Міністерство освіти і науки України
Дніпропетровський національний університет
Факультет фізики, електроніки та комп’ютерних систем
Курсова робота
з дисципліни
об’єктно-орієнтовне програмування
на тему: "Розробка власного класу String"
Виконав:
ст. гр. РС-05-1
Тимощенко П.А.
Перевірив:
доц. Вовк С.М.
Дніпропетровськ 2007
Содержание
Завдання
1. Теоретична частина
1.1 Введення в об’єктно-орієнтовну технологію
1.2 Визначення структур
1.3 Доступ до елементів структури
1.4 Використання визначеного користувачем типу Time за допомогою Struct
1.5 Використання абстрактного типу даних Time за допомогою класу
1.6 Область дії клас і доступ до елементів класу
1.7 Конструктор класу
1.8 Конструктор копіювання
1.9 Деструктор класу
1.10 Явний виклик деструктора
1.11 Небезпека збільшення розміру програми
1.12 Константні об'єкти й функції-елементи
1.13 Друзі
1.14 Ядро ООП: Успадкування та поліморфізм
1.4.1 Похідні класи
1.14.2 Функції-члени
1.14.3 Конструктори й деструктори
1.14.4 Ієрархія класів
1.14.5 Поля типу
1.14.6 Віртуальні функції
1.14.7 Абстрактні класи
1.14.8 Множинне входження базового класу
1.14.9 Вирішення неоднозначності
1.14.10 Віртуальні базові класи
1.14.11 Контроль доступу
1.14.12 Захищені члени
1.14.13 Доступ до базових класів
1.14.14 Вільна пам'ять
1.14.15 Віртуальні конструктори
1.15 Перевантаження операцій
1.15.1 Операторні функції
1.15.2 Бінарні й унарні операції
1.15.3 Операторні функції й типи користувача
1.15.4 Конструктори
1.15.5 Присвоювання й ініціалізація
1.15.6 Інкремент і декремент
1.15.7 Перевантаження операцій помістити в потік і взяти з потоку
2. Розробка власного класу clsString
2.1 Загальний алгоритм вирішення
2.2 Детальний анализ
2.3 Тестування
Висновки
Література
Додатки
Завдання
Розробити клас classString, на основі якого можна створювати об'єкти типу "рядок символів". Цей клас повинен надавати можливість створення програм, в яких реалізуються обробка рядків символів. В класі повинні бути визначені методи присвоєння рядків, додавання рядків, вставки рядка в рядок з заданого місця та вилучення певної кількості символів з рядка, звертання до окремого елементу рядка, операції відношень для порівняння рядків (більше, менше, рівно, нерівно), операції вставки рядка в потік введення/виведення та його вилучення з потоку, метод визначення довжини рядка, тощо. Розробку виконувати в середовищі Borland C++ Builder або MS Visual Studio C++.
1. Теоретична частина 1.1 Введення в об’єктно-орієнтовну технологію
Подивіться навколо себе на реальній світ. Куди б ви не подивились завжди знаходяться об’єкти! Люди, тварини, рослини, автомобілі, літаки, комп’ютери і тощо. Людина кумекає в термінах об’єктів. Мі володіємо чудовою можливістю абстрагувати, що дозволяє нам бачити картинки на екрані (людей, дерева, літаки) саме у вигляді об’єктів, а не у вигляді окремих кольорових точок.
Як би ми не класифікували ці об’єкти, всі вони мають спільні атрибути: форма, колір, маса тощо. Кожен з них має свій набір рухів, наприклад, м’яч котиться, підстрибує, спускає, дитина кричить, сміється, спить, їсть, блимає очима тощо.
Людство пізнає об’єкти шляхом вивчення їх атрибутів. Різні об’єкти можуть мати багато однакових атрибутів та представляти схожу поведінку.
Об’єктно-орієнтовне програмування (ООП) моделює об'єкти реального світу за допомогою програмних аналогів. Це приводить до появи відносин класів, коли об'єкти певного класу - такого, як клас засобів пересування - мають однакові характеристики. Це висуває відносини спадкування й навіть відносини множинного спадкування, коли знову створювані класи здобувають наслідувані характеристики існуючих класів, а також містять свої власні унікальні характеристики. Об'єкти класу автомобілів з відкидним верхом виразно мають характеристики класу автомобілів, але дах у них відкидається й закривається.
Об’єктно-орієнтовне програмування дає нам найбільш природний і інтуїтивний спосіб розгляду процесу програмування як моделювання реально існуючих об'єктів, їхніх атрибутів і поводження. ООП моделює також зв'язок між об'єктами. Подібно тому, як люди посилають один одному повідомлення (наприклад, сержант, командуючий групі стояти струнко), об'єкти теж зв'язуються один з одним за допомогою повідомлень.
ООП інкапсулює дані (атрибути) і функції (способи поводження) у пакети, називані об'єктами; дані й функції об'єктів тісно взаємозалежні. Об'єкти мають властивість приховування інформації. Це означає, що хоча об'єкти можуть знати, як зв'язатися один з одним за допомогою добре визначених інтерфейсів, вони не знають, як реалізовані інші об'єкти - деталі реалізації заховані всередині самих об'єктів. Безсумнівно, можна ефективно їздити на автомобілі, не знаючи деталей того, як працює його мотор, трансмісія й система вихлопу.
У С та інших мовах процедурного програмування програмування має тенденцію бути орієнтованим на дії, тоді як в C++ програмування прагне бути орієнтованим на об'єкти. У С одиницею програмування є функція. В C++ одиницею програмування є клас, на основі якого в кінцевому результаті створюються екземпляри об'єктів.
Програмісти, що використають С, зосереджені на написанні функцій. Групи дій, що виконують деяке загальне завдання, формуються у вигляді функцій, а функції групуються так, щоб сформувати програму. Дані звичайно важливі в С, але існує думка, що дані призначені в першу чергу для підтримки виконуваних функціями дій. Дієслова в оголошенні системи допомагають програмістові на С при розробці системи визначити набір функцій, які, працюючи спільно, і забезпечують функціонування системи.
Програмісти на C++ зосереджені на створенні своїх власних обумовлених користувачем типів, названих класами. Кожний клас містять дані й набір функцій, які маніпулюють цими даними. Компоненти дані класу називаються даними-елементами (елементами даних). Компоненти функції класу називаються функціями-елементами. Точно так само, як екземпляр вбудованого типу, такого як int, називається змінної, екземпляр певного користувачем типу (тобто класу) називається об'єктом. Програміст використає вбудовані типи як блоки для конструювання певних користувачем типів. В C++ увага фокусується скоріше на об'єктах, чим на функціях. Імена іменники в описі системи допомагають програмістові на C++ при створенні системи визначити набір класів, з яких будуть створені об'єкти, які, працюючи спільно, і забезпечують функціонування системи.
Класи для об’єктів є тим же самим, що і проекти для домів. Можна збудувати багато домів згідно одного проекту, і можна реалізувати багато об’єктів з одного класу. Наприклад, в об’єктно-орієнтовному проектуванні банку клас BankTeller, повинен співвідноситися з класом BankAccount. Ці співвідношення називають асоціативними.
Класи в С++ є природнім продовженням структури struck в мові С. Тому, перш ніж, розглядати специфіку розробки класів на С++, мі розглянемо та побудуємо визначений користувачем тип, оснований на структурі. Недоліки, які ми побачимо при цьому, допоможуть пояснити запис класу.
1.2 Визначення структур
Структури - це складені типи даних, побудовані з використанням інших типів. Розглянемо наступне визначення структури:
struct Time
{
int hour; // 0-23
int minute; // 0-59
int second; // 0-59
}
Ключове слово struct починає визначення структури. Ідентифікатор Time - тег (позначення, ім'я-етикетка) структури. Тег структури використається при об’явленні змінних структур даного типу. У цьому прикладі ім'я нового типу - Time. Імена, об’явленні у фігурних дужках опису структури - це елементи структури. Елементи однієї й тієї ж структури повинні мати унікальні імена, але дві різні структури можуть містити не конфліктуючі елементи з однаковими іменами. Кожне визначення структури повинне закінчуватися крапкою з комою. Наведене пояснення, як ми незабаром побачимо, вірно й для класів.
Визначення Time містить три елементи типу int - hour, minute і second (годинники, хвилини й секунди). Елементи структури можуть бути будь-якого типу й одна структура може містити елементи багатьох різних типів. Структура не може, однак, містити екземпляри самої себе. Наприклад, елемент типу Time не може бути оголошений у визначенні структури Time. Однак, може бути включений вказівник на іншу структуру Time. Структура, що містить елемент, котрий є вказівником на такий же структурний тип, називається структурою із самоадресацією. Структури із самоадресацією корисні для формування зв'язних структур даних.
Попереднє визначення структури даних не резервує ніякого простору в пам'яті; визначення тільки створює новий тип даних, що використається для об’явлення змінних. Змінні структури об’явленні так само, як змінні інших типів. Об’явлення
Time timeObject, timeArray [10], *timePtr;
повідомляє timeObject змінна типу Time, timeArray - масив з 10 елементів типу Time, a timePtr - вказівник на об'єкт типу Time.
1.3 Доступ до елементів структури
Для доступу до елементів структури (або класу) використовуються операції доступу до елементів - операція крапка () і операція стрілка (->).
Операція крапка звертається до елемента структури (або класу) по імені змінної об'єкта або по посиланню на об'єкт.
Наприклад, щоб надрукувати елемент hour структури timeObject використається оператор
cout << timeObject. hour;
Операція стрільця, що складається зі знака мінус (-) і знака більше (>), записаних без пропусків, забезпечує доступ до елемента структури (або класу) через вказівник на об'єкт. Припустимо, що вказівник timePtr був уже об’явлений як посилання на об'єкт типу Time і що адреса структури timeObiect була вже присвоєна timePtr. Тоді, щоб надрукувати елемент hour структури timeObject з вказівником timePtr, можна використати оператор
cout << timePtr->hour;
Вираз timePtr->hour еквівалентний (*timePtr). hour, що розіменовує вказівник і робить доступним елемент hour через операцію крапка. Дужки потрібні тому, що операція крапка має більш високий пріоритет, ніж операція розіменування вказівника (*). Операції стрілка й крапка поряд із круглими й квадратними дужками мають другий найвищий пріоритет (після операції дозволу області дії) і асоціативності зліва направо.
1.4 Використання визначеного користувачем типу Time за допомогою Struct
Програма на мал.1 створює визначений користувачем тип структури Time із трьома цілими елементами: hour, minute і second. Програма визначає єдину структуру типу Time, названу dinnerTime, і використовує операцію крапка для присвоєння елементам структури початкових значень 18 для hour, 30 для minute і 0 для second. Потім програма друкує час у військовому (24-годинному) і стандартному (12-годинному) форматах. Помітимо, що функції друку приймають посилання на постійні структури типу Time. Це є причиною того, що структури Time передаються друкуючим функціям по посиланню - цим виключаються накладні витрати на копіювання, пов'язані з передачею структур функціям за значенням, а використання const запобігає зміні структури типу Time функціями друку. Далі ми обговоримо об'єкти const і функції-елементи const.
Порада з підвищення ефективності: Щоб уникнути накладних витрат, пов’язаних із передачею по значенню й одержати користь захисту початкових даних від зміни, передавайте аргументи великого розміру як посилання const.
Існують перешкоди створенню нових типів даних зазначеним способом за допомогою структур. Оскільки ініціалізація структур спеціально не потрібна, можна мати дані без початкових значень і випливаючи звідси проблеми. Навіть якщо дані одержали початкові значення, можливо, це було зроблено невірно. Неправильні значення можуть бути привласнені елементам структури (як ми зробили на мал.1), тому що програма має прямий доступ до даних. Програма присвоїла невірні значення всім трьом елементам об'єкта dinnerTime типу Time. Якщо реалізація struct зміниться (наприклад, час тепер буде представляється як число секунд після півночі), то всі програми, які використовують struct, потрібно буде змінити. Не існує ніякого "інтерфейсу", гарантуючого те, що програміст правильно використає тип даних і що дані є несуперечливими.
// Створення структури, завдання й друк її елементів.
#include <iostream. h>
struct Time { // визначення структури
int hour; // 0-23
int minute; // 0-59
int second; // 0-59 };
void printMilitary (const Time &); // прототип void printStandard (const Time &); // прототип
main ()
{
Time dinnerTime; // змінна нового типу Time
// завдання елементам правильні значення dinnerTime. hour = 18; dinnerTime. minute = 30; dinnerTime. second = 0;
cout " "Обід відбудеться в ";
printMilitary (dinnerTime);
cout " " за військовим часом," " endl
<< "що відповідає "; printStandard{dinnerTime); cout << " за стандартним часом." << endl;
// завдання елементам неправильних значень
dinnerTime. hour = 29;
dinnerTime. minute = 73; dinnerTime. second = 103;
cout " endl << "Час із неправильними значеннями: "; printMilitary (dinnerTime); cout << endl; return 0;
// Друк часу у військовому форматі void printMilitary (const Time &t)
{
cout " (t. hour < 10?"0": "")" t. hour
"": "" (t. minute < 10?"0": "")" t. minute
"": "" (t. second < 10?"0": "")" t. second;
}
// друк часу в стандартному форматі
void printStandard (const Time &t)
{
cout " ( (t. hour == 0 || t. hour == 12)? 12: t. hour%12)" ": "" (t. minute < 10?"0": "")" t. minute " ": "" (t. second < 10?"0": "")" t. second " (t. hour < 12?" AM": " PM");
}
Обід відбудеться в 18: 30: 00 за військовим часом,
що відповідає 6: 30: 00 РМ за стандартним часом.
Час із неправильними значеннями: 29: 73: 103
Мал.1. Створення структури, завдання й друк її елементів
Існують і інші проблеми, пов'язані зі структурами в стилі С. У С структури не можуть бути надруковані як єдине ціле, тільки по одному елементу з відповідним форматом кожного. Для друку елементів структури в якому-небудь потрібному форматі повинна бути написана функція. "Перевантаження операцій" покаже, як перевантажити операцію ", щоб надати можливість простого друку об'єктів типу структура (C++ розширює поняття структури) або типу клас. У С структури не можна порівнювати в цілком, їх потрібно порівнювати елемент за елементом. Далі покажемо, як перевантажити операції перевірки рівності й відношення, щоб можна було в С++ порівнювати об'єкти типів структура й клас.
У наступному розділі ми знову використаємо нашу структуру Time, але вже як клас, і продемонструємо деякі переваги створення таких, так званих абстрактних типів даних, як класи. Ми побачимо, що класи й структури в C++ можна використовувати майже однаково. Різниця між ними складається в доступності за замовчуванням елементів кожного із цих типів. Це буде більш детально пояснено пізніше.
1.5 Використання абстрактного типу даних Time за допомогою класу
Класи надають програмістові можливість моделювати об'єкти, які мають атрибути (представлені як дані-елементи) і варіанти поведінки або операції (представлені як функції-елементи). Типи, що містять дані-елементи й функції-елементи, звичайно визначаються в C++ за допомогою ключового слова class.
Функції-елементи іноді в інших об’єктно-орієнтовних мовах називають методами, вони викликаються у відповідь на повідомлення, що посилаються об'єкту. Повідомлення відповідає виклику функції-елемента.
Коли клас визначений, ім'я класу може бути використане для об’явлення об'єкта цього класу. Мал.1 містить просте визначення класу Time.
Визначення нашого класу Time починається із ключового слова class. Тіло визначення класу береться у фігурні дужки ({ }). Визначення класу закінчується крапкою з комою. Визначення нашого класу Time, як і нашої структури Time, містить три цілих елементи hour, minute і second.
сlass Time {
public:
Time ();
void setTime (int, int, int);
void printMilitary ();
void printStandatd (); private:
int hour; // 0-23
int minute; // 0 - 59
int second; // 0-59
};
Мал.1 Просте визначення класу
Інші частини визначення класу - нові. Мітки public: (відкрита) і private: закрита) називаються специфікаторами доступу до елементів. Будь-які дані-елементи й функції-елементи, об’явлені після специфікатора доступу до елементів public: (і до наступного специфікатора доступу до елементів), доступні при будь-якому звертанні програми до об'єкта класу Time. Будь-які дані-елементи й функції-елементи, об’явлені після специфікатора доступу до елементів private: (і до наступного специфікатора доступу до елементів), доступні тільки функціям-елементам цього класу. Специфікатори доступу до елементів завжди закінчуються двокрапкою (:) і можуть з'являтися у визначенні класу багато разів і в будь-якому порядку. Надалі в тексті нашої роботи ми будемо використовувати записи специфікаторів доступу до елементів у вигляді public і private (без двокрапки).
Гарний стиль програмування: Використовуйте при визначенні класу кожний специфікатор доступу до елементів тільки один раз, що зробить програму більш ясною й простій для читання. Розміщайте першими елементи public, що є загальнодоступними.
Визначення класу в нашій програмі містить після специфікатора доступу до елементів public прототипи наступних чотирьох функцій-елементів: Time, setTime, printMilitary і printStandard. Це - відкриті функції-елементи або відкритий інтерфейс послуг класу. Ці функції будуть використовуватися клієнтами класу (тобто частинами програми, що грають роль користувачів) для маніпуляцій з даними цього класу.
Зверніть увагу на функцію-елемент із тим же ім'ям, що й клас. Вона називається конструктором цього класу. Конструктор - це спеціальна функція-елемент, що ініціалізує дані-елементи об'єкта цього класу. Конструктор класу викликається автоматично при створенні об'єкта цього класу. Ми побачимо, що звичайно клас має декілька конструкторів; це досягається за допомогою перевантаження функції.
Після специфікатора доступу до елементів private слідують три цілих елементи. Це говорить про те, що ці дані-елементи класу є доступними тільки функціям-елементам класу й, як ми побачимо далі, "друзям" класу. Таким чином, дані-елементи можуть бути доступні тільки чотирьом функціям, прототипи яких включені у визначення цього класу (або друзів цього класу). Звичайно дані-елементи перераховуються в частині private, а функції-елементи - у частині public. Як ми побачимо далі, можна мати функції-елементи private і дані public; останнє не типовим й вважається в програмуванні поганим тоном.
Коли клас визначений, його можна використати як тип в оголошеннях, наприклад, у такий спосіб:
Time sunset, // об'єкт типу Time
arrayOfTimes [5], // масив об'єктів типу Time
*pointerToTime, // вказівник на об’єкт типу Time
&dinnerTime = sunset; // посилання на об'єкт типу Time
Ім'я класу стає новим специфікатором типу. Може існувати безліч об'єктів класу як і безліч змінних типу, наприклад, такого, як int. Програміст по мірі необхідності може створювати нові типи класів. Це одна з багатьох причин, з яких C++ є розширюваною мовою.
Програма на мал.2 використовує клас Time. Ця програма створює єдиний об'єкт класу Time, названий t. Коли об'єкт створюється, автоматично викликається конструктор Time, що явно привласнює нульові початкові значення всім даним-елементам закритої частини private. Потім друкується час у військовому й стандартному форматах, щоб підтвердити, що елементи одержали правильні початкові значення. Після цього за допомогою функцій-елементів setTime встановлюється час і воно знову друкується в обох форматах. Потім функція-елемент setTime намагається дати даним-елементам неправильні значення й час знову друкується в обох форматах.
Знову відзначимо, що дані-елементи hour, minute і second об’явлені специфікатором доступу до елементів private. Ці закриті дані-елементи класу звичайно недоступні поза класом. Глибокий зміст такого підходу полягає в тому, що реальне становище даних усередині класу не стосується клієнтів класу. Наприклад, було б цілком можливо змінити внутрішню структуру даних і представляти, наприклад, час усередині класу як число секунд після опівночі. Клієнти могли б використати ті ж самі відкриті функції-елементи й одержувати ті ж самі результати, навіть не усвідомлюючи про зроблені зміни. У цьому сенсі, говорять, що реалізація класу схована від клієнтів. Таке приховання інформації сприяє модифікаційності програм і спрощує сприйняття класу клієнтами.
// FIG 3. CPP // Клас Time.
#include <iostream. h>
// Визначення абстрактного типу даних (АТД) Time
class Time{
public:
Time{); // конструктор
void setTime (int, int, int); // установка годин, хвилин
// та секунд
void printMilitary (); // часу у військовому форматі
void printStandard (); // друк часу
// у стандартному форматі
private:
int hour; // 0-23
int minute; // 0-59
int second; // 0-59
// Конструктор Time привласнює нульові початкові значення // кожному елементу даних. Забезпечує погоджене
// початковий стан всіх об'єктів
Time Time:: Time () { hour = minute = second =0; }
// Завдання нового значення Time у вигляді воєнного часу. // Перевірка правильності значень даних.
// Обнуління неправельних значень,
void Time:: setTime (int h, int m, int s) {
hour = (h>=0&&h<24)? h: 0;
minute = (m >= 0 && m < 60)? m: 0;
second ~ (s > - 0 && s < 60)? s: Q-; }
// Друк часу у військовому форматі
void Time:: printMilitary ()
{
cout " {hour < 10?"0": "")" hour" ": "
" (minute < 10?"0": "")" minute " ": "
" (second < 10?"0": "")" second; }
// Друк часу в стандартному форматі void Time:: printStandard ()
{
cout " ( (hour == 0 || hour == 12)? 12: hour% 12)
"": " " (minute < 10?"0": "")" minute
"": " " (second < 10?"0": "")" second
" (hour < 12?" AM": " PM");
}
![]() // Формування перевірки простого класу Time
// Формування перевірки простого класу Time
main ()
{
Time t; // визначення екземпляра об'єкта t класу Time
cout " "Початкове значення воєнного часу дорівнює "; t. printMilitary (); cout << endl
<< "Початкове значення стандартного часу дорівнює "; t. printStandard ();
t. setTime (13, 27,6):
cout " endl " endl << "Воєнний час після setTime дорівнює "; t. printMilitary ();
cout << endl << "Стандартний час після setTime дорівнює"; t. printStandard ();
t. setTime (99, 99, 99); // спроба встановити неправильні значення cout << endl << endl
<< "Після спроби неправильної установки: "
<< endl " "Воєнний час: "; t. printMilitary ();
cout << endl " "Стандартний час: "; t. printStandard (); cout << endl; return 0; }
Мал.2. Використання абстрактного типу даних Time як класу
Початкове значення воєнного часу дорівнює 00: 00: 00 Початкове значення стандартного часу дорівнює 12: 00: 00 AM
Воєнний час після setTime дорівнює 13: 27: 06
Після спроби неправильної установки: Воєнний час: 00; 00: 00 Стандартний час: 12: 00: 00 AM
У нашій програмі конструктор Time просто встановлює початкові значення, рівні 0, даним-елементам, (тобто задає воєнний час, еквівалентний 12AM). Це гарантує, що об'єкт при його створенні перебуває у відомому стані. Неправильні значення не можуть зберігатися в даних-елементах об'єкта типу Time, оскільки конструктор автоматично викликається при створенні об'єкта типу Time, а всі наступні спроби змінити дані-елементи ретельно розглядаються функцією setTime.
Відзначимо, що дані-елементи класу не можуть одержувати початкові значення в тілі класу, де вони оголошуються. Ці дані-елементи повинні одержувати початкові значення за допомогою конструктора класу або їм можна присвоїти значення через функції.
Функція з тим же ім'ям, що й клас, але з символом-тильда (~) перед нею, називається деструктором цього класу (наш приклад не включає деструктор). Деструктор робить "завершальні службові дії над кожним об'єктом класу перед тим, як пам'ять, відведена під цей об'єкт, буде повторно використана системою.
Помітимо, що функції, якими клас постачає зовнішній світ, визначаються міткою public. Відкриті функції реалізують всі можливості класу, необхідні для його клієнтів. Відкриті функції класу називають інтерфейсом класу або відкритим інтерфейсом.
Об’ява класу містить об’яви даних-елементів і функцій-елементів класу. Об’ява функцій-елементів є прототипами функцій. Функції-елементи можуть бути описані всередині класу, але гарний стиль програмування полягає в описі функцій поза визначенням класу.
Відзначимо використання бінарної операції дозволу області дії (::) у кожному визначенні функції-елемента, що випливає за визначенням класу на мал.3. Після того, як клас визначений і його функції-елементи Об’явлені, ці функції-елементи повинні бути описані. Кожна функція-елемент може бути описана прямо в тілі класу (замість включення прототипу функції класу) або після тіла класу. Коли функція-елемент описується після відповідного визначення класу, ім'я функції випереджається ім'ям класу та бінарною операцією дозволу області дії (::). Оскільки різні класи можуть мати елементи з однаковими іменами, операція дозволу області дії "прив'язує" ім'я елемента до імені класу, щоб однозначно ідентифікувати функції-елементи даного класу.
Незважаючи на те, що функція-елемент, об’явлена у визначенні класу, може бути описана поза цим визначенням, ця функція-елемент однаково має областю дії клас, тобто її ім'я відомо тільки іншим елементам класу поки до неї звертаються за допомогою об'єкта класу, посилання на об'єкт класу або покажчика на об'єкт класу. Про області дії класу ми більш докладно ще поговоримо пізніше.
Якщо функція-елемент описана у визначенні класу, вона автоматично вбудовується inline. Функція-елемент, описана поза визначенням класу, може бути inline за допомогою явного використання ключового слова inline. Нагадаємо, що компілятор резервує за собою право не вбудовувати ніяких функцій.
Цікаво, що функції-елементи printMilitary і printStandard не одержують ніяких аргументів. Це відбувається тому, що функції-елементи неявно знають, що вони друкують дані-елементи певного об'єкта типу Time, для якого вони активізовані. Це робить виклики функцій-елементів більш короткими, ніж відповідні виклики функцій у процедурному програмуванні. Це зменшує також ймовірність передачі неправильних аргументів, неправильних типів аргументів або неправильної кількості аргументів.
Класи спрощують програмування, тому що клієнт (або користувач об'єкта класу) має справу тільки з операціями, інкапсульованими або вбудованими в об'єкт. Такі операції звичайно проектуються орієнтовними саме на клієнта, а не на зручну реалізацію. Інтерфейси міняються, але не так часто, як реалізації. При зміні реалізації відповідно повинні змінюватися орієнтовані на реалізацію коди. А шляхом приховання реалізації ми виключаємо можливість для інших частин програми виявитися залежними від особливостей реалізації класу.
Часто класи не створюються "на порожнім місці". Звичайно вони є похідними від інших класів, що забезпечують нові класи необхідними їм операціями. Або класи можуть включати об'єкти інших класів як елементи. Таке повторне використання програмного забезпечення значно збільшує продуктивність програміста. Створення нових класів на основі вже існуючих класів називається успадкуванням. Включення класів як елементів інших класів називається композицією.
1.6 Область дії клас і доступ до елементів класуДані-елементи класу (змінні, об’явлені у визначенні класу) і функції-елементи (функції, об’явлені у визначенні класу) мають областю дії клас. Функції, що не є елементами класу, мають областю дії файл.
При області дії клас елементи класу безпосередньо доступні всім функціям-елементам цього класу й на них можна посилатися просто по імені. Поза областю дії клас до елементів класу можна звертатися або через ім'я об'єкта, або посиланням на об'єкт, або за допомогою вказівника на об'єкт.
Функції-елементи класу можна перевантажувати, але тільки за допомогою інших функцій-елементів класу. Для перевантаження функції-елемента просто забезпечте у визначенні класу прототип для кожної версії перевантаженої функції й позначить кожну версію функції окремим описом.
Але, не можна перевантажити функцію-елемент класу за допомогою функції не з області дії цього класу.
Функції-елементи мають всередині класу область дії функцію: змінні, об’явлені у функції-елементі, відомі тільки цій функції. Якщо функція-елемент об’являє змінну з тим же ім'ям, що й змінна в області дії клас, остання робиться невидимої в області дії функції. Така схована змінна може бути доступна за допомогою операції дозволу області. Невидимі глобальні змінні можуть бути доступні за допомогою унарної операції дозволу області дії.
Операції, для доступу до елементів класу, аналогічні операціям, для доступу до елементів структури. Операція вибору елемента крапка () комбінується для доступу до елементів об'єкта з ім'ям об'єкта або з посиланням на об'єкт. Операція вибору елемента стрілка (->) комбінується для доступу до елементів об'єкта з вказівником на об'єкт.
Програма на мал.3 використає простий клас, названий Count, з відкритим елементом даних х типу int і відкритої функцією-елементом print, щоб проілюструвати доступ до елементів класу за допомогою операції вибору елемента. Програма створює три екземпляри змінних типу Count - counter, counterRef (посилання на об'єкт типу Count) і counterPtr (покажчик на об'єкт типу Count). Змінна counterRef об’явлена, щоб![]() посилатися на counter, змінна counterPtr об’явлена, щоб указувати на counter. Важливо відзначити, що тут елемент даних х зроблений відкритим просто для того, щоб продемонструвати способи доступу до відкритих елементів. Як ми вже встановили, дані звичайно робляться закритими (private).
посилатися на counter, змінна counterPtr об’явлена, щоб указувати на counter. Важливо відзначити, що тут елемент даних х зроблений відкритим просто для того, щоб продемонструвати способи доступу до відкритих елементів. Як ми вже встановили, дані звичайно робляться закритими (private).
// FIG6_4. CPP
// Демонстрація операцій доступу до елементів класу. і - >
#include <iostream. h>
// Простий клас Count class Count { public:
int x;
void print () { cout << x " endl; } };
main ()
{
Count counter, // створюється об'єкт counter
*counterPtr = &counter, // покажчик на counter &counterRef = counter; // посиланя на counter
cout " "Присвоювання х значення 7 і друк по імені об'єкта: ";
counter. х =7; // присвоювання 7 елементу даних х
counter. print (); // виклик функції-елемента для друку
cout << "Присвоювання х значення 8 і друк по посиланню: ";
counterRef. x = 8; // присвоювання 8 елементу даних х
counterRef. print (); // виклик функції-елемента для друку
cout << "Присвоювання х значення 10 і друк по покажчику: "; counterPtr->x = 10; // присвоювання 10 елементу даних х counterPtr->print (); // виклик функції-елемента для друку
return 0;
}
Мал.3. Доступ до даних-елементів об'єкта й функціям-елементам за допомогою імені об'єкта, посилання й вказівника на об'єкт
Присвоювання х значення 7 і друк по імені об'єкта: 7
Присвоювання х значення 8 і друк по посиланню: 8
Присвоювання х значення 10 і друк по покажчику: 10
1.7 Конструктор класуСеред інших функцій-членів конструктор виділяється тим, що його ім'я збігається з ім'ям класу. Для оголошення конструктора за замовчуванням ми пишемо:
class Account {
public:
// конструктор за замовчуванням...
Account ();
// ...
private:
char *_name;
unsigned int _acct_nmbr;
double _balance;
};
Єдине синтаксичне обмеження, що накладає на конструктор, полягає в тому, що він не повинен мати тип значення, що повертає, навіть void.
Кількість конструкторів в одного класу може бути будь-яким, аби тільки всі вони мали різні списки формальних параметрів.
Звідки ми знаємо, скільки і які конструктори визначити? Як мінімум, необхідно присвоїти початкове значення кожному члену, що це потребує. Наприклад, номер рахунку або задається явно, або генерується автоматично таким чином, щоб гарантувати його унікальність. Припустимо, що він буде створюватися автоматично. Тоді ми повинні дозволити ініціализувати два члени, що залишилися _name і _balance:
Account (const char *name, double open_balance);
Об'єкт класу Account, ініціалізуємий конструктором, можна об’явити в такий спосіб:
Account newAcct ("Mikey Matz", 0);
Якщо ж є багато рахунків, для яких початковий баланс дорівнює 0, то корисно мати конструктор, що задає тільки ім'я власника й автоматично ініцілізує _balance нулем. Один зі способів зробити це - надати конструктор виду:
Account (const char *name);
Інший спосіб - включити в конструктор із двома параметрами значення за замовчуванням, рівне нулю:
Account (const char *name, double open_balance = 0.0);
Обоє конструктора володіють необхідної користувачеві функціональністю, тому обоє рішення прийнятні. Ми воліємо використати аргумент за замовчуванням, оскільки в такій ситуації загальне число конструкторів класу скорочується.
Потрібно чи підтримувати також завдання одного лише початкового балансу без вказівки імені клієнта? У цьому випадку специфікація класу явно забороняє це. Наш конструктор із двома параметрами, з яких другий має значення за замовчуванням, надає повний інтерфейс для задання початкових значень тих членів класу Account, які можуть бути ініціалізовані користувачем:
class Account {
public:
// конструктор за замовчуванням...
Account ();
// імена параметрів в оголошенні вказувати необов'язково
Account (const char*, double=0.0);
const char* name () { return name; }
// ...
private:
// ...
};
Нижче наведені два приклади правильного визначення об'єкта класу Account, де конструкторові передається один або два аргументи:
int main ()
{
// правильно: в обох випадках викликається конструктор
// с двома параметрами
Account acct ("Ethan Stern");
Account *pact = new Account ("Michael Lieberman", 5000);
if (strcmp (acct. name (), pact->name ()))
// ...
}
C++ вимагає, щоб конструктор застосовувався до певного об'єкта до його першого використання. Це означає, що як для acct, так і для об'єкта, на який указує pact, конструктор буде викликаний перед перевіркою в інструкції if.
Компілятор перебудовує нашу програму, вставляючи виклики конструкторів.
От як, цілком ймовірно, буде модифіковане визначення acct усередині main ():
// псевдокод на C++,
// іллюструючий внутрішню вставку конструктора
int main ()
{
Account acct;
acct. Account:: Account ("Ethan Stern", 0.0);
// ...
}
Звичайно, якщо конструктор визначений як вбудований, то він підставляється в точці виклику.
Обробка оператора new трохи складніше. Конструктор викликається тільки тоді, коли він успішно виділив пам'ять. Модифікація визначення pact у трохи спрощеному виді виглядає так:
// псевдокод на C++,
// іллюструючий внутрішню вставку конструктора при обробці new
int main ()
{
// ...
Account *pact;
try {
pact = _new (sizeof (Account));
pact->Acct. Account:: Account (
"Michael Liebarman", 5000.0);
}
catch (std:: bad_alloc) {
// оператор new закінчився невдачею:
// конструктор не викликається
}
// ...
}
Існує три в загальному випадку еквівалентні форми завдання аргументів конструктора:
// загалом ці конструктори еквівалентні
Account acct1 ("Anna Press");
Account acct2 = Account ("Anna Press");
Account acct3 = "Anna Press";
Форма acct3 може використовуватися тільки при завданні єдиного аргументу. Якщо аргументів два або більше, рекомендовано користуватися формою acct1, хоча припустимо й acct2.
// рекомендує форма, що, виклику конструктора
Account acct1 ("Anna Press");
Визначати об'єкт класу, не вказуючи списку фактичних аргументів, можна в тому випадку, якщо в ньому або об’явлений конструктор за замовчуванням, або взагалі немає об’яв конструкторів. Якщо в класі об’явлений хоча б один конструктор, то не дозволяється визначати об'єкт класу, не викликаючи жодного з них. Зокрема, якщо в класі визначений конструктор, що приймає один або більше параметрів, але не визначений конструктор за замовчуванням, то в кожному визначенні об'єкта такого класу повинні бути присутнім необхідні аргументи. Можна заперечити, що не має змісту визначати конструктор за замовчуванням для класу Account, оскільки не буває рахунків без імені власника. У переглянутій версії класу Account такий конструктор виключений:
class Account {
public:
// імена параметрів в оголошенні вказувати необов'язково
Account (const char*, double=0.0);
const char* name () { return name; }
// ...
private:
// ...
};
Тепер при оголошенні кожного об'єкта Account у конструкторі обов'язково треба вказати як мінімум аргумент типу C-рядка, але це швидше за все безглуздо. Чому? Контейнерні класи (наприклад, vector) вимагають, щоб для класу елементів, що поміщають у них, був або заданий конструктор за замовчуванням, або взагалі ніяких конструкторів. Аналогічна ситуація має місце при виділенні динамічного масиву об'єктів класу. Так, що інструкція викликала б помилку компіляції для нової версії Account:
// помилка: потрібен конструктор за замовчуванням для класу
Account *pact = new Account [new_client_cnt];
На практиці часто потрібно задавати конструктор за замовчуванням, якщо є які-небудь інші конструктори.
А якщо для класу немає розумних значень за замовчуванням? Наприклад, клас Account вимагає задавати для будь-якого об'єкта прізвище власника рахунку.
У такому випадку найкраще встановити стан об'єкта так, щоб було видно, що він ще не ініціалізований коректними значеннями:
// конструктор за замовчуванням для класу Account
inline Account:: Account () {
_name = 0;
_balance = 0.0;
_acct_nmbr = 0;
}
Однак у функції-члени класу Account прийдеться включити перевірку цілісності об'єкта перед його використанням.
Існує й альтернативний синтаксис: список ініціалізації членів, у якому через кому вказуються імена й початкові значення. Наприклад, конструктор за замовчуванням можна переписати в такий спосіб:
// конструктор за замовчуванням класу Account з використанням
// списку ініціалізації членів
inline Account::
Account ()
: _name (0),
_balance (0.0), _acct_nmbr (0)
{}
Такий список допустимо тільки у визначенні, але не в оголошенні конструктора. Він міститься між списком параметрів і тілом конструктора й відділяється двокрапкою. От як виглядає наш конструктор із двома параметрами при частковому використанні списку ініціалізації членів:
inline Account::
Account (const char* name, double opening_bal)
: _balance (opening_bal)
{
_name = new char [strlen (name) +1];
strcpy (_name, name);
_acct_nmbr = get_unique_acct_nmbr ();
}
Конструктор не можна об’являти із ключовими словами const або volatile, тому наведені записи невірні:
class Account {
public:
Account () const; // помилка
Account () volatile; // помилка
// ...
};
Це не означає, що об'єкти класу з такими специфікаторами заборонено ініціалізувати конструктором. Просто до об'єкта застосовується підходящий конструктор, причому без обліку специфікаторів в оголошенні об'єкта. Константність об'єкта класу встановлюється після того, як робота з його ініціалізації завершена, і пропадає в момент виклику деструктора. Таким чином, об'єкт класу зі специфікатором const уважається константним з моменту завершення роботи конструктора до моменту запуску деструктора. Те ж саме ставиться й до специфікатора volatile.
Розглянемо наступний фрагмент програми:
// у якімсь заголовному файлі
extern void print (const Account &acct);
// ...
int main ()
{
// перетворить рядок "oops" в об'єкт класу Account
// за допомогою конструктора Account:: Account ("oops", 0.0)
print ("oops");
// ...
}
За замовчуванням конструктор з одним параметром (або з декількома - за умови, що всі параметри, крім першого, мають значення за замовчуванням) відіграє роль оператора перетворення. У цьому фрагменті програми конструктор Account неявно застосовується компілятором для трансформації літерального рядка в об'єкт класу Account при виклику print (), хоча в даній ситуації таке перетворення не потрібно.
Ненавмисні неявні перетворення класів, наприклад трансформація "oops" в об'єкт класу Account, виявилися джерелом помилок, що виявляють важко. Тому в стандарт C++ було додано ключове слово explicit, що говорить компіляторові, що такі перетворення не потрібні:
class Account {
public:
explicit Account (const char*, double=0.0);
};
Даний модифікатор застосуємо тільки до конструктора.
1.8 Конструктор копіювання
Ініціалізація об'єкта іншим об'єктом того ж класу називається почленною ініціалізацією за замовчуванням. Копіювання одного об'єкта в іншій виконується шляхом послідовного копіювання кожного нестатичного члена. Проектувальник класу може змінити цей процес, надавши спеціальний конструктор копіювання. Якщо він визначений, то викликається щоразу, коли один об'єкт ініціалізується іншим об'єктом того ж класу.
Часто почленна ініціалізація не забезпечує коректну дію класу. Тому ми явно визначаємо конструктор копіювання. У нашому класі Account це необхідно, інакше два об'єкти будуть мати однакові номери рахунків, що заборонено специфікацією класу.
Конструктор копіювання приймає як формальний параметр посилання на об'єкт класу (рекомендовано зі специфікатором const). Його реалізація:
inline Account::
Account (const Account &rhs)
: _balance (rhs. _balance)
{
_name = new char [strlen (rhs. _name) + 1];
strcpy (_name, rhs. _name);
// копіювати rhs. _acct_nmbr не можна
_acct_nmbr = get_unique_acct_nmbr ();
}
Коли ми пишемо:
Account acct2 (acct1);
компілятор визначає, чи оголошений явний конструктор копіювання для класу Account. Якщо він оголошений і доступний, то він і викликається; а якщо недоступний, то визначення acct2 вважається помилкою. У випадку, що коли конструктор копіювання не об’явлений, виконується почленна ініціалізація за замовчуванням. Якщо згодом об’явлення конструктор копіювання буде додане або вилучене, ніяких змін у програми користувачів вносити не прийдеться. Однак перекомпілювати їх все-таки необхідно.
1.9 Деструктор класуОдна із цілей, що ставляться перед конструктором, - забезпечити автоматичне виділення ресурсу. Ми вже бачили в прикладі із класом Account конструктор, де за допомогою оператора new виділяється пам'ять для масиву символів і привласнюється унікальний номер рахунку. Можна також представити ситуацію, коли потрібно одержати монопольний доступ до поділюваної пам'яті або до критичної секції потоку. Для цього необхідна симетрична операція, що забезпечує автоматичне звільнення пам'яті або повернення ресурсу після завершення часу життя об'єкта, - деструктор. Деструктор - це спеціальна обумовлена користувачем функція-член, що автоматично викликається, коли об'єкт виходить із області видимості або коли до покажчика на об'єкт застосовується операція delete. Ім'я цієї функції створено з імені класу з попереднім символом “тильда" (~). Деструктор не повертає значення й не приймає ніяких параметрів, а отже, не може бути перевантажений.
Хоча дозволяється визначати кілька таких функцій-членів, лише одна з них буде застосовуватися до всіх об'єктів класу. От, наприклад, деструктор для нашого класу Account:
class Account {
public:
Account ();
explicit Account (const char*, double=0.0);
Account (const Account&);
~Account ();
// ...
private:
char *_name;
unsigned int _acct_nmbr;
double _balance;
};
inline
Account:: ~Account ()
{
delete [] _name;
return_acct_number (_acct_nnmbr);
}
Зверніть увагу, що в нашому деструкторі не скидаються значення членів:
inline Account:: ~Account ()
{
// необхідно
delete [] _name;
return_acct_number (_acct_nnmbr);
// необов'язково
_name = 0;
_balance = 0.0;
_acct_nmbr = 0;
}
Робити це необов'язково, оскільки відведена під члени об'єкта пам'ять однаково буде звільнена. Розглянемо наступний клас:
class Point3d {
public:
// ...
private:
float x, y, z;
};
Конструктор тут необхідний для ініціалізації членів, що представляють координати точки. Чи потрібний деструктор? Немає. Для об'єкта класу Point3d не потрібно звільняти ресурси: пам'ять виділяється й звільняється компілятором автоматично на початку й наприкінці його життя.
В загальному випадку, якщо члени класу мають прості значення, скажімо, координати точки, то деструктор не потрібний. Не для кожного класу необхідний деструктор, навіть якщо в нього є один або більше конструкторів. Основною метою деструктора є звільнення ресурсів, виділених або в конструкторі, або під час життя об'єкта, наприклад звільнення пам'яті, виділеної оператором new.
Але функції деструктора не обмежені тільки звільненням ресурсів. Він може реалізовувати будь-яку операцію, що за задумом проектувальника класу повинна бути виконана відразу по закінченні використання об'єкта. Так, широко розповсюдженим прийомом для виміру продуктивності програми є визначення класу Timer, у конструкторі якого запускається та або інша форма програмного таймера. Деструктор зупиняє таймер і виводить результати вимірів. Об'єкт даного класу можна умовно визначати в критичних ділянках програми, які ми хочемо профілювати, у такий спосіб:
{
// початок критичної ділянки програми
#ifdef PROFILE
Timer t;
#endif
// критична ділянка
// t знищується автоматично
// відображається витрачений час...
}
Щоб переконатися в тім, що ми розуміємо поводження деструктора (та й конструктора теж), розберемо наступний приклад:
(1) #include "Account. h"
(2) Account global ("James Joyce");
(3) int main ()
(4) {
(5) Account local ("Anna Livia Plurabelle", 10000);
(6) Account &loc_ref = global;
(7) Account *pact = 0;
(8)
(9) {
(10) Account local_too ("Stephen Hero");
(11) pact = new Account ("Stephen Dedalus");
(12) }
(13)
(14) delete pact;
(15) }
Скільки тут викликається конструкторів? Чотири: один для глобального об'єкта global у рядку (2); по одному для кожного з локальних об'єктів local і local_too у рядках (5) і (10) відповідно, і один для об'єкта, розподіленого в купі, у рядку (11). Ні об’явлення посилання loc_ref на об'єкт у рядку (6), ні об’явлення вказівника pact у рядку (7) не приводять до виклику конструктора. Посилання - це псевдонім для вже сконструйованого об'єкта, у цьому випадку для global. Вказівника також лише адресує об'єкт, створений раніше (у цьому випадку розподілений у купі, рядок (11)), або не адресує ніякого об'єкта (рядок (7)).
Аналогічно викликаються чотири деструктори: для глобального об'єкта global, об’явленого в рядку (2), для двох локальних об'єктів і для об'єкта в купі при виклику delete у рядку (14). Однак у програмі немає інструкції, з якої можна зв'язати виклик деструктора. Компілятор просто вставляє ці виклики за останнім використанням об'єкта, але перед закриттям відповідної області видимості.
Конструктори й деструктори глобальних об'єктів викликаються на стадіях ініціалізації й завершення виконання програми. Хоча такі об'єкти нормально поводяться при використанні в тім файлі, де вони визначені, але їхнє застосування в ситуації, коли виробляються посилання через границі файлів, стає в C++ серйозною проблемою.
Деструктор не викликається, коли з області видимості виходить посилання або вказівник на об'єкт (сам об'єкт при цьому залишається).
С++ за допомогою внутрішніх механізмів перешкоджає застосуванню оператора delete до вказівника, що не адресує ніякого об'єкта, так що відповідні перевірки коду необов'язкові:
// необов'язково: неявно виконується компілятором
if (pact! = 0) delete pact;
Щораз, коли усередині функції цей оператор застосовується до окремого об'єкта, розміщеному в купі, краще використати об'єкт класу auto_ptr, а не звичайний вказівник. Це особливо важливо тому, що пропущений виклик delete (скажемо, у випадку, коли збуджується виключення) веде не тільки до витоку пам'яті, але й до пропуску виклику деструктора. Нижче приводиться приклад програми, переписаної з використанням auto_ptr (вона злегка модифікована, тому що об'єкт класу auto_ptr може бути явно із для адресації іншого об'єкта тільки присвоюванням його іншому auto_ptr):
#include <memory>
#include "Account. h"
Account global ("James Joyce");
int main ()
{
Account local ("Anna Livia Plurabelle", 10000);
Account &loc_ref = global;
auto_ptr<Account> pact (new Account ("Stephen Dedalus"));
{
Account local_too ("Stephen Hero");
}
// об'єкт auto_ptr знищується тут
}
1.10 Явний виклик деструктора
Іноді викликати деструктор для деякого об'єкта доводиться явно. Особливо часто така необхідність виникає у зв'язку з оператором new. Розглянемо приклад.
Коли ми пишемо:
char *arena = new char [sizeof Image];
то з купи виділяється пам'ять, розмір якої дорівнює розміру об'єкта типу Image, вона не ініціалізована й заповнена випадковими бітами.
Якщо ж написати:
Image *ptr = new (arena) Image ("Quasimodo");
то ніякої нової пам'яті не виділяється. Замість цього змінної ptr привласнюється адреса, асоційованою зі змінною arena. Тепер пам'ять, на яку вказує ptr, інтерпретується як займана об'єктом класу Image, і конструктор застосовується до вже існуючої області. Таким чином, оператор розміщення new () дозволяє сконструювати об'єкт у раніше виділеній області пам'яті.
Закінчивши працювати із зображенням Quasimodo, ми можемо зробити якісь операції із зображенням Esmerelda, розміщеним по тій же адресі arena у пам'яті:
Image *ptr = new (arena) Image ("Esmerelda");
Однак зображення Quasimodo при цьому буде затерто, а ми його модифікували й хотіли б записати на диск. Звичайне збереження виконується в деструкторі класу Image, але якщо ми застосуємо оператор delete:
// погано: не тільки викликає деструктор, але й звільняє пам'ять
delete ptr;
то, крім виклику деструктора, ще й повернемо в купу пам'ять, чого робити не варто було б. Замість цього можна явно викликати деструктор класу Image:
ptr->~Image ();
зберігши відведену під зображення пам'ять для наступного виклику оператора розміщення new.
Відзначимо, що, хоча ptr і arena адресують ту саму область пам'яті в купі, застосування оператора delete до arena
// деструктор не викликається
delete arena;
не приводить до виклику деструктора класу Image, тому що arena має тип char*, а компілятор викликає деструктор тільки тоді, коли операндом в delete є вказівник на об'єкт класу, що має деструктор.
1.11 Небезпека збільшення розміру програми
Вбудований деструктор може стати причиною непередбаченого збільшення розміру програми, оскільки він вставляється в кожній точці виходу всередині функції для кожного активного локального об'єкта. Наприклад, у наступному фрагменті
Account acct ("Tina Lee");
int swt;
// ...
switch (swt) {
case 0:
return;
case 1:
// щось зробити
return;
case 2:
// зробити щось інше
return;
// і так далі
}
компілятор підставить деструктор перед кожною інструкцією return. Деструктор класу Account невеликий, і витрати часу й пам'яті на його підстановку теж малі. У противному випадку прийдеться або об’явити деструктор невбудованим, або реорганізувати програму. У прикладі вище інструкцію return у кожній мітці case можна замінити інструкцією break для того, щоб у функції була єдина точка виходу:
// переписано для забезпечення єдиної точка виходу
switch (swt) {
case 0:
break;
case 1:
// щось зробити
break;
case 2:
// зробити щось інше
break;
// і так далі
}
// єдина точка виходу
return;
1.12 Константні об'єкти й функції-елементи
Ми ще раз особливо відзначаємо принцип найменших привілеїв як один з найбільш фундаментальних принципів створення гарного програмного забезпечення. Розглянемо один зі способів застосування цього принципу до об'єктів.
Деякі об'єкти повинні допускати зміни, інші - ні. Програміст може використовувати ключове слово const для вказівки на те, що об'єкт незмінний - є константним і що будь-яка спроба змінити об'єкт є помилкою. Наприклад,
const Time noon (12, 0, 0);
об’являє як константний об'єкт noon класу Time і присвоює йому початкове значення 12 годин пополудні.
Компілятори C++ сприймають оголошення const настільки неухильно, що в підсумку не допускають ніяких викликів функцій-елементів константних об'єктів (деякі компілятори дають у цих випадках тільки попередження). Це жорстоко, оскільки клієнти об'єктів можливо захочуть використати різні функції-елементи читання "get", а вони, звичайно, не змінюють об'єкт. Щоб обійти це, програміст може оголосити константні функції-елементи; тільки вони можуть оперувати константними об'єктами. Звичайно, константні функції-елементи не можуть змінювати об'єкт - це не дозволить компілятор.
Константна функція вказується як const і в об’яві, і в описі за допомогою ключового слова const після списку параметрів функції, але перед лівою фігурною дужкою, що починає тіло функції. Наприклад, у наведеному нижче прикладі об’являється як константна функція-елемент деякого класу А
int A:: getValue () const {return privateDateMember};
яка просто повертає значення одного з даних-елементів об'єкта. Якщо константна функція-елемент описується поза об’явою класу, то як об’ява функції-елемента, так і її опис повинні включати const.
Тут виникає цікава проблема для конструкторів і деструкторів, які звичайно повинні змінювати об'єкт. Для конструкторів і деструкторів константних об'єктів оголошення const не потрібно. Конструктор повинен мати можливість змінювати об'єкт із метою присвоювання йому відповідних початкових значень. Деструктор повинен мати можливість виконувати підготовку завершення робіт перед знищенням об'єкта.
Програма на мал.4 створює константний об'єкт класу Time і намагається змінити об'єкт не константними функціями-елементами setHour, setMinute і setSecond. Як результат показані згенеровані компілятором Borland C++ попередження.
// TIME5. H
// Оголошення класу Time.
// Функції-елементи описані в TIMES. CPP
#ifndef TIME5_H idefine TIME5_H
class Time { public:
Time (int = 0, int = 0, int = 0); // конструктор за замовчуванням
// функції запису set
void setTime (int, int, int); // установкачасу
void setHour (int); // установкагодин
void setMinute (int); // установкахвилин
void setSecond (int); // установкасекунд
// функції читання get (звичайно об’являється const)
int getHour () const; // повертає значення годин
int getMinute () const; // повертає значення хвилин
int getSecondf) const; // повертає значення секунд
// функції друк (звичайно об’являється const)
void printMilitary () const; // друк військового часу void printStandard () const; // друк стандартного часу
private:
int hour; // 0-23
int minute; // 0-59
int second; // 0-59
};
#endif
// TIME5. CPP
// Опис функцій-елементів класу Time.
finclude <iostream. h>
iinclude "time5. h"
// Функція конструктор для ініціалізації закритих даних. // За замовчуванням значення рівні 0 (дивися опис класу). Time:: Time (int hr, int min, int sec) { setTime (hr, min, sec); }
// Встановка значень години, хвилин і секунд, void Time:: setTime (int h, int m, int s) {
hour = (h >= 0 && h < 24)? h: 0;
minute = (m >= 0 && m < 60)? m: 0;
second = (s >= 0 && s < 60)? s: 0; }
// Установка значення годин
void Time:: setHour (int h) { hour = (h >= 0 && h < 24)? h: 0; }
// Установка значення хвилин void Time:: setMinute (int m)
{ minute = (m >= 0 && m < 60)? m: 0; }
// Установка значення секунд void Time:: setSecond (int s)
{ second = (s >= 0 && s < 60)? s: 0; }
// Читання значення годин
int Time:: getHour () const { return hour; }
// Читання значення хвилин
int Time:: getMinute () const { return minute; }
// Читання значення секунд
int Time:: getSecond () const { return second; }
// Відображення часу у військовому форматі: HH: MM: SS
void Time:: printMilitary () const
{
cout " (hour < 10?"0": "")" hour " ": "
" (minute < 10?"0": "")" minute" ": "
" (second < 10?"0": "")" second; }
// Відображення часу в стандартному форматі: HH: MM: SS AM // (або РМ)
void Time:: printStandard () const {
cout " ( (hour == 12)? 12: hour% 12)" ": "
" (minute < 10?"0": "")" minute " ": " " (second < 10?"0": "")" second " (hour< 12?"AM": "PM"); }
// FIG7_1. CPP
// Спроба одержати доступ до константного об'єкта
// з не-константними функціями-елементами.
#include <iostream. h>
#include "time5. h"
main () {
const Time t (19, 33, 52); // константний об'єкт
t. setHour (12); // ПОМИЛКА: не-константна функція елемент t. setMinute (20); // ПОМИЛКА: не-константна функція елемент t. setSecond (39); // ПОМИЛКА: не-константна функція елемент
return 0; }
Compiling FIG7_1. CPP:
Warning FIG7_1. CPP: Non-const function
Time:: setHour (int) called for const object Warning FXG7 l. CPP: Non-const function
Time:: setMinute (int) callers for const object Warning FIG7 1. CPP: Non-const function
Time:: setSecond (int) called for const object
Мал.4. Використання класу Time з константними об'єктами й константними функціями-елементами
Зауваження: Константна функція-елемент може бути перевантажена неконстантним варіантом. Вибір того, яка з перевантажених функцій-елементів буде використатися, виконується компілятором автоматично залежно від того, був об’явлений об'єкт як const чи ні.
Константный об'єкт не може бути змінений за допомогою присвоювання, так що він повинен мати початкове значення. Якщо дані-елементи класу об’явлені як const, то треба використати ініціалізатор елементів, щоб забезпечити конструктор об'єкта цього класу початковими значенням даних-елементів. Мал.7 демонструє використання ініціалізатора елементів для завдання початкового значення константному елементу increment класу Increment. Конструктор для Increment змінюється в такий спосіб:
Increment:: Increment (int c, int i): increment (i) { count = c; }
Запис: increment (i) викликає завдання початкового значення елемента increment, рівного i. Якщо необхідно задати початкові значення відразу декільком елементам, просто включіть їх у список після двокрапки, розділяючи комами. Використовуючи ініціатори елементів, можна присвоїти початкові значення всім даним-елементам.
// Використання ініціалізатора елементів для
// ініціалізації даних константного вбудованого типу.
#include <iostream. h>
class Increment { public:
Increment (int з = 0, int i = 1);
void addlncrement () { count += increment; }
void print () const;
private:
int count;
const int increment; // константний елемент даних };
// Конструктор класу Increment Increment:: Increment (int c, int i)
: increment (i) // ініціали затор константного елемента
{ count = с; }
// друк даних
void Increment:: print () const
{
cout << "count = " << count
"", increment = " " increment << endl; }
main ()
{
Increment value (10,5);
cout << "Перед збільшенням: "; value. print ();
for (int j = 1; j <= 3;) }
value. addlncrement ();
cout << "Після збільшення " << j "": "; value. print ();
}
return 0; }
Перед збільшенням: count = 10, increment = 5
Після збільшення 1: count = 15, increment = 5
Після збільшення 2: count = 20, increment = 5
Після збільшення 3: count = 25, increment = 5
Мал.7. Використання ініціалізаторів елементів для ініціалізації даних константного типу убудованого типу
1.13 ДрузіНехай визначені два класи: vector (вектор) і matrix (матриця). Кожний з них приховує своє подання даних, але дає повний набір операцій для роботи з об'єктами його типу. Допустимо, треба визначити функцію, що множить матрицю на вектор. Для простоти припустимо, що вектор має чотири елементи з індексами від 0 до 3, а в матриці чотири вектори теж з індексами від 0 до 3. Доступ до елементів вектора забезпечується функцією elem (), і аналогічна функція є для матриці. Можна визначити глобальну функцію multiply (помножити) у такий спосіб:
vector multiply (const matrix& m, const vector& v);
{
vector r;
for (int i = 0; i<3; i++) { // r [i] = m [i] * v;
r. elem (i) = 0;
for (int j = 0; j<3; j++)
r. elem (i) +=m. elem (i,j) * v. elem (j);
}
return r;
}
Це цілком природнє рішення, але воно може виявитися дуже неефективним. При кожному виклику multiply () функція elem () буде викликатися 4* (1+4*3) раз. Якщо в elem () проводиться контроль границь масиву, то на такий контроль буде витрачено значно більше часу, ніж на виконання самої функції, і в результаті вона виявиться непридатної для користувачів. З іншого боку, якщо elem () є якийсь спеціальний варіант доступу без контролю, то тим самим ми засмічуємо інтерфейс із вектором і матрицею особливою функцією доступу, що потрібна тільки для обходу контролю.
Якщо можна було б зробити multiply членом обох класів vector і matrix, ми могли б обійтися без контролю індексу при звертанні до елемента матриці, але в той же час не вводити спеціальної функції elem (). Однак, функція не може бути членом двох класів. Треба мати в мові можливість надавати функції, що не є членом, право доступу до приватних членів класу. Функція - не член класу, але має доступ до його закритої частини, називається другом цього класу. Функція може стати другом класу, якщо в його описі вона описана як friend (друг). Наприклад:
class matrix;
class vector {
float v [4];
// ...
friend vector multiply (const matrix&, const vector&);
};
class matrix {
vector v [4];
// ...
friend vector multiply (const matrix&, const vector&);
};
Функція-друг не має ніяких особливостей, за винятком права доступу до закритої частини класу. Зокрема, у такій функції не можна використати вказівник this, якщо тільки вона дійсно не є членом класу. Опис friend є дійсним описом. Воно вводить ім'я функції в область видимості класу, у якому вона була описана, і при цьому відбуваються звичайні перевірки на наявність інших описів такого ж імені в цій області видимості. Опис friend може перебуває як у загальній, так і в приватній частинах класу, це не має значення.
Тепер можна написати функцію multiply, використовуючи елементи вектора й матриці безпосередньо:
vector multiply (const matrix& m, const vector& v)
{
vector r;
for (int i = 0; i<3; i++) { // r [i] = m [i] * v;
r. v [i] = 0;
for (int j = 0; j<3; j++)
r. v [i] +=m. v [i] [j] * v. v [j];
}
return r;
}
Відзначимо, що подібно функції-члену дружня функція явно описується в описі класу, з яким дружить. Тому вона є невід'ємною частиною інтерфейсу класу нарівні з функцією-членом.
Функція-член одного класу може бути другом іншого класу:
class x {
// ...
void f ();
};
class y {
// ...
friend void x:: f ();
};
Цілком можливо, що всі функції одного класу є друзями іншого класу. Для цього є коротка форма запису:
class x {
friend class y;
// ...
};
У результаті такого опису всі функції-члени y стають друзями класу x.
1.14 Ядро ООП: Успадкування та поліморфізм
Ця глава присвячена поняттю похідного класу. Похідні класи - це простий, гнучкий і ефективний засіб визначення класу. Нові можливості додаються до вже існуючого класу, не вимагаючи його перепрограмування або перетрансляції. За допомогою похідних класів можна організувати загальний інтерфейс із декількома різними класами так, що в інших частинах програми можна буде одноманітно працювати з об'єктами цих класів. Вводиться поняття віртуальної функції, що дозволяє використати об'єкти належним чином навіть у тих випадках, коли їхній тип на стадії трансляції невідомий. Основне призначення похідних класів - спростити програмістові завдання вираження спільності класів.
1.4.1 Похідні класи
Обговоримо, як написати програму обліку службовців деякої фірми. У ній може використатися, наприклад, така структура даних:
struct employee { // службовець
char* name; // ім'я
short age; // вік
short department; // відділ
int salary; // оклад
employee* next;
// ...
};
Поле next потрібно для зв'язування в список записів про службовців одного відділу (employee). Тепер спробуємо визначити структуру даних для керуючого (manager):
struct manager {
employee emp; // запис employee для керуючого
employee* group; // підлеглий колектив
short level;
// ...
};
Керуючий також є службовцем, тому запис employee зберігається в члені emp об'єкта manager. Для людини ця спільність очевидна, але для транслятора член emp нічим не відрізняється від інших членів класу. Вказівник на структуру manager (manager*) не є вказівником на employee (employee*), тому не можна вільно використати один замість іншого. Зокрема, без спеціальних дій не можна об'єкт manager включити до списку об'єктів типу employee. Доведеться або використати явне приведення типу manager*, або в список записів employee включити адресу члена emp. Обоє рішень некрасиві й можуть бути досить заплутаними. Правильне рішення полягає в тому, щоб тип manager був типом employee з деякою додатковою інформацією:
struct manager: employee {
employee* group;
short level;
// ...
};
Клас manager є похідним від employee, і, навпаки, employee є базовим класом для manager. Крім члена group у класі manager є члени класу employee (name, age і т.д.). Графічно відношення спадкування звичайно зображується у вигляді стрілки від похідних класів до базового:
employee
manager
Звичайно говорять, що похідний клас успадковує базовий клас, тому й відношення між ними називається успадкуванням. Іноді базовий клас називають суперкласом, а похідний - підлеглим класом. Але ці терміни можуть викликати здивування, оскільки об'єкт похідного класу містить об'єкт свого базового класу. Взагалі похідний клас більше свого базового в тому розумінні, що в ньому утримується більше даних і визначено більше функцій.
Маючи визначення employee і manager, можна створити список службовців, частина з яких є й керуючими:
void f ()
{
manager m1, m2;
employee e1, e2;
employee* elist;
elist = &m1; // помістити m1 в elist
m1. next = &e1; // помістити e1 в elist
e1. next = &m2; // помістити m2 в elist
m2. next = &e2; // помістити m2 в elist
e2. next = 0; // кінець списку
}
Оскільки керуючий є також службовцем, вказівник manager* можна використати як employee*. У той же час службовець не обов'язково є керуючим, і тому employee* не можна використати як manager*.
У загальному випадку, якщо клас derived має загальний базовий клас base, то вказівник на derived можна без явних перетворень типу привласнювати змінній, що має тип вказівника на base. Зворотне перетворення від вказівника на base до вказівника на derived може бути тільки явним:
void g ()
{
manager mm;
employee* pe = &mm; // нормально
employee ee;
manager* pm = ⅇ // помилка:
// не всякий службовець є керуючим
pm->level = 2; // катастрофа: при розміщенні ee
// пам'ять для члена 'level' не виділялася
pm = (manager*) pe; // нормально: насправді pe
// не настроєно на об'єкт mm типу manager
pm->level = 2; // відмінно: pm указує на об'єкт mm
// типу manager, а в ньому при розміщенні
// виділена пам'ять для члена 'level'
}
Іншими словами, якщо робота з об'єктом похідного класу йде через вказівник, то його можна розглядати як об'єкт базового класу. Зворотне невірно. Відзначимо, що у звичайній реалізації С++ не передбачається динамічного контролю над тим, щоб після перетворення типу, подібного тому, що використовувалося в присвоюванні pe в pm, отриманий у результаті вказівник дійсно був налаштований на об'єкт необхідного типу.
1.14.2 Функції-члени
Прості структури даних начебто employee і manager самі по собі не занадто цікаві, а часто й не дуже корисні. Тому додамо до них функції:
class employee {
char* name;
// ...
public:
employee* next; // перебуває в загальній частині, щоб
// можна було працювати зі списком
void print () const;
// ...
};
class manager: public employee {
// ...
public:
void print () const;
// ...
};
Треба відповісти на деякі питання. Яким чином функція-член похідного класу manager може використати члени базового класу employee? Які члени базового класу employee можуть використати функції-члени похідного класу manager? Які члени базового класу employee може використати функція, що не є членом об'єкта типу manager? Які відповіді на ці питання повинна давати реалізація мови, щоб вони максимально відповідали завданню програміста?
Розглянемо приклад:
void manager:: print () const
{
cout << " ім'я " << name << '\n';
}
Член похідного класу може використати ім'я із загальної частини свого базового класу нарівні з усіма іншими членами, тобто без вказівки імені об'єкта. Передбачається, що є об'єкт, на який настроєний this, тому коректним звертанням до name буде this->name. Однак, при трансляції функції manager:: print () буде зафіксована помилка: члену похідного класу не надане право доступу до приватних членів його базового класу, значить name недоступно в цій функції.
Можливо багатьом це здасться дивним, але давайте розглянемо альтернативне рішення: функція-член похідного класу має доступ до приватних членів свого базового класу. Тоді саме поняття частки (закритого) члена втрачає всякий зміст, оскільки для доступу до нього досить просто визначити похідний клас. Тепер уже буде недостатньо для з'ясування, хто використає приватні члени класу, переглянути всі функції-члени й друзів цього класу. Прийдеться переглянути всі вихідні файли програми, знайти похідні класи, потім досліджувати кожну функцію цих класів. Далі треба знову шукати похідні класи від уже знайдених і т.д. Це, принаймні, утомливо, а швидше за все нереально. Потрібно всюди, де це можливо, використати замість приватних членів захищені (protected).
Як правило, саме надійне рішення для похідного класу - використати тільки загальні члени свого базового класу:
void manager:: print () const
{
employee:: print (); // друк даних про службовців
// друк даних про керуючих
}
Відзначимо, що операція:: необхідна, оскільки функція print () перевизначена в класі manager. Таке повторне використання імен типово для С++. Необережний програміст написав би:
void manager:: print () const
{
print (); // печатка даних про службовців
// печатка даних про керуючих
}
У результаті він одержав би рекурсивну послідовність викликів manager:: print ().
1.14.3 Конструктори й деструкториДля деяких похідних класів потрібні конструктори. Якщо конструктор є в базовому класі, то саме він і повинен викликатися із вказівкою параметрів, якщо такі в нього є:
class employee {
// ...
public:
// ...
employee (char* n, int d);
};
class manager: public employee {
// ...
public:
// ...
manager (char* n, int i, int d);
};
Параметри для конструктора базового класу задаються у визначенні конструктора похідного класу. У цьому змісті базовий клас виступає як клас, що є членом похідного класу:
manager:: manager (char* n, int l, int d)
: employee (n,d), level (l), group (0)
{
}
Конструктор базового класу employee:: employee () може мати таке визначення:
employee:: employee (char* n, int d)
: name (n), department (d)
{
next = list;
list = this;
}
Тут list повинен бути описаний як статичний член employee.
Об'єкти класів створюються знизу вверх: спочатку базові, потім члени й, нарешті, самі похідні класи. Знищуються вони у зворотному порядку: спочатку самі похідні класи, потім члени, а потім базові. Члени й базові створюються в порядку опису їх у класі, а знищуються вони у зворотному порядку.
1.14.4 Ієрархія класів
Похідний клас сам у свою чергу може бути базовим класом:
class employee {/*... */ };
class manager: public employee {/*... */ };
class director: public manager {/*... */ };
Така безліч зв'язаних між собою класів звичайно називають ієрархією класів. Звичайно вона представляється деревом, але бувають ієрархії з більш загальною структурою у вигляді графа:
class temporary {/*... */ };
class secretary: public employee {/*... */ };
class tsec
: public temporary, public secretary { /*... */ };
class consultant
: public temporary, public manager { /*... */ };
Бачимо, що класи в С++ можуть утворювати спрямований ациклічний граф.
1.14.5 Поля типу
Щоб похідні класи були не просто зручною формою короткого опису, у реалізації мови повинно бути вирішено питання: якому з похідних класів ставиться об'єкт, на який дивиться вказівник base*? Існує три основних способи відповіді:
[1] Забезпечити, щоб вказівник міг посилатися на об'єкти тільки одного типу;
[2] Помістити в базовий клас поле типу, що зможе перевіряти функції;
[3] використати віртуальні функції.
Вказівники на базові класи, звичайно, використаються при проектуванні контейнерних класів (вектор, список і т.д.). Тоді у випадку [1] ми одержимо однорідні списки, тобто списки об'єктів одного типу.
Способи [2] і [3] дозволяють створювати різнорідні списки, тобто списки об'єктів декількох різних типів (насправді, списки вказівників на ці об'єкти).
Спосіб [3] - це спеціальний надійний у сенсі типу варіант спосіб [2]. Особливо цікаві й потужні варіанти дають комбінації способів [1] і [3].
Спочатку обговоримо простий спосіб з полем типу, тобто спосіб [2]. Приклад із класами manager/employee можна перевизначити так:
struct employee {
enum empl_type { M, E };
empl_type type;
employee* next;
char* name;
short department;
// ...
};
struct manager: employee {
employee* group;
short level;
// ...
};
Маючи ці визначення, можна написати функцію, що друкує дані про довільного службовця:
void print_employee (const employee* e)
{
switch (e->type) {
case E:
cout << e->name << '\t' << e->department << '\n';
// ...
break;
case M:
cout << e->name << '\t' << e->department << '\n';
// ...
manager* p = (manager*) e;
cout << "level" << p->level << '\n';
// ...
break;
}
}
Надрукувати список службовців можна так:
void f (const employee* elist)
{
for (; elist; elist=elist->next) print_employee (elist);
}
Це цілком гарне рішення, особливо для невеликих програм, написаних однією людиною, але воно має істотний недолік: транслятор не може перевірити, наскільки правильно програміст поводиться з типами. У більших програмах це приводить до помилок двох видів. Перша - коли програміст забуває перевірити поле типу. Друга - коли в перемикачі вказуються не всі можливі значення поля типу. Цих помилок досить легко уникнути в процесі написання програми, але зовсім нелегко уникнути їх при внесенні змін у нетривіальну програму, а особливо, якщо це велика програма, написана кимось іншим. Ще сутужніше уникнути таких помилок тому, що функції типу print () часто пишуться так, щоб можна було скористатися спільністю класів:
void print (const employee* e)
{
cout << e->name << '\t' << e->department << '\n';
// ...
if (e->type == M) {
manager* p = (manager*) e;
cout << "level" << p->level << '\n';
// ...
}
}
Оператори if, подібні наведеним у прикладі, складно знайти у великій функції, що працює з багатьма похідними класами. Але навіть коли вони знайдені, нелегко зрозуміти, що відбувається насправді. Крім того, при всякім додаванні нового виду службовців потрібні зміни у всіх важливих функціях програми, тобто функціях, що перевіряють поле типу. У результаті доводиться правити важливі частини програми, збільшуючи тим самим час на налагодження цих частин.
Іншими словами, використання поля типу чревате помилками й труднощами при супроводі програми. Труднощі різко зростають по мірі росту програми, адже використання поля типу суперечить принципам модульності й приховування даних. Кожна функція, що працює з полем типу, повинна знати подання й специфіку реалізації всякого класу, котрий є похідним для класу, що містить поле типу.
1.14.6 Віртуальні функціїЗа допомогою віртуальних функцій можна перебороти труднощі, що виникають при використанні поля типу. У базовому класі описуються функції, які можуть перевизначатися в будь-якому похідному класі. Транслятор і завантажник забезпечать правильну відповідність між об'єктами й застосовуваними до них функціями:
class employee {
char* name;
short department;
// ...
employee* next;
static employee* list;
public:
employee (char* n, int d);
// ...
static void print_list ();
virtual void print () const;
};
Службове слово virtual (віртуальна) показує, що функція print () може мати різні версії в різних похідних класах, а вибір потрібної версії при виклику print () - це завдання транслятора. Тип функції вказується в базовому класі й не може бути перевизначений у похідному класі. Визначення віртуальної функції повинне даватися для того класу, у якому вона була вперше описана (якщо тільки вона не є чисто віртуальною функцією). Наприклад:
void employee:: print () const
{
cout << name << '\t' << department << '\n';
// ...
}
Ми бачимо, що віртуальну функцію можна використати, навіть якщо немає похідних класів від її класу. У похідному ж класі не обов'язково перевизначити віртуальну функцію, якщо вона там не потрібна. При побудові похідного класу треба визначати тільки ті функції, які в ньому дійсно потрібні:
class manager: public employee {
employee* group;
short level;
// ...
public:
manager (char* n, int d);
// ...
void print () const;
};
Місце функції print_employee () зайняли функції-члени print (), і вона стала не потрібна. Список службовців будує конструктор employee. Надрукувати його можна так:
void employee:: print_list ()
{
for (employee* p = list; p; p=p->next) p->print ();
}
Дані про кожного службовця будуть друкуватися відповідно до типу запису про нього. Тому програма
int main ()
{
employee e ("J. Brown",1234);
manager m ("J. Smith",2,1234);
employee:: print_list ();
}
надрукує
J. Smith 1234
level 2
J. Brown 1234
Зверніть увагу, що функція друку буде працювати навіть у тому випадку, якщо функція employee_list () була написана й трансльована ще до того, як був задуманий конкретний похідний клас manager! Очевидно, що для правильної роботи віртуальної функції потрібно в кожному об'єкті класу employee зберігати деяку службову інформацію про тип. Як правило, реалізація як така інформація використовується просто вказівник. Цей вказівник зберігається тільки для об'єктів класу з віртуальними функціями, але не для об'єктів всіх класів, і навіть для не для всіх об'єктів похідних класів. Додаткова пам'ять виділяється тільки для класів, у яких описані віртуальні функції. Помітимо, що при використанні поля типу, для нього однаково потрібна додаткова пам'ять.
Якщо у виклику функції явно зазначена операція дозволу області видимості::, наприклад, у виклику manager:: print (), то механізм виклику віртуальної функції не діє. Інакше подібний виклик привів би до нескінченної рекурсії. Уточнення імені функції дає ще один позитивний ефект: якщо віртуальна функція є підстановкою (у цьому немає нічого незвичайного), те у виклику з операцією:: відбувається підстановка тіла функції. Це ефективний спосіб виклику, якому можна застосовувати у важливих випадках, коли одна віртуальна функція звертається до іншої з тим самим об'єктом. Приклад такого випадку - виклик функції manager:: print (). Оскільки тип об'єкта явно задається в самому виклику manager:: print (), немає потреби визначати його в динаміку для функції employee:: print (), що і буде викликатися.
1.14.7 Абстрактні класи
Багато класів подібні із класом employee тим, що в них можна дати розумне визначення віртуальним функціям. Однак, є й інші класи. Деякі, наприклад, клас shape, представляють абстрактне поняття (фігура), для якого не можна створити об'єкти. Клас shape набуває сенсу тільки як базовий клас у деякому похідному класі. Причиною є те, що неможливо дати осмислене визначення віртуальних функцій класу shape:
class shape {
// ...
public:
virtual void rotate (int) { error ("shape:: rotate"); }
virtual void draw () { error ("shape:: draw"): }
// не можна не обертати, не малювати абстрактну фігуру
// ...
};
Створення об'єкта типу shape (абстрактної фігури) законна, хоча зовсім безглузда операція:
shape s; // нісенітниця: ''фігура взагалі''
Вона безглузда тому, що будь-яка операція з об'єктом s приведе до помилки.
Краще віртуальні функції класу shape описати як чисто віртуальні. Зробити віртуальну функцію чисто віртуальної можна, додавши ініціалізатор = 0:
class shape {
// ...
public:
virtual void rotate (int) = 0; // чисто віртуальна функція
virtual void draw () = 0; // чисто віртуальна функція
};
Клас, у якому є віртуальні функції, називається абстрактним. Об'єкти такого класу створити не можна:
shape s; // помилка: змінна абстрактного класу shape
Абстрактний клас можна використати тільки в якості базового для іншого класу:
class circle: public shape {
int radius;
public:
void rotate (int) { } // нормально:
// перевизначення shape:: rotate
void draw (); // нормально:
// перевизначення shape:: draw
circle (point p, int r);
};
Якщо чиста віртуальна функція не визначається в похідному класі, то вона й залишається такою, а значить похідний клас теж є абстрактним. При такому підході можна реалізовувати класи поетапно:
class X {
public:
virtual void f () = 0;
virtual void g () = 0;
};
X b; // помилка: опис об'єкта абстрактного класу X
class Y: public X {
void f (); // перевизначення X:: f
};
Y b; // помилка: опис об'єкта абстрактного класу Y
class Z: public Y {
void g (); // перевизначення X:: g
};
Z c; // нормально
Абстрактні класи потрібні для завдання інтерфейсу без уточнення яких-небудь конкретних деталей реалізації. Наприклад, в операційній системі деталі реалізації драйвера пристрою можна сховати таким абстрактним класом:
class character_device {
public:
virtual int open () = 0;
virtual int close (const char*) = 0;
virtual int read (const char*, int) =0;
virtual int write (const char*, int) = 0;
virtual int ioctl (int. .) = 0;
// ...
};
Дійсні драйвери будуть визначатися як похідні від класу character_device.
1.14.8 Множинне входження базового класу
Можливість мати більше одного базового класу спричиняє можливість кількаразового входження класу як базового. Припустимо, класи task і displayed є похідними класу link, тоді в satellite (зроблений на їх основі) він буде входити двічі:
class task: public link {
// link використається для зв'язування всіх
// завдань у список (список диспетчера)
// ...
};
class displayed: public link {
// link використається для зв'язування всіх
// зображуваних об'єктів (список зображень)
// ...
};
Але проблем не виникає. Два різних об'єкти link використаються для різних списків, і ці списки не конфліктують один з одним. Звичайно, без ризику неоднозначності не можна звертатися до членів класу link, але як це зробити коректно, показано в наступному розділі. Графічно об'єкт satellite можна представити так:
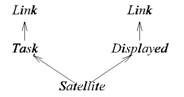
Але можна привести приклади, коли загальний базовий клас не повинен представлятися двома різними об'єктами.
1.14.9 Вирішення неоднозначності
Природно, у двох базових класів можуть бути функції-члени з однаковими іменами:
class task {
// ...
virtual debug_info* get_debug ();
};
class displayed {
// ...
virtual debug_info* get_debug ();
};
При використанні класу satellite подібна неоднозначність функцій повинна бути дозволена:
void f (satellite* sp)
{
debug_info* dip = sp->get_debug (); // помилка: неоднозначність
dip = sp->task:: get_debug (); // нормально
dip = sp->displayed:: get_debug (); // нормально
}
Однак, явний дозвіл неоднозначності клопітно, тому для її усунення найкраще визначити нову функцію в похідному класі:
class satellite: public task, public derived {
// ...
debug_info* get_debug ()
{
debug_info* dip1 = task: get_debug ();
debug_info* dip2 = displayed:: get_debug ();
return dip1->merge (dip2);
}
};
Тим самим локалізується інформація з базових для satellite класів. Оскільки satellite:: get_debug () є перевизначенням функцій get_debug () з обох базових класів, гарантується, що саме вона буде викликатися при всякім звертанні до get_debug () для об'єкта типу satellite.
Транслятор виявляє колізії імен, що виникають при визначенні того самого імені в більш, ніж одному базовому класі. Тому програмістові не треба вказувати яке саме ім'я використається, крім випадку, коли його використання дійсно неоднозначно. Як правило використання базових класів не приводить до колізії імен. У більшості випадків, навіть якщо імена збігаються, колізія не виникає, оскільки імена не використаються безпосередньо для об'єктів похідного класу.
Якщо неоднозначності не виникає, зайво вказувати ім'я базового класу при явному звертанні до його члена. Зокрема, якщо множинне успадкування не використовується, цілком достатньо використати позначення типу "десь у базовому класі". Це дозволяє програмістові не запам'ятовувати ім'я прямого базового класу й рятує його від помилок (втім, рідких), що виникають при перебудові ієрархії класів.
void manager:: print ()
{
employee:: print ();
// ...
}
передбачається, що employee - прямій базовий клас для manager. Результат цієї функції не зміниться, якщо employee виявиться непрямим базовим класом для manager, а в прямому базовому класі функції print () немає. Однак, хтось міг би в такий спосіб перешикувати класи:
class employee {
// ...
virtual void print ();
};
class foreman: public employee {
// ...
void print ();
};
class manager: public foreman {
// ...
void print ();
};
Тепер функція foreman:: print () не буде викликатися, хоча майже напевно передбачався виклик саме цієї функції. За допомогою невеликої хитрості можна перебороти ці труднощі:
class foreman: public employee {
typedef employee inherited;
// ...
void print ();
};
class manager: public foreman {
typedef foreman inherited;
// ...
void print ();
};
void manager:: print ()
{
inherited:: print ();
// ...
}
Правила областей видимості, зокрема ті, які ставляться до вкладених типів, гарантують, що виниклі кілька типів inherited не будуть конфліктувати один з одним. Взагалі ж справа смаку, використовувати рішення з типом inherited наочним чи ні.
1.14.10 Віртуальні базові класиУ попередніх розділах множинне спадкування розглядалося як істотного фактора, що дозволяє за рахунок злиття класів безболісно інтегрувати незалежно, що створювалися програми. Це саме основне застосування множинного спадкування, і, на щастя (але не випадково), це найпростіший і надійний спосіб його застосування.
Іноді застосування множинного спадкування припускає досить тісний зв'язок між класами, які розглядаються як "братні" базові класи. Такі класи-брати звичайно повинні проектуватися спільно. У більшості випадків для цього не потрібен особливий стиль програмування, що істотно відрізняється від того, котрий ми тільки що розглядали. Просто на похідний клас покладається деяка додаткова робота. Звичайно вона зводиться до перевизначення однієї або декількох віртуальних функцій. У деяких випадках класи-брати повинні мати загальну інформацію. Оскільки С++ - мову зі строгим контролем типів, спільність інформації можлива тільки при явній вказівці того, що є загальним у цих класах. Способом такої вказівки може служити віртуальний базовий клас.
Віртуальний базовий клас можна використати для подання "головного" класу, що може конкретизуватися різними способами:
class window {
// головна інформація
virtual void draw ();
};
Для простоти розглянемо тільки один вид загальної інформації із класу window - функцію draw (). Можна визначати різні більше розвинені класи, що представляють вікна (window). У кожному визначається своя (більше розвинена) функція малювання (draw):
class window_w_border: public virtual window {
// клас "вікно з рамкою"
// визначення, пов'язані з рамкою
void draw ();
};
class window_w_menu: public virtual window {
// клас "вікно з меню"
// визначення, пов'язані з меню
void draw ();
};
Тепер хотілося б визначити вікно з рамкою й меню:
class Clock: public virtual window,
public window_w_border,
public window_w_menu {
// клас "вікно з рамкою й меню"
void draw ();
};
Кожний похідний клас додає нові властивості вікна. Щоб скористатися комбінацією всіх цих властивостей, ми повинні гарантувати, що той самий об'єкт класу window використається для подання входжень базового класу window у ці похідні класи. Саме це забезпечує опис window у всіх похідних класах як віртуального базового класу.
Можна в такий спосіб зобразити состав об'єкта класу window_w_border_and_menu:
Щоб побачити різницю між звичайним і віртуальним спадкуванням, зрівняєте цей малюнок з малюнком, що показує состав об'єкта класу satellite. У графі спадкування кожний базовий клас із даним ім'ям, що був зазначений як віртуальний, буде представлений єдиним об'єктом цього класу. Навпроти, кожний базовий клас, що при описі спадкування не був зазначений як віртуальний, буде представлений своїм власним об'єктом.
Тепер треба написати всі ці функції draw (). Це не занадто важко, але для необережного програміста тут є пастка. Спочатку підемо найпростішим шляхом, що саме до неї й веде:
void window_w_border:: draw ()
{
window:: draw ();
// малюємо рамку
}
void window_w_menu:: draw ()
{
window:: draw ();
// малюємо меню
}
Поки всі добре. Все це очевидно, і ми додержуємося зразка визначення таких функцій за умови єдиного спадкування, що працював прекрасно. Однак, у похідному класі наступного рівня з'являється пастка:
void clock:: draw () // пастка!
{
window_w_border:: draw ();
window_w_menu:: draw ();
// тепер операції, що ставляться тільки
// до вікна з рамкою й меню
}
На перший погляд все цілком нормально. Як звичайно, спочатку виконуються всі операції, необхідні для базових класів, а потім ті, які ставляться властиво до похідних класів. Але в результаті функція window:: draw () буде викликатися двічі! Для більшості графічних програм це не просто зайвий виклик, а псування картинки на екрані. Звичайно друга видача на екран затирає першу.
Щоб уникнути пастки, треба діяти не так поспішно. Ми відокремимо дії, виконувані базовим класом, від дій, виконуваних з базового класу. Для цього в кожному класі введемо функцію _draw (), що виконує потрібні тільки для нього дії, а функція draw () буде виконувати ті ж дії плюс дії, потрібні для кожного базового класу. Для класу window зміни зводяться до введення зайвої функції:
class window {
// головна інформація
void _draw ();
void draw ();
};
Для похідних класів ефект той же:
class window_w_border: public virtual window {
// клас "вікно з рамкою"
// визначення, пов'язані з рамкою
void _draw ();
void draw ();
};
void window_w_border:: draw ()
{
window:: _draw ();
_draw (); // малює рамку
};
Тільки для похідного класу наступного рівня проявляється відмінність функції, що і дозволяє обійти пастку з повторним викликом window:: draw (), оскільки тепер викликається window:: _draw () і тільки один раз:
class clock
: public virtual window,
public window_w_border,
public window_w_menu {
void _draw ();
void draw ();
};
void clock:: draw ()
{
window:: _draw ();
window_w_border:: _draw ();
window_w_menu:: _draw ();
_draw (); // тепер операції, що ставляться тільки
// до вікна з рамкою й меню
}
Не обов'язково мати обидві функції window:: draw () і window:: _draw (), але наявність їх дозволяє уникнути різних простих описок.
У цьому прикладі клас window служить сховищем загальної для window_w_border і window_w_menu інформації й визначає інтерфейс для спілкування цих двох класів.
Якщо використається єдине спадкування, то спільність інформації в дереві класів досягається тим, що ця інформація пересувається до кореня дерева доти, поки вона не стане доступна всім зацікавленим у ній вузловим класам.
У результаті легко виникає неприємний ефект: корінь дерева або близькі до нього класи використаються як простір глобальних імен для всіх класів дерева, а ієрархія класів вироджується в безліч незв'язаних об'єктів.
Істотно, щоб у кожному із класів-братів перевизначалися функції, певні в загальному віртуальному базовому класі. У такий спосіб кожний із братів може одержати свій варіант операцій, відмінний від інших. Нехай у класі window є загальна функція уведення get_input ():
class window {
// головна інформація
virtual void draw ();
virtual void get_input ();
};
В одному з похідних класів можна використати цю функцію, не замислюючись про те, де вона визначена:
class window_w_banner: public virtual window {
// клас "вікно із заголовком"
void draw ();
void update_banner_text ();
};
void window_w_banner:: update_banner_text ()
{
// ...
get_input ();
// змінити текст заголовка
}
В іншому похідному класі функцію get_input () можна визначати, не замислюючись про те, хто її буде використати:
class window_w_menu: public virtual window {
// клас "вікно з меню"
// визначення, пов'язані з меню
void draw ();
void get_input (); // перевизначає window:: get_input ()
};
Всі ці визначення збираються разом у похідному класі наступного рівня:
class clock
: public virtual window,
public window_w_banner,
public window_w_menu
{
void draw ();
};
Контроль неоднозначності дозволяє переконатися, що в класах-братах визначені різні функції:
class window_w_input: public virtual window {
// ...
void draw ();
void get_input (); // перевизначає window:: get_input
};
class clock
: public virtual window,
public window_w_input,
public window_w_menu
{ // помилка: обидва класи window_w_input і
// window_w_menu перевизначають функцію
// window:: get_input
void draw ();
};
Транслятор виявляє подібну помилку, а усунути неоднозначність можна звичайним способом: ввести в класи window_w_input і window_w_menu функцію, що перевизначає "функції-порушника", і якимось чином усунути неоднозначність:
class window_w_input_and_menu
: public virtual window,
public window_w_input,
public window_w_menu
{
void draw ();
void get_input ();
};
У цьому класі window_w_input_and_menu:: get_input () буде перевизначати всі функції get_input ().
1.14.11 Контроль доступу
Член класу може бути приватним (private), захищеним (protected) або загальним (public):
Приватний член класу X можуть використати тільки функції-члени й друзі класу X.
Захищений член класу X можуть використати тільки функції-члени й друзі класу X, а так само функції-члени й друзі всіх похідних від X класів.
Загальний член можна використати в будь-якій функції.
Ці правила відповідають розподілу функцій, що звертаються до класу, на три види: функції, що реалізують клас (його друзі й члени), функції, що реалізують похідний клас (друзі й члени похідного класу) і всі інші функції.
Контроль доступу застосовується одноманітно до всіх імен. На контроль доступу не впливає, яку саме сутність позначає ім'я. Це означає, що частками можуть бути функції-члени, константи й т.д. нарівні із приватними членами, що представляють дані:
class X {
private:
enum { A, B };
void f (int);
int a;
};
void X:: f (int i)
{
if (i<A) f (i+B);
a++;
}
void g (X& x)
{
int i = X:: A; // помилка: X:: A приватний член
x. f (2); // помилка: X:: f приватний член
x. a++; // помилка: X:: a приватний член
}
1.14.12 Захищені члени
Дамо приклад захищених членів, повернувшись до класу window з попереднього розділу. Тут функції _draw () призначалися тільки для використання в похідних класах, оскільки надавали неповний набір можливостей, а тому не були достатньо зручні й надійні для загального застосування. Вони були як би будівельним матеріалом для більше розвинених функцій.
З іншого боку, функції draw () призначалися для загального застосування.
Це розходження можна виразити, розбивши інтерфейси класів window на дві частини - захищений інтерфейс і загальний інтерфейс:
class window {
public:
virtual void draw ();
// ...
protected:
void _draw ();
// інші функції, що служать будівельним матеріалом
private:
// подання класу
};
Така розбивка можна проводити й у похідних класах, таких, як window_w_border або window_w_menu.
Префікс _ використається в іменах захищених функцій, що є частиною реалізації класу, за загальним правилом: імена, що починаються з _, не повинні бути присутнім у частинах програми, відкритих для загального використання. Імен, що починаються з подвійного символу підкреслення, краще взагалі уникати (навіть для членів).
От менш практичний, але більше докладний приклад:
class X {
// за замовчуванням приватна частина класу
int priv;
protected:
int prot;
public:
int publ;
void m ();
};
Для члена X:: m доступ до членів класу необмежений:
void X:: m ()
{
priv = 1; // нормально
prot = 2; // нормально
publ = 3; // нормально
}
Член похідного класу має доступ тільки до загальних і захищених членів:
class Y: public X {
void mderived ();
};
Y:: mderived ()
{
priv = 1; // помилка: priv приватний член
prot = 2; // нормально: prot захищений член, а
// mderived () член похідного класу Y
publ = 3; // нормально: publ загальний член
}
У глобальній функції доступні тільки загальні члени:
void f (Y* p)
{
p->priv = 1; // помилка: priv приватний член
p->prot = 2; // помилка: prot захищений член, а f ()
// не друг або член класів X і Y
p->publ = 3; // нормально: publ загальний член}
1.14.13 Доступ до базових класів
Подібно члену базовий клас можна описати як приватний, захищений або загальний:
class X {
public:
int a;
// ...
};
class Y1: public X { };
class Y2: protected X { };
class Y3: private X { };
Оскільки X - загальний базовий клас для Y1, у будь-якій функції, якщо є необхідність, можна (неявно) перетворити Y1* в X*, і притім у ній будуть доступні загальні члени класу X:
void f (Y1* py1, Y2* py2, Y3* py3)
{
X* px = py1; // нормально: X - загальний базовий клас Y1
py1->a = 7; // нормально
px = py2; // помилка: X - захищений базовий клас Y2
py2->a = 7; // помилка
px = py3; // помилка: X - приватний базовий клас Y3
py3->a = 7; // помилка
}
Тепер нехай описані
class Y2: protected X { };
class Z2: public Y2 { void f (); };
Оскільки X - захищений базовий клас Y2, тільки друзі й члени Y2, а також друзі й члени будь-яких похідних від Y2 класів (зокрема Z2) можуть при необхідності перетворювати (неявно) Y2* в X*. Крім того вони можуть звертатися до загальних і захищених членів класу X:
void Z2:: f (Y1* py1, Y2* py2, Y3* py3)
{
X* px = py1; // нормально: X - загальний базовий клас Y1
py1->a = 7; // нормально
px = py2; // нормально: X - захищений базовий клас Y2, // а Z2 - похідний клас Y2
py2->a = 7; // нормально
px = py3; // помилка: X - приватний базовий клас Y3
py3->a = 7; // помилка
}
Нарешті, розглянемо:
class Y3: private X { void f (); };
Оскільки X - приватний базовий клас Y3, тільки друзі й члени Y3 можуть при необхідності перетворювати (неявно) Y3* в X*. Крім того вони можуть звертатися до загальних і захищених членів класу X:
void Y3:: f (Y1* py1, Y2* py2, Y3* py3)
{
X* px = py1; // нормально: X - загальний базовий клас Y1
py1->a = 7; // нормально
px = py2; // помилка: X - захищений базовий клас Y2
py2->a = 7; // помилка
px = py3; // нормально: X - приватний базовий клас Y3, // а Y3:: f член Y3
py3->a = 7; // нормально
}
1.14.14 Вільна пам'ятьЯкщо визначити функції operator new () і operator delete (), керування пам'яттю для класу можна взяти у свої руки. Це також можна, (а часто й більш корисно), зробити для класу, що служить базовим для багатьох похідних класів. Допустимо, нам потрібні були свої функції розміщення й звільнення пам'яті для класу employee ($$6.2.5) і всіх його похідних класів:
class employee {
// ...
public:
void* operator new (size_t);
void operator delete (void*, size_t);
};
void* employee:: operator new (size_t s)
{
// відвести пам'ять в 's' байтів
// і повернути покажчик на неї
}
void employee:: operator delete (void* p, size_t s)
{
// 'p' повинне вказувати на пам'ять в 's' байтів,
// відведену функцією employee:: operator new ();
// звільнити цю пам'ять для повторного використання
}
Призначення до цієї пори загадкового параметра типу size_t стає очевидним. Це - розмір об'єкта, що звільняє. При видаленні простого службовця цей параметр одержує значення sizeof (employee), а при видаленні керуючого - sizeof (manager). Тому власні функції класи для розміщення можуть не зберігати розмір кожного розташованого об'єкта. Звичайно, вони можуть зберігати ці розміри (подібно функціям розміщення загального призначення) і ігнорувати параметр size_t у виклику operator delete (), але тоді навряд чи вони будуть краще, ніж функції розміщення й звільнення загального призначення.
Як транслятор визначає потрібний розмір, якому треба передати функції operator delete ()? Поки тип, зазначений в operator delete (), відповідає щирому типу об'єкта, все просто; але розглянемо такий приклад:
class manager: public employee {
int level;
// ...
};
void f ()
{
employee* p = new manager; // проблема
delete p;
}
У цьому випадку транслятор не зможе правильно визначити розмір. Як і у випадку видалення масиву, потрібна допомога програміста.
Він повинен визначити віртуальний деструктор у базовому класі employee:
class employee {
// ...
public:
// ...
void* operator new (size_t);
void operator delete (void*, size_t);
virtual ~employee ();
};
Навіть порожній деструктор вирішить нашу проблему:
employee:: ~employee () { }
Тепер звільнення пам'яті буде відбуватися в деструкторі (а в ньому розмір відомий), а будь-який похідний від employee клас також буде змушений визначати свій деструктор (тим самим буде встановлений потрібний розмір), якщо тільки користувач сам не визначить його. Тепер наступний приклад пройде правильно:
void f ()
{
employee* p = new manager; // тепер без проблем
delete p;
}
Розміщення відбувається за допомогою (створеного транслятором) виклику
employee:: operator new (sizeof (manager))
а звільнення за допомогою виклику
employee:: operator delete (p,sizeof (manager))
Іншими словами, якщо потрібно мати коректні функції розміщення й звільнення для похідних класів, треба або визначити віртуальний деструктор у базовому класі, або не використати у функції звільнення параметр size_t. Звичайно, можна було при проектуванні мови передбачити засоби, що звільняють користувача від цієї проблеми. Але тоді користувач "звільнився" би й від певних переваг більше оптимальної, хоча й менш надійної системи.
У загальному випадку, завжди має сенс визначати віртуальний деструктор для всіх класів, які дійсно використаються як базові, тобто з об'єктами похідних класів працюють і, можливо, видаляють їх, через покажчик на базовий клас:
class X {
// ...
public:
// ...
virtual void f (); // в X є віртуальна функція, тому
// визначаємо віртуальний деструктор
virtual ~X ();
};
1.14.15 Віртуальні конструкториДовідавшись про віртуальні деструктори, природно запитати: "Чи можуть конструктори те ж бути віртуальними?" Якщо відповісти коротко - немає. Можна дати більше довга відповідь: "Ні, але можна легко одержати необхідний ефект".
Конструктор не може бути віртуальним, оскільки для правильної побудови об'єкта він повинен знати його тип. Більше того, конструктор - не зовсім звичайна функція. Він може взаємодіяти з функціями керування пам'яттю, що неможливо для звичайних функцій. Від звичайних функцій-членів він відрізняється ще тим, що не викликається для існуючих об'єктів. Отже не можна одержати вказівник на конструктор.
Але ці обмеження можна обійти, якщо визначити функцію, що містить виклик конструктора й повертає побудований об'єкт. Це вдало, оскільки нерідко буває потрібно створити новий об'єкт, не знаючи його реального типу. Наприклад, при трансляції іноді виникає необхідність зробити копію дерева, що представляє вираз, що розбирається. У дереві можуть бути вузли виражень різних видів. Припустимо, що вузли, які містять повторювані у вираженні операції, потрібно копіювати тільки один раз. Тоді нам буде потрібно віртуальна функція розмноження для вузла вираження.
Як правило "віртуальні конструктори" є стандартними конструкторами без параметрів або конструкторами копіювання, параметром яких служить тип результату:
class expr {
// ...
public:
expr (); // стандартний конструктор
virtual expr* new_expr () { return new expr (); }
};
Віртуальна функція new_expr () просто повертає стандартно ініціалізований об'єкт типу expr, розміщений у вільній пам'яті. У похідному класі можна перевизначити функцію new_expr () так, щоб вона повертала об'єкт цього класу:
class conditional: public expr {
// ...
public:
conditional (); // стандартний конструктор
expr* new_expr () { return new conditional (); }
};
Це означає, що, маючи об'єкт класу expr, користувач може створити об'єкт в "точності такого ж типу":
void user (expr* p1, expr* p2)
{
expr* p3 = p1->new_expr ();
expr* p4 = p2->new_expr ();
// ...
}
Змінним p3 і p4 привласнюються вказівники невідомого, але підходящого типу.
Тим же способом можна визначити віртуальний конструктор копіювання, названий операцією розмноження, але треба підійти більш ретельно до специфіки операції копіювання:
class expr {
// ...
expr* left;
expr* right;
public:
// ...
// копіювати 's' в 'this'
inline void copy (expr* s);
// створити копію об'єкта, на який дивиться this
virtual expr* clone (int deep = 0);
};
Параметр deep показує розходження між копіюванням властивому об'єкту (поверхневе копіювання) і копіюванням усього піддерева, коренем якого служить об'єкт (глибоке копіювання). Стандартне значення 0 означає поверхневе копіювання.
Функцію clone () можна використати, наприклад, так:
void fct (expr* root)
{
expr* c1 = root->clone (1); // глибоке копіювання
expr* c2 = root->clone (); // поверхневе копіювання
// ...
}
Будучи віртуальної, функція clone () здатна розмножувати об'єкти будь-якого похідного від expr класу. Дійсне копіювання можна визначити так:
void expr:: copy (expression* s, int deep)
{
if (deep == 0) { // копіюємо тільки члени
*this = *s;
}
else { // пройдемося по вказівником:
left = s->clone (1);
right = s->clone (1);
// ...
}
}
Функція expr:: clone () буде викликатися тільки для об'єктів типу expr (але не для похідних від expr класів), тому можна просто розмістити в ній і повернути з її об'єкт типу expr, що є власною копією:
expr* expr:: clone (int deep)
{
expr* r = new expr (); // будуємо стандартне вираження
r->copy (this,deep); // копіюємо '*this' в 'r'
return r;
}
Таку функцію clone () можна використати для похідних від expr класів, якщо в них не з'являються члени-дані (а це саме типовий випадок):
class arithmetic: public expr {
// ...
// нових член-член-даних немає =>
// можна використати вже певну функцію clone
};
З іншого боку, якщо додані члени-дані, то потрібно визначати власну функцію clone ():
class conditional: public expression {
expr* cond;
public:
inline void copy (cond* s, int deep = 0);
expr* clone (int deep = 0);
// ...
};
Функції copy () і clone () визначаються подібно своїм двійникам з expression:
expr* conditional:: clone (int deep)
{
conditional* r = new conditional ();
r->copy (this,deep);
return r;
}
void conditional:: copy (expr* s, int deep)
{
if (deep == 0) {
*this = *s;
}
else {
expr:: copy (s,1); // копіюємо частину expr
cond = s->cond->clone (1);
}
}
Визначення останньої функції показує відмінність дійсного копіювання в expr:: copy () від повного розмноження в expr:: clone () (тобто створення нового об'єкта й копіювання в нього). Просте копіювання виявляється корисним для визначення більш складних операцій копіювання й розмноження. Розходження між copy () і clone () еквівалентно розходженню між операцією присвоювання й конструктором копіювання і еквівалентно розходженню між функціями _draw () і draw (). Відзначимо, що функція copy () не є віртуальною. Їй і не треба бути такою, оскільки віртуальна викликаюча її функція clone (). Очевидно, що прості операції копіювання можна також визначати як функції-підстановки.
1.15 Перевантаження операційЗвичайно в програмах використовуються об'єкти, що є конкретним поданням абстрактних понять. Наприклад, у С++ тип даних int разом з операціями +, - , *, / і т.д. реалізує (хоча й обмежено) математичне поняття цілого. Звичайно з поняттям зв'язується набір дій, які реалізуються в мові у вигляді основних операцій над об'єктами, що задають у стислому, зручному й звичному виді. На жаль, у мовах програмування безпосередньо представляється тільки мале число понять. Так, поняття комплексних чисел, алгебри матриць, логічних сигналів і рядків у С++ не мають безпосереднього вираження. Можливість задати подання складних об'єктів разом з набором операцій, котрі виконуються над такими об'єктами, реалізують у С++ класи. Дозволяючи програмістові визначати операції над об'єктами класів, ми одержуємо більше зручну й традиційну систему позначень для роботи із цими об'єктами в порівнянні з тієї, у якій всі операції задаються як звичайні функції. Приведемо приклад:
class complex {
double re, im;
public:
complex (double r, double i) { re=r; im=i; }
friend complex operator+ (complex, complex);
friend complex operator* (complex, complex);
};
Тут наведена проста реалізація поняття комплексного числа, коли воно представлено парою чисел із плаваючою крапкою подвійної точності, з якими можна оперувати тільки за допомогою операцій + і *. Інтерпретацію цих операцій задає програміст у визначеннях функцій з іменами operator+ і operator*. Так, якщо b і c мають тип complex, те b+c означає (по визначенню) operator+ (b,c). Тепер можна наблизитися до звичного запису комплексних виражень:
void f ()
{
complex a = complex (1,3.1);
complex b = complex (1.2,2);
complex c = b;
a = b+c;
b = b+c*a;
c = a*b+complex (1,2);
}
Зберігаються звичайні пріоритети операцій, тому другий вираз виконується як b=b+ (c*a), а не як b= (b+c) *a.
1.15.1 Операторні функції
Можна описати функції, що визначають інтерпретацію наступних операцій:
+ - * /% ^ & | ~!
= < > += - = *= /=%= ^= &=
|= << >> >>= <<= ==! = <= >= &&
|| ++ - і - >*, - > [] () new delete
Останні п'ять операцій означають: непряме звертання, індексацію, виклик функції, розміщення у вільній пам'яті й звільнення. Не можна змінити пріоритети цих операцій, так само як і синтаксичні правила для виразів. Так, не можна визначити унарну операцію%, також як і бінарну операцію!. Не можна ввести нові лексеми для позначення операцій, але якщо набір операцій вас не влаштовує, можна скористатися звичним позначенням виклику функції. Тому використайте pow (), а не **. Ці обмеження можна ввжати драконівськими, але більш вільні правила легко приводять до неоднозначності. Припустимо, ми визначимо операцію ** як піднесення до степеня, що на перший погляд здається очевидним і простим завданням. Але якщо як варто подумати, то виникають питання: чи належні операції ** виконуватися ліворуч праворуч або праворуч ліворуч? Як інтерпретувати вираження a**p як a* (*p) або як (a) ** (p)?
Ім'ям операторної функції є службове слово operator, за яким іде сама операція, наприклад, operator<<. Операторна функція описується й викликається як звичайна функція. Використання символу операції є просто короткою формою запису виклику операторної функції:
void f (complex a, complex b)
{
complex c = a + b; // коротка форма
complex d = operator+ (a,b); // явний виклик
}
З урахуванням наведеного опису типу complex ініціалізатори в цьому прикладі є еквівалентними.
1.15.2 Бінарні й унарні операції
Бінарну операцію можна визначити як функція-член з одним параметром, або як глобальну функцію із двома параметрами. Виходить, для будь-якої бінарної операції @ вираження aa @ bb інтерпретується або як aa. operator (bb), або як operator@ (aa,bb). Якщо визначені обидві функції, то вибір інтерпретації відбувається за правилами зіставлення параметрів. Префіксна або постфіксна унарна операція може визначатися як функція-член без параметрів, або як глобальна функція з одним параметром. Для будь-якої префиксної унарної операції @ вираження @aa інтерпретується або як aa. operator@ (), або як operator@ (aa). Якщо визначені обидві функції, то вибір інтерпретації відбувається за правилами зіставлення параметрів. Для будь-якої постфіксної унарної операції @ вираз @aa інтерпретується або як aa. operator@ (int), або як operator@ (aa, int). Якщо визначені обидві функції, то вибір інтерпретації відбувається за правилами зіставлення параметрів. Операцію можна визначити тільки відповідно до синтаксичних правил, наявними для неї в граматиці С++. Зокрема, не можна визначити% як унарну операцію, а + як тернарну. Проілюструємо сказане прикладами:
class X {
// члени (неявно використається покажчик 'this'):
X* operator& (); // префіксна унарная операція &
// (узяття адреси)
X operator& (X); // бінарна операція &
X operator++ (int); // постфіксний інкремент
X operator& (X,X); // помилка: & не може бути тернарною
X operator/ (); // помилка: / не може бути унарною
};
// глобальні функції (звичайно друзі)
X operator- (X); // префіксний унарный мінус
X operator- (X,X); // бінарний мінус
X operator-і (X&, int); // постфіксний інкремент
X operator- (); // помилка: немає операнда
X operator- (X,X,X); // помилка: тернарна операція
X operator% (X); // помилка: унарна операція%
1.15.3 Операторні функції й типи користувачаОператорна функція повинна бути або членом, або мати принаймні один параметр, що є об'єктом класу (для функцій, що перевизначають операції new і delete, це не обов'язково). Це правило гарантує, що користувач не зуміє змінити інтерпретацію виразів, що не містять об'єктів типу користувача. Зокрема, не можна визначити операторну функцію, що працює тільки з вказівниками. Цим гарантується, що в ++ можливі розширення, але не мутації (не вважаючи операцій =, &, і, для об'єктів класу).
Операторна функція, що має першим параметр основного типу, не може бути функцією-членом. Так, якщо ми додаємо комплексну змінну aa до цілого 2, то при підходящому описі функції-члена aa+2 можна інтерпретувати як aa. operator+ (2), але 2+aa так інтерпретувати не можна, оскільки не існує класу int, для якого + визначається як 2. operator+ (aa). Навіть якби це було можливо, для інтерпретації aa+2 і 2+aa довелося мати справа із двома різними функціями-членами. Цей приклад тривіально записується за допомогою функцій, що не є членами.
1.15.4 КонструкториЗамість того, щоб описувати кілька функцій для кожного випадку виклику (наприклад, комбінації типу double та complex з усіма операціями), можна описати конструктор, що з параметра double створює complex:
class complex {
// ...
complex (double r) { re=r; im=0; }
};
Цим визначається як одержати complex, якщо задано double. Конструктор з єдиним параметром не обов'язково викликати явно:
complex z1 = complex (23);
complex z2 = 23;
Обидві змінні z1 і z2 будуть ініціалізовані викликом complex (23).
Конструктор є алгоритмом створення значення заданого типу. Якщо потрібне значення деякого типу й існує його конструктор, параметром якого є це значення, то тоді цей конструктор і буде використатися. Так, клас complex можна було описати в такий спосіб:
class complex {
double re, im;
public:
complex (double r, double i =0) { re=r; im=i; }
friend complex operator+ (complex, complex);
friend complex operator* (complex, complex);
complex operator+= (complex);
complex operator*= (complex);
// ...
};
Всі операції над комплексними змінними й цілими константами з урахуванням цього опису стають законними. Ціла константа буде інтерпретуватися як комплексне число із мнимою частиною, рівної нулю. Так, a=b*2 означає
a = operator* (b, complex (double (2), double (0)))
Нові версії операцій таких, як +, має сенс визначати тільки для підвищення ефективності за рахунок відмови від перетворень типу коштує того. Наприклад, якщо з'ясується, що операція множення комплексної змінної на речовинну константу є критичної, то до безлічі операцій можна додати operator*= (double):
class complex {
double re, im;
public:
complex (double r, double i =0) { re=r; im=i; }
friend complex operator+ (complex, complex);
friend complex operator* (complex, complex);
complex& operator+= (complex);
complex& operator*= (complex);
complex& operator*= (double);
// ...
};
Операції присвоювання типу *= і += можуть бути дуже корисними для роботи з типами користувача, оскільки звичайно запис із ними коротше, ніж з їх звичайними "двійниками" * і +, а крім того вони можуть підвищити швидкість виконання програми за рахунок виключення тимчасових змінних:
inline complex& complex:: operator+= (complex a)
{
re += a. re;
im += a. im;
return *this;
}
При використанні цієї функції не потрібно тимчасовий змінної для зберігання результату, і вона досить проста, щоб транслятор міг "ідеально" зробити підстановку тіла. Такі прості операції як додавання комплексних теж легко задати безпосередньо:
inline complex operator+ (complex a, complex b)
{
return complex (a. re+b. re, a. im+b. im);
}
Тут в операторі return використається конструктор, що дає транслятору коштовну підказку на предмет оптимізації. Але для більше складних типів і операцій, наприклад таких, як множення матриць, результат не можна задати як одне вираження, тоді операції * і + простіше реалізувати за допомогою *= і +=, і вони будуть легше піддаватися оптимізації:
matrix& matrix:: operator*= (const matrix& a)
{
// ...
return *this;
}
matrix operator* (const matrix& a, const matrix& b)
{
matrix prod = a;
prod *= b;
return prod;
}
Відзначимо, що в певної подібним чином операції не потрібних ніяких особливих прав доступу до класу, до якого вона застосовується, тобто ця операція не повинна бути другом або членом цього класу.
Користувальницьке перетворення типу застосовується тільки в тому випадку, якщо воно єдине.
Побудований у результаті явного або неявного виклику конструктора, об'єкт є автоматичним, і знищується за першою нагодою, як правило відразу після виконання оператора, у якому він був створений.
1.15.5 Присвоювання й ініціалізація
Розглянемо простий строковий клас string:
struct string {
char* p;
int size; // розмір вектора, на який указує p
string (int size) { p = new char [size=sz]; }
~string () { delete p; }
};
Рядок - це структура даних, що містить вказівник на вектор символів і розмір цього вектора. Вектор створюється конструктором і знищується деструктором. Але тут можуть виникнути проблеми:
void f ()
{
string s1 (10);
string s2 (20)
s1 = s2;
}
Тут будуть розміщені два символьних вектори, але в результаті присвоювання s1 = s2 вказівник на один з них буде знищений, і заміниться копією другого. Після виходу з f () буде викликаний для s1 і s2 деструктор, що двічі видалить той самий вектор, результати чого по всій видимості будуть жалюгідні. Для рішення цієї проблеми потрібно визначити відповідне присвоювання об'єктів типу string:
struct string {
char* p;
int size; // розмір вектора, на який указує p
string (int size) { p = new char [size=sz]; }
~string () { delete p; }
string& operator= (const string&);
};
string& string:: operator= (const string& a)
{
if (this! =&a) { // небезпечно, коли s=s
delete p;
p = new char [size=a. size];
strcpy (p,a. p);
}
return *this;
}
При такім визначенні string попередній приклад пройде як задумано. Але після невеликої зміни в f () проблема виникає знову, але в іншому виді:
void f ()
{
string s1 (10);
string s2 = s1; // ініціалізація, а не присвоювання
}
Тепер тільки один об'єкт типу string будується конструктором string:: string (int), а знищуватися буде два рядки. Справа в тому, що користувальницька операція присвоювання не застосовується до неініціалізованого об'єкта. Досить глянути на функцію string:: operator (), щоб зрозуміти причину цього: вказівник p буде тоді мати невизначене, по суті випадкове значення. Як правило, в операції присвоювання передбачається, що її параметри проініціалізовані. Отже, щоб упоратися з ініціалізацією потрібна схожа, але своя функція:
struct string {
char* p;
int size; // розмір вектора, на який указує p
string (int size) { p = new char [size=sz]; }
~string () { delete p; }
string& operator= (const string&);
string (const string&);
};
string:: string (const string& a)
{
p=new char [size=sz];
strcpy (p,a. p);
}
Ініціалізація об'єкта типу X відбувається за допомогою конструктора X (const X&). Особливо це важливо в тих випадках, коли визначений деструктор. Якщо в класі X є нетривіальний деструктор, наприклад, що робить звільнення об'єкта у вільній пам'яті, найімовірніше, у цьому класі буде потрібно повний набір функцій, щоб уникнути копіювання об'єктів по членах:
class X {
// ...
X (something); // конструктор, що створює об'єкт
X (const X&); // конструктор копіювання
operator= (const X&); // присвоювання:
// видалення й копіювання
~X (); // деструктор
};
Є ще два випадки, коли доводиться копіювати об'єкт: передача параметра функції й повернення нею значення. При передачі параметра неініціалізована змінна, тобто формальний параметр ініціалізується. Семантика цієї операції ідентична іншим видам ініціалізації. Теж відбувається й при поверненні функцією значення, хоча цей випадок не такий очевидний. В обох випадках використається конструктор копіювання:
string g (string arg)
{
return arg;
}
main ()
{
string s = "asdf";
s = g (s);
}
Очевидно, після виклику g () значення s повинне бути "asdf". Не важко записати в параметр s копію значення s, для цього треба викликати конструктор копіювання для string. Для одержання ще однієї копії значення s по виходу з g () потрібний ще один виклик конструктора string (const string&). Цього разу ініціалізується тимчасова змінна, котра потім привласнюється s. Для оптимізації одну, але не обидві, з подібних операцій копіювання можна забрати. Природно, тимчасові змінні, використовувані для таких цілей, знищуються належним чином деструктором string:: ~string ().
Якщо в класі X операція присвоювання X:: operator= (const X&) і конструктор копіювання X:: X (const X&) явно не задані програмістом, що бракують операції будуть створені транслятором. Ці створені функції будуть копіювати по членах для всіх членів класу X. Якщо члени приймають прості значення, як у випадку комплексних чисел, це, те, що потрібно, і створені функції перетворяться в просте й оптимальне поразрядное копіювання. Якщо для самих членів визначені користувальницькі операції копіювання, вони й будуть викликатися відповідним чином:
class Record {
string name, address, profession;
// ...
};
void f (Record& r1)
{
Record r2 = r1;
}
Тут для копіювання кожного члена типу string з об'єкта r1 буде викликатися string:: operator= (const string&).
У нашому першому й неповноцінному варіанті строковий клас має член-вказівник і деструктор. Тому стандартне копіювання по членах для нього майже напевно невірно. Транслятор може попереджати про такі ситуації.
1.15.6 Інкремент і декрементНехай є програма з розповсюдженою помилкою:
void f1 (T a) // традиційне використання
{
T v [200];
T* p = &v [10];
p--;
*p = a; // Приїхали: `p' настроєні поза масивом,
// і це не виявлено
++p;
*p = a; // нормально
}
Природне бажання замінити вказівник p на об'єкт класу CheckedPtrTo, по якому непряме звертання можливо тільки за умови, що він дійсно вказує на об'єкт. Застосовувати інкремента і декремента до такого вказівника буде можна тільки в тому випадку, що вказівник настроєний на об'єкт у границях масиву й у результаті цих операцій вийде об'єкт у границях того ж масиву:
class CheckedPtrTo {
// ...
};
void f2 (T a) // варіант із контролем
{
T v [200];
CheckedPtrTo p (&v [0],v, 200);
p--;
*p = a; // динамічна помилка:
// 'p' вийшов за межі масиву
++p;
*p = a; // нормально
}
Інкремент і декремент є єдиними операціями в С++, які можна використати як постфіксні так і префіксні операції. Отже, у визначенні класу CheckedPtrTo ми повинні передбачити окремі функції для префіксних і постфіксних операцій інкремента й декремента:
class CheckedPtrTo {
T* p;
T* array;
int size;
public:
// початкове значення 'p'
// зв'язуємо з масивом 'a' розміру 's'
CheckedPtrTo (T* p, T* a, int s);
// початкове значення 'p'
// зв'язуємо з одиночним об'єктом
CheckedPtrTo (T* p);
T* operator++ (); // префіксна
T* operator++ (int); // постфіксна
T* operator-- (); // префіксна
T* operator-- (int); // постфісна
T& operator* (); // префіксна
};
Параметр типу int служить вказівкою, що функція буде викликатися для постфісної операції. Насправді цей параметр є штучним і ніколи не використається, а служить тільки для розходження постфіксної і префіксної операції. Щоб запам'ятати, яка версія функції operator++ використається як префіксна операція, досить пам'ятати, що префіксна є версія без штучного параметра, що вірно й для всіх інших унарних арифметичних і логічних операцій. Штучний параметр використається тільки для "особливих" постфіксних операцій ++ і - -. За допомогою класу CheckedPtrTo приклад можна записати так:
void f3 (T a) // варіант із контролем
{
T v [200];
CheckedPtrTo p (&v [0],v, 200);
p. operator-і (1);
p. operator* () = a; // динамічна помилка:
// 'p' вийшов за межі масиву
p. operator++ ();
p. operator* () = a; // нормально
}
1.15.7 Перевантаження операцій помістити в потік і взяти з потоку
C++ здатний вводити й виводити стандартні типи даних, використовуючи операцію помістити в потік " і операцію взяти з потоку ". Ці операції вже перевантажені в бібліотеках класів, якими постачені компілятори C++, щоб обробляти кожний стандартний тип даних, включаючи рядки й адреси пам'яті. Операції помістити в потік і взяти з потоку можна також перевантажити для того, щоб виконувати введення й вивід типів користувача. Програма на малюнку 8 демонструє перевантаження операцій помістити в потік і взяти з потоку для обробки даних певного користувачем класу телефонних номерів PhoneNumber. У цій програмі передбачається, що телефонні номери вводяться правильно. Перевірку помилок ми залишаємо для вправ.
На мал.8 функція-операція взяти з потоку (operator") одержує як аргументи посилання input типу istream, і посилання, названу num, на заданий користувачем тип PhoneNumber; функція повертає посилання типу istream. Функція-операція (operator") використається для введення номерів телефонів у вигляді
(056) 555-1212
в об'єкти класу PhoneNumber. Коли компілятор бачить вираження
cin >> phone
в main, він генерує виклик функції
operator>> (cin, phone);
Після виконання цього виклику параметр input стає псевдонімом для cin, а параметр num стає псевдонімом для phone. Функція-операція використовує функцію-елемент getline класу istream, щоб прочитати з рядка три частини телефонного номера викликаного об'єкта класу PhoneNumber (num у функції-операції й phone в main) в areaCode (код місцевості), exchange (комутатор) і line (лінія). Символи круглих дужок, пробілу й дефіса пропускаються при виклику функції-елемента ignore класу istream, що відкидає зазначену кількість символів у вхідному потоці (один символ за замовчуванням). Функція operator" повертає посилання input типу istream (тобто cin). Це дозволяє операціям введення об'єктів PhoneNumber бути зчепленими з операціями уведення інших об'єктів PhoneNumber або об'єктів інших типів даних. Наприклад, два об'єкти PhoneNumber могли б бути уведені в такий спосіб:
cin >> phonel >> phone2;
Спочатку було б виконане вираження cin " phonel шляхом виклику
operator>> (cin, phonel);
// Перевантаження операцій помістити в потік і взяти з потоку.
#include <iostream. h>
class PhoneNumber{
friend ostream soperator << (ostream &, const PhoneNumber &); friend istream ^operator >> (istream &, PhoneNumber &);
private:
char areaCode [4]; // трицифровий код місцевості й нульовий символ
char exchange [4]; // трицифровий комутатор і нульовий символ
char line [5]; // чотирицифрова лінія й нульовий символ
};
// Перевантажена операція помістити в потік
// (вона не може бути функцією-елементом).
ostream &operator<< (ostream soutput, const PhoneNumber &num)
{
output << " (" << num. areaCode << ")"
"num. exchange << "-" " num. line;
return output; // дозволяє cout << a << b <<c;
}
// Перевантажена операція взяти зпотоку
istream &operator>> (istream sinput, PhoneNumber &num)
{
input. ignore (); // пропуск (
input. getline (num. areaCode,
4); // введення коду місцевості
input. ignore (2); // пропуск) і пробілу
input. getline (num. exchange,
4); // введення комутатора
input. ignore (); // пропуск дефіса (-)
input. getline (num. line,
5); // введення лінії
return input; // дозволяє cin >> a >>b >>c;
}
main () {
PhoneNumber phone; // створення об'єкта phone
cout << "Введіть номер телефону у "
"" вигляді (123) 456-7890: " " endl;
// cin >> phone активізує функцію operator>> // шляхом виклику operator>> (cin, phone). cin >> phone;
// cout << phone активізує функцію operator<< // шляхом виклику operator<< (cout, phone).
cout << "Був введений номер телефону: "<<endl
<< phone << endl;
return 0; }
Введіть номер телефону у вигляді (123) 456-7890: (800) 555-1212
Був введений номер телефону: (800) 555-1212
Мал.8 Задані користувачем операції "помістити в потік" і "взяти з потоку"
Цей виклик міг би потім повернути посилання на cin як значення cin " phonel, так що частина, що залишилася, вираження була б інтерпретована просто як cin " phone2. Це було б виконане шляхом виклику
operator" (cin, phone2);
Операція помістити в потік одержує як аргументи посилання output типу ostream і посилання пшп на певний користувачем тип PhoneNumber і повертає посилання типу ostream. Функція operator" виводить на екран об'єкти типу PhoneNumber. Коли компілятор бачить вираження
cout << phone
в main, він генерує виклик функції
operator<< (cout, phone);
Функція operator" виводить на екран частини телефонного номера як рядка, тому що вони зберігаються у форматі рядка (функція-елемент getline класу istream зберігає нульовий символ після завершення введення).
Помітимо, що функції operator" і operator" об’явлені в class PhoneNumber не як функції-елементи, а як дружні функції. Ці операції не можуть бути елементами, тому що об'єкт класу PhoneNumber з'являється в кожному випадку як правий операнд операції; а для перевантаженої операції, записаної як функція-елемент, операнд класу повинен з'являтися ліворуч. Перевантажені операції помістити в потік і взяти з потоку повинні об’являтися як дружні, якщо вони повинні мати прямий доступ до закритих елементів класу з міркувань продуктивності.
2. Розробка власного класу clsString
2.1 Загальний алгоритм вирішення
Створимо базовий клас TPString у якому розмістимо мінімальнонеобхідні компоненти, але при цьому цей клас вже буде функціональною одиницею. На основі класу TPString створимо два нащадки TPStrThread-відповідатиме за потокову обробку рядка, а клас TPStrCompare-відповідатиме за порівнння. Обидва класи будуть абстрактними, так як представляють логічно незавершений результат виконання завдання. Використовуючи множинне успадкування створимо результуючий клас clsString, додавши іще декілька методів.
Загальна UML діаграма пропонованого варіанту
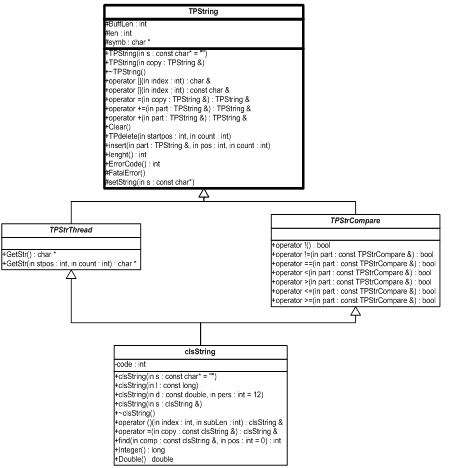
2.2 Детальний анализ
Почнемо аналізувати програму з класу TPString. Цей клас є базовим, а крім того може бути і віртуальним (для нащадків), тобто потрібен конструктор за замовченням. Цю функцію краще всього виконає конструктор перетворення. Його прототип:
TPString (const char * = "");
Цей конструктор виконуватиме перетворення рядків у стилі С. Код конструктору
TPString:: TPString (const char *s)
{
len=strlen (s);
BuffLen=0;
symb=NULL;
setString (s);
}
Захищена змінна len зберігає довжину рядка, а змінна BuffLen зберігає довжину буферу пам’яті, на який посилається вказівник symb. Функція setString виконує всю роботу зі збереження рядка.
Конструктор копіювання реалізований майже однаково з конструктором перетворення, окрім того, що аргументом є посилання на об’єкт TPString.
TPString:: TPString (TPString & copy)
{
len (copy. len)
BuffLen=0;
symb=NULL;
setString (copy. symb);
}
Головне завдання деструктору-звільнити пам’ять, де зберігається рядок.
TPString:: ~TPString ()
{
delete [] symb;
}
Операція індексації реалізована 2 функціями
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) | char&TPString:: operator [] (int index) { if ( (index<0) || (index>=len)) FatalError (); return * (symb+index); } const char &TPString:: operator [] (int index) const { if ( (index<0) || (index>=len)) { FatalError (); } return symb [index]; } |
(1) даємо посилання на відповідний до індексу символ для того, щоб у нього можна було записати необхідну інформацію. Але недоліком є те, що замість присвоєння символу, ми можемо за посиланням зберегти адресу цього символа, а це може викликати помилки в роботі. Для недопущення цієї помилки використовуємо другу операцію індексації (7), котра повертає константний символ і, до того ж, є константною.
У разі спроби прочитати/записати символ за неіснуючим індексом, программа викликає функцію FatalError (), котра завершить виконання.
Перевантаження оператора писвоєння є аналогічною до конструктора копіювання, за виключенням того,що вона повертає вказівник на об’єкт, котрому присвоюється значення. Це дає можливість наступного коду:
TPString a,b,c;
· · ·
a = b = c;
Операцій додавання рядків, або конкатенація реалізовані наступним чином:
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) | TPString &TPString:: operator+= (const TPString& part) { if (BuffLen< (len+1+part. len)) { BuffLen=len+1+part. len; char *ptr=new char [BuffLen]; strcpy (ptr,symb); strcpy (ptr+len,part. symb); ptr [BuffLen-1] =0; delete [] symb; symb=ptr; } else { strcpy (symb+len,part. symb); } len+=part. len; return *this; } TPString &TPString:: operator+ (const TPString& part) { TPString temp (*this); temp+=part; return temp; } |
В (1) об’являється оператор += котрий і виконує конкатенацію. Параметром є посилання на об’єкт типу TPString. сonst гарантує незмінність об’єкту. (3) перевірка на достатність виділеної пам’яті для розміщення рядка. (4) обчислення необхідго розміру буферу. (5) видіеня необхідної пам’яті. (6) та (7) копіювання рядків до нового буферу. (8) встановлення символу кінця рядка. (9) знищення старого буферу.
Оператор + загалом об’влений у (18) також має константний параметр. У (20) створюється тимчасовий об’єкт на основі існуючого. Далі виклик += і повернення результату. Завдяки первантаженню операції = уникаємо помлок копіювання.
Функція Clear () присвоює значення рядку “”
void TPString:: Clear ()
{
len=0;
if (symb! =NULL) symb [0] ='\0';
}
Функція видалення певної кількості символів приймає два параметра: стартова позиція та кількість символів.
| (1) (2) (3) (4) (5) (6) (7) (8) | void TPString:: TPdelete (int startpos, int count) { if (startpos>=len||startpos<0||count<0) return; if (startpos+count>=len||count==0) count=len-startpos+1; int st=startpos+count; for (; st<=len; st++) symb [startpos++] =symb [st]; len=len-count; } |
Алгоритм видалення досить простий: символи з кінця рядка переписуються замість тих, що підлягають видаленню (6). Перевірки (3) та (4) реалізують коректність роботи алгоритму.
Алгоритм вставки рядка в рядок є більш складним, але подібний до операції інкременту.
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) | void TPString:: insert (TPString& part, int pos, int count) { if (pos>len) return; if (count>part. len) count=part. len; if (part. len<count||count<=0) count=part. len; if (BuffLen>=len+count+1) { for (int i=len; i>=pos; - -i) { symb [i+count] =symb [i]; } for (int i=0; i<count; i++, pos++) { symb [pos] =part. symb [i]; } } else { char *temp=new char [len+part. len+1]; strncpy (temp,symb,pos); strncpy (temp,part. symb,count); strncpy (temp,symb+pos,len-pos); delete [] symb; symb=temp; BuffLen=len+part. len+1; } len+=count; } |
Рядки (3) - (5) реалізують коректність роботи алгоритму. У рядках (7) - (24) реалізований алгоритм конкатенації, оснований на попередньому "роздвиганні" базового рядка у який виконується ставка. У (26) ми встановлюємо поточну довжину рядка.
Захищена функція
void TPString:: setString (const char* s)
{
if (BuffLen<len+1)
{
if (symb! =NULL) delete [] symb;
BuffLen=len+1;
symb=new char [BuffLen];
}
strcpy (symb,s);
}
виконує виділення необхідного об’єму буферу та копіювання у нього нове значення.
Об’ява нащадку TPStrThread від TPString має наступний вигляд:
class TPStrThread abstract: virtual public TPString
{
···
}
Ключове слово abstract говорить про те, що об’єкти класу неможна створювати, проте ми додали конструктор, що ініціалізуватиме у подальшому усю систему.
Головною відмінністю є наявність двох дружніх функцій, що є перевантаженням операцій введення/виведення.
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) (30) (31) | ostream &operator<< (ostream& out, const TPStrThread& tp) { for (int i=0; i<tp. len; i++) out<<tp. symb [i]; return out; } istream &operator>> (istream& input, TPStrThread& tp) { int i=256; int k=-1; char *temp=new char [i]; do{ k++; if (k>i) { i<<1; char * t=new char [i]; strncpy (t,temp,k); delete [] temp; temp=t; } input. get (temp [k]); }while (temp [k] ! ='\n'); temp [k] =0; if (tp. symb! =NULL) delete [] tp. symb; tp. symb=temp; tp. BuffLen=i; tp. len=strlen (temp); return input; } |
У рядку (1) перевантажується операція виведення, вона подібна до операції виведення рядка у стилі С. (5) повертає посилання на потік, що дозволяє виконувати наступну операцію:
cout << … << …;
Операція введення (8) реалізована на основі динамічного алгоритму: виділяється буфер, якщо не вистачає, то виділяється у два рази більший (у нього копіюється попередній і звільняється) і т.д. Замість множення на 2 використовуюємо швидшу операцію зсуву. Це дозволяє максимально збалансувати швидкість виконання та використання ресурсів.
Об’ява нащадку TPStrCompare від TPString має наступний вигляд:
class TPStrCompare abstract: virtual public TPString
{···}
У ньому ми перевантажимо всі операції порівняння:
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) | bool TPStrCompare:: operator! () const { if (len==0) return true; else return false; } bool TPStrCompare:: operator! = (const TPStrCompare& part) const { return (strcmp (symb,part. symb) ! =0); } bool TPStrCompare:: operator== (const TPStrCompare& part) const { return! (*this! = part); } bool TPStrCompare:: operator< (const TPStrCompare& part) const { return strcmp (symb,part. symb) <0; } bool TPStrCompare:: operator> (const TPStrCompare& part) const { return (strcmp (symb,part. symb) >0); } bool TPStrCompare:: operator<= (const TPStrCompare& part) const { return! (*this> part); } bool TPStrCompare:: operator>= (const TPStrCompare& part) const { return! (*this< part); } |
У рядках (1), (6), (10), (14), (16), (18), (22), (26) об’являються оператори порівнняння. Кожен з них є константною функцією та приймає константні аргументи, що гарантує захищеність, та щожливість використання, коли об’єкт був об’явлений константно.
У рядках (16) та (20) викорисовубться функіії порівняння у стилі С. Останні функції порівняння (крім (1)) створювалися на основі заданих.
Розробка результуючого класу пов’язана з успадкуванням від двох абстрактних. Має наступну об’яву:
class clsString: public TPStrThread, public TPStrCompare
{ ··· }
Зауважимо, що базові класи не є віртуальними і немає наслідування від базового класу (як це зазначено у теоретичній частині). Виклики конструкторів будуть проходити так:
Конструктор за замовчуванням TPString
Конструктор за замовчуванням TPStrThread або TPStrCompare
Конструктор за замовчуванням TPStrCompare або TPStrThread
Конструктор clsString
Пункти 2 і 3 рівносильні і їх порядок залежить від компілятору (хоча в стандарті сказано, що вони викликаються в порядку об’яви).
В звязку з тим, що конструктори та операції присвоєння не наслідубться потрібно їх створювати зоново. Конструктори копіювання та перетворення аналогічні TPString. Розглянемо добавлені конструктори.
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) | clsString:: clsString (const long l) { char s [_CVTBUFSIZE]; if (_i64toa_s (l,s,15,10) ==EINVAL) code=1; else code=0; len=strlen (s); BuffLen=0; symb=NULL; setString (s); } clsString:: clsString (const double d, int pers) { char buf [_CVTBUFSIZE]; if (_gcvt (d,pers,buf) ! =0) code=1; else code=0; len=strlen (buf); BuffLen=0; symb=NULL; setString (buf); } |
У рядках (1) та (11) також об’явлені конструктори перетворення.
Цікавим є виділення пам’яті для тимчасового буферу, використовуючи _CVTBUFSIZE.
Згідно документації вона забезпечує саме той розмір, який необхідно для розміщення будь-якого число у строковому форматі, не залежно від системи (3) та (13).
Функція i64toa_s (4) забезпечує перетворення 64 бітного цілого на строку і у разі помилки повертає EINVAL.
Функція _gcvt (14) перетворює дійсне число у рідок символів і у разі помилки повертає її значення. (6) - (9) та (15) - (18) аналогічні розлянутим раніше.
Оператор () повертає підстроку але за типом класу:
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) | clsString& clsString:: operator () (int index, int subLen) { if (index<0 ||index>=len|| index+subLen>=len) return clsString (""); char *tempstr=new char [subLen+1]; if (subLen==0) subLen=len-index; strncpy (tempstr,symb+index,subLen); tempstr [subLen] ='\0'; clsString temp (tempstr); delete [] tempstr; return temp; } |
У (3) забзпечення коректності роботи алгоритму. (4) виділення тимчасовогу буферу.
У рядку (6) - копіювання підрядка, котрий у (8) передається у якості аргументу.
Далі (9) знищення тимчасового буферу та (10) повертання результату.
Функція пошуку першого входження реалізована за надійним але не найшвидшим алгоритмом О (n) =n*m, n-довжина базового рядка, а m-довжина рядка еквівалент якого шукаємо.
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) | int clsString:: find (const clsString& comp, int pos) { bool Notequal=1; if (comp. len>pos+this->len) return - 1; int fin=this->len-comp. len; for (; (pos<=fin) &&Notequal; pos++) { int k=0; for (int j=pos; k<comp. len; k++,j++) if (this->symb [j] ! =comp. symb [k]) break; if (k==comp. len) Notequal=0; } if (Notequal) return - 1; else return pos; } |
Флагова змінна Notequal (3) слугує для визначення: чи було знайдене вхождения. Змінна fin (5) вказує на кількість символім починаючи з яких необхідно виконати порівняння. (10) вийти з вложенного циклу, якщо знайдені неодинакові символи.
2.3 Тестування
Результат проведення тестування:
| (Т1) (Т2) (Т3) (Т4) (Т5) (Т6) (Т7) (Т8) (Т9) (Т10) (Т11) (Т12) (Т13) (Т14) (Т15) (Т16) (Т17) (Т18) (Т19) (Т20) (Т21) (Т22) (Т23) (Т24) (Т25) (Т26) (Т27) (Т28) (Т29) (Т30) (Т31) (Т32) (Т33) (Т34) (Т35) (Т36) (Т37) (Т38) (Т39) | This program will test my work This is a small driver Testing in process This is a small driver Enter string Enter string Good day! This is a very good day! I have already done my work! Good day! This is a very good day! I have already done my work! s1 is "Testing in process" and s2 is "This is a small driver" The results of comparing is: s2==s1 yields false s2! =s1 yields true s2>s1 yields true s2<s1 yields false s2<=s1 yields false s2>=s1 yields true s1 += s2 yields s1 = Testing in processThis is a small driver s1 after s1 [0] = 't' and s1 [1] ='E' tEsting in processThis is a small driver find and delete in s1 s2 tEsting in process ********************************************************** s1 is "112211221122" and s2 is "334433443344334"Insert to s1 5 symbols from s2. Start position 0: 33443112211221122 Insert to s1 5 symbols from s2. Start position 5: 11221334431221122 Insert to s1 5 symbols from s2. Start position end of s1: 11221122112233443 2007 12.3456789012 Для продолжения нажмите любую клавишу... |
Тестування об’яви змінних, тобто конструкторів:
| (1) (2) (3) (4) (5) (6) (7) | clsString* temp=new clsString ("This program will test my work"); cout <<*temp<<endl; *temp= (clsString)"This is a small driver"; clsString test1 ("Testing in process"); clsString test2; clsString test3 (*temp); cout<<*temp<<endl<<test1<<endl<<test2<<endl<<test3; |
Создамо динамічний об’єкт (1) присвоївши значення "This program will test my work". Буде викликаний конструктор преведення типів. Перевіримо отримане значення (2), вивівши його в потік (чим і почнемо тестуваня введення/виведення). Далі виконаємо явне приведення типів (3), а також перевіримо оператор присвоєння. Крім того в покроковому режимі перевіримо роботу деструктора. Варіант створення статичної змінної (4) з початковим значенням, а із значенням за замовчуванням (5). Створення об’єкту на основі конструктора копіювання у рядку (6). Створені об’єкти у рядках (3) - (6) виведемо в потік (7). Результати роботи рядкі (1) - (7) є рядки на єкрані (Т1) - (Т5).
Далі протестуємо оператор введення.
| (1) (2) (3) (4) (5) (6) | cout<<"\nEnter string"<<endl; cin>>test2; cout<<test2<<endl; cout<<"Enter string"<<endl; cin>>test2; cout<<test2<<endl; |
У рядках (1) та (3) попросимо ввести рядок символів, що закінчується оператором переходу на новий рядок. Далі (2) та (4) вводимо ці рядки, та відразу ж показуємо введене. Має сенс ввести порожню строку, а потім непорожню. Результати у рядках (6) - (11).
Протестуємо оператори порівняння:
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) | cout<<"\ns1 is \""<<test1<<"\" and s2 is \""<< test3<<"\"" <<"\n\nThe results of comparing is: " <<"\ns2==s1 yields " << (test3==test1?"true": "false") <<"\ns2! =s1 yields " << (test3! =test1?"true": "false") <<"\ns2>s1 yields " << (test3>test1?"true": "false") <<"\ns2<s1 yields " << (test3<test1?"true": "false") <<"\ns2<=s1 yields " << (test3<=test1?"true": "false") <<"\ns2>=s1 yields " << (test3>=test1?"true": "false") <<endl; |
У рядку (1) вказуємо дві строки, які ми будемо порівнювати. У рядках (3), (5), (7), (9), (11), (13) ми говоримо користувачу, яку операцію будемо тестувати, а у наступномі виводимо результат відповідного тестування, використовуючи тернарну операцію. Результати (Т12) - (Т20).
Наступним етапом тестування стане операція конкатенації, процес її тестування подібний до операції тестування (Т23):
cout << "\n\ns1 += s2 yields s1 = ";
test1 += test3; // test overloaded concatenation
cout << test1<<endl;
Операція індексації матиме 2 тести: зміна 0 символу (відлік символів починається з 0), будь-якого іншого, наприклад 1, бо вказівник на рядок-вказівник на перший символ, а далі перевірка операції індексації (Т24) - (Т25):
test1 [0] ='t';
test1 [1] ='E';
cout<<"s1 after s1 [0] = 't' and s1 [1] ='E'"<<endl;
cout<<test1<<endl;
Функцію пошуку об’єднаємо з функцією видалення рядка:
| (1) (2) (3) | int pos=test1. find (test3); test1. TPdelete (pos,test3. lenght ()); cout<<test1<<endl; |
У змінну pos отримаємо позицію входження, потім (2) з цієї позиції видалимо весь рядок test3, використовуючи функцію визначення довжини рядка. Та виведемо (3) результат видалення (Т26) - (Т27).
Тестування операцій вставки більш складне:
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) | test1="112211221122"; test3="334433443344334"; cout<<"\ns1 is \""<<test1<<"\" and s2 is \""<< test3<<"\""; cout<<"Insert to s1 5 symbols from s2. Start position 0: "<<endl; test1. insert (test3,0,5); cout<<test1<<endl; test1="112211221122"; test3="334433443344334"; cout<<"Insert to s1 5 symbols from s2. Start position 5: "<<endl; test1. insert (test3,5,5); cout<<test1<<endl; test1="112211221122"; test3="334433443344334"; cout<<"Insert to s1 5 symbols from s2. Start position end of s1: "<<endl; test1. insert (test3,test1. lenght (),5); cout<<test1<<endl; |
Для полегшення перевірки вставки задамо початкові строки (1) - (2), (7) - (8), та (12) - (13).
Вставка в початок рядка (5), між 5 та 6 символами (10) та в кінець (13). Результати приведені у рядках (Т30) - (Т36).
На останок тестування конструкторів перетворення з числа до строки. Так як вони основані лице на стандартних операціях строк у стилі С, достатньо одного тесту на кожний:
| (1) (2) (3) (4) (5) (6) | temp=new clsString ( (long) 2007); cout<<*temp<<endl; temp->~clsString (); temp=new clsString (-12.34567890123); cout<<*temp<<endl; temp->~clsString (); |
У (1) та (4) створення об’єкту та передача значення. Замітимо явне приведення типу у (1), якщо цьго невиконати, то компілятор видасть помилку "error C2668: 'clsString:: clsString': ambiguous call to overloaded function". Це пов’язане з тим, що компілятор неявно не розрізняє ціле та дійсне числа, тому виника б неоднозначність. Ми використовуємо динамічні об’єкти, а отже виклик деструкторів (3) та (6) обов’язковий. Результат (2) та (3) є рядки (Т37) та (Т38).
Висновки
В ході виконання курсової роботи були отримані наступні результати.
Розроблено клас clsString, який призначений для розв'язку задачі обробки рядків.
Розроблений клас включає 4 компонентів-даних та 29 компонентів-методів, серед яких 2 є захищеними, 29 можуть успадковуватися, а 27 є загальнодоступними. Клас включає 4 конструктори, 1 деструктор, 1 віртуальних функцій, надає можливості з використання найменувань стандартних операцій для виконання введення/виведення в потік, порівняння рядків.
Розроблений клас є похідним від класів TPStrThread та TPStrCompare, котрі є похідними від класу TPString.
Особливостями розробленого класу є можливість ініціалізації, отримуючи дійсне чи ціле число, та пошук першого входження з вказаної позиції підстроки.
Результати тестування підтвердили працездатність і ефективність використання об'єктів, створюваних на основі розробленого класу.
Розроблене програмне забезпечення функціонує під керуванням операційної системи Windows.
Література
1. MSDN
2. Pohl, Ira C++ by Dissection. Addison-Winsley: New York, 2002.520p
3. Stroustrup, Bjarne The C++ Programing Language. Addison-Winsley: New York, 1997.912p
4. Дейтел Х.М. Дейтел П. Дж. Как программировать на С++. М.: Бином, 2005.1244с
5. Липпман С.Б. С++ для начинающих. М.: Питер, 2002.1194с
Додатки
Додаток А
Код файлу "TPstr. h", з об’явою класів.
#ifndef TPSTR_H
#define TPSTR_H
#include <iostream>
using std:: ostream;
using std:: istream;
class TPString
{
public:
// TPString ();
TPString (const char * = "");
TPString (TPString&);
~TPString ();
char&operator [] (int);
const char &operator [] (int) const;
TPString &operator= (TPString&);
TPString &operator+= (const TPString&);
TPString &operator+ (const TPString&);
void Clear ();
void TPdelete (int startpos, int count);
void insert (TPString&, int pos, int count);
int lenght () const;
virtual int ErrorCode () {return 0; }
protected:
int BuffLen;
int len;
char * symb;
void FatalError () const;
void setString (const char*);
};
class TPStrThread abstract: virtual public TPString
{
friend ostream &operator<< (ostream&, const TPStrThread&);
friend istream &operator>> (istream&, TPStrThread&);
public:
char* GetStr (); // повертає копію рядка у стилі С
char* GetStr (int stpos, int count); // копія підрядка у стилі С
};
class TPStrCompare abstract: virtual public TPString
{
public:
bool operator! () const; // Чи порожня строка
bool operator! = (const TPStrCompare&) const;
bool operator== (const TPStrCompare&) const;
bool operator< (const TPStrCompare&) const;
bool operator> (const TPStrCompare&) const;
bool operator<= (const TPStrCompare&) const;
bool operator>= (const TPStrCompare&) const;
};
class clsString: public TPStrThread, public TPStrCompare
{
public:
clsString (const char * = "");
clsString (const long);
clsString (const double, int pers = 12);
clsString (clsString&);
~clsString () {}
clsString &operator () (int, int);
clsString & operator= (const clsString&);
int ErrorCode () {return code; }
int find (const clsString&, int pos =0);
private:
int code;
};
#endif
Додаток Б
Код файлу "TPstr. cpp", з описом методів класів.
#include "TPstr. h"
#include <errno. h>
// class TPString
TPString:: TPString (const char *s)
{
len=strlen (s);
BuffLen=0;
symb=NULL;
setString (s);
}
TPString:: TPString (TPString & copy)
{
len=copy. len;
BuffLen=0;
symb=NULL;
setString (copy. symb);
}
TPString:: ~TPString ()
{
delete [] symb;
}
char&TPString:: operator [] (int index)
{
if ( (index<0) || (index>=len)) FatalError ();
return * (symb+index);
}
const char &TPString:: operator [] (int index) const
{
if ( (index<0) || (index>=len))
{
FatalError ();
}
return symb [index];
}
TPString &TPString:: operator= (TPString& copy)
{
len=copy. len;
setString (copy. symb);
return *this;
}
TPString &TPString:: operator+= (const TPString& part)
{
if (BuffLen< (len+1+part. len)) {
BuffLen=len+1+part. len;
char *ptr=new char [BuffLen];
strcpy (ptr,symb);
strcpy (ptr+len,part. symb);
ptr [BuffLen-1] =0;
delete [] symb;
symb=ptr;
} else {
strcpy (symb+len,part. symb);
}
len+=part. len;
return *this;
}
TPString &TPString:: operator+ (const TPString& part)
{
TPString temp (*this);
temp+=part;
return temp;
}
void TPString:: Clear ()
{
len=0;
if (symb! =NULL) symb [0] ='\0';
}
void TPString:: TPdelete (int startpos, int count)
{
if (startpos>=len||startpos<0||count<0) return;
if (startpos+count>=len||count==0) count=len-startpos+1;
int st=startpos+count;
for (; st<=len; st++) symb [startpos++] =symb [st];
len=len-count;
}
void TPString:: insert (TPString& part, int pos, int count)
{
if (pos>len) return;
if (count>part. len) count=part. len;
if (part. len<count||count<=0) count=part. len;
if (BuffLen>=len+count+1) {
for (int i=len; i>=pos; - -i)
{
symb [i+count] =symb [i];
}
for (int i=0; i<count; i++, pos++)
{
symb [pos] =part. symb [i];
}
// symb [pos] ='\0';
} else {
char *temp=new char [len+part. len+1];
strncpy (temp,symb,pos);
strncpy (temp,part. symb,count);
strncpy (temp,symb+pos,len-pos);
delete [] symb;
symb=temp;
BuffLen=len+part. len+1;
}
len+=count;
}
int TPString:: lenght () const
{
return len;
}
void TPString:: setString (const char* s)
{
if (BuffLen<len+1)
{
if (symb! =NULL) delete [] symb;
BuffLen=len+1;
symb=new char [BuffLen];
}
strcpy (symb,s);
}
void TPString:: FatalError () const
{
exit (1); }
// class TPStrThread
ostream &operator<< (ostream& out, const TPStrThread& tp)
{
for (int i=0; i<tp. len; i++)
out<<tp. symb [i];
return out;
}
istream &operator>> (istream& input, TPStrThread& tp)
{
int i=256;
int k=-1;
char *temp=new char [i];
do{
k++;
if (k>i) {
i<<1;
char * t=new char [i];
strncpy (t,temp,k);
delete [] temp;
temp=t;
}
input. get (temp [k]);
}while (temp [k] ! ='\n');
temp [k] =0;
if (tp. symb! =NULL) delete [] tp. symb;
tp. symb=temp;
tp. BuffLen=i;
tp. len=strlen (temp);
return input;
}
// TPStrThread &operator= (TPStrThread&);
char* TPStrThread:: GetStr ()
{
char *temp=new char [len+1];
strcpy (temp,symb);
return temp;
}
char* TPStrThread:: GetStr (int stpos, int count)
{
if (stpos<0|| stpos>=len||count<=0||count+stpos>=len) return NULL;
char *temp=new char [count+1];
strncpy (temp,symb+stpos,count);
temp [count] ='\0';
return temp;
}
// class TPStrCompare
bool TPStrCompare:: operator! () const
{
if (len==0) return true; else return false;
}
bool TPStrCompare:: operator! = (const TPStrCompare& part) const
{
return (strcmp (symb,part. symb) ! =0);
}
bool TPStrCompare:: operator== (const TPStrCompare& part) const
{
return! (*this! = part);
}
bool TPStrCompare:: operator< (const TPStrCompare& part) const
{
return strcmp (symb,part. symb) <0;
}
bool TPStrCompare:: operator> (const TPStrCompare& part) const
{
return (strcmp (symb,part. symb) >0);
}
bool TPStrCompare:: operator<= (const TPStrCompare& part) const
{
return! (*this> part);
}
bool TPStrCompare:: operator>= (const TPStrCompare& part) const
{
return! (*this< part);
}
// class clsString
clsString:: clsString (const char * s)
{
len=strlen (s);
BuffLen=0;
symb=NULL;
setString (s);
}
clsString:: clsString (const long l)
{
char s [_CVTBUFSIZE];
if (_i64toa_s (l,s,15,10) ==EINVAL) code=1;
else code=0;
len=strlen (s);
BuffLen=0;
symb=NULL;
setString (s);
}
clsString:: clsString (const double d, int pers)
{
char buf [_CVTBUFSIZE];
if (_gcvt (d,pers,buf) ! =0) code=1; else code=0;
len=strlen (buf);
BuffLen=0;
symb=NULL;
setString (buf);
}
clsString:: clsString (clsString& s)
{
len=s. len;
setString (s. symb);
}
clsString & clsString:: operator= (const clsString& copy)
{
len=copy. len;
setString (copy. symb);
return *this;
}
clsString& clsString:: operator () (int index, int subLen)
{
if (index<0 ||index>=len|| index+subLen>=len) return clsString ("");
char *tempstr=new char [subLen+1];
if (subLen==0) subLen=len-index;
strncpy (tempstr,symb+index,subLen);
tempstr [subLen] ='\0';
clsString temp (tempstr);
delete [] tempstr;
return temp;
}
int clsString:: find (const clsString& comp, int pos)
{
bool Notequal=1;
if (comp. len>pos+this->len) return - 1;
int fin=this->len-comp. len;
for (; (pos<=fin) &&Notequal; pos++)
{
int k=0;
for (int j=pos; k<comp. len; k++,j++)
if (this->symb [j] ! =comp. symb [k]) break;
if (k==comp. len) Notequal=0;
}
if (Notequal) return - 1;
else return pos;
}
Додаток С
Код файлу "driver. cpp", з драйвером тестування.
#include <iostream>
#include "TPstr. h"
using namespace std;
int main ()
{
clsString* temp=new clsString ("This program will test my work");
cout <<*temp<<endl;
*temp= (clsString)"This is a small driver";
clsString test1 ("Testing in process");
clsString test2;
clsString test3 (*temp);
cout<<*temp<<endl<<test1<<endl<<test2<<endl<<test3;
cout<<"\nEnter string"<<endl;
cin>>test2;
cout<<test2<<endl;
cout<<"Enter string"<<endl;
cin>>test2;
cout<<test2<<endl;
cout<<"s1 is \""<<test1<<"\" and s2 is \""<< test3<<"\""
<<"\n\nThe results of comparing is: "
<<"\ns2==s1 yields "
<< (test3==test1?"true": "false")
<<"\ns2! =s1 yields "
<< (test3! =test1?"true": "false")
<<"\ns2>s1 yields "
<< (test3>test1?"true": "false")
<<"\ns2<s1 yields "
<< (test3<test1?"true": "false")
<<"\ns2<=s1 yields "
<< (test3<=test1?"true": "false")
<<"\ns2>=s1 yields "
<< (test3>=test1?"true": "false") <<endl;
cout << "\n\ns1 += s2 yields s1 = ";
test1 += test3; // test overloaded concatenation
cout << test1<<endl;
test1 [0] ='t';
test1 [1] ='E';
cout<<"s1 after s1 [0] = 't' and s1 [1] ='E'"<<endl;
cout<<test1<<endl;
cout<<"find and delete in s1 s2"<<endl;
int pos=test1. find (test3);
test1. TPdelete (pos,test3. lenght ());
cout<<test1<<endl;
cout<<"**********************************************************\n";
test1="112211221122";
test3="334433443344334";
cout<<"\ns1 is \""<<test1<<"\" and s2 is \""<< test3<<"\"";
cout<<"Insert to s1 5 symbols from s2. Start position 0: "<<endl;
test1. insert (test3,0,5);
cout<<test1<<endl;
test1="112211221122";
test3="334433443344334";
cout<<"Insert to s1 5 symbols from s2. Start position 5: "<<endl;
test1. insert (test3,5,5);
cout<<test1<<endl;
test1="112211221122";
test3="334433443344334";
cout<<"Insert to s1 5 symbols from s2. Start position end of s1: "<<endl;
test1. insert (test3,test1. lenght (),5);
cout<<test1<<endl;
temp->~clsString ();
temp=new clsString ( (long) 2007);
cout<<*temp<<endl;
temp->~clsString ();
temp=new clsString (-12.34567890123);
cout<<*temp<<endl;
temp->~clsString ();
return 0;
}
Похожие работы
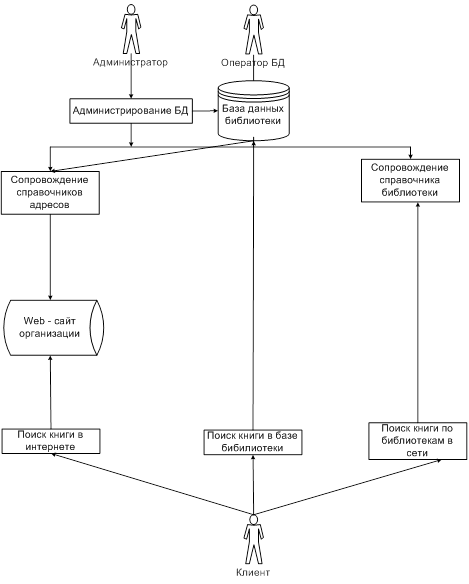
... адміністратор локальної мережі, який є у штатному розкладі і займається усіма проблемами, зв’язаними з комп’ютерами. Рисунок 1.2 – Функціональна схема автоматизованого робочого місця науково-технічної бібліотеки Метою розробки АРМ є - скорочення часу обробки оперативних даних, зменшення кількості помилок при обробці інформації. Основні функціональні вимоги до розроблюваного автоматизованого ...
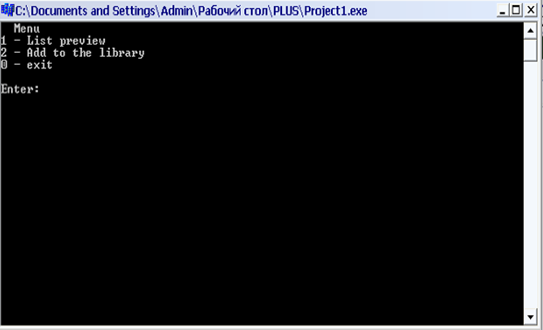
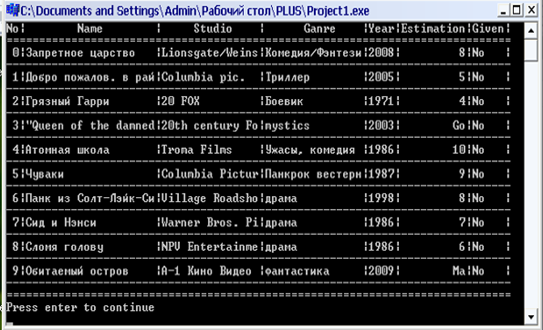
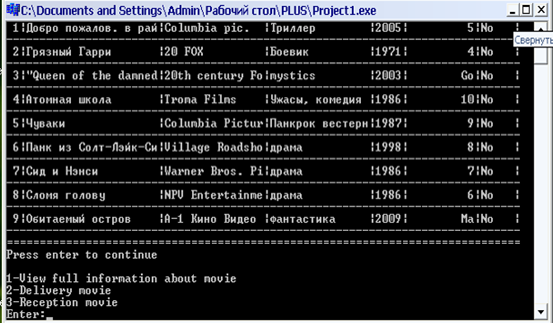
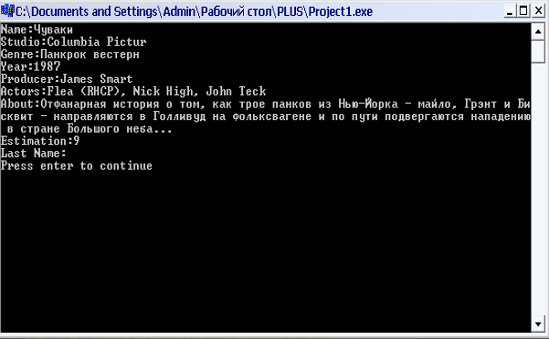
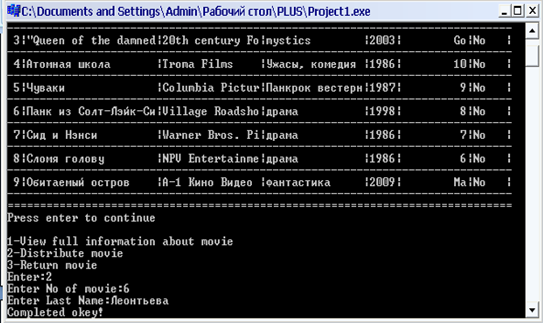
... функцією з чітко певними вхідними і виходять даними. Основна мета використовування модуля – можливість його повторного використання для вирішення різних задач. 2 РОЗРОБКА РІШЕННЯ ЗАДАЧІ СТВОРЕННЯ БАЗИ ВІДЕОФІЛЬМІВ 2.1 Бази даних 2.1.1 Основні положення та моделі БД Взагалі технологія баз даних як самостійна гілка розвитку інформатики з’явилася порівняно недавно: початок досліджень в ...
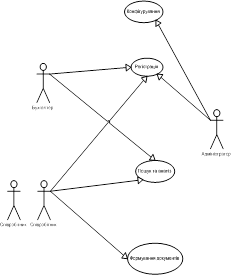
... оформления : ДСТУ 3008–95. – Киев: Госстандарт Украины, 1995. – 38 с. – (Государственный стандарт Украины). Додаток До пояснювальної записки дипломного проекту "Розробка автоматизованого робочого місця управління замовленнями у малому бізнесі (ПП "Сігма")" Вихідний код програми Public Class frmГлавная Inherits System.Windows.Forms.Form Private Готов As Boolean = False Private ...
гового клієнта. Примітка Такий підхід особливо характерний для Web‑серверу Microsoft Internet Information Services і додатків, оброблювальних запити в його середовищі. Якщо ви створюєте додатки ISAPI на Delphi, то можете використовувати пулінг потоків, підключивши до проекту модуль ISAPIThreadPool.pas. Якщо ви хочете запозичити ідеї для інших цілей, ознайомтеся з вмістом цього модуля. ...
0 комментариев