Мазмұны:
Кіріспе............................................................................................................3
1. Лексикалық анализатордың құрылу принциптері.........................4
2. Тілдерді өрнектеу...................................................................................6 3. Синтаксистік анализатордың қолданылуы.....................................8 4. КБ-тілдердің тізімін анықтау мәселелері.......................................10 5. Кірістіру тілінің сөйлемдерін талдау...............................................11 6. Синтаксистік анықтауышты жүзеге асыру....................................14 6.1Грамматика ережесі және басымдығы бар матрицаны сипаттау модулдер............................................................................................14 6.2Мәліметтер құрлымы модулі үшін синтаксистік талдау және «сдвиг-свертка» алгоритмін іске асыру..........................................166.3Анықтауыштың бағдарлама мәтіні..................................................17
7. Лексическалық анализаторды жобалау...........................................19
Қосымша А.................................................................................................21
Қорытынды................................................................................................28
Қолданылған әдебиеттер.........................................................................29
Кіріспе
Лексикалық анализ – бұл компилятордың бір бөлігі. Ол шығару тіліндегі программалардың литерлерін оқиды және шығару тілінде сөздер құрастырады. Лексикалық анализаторлардың енгізуіне шығарылған программаныңтексті кіреді, ал шығарылған информация ары қарай синтактикалық талдауэтапындағы компилятормен жұмыс істеу үшін жүзеге асырылады. Теориялық нүктеден қарасақ компилятор қажет емес бөлік болып табылады. Бірақ та барлық компиляторда оның бар екендігі анықталады. Синтактиаклық талдау – бұл анализ этапындағы компиляторың ең маңызды бөлігі. Ол лексикалық анализбен қарастырылған шығарылған программа мәтіндегі синтактикалық құрылымдарын белгілейді. Дәл осы фазада синтаетикалық программаның дұрыстылығы тексеріледі. Синтактикалық талдау басты роль ойнайды. Бұл программадағы енгізу тексті анықтайды. Семантикалық анализ – бұл шығу программасының дұрыстығын тексеретін компилятордың бөлігі. Тексеруден басқа семантикалық анализ мәтінді өзгертуі тиіс. Семантикалық анализдің бір бөлігі синтактикалық талдауға, бір бөлігі генерациялық код дайындық фазасына кіруі мүмкін. Генерациялық кодқа дайындық - бұл фаза компилятор арқылы жұмыстар істелінеді, ол әрине нәтижелік программа синтез мәтініне байланысты. 1. Лексикалық анализатордың құрылу принциптері. Лексикалық анализатор тұрақтылар және идентификатор сияқты объектілермен қарым қатынаста болады. Тұрақтылар және идентификаторлар тілі – көп жағдайда қайталанбас болады және қайталанбас грамматикаларының көмегімен жазылуы мүмкін. Қайталанбас тілдердің анықтамасы соңғы автоматтар болады. Мынадай ережелер болады, осы ережелер арқылы кез келген қайталанбас грамматика үшін детерминировалданған емес соңғы автомат құрылуы мүмкін. Әрбір кіру тізбегінің тілі үшін соңғы автомат сұраққа жауап қайтарады. Сканер келесі іс - әрекеттерді орындау керек: • лексеманың шекарасын толық анықтауы керек, олар шығу мәтінінде берілмеген; • ақпаратты сақтау үшін, белгілі бір іс - әрекеттерді орындауы керек. 1.1 Лексемалардың шекараларын анықтау. Лексемалардың шекараларын белгілеу қателіктер туғызады. Өйткені кіру программасының мәтінінде лексемалар арнайы символдармен шектелмеген. Егер сканер – программасының терминында айтатын болсақ, онда лексемалардың шекараларын анықтау – бұл дегеніміз кіру символдарының жалпы ағымына кіретін жолдардың белгіленуі. Жалпы түрде бұл мақсат қиын болуы мүмкін, онда сканердің параллельдік жұмысы керек болды (лексикалық анализатордың), синтаксистік талдаудың және семантикалық талдаудың да жұмысы керек болды. Көптеген кіру тілдеріне лексема шекаралары берілген терминалдық символдармен шешіледі. Бұл символдар – пробелдер, операция белгілері, коментарий символдары, сонымен қатар бөлінділер (үтірлер, нүктелі үтірлер және тағы басқа). Бұндай терминалдық смиволдардың жиынтығы кіру тілінің синтаксисіне байланысты болады. Маңыздысы, операция белгілері лексемалар болады және оларды жіберуге болмайды. Ереже бойынша сканерлер келесі принцип бойынша жүзеге асады: кіру ағымы мәтінінің кезекті символы лексемаға әрдайым қосылады. Егер символ лексемаға қосылмаса, онда ол лексеманың шекарасы және келесі лексемасының басы болып табылады. (егер символ бос бөлгіш бомаса – пробел, табуляция символы немесе жолдың ауыстыруы). Бұндай принцип лексема шекарасын дұрыс анықтауға мүмкіндік бермейді. Мысалы, жоғарыда көрсетілген С тілінің жолы k = i +++++ j; лексемаларға келесі түрде бөлінеді: K = I ++ ++ +j; - және бұл бөлу дұрыс емес, компилятор қолданушыға қате туралы хабарлама жібереді. Лексикалық анализатор түзу жұмыс істейді, егер берілген шығу мәтінінде (шығу тілінің символдар тізбегіне) және ағымдағы көрсеткіш онда лексеманы анықтайды, лексикалық анализатордың тура жұмысында оның синтаксистік танытумен байланыста болуы мүмкін. Лексикалық анализатор тура жұмыс істемейді, берілген түрдің лексемасы және көрсеткіштің ағымдағы түрінде ол көрсеткіштің оң жағында орналасқан лексеманы анықтайды, және егер ол талап ететін түрге сәйкес келсе, онда көрсеткішті мәтін белгінің оң жағына жылжытады. Тура нұсқасына қарағанда берілген лексикалық анализаторға кірген кезде күтудегі лексеманың типін беру керек. Сондықтан лексикалық анализдің тура емес жұмысында оның синтаксистік танытумен параллельдік байланыс болуы керек. Лексикалық анализатордың құрылуы. Енді сканерлердің практикалық орындалуын қарастыруға болады: Компилятордың құрамында бір емес, бірнеше лексикалық анализатор болуы мүмкін. Олардың әрқайсысы анықталған лексеманың типін тексеру және таңдау үшін арналған. Сонымен қарапайым лексикалық анализатордың компиляторда жұмысын келесі түрде бейнелеуге болады: • кіру ағымынан бір символ таңдалады, ол қандай сканер іске қосылатынына байланысты (символ қате болуы мүмкін); • жіберілген сканер негізгі тілде программаның кіру символының ағымын қарастырады, келесі символды анықтағанша талап ететін лексемаға кіретін символдарды белгілейді, ол лексеманы шектеуі керек. • белгіленген лексема туралы анықтаманың табысты анықталуы лексема кестелерін және идентификаторлар кестесіне енгізіледі, алгоритм бірінші қадамға қайтады және кіру ағымының символдарын қарастыруға жалғастырады. Жалғасы сканерлер тоқталған жерден басталады; • егер танылу дұрыс орындалмаса қате туралы хабарлама келеді, ал қалғаны сканердің жұмысына байланысты болады – оның жұмысы тоқтатылады немесе келесі лексеманы орындайды. (алгоритмнің бірінші қадамына өту жүріп жатыр). Лексикалық анализатордың құрылу автоматизациясы (LEX программасы). Лексикалық танушылар (сканерлер) – бұл компилятордың маңызды бөлігі ғана емес. Сонымен қатар лексикалық анализ басқа да облыстарда қолданылады, мысалға компьютерде мәтіндік ақпаратты өңдеумен байланысты. Ең алдымен, лексикалық анализ барлық командалық процессорларды және утилиттерді талап етеді. Сонымен қатар, енгізілу мәтінінің лексикалық анализін барлық мәтіндік редакторлар және мәтіндік процессорлар қолданады. Лексикалық анализаторды құруға арналған көптеген программалар бар. Олардың арасынан ең танымалысы LEX программасы. LEX – сканерлерді генерациялауға арналған прграмма (лексикалық анализатордың). LEX программасының нәтижесі, программалау тілінің кейбіреуінде болады, ол ену файлын оқиды және одан берілген айтылуларды белгілеп алады. LEX программасының тарихы UNIX операциялық жүйесінің тарихымен тығыз байланыста. Бұл программа OC UNIX утилиттердің құрамында пайда болады, қазіргі уақытта осы типтің әрбіріне кіреді. Қазіргі кезде кез келген OC үшін LEX программасының көптеген түрлері бар. LEX тің жұмыс принципі өте жеңіл: оған енгізілуге мәтіндік файл беріледі, ал шығу кезінде сканер программасының шығу мәтінімен файл алынады. Сканердің шығу программасының мәтіні кез келген кітапханалардың кез келген функцияларымен толықтырылуы мүмкін. Осындай жағдайда LEX лексикалық анализатордың өңделуін жеңілдетеді. 2 Тілдерді өрнектеу. Программалау тілдері төмендегі элемменттерден тұрады: 1. Символдар – бұл берілген тілдер программаның барлық мәтінін құрайтын негізгі бөлінбейтін белгілер. Барлық символдар жиыны тілдің алфавитін құрайды. Табиғи тілге қарағанда программалау тілдің алфавиті кеңірек. Ол латын әріптерін, арифметикалық амалдар белгілерін, ажыратқыш символдарды және басқа да арнайы символдарды қосады. 2. Лексемдер - Өзіндік мағынасы бар алфавитің символдардың көрінбейтін тізбектері. Олар тілдің негізгі символдары арнқылы құралады. Бір символдан тұратын лексемдер бар болуы м үмкін, мысалы, амалдар белгілері. Кез-келген программалау тілдерінің кілттік сөздерінің нақты жинағы бар. Олар тілдің сөздігін құрайды.Программист нақты ереже бойынша жеке меншік сөздер – идентификаторлар құрай алады. Табиғи тілде жазылғане алгоритім жазбасына қарағанда күрделірек түсіндіріледі. Лексемдер және олардың құрылу ережелері тілдің лексикасын құрайды. 3. Өрнектер тілдің ережесіне сәйкес лексемдерден құралады. Олар кейбір мәндердің есептеу тәртібін береді. Өрнектер қарапайым тілдегі сөз тізбектеріндегі сияқты программалау тілдерінде де сол рөлді атқарады. 4. Операторлар тілдің кейбір іс-әрекеттердің толық сипаттамасын береді. Күрделі әрекеттерді сипаттау үшін операторлар тобы керек. Бұл жағдайда операторлар құрамдас операторлар немесе блокқа біріктіріледі. Оператор берген әрекеттің деректері арқылы орындалады. Деректер туралы мәліметтер берілген тілдің сөйлемдері сипаттау немесе орындалмайтын операторлар деп аталады. Сипаттау немесе операторлар жиыны программа түзеді. Программалау тілдерінің элементтерінің жазылу ережелерінің жүйесі оның синтаксисін құрайды. Тілдің құру мағынасы - бұл оның семантикасы. Басқа сөзбен айтқанда,тілдің синтаксисі жеке құрастырушылардың сыртқы түрін анықтайды,ал семантика осы құрастырушылар арқылы компьютер орындайтын әрекеттерді талқылайды.Жоғарғы деңгейлі қазіргі тілдер симантикалары бойынша ұқсас,бірақ синтаксисте кейбір ерекшеліктері бар. Осыдан шығатын маңызды қортынды: программалауды алғаш меңгерушілер тілдің семантикасына көңіл аударуы қажет. Сапалы программаларды жазу тілдің синтаксисіне байланысты емес. Семантиканы соңына дейін түсіну күрделірек. Тілдің әрбір құрастырушысын жеке алгоритімдер жазуда міндеттері бойынша пайдалану одан сайын күрделірек. Бұл жерде бұрынғы сыналған амалды компьютерде жұмыс, көптеген мысалдарды өңдеу, есептерді шығаруды ұсынуға болады. Табиғи тілден айырмашылығы әр программалау тілінің қатаң сипатталуы болады.Мұндай сипаттау не үшін керек? Бұл жерде компьютермен байланысу үшін арналған тіл туралы айтылып тұр. Яғни, аздаған екі ойлар қателікке соқтырады. Тілді сипаттау дегеніміз – оның негізгі элементтерін сипаттау.Тілдің әр элементін сипаттау оның синтаксисімен және симантикасы мен беріледі.Синтаксистік анықтамалар тілдің элементтерін құру ережелерін тағайындайды. Семантика синтаксистік анықтамалар берілген элементтердің қолдану ережелерін және мағынасын анықтайды. Программалау тілін сипаттау үшін табиғи тілді қолдануға болады.Бірақ мұндай сипаттаудың қалыпты сөз тілінде сипатталған алгоритімдер сияқты кемшіліктері болады. Алгоритімдей сипаттаудан айырмашылығы, тілді сипаттау адамның меңгеруіне шақталған. Сондықтан программалау туралы әдебиеттерде мұндай сипаттау жиі қолданылады. Бірақ транцляторды ойлап табушылар тілдің қалыпты сипатталуын қажет етеді. Сонымен ол сипатталу ешқандай бір мәнді талқылау жібермеуі қажет және мамандар үшін жинақы әрі ыңғайлы болу қажет.Олардыдың тілекттеріне сәйкес алғашқы тілдердің бірін сипаттау үшін арнайы қалыпты сипаттау типі ойлап табылды. Қазіргі кезде тілдерді сипаттаудың бірнеше түрлері бар. Оларды программалау тілдеріне ажырату үшін оларды тілдердің белгілері деп атайды. Бірдей мақсаттар үшін және өзара толық байланысқан әр түрлі екі тілдің белгілеріне сипаттама берейік: 1. Бэкус-Наур (БНФ) қалыпты. Осы белгілі Algol тілін сипаттау үшін қолданылған, содан кейін әр түрлі программалау тілдерінің авторлары арқылы оларды қалыпты сипаттау үшін қолданылды. Қазіргі уақытты РБНФ деп аталатын кеңейтілген нұсқасы пайдаланылады. 2.Вирттің синтаксистік диаграммалары. Тілдің негізгі құрастырушыларының графиктік бейнеленуі. Бэкус-Наур қалыпты бірнеше арнайы қызметті символдарды – метасимволдарды пайдаланып, тілдің барлық элементтерін өте қатаң және жинақы сипаттауға мүмкіндік береді. Сонымен қатар тілдің әр түсінігі ең қарапайым түсініктерден шығады. Барлық басқа түсініктер – терминалдар еместер – терминалдар бірте-бірте арнайы металингвистік формулалар көмегімен шығады. Ол формулаларда теңдік белгісінің орнына ::= қолданылады. Әр терминал емес бұрышты жақшаға алады. Мета символың мәні “немесе” (или) болады. Кеңейтілген БНФ-тағы да бірнеше пайдалы метасимволдармен толықтырылған.[pic] жазбасы А символын бірнеше рет( ноль болуы да мүмкін ) қайталау дегенді білдіреді. [pic] жазбасы А символын ноль немесе бір рет қайталау дегенді көрсетеді. РНБФ формулалары БНФ – ға қараған да қарапайым. Өйткені мұнда түсініктер бұрышы жақшаға алынбайды. Ал ::= белгісі кәдімгі теңдікке алмастырылған. Терминалдық символдар тырнақшаға алынады. Вирттің синтаксистік диаграммалары – бұл түзу сызықтар мен біріктірілген блоктарды пайдаланып, тілді графикалық түрде сипаттау. Мұнда терминалдар дөңгелектер көмегі мен, ал терминал, еместер тікбұрыштар көмегі мен белгіленеді. Бэкус – Наурдың әр құрастырушысы үшін эквиваленттік синтаксисін диаграмма құруға болады.3 Синтаксистік анализатордың қолданылуы
Хомск грамматикасының иерархиясы бойынша тілдердің (және олардың грамматикасын сипаттайтын ) негізгі төрт тобын қарастырады. Және осы жағдайда көп қызығушылық регулярлы және контексті – бос грамматикаға білдіреді. Олар бағдарламалау тілінің синтаксисін сипаттаған кезде қолданылады. Регулярлы грамматика көмегімен тілдің лексемасын жазуға болады – идентификаторларды, тұрақтыларды, қызметтік сөздерді және тағы басқалары. КБ грамматиканың негізінде үлкен синтаксистік конструкциялар құрылады: айнымалылардың типін сипаттау, арифметикалық және логикалық мәндер, басқарушы операторлар және кіріс тіліндегі барлық бағдарлама.
Регулярлы тілдердің кіріс тізбектері ақырлы автоматтардың (АА) көмегімен анықталады. Ол лексикаолық анализ жасайтын сканерлердің негізінде жатады және кіріс тіліндегі мәтіндегі сөздерді ерекшелейді. Сканер жұмысының нәтижесі болып алғашқы бағдарламаны тізім немесе лексемдер кестесі түріне айналдыруы саналады. Әрі қарай оны өңдеуді компилятордың басқа бөлігі орындайды – синтаксистік анализатор. Оның жұмысы алғашқы тілдің конструкциясын сипаттайтын КБ-грамматиканың ережелеріне негізделген.
Синтаксистік анализататор – кіріс тілінің синтаксистік конструкцияларын тексеру және шығаруына жауап беретін компилятордың бөлшегі. Синтаксистік анализататордың міндетіне кіреді:
· Алғашқы бағдарлама мәтінінде синтаксистік конструкцияларды іздеу және ерекшелеп белгілеу;
· Әрбір синтаксистік конструкциялардың дұрыстығын тексеру және типін орнату;
· Нәтижелі бағдарламаны әрі қарай генерациялауға ыңғайлы етіп синтаксистік конструкциялардың типін келтіру
Синтаксистік анализататор – талдау кезеңіндегі компилятордың негізгі бөлігі болып табылады.
Синтаксистік талдау жасалмаған болса, компилятордың жұмысының мағынасы болмайды, ал лексикалық анализ міндетті бөлшек болып саналмайды. Кіріс тілінің барлық синтаксисін тексеру үшін жүргізілетін есептер синтаксистік талдау кезінде орындалады. Лексикалық анализатор тек қана синтаксистік анализатордың жұмысын жеңілдету үшін алғашқы бағдарламадағы қиын құрылымды есептерді жеңілдетуге мүмкіндік береді.
Лексикалық анализатордың нәтижесі болып лексем кестесі табылады. Бұл кесте синтаксистік анализатордың кірісін орнатады және әр кірісте бір ғана кіріс компоненті болады – оның типі.
Лексемдер жайлы басқа ақпарат кейінгі компиляция фазаларында (семантикалық анализ бөлімі, нәтижелі бағдарламаның коды генерациясы) қолданылады.
Синтаксистік анализатор лексикалық анализатордың нәтижесін қабылдайды және оны кіріс тілінің грамматикасы негізінде талдайды. Бірақ кіріс бағдарламалау тілінде өандай конструкцияларды лексем ретінде қабылдау керек екенідігі анықталмайды.
Конструкциялардың мысалы ретінде, әдетте лексикалық анализ кезінде анықталатын кілттік сөздер, тұрақтылар және идентификаторлар қарастырылады.
Және осы конструкциялар синтаксистік анализаторда да қабылдануы мүмкін. Тәжірибе жүзінде қандай конструкциялар лексикалық анализ кезінде, қандай конструкциялар тәжірибе жүзінде қабылдануы керек жайлы қатып қалған ереже жоқ.
Әдетте мұны компилятор өңдееушісі бағдарламалау технологиясының аспектілеріне сүйене және кіріс тілінің синтаксисіне және семантикасына негіздеп қабылдайды. Лексикалық және синтаксистік анализаторлардың байланысу прициптері екінші зертханалық жұмыста қарастырылған болатын.
Синтаксистік анализатордың негізіне кіріс тілінің грамматикасының негізінде құрылған алғашқы бағдарламаның мәтінін анықтауыш жатыр. Бағдарламалау тілінің синтаксистік конструкциялары контексті – бос грамматикасының көмегімен жасалады, регулярлы грамматиканың көмегімен жазылған синтаксистік анализатор қазіргі кезде сирек кездеседі.
Синтаксистік анализатордың қалай функционалданатынында және оның негізіне қандай алгоритм жататындығында КБ-тілдердің анықтауыштары басты роль атқарады. Бұл принциптерді қолданбай кіріс тілінің мәтіндеріне эффективті синтаксисті анализатор жасау мүмкін емес.
4 КБ-тілдердің тізімін анықтау мәселелері.
Лексикалық және синтаксистік анализатордың байланысы алдыңғы зертханалық жұмыста қарастырылған болатын, ал енді бұл жұмыста синтаксистік анализдің негізіндегі алгоритмдер қарастырылады. Синтаксистік анализатордың алдында екі негізгі міндет бар: кіріс тілінің белгіленген сөздер түрінде берілген бағдарлама конструкциясының дұрыс екендігін тексеру және оны әрі қарай семантикалық өңдеу және кодын генерациялауға тиімді болу үшін түрлендіру. Осындай түрдің бірі болып синтаксистік талдау ағашы болып табылады.
КБ-тілдердің анықтауыштарын құрудың негізі юолып дқосвлқы жадысы бар автоматтар – МП автоматтар (біржақты, детерминалданбаған, сызықты – шектеулі қосалқы жадысы бар анықтауыштар )болып табылады. Сондықтан МП автоматтардың қалай функционалданатыны және КБ – тілінің талдау есебін орындауы – берілген грамматика негізінде тілдің анықтауышын құру. Әрі қарай синтаксисті анализатордың орындалуымен байланысты техникалық аспектілерді қарастырамыз.
Мп автоматтар КБ автоматтарға қарағанда айырмашылығы арнайы стек (қосалқы жады) болады. Бұл стекте арнайы жеке символдар орналастырылады (әдетте бұл тіл грамматикасының терминалды және терминалды емес символдары ). Мп автоматтардың бір күйден екінші күйге ауысуы тек қана кіріс символдарына байланысты емес, сонымен қатар стектің бірнеше жоғарғы символына байланысты. Сонымен, автомат конфигурациясы үш параметрмен анықталады: автомат күйімен, кіріс тізбегінің ағымдағы символмен және стектің мазмұнымен.
МП автоматтың бір конфигурациядан екінші күйге өткен кезде ауысу шартына байланысты стектен жоғарғы символдар өшіріледі және жаңа тізбектер қосылады. Тізбектің бірінші символы стектің төбесі болады. Кіріс символы оқылмайтын жағдайлар болаыд, Бұл ауысулар λ-ауысулар деп аталады. Егер тізбек аяқталғанда автомат ақырлы күйдің бірінде болса, ал стек бос болса, тізім қабылданды деп есептелінеді. Басқа жағдайда тізім қабылданбайды.
МП автоматтар детерминалданбаған деп саналады, егер бір конфигурациямен тек қана бір ғана ауысу орындалса. Басқа жағдайда МП автоматы детерминалданған деп есептелінеді (ДМП). ДМП аавтоматтар детерминалданған КБ тілдер класын құрады. Және осы кластар үшін бір типті КБ грамматикалар бар. Осы класс барлық бағдарламалау тілінің синтаксистік конструкциясында жатыр. Әрбір тілдің синтаксистік конструкциясы бір ғана түсіндірмеден тұру керек.
Туынды КБ грамматикасы үшін G(VN,VT,P,5), V - VTuVN әрқашан детерминалданбаған МП автомат құруға болады және бұл автомат осы грамматика белгілеген тілдің тізімін орындауға жібереді. Ал бұл МП автоматтың негізінде берілген тілдің анықтауышын бекітуге болады.
5 Кірістіру тілінің сөйлемдерін талдау.
Талдау жасайтын МП автоматы конфигурация реттілігі түріндегі кірістіру тілінің тізбегін талдау мысалын қарастырайық. Талдау нәтежесін грамматика ережесінің реттілік нөмерлер түрінде келтіріледі. Талдау жасалғаннан кейін, қате болмаған жағдайда(кіріс тізбекті ОҚ-автоматы қабылдаса), табылған ереже реттілігі негізінде синтакситік талдау ағашын құруға болады.
Қарастырылатын МП-автоматы бір ғана күйде болады. ОҚ-автомат жұмысын сипаттау үшін оның әрбір конфигурациясын үш құрамдас бөлікке бөлеміз {α,β,γ} яғни:
· α-кіріс тізбектің оқылмаған бөлігі;
· β- МП – автоматының стек құрамы;
· γ-қолданылған ережелердің нөмерлер реттілігі;
Бастапқыда барлық кіріс тізбегі оқылмаған жағдайда болады, автомат стегінде ”начало строки” лексемасы жазылады, ережелердің нөмер реттілігі бос болады. Оқуды ыңғайлату үшін МП -автомат стегін оңнан солға қарай толтырамыз, онда β тізбегіндегі оң жақтағы шеткі символ стектің жоғарғы бөлігі болып есептеледі.
Мысал 1
«if а or b and с then a := 1 хоr с;» кіріс тізбегін алайық.
Лексикалық талдаудан кейін, егер барлық «идентификатор» және «константа» лексемаларын «а» деп белгілесек, келесі тізбекті аламыз: «if a or a and a then a := а хог а;». Осы кіріс тізбегінің ситаксистік талдау процесін қарастырайық. МП -автомат жұмыс істеу қадамдарын « + » символымен белгілейік. « + н» символымен тасымал орындалатын қадамдарды, ал « +с» символымен свертка жасалытын қадамдарды белгілейміз.

{lj£lH|12 12 12 10 7 12 12 8 4 3 1} -талдау аяқталды, МП - автоматы тізбекті қабылдап , соңғы конфигурацияға көшті. Осының нәтежесінде келесі ереже тізбегін аламыз: 12 12 12 10 7 12 12 8 4 3 1. Бұл ереже тізбегіне G грамматика шығару реттілігі сәйкес келеді:
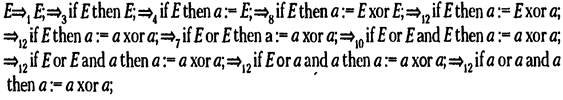
Берілген МП -автоматы оң жақты шығарумен құралған,сонымен қатар шығару ретілігінде тізбектегі әрбір қадамда оң жақ шеттегі символға ереже қолданылады.
Берілген кіріс тізбегіне сәйкес синтаксистік талдау ағашы 3.2 суретте келтірілген:
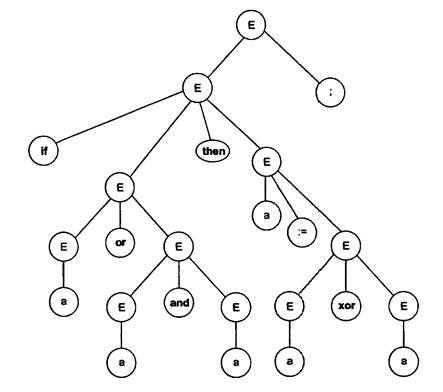
Сурет 3.2 Берілген кіріс тізбегіне сәйкес синтаксистік талдау ағашы.
Мысал 2
«if (a or b then a :=25;» кіріс тізбегін алайық.
Лексикалық талдаудан кейін, егер барлық «идентификатор» және «константа» лексемаларын «а» деп белгілесек, келесі тізбекті аламыз: «if (a or a then a := а».
Бұл кіріс тізбігенің синтаксистік талдау процесін қарастырайық:
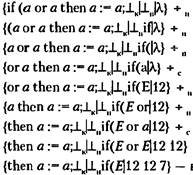
«then» және «(» лексемалар арасында қарым қатынас жоқ, талдау аяқталған, МП-автоматы сонғы конфигурацияға көшкен жоқ және тізбек қабылданған жоқ(қателік туралы хабарлама шығады).
6 Синтаксистік анықтауышты жүзеге асыру
Модулге бөлу
№ 3 зертханалық жұмыста және № 2 зертханалық жұмыста синтаксистік анализаторды іске қосатын модулдер екі топқа бөлінеді:
· Програмалық коды кірістіру тіліне тәуелсіз модулдер;
· Програмалық коды кірістіру тіліне тәуелді модулдер.
Бірінші топқа кіретін модулдер:
· SyntSymb – синтаксистік талдау үшін мәлімет құрлымын сипаттайды және оперативті басымдығы бар граматикасы үшін «сдвиг-свертка» алгоритмін іске асырады;
· FormLab3- қолданушы интерфейсін сипаттайды.
Екінші топқа бір модуль кіреді:
SyntRule- матрицаның оперативті басымдығы бар сипатамасы және бастапқы граматика ережесін қолдайды.
Бұндай модулге бөлу, кірістіру тілі өзгертілген жағдайда дәл сондай мәліметтер құрлымын қолданып синтаксистік анықтауышты ұйымдастырға мүмкіндік береді.
Бұл модулдерден басқа № 3 зертханалық жұмысты іске асыру үшін TblElem және FncTree программалық модулдері № 1 зертханалық жұмыста жасалған аралас идентификатролар кестелерімен жұмыс жасау үшін қолданыла алады.Сонымен қатар лексикалық анықтауыштың жұмыс жасауын қамтамасыз ететін LexType, LexElem және LexAuto модулдері бар.
Синтаксистік талдауды ұйымдастыру үшін қолданылатын модулдер туралы қысқаша сипаттама берейік.
6.1 Грамматика ережесі және басымдығы бар матрицаны сипаттау модулдері
SyntRule модул қабырғалы грамматика және оперативті басымдығы бар матрицасының құрлым мәліметтер сипаттамасын қолдайды.
оперативті басымдығы бар матрицасы (GramMatrix) екілік массив түрінде сипатталады, әрбір жолыға және әрбір бағанға лексема сәйкес келеді (TlexType типі). Матрица жолы мен бағаны LexType модуліндегі TLexType лексема сипатамасындағы реттілікпен бірдей болуы маңызды. Матрицаның әр ұяшығында алдын алудың қатынасын белгілейтін символдар орналасқан.
“<”- қатынасы үшін «<»
“>”- қатынасы үшін «>»
“=” - қатынасы үшін «=»
“ ” – бос ұяшықтар үшін.
Жоғарыда айтылғанан басқа SyntRule модулде оперативті басымдығы бар граматикасының мүмкіндіктерін кеңейтетін CorrectRule функциясы сипатталған. Берілген зертханалық жұмыста бұл функция қарастырылмаған.
Жалпы айтқанда SyntRule модулінде сипатталған оперативті басымдығы бар матрица GramMatrix-те құрылған оперативті басымдығы бар матрицаға толықтай сәйкес келеді( 3.8 кесте). Айырмашылығы G грамматикасында терминалды символға кірістіру тілінің екі лексема сәйкес келеді(тұрақтылар және айнымалылар), ал GramMatrix матрицасында символға сәйкес жол және баған 3.8 кестеде қайталанып келеді.
Сондықтан 3.8 кестесінен алынған басымды матрица негізінде синтаксисті талдаушы тұрақтылар мен айнымалыларды ажыратыра алмайды. Бұл тіл үшін айнымалылар мен тұрақтылар арасындағы айырмашылықты бір ғана жағдайда өткізуге болады: тағайындау операторын талдау кезінде(тұрақтыға мән беруге болмайды). Компилятор бұндай қатені табу үшін екі тәсіл бар:
· Кірістіру тілінің синтаксисін өзгерту (G грамматикасын)кажет, нәтежесінде айнымалылар және тұрақтылар бір бірінен грамматика ережелерінде ажыратылуы тиіс және синтаксистік талдауышты қайта құру.
· Семантикалық талдау кезеңінде тұрақты мәндерді өңдеу.
Бұл жағдайда екінші тәсіл таңдалған және № 4 зертханалық жұмыста жүзеге асырылған(кодты генерациялау және кодты генерациялауға дайындық қарастырылады ).
Содан соң курстық жұмысты орындау үшін компилятор құруда, бірінші тәсіл қарастырылды. Қарастырылған тәсілдердің әрқайсысы өз артықшылықтары мен кемшіліктері бар.
Жалпы, компиляцияның қай сатысында қате анықталғаны компилятор құрастырушысынан байланысты.
Негізгі G грамматика ережелері GramRules массив жолдары ретінде сипатталған.Бұл массивте әрбір ережеге ереженің оң жақымен сәйкес келген жол сәйкес болады(бос орын ескерілмейді).
Ережелер нөмір реті қабырғалы G грамматикасында сияқты солдан оңға қарай және жоғарыдан төмен нөмерленген. Сәйкес келетін ережені табу үшін сұрыптау әдісі қолданылады, ережелер аз болғандықтан (тек қана 13), бұл жағдайда, осы әдіс қанағаттанарлық болып табылады.
Жоғарыда сипатталған мәліметтер құрлымы(GramRules және GranMatrix) басқа SyntRule модулінде MakeSymbolStr қабырғалы грамматика ережесіндеге терминалді емес символдарды қайтаратын функциясы сипатталған.
G грамматикасындағы барлық ережелерінде символ E белгіленген, сондықтан MakeSymbolStr функциясы Е мәнін өзінің орындаған нәтежесі ретінде қайтарады. Алайда бұл функция мағынасыз емес, өйткені қабырғалы грамматиканың басқада нұсқалары болуы мүмкін.
6.2 Мәліметтер құрлымы модулі үшін синтаксистік талдау және «сдвиг-свертка» алгоритмін іске асыру.
SyntSymb модулі «сдвиг-свертка» алгоритімін іске асыра алады және оған керекті барлық мәліметтер құрлымы сипаттауын қолдайды. «сдвиг-свертка» алгоритімі кірістіру тілінен тәуелсіз болғандықтан, оның іске асытратын модулі де кірістіру тілінен және бастапқы грамматикадан тәуелсіз болып табылады.
Модулдің негізін келесі мәліметтер құрлымы құрайды:
· TSymblnfo – грамматика символының екі түрі сипаттамасы:терминалды және терминелды емес;
· TSymbol – грамматика символы мағынасымен байланысты барлық мәліметтер сипаттамасы;
· TSymbStack - синтаксистік стек сипаттамасы.
Tsymblnfo құрлымының грамматика символы туралы ақпарат сақтайтын өріс SymbType өрісі. Ол екі мән қабыладай алады: SYMBLEX (терминалды символ) немесе SYMBSYNT(терминалды емес символ) және қосымша мәлімет:
· Лексемге сілтеме (LexOne) – терминалды символ үшін;
· Барлық компонентер тізімі (LexList) – терминалды емес үшін.
Терминалды емес символдың барлық компонентер тізімі LexList динамикалық массив негізінде құралған(Delphi 5 жүйелік бағдарламалаудың VCL кітапханаысындағы TList-тің бір түрі). Оның ішінеграматтика ережесімен сәйкес ретмен орналасқан,берілген символға негізі болып табылатын, символға сілтемелер енгізіледі.
TSymbol құрлымы символ туралы ақпаратты қамтиды(Symblnfo өрісітің Tsymblnfo түрі), және де символ негізінде құралған грамматика ережесі нөмерін қамтиды (iRuleNum мәліметтер өрісі). Терминалды сиволдар үшін ереже нөмері 0-ге тең, ал терминалды емес символдар үшін ол 1-ден 13-ке дейін болуы мүмкін.
Осы мәліметтерден басқа құрлымда грамматика символдармен жұмыс жасайтын әдістер бар:
· Лексема негізінде терминалды символ құру үшін CreateLex конструкторы;
· Бастапқы символдар массиві және грамматика ережелері негізінде терминалды емес символды құру үшін CreateSymb конструкторы
· Символды жойған кездегі жадыны бостау үшін Destroy деструкторы.( терминалды емес символды жойған кезде оның барлық сілтемелері және оларды сақтайтын динамикалық массиві жойылады).
· Мәліметтер құрлымында сақталатын ақпаратпен жұмыс істеу функциялары және процедулары.
TSymbol құрлымының Symblnfo өріс мәліметтерінде барлық сілтемелер сақталса, оның ішінде олардың құрамдас бөліктеріне сілтемелер болуы мүмкін,онда TSymbol құрлымының негізінде толық синтаксистік талдау ағашын құруға болады.
Мәліметтердің үшінші TsymbStack құрлымы Delphi 5 жүйелік бағдарламалаудың VCL кітапханаысындағы TList динамикалық массив түрінің негізінде құрылған. Ол МП – автоматының синтаксистік стегін моделдеуі үшін құрылған. Бұл құрлымда ешқандай мәлімет жоқ(TList класынан мұраға қалған мәліметтер ғана пайдаланылады),бірақ онымен синтаксистік стектін жұмыс істеу әдістері байлнысқан:
· Стекті тазарту (Clear) және стекті жойғанда жадыны бостау деструктор (Destroy) функциясы;
· Стек шыңынан бастап симолға қол жеткізу функциясы (GetSymbol);
· Кіріс лексеманы стекке орналастыру функциясы(Push), сонымен қатар лексема терминалды символға ауысады.
· Стектегі ең жоғарғы лексеманы қайтаратын функция(TopLexem), терминалды емес символдар көрсетілмейді.
· Свертка жасайтын функция(MakeTopSymb);свертка нәтежесінде пайда болған жаңа символ стектің шыңында орналасады.
SyntSymb модулінде жоғардағы айтылған үш құрылымнан басқа, оперативті басымдылығы бар грамматика үшін «сдвиг-свертка» алгоритмінің жұмысын моделдейтін BuildSyntList функциясы сипатталады. Бұл функция үшін кіріс мәліметтер ол лексем тізімі(listLex) болып табылады. Ол лексикалық талдау нәтежесінде толтыруы қажет және функция орындалған уақытта бос болуы қажет синтаксистік стек (symbStack) арқылы толтырылады. Функция нәтежесі келесідей:
· Терминалды емес символ(синтаксистік ағаштың түбіне сілтеме жасап тұрған),егер талдау сәтті аяқталса;
· Терминалды символ, қате табылған жердегі лексемге сілтеме береді, егер талдау сәтті орындалса.
BuildSyntList функциясы оперативті басымдылығы бар грамматика үшін «сдвиг-свертка» алгоритмін моделдейді. Ол «Краткие теоретические сведения» бөліміндегідей сипатталады.
6.3Анықтауыштың бағдарлама мәтіні.
Жоғарыда жазылған модулдерден басқа, қолданушымен интерфейсті байланыстыратын модуль қажет. Бұл модуль (FormLab3), TForm класы негізінде VCL кітапханасының TLab3Form графикалық терезесін іске қосады және екі крмпоненттен тұрады:
· Бағдарламалық коды бар файл(Form Lab3.pas файлы);
· Қолданушы интерфейсінің ресурстардың сипатталу файлы(Form Lab3.dfm)
Form Lab3 модулі Form Lab 2 модулі негізінде құралған және № 2 зертханалық жұмыстағы интерфейсті іске асыру үшін пайдаланылған болатын.Ол және № 2 зертханалық жұмыстағы барлық ақпараттады, басқарушы және интерфейсті элементерді қамтиды. Ол № 3 зертханалық жұмыстағы бірінші кезені модулдермен орындалатын лексикалық талдау болғандықтан № 2 зертханалық жұмыс үшін құралған болатын.
№ 2 зертханалық жұмыстағы сипатталған лексикалық талдаудағыдай модулде синтаксистік талдау жасайтын синтаксистік стек үшін қолданылатын symbStack өрісін қамтиды. Бұл стек интерфейсті форма орындалғанда құрылады және оны жапқан уақытта ол жойылады. Синтаксистік және лексикалық талдау процедуралары іске қосылғанда, ол әрдайым тазатып отырады.
№ 2 зертханалық жұмыстағы басқару элементтерінен басқа Form Lab3 модулінде сипатталған интерфейстік форма, № 3 зертханалық жұмыстағы синтаксистік талдауыш үшін басқару элементтерін қамтиды:
· Көп бетті вкладкада(PageControl) «Синтаксис» атауы бар жаңа закладка (SheetSynt) пайда болды;
· SheetSynt закладкасында иерархиялық құрлымы бар интерфейстік элемент орналасқан(TTreeView түріндегі TreeSynt).
TLab3Form интерфейстік форманың жаңа закладка көрінісі 3.3 суретте келтірілген
Кіріс файлын мазмұнын оқу № 2 зертханалық жұмыста сияқты ұйымдастырылған.
Файл оқылғанна кейін оқу № 2 зертханалық жұмыста сияқты лексикалық талдау орындалады.
Егер лексикалық талдау сәтті орындалса, ListLex лексем тізімінде ақпараттық лексема қосылады. Ол жолдың соңын белгілейді, содан соң синтаксистік талдау жасайтын BuildSyntList функциясын шақырылады. Оның енгізу кезінде ListLex лексем тізімі және symbStack синтаксистік стекгі беріледі. Функцияның орындалу нәтежесі symbRes уақытша айнымалысында сақталады.
Егер symbRes айнымалысы лексемге сілтемесі болса, онда синтаксистік талдау қателермен орындалған және бұл лексема қатенің табылған жерін көрсетіп тұрған дегенді білдіреді. Кіріс файлының жол тізімі қате бар жерге тоқталады және қолданушыға қателік туралы хабарлама беріледі.
Егер қате табылмаған уақытта symbRes айнымалысы құрылған синтаксистік ағаштың түбірін көрсетеді. Онда TreeSynt интерфейс элементіне синтаксистік ағаштың түбіріне сілтеме жазылады,содаң соң ағаш MakeTree функциясы арқылы экранда көрсетіледі.
MakeTree функцясы TTreeView түріндегі интерфейс элементіндегі синтакиситік ағашты бейнелеуін қамтамасыз етеді. TTreeView элементі Windows ОЖ-дағы иерархиялық құрлымды бейнелеу үшін стандартты интерфейстік элемент болып табылады(мысалы үшін ол файлдық құрлымды бейнелеу үшін қолданылады).
7 Лексическалық анализаторды жобалау .
Бэкуса-Наура формасындағы кірістіру тіліндегі КС-грамматика :
шартты белгілеулер:
x1 – все символы кроме «^»
x2 – все символы кроме: 0..9, a..z, ^
х3 – все символы кроме: =
x4 – все символы кроме: 0..9, е, ^ , .
x5 – все символы кроме: ^ , .
х6 – все символы кроме: 0..9
х7 – все символы кроме: +, –
х8 – все символы кроме: 0..9, е, ^
х9 – все символы кроме: .
х10– все символы кроме: 0..9, ^
x11 – символы a..z
x12 – символы 0..9
x13 – символы 1..9
x14 – символы a..z,0..9
х15 – все символы
^-знак пробела
G({0..9, a..z, ; , : , ^ , +, –, /, *, (, ), .}, {S, F, T, I, P1, P2, Z, C1, D1, D2, D3, L1, L2, L3, L4, L5, L6, E},P,S)
P:
F®(|)
T®;
I®x11|Ix14
P1®:
P2®P1=
Z®+|–|*|/
C1®x13|C1x12
D1®0
D2®D1.|C1.
D3®D2x12|D3x12
L1®C1e|D3e
L2®Ll+|L1–
L3®L20
L4®L2x13
L5®L3.|L4.
L6®L5x12|L6x12
S®F^|T^|I^|P2^|Z^|C1^|D1^|D3^|L4^|L6^
E®Fx1|Tx1|P2x1|Ix2|P1x3|Zx2|C1x4|D1x5|D2x6|D3x8|L1x7|L2x6|L3x9|L4x5|L5x6|L6x10|Ex15
КА ауысу графы:
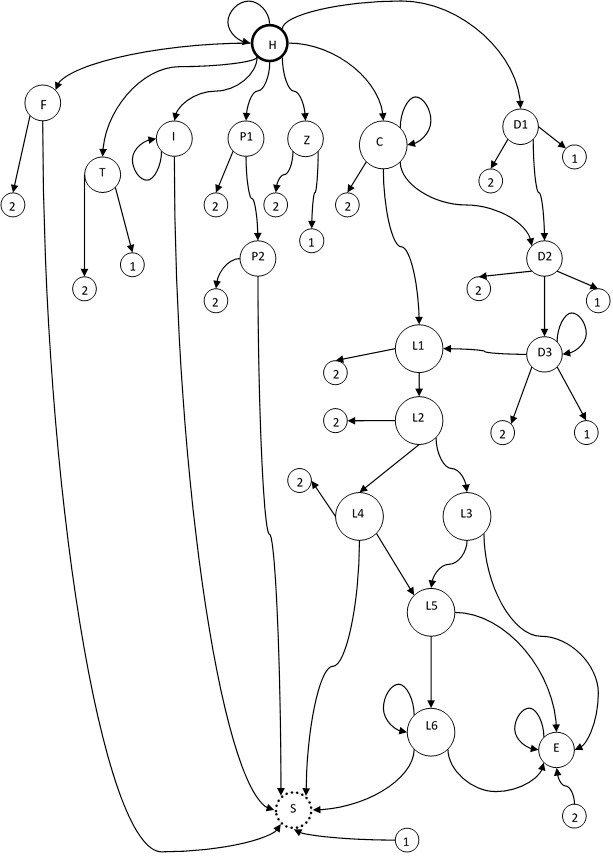
Сурет 1. КА ауысу графы
Қосымша А
Программа листингі:
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls, ComCtrls, Grids;
type
TAutoState = (AUTO_H,AUTO_F,AUTO_T,AUTO_I,AUTO_P1,AUTO_P2,AUTO_Z,AUTO_C1,AUTO_D1,
AUTO_D2,AUTO_D3,AUTO_L1,AUTO_L2,AUTO_L3,AUTO_L4,AUTO_L5,AUTO_E,AUTO_L6);
TForm1 = class(TForm)
PageControl1: TPageControl;
TabSheet1: TTabSheet;
Button2: TButton;
Memo1: TMemo;
TabSheet2: TTabSheet;
Memo2: TMemo;
OpenDialog1: TOpenDialog;
StringGrid1: TStringGrid;
Button1: TButton;
Button4: TButton;
Label1: TLabel;
procedure FormCreate(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure Button1Click(Sender: TObject);
procedure Button4Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
implementation
{$R *.dfm}
procedure TForm1.FormCreate(Sender: TObject);
begin
Memo1.Text:='';
Memo2.Text:='';
StringGrid1.Cells[0,0]:='Номер';
StringGrid1.Cells[1,0]:='Значение';
StringGrid1.Cells[2,0]:='Лексема';
end;
procedure TForm1.Button2Click(Sender: TObject);
var ind,pos,dl,i,j,i1,fl,zn:integer;
st,str,sInput:string;
iState:TAutoState;
begin
if OpenDialog1.Execute then Memo1.Lines.LoadFromFile(OpenDialog1.FileName) ;
for i:=0 to 2 do
for j:=1 to 999 do
StringGrid1.Cells[i,j]:=' ';
j:=Memo1.Lines.Count;
ind:=1;
pos:=1;
for i:=1 to j do
begin
str:='';
sInput:=Memo1.Lines[i-1];
sInput:=sInput+' ';
dl:=Length(sInput);
iState:=AUTO_H;
fl:=0;
zn:=0;
for j:=1 to dl do
begin
st:=sInput[j];
case iState of
AUTO_H:
case sInput[j] of
'(',')': begin iState:=AUTO_F;str:=str+st; end;
';': begin iState:=AUTO_T;str:=str+st; end;
'a'..'z': begin iState:=AUTO_I;str:=str+st; end;
':': begin iState:=AUTO_P1;str:=str+st; end;
'+','-','*','/':begin iState:=AUTO_Z;str:=str+st; end;
'1'..'9': begin iState:=AUTO_C1;str:=str+st; end;
'0': begin iState:=AUTO_D1;str:=str+st; end;
' ': begin iState:=AUTO_H;str:='';end;
else begin iState:= AUTO_E;str:=str+st; end;
end;
AUTO_F:
case sInput[j] of
' ': begin iState:=AUTO_H;fl:=1;zn:=1;end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_T:
case sInput[j] of
' ':begin iState:=AUTO_H;fl:=1;zn:=8; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_I:
case sInput[j] of
' ': begin iState:=AUTO_H;fl:=1;zn:=2;end;
'a'..'z','0'..'9':begin iState:=AUTO_I;str:=str+st; end;
else begin iState:=AUTO_E; str:=str+st; end;
end;
AUTO_P1:
case sInput[j] of
'=':begin iState:=AUTO_P2;str:=str+st;end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_P2:
case sInput[j] of
' ':begin iState:=AUTO_H;fl:=1;zn:=3;end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_Z:
case sInput[j] of
' ': begin iState:=AUTO_H;fl:=1;zn:=4;end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_C1:
case sInput[j] of
' ': begin iState:=AUTO_H;fl:=1;zn:=5;end;
'0'..'9':begin iState:=AUTO_C1;str:=str+st; end;
'e':begin iState:=AUTO_L1;str:=str+st; end;
'.':begin iState:=AUTO_D2;str:=str+st; end;
else begin iState:=AUTO_E; str:=str+st; end;
end;
AUTO_D1:
case sInput[j] of
' ': begin iState:=AUTO_H;fl:=1;zn:=6; end;
'.': begin iState:=AUTO_D2;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_D2:
case sInput[j] of
'0'..'9': begin iState:=AUTO_D3;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_D3:
case sInput[j] of
' ': begin iState:=AUTO_H;fl:=1;zn:=7; end;
'e':begin iState:=AUTO_L1;str:=str+st; end;
'0'..'9': begin iState:=AUTO_D3;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_L1:
case sInput[j] of
'+','-':begin iState:=AUTO_L2;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_L2:
case sInput[j] of
'0':begin iState:=AUTO_L3;str:=str+st;end;
'1'..'9': begin iState:=AUTO_L4;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_L3:
case sInput[j] of
'.':begin iState:=AUTO_L5;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_L4:
case sInput[j] of
' ':begin iState:=AUTO_H;fl:=1;zn:=9;end;
'.':begin iState:=AUTO_L5;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_L5:
case sInput[j] of
'0'..'9':begin iState:=AUTO_L6;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_L6:
case sInput[j] of
' ':begin iState:=AUTO_H;fl:=1;zn:=10;end;
'0'..'9':begin iState:=AUTO_L6;str:=str+st; end;
else begin iState:=AUTO_E;str:=str+st; end;
end;
AUTO_E: begin
if sInput[j]<>' 'then
begin
iState:=AUTO_E;
str:=str+st;
end
else
begin
iState:=AUTO_H;
Memo2.Lines.Append(str);
str:='';
end;
end;
end;
if fl=1 then
begin
StringGrid1.Cells[0,ind]:=IntToStr(ind);
StringGrid1.Cells[1,ind]:=str;
case zn of
1: StringGrid1.Cells[2,ind]:='Круглая скобка';
2: StringGrid1.Cells[2,ind]:='Идентификатор';
3: StringGrid1.Cells[2,ind]:='Оператор присваивания';
4: StringGrid1.Cells[2,ind]:='Арифметическая операция';
5, 6: StringGrid1.Cells[2,ind]:='Целое число';
7: StringGrid1.Cells[2,ind]:='Дробное число';
8: StringGrid1.Cells[2,ind]:='Разделитель';
9: StringGrid1.Cells[2,ind]:='Логарифмическое число с целой степеью';
10: StringGrid1.Cells[2,ind]:='Логарифмическое число с дробной степеью';
end;
str:='';
ind:=ind+1;
fl:=0;
end;
end;
end;
end;
procedure TForm1.Button1Click(Sender: TObject);
begin
close;
end;
procedure TForm1.Button4Click(Sender: TObject);
begin
close;
end;
end.
Бастапқы файл мазмұны:
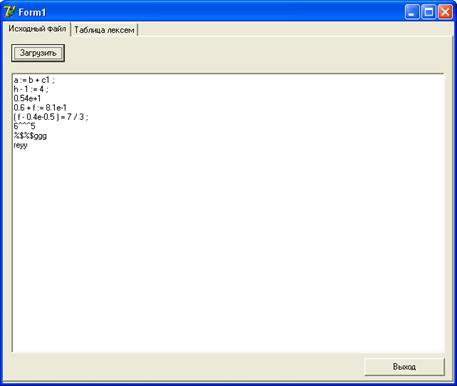
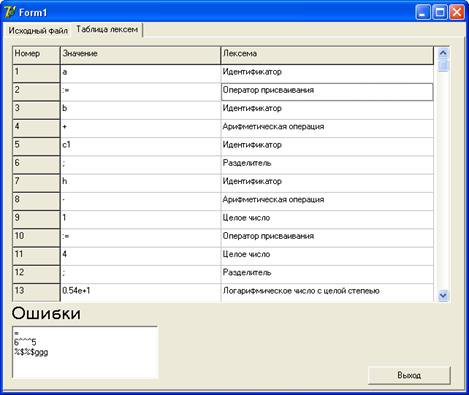
Лексем кестесі:
Қорытынды
Бұл курстық жұмыста синтаксистік анлизатор және лексикалық анализатор ұғымдары қарастырылды. Осы курстық жұмыс нәтежесінде кірістіру мәтінінде керекті лексемаларды ерекшелейтін лексикалық анализатор құрылды. Бұл анализатор дұрыс емес лексемаларды қате лексемалар өрісіне сақтайды және жұмысты файлдың соңына дейін жалғастырады.
Қолданылған әдебиеттер:
1. Системное программное обеспечение: Учебник для вузов/ А.Ю. Молчанов- СПб.: Питер, 2003.- 396 с.
2. Системное программное обеспечение. Лабораторный практикум/ А.Ю. Молчанов- СПб.: Питер, 2005.- 284 с.
0 комментариев