Шини (Industrial Standard Architecture)
Шина, як відомо, представляє із себе, власне, набір проводів (ліній), що з'єднує різні компоненти комп'ютера для підведення до них живлення й обміну даними. У "мінімальній комплектації" шина має три типи ліній:
· лінії керування;
· лінії адресації;
· лінії даних.
Пристрою, підключені до шини, поділяються на двох основних категорій - bus masters і bus slaves. Bus masters - це пристрою, здатні керувати роботою шини, т. ч. ініціювати запис/читання і т.д. Bus slaves - відповідно, пристрою, що можуть тільки відповідати на запити. Правда, є ще "інтелектуальні слуги" (intelligent slaves), але ми їх поки для ясності замнемо. Ну от, власне, і усе, що потрібно знати про шини для того, щоб зрозуміти, про що піде мова далі.
Компанія IBM у 1981 представила нову шину для використання в комп'ютерах серії PC/XT. Шина була вкрай проста по дизайні, містила 53 сигнальні лінії і 8 ліній харчування і являла собою синхронну 8-бітну шину з контролем парності і дворівневих переривань (trigger-edge interrupts), при використанні яких пристрою запитують переривання, змінюючи стан лінії відповідного IRQ з 0 на 1 або назад. Така організація запитів переривань дозволяє використовувати кожне переривання тільки одному пристроєві. Крім того, шина не підтримувала додаткових bus masters, і єдиними пристроями, що керують шиною, минулого процесор і контролер DMA на материнській платі.
62-контактний слот (див. таблицю 1) уключав 8 ліній даних, 20 ліній адреси (А0-А19), 6 ліній запиту переривань (IRQ2-IRQ7). Таким чином, обсяг пам'яті, що адресується, складав 1 Мбайт, і при частоті шини 4.77 Мгц пропускна здатність досягала 1.2 Мбайта/хв.
Забавно, що IBM не опублікувала повного опису шини з тимчасовими діаграмами сигналів на лініях даних і адреси, тому першим розроблювачам плат розширення довелося неабияк потрудитися.
Недоліки шини, що випливають із простоти конструкції, очевидні. Тому для використання в комп'ютерах IBM-AT ('Advanced Technology') у 1984 році була представлена нова версія шини, згодом названої ISA. Зберігаючи сумісність зі старими 8-бітними платами розширення, нова версія шини володіла поруч істотних переваг, як то:
· додавання 8 ліній даних дозволило вести 16-бітний обмін даними;
· додавання 4 ліній адреси дозволило збільшити максимальний розмір пам'яті, що адресується, до 16 МВ;
· були додані 5 додаткових trigger-edged ліній IRQ;
· була реалізована часткова підтримка додаткових bus masters;
· частота шини була збільшена до 8 MHz;
· пропускна здатність досягла 5.3 МВ/хв.
Реалізація bus mastering не була особливо вдалої, оскільки, наприклад, запит на звільнення шини ('Bus hang-off') до поточного bus master оброблявся кілька тактів, до того ж кожен master повинний був періодично звільняти шину, щоб дати можливість провести відновлення пам'яті (memory refresh), або сам проводити відновлення. Для забезпечення зворотної сумісності з 8-бітними платами більшість нових можливостей було реалізовано шляхом додавання нових ліній (див. таблицю 2). Тому що АТ був побудований на основі процесора Intel 80286, що був істотно швидше, ніж 8088, довелося додати генератор станів чекання (wait-state generator). Для обходу цього генератора використовується вільна лінія (контакт У8 NOWS-'No Wait State') вихідної 8-бітної шини. При установці цієї лінії в 0 такти чекання пропускаються. Використання в якості NOWS лінії вихідної шини дозволяло розроблювачам робити як 16-бітні, так і 8-бітні "швидкі" плати.
Таблиця 1. Призначення контактів рознімання 8-розрядної шини ISA
Контакт | Назва сигналу | Контакт | Назва сигналу |
| B1 | Ground | A1 | I/O Channel Check |
| B2 | Reset Driver | A2 | Data7 |
| B3 | +5V | A3 | Data6 |
| B4 | IRQ2 | A4 | Data5 |
| B5 | -5V | A5 | Data4 |
| B6 | DMA Request 2 | A6 | Data3 |
| B7 | -12V | A7 | Data2 |
| B8 | J8/NOWS[1] | A8 | Data1 |
| B9 | +12V | A9 | Data0 |
| B10 | Ground | A10 | I/O Channel Ready |
| B11 | Memory Write | A11 | Address Enable |
| B12 | Memory Read | A12 | Address19 |
| B13 | I/O Write | A13 | Address18 |
| B14 | I/O Read | A14 | Address17 |
| B15 | DMA Acknoledge3 | A15 | Address16 |
| B16 | DMA Request3 | A16 | Address15 |
| B17 | DMA Acknoledge1 | A17 | Address14 |
| B18 | DMA Request1 | A18 | Address13 |
| B19 | Refresh | A19 | Address12 |
| B20 | Clock | A20 | Address11 |
| B21 | IRQ7 | A21 | Address10 |
| B22 | IRQ6 | A22 | Address9 |
| B23 | IRQ5 | A23 | Address8 |
| B24 | IRQ4 | A24 | Address7 |
| B25 | IRQ3 | A25 | Address6 |
| B26 | DMA Acknoledge2 | A26 | Address5 |
| B27 | Terminal Count | A27 | Address4 |
| B28 | Address Latch Enable | A28 | Address3 |
| B29 | +5V | A29 | Address2 |
| B30 | Oscillator | A30 | Address1 |
| B31 | Ground | A31 | Address0 |
Новий слот містив 4 нових адресні лінії (LA20-LA23) і копії трьох молодших адресних ліній (LA17-LA19). Необхідність у такому дублюванні виникла через те, що адресні лінії ХТ були лініями з затримкою (latched lines), і ці затримки приводили до зниження швидкодії периферійних пристроїв. Використання дублюючого набору адресних ліній дозволяло 16-бітній карті на початку циклу визначити, що до неї звертаються, і послати сигнал про те, що вона може здійснювати 16-бітний обмін. Насправді, це ключовий момент у забезпеченні зворотної сумісності. Якщо процесор намагається здійснити 16-бітний доступ до плати, він зможе це зробити тільки в тому випадку, якщо одержить від неї відповідний відгук IO16. У противному випадку чипсет ініціює замість одного 16-бітного циклу два 8-бітних. І усі б було гарно, але адресних ліній без затримки лише 7, тому плати, що використовують діапазон адрес менший, чим 128Кбайт, не могли визначити, де знаходиться передана адреса в їхньому діапазоні адрес, і, відповідно, послати відгук IO16. Таким чином, багато плат, у тому числі плати EMS, не могли використовувати 16-бітний обмін
Таблиця 2. Призначення контактів рознімання 16-розрядної шини ISA
| Контакт | Назва сигналу | Контакт | Назва сигналу |
| B1 | Ground | A1 | I/O Channel Check |
| B2 | Reset Driver | A2 | Data7 |
| B3 | +5V | A3 | Data6 |
| B4 | IRQ2 | A4 | Data5 |
| B5 | -5V | A5 | Data4 |
| B6 | DMA Request 2 | A6 | Data3 |
| B7 | -12V | A7 | Data2 |
| B8 | No Wait States | A8 | Data1 |
| B9 | +12V | A9 | Data0 |
| B10 | Ground | A10 | I/O Channel Ready |
| B11 | Memory Write | A11 | Address Enable |
| B12 | Memory Read | A12 | Address19 |
| B13 | I/O Write | A13 | Address18 |
| B14 | I/O Read | A14 | Address17 |
| B15 | DMA Acknoledge3 | A15 | Address16 |
| B16 | DMA Request3 | A16 | Address15 |
| B17 | DMA Acknoledge1 | A17 | Address14 |
| B18 | DMA Request1 | A18 | Address13 |
| B19 | Refresh | A19 | Address12 |
| B20 | Clock | A20 | Address11 |
| B21 | IRQ7 | A21 | Address10 |
| B22 | IRQ6 | A22 | Address9 |
| B23 | IRQ5 | A23 | Address8 |
| B24 | IRQ4 | A24 | Address7 |
| B25 | IRQ3 | A25 | Address6 |
| B26 | DMA Acknoledge2 | A26 | Address5 |
| B27 | Terminal Count | A27 | Address4 |
| B28 | Address Latch Enable | A28 | Address3 |
| B29 | +5V | A29 | Address2 |
| B30 | Oscillator | A30 | Address1 |
| B31 | Ground | A31 | Address0 |
| Ключ | Ключ | ||
| D1 | Memory Access 16 bit | C1 | System Bus High |
| D2 | I/O 16 bit | C2 | Latch Address 23 |
| D3 | IRQ10 | C3 | Latch Address 22 |
| D4 | IRQ11 | C4 | Latch Address 21 |
| D5 | IRQ12 | C5 | Latch Address 20 |
| D6 | IRQ15 | C6 | Latch Address 19 |
| D7 | IRQ14 | C7 | Latch Address 18 |
| D8 | DMA Acknoledge0 | C8 | Latch Address 17 |
| D9 | DMA Request1 | C9 | Memory Read |
| D10 | DMA Acknoledge5 | C10 | Memory Write |
| D11 | DMA Request5 | C11 | Data8 |
| D12 | DMA Acknoledge6 | C12 | Data9 |
| D13 | DMA Request6 | C13 | Data10 |
| D14 | DMA Acknoledge7 | C14 | Data11 |
| D15 | DMA Request7 | C15 | Data12 |
| D16 | +5V | C16 | Data13 |
| D17 | Master 16 bit | C17 | Data14 |
| D18 | Ground | C18 | Data15 |
Незважаючи на відсутність офіційного стандарту і технічних "ізюминок" шина ISA перевершувала потреби середнього користувача зразка 1984 року, а "засилля" IBM AT на ринку масових комп'ютерів привело до того, що виробники плат розширення і клонів AT прийняли ISA за стандарт. Така популярність шини привела до того, що слоти ISA дотепер присутні на всіх системних платах, і плати ISA до цих виробляються. Правда, Microsoft у специфікації PC99 передбачає відмовлення від ISA, але, як говориться, до цього потрібно ще дожити.
Шина EISA (Extended Industry Standard Architecture)
Шина EISA з'явилася "асиметричною відповіддю" виробників клонів РС на спробу IBM поставити ринок під свій контроль. У вересні 1988 року Compaq, підтриманий "бандою дев'яти" - Wyse, AST Research, Tandy, власне Compaq, Hewlett-Packard, Zenith, Olivetti, NEC і Epson - представив 32-розрядне розширення шини ISA з повною зворотною сумісністю. Основні характеристики нової шини були наступними:
· 32-розрядна передача даних;
· максимальна пропускна здатність - 33 МВ/хв;
· 32-розрядна адресація пам'яті дозволяла адресувати до 4 GB (як і в розширенні ISA, нові адресні лінії були без затримки);
· підтримка multiply bus master;
· можливість завдання рівня дворівневого (edge-triggered) переривання (що дозволяло декільком пристроям використовувати одне переривання, як і у випадку багаторівневого (level-triggered) переривання);
· автонастрій плат розширення;
Як і у випадку 16-розрядного розширення, нові можливості забезпечувалися шляхом додавання нових ліній. Оскільки далі подовжувати рознімання ISA було нікуди, розроблювачі знайшли оригінальне рішення: нові контакти були розміщені між контактами шини ISA і не були доведені до краю рознімання. Спеціальна система виступів на розніманні і щілин у EISA-картах дозволяла їм глибше заходити в рознімання і приєднуватися до нових контактів. (Правда, затверджують, що при великому бажанні можна запхнути і ISA-карту так, щоб вона замкнула EISA-контакти. Не знаю, не пробував, тому що великого досвіду спілкування з EISA у мене немає: маленький був ще). Оскільки на даний момент шина EISA практично вимерла, приводити значення контактів рознімання не має змісту. Варто відзначити лише дві нових сигнальних лінії - EX32 і EX16, що визначали, що bus slave підтримує відповідно 32- і 16-розрядний цикл EISA. Якщо жоден з цих сигналів не був отриманий на початку циклу шини, виконувався цикл ISA.
Важливою особливістю шини була можливість для будь-якого bus master звертатися до будь-якого пристрою пам'яті або периферійному пристроєві, навіть якщо вони мали різні розряди шини. Говорячи про повну зворотну сумісність з ISA, слід зазначити, що ISA-карти, природно, не підтримували поділ переривань, навіть будучи вставленими в EISA-коннектор. Що стосується підтримки multiply bus master, те вона являла собою поліпшену і доповнену версію такої для ISA. Також були присутні чотири рівні пріоритету:
1. схеми відновлення пам'яті;
2. DMA;
3. процесор;
4. адаптери шини
і арбітр шини EISA - периферійний контролер (ISP - Integrated System Peripheral) - "стежив за порядком". Крім цього, було в наявності ще один пристрій - Intel's Bus Master Interface Chip (BMIC), що стежило за тим, щоб master "не засиджувався" на шині. Через визначену кількість тактів master "знімався" із шини і генерувалося немаскируемое переривання.
MCA проти EISA
Відразу ж після виходу шини EISA почалася "шинна війна", причому це була не стільки війна між архитектурами (вони обидві пішли в минуле), скільки війна за контроль IBM над ринком персональних комп'ютерів. І цю війну корпорація з тріском програла. Так, архітектура MCA по закладених технічних рішеннях і перспективам розвитку виглядала переважніше. Але, як не дивно, саме це виявилося другим фактором, що неї сгубил. Порівняльна характеристика шин EISA і MCA представлена у виді табл. 3.
Таблиця 3. Порівняльна характеристика шин EISA і MCA.
| MCA | EISA | |
| Пропускна здатність, МВ/хв | 20 | 33 |
| Спосіб передачі даних | асинхронний | Синхронний |
| Розмір карти (довжина х ширина), мм | 292.1 х 88.2 | 333.5 х 127.0 |
Площа поверхні карти EISA у 1.65 рази більше. А якщо ще врахувати, що адаптер EISA міг споживати більш ніж у 2 рази більше потужності, чим адаптер MCA, стає ясно, що робити периферію під EISA було і простіше і дешевше.
Крім того, у "шинній війні", як і скрізь, є присутнім "рука Intel". У прагненні звільнити ринок для нових процесорів 80386 і 80486, Intel випускав EISA-чипсети, що не підтримують 286 процесор (не чи правда, знайома ситуація), у той час, як шина MCA прекрасно працювала і на комп'ютерах з 286. Таким чином, перспективна розробка IBM так і залишилася перспективною розробкою, але і шина EISA не стала хітом: на той час, коли потреби комп'ютерів середнього рівня переросли можливості шини ISA, розроблювачі перейшли, минаючи EISA, до локальної шини.
Шина MCA (Micro Channel Architecture)
"До 1 квітня 1987 року життя у світі РС був украй простій: у байті було 8 біт, і при цьому існувала тільки одна шина, по якій ці біти можна було передавати. Звичайно, ця шина була "двох розмірів" - розрядністю 8 і 16 біт - але це була одна шина. Але наступного дня - 2 квітня - усі змінилося, і, здається, простота більше ніколи не повернеться."
Крис Лонг (Chris Long) PC User.
У 1987 році компанія IBM припинила випуск серії РС/АТ і початку виробництво лінії PS/2. Одним з головних відмінностей нового покоління персональних комп'ютерів була нова системна шина - Micro Channel Architecture (MCA). Ця шина не мала зворотну сумісність з ISA, але зате містила ряд передових для свого часу рішень:
· 8/16/32-розрядна передача даних;
· 20 МВ/хв пропускна здатність при частоті шини 10 MHz (у 4 рази більше,ніж у ISA!) при максимально можливій пропускній здатності шини 160 МВ/хв !!! (більше, ніж у PCI) (правда, не всі карти здатні працювати з такою швидкістю);
· Підтримка декількох bus master. Будь-який пристрій, підключений до шини, може одержати право на її виняткове використання для передачі або прийому даних з іншого з'єднаного з нею пристрою. Такий пристрій, по суті, являє собою спеціалізований процесор, що може здійснювати обмін даними по шині незалежно від основного процесора. Роботу пристроїв координує пристрій, називаний арбітром шини (CACP - Central Arbitration Control Point). При розподілі функцій керування шиною арбітр виходить з рівня пріоритету, яким володіє той або інший пристрій або операція. Усього таких рівнів чотири (у порядку убування):
5. регенерація системної пам'яті;
6. прямий доступ до пам'яті (DMA);
7. плати адаптерів.
8. процесор.
Якщо пристроєві необхідний контроль над шиною, він сповіщає про це арбітрові. З першою нагодою (після обробки запитів з більш високими пріоритетами) арбітр передає йому керування шиною. Поза системою пріоритетів обслуговуються тільки немасковані переривання (NMI - non-maskable interrupts), при виникненні яких керування негайно передається процесорові;
· 11-рівневі переривання (11-level triggered interrupts) замість дворівневих (trigger-edged) у ISA дозволяли поділяти (share) переривання між пристроями, що дозволило вилікувати одну з хвороб перших PC - недостачу ліній IRQ;
· 24 або 32 адресні лінії дозволяли адресувати до 4 GB пам'яті;
· автоматичне конфігурування пристроїв істотно спростило установку нових плат. У комп'ютерів із шиною MCA немає ніяких перемичок або перемикачів - ні на системній платі, ні на платах розширення. Замість використання адрес портів уведення-висновку, що зашиті у залізо, центральний процесор призначає них при старті системи, базуюся на інформації, ліченої з ROM карти;
· асинхронний протокол передачі даних знижував імовірність виникнення конфліктів і перешкод між пристроями, підключеними до шини.
Не чи правда, непоганий набір для 1987 року? Можливо, весь розвиток персональних комп'ютерів пішло б по іншому шляху, якби не одне але - гроші. Справа в тім, що IBM, порахувавши своє лідируюче положення на ринку персональних комп'ютерів непорушним, запропонувало незалежним виробникам, що бажають використовувати шину МСА, зовсім кабальні умови, що включають вимогу заплатити за використання шини ISA в усіх раніше зроблених комп'ютерах!!! Як Ви самі розумієте, що бажають виявилося, м'яко скажемо, небагато. Із серйозних компаній тільки Apricot і Olivetti підтримали нову архітектуру (причому Olivetti брала активну участь у розробці конкуруючого стандарту - EISA). Більшість покупців систем PS/2 "купували IBM", а не МСА. У результаті величезна робота - було розроблено 6 типів слотів -
· 16-розрядні (основні слоти, що установлюється в усі комп'ютери із шиною МСА);
· 32-розрядні ( установлюються на комп'ютерах із шиною МСА і процесором 386DX і вище. Так само, як і в ISA, є тільки розширенням основного слоту, але, оскільки розроблялися одночасно із шиною, конструкція вийшла більш логічної);
· 16 і 32-розрядні з доповненнями для плат пам'яті (встановлюються в деяких комп'ютерах із шиною МСА, наприклад, PS/2 моделей 70 і 80, мають 8 додаткових контактів для роботи з платами розширення пам'яті, розташованих на самому початку рознімання, зверненому до задньої стінки комп'ютера, перед основними контактами);
· 16 і 32-розрядні з доповненнями для відеоадаптерів (призначені для збільшення швидкодії відеосистеми. Звичайно в комп'ютері із шиною МСА встановлений один такий слот. 10 додаткових контактів також розташовані на початку рознімання і дозволяють платі відеоадаптера одержати доступ до вбудованої у системну плату схемі VGA)
пропала фактично даром. На даний момент посилання на архітектуру МСА практично не зустрічаються навіть на сайті IBM (наскільки мені відомо, у даний час архітектура МСА використовується IBM тільки в RISC-системах, наприклад, сервер RS/6000 побудований на базі шини МСА з пропускною здатністю 160 МВ/хв), тому приводити таблиці значень контактів не буду.
Локальна шина (Local bus)
Всі описані раніше шини мають загальний недолік - порівняно низьку пропускну здатність. Це зв'язано з тим, що шини розроблялися в розрахунку на повільні процесори. Надалі швидкодія процесора зростала, а характеристики шин поліпшувалися в основному "екстенсивно", за рахунок додавання нових ліній. Перешкодою для підвищення частоти шини була величезна кількість випущених плат, що не могли працювати на великих швидкостях обміну (МСА це стосується в меншому ступені, але в силу вищевикладених причин ця архітектура не грала помітної ролі на ринку). У той же час на початку 90-х років у світі персональних комп'ютерів відбулися зміни, що зажадали різкого збільшення швидкості обміну з пристроями:
· створення нового покоління процесорів типу Intel 80486, що працюють на частотах до 66 MHz;
· збільшення ємності твердих дисків і створення більш швидких контролерів;
· розробка й активне просування на ринок графічних інтерфейсів користувача (типу Windows або OS/2) привели до створення нових графічних адаптерів, що підтримують більш високий дозвіл і більша кількість квітів (VGA і SVGA).
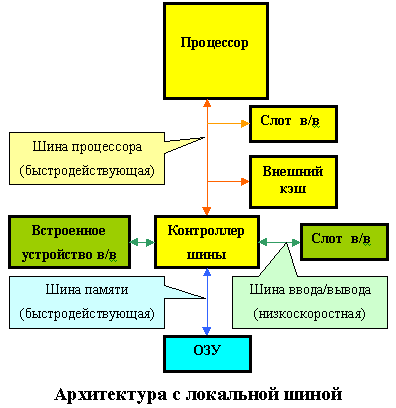
Очевидним виходом з положення, що створилося, є наступний: здійснювати частина операцій обміну даними, що вимагають високих швидкостей, не через шину введення/висновку, а через шину процесора, приблизно так само, як підключається зовнішній кеш. Така конструкція одержала назву локальної шини (Local Bus). Малюнки 1 і 2наочно демонструють розходження між звичайною архітектурою й архітектурою з локальною шиною.
Локальна шина не заміняла собою колишні стандарти, а доповнювала них. Основними шинами в комп'ютері як і раніше залишалися ISA або EISA, але до них додавалися один або трохи слотів локальної шини. Спочатку ці слоти використовувалися майже винятково для установки відеоадаптерів, при цьому до 1992 року було розроблено трохи несумісних між собою варіантів локальних шин, виняткові права на які належали фірмам-виготовникам. Природно, така плутанина стримувала поширювання локальних шин, тому VESA (Video Electronic Standard Association) - асоціація, яка представляє більш 100 компаній – запропонувала в серпні 1992 року свою специфікацію локальної шини.
Локальна шина VESA (VL-bus)
Основні характеристики VL-bus такі.
· Підтримка процесорів серій 80386 і 80486. Шина розроблена для використання в однопроцесорних системах, при цьому в специфікації передбачена можливість підтримки х86-несумісних процесорів за допомогою моста (bridge chip).
· Максимальне число bus master - 3 (не включаючи контролер шини). При необхідності можлива установка декількох підсистем для підтримки більшого числа маstеrов.
· Незважаючи на те, що споконвічно шина була розроблена для підтримки відеоконтролерів, можливі підтримка й інші пристрої (наприклад, контролерів твердого диска).
· Стандарт допускає роботу шини на частоті до 66 MHz, однак електричні характеристики рознімання VL-bus обмежують неї до 50 MHz (це обмеження, природно, не відноситься до інтегрованого в материнську плату пристроям).
· Двунаправлена (bi-directional) 32-розрядна шина даних підтримує і 16-розрядний обмін. У специфікацію закладена можливість 64-розрядного обміну.
· Підтримка DMA забезпечується тільки для bus masters. Шина не підтримує спеціальних "ініціаторів" DMA.
· Максимальна теоретична пропускна здатність шини - 160 МВ/хв (при частоті шини 50 MHz), стандартна - 107 МВ/хв при частоті 33 MHz.
· Підтримується пакетний режим обміну (для материнських плат 80486, що підтримують цей режим). 5 ліній використовується для ідентифікації типу і швидкості процесора, сигнал Burst Last (BLAST#) використовується для активізації цього режиму. Для систем, що не підтримують цей режим, лінія встановлюється в 0.
· Шина використовує 58-контактне рознімання МСА. Максимально підтримується 3 слоту (на деяких 50-мегагерцовых шинах можлива установка тільки 1 слоту).
· Слот VL-bus встановлюється в лінію за слотами ISA/EISA/MCA, тому VL-платам доступні всі лінії цих шин.
· Підтримується як інтегрований кеш процесора, так і кеш на материнській платі.
· Напруга харчування - 5 В. Пристрою з рівнем вихідного сигналу 3.3 У підтримуються за умови, що вони можуть працювати з рівнем вхідного сигналу 5 В.
Шина VL-bus з'явилася величезним кроком вперед у порівнянні з ISA як по продуктивності, так і по дизайні. Одним з переваг шини було те, що вона дозволяла створювати карти, що працюють з існуючими чипсетами і не утримуючої великої кількості схем дорогої керуючої логіки. У результаті VL-карти виходили дешевше аналогічних EISA-карт. Однак і ця шина не була позбавлена недоліків, головними з яких були наступні.
· Орієнтація на 486-ий процесор. VL-bus жорстко прив'язана до шини процесора 80486, що відрізняється від шин Pentium і Pentium Pro/Pentium II.
· Обмежена швидкодія. Як уже було сказано, реальна частота VL-bus - не більше 50 MHz. Причому при використанні процесорів із множником частоти шина використовує основну частоту (так, для 486DX2-66 частота шини буде 33 MHz).
· Схемотехнічні обмеження. До якості сигналів, переданих по шині процесора, пред'являються дуже тверді вимоги, дотриматися які можна тільки при визначених параметрах навантаження кожної лінії шини. На думку Intel, установка недостатньо акуратно розроблених VL-плат може привести не тільки до втрат даних і порушенням синхронізації, але і до ушкодження системи.
· Обмеження кількості плат. Це обмеження випливає також з необхідності дотримання обмежень на навантаження кожної лінії.
Незважаючи на існуючі недоліки, VL-bus була безсумнівним лідером на ринку, тому що дозволяла усунути вузьке місце відразу в двох підсистемах - відеопідсистемі і підсистемі обміну з твердим диском. Однак лідерство було недовгим, оскільки корпорація Intel розробила свою новинку - шину PCI. На думку компанії, VL-bus базувалася на технологіях 11-літньої давнини і була усього лише "латочкою", компромісом між виробниками. Правда, VESA заявляла, що обидві шини можуть "уживатися" спільно в одній системі. Intel погоджувалася, що таке сусідство можливо, але задавала зустрічне убивче питання: "А навіщо?". Справедливості заради, треба сказати, що PCI дійсно була урятована від більшості недоліків, властивих VL-bus.
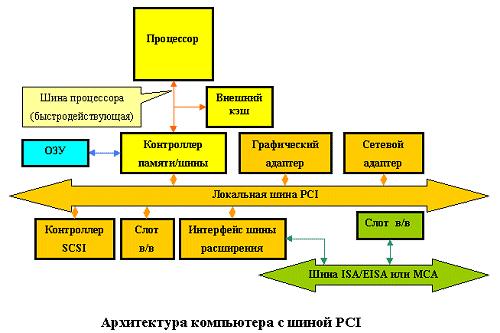
Шина PCI (Peripheral Component Interconnect bus)
Отже, переходимо до самого цікавого. Що ж знаходиться на сьогоднішній день усередині більшості наших комп'ютерів? Природно, шина PCI. Інше питання, чому саме ця шина. Спробуємо розібратися.
Отже, розробка шини PCI почалася навесні 1991 року як внутрішній проект корпорації Intel (Release 0.1). Фахівці компанії поставили перед собою ціль розробити недороге рішення, яке б дозволило цілком реалізувати можливості нового покоління процесорів 486/Pentium/P6 (от уже половина відповіді). Особливо підкреслювалося, що розробка проводилася "з нуля", а не була спробою установки нових "латок" на існуючі рішення. У результаті шина PCI з'явилася в червні 1992 року (R1.0). Розроблювачі Intel відмовилися від використання шини процесора і ввели ще одну "антресольну" (mezzanine) шину.
Завдяки такому рішенню шина вийшла, по-перше, процесоро-незалежною (на відміну від VLbus), а по-друге, могла працювати паралельно із шиною процесора, не звертаючи до неї за запитами. Наприклад, процесор працює собі з кешем або системною пам'яттю, а в цей час по мережі на вінчестер пишеться інформація. Просто здорово! Насправді ідилії, звичайно, не виходить, але завантаження шини процесора знижується здорово. Крім того, стандарт шини був оголошений відкритим і переданий PCI Special Interest Group, що продовжила роботу з удосконалювання шини (у даний час доступний R2.1), і в цьому, мабуть, друга половина відповіді на питання "чому PCI?"
Основні можливості шини наступні.
· Синхронний 32-х або 64-х розрядний обмін даними (правда, наскільки мені відомо, 64-розрядна шина в даний час використовується тільки в Alpha-системах і серверах на базі процесорів Intel Xeon, але, у принципі, за нею майбутнє). При цьому для зменшення числа контактів (і вартості) використовується мультіплексірування, тобто адреса і дані передаються по тим самим лініях.
· Підтримка 5V і 3.3V логіки. Рознімання для 5 і 3.3V плат розрізняються розташуванням ключів
· Частота роботи шини 33MHz або 66MHz (у версії 2.1) дозволяє забезпечити широкий діапазон пропускних здібностей (з використанням пакетного режиму):
· 132 МВ/хв при 32-bit/33MHz;
· 264 MB/хв при 32-bit/66MHz;
· 264 MB/хв при 64-bit/33MHz;
· 528 МВ/хв при 64-bit/66MHz.
При цьому для роботи шини на частоті 66MHz необхідно, щоб усі периферійні пристрої працювали на цій частоті.
· Повна підтримка multiply bus master (наприклад, кілька контролерів твердих дисків можуть одночасно працювати на шині).
· Підтримка write-back і write-through кеша.
· Автоматичне конфігуровання карт розширення при включенні харчування.
· Специфікація шини дозволяє комбінувати до восьми функцій на одній карті (наприклад, відео + звук і т.д.).
· Шина дозволяє встановлювати до 4 слотов розширення, однак можливе використання моста PCI-PCI для збільшення кількості карт розширення.
· PCI-пристрої обладнані таймером, що використовується для визначення максимального проміжку часу, у плині якого пристрій може займати шину.
При розробці шини в її архітектуру були закладені передові технічні рішення, що дозволяють підвищити пропускну здатність.
Шина підтримує метод передачі даних, називаний "linear burst" (метод лінійних пакетів). Цей метод припускає, що пакет інформації зчитується (або записується) "одним шматком", тобто адреса автоматично збільшується для наступного байта. Природним образом при цьому збільшується швидкість передачі власне даних за рахунок зменшення числа переданих адрес.
Шина PCI є тією черепахою, на якій коштують слони, що підтримують "Землю" - архітектуру Microsoft/Intel Plug and Play (Pn) PC architecture. Специфікація шини PCI визначає три типи ресурсів: два звичайних (діапазони пам'яті і діапазон уведення/висновку, як них називає компанія Microsoft) і configuration space - "конфігураційний простір".
Конфігураційний простір складається з трьох регіонів:
· заголовка, незалежного від пристрою (device-independent header region);
· регіону, обумовленого типом пристрою (header-type region);
· регіону, обумовленого користувачем (user-defined region).
У заголовку утримується інформація про виробника і тип пристрою - поле Class Code (мережний адаптер, контролер диска, мультімедіа і т.д.) і інша службова інформація.
Наступний регіон містить регістри діапазонів пам'яті і введення/висновку, що дозволяють динамічно виділяти пристроєві область системної пам'яті й адресного простору. У залежності від реалізації системи конфігурація пристроїв виробляється або BIOS (при виконанні POST - power-on self test), або програмно. Базовий регістр expansion ROM аналогічно дозволяє відображати ROM пристрою в системну пам'ять. Поле CIS (Card Information Structure) pointer використовується картами cardbus (PCMCIA R3.0). З Subsystem vendor/Subsystem ID усі зрозуміло, а останні 4 байти регіону використовуються для визначення переривання і часу запиту/володіння.

Малюнок 4. Конфігураційний простір.
Усе гарне коли-небудь кінчається. Кривдно - але істинно. Скільки писали про те, що шина PCI нарешті-те усунула "вузьке місце" РС - обмін з відеокартами - але та ба! Прогрес, як відомо, не коштує на місці. Поява різних там 3D прискорювачів привело до того, що ребром устав питання: що робити? Або збільшувати кількість дорогої пам'яті безпосередньо на відеокарті, або зберігати частина інформації в дешевій системній пам'яті, але при цьому яким-небудь образом організувати до неї швидкий доступ.
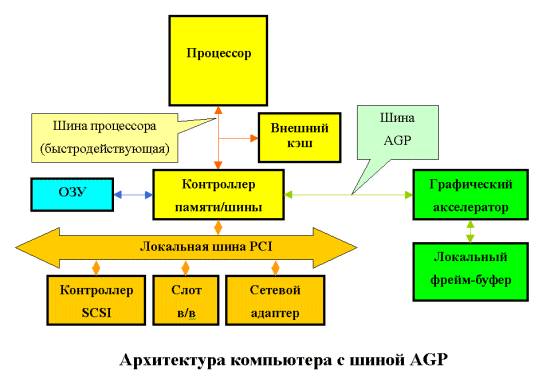
Як це практично завжди буває в комп'ютерній індустрії, питання вирішене не був. Здавалося б, от вам найпростіше рішення: переходите на 66-мегагерцовую 64-розрядну шину PCI з величезною пропускною здатністю, так немає ж. Intel на базі того ж стандарту PCI R2.1 розробляє нову шину - AGP (R1.0, потім 2.0), що відрізняється від свого "батька" у наступному:
1. шина здатна передавати два блоки даних за один 66 MHz цикл (AGP 2x);
2. усунута мультіплексованість ліній адреси і даних (нагадаю, що в PCI для здешевлення конструкції адреса і дані передавалися по тим самим лініях);
3. подальша конвеєризація операцій читання/запису, на думку розроблювачів, дозволяє усунути вплив затримок у модулях пам'яті на швидкість виконання цих операцій.
У результаті пропускна здатність шини була оцінена в 500 МВ/хв, і призначалася вона для того, щоб відеокарти зберігали текстури в системній пам'яті, відповідно мали менше пам'яті на платі, і, відповідно, дешевшали.
Парадокс у тім, що відеокарти усе-таки воліють мати БІЛЬШЕ пам'яті, і МАЙЖЕ НІХТО не зберігає текстури в системній пам'яті, оскільки текстур такого обсягу поки (підкреслюю - поки) практично немає. При цьому в силу здешевлення пам'яті взагалі, карти особливо і не дорожчають. Однак практично усі вважають, що майбутнє - за AGP, а бурхливий розвиток мультімедіа-додатків (особливо - ігор) може незабаром привести до того, що текстури перестануть влазити й у системну пам'ять. Тому має сенс, особливо не вдаючись у технічні подробиці, розповісти, як же це все працює.
Отже, почнемо з початку, тобто з AGP 1.0. Шина має два основних режими роботи: Execute і DMA. У режимі DMA основною пам'яттю є пам'ять карти. Текстури зберігаються в системній пам'яті, але перед використанням (той самий execute) копіюються в локальну пам'ять карти. Таким чином, AGP діє в якості "тилової структури", що забезпечує своєчасну "доставку патронів" (текстур) на передній край (у локальну пам'ять). Обмін ведеться великими послідовними пакетами.
У режимі Execute локальна і системна пам'ять для відеокарти логічно рівноправні. Текстури не копіюються в локальну пам'ять, а вибираються безпосередньо із системної. Таким чином, приходиться вибирати з пам'яті відносно малі випадково розташовані шматки. Оскільки системна пам'ять виділяється динамічно, блоками по 4ДО, у цьому режимі для забезпечення прийнятної швидкодії необхідно передбачити механізм, що відображає послідовні адреси на реальні адреси 4-х кілобайтних блоків у системній пам'яті. Ця нелегка задача виконується з використанням спеціальної таблиці (Graphic Address Re-mapping Table або GART), розташованої в пам'яті.
При цьому адреси, що не попадають у діапазон GART (GART range), не змінюються і безпосередньо відображаються на системну пам'ять або область пам'яті пристрою (device specific range). На малюнку як таку область показаний локальний фрейм-буфер карти (Local Frame Buffer або LFB). Точний вид і функціонування GART не визначені і залежать від керуючої логіки карти.
Шина AGP цілком підтримує операції шини PCI, тому AGP-трафік може представляти із себе суміш що чергуються AGP і PCI операцій читання/запису. Операції шини AGP є роздільними (split). Це означає, що запит на проведення операції відділений від власне пересилання даних.
Такий підхід дозволяє Устрі-AGP-пристроєві генерувати черга запитів, не чекаючи завершення поточної операції, що також підвищує швидкодію шини.
У 1998 році специфікація шини AGP одержала подальший розвиток - вийшов Revision 2.0. У результаті використання нових низьковольтних електричних специфікацій з'явилася можливість здійснювати 4 транзакции (пересилання блоку даних) за один 66-мегагерцовый такт (AGP 4x), що означає пропускну здатність шини в 1GB/хв! Єдине, чого не вистачає для повного щастя, так це щоб пристрій міг динамічно переключатися між режимами 1х, 2х і 4х, але з іншого боку, це нікому і не потрібно.
Однак потреби і запити в області обробки відеосигналів усі зростають, і Intel готує нову специфікацію - AGP Pro (у даний час доступний Revision 0.9) - спрямовану на задоволення потреб високопродуктивних графічних станцій. Новий стандарт не видозмінює шину AGP. Основний напрямок - збільшення енергопостачання графічних карт. З цією метою в рознімання AGP Pro додані нові лінії харчування.
Передбачається, що буде існувати два типи карт AGP Pro - High Power і Low Power. Карти High Power можуть споживати від 50 до 110W. Природно, такі карти мають потребу в гарному охолодженні. З цією метою специфікація вимагає наявності двох вільних слотів PCI з component side (сторони, на якій розміщені основні чіпи) карти.
При цьому дані слоти можуть використовуватися картою як додаткові кріплення, для підведення додаткового харчування і навіть для обміну по шині PCI! При цьому на використання цих слотів накладаються лише незначні обмеження.
При використанні слотів для підведення додаткового харчування:
· Не використовувати для харчування лінії V I/O;
· Не встановлювати лінію M66EN (контакт 49В) у GND (що цілком природно, тому що це переводить шину PCI у режим 33 MHz).
При використанні слоту для обміну по шині:
· Підсистема PCI I/O повинна розроблятися під напругу 3.3V c можливістю функціонування при 5 V.
Підтримка 64-розрядного або 66 MHz режимів не потрібно.
Карти Low Power можуть споживати 25-50W, тому для забезпечення охолодження специфікація вимагає наявності одного вільного слоту PCI.
При цьому всі retail-карти AGP Pro повинні мати спеціальну накладку шириною відповідно в 3 або 2 слоту, при цьому карта здобуває вид досить застрашливий.
Загалом, як уявлю собі графічну станцію з двома процесорами Xeon і відеокартою AGP Pro High Power... Можна здорово заощадити на опаленні... Закрадається крамольна думка, що в специфікацію PC 200? буде закладене рідинне охолодження. Знов-таки поживемо – побачимо…
Шина USB (Universal Serial Bus)
Що таке USB?
Специфікація периферійної шини USB розроблена лідерами комп'ютерної і телекомунікаційної промисловості -і Compaq, DEC, IBM, Intel, Microsoft, NEC і Northern Telecom -і для підключення комп'ютерної периферії поза корпусом машини по стандарті рlug'n'рlау, у результаті відпадає необхідність в установці додаткових плат у слоти розширення і переконфігуруванні системи. Персональні комп'ютери, що мають шину USB, дозволяють підключати периферійні пристрої і здійснюють їхній автоматичне конфігурування, як тільки пристрій фізично буде приєднано до машини, і при цьому немає необхідність перезавантажувати або виключати комп'ютер, а так само запускати програми установки і конфігурування. Шина USB дозволяє одночасно підключати послідовно до 127 пристроїв, таких, як монітори або клавіатури, що виконують роль додатково підключених компонентів, або хабов (тобто пристрій, через яке підключається ще трохи).
Хто створив USB?
USB була розроблена групою із семи компаній, що бачили необхідність у взаємодії для забезпечення подальшого росту і розвитку розквітаючої індустрії інтегрованих комп'ютерів і телефонії. Ці сім компаній, що просувають USB, що випливають: Compaq, Digital Equipment Corp, IBM PC Co., Intel, Microsoft, NEC і Northern Telecom.
Як це працює?
USB визначає, додані пристрій або відключений, завдяки своїй розумності, забезпечуваною основною системою. Шина автоматично визначає, який системний ресурс, включаючи програмний драйвер і пропускну здатність, потрібний кожному периферійному пристроєві і робить цей ресурс доступним без утручання користувача. Власники комп'ютерів, оснащених шиною USB мають можливість переключати сумісні периферійні пристрої, так само просто, як вони вкручують нову лампочку в лампу.
Ви знаєте ці пристрої: телефони, модеми, клавіатури, миші, пристрої читання CD ROM, джойстики, стрічкові і дискові нагромаджувачі, сканери і принтери. Швидкість прокачування в 12 мегабит/хвунду дозволяє підключати через USB усе сучасне покоління периферійних пристроїв, включаючи апаратуру для обробки відео даних формату MPEG-2, рукавички для керування віртуальними об'єктами і дигитайзеры. Також, з чеканням великого росту в області інтеграції комп'ютерів і телефонії, шина USB може виступати як інтерфейс для підключення пристроїв Цифрової мережі з інтегрованими послугами (ISDN) і цифрових пристроїв Private Branch eXchange (PBX), що дозволяють підключати велику кількість телефонів до невеликої кількості ліній зв'язку.
Що означає існування USB для постачальників систем і периферії?
Сумісність USB будується на основі технологічно цілісної і відкритої специфікації, що задовольняє потреби споживачів у легко розширюваних комп'ютерах. У свою чергу, для постачальників і реселерів комп'ютерів, периферії і програмного забезпечення, сумісність USB принесе прибуток, за рахунок використання нових методів маркетингу:
· "Готова платформа" дозволяє логічно зв'язати апаратне і програмне забезпечення для спільного постачання покупцеві.
· USB може знизити ризик можливої несумісності периферійного і програмного забезпечення, що поставляється з комп'ютерами, за рахунок постачання готових систем по ключ, що задовольняють вимогам спеціалізованих ринкових ніш.
· USB-сумісна периферія може запропонувати приватним і корпоративним покупцям більший вибір устаткування, без страху зниження функціональних можливостей апаратних засобів.
· Реселери одержують велику гнучкість у підборі апаратури і готових систем, для стимуляції купівельного попиту, за рахунок можливості комбінування комплектів периферії, що поставляється, без побоювань, що щось з чимось не буде працювати в парі.
· USB може забезпечити постачальникам периферії додаткову вигоду, за рахунок постачання нового обладнання для систем, що використовують технологію MMX™.
· USB може допомогти постачальникам знизити їхньої витрати на розробки, що у свою чергу дозволить їм установлювати нові, більш конкурентноспроможні ціни.
Як багато USB-сумісних комп'ютерів можна екати на ринку?
Компанія Dataquest вважає, що до 30 мільйонів USB-сумісних персональних комп'ютерів було продано протягом 1997, а в 1998-99 році, усі персональні комп'ютери будуть оснащені шиною USB.
Є чи вже пристрою для USB шини?
Персональні комп'ютери із шиною USB почали поставлятися на ринок ще в середині 1996 року, і перша хвиля периферії з підключенням через USB шину вже доступна користувачам.
Так само доступні технології, використовувані для розробки і створення USB систем, таких як конекторів, чипсетів і материнських плат.
Як може застосовуватися USB при наявності двох систем, наприклад ноутбука і настільного комп'ютера?
Відповіддю є застосування маленького адаптера, що буде визначений як пристрій для кожної USB системи, що входить у з'єднання. Два USB контролери периферії з загальним буфером пам'яті буде найбільш оптимальним рішенням, вартість якого не повинна перевищити $50. Корпус адаптера може виглядати, як маленька крапля в середині кабелю або, може бути, невелике стовщення, розташоване на одному з його кінців. Кабель, подібний описаному, зможе виконувати так само і функції хаба, усього лише за невелику додаткову плату, а це вже набагато більш коштовний продукт.
Як можна порівняти USB зі стандартом Sony FireWire/IEEE 1394?
Основні відмінності складаються в області застосування, приступності і ціні. Використання USB доступно вже зараз для традиційних пристроїв, що підключаються до PC, таких, як клавіатури, миші, джойстики і ручні сканери. Проте, пропускна можливість USB у 12 Mb/хв більш ніж достатня для більшості застосувань її користувачами, включаючи більш просунуті ігрові пристрої, високоякісний звук і стиснуте відео стандартів MPEG-1 і MPEG-2. Але, що більш важливо, застосування USB не збільшує вартість готової системи в силу інтегрування контролера в чипсет.
FireWire буде доступна в найпростіших варіантах не раніше початку 1999. FireWire орієнтована на підключення до персонального комп'ютера побутової електроніки, що вимагає високої смуги пропущення, наприклад, цифрових камер, програвачів цифрових відеодисків і цифрових пристроїв запису.
| Шина | Швидкість передачі даних | Топологія | Довжина сполучного кабелю | Підтримувані пристрої |
| USB | 12 Мб/з | Зірка | 5 м на сегмент | Периферія: пристрою введення, телекомунікаційне устаткування, принтери, аудио/відео пристрою |
| Firewire (IEEE P1394) | 100 Мб/з | Дерево | 4.5 м | Пристрою збереження даних і цифрова відеоелектроніка |
Чи замінить FireWire шину USB після своєї появи?
Немає. Дві технології орієнтовані на підключення різних периферійних пристроїв і отже будуть доповнювати один одного. Якщо FireWire стане переважаючої, десь через рік, усі буде зависить від конкретного покупця і його вимог до свого нового комп'ютера. Здається цілком ймовірним, що в майбутньому персональні комп'ютери будуть одночасно оснащені сполучними портами шини USB і FireWire.
Що таке інтелектуальні питання власності (Intellectual Property - IP) у відношенні USB, чи ліцензія це, скільки вона коштує, що таке "Зворотний Договір"(Reciprocal Covenent Agreement) про яке я чув?
Використання USB вільно від авторського гонорару, тобто творці специфікації дозволяють кожному розробляти на її підставі продукцію без якої або плати за це. Розроблювачі специфікації шини підписали IP угоду, у якому обіцяється, що не буде ніякого судового переслідування по будь-якому включеному пункті в IP у межах специфікації. Зворотний Договір є копією цієї угоди з можливістю для кожного, хто впроваджує шину USB, підписати цей договір і повернути його в адміністрацію USB-IF, для внесення запису про те, що угода прочитана і зрозуміле. Зворотний Договір доступний кожному (членам USB-IF чи ні) для роз'яснення ліцензійної угоди на USB.
Що таке специфікації OHCI і UHCI?
OHCI і UHCI, є специфікаціями, сумісними з USB, і описують інтерфейс різних апаратних реалізацій контролера, що вбудовується. Різноманіття в апаратну частину систем контролерів, що вбудовуються, є природним розвитком і створюється в рамках специфікації USB.
Є чи можливість збільшити довжину з'єднання пристроїв через шину USB до 50-200 метрів (наприклад, використовуючи оптоволокно), якщо це знадобиться користувачам?
Периферійний інтерфейс USB призначений для настільних систем, а відстань у 200 метрів, схоже, відповідає дуже більшому столові. Багато компаній, що входять у співтовариство впровадження USB, уже довгий час обговорюють проблему застосування шини на великих відстанях і думають про створення продуктів, що дозволили б зробити це можливим. Пристрій розширення виглядає як два хаба для шини USB, однак використовує інші протоколи (наприклад, для оптоволокна) між крапками з'єднання кабелю. На кожнім кінці електричний сигнал у USB повинний бути трансльований в або із сигналу для довгих відстаней. Для того, що б усе це стало можливим, необхідно вирішити питання, зв'язані з протоколом передачі пакетів даних і тимчасових затримок, що повинні бути сумісні і відповідати специфікації USB.
Коли пристрій відключений, його драйвер вивантажується з пам'яті, якщо знову підключити цей же пристрій, чи буде його драйвер знову завантажений?
Так, динамічне конфігурування й ініціалізація операційною системою містить у собі автоматичне завантаження і вивантаження з пам'яті драйверів, при виникненні необхідності.
Чи існують плани по збільшенню пропускної здатності шини USB удвічі, утроє?
Ні, шина USB була розроблена в якості периферійного інтерфейсу для настільних систем і має оптимальне співвідношення продуктивності і ціни на сьогоднішній день. Новий інтерфейс, такий як FireWire, для майбутніх високошвидкісних периферійних пристроїв, вже в стадії впровадження.
Чи може хто-небудь роз'яснити різницю між з'єднувачами серії "A" і "B"?
Конектори серії "A" розроблені для всіх пристроїв USB, і є розніманням для периферії і гніздом для персонального комп'ютера. У більшості випадків, кабель USB повинний бути убудований у периферійний пристрій. Це знижує вартість з'єднувачів, рятує від несумісності, можливої у випадку різного опору кабелів, і спрощує дії користувачів по підключенню. Однак у деяких випадках убудований кабель не можна використовувати. Гарним прикладом можуть служити дуже великі і важкі пристрої, що погано поєднувалися з тонким кабелем, якому не можна видалити, а так само пристрою, що підключаються тільки зрідка, що інтенсивно використовуються, коли не є підключеними. Для таких випадків і були створені конектори серії "B". Дві серії конекторів розрізняються зовні, це зроблено для запобігання з'єднань, які б могли порушити топологію архітектури USB.
У чому різниця між основним хабом і звичайним з погляду апаратної реалізації і програмного забезпечення?
Усі хаби зовсім однакові з погляду програмного забезпечення (крім різниці, як пристроїв що мають живлення і не мають). Основний хаб (або кореневий), це просто перший хаб, виявлений при нумерації. У багатьох реалізаціях основний хаб може бути інтегрований у ту ж мікросхему, що й основний контролер, це дозволяє знизити вартість.
Чи можливо використання шини USB для підключення таких периферійних пристроїв, як CD-R, стрічкових нагромаджувачів або твердих дисків?
Можливість застосування заснована на прийнятності рівня продуктивності. Якщо якесь з цих пристроїв передбачається часто використовувати, то, звичайно пред'являються вимоги, що б воно було механічно інтегроване в систему і мало високу продуктивність, що знову ж відповідає рівневі системи в цілому. Шина USB не розроблялася для забезпечення постійного з'єднання високошвидкісних периферійних пристроїв усередині корпуса комп'ютера. Якщо пристрій використовується час від часу або підключається до різних комп'ютерів, тоді, продуктивність, забезпечувана шиною USB буде більш ніж достатньою. Зручності використання і підключення пристроїв, забезпечувані USB з лишком переважують параметри швидкості передачі даних. Але всі таки, USB забезпечує швидкість передачі на рівні 4x або 6x швидкісних приводів CD (чого недостатньо для перезаписуючих пристроїв), але при цьому кращу, чим забезпечують звичайні стрічкові нагромаджувачі, підключені через рівнобіжний порт, дисководи для гнучких магнітних дисків або знімні тверді диски типу SyQuest.
IEEE 1394 (Firewire) - нова послідовна шина
IEEE 1394 або Firewire - це послідовна високошвидкісна шина, призначена для обміну цифровою інформацією між комп'ютером і іншими електронними пристроями. Завдяки невисокій ціні і великій швидкості передачі даних ця шина стає новим стандартом шини введення-висновку для персонального комп'ютера. Її змінювана архітектура й однорангова топологія роблять Fireware ідеальним варіантом для підключення твердих дисків і пристроїв обробки аудіо- і відеоінформації. Ця шина також ідеально підходить для роботи мультімедійних додатків у реальному часі. У цьому матеріалі приведені деякі загальні зведення про стандарт IEEE 1394.
Навіщо потрібний новий інтерфейс
Насамперед, подивитеся на задню стінку свого комп'ютера. Там можна знайти безліч усяких рознімань: послідовний порт для модему, принтерний порт для принтера, рознімання для клавіатури, миші і монітора, SCSI-інтерфейс, призначений для підключення зовнішніх носіїв інформації і сканерів, рознімання для підключення аудіо і MIDI пристроїв, а також для пристроїв захоплення і роботи з відеозображеннями. Цей достаток збиває з користі користувачів і створює безладдя зі сполучних кабелів. Причому, нерідко виробники ноутбуків використовують і інші типи конекторів.
Новий інтерфейс покликаний позбавити користувачів від цієї мішанини і до того ж має цілком цифровий інтерфейс. Таким чином, дані з компакт-дисків і цифрових магнітофонів зможуть передаватися без перекручувань, тому що в даний час ці дані спочатку конвертуються в аналоговий сигнал, а потім назад оцифровуються устроєм-одержувачем сигналу. Кабельне телебачення, радіомовлення і відео CD передають дані також у цифровому форматі.
Цифрові пристрої генерують великі обсяги даних, необхідні для передачі якісної мультімедіа-інформації. Наприклад:
Високоякісне відео
Цифрові дані = (30 frames / second) (640 x 480 pels) (24-bit color / pel) = 221 Mbps
Відео середньої якості
Цифрові дані = (15 frames / second) (320 x 240 pels) (16-bit color / pel) = 18 Mbps
Високоякісне аудіо
Цифрові дані = (44,100 audio samples / sec) (16-bit audio samples) (2 audio channels for stereo) = 1.4 Mbps
Аудио середньої якості
Цифрові дані = (11,050 audio samples / sec) (8-bit audio samples) (1 audio channel for monaural) = 0.1 Mbps
Позначення Mbps - мегабит у хвунду.
Для рішення всіх цих проблем і високошвидкісної передачі даних була розроблена шина IEEE 1394 (Firewire).
IEEE 1394 - високошвидкісна послідовна шина
Стандарт підтримує пропускну здатність шини на рівнях 100, 200 і 400 Мбит/с. У залежності від можливостей підключених пристроїв одна пара пристроїв може обмінюватися сигналами на швидкості 100 Мбит/з, у той час як інша на тій же шині - на швидкості 400 Мбит/с. На початку наступного року будуть реалізовані дві нові швидкості - 800 і 1600 Мбит/з, що в даний час пропонуються як розширення стандарту. Такі високі показники пропускної здатності послідовної шини практично виключають необхідність використання рівнобіжних шин, основною задачею яких стане передача потоків даних, наприклад незжатих відеосигналів, усередині комп'ютера.
Таким чином, Firewire задовольняє всім перерахованим вище вимогам, включаючи:
· Цифровий інтерфейс - дозволяє передавати дані між цифровими пристроями без втрат інформації
· Невеликий розмір - тонкий кабель заміняє купу громіздких проводів
· Простота у використанні - відсутність термінаторів, ідентифікаторів пристроїв або попередньої установки
· Гаряче підключення - можливість переконфігурувати шину без вимикання комп'ютера
· Невелика вартість для кінцевих користувачів
· Різна швидкість передачі даних - 100, 200 і 400 Мбит/з
· Гнучка топологія - рівноправність пристроїв, що допускає різні конфігурації
· Висока швидкість - можливість обробки мультімедіа-сігналу в реальному часі
· Відкрита архітектура - відсутність необхідності використання спеціального програмного забезпечення
Завдяки цьому шина IEEE 1394 може використовуватися з:
· Комп'ютерами
· Аудіо і відео мультімедійними пристроями
· Принтерами і сканерами
· Твердими дисками, масивами RAID
· Цифровими відеокамерами і відеомагнітофонами
Найпростіша система для відеоконференцій, побудована на шині IEEE 1394, що використовує два 15 fps аудіо/відео каналу завантажить усього третю частину 100Mbps інтерфейсу 1394. Але, у принципі, для цієї задачі можливо і використання 400Mbps інтерфейсу.
Шість контактів FireWire приєднані до двох проводів, що йдуть до джерела харчування, і двом крученим парам сигнальних проводів. Кожна кручена пара і весь кабель у цілому екрановані. Проводу харчування розраховані на струм до 1,5 А при напрузі від 8 до 40 В, підтримують роботу всієї шини, навіть коли деякі пристрої виключені. Вони також роблять непотрібними кабелі харчування в багатьох пристроях. Не дуже давно інженери Sony розробили ще більш тонкий чотирьох дротовий кабель, у якому відсутні проводу харчування. (Вони мають намір додати свою розробку до стандарту.) Цей так називане AV-рознімання буде зв'язувати невеликі пристрої, як "листи" з "гілками" 1394.
Гніздо рознімання має невеликі розміри. Ширина його складає 1/10 ширини гнізда рознімання SCSI, у нього лише шість контактів (у SCSI - 25 або 50 рознімань).
До того ж кабель 1394 тонкий - приблизно в три рази тонше, ніж кабель SCSI. Хврет отут простий - адже це послідовна шина. Усі дані посилаються послідовно, а не паралельно по різних проводах, як це робить шина SCSI.
Топологія
Стандарт 1394 визначає загальну структуру шини, а також протокол передачі даних і поділу носія. Деревоподібна структура шини завжди має "кореневе" пристрій, від якого відбувається розгалуження до логічного "вузлам", що знаходяться в інших фізичних пристроях.
Кореневий пристрій відповідає за визначені функції керування. Так, якщо це ПК, він може містити міст між шинами 1394 і PCI і виконувати деякі додаткові функції по керуванню шиною. Кореневий пристрій визначається під час ініціалізації і, будучи один раз обраним, залишається таким на увесь час підключення до шини.
Мережа 1394 може включати до 63 вузлів, кожний з яких має свій 6-розрядний фізичний ідентифікаційний номер. Кілька мереж можуть бути з'єднані між собою мостами. Максимальна кількість з'єднаних шин у системі - 1023. При цьому кожна шина ідентифікується окремим 10-розрядним номером. Таким чином, 16-розрядна адреса дозволяє мати до 64449 вузлів у системі. Оскільки розрядність адрес пристроїв 64 біта, а 16 з них використовуються для специфікації вузлів і мереж, залишається 48 біт для адресного простору, максимальний розмір якого 256 Терабайт (256х10244 байт) для кожного вузла.
Конструкція шини дивно проста. Пристрої можуть підключатися до будь-якого доступного порту (на кожнім пристрої звичайно 1 - 3 порти). Шина допускає "гаряче" підключення - з'єднання або роз'єднання при включеному харчуванні. Немає також необхідності в яких-небудь адресних перемикачах, оскільки відсутні електронні адреси. Щораз, коли вузол додається або вилучається з мережі, топологія шини автоматично переконфігурується відповідно до шинного протоколу.
Однак є кілька обмежень. Між будь-якими двома вузлами може існувати не більше 16 мережних сегментів, а в результаті з'єднання пристроїв не повинні утворюватися петлі. До того ж для підтримки якості сигналів довжина стандартного кабелю, що з'єднує два вузли, не повинний перевищувати 4,5 м.
Протокол
Інтерфейс дозволяє здійснювати два типи передачі даних: синхронний і асинхронний. При асинхронному методі одержувач підтверджує одержання даних, а синхронна передача гарантує доставку даних у необхідному обсязі, що особливо важливо для мультімедійних додатків.
Протокол IEEE 1394 реалізує три нижніх рівні еталонної моделі Міжнародної організації по стандартизації OSI: фізичний, канальний і мережний. Крім того, існує "менеджер шини", якому доступні всі три рівні. На фізичному рівні забезпечується електричне і механічне з'єднання з конектором, на інших рівнях - з'єднання з прикладною програмою.
На фізичному рівні здійснюється передача й одержання даних, виконуються арбітражні функції - для того щоб усі пристрої, підключені до шини Firewire, мали рівні права доступу.
На канальному рівні забезпечується надійна передача даних через фізичний канал, здійснюється обслуговування двох типів доставки пакетів - синхронного й асинхронного.
На мережному рівні підтримується асинхронний протокол запису, читання і блокування команд, забезпечуючи передачу даних від відправника до одержувача і читання отриманих даних. Блокування поєднує функції команд запису/читання і роблять маршрутизацію даних між відправником і одержувачем в обох напрямках.
"Менеджер шини" забезпечує загальне керування її конфігурацією, виконуючи наступні дії: оптимізацію арбітражної синхронізації, керування споживанням електричної енергії пристроями, підключеними до шини, призначення ведучого пристрою в циклі, присвоєння ідентифікатора синхронного каналу і повідомлення про помилки.
Щоб передати дані, пристрій спочатку запитує контроль над фізичним рівнем. При асинхронній передачі в пакеті, крім даних, утримуються адреси відправника й одержувача. Якщо одержувач приймає пакет, то підтвердження повертається відправникові. Для поліпшення продуктивності відправник може здійснювати до 64 транзакцій, не чекаючи обробки. Якщо повернуто негативне підтвердження, то відбувається повторна передача пакета.
У випадку синхронної передачі відправник просить надати синхронний канал, що має смугу частот, що відповідає його потребам. Ідентифікатор синхронного каналу передається разом з даними пакета. Одержувач перевіряє ідентифікатор каналу і приймає тільки ті дані, що мають визначений ідентифікатор. Кількість каналів і смуга частот для кожного залежать від додатка користувача. Може бути організоване до 64 синхронних каналів.
Шина конфігурується таким чином, щоб передача кадру починалася під час інтервалу синхронізації. На початку кадру розташовується індикатор початку і далі послідовно в часі випливають синхронні канали 1, 2... На малюнку зображений кадр із двома синхронними каналами й одним асинхронним
Час, що залишився, у кадрі використовується для асинхронної передачі. У випадку встановлення для кожного синхронного каналу вікна в кадрі шина гарантує необхідну для передачі смугу частот і успішну доставку даних.
Резюме
Таким чином, у швидкому майбутньому, на задній панелі комп'ютера можна буде побачити виходи лише двох послідовних шин: USB для низько швидкісних застосувань і Firewire - для високошвидкісних. Причому шлях у життя в шини IEEE 1394 відбудеться набагато швидше, ніж у USB. У цьому випадку виробники програмних продуктів і апаратури діють спільно. Уже зараз доступні різні види пристроїв із шиною Firewire, підтримка цієї шини буде убудована в операційну систему Windows 98 і в найближчому майбутньому ведучі виробники чипсетів для PC умонтують підтримку цієї шини у свої продукти. Так що 1999 рік стане роком Firewire.
(Intelligent Input/Output)
I2O (Intelligent Input/Output) - специфікація, що визначає стандартну архітектуру інтелектуального введення/висновку, що не залежить від специфічних пристроїв і операційної системи. Специфікація I2O покликана вирішити дві ключові проблеми:
· Зайнятість процесора операціями введення-висновку
· Необхідність у розробці драйверів для кожного пристрою і для кожної операційної системи
Суть архітектури I2O полягає в обробці низькорівневих переривань уведення-висновку, що надходять від пристроїв, не центральним процесором (CPU), а спеціалізованим процесором уведення-висновку (IOP), розробленим спеціально для цієї мети. В даний момент ця задача вирішується застосуванням RISC-процесора i960, що працює на частоті 66 МГц зі своєю власною пам'яттю, обсягом до 64 МБ. За підтримкою обміну повідомленнями між декількома процесорами, архітектура I2O розвантажує центральний процесор і дозволяє виконання задач, що вимагають інтенсивного введення-висновку і широкої смуги пропущення, наприклад відео-додатків або роботи в середовищі клієнт-сервер. Застосування I2O не обмежені і вона може бути використана як в одно-процесорних, так і багатопроцесорних і кластерных системах.
Специфікація I2O визначає розбивку драйвера пристрою на двох частин: Ос-ос-залежного й апаратно-залежного модуля, створеного для конкретного пристрою. Ці модулі працюють автономно і можуть виконувати задачі незалежно. В даний час підтримка I2O забезпечується в NetWare 4, Windows NT Server 5.0 і UnixWare. Таким чином, технологія з розбивкою драйвера, зменшує загальне число необхідних драйверів: виробники операційних систем пишуть по одному драйвері на кожен клас пристроїв, наприклад дискові контролери, а виробники устаткування - по одному драйвері на кожен свій пристрій, що може бути використаний з будь-якою операційною системою підтримуючий I2O.
Одна з цілей створення відкритої архітектури I2O - забезпечення можливості легкого підключення пристроїв і написання драйверів, що розширює можливості для створення нових систем.
Короткий огляд
Дві частини драйвера I2O пристрою являють собою Operating System Services Module (OSM), модуль обслуговування операційної системи, що забезпечує інтерфейс із нею і Hardware Device Module (HDM), модуль пристрою, що забезпечує керування устаткуванням. OSM працює з зовнішнім пристроєм за допомогою HDM. Спілкування між цими модулями відбувається на двох рівнях - рівні повідомлень, на якому відбувається встановлення зв'язку і транспортному рівні, що визначає способи поділу інформації. Як і в більшості протоколів зв'язку, рівень повідомлень базується на транспортному рівні.
Модель зв'язку I2O, у комбінації із середовищем виконання і конфігураційним інтерфейсом, забезпечує незалежний інтерфейс із HDM. Модулі здатні зв'язатися один з одним без знання архітектури шини або топології системи. Передані повідомлення формують якийсь метаязык, що не залежить від апаратної реалізації. Уся ця технологія сильно нагадує мережу TCP/IP. Така реалізація I2O, крім всього іншого, забезпечує мобільність пристроїв уведення-висновку.
Модель зв'язку I2O
Модель зв'язку для I2O - це система обміну повідомленнями. Коли OSM одержує запит від операційної системи, він транслює його в запит I2O і передає його HDM для обробки. Після обробки запиту, HDM повертає результат назад OSM, посилаючи повідомлення за допомогою рівня повідомлень I2O. Далі результат передається операційній системі, як від будь-якого іншого драйвера пристрою.
Рівень повідомлень
Рівень повідомлень визначає відкритий, стандартний і абстрактний механізм для зв'язку між сервісними модулями, забезпечуючи основу для інтелектуального введення - висновку. Цей рівень, керуючи пересиланням усіх запитів, а також забезпечуючи функціонування API (Application Programming Interface), зв'язує модель драйверів I2O.
Рівень повідомлень складається з трьох основних компонентів: дескриптора повідомлення, сервісної програми повідомлення (Message Service Routine - MSR), і черги повідомлень. Дескриптор власне кажучи є адресою ресурсу, до якого йде звертання. Для кожного повідомлення, що проходить на рівні повідомлень створюється свій дескриптор. Черга повідомлень організується між передавальним і приймальням пристроями.
Коли драйвер формує повідомлення, воно міститься в чергу і для його обробки активізується MSR. Повідомлення містить двох частин - заголовок і тіло. Заголовок містить тип повідомлення й адреса його відправника.
I2O базується на черзі між MSR і відправником. Ініціатор запиту і сервісний модуль обслуговуються IOP. I2O визначає також формат пам'яті, необхідної для функціонування технології, що не залежить від організації операційної системи.
Модуль обслуговування операційної системи - OSM
OSM забезпечує інтерфейс між операційною системою і рівнем повідомлень I2O. У використовуваній моделі драйверів, OSM являє собою ту частину драйвера, що забезпечує інтерфейс між системно-залежним API і абстрактним форматом повідомлень, що посилаються в HDM для обробки. OSM залежать від операційних систем і створюються їх розроблювачами.
OSM переводить повідомлення операційної системи у формат, що може бути зрозумілий HDM. Передача інформації назад, від HDM до операційної системи реалізується також через OSM за допомогою рівня повідомлень I2O.
Один OSM може обслуговувати множинні HDM. Завдяки існуванню дескрипторів на рівні повідомлень, OSM має можливість розсилати свої повідомлення багатьом адресатам, а також організовувати пересилання інформації між ними.
Апаратний модуль пристрою - HDM
HDM - низкорівневий модуль у середовищі I2O. HDM являє собою аппартнозалежну частину драйвера, що забезпечує взаємодія з контролером або безпосередньо пристроєм. Можна провести аналогію між HDM і апаратно залежною частиною драйвера мережі або драйвером SCSI у тім виді, у якому він існує сьогодні. Кожен HDM унікальний для кожного конкретного пристрою і виробника. Він підтримує всі низько-рівневі операції пристрою, такі як синхронні й асинхронні запити, а також транзакції керовані подіями.
HDM оточений середовищем I2O, що ізолює його від спілкування з операційною системою і шинними протоколами. Таким чином, один HDM може бути використаний не тільки з різними операційними системами, але навіть з різними платформами. HDM пишеться виробником пристрою і звичайно прошивається в адаптер.
Системне середовище
Модель I2O може бути застосована в будь-яких умовах - як і в одно процесорних, так і багатопроцесорних системах.
Інтерфейси OSM і HDM входять в основний API I2O. Середовище виконання OSM залежать від операційної системи, що впливає на реалізацію деяких функцій API. У задачі OSM входить реалізація зв'язку між API, використовуваного операційною системою, і HDM, керуючим пристроєм.
Крім основних функцій у API HDM може бути введений додатковий набір команд. Цей набір необхідний для прямого спілкування операційної системи з HDM і застосовується при її завантаженні для ініціалізації ядра. Приблизно це і реалізується в основних багатозадачних середовищах. Однак цей додатковий набір також є єдиним для всіх пристроїв одного класу. Так що технологія I2O не несе в собі ніяких обмежень для області її використання.
Реалізація архітектури I2O
Гнучка, відкрита архітектура I2O надає розроблювачам різні варіанти для реалізації. Основні три підходи наступні:
· Установка IOP на материнську плату. IOP установлюється на материнську плату і використовується при інтелектуальному введенні-висновку. У цьому випадку IOP використовується в якості стандартного PCI Bridge і додає "інтелектуальності" до шини PCI
· Установка IOP на додатковій платі розширення. Інтелектуальний контролер I2O інсталюється як, наприклад, звичайна мережна карта
· Установка опціональної плати розширення з IOP у спеціалізований слот на материнській платі. Цей процесор буде функціонувати з усіма пристроями, що вимагають інтелектуальний уведення-висновок
Практика використання I2O
Пристрою, сумісні з технологією I2O будуть маркіруватися виробниками як "I2O ready". Однак в одній системі можна буде застосовувати, як і I2O пристрою, так і звичайні, не інтелектуальні пристрої. Це дозволить організувати легкий перехід до нової архітектури. Тим більше вартість материнської плати з IOP зросте максимум на $10-15.
Очікується, що в зв'язку з уведенням додаткових пристроїв (IOP) і розбивки драйвера на частини, швидкість обміну інформацією може упасти. У принципі, ця думка виправдана. Однак, у зв'язку з тим що по-перше спрощується задача написання драйверів, а по-друге розвантажується центральний процесор, загальна ефективність системи повинна зрости. Приклад подібного росту ефективності - застосування IDE Bus Master драйверів.
Упровадження технології інтелектуального введення-висновку повинне відбутися найближчим часом, тим більше що ведучі виробники материнських плат уже представили свої вироби з установленим на борті IOP i960, єдиним на дійсний час процесором для реалізації I2O. Перший час I2O буде використовуватися в серверах, однак у найближчому майбутньому може поширитися і на домашні системи.
Висновок
Таким чином, I2O пропонує новий підхід до організації інтелектуального введення-висновку, спрощуючи життя, як розроблювачем пристроїв, так і виробникам операційних систем завдяки поділові функцій драйверів. Крім того, I2O покликана реалізувати нову високопродуктивну концепцію високопродуктивного і платформено-незалежного інтелектуального введення-висновку. Відкритість цього стандарту дозволяє легко перейти від сьогоднішніх реалій у світ інтелектуального обміну інформацією.
[1] Контакт В8 по-разному использовался в ХТ и АТ. Для обеспечения совместимости IBM XT со специфической системой под названием 3270 РС, восьмой (ближайший к блоку питания) слот расширения ХТ был особенным. В него можно было устанавливать лишь платы, выдающие на контакт В8 сигнал "выбор платы" или, как его еще называют, "сигнал J8" - например, плату клавиатуры/таймера от 3270 РС. К этим платам, кроме того, предъявлялись другие требования по синхронизации. В IBM AT такую хитрую совместимость обеспечивать не стали, а контакт В8 приспособили для подачи сигнала NOWS - No Wait State
Похожие работы


... характеристики разъема VL-bus ограничивают ее до 50 MHz (это ограничение, естественно, не относится к интегрированным в материнскую плату устройствам). Двунаправленная (bi-directional) 32-разрядная шина данных поддерживает и 16-разрядный обмен. В спецификацию заложена возможность 64-разрядного обмена. Поддержка DMA обеспечивается только для bus masters. Шина не поддерживает ...
... могли осуществлять арбитраж на шине. После появления процессора Pentium ассоциация VESA приступила к работе над новым стандартом VL-bus (версия 2). Он предусматривает, в частности, использование 64-разрядной шины данных и увеличение количества разъемов расширения (предположительно три разъема на 40 МГц и два на 50 Мгц). Ожидаемая скорость передачи теоретически должна возрасти до 400 Мбайт/с. ...
... метод доступа с передачей полномочия. Охарактеризовать метод множественного доступа с разделением частоты. Какие существуют варианты использования множественного доступа с разделением во времени? Лекция 5.ЛВС и компоненты ЛВС Компьютерная сеть состоит из трех основных аппаратных компонент и двух программных, которые должны работать согласованно. Для корректной работы устройств в сети их нужно ...
... ? 8. Какими программами можно воспользоваться для устранения проблем и ошибок, обнаруженных программой Sandra? Раздел 3. Автономная и комплексная проверка функционирования и диагностика СВТ, АПС и АПК Некоторые из достаточно интеллектуальных средств вычислительной техники, такие как принтеры, плоттеры, могут иметь режимы автономного тестировании. Так, автономный тест принтера запускается без ...
0 комментариев