL, имеются многочисленные части, или подразделы. Они являются составными частями SQL в ANSI. Это не различные языки, а разделы команд SQL, сгруппированных по их функциям
DDL (Data Definition Language - Язык Определения Данных) - так называемый Язык Описания Схемы в ANSI, состоит из команд, которые создают объекты (таблицы, индексы, просмотры, и так далее) в базе данных.
DML (Data Manipulation Language - Язык Манипулирования Данными) - это набор команд, которые определяют, какие значения представлены в таблицах в любой момент времени.
DCL (Data Control Language - Язык Управления Данными) состоит из средств, которые определяют, разрешить ли пользователю выполнять определенные действия или нет.
Теоретической основой языка QBE является реляционное исчисление с
переменными-доменами (однако в языке присутствуют и элементы исчисления кортежей).
Язык QBE позволяет задавать сложные запросы к БД путем заполнения предлагаемой СУБД запросной формы (иногда также используют термин QBЕ - запрос по форме).
Такой способ задания запросов обеспечивает высокую наглядность и не требует указания алгоритма выполнения операции - достаточно описать образец ожидаемого результата.
В каждой из современных реляционных СУБД имеется свой вариант языка QBE.
На языке QBE можно задавать однотабличные и многотабличные (выбирающие или обрабатывающие данные из нескольких связанных таблиц) запросы.
С помощью запросов на языке QBE можно выполнять следующие основные операции:
выборку данных;
вычисление над данными;
вставку новых записей;
удаление записей;
модификацию (изменение) данных.
Результатом выполнения запроса является новая таблица, называемая ответной (первые две операции), или обновленная исходная таблица (остальные операции). В реальных приложениях баз данных QBE используется в основном для выборки данных.
Выборка, вставка, удаление и модификация могут производиться безусловно или в соответствии с условиями, задаваемыми с помощью логических выражений. Вычисления над данными задаются с помощью арифметических выражений и порождают в ответных таблицах новые поля, называемые вычисляемыми.
Запросная форма обычно имеет вид таблицы, имя и названия полей которой совпадают с именем и названиями полей соответствующей исходной
таблицы. Чтобы узнать имена доступных таблиц БД, в языке QBE предусмотрен запрос на выборку имен таблиц. Названия полей исходной таблицы могут вводиться в шаблон вручную или автоматически. Во втором случае используется запрос на выборку заголовков столбцов.
В современных СУБД, например, в Access и Visual FoxPro, многие действия по подготовке запросов с помощью языка QBE выполняются визуально с помощью мыши. В частности, визуальное связывание таблиц при подготовке запроса выполняется не элементами примеров, а просто "протаскиванием" мышью поля одной таблицы к полю другой.
По возможностям манипулирования данными при описании запросов указанные языки практически эквивалентны. Более того, на практике запрос, составленный на QBE, обычно транслируется в SQL - запрос и лишь затем выполняется.
Главное отличие между данными языками заключается в способе формирования запросов: язык QBE предполагает ручное или визуальное формирование запроса, в то время как использование SQL означает программирование запроса.
Похожие работы
... ». ЦЕЛЬ КУРСОВОЙ РАБОТЫ Основываясь на аргументации об актуальности выбранной темы, можно определить целевую ориентацию работы. Цель курсовой работы рассмотреть и проанализировать этапы истории развития теории и практики менеджмента. В соответствии с данной целью в курсовой работе мною решаются следующие задачи: 1.Выявить основные стадии развития науки управления и проследить попытки ...
... самостоятельную учебную дисциплину и область научных знаний [9, с.32]. Четвёртый, или информационный, период (с 1950 г. по настоящее время) характеризуется наиболее интенсивным развитием кибернетических и других теорий и практики менеджмента. Он связан с разработками более поздних научных школ и концепций управления, опирающихся на использование количественного (математического), системного ...
... (в виде связей). В последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных. Физическая организация баз данных Физическая организация данных определяет собой способ непосредственного размещения данных на машинном носителе. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства ...
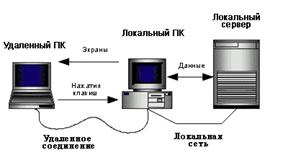
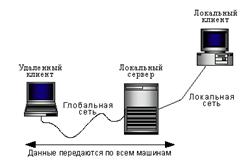
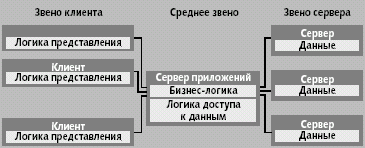
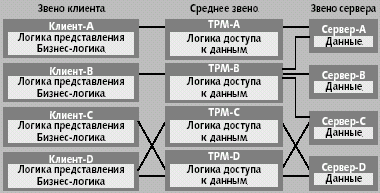
... на будущее. DAO и RDO известны уже достаточно давно, и появление двух разных механизмов было связано с необходимостью оптимизации решения двух отдельных задач: доступа к локальным и удаленным базам данных соответственно. Однако естественное развитие вычислительных систем привело к необходимости создания единого механизма, который обеспечил бы единый подход при работе с БД различных классов. В ...
0 комментариев