Пояснювальна записка до курсової роботи: 50 сторінок, 31 рисунок, 9 літературних джерел.
Метою роботи є вивчення мережевої моделі даних, її особливостей та відмінностей від реляційної моделі. Об’єкт дослідження – це мережева модель даних, а предмет – реалізація бази даних факультету на основі цієї моделі.
Дослідження мережевої моделі та власне побудова бази даних проводилися в інструментальній системі управління базами даних CronosPRO, яка забезпечила використання всіх необхідних засобів проектування БД. У ході роботи було розроблено кілька моделей даних: концептуальну, логічну та фізичну, вивчені механізми переходу від одного рівня проектування до іншого.
Практичним результатом даної роботи є готова функціонуюча база даних факультету, що має у підпорядкуванні кілька кафедр, на яких працюють викладачі, викладаючи різні предмети різним академічним групам. Кожен зі студентів групи отримує оцінки з різних предметів, які також фіксуються у базі. База даних заповнена реальними даними, протестована та готова для роботи.
Робота є актуальною, оскільки вивчення мережевих моделей на рівні з більш сучасними реляційними є розширенням кругозору програміста, збільшення його досвіду та знань щодо розв’язань задач альтернативними засобами.
МЕРЕЖЕВА МОДЕЛЬ ДАНИХ, РОЗРОБКА БАЗИ ДАНИХ, CODASYL-СИСТЕМИ, ДІАГРАМА БАХМАНА, ГРАФОВІ СТРУКТУРИ.
ЗМІСТ
ЗАВДАННЯ ДО КУРСОВОЇ РОБОТИ
ВСТУП
1 Мережева модель даних
1.1 Місце мережевої моделі у класифікації
1.2 Математична основа мережевої моделі
1.3 Структури даних мережевої моделі
1.4 Операції над даними у мережевій моделі
1.5 Архітектура СУБД на основі мережевої моделі
1.6 Висновки
2 Інструментальна система управління базами даних CronosPRO
2.1 Загальна характеристика системи
2.2 Засоби управління ІСУБД
2.3 Захист та відновлення інформації у ІСУБД
2.4 Оптимізація роботи системи
2.5 Висновки
3 Реалізація бази даних факультету засобами ІСУБД CronosPRO
3.1 Постановка задачі
3.2 Проектування бази даних
3.2.1 Концептуальна модель даних
3.2.2 Логічна модель даних
3.2.3 Фізична модель даних
3.3 Тестування бази даних
ВИСНОВКИ
ПЕРЕЛІК ПОСИЛАНЬ
ВСТУП
Основа роботи в області комп'ютерних наук – це інформація. Під цим поняттям ми звикли розуміти будь-які відомості про предмети та явища навколишнього середовища – усього, що заслуговує на увагу окремої людини або підприємства.[1, с.46] Зрозуміло, що для зручного користування такою кількістю інформації, яку має людство на сьогодні, потрібна якнайкраща організація її зберігання та обробки. Лише у такому випадку нагромаджена купа знань перетворюється на дані, з якими набагато легше працювати як людині, так і обчислювальній машині.
Сучасні інформаційні технології мають достатній набір інструментів для роботи з даними – ряд файлових систем, мережі зберігання даних, хмарні сховища. Проте коли мова йде про високу швидкість обробки, необхідність упорядкування, постійне оновлення постійних масивів даних, зазвичай звертаються до баз даних – сукупності даних, що відображає стан об'єктів та їх відношення у предметній області.[2,с.6] Саме таке представлення інформації дозволяє знизити затрати праці, зменшити використання ресурсів та забезпечити актуальність даних.
Для створення, керування та користування базами даних застосовують диспетчери, сервери або системи управління базами даних (СУБД), що являють собою сукупність лінгвістичних та програмних засобів. Вони виступають посередниками між фізичними даними, що зберігаються на комп'ютері, та користувачем, що надсилає запити, таким чином приховуючи від нього подробиці роботи апаратного забезпечення. [1, с.48]
Такі системи різняться за способом доступу (локальні та розповсюджені), ступенем розподіленості (файл-серверні, клієнт-серверні, вбудовані). Проте ми будемо звертати увагу перш за все на їх основу – моделі даних, тобто певну теорію представлення та обробки інформації. В залежності від того, на якій моделі ґрунтується СУБД, говорять про її тип.
Значна частина сучасних СУБД здатна працювати на комп'ютерах різної архітектури під керівництвом різноманітних операційних систем. Вони спираються на встановлені стандарти як при визначенні та маніпуляції даними, так і при їх передачі між собою.[2, с.7]
Багато наявних систем належать до так званих мережевих СУБД, що призначені для підтримки багатокористувацького режиму роботи з базою даних і можливості децентралізованого зберігання даних. Вони мають розвинені засоби адміністрування баз даних, засобів захисту інформації та підключення клієнтських додатків. Прикладами таких систем є Caché, Cerebrum, dbVista, GT.M, CronosPRO. Саме остання буде використана у нашій роботі як засіб розв'язання задачі.
Робота складається з трьох розділів. Перший розділ містить теоретичний матеріал, зокрема тут розглядаються особливості та математичні підґрунтя мережевої моделі, її переваги та недоліки у порівнянні з ієрархічними та реляційними моделями. У другом розділі зібрані відомості про головні характеристики та можливості у ІСУБД CronosPRO. Третій розділ є практичною частиною і описує процес та результат проектування конкретної бази даних факультету.
1 Мережева модель даних
1.1 Місце мережевої моделі даних у загальній класифікації
Однією з основних категорій теорії баз даних є модель даних. Вона являє собою формалізований опис структури одиниць інформації та операцій над ними в інформаційній системі. [2, с.45]
Дейт дає наступне визначення моделі даних: «Модель даних – це абстрактне, самодостатнє, логічне визначення об’єктів, операторів та інших елементів, що у сукупності складають абстрактну машину доступу до даних, із якою взаємодіє користувач». Фізичне ж її втілення на реальній машині є реалізацією [1, с.57]
Характерна риса моделі даних – це відображення найважливіших функціональних аспектів виділеної предметної області та ігнорування другорядних.
Модель даних включає в себе набір понять для опису даних, зв'язків між ними та обмежень, що накладаються на дані. Вона має три головні складові:
· структурну частину, що визначає правила породження допустимих для даної СУБД видів структур даних;
· керуючу частину, що визначає можливі операції над такими структурами;
· класи обмежень цілісності даних, які можуть бути реалізовані засобами цієї системи.
Таким чином, уся різниця між моделями полягає у виборі структури даних і доступних користувачеві дій над ними.
Кожна СУБД підтримує ту чи іншу модель даних. По суті модель даних, що підтримується механізмами СУБД повністю визначає множину конкретних баз даних, як можуть бути створені засобами цієї системи, а також способи модифікації станів БД з метою відображення тих змін, що відбуваються у предметній області. Отже, на вибір моделі даних неодмінно впливає і предметна область, у якій вона буде застосовуватися.
Одним із найперших застосувань баз даних, основаних на мережевій моделі, були корпоративні системи. Корпоративна інформація передбачала записи про продажі та закупки, дані про залишки на рахунках внутрішнього бухгалтерського обліку або персональних відомостей про службовців. Запити до таких баз даних дозволяють отримувати інформацію про стан рахунків, виплатах співробітникам тощо. Кожна операція купівлі-продажу, доходу-витрат, прийому співробітника на роботу, його кар’єрне просування чи звільнення призводить до зміни відповідних елементів даних. Саме такі запити легко реалізовувалися у СУБД, побудованих на основі мережевої моделі даних. [3, c.33]
На початку свого існування мережева модель спиралася на тоді вже звичну – ієрархічну. Вона створювалася для представлення більш складних взаємозв’язків між даними, ніж ті, що можна було моделювати за допомогою ієрархічних структур, а також для формування стандарту баз даних. Для створення таких стандартів у 1965 році на конференції CODASYL (Conference on Data System Languages) була організована робоча група, що отримала назву Data Base Task Group (DBTG). Окрім іншого ця група запропонувала стандартизувати такі дві мови: DDL (Data Definition Language), DML (Data Manipulation Language), на основі яких побудована більшість СУБД першого покоління. [4, c.57]
Таким чином, поява мережевої моделі даних значно вплинула на розвиток тодішніх інформаційних технологій, у тому числі і на виникнення нових моделей.
Узагальнюючи різноманіття моделей, що існують на сьогодні, можна виділити три основні типи: об'єктні, фізичні та моделі даних на основі записів (рис. 1). Остання категорія передбачає створення бази даних з декількома записами різних типів. Класично вона поділяється на два типи: теоретико-графові та теоретико-множинні моделі. До першого належать мережева та ієрархічна моделі, до другого – реляційна. Відмінність у структурі відповідно вимагає і застосування різних операцій. Теоретико-графові моделі використовують апарат навігації - переходу від попереднього до наступного об'єкту. Теоретико-множинні послуговуються математичним апаратом, для них характерна реляційна алгебра та реляційне числення.
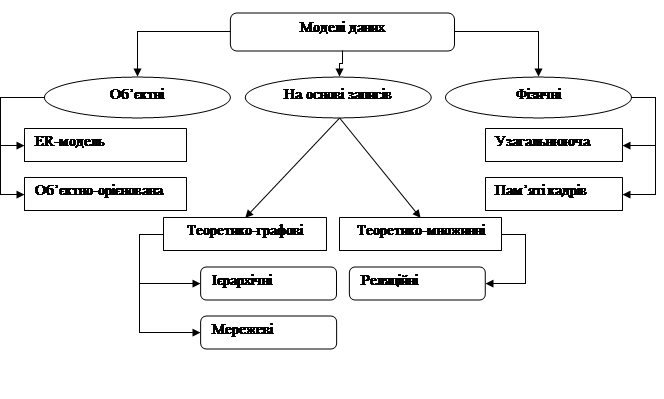
Рисунок 1 – Класифікація моделей даних
1.2 Математична основа мережевої моделі
На відміну від реляційної моделі, що відноситься до теоретико-множинного типу і представляє відповідно множину істинних висловлювань, мережева модель як представниця теоретико-графової категорії спирається на таку математичну структуру як граф – сукупність вершин та ребер між ними. В контексті моделей даних вершини виступають у ролі об'єктів, тоді як ребра – це зв'язки між об'єктами. Оскільки у мережі важливе не лише існування зв'язків, а їх напрямок, то необхідно розглядати не довільний, а орієнтований граф (рис.2).
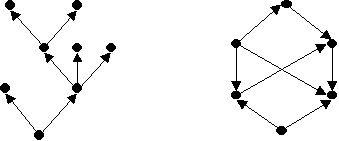
Рисунок 2 – Приклади орієнтованих графів
Через степінь вершини представляється показник кардинальності зв'язку, тобто кількість можливих зв’язків для кожного екземпляру сутності, що приймає участь у зв’язку. Для бінарних зв’язків він може набувати наступних значень:
· «один до одного»(1:1),
· «один до багатьох» (1:N),
· «багато до багатьох» (M : N).
Перший вид зв’язку у випадку графа означає, що одна вершина з’єднана лише з однією вершиною. Другий вид передбачає з’єднання однієї вершини з багатьма іншими вершинами. У третьому випадку кожна вершина з’єднується з багатьма вершинами. Що стосується мережевої моделі, то у ній точно можливі перші два варіанти. Класичні джерела, такі як [1], [2], на цьому і зупиняються, проте сучасні дослідники, наприклад [3], [5], наполягають на існуванні ще й зв’язку M:N, при цьому вказуючи на те, що саме існування такого зв’язку є характерною відмінністю мережевої моделі від ієрархічної. Дійсно, ієрархічна модель не може реалізовувати сюр’єктивний зв’язок, оскільки утворення циклів суперечить її математичній основі – дереву (графу без циклів) (рис.3). А мережева модель розширює можливості ієрархічної завдяки тому, що орграф у загальному випадку забезпечує існування багатьох зв’язків між багатьма вершинами. Інша справа, що реалізація зв’язку типу M : N вимагає особливого підходу – введення додаткових записів-зв’язків, яке дещо ускладнює розробку моделі.[5] У нашій роботі при побудові структур банку даних використано цей зв’язок, що доводить можливість його існування.
Слід зауважити, що найбільш розповсюдженими є зв’язки другого типу і тому найчастіше на практиці застосовуються частинні випадки графів, його різновиди. Звуження математичної категорії збільшує кількість обмежень, що накладаються на дані, а отже, спрощує алгоритм роботи з ними.
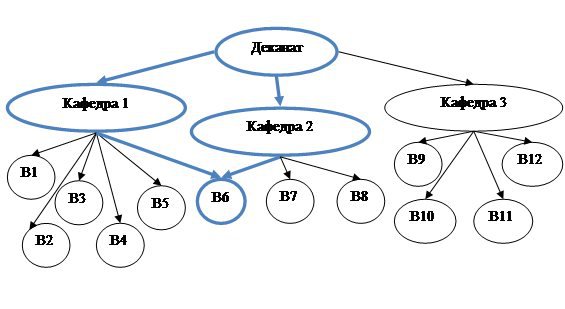
Рисунок 3 – Наявність циклу у графі, що відображає структуру деканату
Спираючись на властивості характерні для графа, ми отримаємо наступні способи представлення мереж:
· прості та багаторівневі списки суміжності,
· перерахування шляхів за вузлами та ребрами,
· вкладені набори та їх лінійна версія,
· дерева з частими вставками,
· бінарні дерева та інші.
Кожна з цих моделей має певні проблеми у реалізації, проте уважно розглянувши усі переваги та недоліки, можна підібрати найбільш оптимальну модель розв'язку конкретної задачі. Тим не менш всі вони обов'язково реалізовують основні операції, такі як пошук вершини, її переміщення, видалення, створення нової тощо. [6]
1.3 Структури даних мережевої моделі
Перш ніж розглянути структуру даних мережевої моделі, слід ознайомитися із її термінологією, оскільки вона має декілька відмінностей від термінології сучасних, реляційних систем.
Елемент даних – це іменоване поле (або підпорядковане поле). Іменована сукупність підпорядкованих елементів називається групою (агрегатом). Тип запису – це іменована група елементів даних, а тип набору – іменований зв’язок типу 1:N між двома типами записів.[3, с.1028]
Як стало зрозуміло з визначень, найменшою інформаційною одиницею даних є елемент даних. Кожен елемент даних має власне ім’я та формат, тобто тип даних. Вони можуть об’єднуватися у групи (зазвичай за змістом). Наприклад, місто, вулиця і будинок є елементами даних, проте їх можна об’єднати в одну групу з ім’ям «адреса». Групи можуть об’єднувати не лише окремі елементи даних, а й інші групи, наприклад, група «відмітка» (timestamp) об’єднує дві групи – групу «час» і групу «дата», які в свою чергу містять елементи години, хвилини, секунди і день, місяць, рік відповідно (рис. 4). Групи є не обов’язковими у проектуванні, проте вони значно полегшують розробку бази даних та доступ до даних, об’єднуючи їх у смислові сукупності.
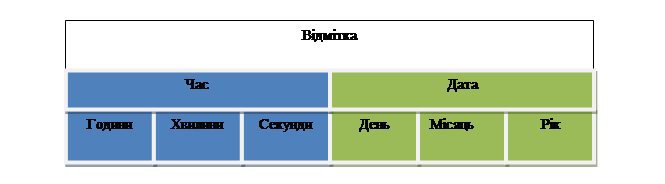
Рисунок 4 – Об’єднання елементів даних у групи
Елемент даних і групи – це два конструктивних елементи, з яких будуються інші складніші структури. Такою структурою є тип запису – сукупність елементів даних або їх груп. На діаграмах вони відображаються у вигляді окремих прямокутників, що містять ім’я цих типів записів. Окремі їх значення називаються екземплярами.
Інтраструктурою називається структура, що знаходиться усередині типу запису. Окрім наведеної вище групи, у мережевих моделях також допускається визначення груп, що повторюються або таблиць. Наприклад, розглядаючи у якості типу запису замовлення, ми можемо визначити не одну, а декілька груп «товар», які будуть мати абсолютно однакову структуру: назву товару, його характеристики, ціна, кількість (рис. 5).
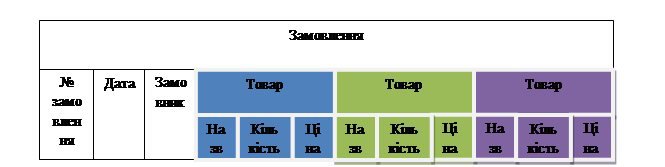
Рисунок 5 – приклад типу запису, який містить групи, що повторюються
Групи, що повторюються, можуть мати розмірність 1, 2 або 3. Доступ до їх елементів здійснюється за допомогою індексів.
Наступною складеною структурою є тип набору. Це іменований зв’язок «один до багатьох» (1:N), що встановлений між записом-власником і однією або декількома записами-членами. При цьому тип запису на стороні «один» є записом-власником, а тип запису на стороні «багато» – записом-членом. Приклад типу набору зображений на рисунку 6.
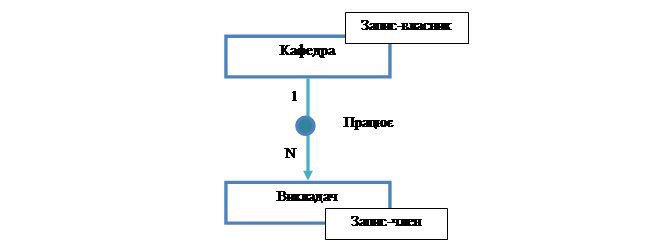
Рисунок 6 – Діаграма типу набору Працює (діаграма Бахмана)
Тип набору являє собою конструкцію, що підтримує роботу з інтраструктурами, тобто зі структурами усередині записів.
При створенні типів наборів необхідно враховувати наступні особливості:
· всі типи повинні мати ім’я;
· тип набору може мати декілька екземплярів;
· набір може бути пустим, тобто у ньому може знаходитися лише один запис-власник.
На рисунках 7 – 8 представлені замкнений ланцюг наборів і порожній набір.
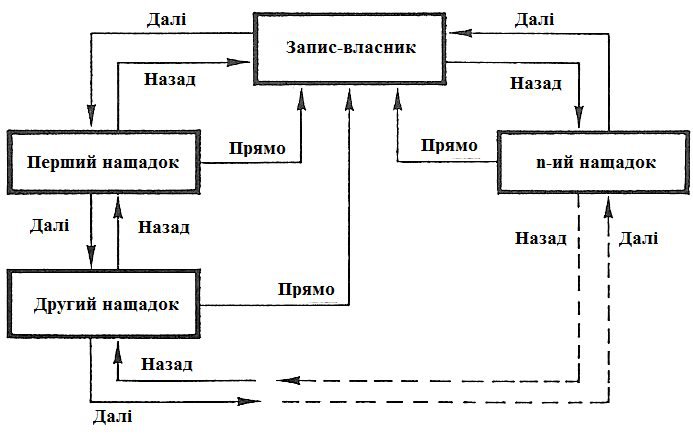
Рисунок 7 – представлення типу набору у вигляді замкненого ланцюга
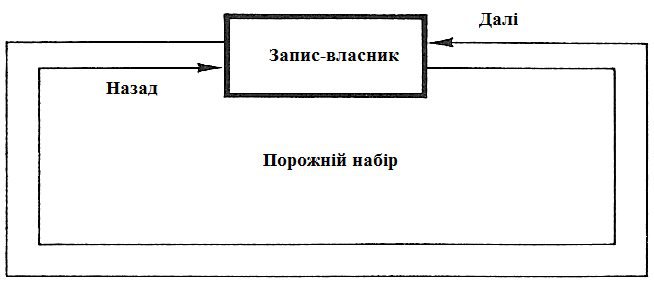
Рисунок 8 – представлення порожнього набору
Типи записів і набори використовуються для розробки структури бази даних. База даних – це поіменована сукупність екземплярів записів різного типу та екземплярів наборів, що містять зв'язки між ними. При її побудові слід мати на увазі перераховані нижче правила:
1. Тільки один тип запису може бути власником у кожному наборі, хоча один і той самий тип запису може бути власником у кількох різних типів наборів (рис. 9).
2. Один або більше типів записів можуть бути членами одного й того ж типу набору (багаточленного типу набору) (рис. 10) .
3. Тип запису може бути членом декількох типів наборів (рис. 11).
4. Тип запису може бути власником в одних типах наборів і членом в інших типах наборів (рис. 12).
5. Між будь-якими двома типами записів може бути визначена будь-яка кількість типів набору.
6. Типи набору можуть бути визначені так, що в результаті вони утворюють циклічну структуру.
7. Запис необов’язково повинен бути членом двох екземплярів одного й того ж типу набору.
8. Тип запису необов’язково повинен бути членом будь-якого типу набору (окремий тип запису).
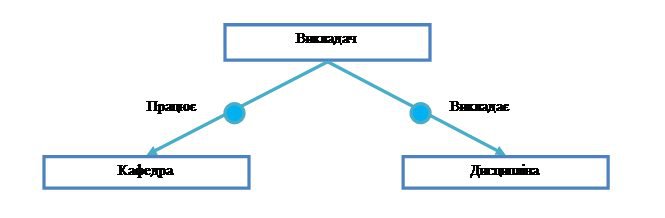
Рисунок 9 – Тип запису Викладач є власником типів наборів Працює і Викладає
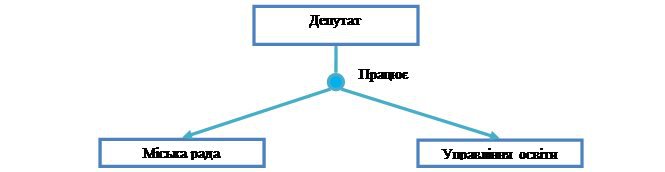
Рисунок 10 – Тип запису Депутат є власником типу набору Працює, який містить два типи записів Міська рада і Управління освіти
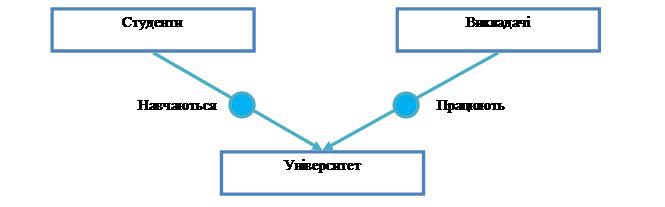
Рисунок 11 – Тип запису Університет є членом типів наборів Навчаються і Працюють
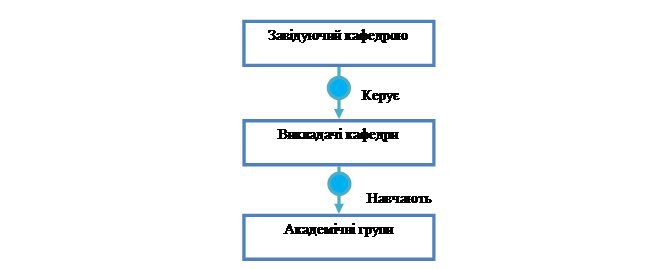
Рисунок 12 – Ієрархічна структура, у якій тип запису Завідуючий кафедрою володіє багатьма типами запису Викладачі кафедри, кожен з яких володіє багатьма типами запису Академічні групи
Шосте правило, що передбачає циклічність, також уможливлює рекурсивний зв’язок. Він виникає у тому випадку, коли екземпляр типу запису приймає участь у зв’язку з іншим екземпляром того ж типу запису. Рекурсивні зв’язки можуть мати тип 1 :1, 1: N, M:N. Наприклад, серед викладачів кафедри є один, який займає посаду завідуючого кафедрою і керує рештою викладачів. На рисунку 13 цей зв’язок показаний у вигляді діаграми Бахмана.
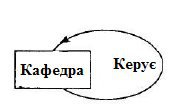
Рисунок 13 – Рекурсивний зв'язок типу 1: N
1.4 Операції над даними мережевої моделі
Для маніпулювання над даними визначений ряд типових операцій, що діляться на дві групи: навігаційні операції та операції модифікації.
Навігаційні операції здійснюють переміщення базою даних по зв'язкам, що визначені у схемі бази даних. За допомогою цих операцій визначається поточний запис. До таких операцій відносяться:
1. Знайти конкретний запис у наборі однотипних записів і зробити його поточним.
2. Перейти до наступного запису у деякому зв'язку.
3. Перейти від запису-власника до запису-члена у деякому наборі.
4. Перейти від запису-члена до власника за деяким зв'язком.
Операції модифікації здійснюють як додавання (видалення) нових екземплярів окремих типів записів, так і екземплярів нових наборів, модифікацію окремих компонентів самого запису.
Для реалізації цих операцій деталізується поточний стан шляхом запам'ятовування трьох його складових: поточного набору, поточного типу запису, поточного екземпляру типу запису.
Можливі такі операції:
1. Витягнути поточний запис у буфер прикладної програми для обробки.
2. Змінити у витягнутому записі значень вказаних елементів даних.
3. Запам'ятати запис із буфера у базу даних.
4. Створити новий запис.
5. Видалити запис.
6. Включити поточний запис у поточний екземпляр набору.
7. Виключити поточний запис з поточного екземпляру набору.
1.5 Архітектура СУБД на основі мережевої моделі даних
Одним із найважливіших аспектів розвитку СУБД є ідея відділення логічної структури БД і маніпуляцій даними, необхідними користувачам, від фізичного представлення, якого потребує комп’ютерне обладнання.
Одна й та сама БД в залежності від точки зору може мати різні рівні опису. За числом рівнів опису даних, що підтримуються СУБД, розрізняють одно-, дво- і трирівневі системи. Сьогодні найчастіше підтримується трирівнева архітектура опису БД, з трьома рівнями абстракції, на яких можна розглядати базу даних. Така архітектура включає:
· зовнішній рівень, на якому користувачі сприймають дані, де окремі групи користувачів мають своє представлення на базу даних;
· внутрішній рівень, на якому СУБД і операційна система сприймають дані;
· концептуальний рівень представлення даних, призначений для відображення зовнішнього рівня на внутрішній рівень, а також для забезпечення необхідної їх незалежності один від одного; він пов'язаний з узагальненим представленням користувачів.
Комітет CODASYL DBTG запропонував свій варіант структури СУБД, який схематично представлений на рисунку 14. З цього рисунку видно, що кінцеві користувачі здійснюють доступ до бази даних за допомогою прикладної програми на базовій мові (зазвичай це COBOL). Для того щоб здійснити доступ до інформації у базі даних, кожна прикладна програма повинна використати деяку підсхему, яка є обмеженим представленням структури усієї бази даних. Декілька програм можуть паралельно використовувати одну й ту саму підсхему, проте кожна програма може використовувати тільки одну підсхему. Більше того, підсхема визначається тільки на одній схемі, але вона може перекривати іншу підсхему. CODASYL–сумісна СУБД може підтримувати декілька різних баз даних, структура кожної з яких визначається власною схемою.
Схема і підсхеми визначаються з допомогою різноманітних DDL–мов (мова SSDDL є декларативним розширенням мови програмування.) Визначивши схему з допомогою мови SDDL, перш ніж вона зможе використовуватися СУБД, її необхідно транслювати з вихідної форми в об’єктну. Після цього вихідне визначення кожної підсхеми також повинно бути трансльовано з перетворенням в об’єктну форму – тільки після цього воно зможе використовуватися прикладною програмою.
Зазвичай усередині прикладної програми повинно міститися тимчасове сховище, яке призначено або для зберігання даних, що витягуються з допоміжного джерела зберігання, або для розміщення даних перед їх збереженням. У програмі на мові COBOL це досягається за рахунок указування відповідних типів записів у розділі оперативного запам’ятовуючого пристрою розділу даних. Тимчасове сховище необхідно і в тих випадках, коли програма працює з СУБД, оскільки тут також має місце обмін даними між прикладною програмою і базою даних. Використання підсхеми прикладної програми викликає неявне оголошення елементів цієї підсистеми у тимчасовому сховищі. Простір, зарезервований для елементів підсхеми, називається робочою областю користувача.
Фізична база даних охоплює записи, які зберігаються в одній або декількох областях, а самі області відображаються на фізичні файли. Одна область може покривати декілька файлів, а фізичний файл може містити декілька областей.
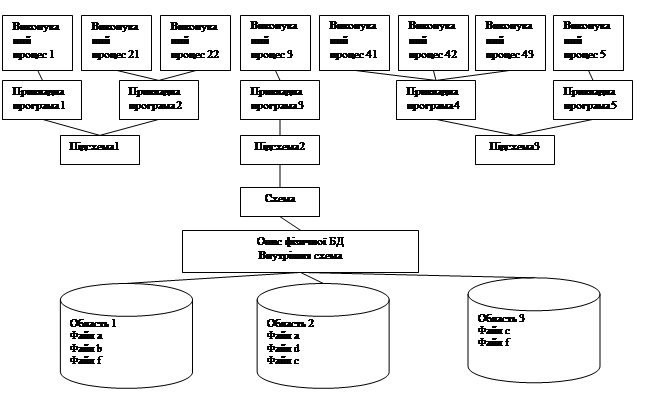
Рисунок 14 – Загальна архітектура CODASYL–сумісної СУБД
6. Висновки: переваги та недоліки мережевої моделі даних
Отже, враховуючи усі вищеперераховані особливості структури та будови мережевої моделі, можна виділити наступні її переваги:
· безпосередньо підтримує бінарні зв’язки і зв’язки більш високих ступенів типу 1:1 і 1:N;
· підтримує бінарні зв’язки та зв’язки більш високих степенів типу M:N з допомогою декомпозиції;
· підтримує рекурсивні зв’язки з допомогою декомпозиції;
· типи записів безпосередньо пов’язані один з одним з допомогою конструкції «тип набору»;
· цілісність на рівні посилань підтримується за рахунок конструкцій «тип набору»;
· доступ до типів записів здійснюється шляхом «переміщення» (навігації) структурою. У залежності від конкретного розміщення типу запису по відношенню до початкової точки у структурі, для доступу до даних можуть використовуватися різноманітні спеціальні команди.
Проте також слід відмітити, що мережева модель даних була створена на самому початку розвитку баз даних як засобі зберігання та обробки інформації. Тому її не можна назвати абсолютно досконалою. У порівнянні з більш сучасними реляційними системами мережева модель має низку недоліків, серед яких виділимо наступні:
· навіть для виконання простих запитів з використанням переходів і доступом до окремих записів необхідно створювати досить складні програми;
· незалежність від даних існує лише у мінімальному ступені;
· відсутність загальновизнаних теоретичних основ.
2 Інструментальна система управління базами даних CronosPRO
2.1 Загальна характеристика системи
ІСУБД CronosPro – це система, призначена для організації інформації у вигляді банків даних та їх подальшої обробки. Інформація зберігається в структурованому вигляді , тобто упорядкована певним чином. Структура банку визначається користувачем власноруч, залежно від поставлених перед ним. Структурованість даних дозволяє максимально точно наблизитися до опису предметної області, зробити зв'язки прозорими і легко контрольованими.
Всі накопичені дані обробляються швидко і зручно. Розвинений апарат пошуку використовує різні види порівняння і дозволяє виконувати запити будь-якої складності в тому числі по зв'язаним базам даних. Крім того, в ІСУБД CronosPro є можливість проводити пошук не тільки в рамках одного банку даних, але і по декільком банкам одночасно. Причому структури цих банків можуть значно відрізнятися. За результатами такого «глобального» ??пошуку може бути складений єдиний звіт.
У ІСУБД CronosPro спеціально розроблені засоби графічного аналізу зв'язків об'єктів. Такі засоби дозволяють виявляти неявні зв'язки між об'єктами, діями, подіями і т.д. Представлення даних, що мають складну структуру, в графічному вигляді значно спрощують роботу з інформацією.
Інша особливість ІСУБД CronosPro – надання користувачеві широких можливостей щодо забезпечення безпеки і цілісності даних. Спеціально розроблена система доступу дозволяє відстежити звернення до банку даних і виключити несанкціоноване отримання інформації. Система доступу має ієрархічну структуру і дозволяє розмежувати доступ аж до рівня окремих записів. Різні додаткові способи захисту забезпечують надійність зберігання і використання інформації.
ІСУБД CronosPro невимоглива до ресурсів і може працювати практично на будь-якому комп’ютері під управлінням Windows XP або вище. Нижче наводяться рекомендовані параметри конфігурації комп'ютера :
· операційна система: Windows ХР ( Service Pack 2 або вище) , Vista, 7, Server 2003/2008 ;
· вільне місце на жорсткому диску, не менше: 15 Мб;
· процесор , не нижче: Intel Pentium - 4 1,5 ГГц (або сумісний аналог) ;
· оперативна пам'ять , не менше: 256Мб для Windows ХР , 1GB для Windows Vista і Windows 7 , 2 GB для Server 2003 і Server 2008 ;
· мережева карта ( для роботи в мережі ) , з пропускною здатністю , не менше: 100 Мбіт /с.
Для роботи окремих режимів ІСУБД CronosPro потрібна наявність на комп'ютері наступних програмних продуктів :
· текстового редактора MS Word з пакету Microsoft Office версії 2003 або вище;
· табличного процесора MS Excel з пакету Microsoft Office версії 2003 або вище;
· браузера Windows Internet Explorer версії 7.0 або вище.
2.2 Засоби управління ІСУБД
Управління СУБД CronosPRO передбачає наступні пункти:
1. Проектування структури бази даних.
Під проектуванням розуміємо створення окремих баз даних, визначення їх властивостей та властивостей інфраструктури (полів), встановлення зв’язків між базами.
2. Створення словникових банків даних.
При використанні традиційної системи накопичення інформації, виникає безліч помилок, пов'язаних в першу чергу з нестандартизованого використовуваних понять, а часто і з помилками людини (такими як описка, пропуск букви і т.д.) Наприклад, при описі громадянства можна використовувати різні назви країн: Росія і Російська Федерація, Англія і Великобританія і т.д. Ймовірно, це може викликати плутанину і створити деякі проблеми при обробці інформації. Можна призначити кожній країні деякий унікальний код, але при його дублюванні в новому документі, знову виникає ймовірність помилки, наприклад, через неуважність людини.
Для виключення подібних ситуацій в ІСУБД CronosPro реалізована можливість створення словникових баз даних. Словникова база являє собою список всіх можливих значень деякого поля, яке має бути описано точно і однозначно. Наприклад, таке поле як «Громадянство». При використанні словникової бази, введення значення даного поля зводиться до простого вибору значення зі списку, який виводиться на екран. Такий список, тобто словникова база, попередньо заповнений тільки тими значеннями, які слід використовувати. У ІСУБД CronosPro словникову базу часто називають просто словником.
Часто під час роботи може знадобитися створити не одну словникову базу. Вони можуть зберігатися як в одному банку з іншими (НЕ словниковими базами), так і в окремому банку даних. Такий банк називають словниковим банком даних.
3. Введення та корекцію даних.
Після того як банк створений, описані бази даних, що входять у нього і для кожної бази визначені поля, можна приступити до накопичення в ньому інформації, тобто до введення записів.
Процес накопичення інформації включає в себе створення нового запису, заповнення необхідних полів (тобто власне введення інформації) і завантаження запису в банк даних. У ході завантаження виконується ідентифікація введеної інформації, її фізичне збереження в банку даних, перерахунок формул і оновлення необхідних індексних масивів.
Як правило, завантаження запису в підключений до системи банк виконується безпосередньо після завершення введення даних в її поля. Така організація процесу накопичення інформації отримала назву прямого (безпосереднього) введення.
Поряд з цим , в ІСУБД CronosPro існує спеціальний механізм, який дозволяє розділити етапи введення і завантаження інформації. В основі цього механізму лежить використання проміжного сховища інформації – так званого вхідного банку даних. Застосування вхідного банку дозволяє повною мірою реалізувати можливості системи з ідентифікації введеної інформації, забезпечити завантаження одноразово введеної інформації в кілька банків даних, а також у ряді випадків прискорити процес введення даних.
Як при використанні вхідного банку даних, так і при безпосередньому введенні інформації для створення нових і модифікації вже наявних записів можуть використовуватися такі режими:
· режим стандартного введення / корекції;
· режим введення з текстового файлу;
· режим введення / корекції за формою .
4. Створення та використання форм для введення даних.
Правильно спроектовані форми надають користувачеві зручний і наочний спосіб роботи з даними. Крім цього, форми виконують ще одну важливу задачу: вони надають в розпорядження розробника банку даних програмний механізм , що дозволяє реалізувати доступ до багатьох можливостей ІСУБД CronosPro без використання стандартного інтерфейсу користувача програми .
У поточних версіях ІСУБД CronosPro для введення, корекції та перегляду даних використовуються віконні форми. З точки зору користувача така форма являє собою звичайне вікно Windows, на якому розміщені об'єкти графічного інтерфейсу – елементи форми.
Існує два види елементів: елементи, що відображають вміст полів бази даних (елементи введення) та елементи управління, що використовуються для виконання дій , установки параметрів , графічного оформлення форми , а також для відображення інформації, непов'язаної з даними бази.
Віконні форми поділяються на два види:
· форми введення служать для введення значень в поля певної бази і можуть містити як елементи управління, так і елементи введення. З формою введення завжди пов'язаний певний набір записів бази, при цьому в кожний момент часу форма може відображати тільки один запис з цього набору (цей запис називається поточної) . Використовуючи спеціальний механізм , користувач може переходити від одного запису форми до іншої.
· керуючі форми призначені для виконання будь-яких дій, наприклад, для виклику інших форм, не мають пов'язаного набору записів і можуть містити тільки елементи управління.
5. Індексацію полів.
Якщо кількість записів у банку даних досить велике (близько декількох тисяч і більше), пошук інформації, навіть за допомогою запитів, може затягнутися. Справа в тому, що навіть автоматизований пошук інформації полягає в порівнянні кожної записи із заданим умовою пошуку. Виконання запиту можна прискорити, створивши індекс для поля, за яким здійснюється пошук. Процес створення індексів називається індексацією.
Індекс для системи – це предметний покажчик , в якому перераховані всі присутні в базі значення індексованого поля і для кожного такого значення вказані записи, в яких воно фігурує. Наприклад, якщо для бази даних, яка накопичує інформацію про клієнтів, створений індекс по полю «Прізвище», система створить для себе деяку подобу предметного покажчика, який міститиме приблизно таку інформацію: Іванов згадується в записах № 1, № 94 та № 1037; Петров згадується в записах № 46 та № 72 і т.д. Система буде звертатися до свого «предметного покажчику» , при пошуку інформації в банку даних, точно також як людина звертається до предметного покажчику в книзі. Це значно прискорить процес отримання результатів. Тому що для системи швидше переглянути невеликий список, в пошуках необхідного значення і потім перейти до потрібного запису, ніж зчитувати і аналізувати всі записи в базі.
6. Запити на пошук інформації та глобальний пошук зокрема.
ІСУБД CronosPro дозволяє не тільки накопичувати інформацію, а й забезпечує швидкий і ефективний доступ до даних за допомогою запитів. Запит в ІСУБД CronosPro – це спеціальний інструмент для швидкого відбору даних, відповідно з деякими умовами. За допомогою запитів можна відібрати з усього банку даних тільки необхідну інформацію.
Перед тим як виконати запит, необхідно задати умову пошуку. Результатом виконання запиту будуть записи, відповідні заданій умові. Більше того, тут само можна внести необхідні корективи в будь-яку з відібраних записів або провести зміни відразу у всіх відібраних записах, тобто провести масову корекцію.
7. Масова корекція даних.
З часом інформація, що зберігається у банку даних , може змінитися. Наприклад, може виникнути ситуація, коли, через перейменування міста, буде потрібно провести однотипну корекцію кілька десятків (і більше) записів. Причому в кожному записі буде змінюватися значення одного і того ж поля (наприклад , назва міста) . У цьому випадку, корекція «Вручну» , тобто послідовний пошук кожної такого запису і її зміна, зажадає великих часових витрат.
Для вирішення подібних завдань в ІСУБД CronosPro передбачений спеціальний режим масової корекції, що дозволяє внести зміни одночасно в усі відібрані в результаті запиту записи кореневої бази.
Даний режим призначений для корекції тільки простих полів (за винятком полів типу «Файл» і «Зовнішній файл»). Масова корекція складних полів неможлива.
8. Створення і використання шаблонів звітів.
Шаблон звіту являє собою звичайний документ RTF, оформлений відповідно до вимог користувача. Щоб документ міг використовуватися як шаблон, у нього вноситься спеціальна розмітка, яка вказує де і які дані повинні бути розміщені при видачі за шаблоном. При формуванні звіту система просто підставляє необхідні дані в указані за допомогою розмітки позиції шаблону. Отриманий у результаті звіт зберігає все оформлення вихідного шаблону.
9. Статистичні звіти.
Статистичний звіт – це інструмент для аналізу попередньо відібраної інформації і представлення результатів даного аналізу у вигляді двовимірної таблиці. Джерелом даних для статистичного звіту є певним чином налаштований запит за зразком. При виконанні такого запиту відбираються записи, що відповідають заданим умовам пошуку. Далі в осередках таблиці виконується аналіз відібраних записів – перевірка їх на відповідність умовами, накладеним на рядки і стовпці статистичної таблиці. Над записами, які задовольняють цим умовам, здійснюються заздалегідь певні дії (наприклад , підраховується число записів). На завершальному етапі результати аналізу видаються в MS Excel, де виконується їх додаткова обробка за допомогою формул.
У роботі зі статистичними звітом можна виділити наступні основні етапи:
· створення та проектування макета статистичного звіту. Проектування макета включає в себе налаштування структури і зовнішнього вигляду статистичного звіту, завдання умов аналізу, а також (при необхідності) налаштування властивостей статистичного звіту;
· створення і налаштування запиту за зразком, результати виконання якого будуть аналізуватись в статистичному звіті;
· виконання запиту за зразком і формування (обчислення) статистичного звіту на основі макета. Одноразово спроектований макет може використовуватися для формування статистичних звітів необмежену кількість разів.
2.3 Захист та відновлення системи СУБД
Контроль несанкціонованого доступу до даних є однією з найбільш важливих задач адміністратора системи. Без ефективного захисту даних, будь-який, в тому числі і сторонній, користувач може отримати доступ до банку даних. Результатом цього може бути як випадкова або умисна зміна інформації, що міститься в банку, так і її небажане використання. У ІСУБД CronosPro передбачені засоби захисту інформації, використовуючи котрі адміністратор може контролювати доступ до банків даних і системних ресурсів.
Система контролю доступу до даних передбачає використання наступних режимів:
1. Захист банку даних паролем.
У результаті встановлення пароля до банку, система кожного разу, перш ніж підключити банк, буде запитувати цей пароль. Таким чином, ніхто без знання пароля не зможе підключити банк даних до системи.
2. Захист системи і банку даних системним паролем.
Системний пароль встановлюється для всієї системи і для конкретних (захищених) банків даних. При підключенні до системи банку, захищеного системним паролем, автоматично перевіряється ідентичність системних паролів банку, що підключається і всієї системи. Якщо паролі не збігаються, банк не підключається до системи.
3. Захист банку даних шляхом розмежування прав доступу зареєстрованих в системі користувачів.
Після установки ІСУБД CronosPro, система автоматично створює одного користувача – адміністратора. Цьому користувачу за замовчуванням доступно виконання будь-яких дій над будь-яким з банків.
Під правами доступу розуміється набір можливостей користувача звертатися до тієї чи іншої інформації, що зберігається в банку даних, використовувати режими її обробки, передбачені в системі. Права доступу поділяються на 6 видів: доступ до структури; доступ до режимів; доступ до вихідних форм; доступ до форм; доступ до запитів за зразком; доступ до записів.
Права доступу визначаються для кожного користувача таким чином. Адміністратор створює для кожного виду доступу так звану схему доступу. Схема доступу – це опис конкретного набору прав користувача. Для схеми доступу до структури це буде перелік усіх доступних баз і їх полів; для схеми доступу до режимів – конкретних режимів; для схеми доступу до вихідних форм і форм введення – конкретних форм і т.д. Після того, як створені всі потрібні схеми доступу, адміністратор визначає кожному користувачеві, зареєстрованому в системі, конкретну схему доступу для кожного виду доступу. При цьому система автоматично створює для кожного виду доступу схему повного доступу («доступно все»), яка використовується за замовчуванням.
4. Реєстрація всіх дій користувачів у системному журналі.
Системний журнал являє собою банк даних спеціальної структури, що заповнюється системою автоматично і призначений для фіксації відомостей про дії користувачів і інші важливі події, що відбуваються в системі. Набір подій, що підлягають фіксації в системному журналі, визначається адміністратором ІСУБД.
Всі події, що фіксуються в системному журналі, можна розділити на дві великі групи:
· глобальні (загальні) події. Під глобальними розуміються події, що стосуються системи в цілому: створення та видалення користувачів; зміна прав доступу користувачів, створення банків і т.д. Фіксація глобальних подій виробляється завжди, коли включений системний журнал;
· події конкретного банку. До таких подій належать введення даних, виконання запитів, робота з вихідними формами і т.д. Події будь-якого банку фіксуються у системному журналі лише тоді, якщо це явно указано у налаштуваннях системного журналу для даного банку.
Всі перераховані вище режими можуть використовуватися як окремо, так і разом.
З ряду причин файли банку даних можуть бути пошкоджені (наприклад, при пошкодженні жорсткого диску) або видалені (наприклад, через необережність), в результаті чого підключення банку до системи виявиться неможливим. В такому випадку сам банк і всі його складові (дані, які зберігаються, а також створені для банку форми, запити за зразком, таблиці обміну тощо) будуть втрачені. Відновлення банку вручну (тобто створення нового банку, опис його структури, введення даних і т.д.) може зайняти дуже багато часу, особливо якщо обсяг втрачених даних досить великий. Єдиною можливістю швидкого і точного відновлення банку даних є використання створеної раніше резервної копії банку.
Для створення резервних копій банку в ІСУБД CronosPro передбачений спеціальний режим копіювання. Результатом роботи в даному режимі є файл з розширенням *.cpy, що містить повну копію банку.
У ІСУБД CronosPro передбачена можливість копіювання і відновлення не тільки власне банку, але і його складових: форм введення (керівних і вхідних форм); вихідних форм; шаблонів звітів; формул; запитів за зразком; завдань планувальника; таблиць обміну; таблиць імпорту / експорту; списку користувачів системи.
Ці режими використовуються, наприклад, для копіювання зазначених компонентів одного банку в інший, що дозволяє значно спростити процес проектування нового банку даних.
При відновленні банку з копії поточний банк замінюється відновлюваним банком даних. Тому перед початком роботи банк, назву і місце розташування якого будуть «успадковані» відновленим банком (тобто залишаться колишніми).
2.4 Оптимізація роботи СУБД
Оптимізація банку даних використовується для зменшення фізичних розмірів файлів даних та індексів за рахунок оптимального розміщення записів у файлах, а також фізичного видалення із записів квартальна полів, виключених зі структури баз. Крім того, оптимізація дозволяє видалити з банку помилкові записи, які не можуть бути виправлені в ході ревізії. Такі записи в процесі оптимізації пропускаються і по її завершенні виключаються з банку. Оптимізація може проводитися як для даних, так і для індексів. Серед можливих варіантів оптимізації є:
· Шифрування даних – захист інформації від перегляду з використанням текстових процесорів та сервісних програм.
· Стиснення даних – зберігання їх у більш компактному вигляді. Зменшує розмір даних, але збільшує час на їх обробку.
· Повна дефрагментація бази дозволяє максимально зменшити розмір даних за рахунок оптимізації внутрішньої структури записів бази даних. Така операція корекції записів досить тривала, а також вона значно збільшує розмір «дефрагментованих» файлів.
Режим ревізії призначений для пошуку та виправлення помилок, що з яких-небудь причин з’являються в банку даних (або системних файлах ІСУБД CronosPro) .
Розглянемо основні види ревізії:
· В ході ревізії банку система аналізує коректність структури та вмісту підключеного банку даних (або окремих його баз) відповідно до параметрів, заданими користувачем, а потім виправляє знайдені помилки.
· Ревізія окремих записів дозволяє провести аналіз вмісту записів не всього банку (бази) даних, а тільки записів, відібраних у результаті виконання запиту.
· Ревізія структури банку дозволяє виявити такі помилки опису структури , як коректність встановлення посилань, коректність опису словникових баз банку, наявність індексів в ідентифікованих наборах і т.д.
· Ревізія системних файлів оптимізує службові файли поточного додатка ІСУБД CronosPro. Даний вид ревізії використовується в тих випадках, коли при роботі з банком даних виникають проблеми , що вказують на помилки в системних даних. У ході ревізії система виконує оптимізацію службових файлів.
· За допомогою ревізії зовнішніх файлів можна провести оптимізацію будь-якого службового файлу ІСУБД CronosPro, попередньо вказавши ім'я і шлях до цього файлу за допомогою стандартного діалогу.
· Ревізія вихідних форм дозволяє виявити ті форми, елементи яких посилаються на неіснуючі поля, бази, «вкладені» форми.
2.5 Висновки
Таким чином, можемо зробити висновок, що ІСУБД CronosPRO забезпечує:
1. Реалізацію будь концептуальної моделі через мережеву модель даних.
2. Візуалізацію баз даних і зв'язків між ними.
3. Зручну організацію даних, що спрощує створення, редагування та видалення записів.
4. Створення словникових банків даних, які попереджають помилки введення і полегшують заповнення бази даних новими даними.
5. Простоту користування, автоматичне збереження оновлень і відновлення даних.
3 Реалізація бази даних факультету засобами ІСУБД CronosPRO
3.1 Постановка задачі
Необхідно спроектувати базу даних факультету (електроніки та комп’ютерної інженерії), яка б задовольняла наступним умовам:
1. Факультет представлений чотирма кафедрами.
2. За кожною кафедрою закріплені певні викладачі, причому один викладач може працювати одночасно на кількох кафедрах.
3. Кожен викладач викладає певний набір дисциплін, причому одна дисципліна може викладатися кількома викладачами.
4. На факультеті є кілька академічних груп.
5. Студенти закріплені за певною групою, причому студент одночасно може навчатися у кількох групах (наприклад, на заочній формі).
6. Кожен студент під час сесії отримує оцінки з певних дисциплін. Одній дисципліні може відповідати кілька оцінок одного й того ж студента (наприклад, якщо дисципліна викладається кілька семестрів).
Інформація про викладача має включати прізвище, ім’я та по-батькові, дату народження, дату початку та кінця роботи. Також має вказуватися, на якій кафедрі працює викладач та які дисципліни викладає.
Інформація про студента містить прізвище, ім’я та по-батькові, дату народження, стать, дату початку та завершення навчання, групу, у якій він навчається, та оцінки, які отримав впродовж навчання.
Для дисципліни обов’язковими даними є її назва та кількість годин.
Оцінки мають бути виставлені за трьома шкалами: національною (5-бальною), 100-бальною, та шкалою ECTS. Також необхідно знати, з якої дисципліни ця оцінка, якою була форма контролю та хто її отримав.
Дані про оцінки, студентів та викладачів, що використовуються у базі, мають бути актуальними.
3.2 Проектування бази даних
Правильно спроектований банк даних забезпечує зручний і безпомилковий доступ до даних, що зберігаються в ньому. Тут мається на увазі правильно спроектована структура банку даних. Якщо банк даних спроектований, а, отже, і організований правильно, часу і зусиль при роботі з даними буде витрачено менше, а результати будуть кращі . В іншому випадку може з’явитися безліч помилок, які буде нелегко виправити.
Для того щоб банк даних був організований правильно, рекомендується спочатку створити попередній проект: обміркувати які бази даних будуть входити в банк, яка їхня структура, як вони пов'язані між собою.
Таким чином, метою попереднього проектування можна вважати зниження ймовірності виникнення помилок, пов'язаних з неправильною організацією структури банку даних.
Спроектувати структуру банку означає визначити всі інформаційні одиниці (бази даних, склад полів) і зв'язки між ними; задати їх імена.
3.2.1 Концептуальна модель даних
Перша фаза процесу проектування бази даних полягає в створенні для аналізованої предметної області концептуальної моделі даних. Проектування складних баз даних з великою кількістю атрибутів здійснюється використанням, так званого, спадного підходу.
Цей підхід починається з розробки моделей даних, які містять кілька високорівневих сутностей і зв'язків, потім робота продовжується у вигляді серії низхідних уточнень низькорівневих сутностей, зв'язків і належних до них атрибутів.
При побудові загальної концептуальної моделі даних будемо притримуватися наступної послідовності дій.
1. Виділимо загальний набір інформації в окремі сутності.
2. Сформулюємо сутності, що описують локальну предметну область проектованої БД, і опис атрибутів, що складають структуру кожної сутності.
3. Проведемо специфікацію зв'язків між сутностями.
4. Змоделюємо БД за допомогою діаграми Бахмана.
Виходячи з постановки задачі, можемо визначити, що у базі нам необхідна інформація про наступні об’єкти: кафедри, викладачів, дисципліни, групи, студентів та оцінки. Кожен з цих об’єктів пов’язаний з іншим, проте їх можна розглядати окремо. Щоб переконатися у цьому, розглянемо спочатку такі об’єкти як кафедра і викладач.
Нехай запис про викладача містить не лише його дані, а й дані про кафедру, тобто виглядає так: «Прізвище, ім’я, по-батькові, дата народження, дата початку роботи, дата закінчення роботи, назва кафедри, на якій він працює».
Здавалося б, у такому випадку відпадає необхідність в окремій базі даних для кафедри. Проте у такому підході є кілька недоліків:
1. При зміні назви кафедри необхідно змінювати і всі записи про викладачів, що працюють на ній. Причому невчасна, непослідовна або неуважна корекція призведе до порушення роботи банку даних.
2. Запит про виведення всіх викладачів певної кафедри змусить систему переглядати записи усіх викладачів, що при великій кількості даних призведе до великих затрат часу.
Отже, найкращий варіант – розділити дані на дві бази даних: Викладачі та Кафедри.
Те саме стосується й інших об’єктів. Таким чином, маємо, що кожному вищезгаданому об’єкту буде відповідати своя окрема сутність.
Тепер можемо переходити до наступного етапу.
Сутність Кафедри буде зберігати відомості про кафедру. Проте нам треба зафіксувати не усі відомі дані, а лише ті, які будуть використовуватися для досягнення певних цілей, що ми визначили у постановці задачі. Таким чином, інформація про дату заснування кафедри, її статус, фізичне розміщення в університеті є другорядною, оскільки вона не впливає на виконання базою даних своїх функцій, таких як, наприклад, пошук викладачів, знаходження дисциплін, які читаються викладачами цієї кафедри тощо. Назва кафедри – це все, що нам потрібно знати про неї. Отже, ми визначили єдине поле для бази даних Кафедри – це її назва.
База даних Викладачі має основну інформацію про викладачів. Обов’язковими мають бути прізвище, ім’я та по-батькові, а також дата народження. Необхідно знати і про те, коли викладач почав працювати на кафедрі, тау випадку звільнення чи виходу на пенсію – дату закінчення роботи. Для роботи з базою цієї інформації буде достатньо, тому інші дані є другорядними, і ми їх враховувати не будемо.
Зрозуміло, що для бази студентів поля будуть майже ті самі, проте слід ще вказати стать. Це поле буде корисним, наприклад, для запитів про хлопців призовного віку.
Визначальними рисами для дисциплін є їх назва та кількість годин, що відводиться на їх вивчення. Оцінки, окрім власне оцінки за різними шкалами, також мають нести інформацію про форму контролю, за яку вони були виставлені, оскільки це випливає, наприклад, на середній бал студента.
Визначені об’єкти не є незалежними, вони мають певні зв’язки. Визначимо останні, розглядаючи отримані бази даних. Очевидно, що база Кафедри пов’язана з викладачами, що працюють на ній, при чому тип цього зв’язку – «багато до багатьох». В свою чергу викладачі пов’язані не лише з кафедрою або кафедрами, за якими вони закріплені, а й з дисциплінами, які викладають. Цей зв'язок також має ступінь кардинальності M:N. Зі студентами, групами чи оцінками за даною постановкою задачі у викладачів немає прямого зв’язку. Отже, переходимо до бази Дисципліни. Як було визначено вище, за дисципліну виставляється оцінка (одна або декілька), тому маємо зв'язок між дисциплінами та оцінками («один до багатьох»). Оцінки виставляються за дисципліну певному студенту, отже, наступним буде зв'язок – «оцінка – студент». Оскільки один студент може мати кілька оцінок, то маємо зв'язок типу «один до багатьох». Студенти закріплені за певною академічною групою (або декількома групами), тому також треба встановити зв'язок 1:N між базою Студенти і базою Групи.
Таким чином, ми виокремили шість таблиць, визначили їх структуру та зв’язки між ними. В результаті цього отримали концептуальну модель, яку можна представити у вигляді діаграми Бахмана (рис. 15).
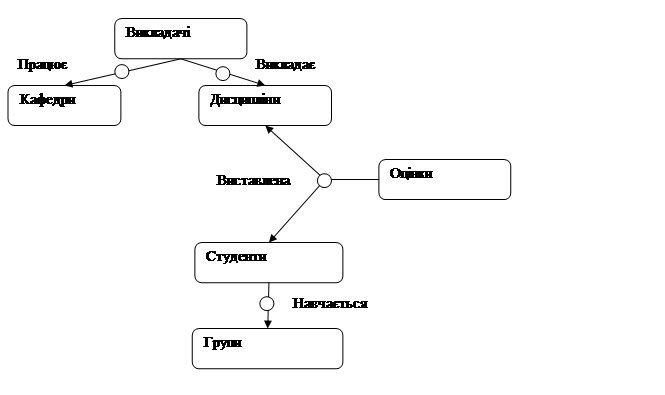
Рисунок 15 – Концептуальна модель у вигляді діаграми Бахмана
3.2.2 Логічна модель
Логічна модель описує поняття предметної області, їх взаємозв'язок, а також обмеження, що накладаються на дані предметною областю. Логічна модель даних є початковим прототипом майбутньої бази даних. Вона будується в термінах інформаційних одиниць, але без прив'язки до конкретної СУБД. Основним засобом розробки логічної моделі даних у даний момент є різні варіанти ER- діаграм (Entity – Relationship , діаграми сутність-зв'язок) .
Основні поняття ER-діаграм
Сутність – це клас однотипних об'єктів, інформація про яких повинна бути врахована в моделі. Кожна сутність повинна мати найменування, виражене іменником в однині. Кожна сутність в моделі зображується у вигляді прямокутника з найменуванням.
Атрибут сутності – це іменована характеристика , що є деякою властивістю сутності. Найменування атрибуту повинне бути виражене іменником в однині (можливо, з прикметниками) . Атрибути зображуються у межах прямокутника , що визначає сутність.
Ключ сутності – це ненадмірний набір атрибутів, значення яких в сукупності є унікальними для кожного екземпляра сутності. Ненадмірність полягає в тому, що видалення будь-якого атрибута з ключа порушує його унікальність. Сутність може мати кілька різних ключів. Ключові атрибути зображуються на діаграмі підкресленням.
Зв'язок – це деяка асоціація між двома сутностями. Одна сутність може бути пов'язана з іншою сутністю (або сама з собою) . Кожен зв'язок має два кінця і одне або два найменування. Найменування зазвичай виражається в невизначеній дієслівної формі : "мати" , "належати" і т.п. Кожне з найменувань відноситься до свого кінця зв'язку. Іноді найменування не пишуться в зважаючи на їх очевидності.
Зв'язки дозволяють по одній суті знаходити інші сутності, пов'язані з нею. Графічно зв'язок зображується лінією, що з'єднує дві сутності.
Логічна модель факультету у вигляді ER-діаграми матиме вигляд (рис. 16):
Рисунок 16 – Логічна модель у вигляді ER-діаграми
3.2.3 Фізична модель
Метою проектування на даному етапі є створення опису СУБД орієнтованої моделі БД. Дії, що виконуються на цьому етапі, занадто специфічні для різних моделей даних. Спираючись на створену логічну модель, будемо створювати бази даних у СУБД CronosPRO.
На рисунку 17 представлена візуалізація отриманої структури банку даних.
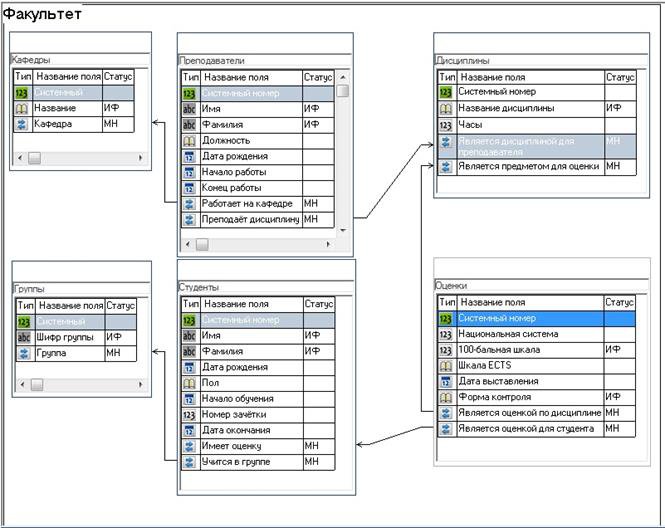
Рисунок 17 – Фізична модель
Як бачимо, отримана фізична модель дуже схожа на логічну, яку ми створювали на попередньому етапі, оскільки фізична модель є реалізацією логічної засобами конкретної СУБД.
Особливої уваги заслуговує організація зв’язків між базами даних. Як бачимо з рисунку 17 зв’язок відбувається через окремі поля, що мають спеціальний тип – посилання. Поле такого типу не призначено для зберігання звичайних даних, воно містить інформацію про те, із записами яких баз даних можуть бути пов'язані записи даної бази. Ця інформація називається посиланням(ами) на базу(и) даних. Пряме посилання встановлюється в тій базі, де б в реляційній схемі на її місці стояв зовнішній ключ, відповідно зворотне посилання буде у базі, чий внутрішній ключ використовується в пов’язані базі в якості зовнішнього.
У розділі 2 згадувалося створення словникових банків даних, де також була аргументована їх необхідність. Спеціально для нашої бази був створений словниковий банк, що включає в себе наступні словники: Посада, Пол, Кафедри, Дисципліни, Шкала ECTS і Форми контролю (рис. 18).
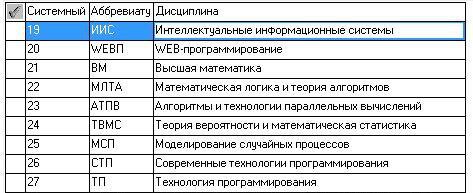
Рисунок 18 – Словникова база даних «Дисципліни»
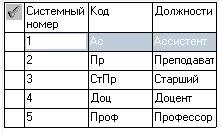
Рисунок 19 – Словникова база даних «Посади»

Рисунок 20 – Словникова база даних «Кафедри»
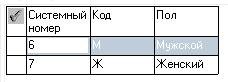
Рисунок 21 – Словникова база даних «Стать»
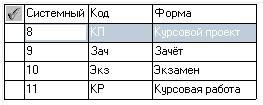
Рисунок 22 – Словникова база даних «Форми контролю»
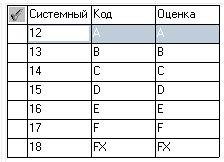
Рисунок 23 – Словникова база даних «Оцінки»
3.3 Тестування бази даних
Оскільки в даній роботі ми розглядали лише структуру бази даних без будь-яких операції над нею, то в нашому випадку процес тестування буде направлений на пошук помилок бази, викликаний неправильним проектуванням. Для того, щоб впевнитися у правильності побудованої структури, перевіримо можливість пересування з однієї бази даних в будь-яку іншу через посилання.
Переглянемо записи , що містяться в базі даних Кафедри.
Побачимо записи бази даних Кафедри. Вони представлені в деревовидному вигляді (ліворуч) і у вигляді таблиці (праворуч зверху). Розкриємо запис кафедри інформатики і вищої математики (рис. 24).
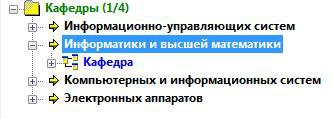
Рисунок 24 – Дерево бази даних Кафедри
Наступний рівень являє поле Кафедра, що має тип зворотне посилання, на яку посилаються записи бази Викладачі, і таких записів 27. Перейдемо на цей рівень (рис. 25).

Рисунок 25 – Посилання на базу даних Викладачі
Розкриваючи список Викладачі побачимо всі записи бази даних Викладачі. Таким чином, ми перейшли вже в іншу базу (рис. 26).
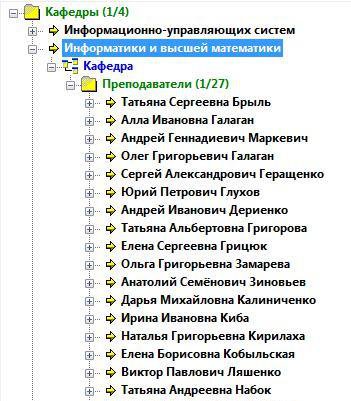
Рисунок 26 – Дерево бази даних Викладачі
Розкриваючи запис, ми побачимо під ним кілька полів – Працює на кафедрі і Викладає дисципліну. Нескладно здогадатися , що ці поля мають тип посилання, і ведуть нас в інші бази: перше – у базу Кафедри , звідки ми щойно прийшли, а друге – в базу Дисциплин, де ми ще були. Проте, щоб переконатися в цьому, розкриємо кожне (рис. 27).
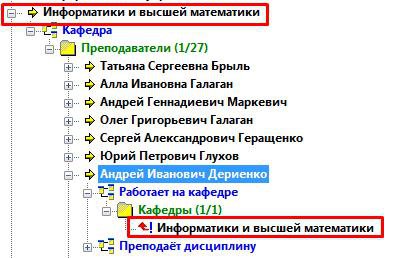
Рисунок 27 – Поле Працює на кафедрі
Розкриття поля Працює на кафедрі привело нас назад до бази Кафедри. Оскільки коло замкнулося, рухатися за рівнем нижче вже нікуди. І надалі ми вже будемо розглядати наше дерево починаючи з рівня обраного запису в базі Викладачі.
Пряме посилання Викладає дисципліну приводить нас до списку дисциплін , які читає викладач, тобто до записів бази Дисципліни (рис. 28).

Рисунок 28 – Дерево бази даних Дисципліни
Виберемо останню з них. Тут, як і в попередній раз, ми бачимо два поля – посилання на інші бази (рис. 29).
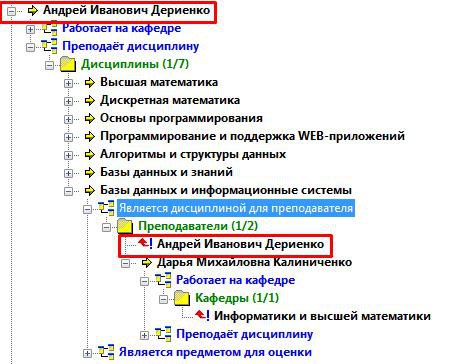
Рисунок 29 – Посилання Є дисципліною для викладача
Пряме посилання Є дисципліною для викладача, як і слід було очікувати, веде нас назад в базу Викладачі. Однак тут, на відміну від попереднього разу, ми бачимо не одного, а декількох викладачів , провідних цю дисципліну. Тому ми можемо продовжити нашу подорож і далі, у результаті повернувшись на самий перший рівень – Кафедри.
Зворотне посилання Є предметом для оцінки приводить нас до нової бази Оцінки (рис. 30). А значить, розглядати решту шляху будемо з позиції обраної дисципліни.
Розглянемо перший запис 95 Іспит. Поле Є оцінкою для студента посилається на запис у базі Студенти і проливає світло на того, хто отримав на іспиті цю оцінку по даного предмета.
Очевидно, що поле є оцінкою з дисципліни знову веде нас на рівень вище, також даючи можливість побачити , по яким ще дисциплін (у будь-якого студента) була отримана така оцінка.
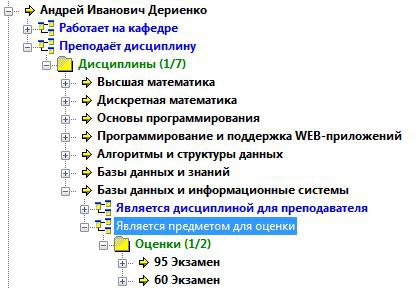
Рисунок 30 – Дерево бази даних Оцінки
Будемо діяти в межах бази Студенти. Вибираючи запис, бачимо два поля Навчається в групі і Має оцінку. Оскільки зараз нашою метою є дістатися до бази Групи, відкриємо перше посилання (рис. 31).
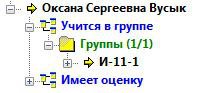
Рисунок 31 – Запис бази даних Студенти
І – 11 – 1 є записом в базі даних Групи, а значить, ми досягли мети, тим самим довівши правильність побудованої структури БД.
ВИСНОВКИ
У даній роботі ми розглянули особливості побудови та роботи з мережевою моделлю даних, зокрема з її реалізацією в інструментальній системі управління базами даних CronosPRO. Під час проектування бази даних був застосований метод низхідного проектування, побудовані діаграми Бахмана та ER-діаграма, розглянуті моделі на різних етапах проектування. У результаті була створена база даних факультету, яка задовольняє умовам поставленої задачі. У ході роботи неодноразово було проведено порівняння з поширеними реляційними моделями, визначено відмінності в архітектурі СУБД. Важливим етапом було глибоке проникнення у математичні основи мережевої моделі, що полегшило розуміння структур та операцій, які проводяться над даними.
Переваги розробленої бази даних полягають у можливості легкого оновлення даних. Її структура передбачає зберігання даних за довгий період, причому завдяки всього лише кільком змінам вони не втрачають актуальності. Так, наприклад, ми можемо прослідкувати за пересуваннями студентів, зміною викладацького складу. За необхідності банк даних можна розширити, додавши нову базу даних. Слід також відмітити використання словникового банку даних, яке попереджує виникнення помилок та дублювання даних. Сильна сторона мережевої моделі полягає в ефективній реалізації за показниками витрат пам’яті та оперативності.
Недоліки пов’язані безпосередньо з недоліками мережевої системи: складністю розробки схеми БД, жорсткого прив’язування моделі до її реалізації.
Робота може бути удосконалена шляхом створення форм введення даних, з можливістю виконувати запити, проводити масову корекцію даних та створювати звіти. Також можна забезпечити захист системи та оптимізувати її роботу.
ПЕРЕЛІК ПОСИЛАНЬ
1. Дейт К.Дж. Введение в системы баз данных / К.Дж.Дейт.– М.:Издательский дом «Вильямс», 2005. – 1329с.
2. Бураков П.В. Введение в системы баз данных: учебное пособие / П.В.Бураков, В.Ю.Петров.–СПб, 2010.–129с.
3. Конноли Т. Базы данных: проектирование, реализация и сопровождение. Теория и практика / Т.Конноли, К.Бегг, А.Страчан. – 2-е изд., испр. – М.: Издательский дом «Вильямс», 2003. – 1120с.
4. Ульман Дж. Введение в системы баз данных / Дж.Ульман, Дж.Уидон. – М.: Изд-во «Лори», 2006. – 379с.
5. Разбираем сетевую модель [Электронный ресурс] / Библиотека программиста.– Режим доступа: URL:http://www.programmer-lib.ru/delphi_page.php?id=9.– Название с екрана.
6. Celko’s J. Trees and hierarchies in SQL for smarties / Joe Celko’s. – Elsevier, 2012.– 277 p.
7. Кузнецов С.Д. Основы баз данных: учебное пособие / С.Д.Кузнецов– М.:Интернет-Университет информационных технологий, 2007. – 484с.
8. Тиори Т. Проектирование структур баз данных. Книга1 / Т.Тиори, Дж.Фрай.–М.:Мир, 1985.–287с.
9. Инструментальная система управления базами данных CronosPRO: руководство пользователя / ЗАО «Научно-производственная компания «КРОНОС_ИНФОРМ», 2013. – 499с.
ВИКОНАЛА студентка групи І-11-1: Вусик О.С.
КРЕМЕНЧУК 2014
0 комментариев