Вступ
Тема реферату «Поняття мультімікропроцесорних систем (ММПС)» з дисципліни «Мультімікропроцесорні системи».
Мета роботи – ознайомитися з:
- визначенням мультіпроцесорних конфігурацій;
- архітектурою ММПС із загальною і розподіленою пам'яттю;
- протоколами взаємодії ММПС – MESI, DASH;
- стратегією запису в кеш-пам'яті та ін.
1. Визначення мультипроцесорних конфігурацій
ММПС - це системи, що мають два й більше компонент, які можуть одночасно виконувати команди. Підпорядкованими процесорами можуть бути спецпроцесори, розраховані на виконання певного типу завдання або процесори широкого застосування. Спецпроцесори - співпроцесори, процесори вводу-виводу.
У міру зменшення відносини вартість/продуктивність стає більше економічним застосовувати кілька мікропроцесорів (далі ─ МП), замість одного складного.
Крім поліпшення економічних показників системи, мультипроцесорні конфігурації забезпечують кілька позитивних якостей, відсутніх в однопроцесорній конфігурації.
Кілька процесорів краще пристосовуються під вимогу конкретного застосування, крім витрат на непотрібні можливості централізованої системи. Більше того, модульність ММПС дозволяє в міру необхідності вводити додаткові процесори.
У ММПС завдання розподіляються між модулями. При виникненні відмови у системі простіше та дешевше знайти й замінити несправний процесор, чим заміняти (відшукувати) елемент, що відмовив, у складному процесорі.
При проектуванні ММПС доводиться вирішувати два завдання:
1.Змагання за доступ до системної шини.
2.Міжпроцесорні взаємодії.
Оскільки пам'ять та пристрої вводу-виводу по загальній системній шині розподіляють кілька процесорів, буде потрібна додаткова логіка для забезпечення того, щоб у будь-який момент часу доступ до системної шини мав тільки один процесор. Щоб один процесор здійснював диспетчеризацію завдання, або повертав результат іншому, необхідний строго певний спосіб взаємодії процесорів.
Максимальний режим роботи МП фірми INTEL спеціально призначений для реалізації ММПС. Наявні мультипроцесорні засоби максимального режиму розраховані на три базові конфігурації - співпроцесор, сильно зв'язана конфігурація та слабко зв'язана конфігурація.
У випадку сильно зв'язаної конфігурації (мал.1), центральний процесор і допоміжний або зовнішній процесор розділяють не тільки всю підсистему пам'яті та введення/виведення але й логіку керування шиною та генератор синхронізації. МП 8086 або його аналог є провідним або головним у системі, а допоміжний процесор - керуємим. Керування доступом до шини здійснює центральний процесор, тому сигнал запиту шини від допоміжного процесора подається в центральний. У даній конфігурації допоміжний процесор діє незалежно усередині кристала, але будучи співпроцесором, він повинен взаємодіяти безпосередньо із центральним процесором.
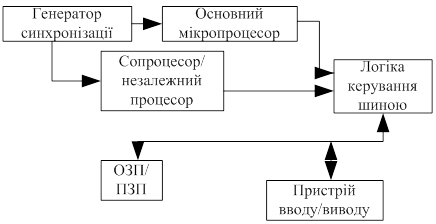
Малюнок 1. Cхема сильно зв'язаної конфігурації
Слабко зв'язані конфігурації застосовуються у середніх і великих системах. Будь-який активний модуль у такій системі може бути ведучим системної шини й містити центральний процесор, а також інший процесор, що може бути ведучим шини, співпроцесор або сильно зв'язану конфігурацію.
Системні ресурси розділяють кілька модулів, а проблему змагань при доступі до шини повинна вирішувати логіка керування системною шиною.
У випадку слабко зв'язаної конфігурації (мал. 2), кожний потенційний ведучий шини працює незалежно й прямі зв'язки між ними відсутні. Між процесорна взаємодія здійснюється через розділені ресурси. Крім того, у кожного модуля може бути своя пам'ять і пристрої вводу-виводу. Процесори в окремих модулях можуть одночасно звертатися до своїх локальних підсистем по локальних шинах і виконувати незалежно друг від друга вибірки команд і даних, що підвищує ступінь паралельності обробки.
1.1 Співпроцессорна конфігураціяАлгоритм функціонування співпроцесорної конфігурації наведений на мал.3.
При виконанні потоку команд основного процесора та виявленні команди, призначеної для співпроцесора, вона транслюється асемблером у такий спосіб ─ код команди WAIT, код команди ESC.
Код команди WAIT перед кодом ESC змушує мікропроцесор увести стан очікування до появи активного сигналу на вході TEST. Ця команда необхідна, щоб команда ESC не встигла дешифруватися до завершення співпроцесором його поточної команди. Якщо сигнал TEST уже активний, співпроцесор дешифрує команду ESC, а потім обидва процесори працюють паралельно (це неявна присутність тактів очікування). Однак у деяких випадках команду WAIT необхідно вказувати явно. Це необхідно, коли центральному процесору потрібно звернутися в пам’ять за операндом, що бере участь у попередній команді ESC. У співпроцесорної конфігурації до одного центрального процесора допускається підключення двох співпроцесорів.
У таких випадках кожному зі співпроцесорів необхідно призначати підмножини з безлічі кодів зовнішніх операцій і кожний співпроцесор повинен розпізнавати й виконувати коди операцій своєї підмножини. Підключення співпроцесорів здійснюється до системної шини, але один з них до лінії HOLD (сигнал запиту шини), іншій до HLDA (сигнал дозволу шини).
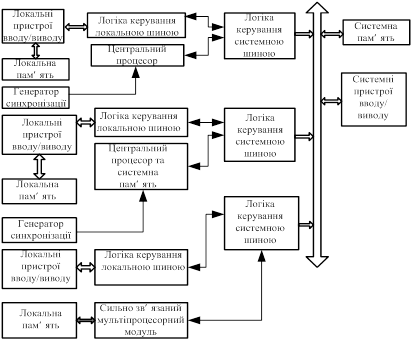
Малюнок 2. Слабко зв'язана конфігурація
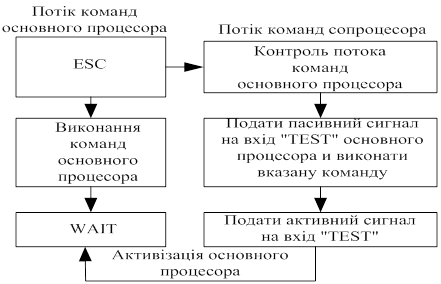
Малюнок 3. Алгоритм функціонування співпроцесорної конфігурації
1.2 Сильно зв'язана конфігурація
У цьому випадку обидва процесори працюють незалежно, але розділяють генератор синхронізації та логіку керування шиною.
Алгоритм меж процесорної взаємодії наведений на мал. 4.
Основний принцип взаємодії полягає у тому, що центральний процесор формує керуюче повідомлення в розділеній пам'яті й активізує незалежний процесор, посилаючи наказ в один з його портів. Потім незалежний процесор звертається до розділеної пам'яті, одержує відтіля призначену йому завдання й виконує її паралельно із центральним процесором. Формат повідомлення про завершення завдання звичайно обумовлений видом (архітектурою й призначенням ) незалежного процесора.
1.3 Слабко зв'язана конфігураціяУ слабко зв'язаних конфігураціях кожний центральний процесор має свою логіку керування шиною, а арбітраж шини досягається шляхом розширення цієї логіки й введення загальної для всіх провідних модулів зовнішньої логіки.
Переваги:
1. Система допускає модульне розширення. Кожний провідний модуль є незалежним пристроєм і звичайно це або окрема друкована плата або окрема мікросхема. Отже, такі модулі можна додавати або видаляти, не впливаючи на інші модулі в системі;
2. Відмова в одному модулі звичайно не викликає простою всієї системи, а модуль, що відмовив, можна легко знайти й замінити;
3. Кожний ведучий шини може мати локальну шину для доступу до відповідної пам'яті й пристроїв вводу/виводу, чим досягається високий ступінь паралельної обробки.
4. Особливість слабко зв'язаної конфігурації - наявність розвиненої логіки доступу до шини.
Три способи завдання пріоритетів:
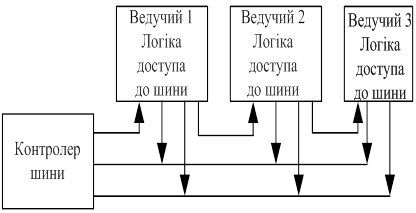
- пріоритетний ланцюжок (мал.5);
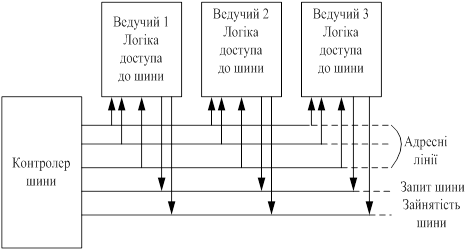
- опитування (мал.6);
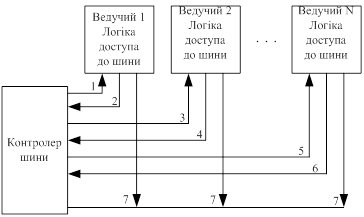
- незалежні запити (мал.7).
Пріоритет у випадку приоритетного ланцюжка визначається фізичним розташуванням модуля в системі, а якість – у мінімальному числі ліній керування, що не залежить від числа модулів у системі. Недолік ─ затримка поширення сигналу дозволу шини, що прямо пропорційна числу модулів у системі.
Пріоритет у випадку опитування – при появі сигналу "Запит шини " контролер генерує послідовність адрес модулів. Коли запитуючий модуль розпізнає свою адресу, він формує активний сигнал " Зайнятість шини ". Вартість - динамічна зміна пріоритетів провідні шини.
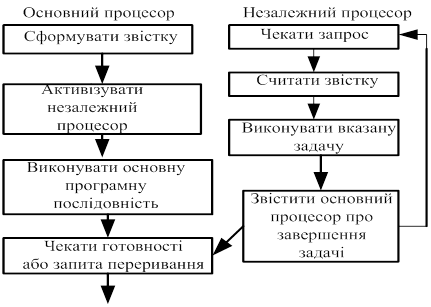
Малюнок 4 . Алгоритм між процесорної взаємодії
Малюнок 5. Пріоритетний ланцюжок
Малюнок 6. Опитування.
мультипроцесорний конфігурація архітектура схема
Малюнок 7. Незалежні запити
Пріоритети враховуються паралельно. Кожний модуль має окрему пару ліній запиту шини (2,4,6) й дозволи шини (1,3,5) й кожній парі призначений свій пріоритет, що перебуває в контролері. Дешифратор пріоритетів вибирає запит з максимальним пріоритетом і повертає відповідний сигнал дозволу шини. Арбітраж реалізується дуже швидко й не залежить від числа модулів у системі. Вада - максимальна швидкодія. Недолік - велика кількість ліній запиту та дозволу шини ( для n модулів необхідно 2n ліній).
2. Архітектура ММПС із загальною і розподіленою пам'яттю
До першого класу з загальною (поділюваною) пам'яттю відносяться ММПС, у якій кількість процесорних елементів ≤ 32 і тому що в системі усього одна пам'ять з тим самим часом доступу, ці обчислювальні системи іноді називаються UMA (Uniform Memory Access).
До другого класу (з розподіленою пам'яттю) відносяться системи в яких, крім загальної пам'яті, існує і визначений обсяг власної (локальної ) пам'яті, доступ до якої можуть мати всі процесорні елементи, що входять у систему.
3. Протоколи взаємодії (забезпечення когерентності кеш-пам'яті) ММПС – MESI, DASH 3.1 Стратегія запису в кеш-пам'яті (К-П) При роботі з К-П операції читання складають близько 90 % і близько 10 % - операції запису. Читання блоку починається відразу, як тільки стає доступним адреса блоку. При читанні з улученням блок негайно відправляється в процесор. При записі процесор визначає розмір запису (від одного до 8 байт) і тільки ця частина може бути змінена Ця операція називається читання-модифікація – запис. При читанні здійснюється читання оригіналу блоку, при модифікації – модифікація частини блоку при необхідності – при записі запис нового значення блоку. Модифікація не може починатися доти, поки не переконаємося у влученні. Операція запису займає більше часу, чим читання і тому організація К-П у різних архітектурах відрізняється саме стратегією виконання запису.
- Наскрізний запис – запис здійснюється відразу в К-П і блок більш низького рівня ( К-П другого рівня чи основну пам'ять).
- Запис зі зворотним копіюванням. Інформація записується тільки в блок К-П. Модифікований блок К-П записується в основну пам'ять тільки у випадку його заміни. Для цього необхідно наявність біта модифікації блоку К-П. Якщо цей біт не встановлений, то зворотне копіювання скасовується.
Для мультіпроцесорних систем запис зі зворотним копіюванням більш краща, тому що операції запису виконуються зі швидкістю К-П і кілька записів в один блок вимагає тільки одного запису в пам'ять більш низького рівня і тим самим звільняється системна шина. Наскрізний запис має перевагу в тім, що основна пам'ять завжди має найбільш свіжу копію даних. Це дуже важливо і для ММПС і для організації вводу/виводу.
Недоліки методу зворотного запису:
- Усі змінені блоки повинні бути переписані в основну пам'ять перед тим, як інший пристрій зможе одержати до них доступ;
-У випадку відключення напруги, коли вміст К-П губиться, а вміст основної пам'яті зберігається, не можна визначити які місця в основній пам'яті містять застарілі дані.
Існує категорія застарілих даних, що з'являються в тому випадку, коли К-П використовується в системі з основною пам'яттю і двома-трьома задатчиками. Два пристрої копіюють розділ пам'яті і перший пристрій обновляє його першим, а коли другий пристрій робить запис своєї копії розділу, то руйнує всі зміни, зроблені першим пристроєм, тим самим порушується погодженість К-П.
Основними методами забезпечення погодженості (когерентності К-П є наступні методи.:
- очищення К-П. При цьому змінені дані записуються в основну пам'ять, а К-П очищається. Якщо всі К-П у системі очищаються перед операцією запису пристроями в пам'ять спільного користування, то можливість появи застарілих даних у будь-який К-П виключається. Головний недолік цього методу – наступні за очищенням звертання до К-П будуть кєш-промахами доти, поки К-П заповниться новими даними;
- апаратна прозорість. Усі записи проходять через єдину К-П;
- кожен запис обновляє основну пам'ять і всі К-П, що розділяють цю пам'ять;
- некэшуєма пам'ять – використання основної пам'яті для декількох пристроїв як некэшуємої, тобто всі звертання до основної пам'яті є кэш-промахами.
Продуктивність К-П визначається через середній час доступу до К-П рівного часу звертання при влученні + частка промахів х утрати.
У процесорах, використовуваних у мультіпроцесорних конфігураціях, застосовується більш складний протокол MESI (Modified, Exclusive, Shared, Invalid) організації К-П зі зворотним записом, що запобігає зайвим передачам даних між К-П і основною пам'яттю. Для ММПС, у яких пам'ять фізично розподілена між процесорними модулями, ідентичність даних у К-П (погодженість, когерентність) різних модулів підтримується за допомогою меж модульних пересилань. Порядок роботи абонентів на системній шині при використанні протоколу MESI полягає в наступному. Усі дії з використанням транзакцій шини мікропроцесора і зовнішніх пристроїв з копіями рядків як у К-П так і в основній пам'яті доступні для відстеження всіма мікропроцесорами. Це є наслідком того, що в кожен момент часу передає тільки один, а сприймають усі підключені до шини абоненти. Однак, якщо для об'єднання мікропроцесорів використовується не шина, а інший елемент комутаційного середовища, то для працездатності протоколу MESI необхідно дотримувати порядок виконання транзакций, щоб вони були доступні іншим мікропроцесорам.
Визначення протоколу – кожен рядок К-П мікропроцесора може знаходитися в одному з наступних станів:
М – рядок модифікований, тобто доступний по читанню/запису тільки в цьому мікропроцесорі, тому що змінений операцією запису в порівнянні з рядком в оперативній пам'яті;
Е – рядок монопольно - копійований (тобто доступний по читанню/запису як у цьому мікропроцесорі так і в основній пам'яті);
S – рядок множинно - копійований чи поділюваний ( доступний операціям читання/запису як у цьому мікропроцесорі, в оперативній пам'яті й у К-П інших мікропроцесорів, у яких міститься його копія);
I – рядок неможливий до використання (недоступний операціям читання/запису).
Прямолінійний підхід до забезпечення когерентності К-П у ММПС полягає в тому, що при кожнім невлученні в К-П у будь-якому процесорі ініціюється запит необхідного рядка з того блоку пам'яті, у якому цей рядок розміщений. Надалі цей блок стосовно рядка буде називатися резидентним. Запит передається через комутатор у модуль з резидентним для рядка блоком пам'яті, з якого необхідний рядок пересилається в модуль, у якому відбулося невлучення. При цьому, у кожнім модулі для кожного резидентного рядка ведеться список модулів, у К-П яких цей рядок розміщається. Рядок, розміщений у К-П більш ніж одного модуля, називається поділюваним. .
Алгоритм забезпечення когерентності.
При записі даних у К-П процесор припиняється доти, поки змінений рядок К-П пересилається в резидентну пам'ять модуля. Якщо цей рядок був поділюваним, він пересилається з резидентної пам'яті в усі, зазначені в списку модулів, модулі. Після одержання підтверджень про зміну всіх необхідних рядків мікропроцесор продовжує роботу. Даний алгоритм дає великі простої при операції запису в К-П.
Алгоритм DASH.
Кожен модуль має для кожного рядка, резидентного у модулі, список модулів, у К-П якого розміщені копії рядків.
Кожен рядок (у резидентном для нього модулі) має три можливих глобальних стани:
- « некєшуємий», якщо копія рядка не знаходиться в К-П якогось іншого модуля , крім резидентного для цього рядка;
- «віддалена-роздільна», якщо копії рядка розміщені в К-П в інших модулів;
- «віддалена -змінена», якщо рядок змінений операцією запису в якомусь модулі.
Існують три локальних стани рядка:
- неможлива до використання;
- поділювана – якщо є незмінена копія в інший К-П;
- змінена, якщо копія змінена операцією запису.
При читанні процесором зі своєї К-П рядка (поділюваного чи зміненого) у випадку його відсутності або неможливості використання здійснюється запит ²промах читання² у резидентний для цього рядка модуль. Для глобального стану рядка:
- некэшуємий чи віддалено-роздільний – копія рядка посилається в модуль, що запросив, а сам модуль міститься в список модулів;
- “ віддалено- змінений” – запит “промах читання” перенаправляеться у модуль, що містить змінений рядок. Цей модуль пересилає необхідний рядок у модуль, що запросив, і в модуль, резидентний для цього рядка . У резидентнім модулі для цього рядка встановлюється стан “ відалено - роздільний”.
Якщо процесор здійснює операцію запису, а стан рядка в який записуємо – “змінений”, то запис виконується. Якщо рядок неможливий до чи використання “поділюваний”, то модуль посилає в резидентний для рядка модуль запит на захоплення у виняткове використання цього рядка і припиняє виконання запису до одержання підтвердження, що всі інші модулі, що розділяють з ним розглянутий рядок, перевели його копію в стан “неможливий до використання”.
Стан рядка “некэшуємий” – він відсилається модулю, що запросив, і він продовжує припинені обчислення.
Стан рядка “ віддалений-роздільний”, резидентний модуль розсилає за списком модулів , що мають копію цього рядка, запит на перехід цих рядків у стан “неможливий до використання”. Після одержання цього запиту кожний з модулів змінює стан своєї копії рядка на “ неможливий до використання” і посилає підтвердження виконання в модуль, що ініціював операцію запису. При цьому в припиненому модулі рядок після запису переходить у стан “віддалено - змінений”.
У системах, що використовують комутатор з тимчасовим поділом (шину), інтерфейс із шиною кожного модуля “прослуховує” усі передачі по шині, тому немає необхідності вести списки модулів, що розділяють рядки. К-П зі зворотним записом створює менше навантаження на шину процесора і забезпечує велику продуктивність, однак контролер для такого типу К-П значно складніше. При виборі способу організації К-П необхідно, крім апаратної реалізації, враховувати особливості генерації програм компілятором (одержання файлів з расширенням .map ). Це має на увазі локальне розташування кодів операцій і даних після компіляції. Тому що області пам'яті програм і пам'яті даних різні і до них відбувається одночасний доступ, то для підвищення паралеллизма при роботі з пам'яттю роблять окремі К-П команд і К-П даних.
Використані джерела
1. Ю-Чжен Лю, Г.Гибсон Микропроцессоры семейства 8086/8088 М.: Радио и связь, 1987.
2. Б.В.Шевкопляс Микропроцессорные структуры. Инженерные решения М.: Радио и связь, 1990
3. В.Шевкопляс Микропроцессорные структуры. Инженерные решения. Дополнение первое. М.: Радио и связь, 1993
4. М.Гук Аппаратные средства IBM PC С.Петербург ²Питер² 2000
5. В.Корнеев, А.Киселев Современные микропроцессоры Санкт-Петербург ² БХВ – Петербург ² 2003
6. Локазюк В.М. и др Микропроцессоры и микроЭВМ в производственных системах Киев Издательский центр ² Академия ² 2002
7. Гуржий А.М. и др Архитектура, принципы функционирования и управления ресурсами IBM PC Харьков, 2003
8. В.В.Сташин, А. В. Урусов, О.Ф. Мологонцева Проектирование цифровых устройств на однокристальных микроконтроллерах Л. Энергоатомиздат
9. Под ред.А.Д.Викторова Руководство пользователя по сигнальным микропроцессорам семейства ADSP-2100 Санкт- Петербургский государственный электротехнический университет. Санкт- Петербург 1997
10. М.Предко Руководство по микроконтроллерам в 2-х томах М: Постмаркет, 2001
Похожие работы
... 4. Як графічно позначаються польові транзистори? Інструкційна картка №9 для самостійного опрацювання навчального матеріалу з дисципліни «Основи електроніки та мікропроцесорної техніки» І. Тема: 2 Електронні прилади 2.4 Електровакуумні та іонні прилади Мета: Формування потреби безперервного, самостійного поповнення знань; розвиток творчих здібностей та активізації розумово ...
не вдаючись в побудову графу станів та таблиці переходів, легко розрахувати схему ПК (мал. 3), робота якої зрозуміла без пояснень.& TR Т _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ D | ПК | | | V | | T | | ...
грам, особливо драйверів різних пристроїв, основними вимогами до яких є висока швидкодія і компактність. Знання мови асемблер і результуючого машинного коду дає розуміння архітектури ЕОМ, що не забезпечується при програмуванні мовою високого рівня. Мови високого рівня створювалися для того, щоб програмувати переважно без обліку технічних особливостей конкретних комп'ютерів, асемблер же оріє ...
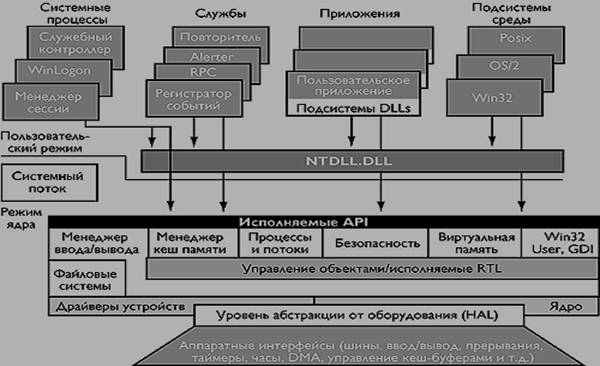
... і додатки, такі як Mіcrosoft SQL Server і Exchange Server, також включають компоненти, що працюють як служби NT. · Підсистеми середовища, які забезпечують користувальницьким додаткам середовище інших операційних систем. Wіndows NT поставляється із трьома підсистемами: Wіn32, Posіx і OS/2 2.1. · Користувальницькі додатки одного з п'яти типів: Wіn32, Wіndows 3.1, MS-DOS, Posіx або OS/2 ...
0 комментариев