CGI
Common Gateway Interface - это спецификация интерфейса взаимодействия Web-сервера с внешними прикладными программами. Главное назначение CGI - обеспечение единообразного потока данных между сервером и работающим на нем приложением. CGI определяет:
порядок взаимодействия сервера с прикладной программой, в котором сервер выступает инициирующей стороной; механизм реального обмена данными и управляющими командами в этом взаимодействии, что не определено в протоколе HTTP. Такие понятия, как метод доступа, переменные заголовка, MIME, типы данных, заимствованы из HTTP и делают спецификацию прозрачной для тех, кто знаком с самим протоколом.Обычно гипертекстовые документы, возвращаемые по запросу клиента WWW сервером, содержат статические данные. CGI обеспечивает средства создания динамических Web-страниц на основе данных, полученных от пользователя. Программы, написанные в соответствии со спецификацией CGI, называются CGI-скриптами или шлюзами. Шлюз - это CGI-скрипт, который используется для обмена данными с другими информационными ресурсами Internet или приложениями-демонами такими, как, например, система управления базами данных. Обычная CGI-программа запускается Web-сервером для выполнения некоторой работы, возвращает результаты серверу и завершает свое выполнение (рис. 1).
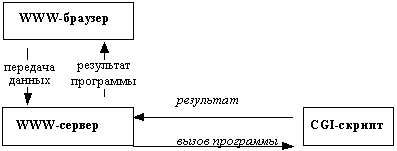
Рис. 1. Схема взаимодействия CGI-скрипта.
Шлюз выполняется точно также, только, фактически, он инициирует взаимодействие в качестве клиента с третьей программой (рис. 2). Если эта третья программа является сервером БД, то шлюз становится клиентом СУБД, который посылает запрос по определенному порту соединения с системой управления базами данных, а после получения ответа пересылает его WWW-серверу.
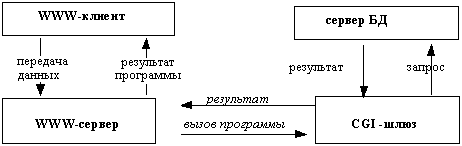
Рис.2. Схема взаимодействия CGI-шлюза.
Обмен данными по спецификации CGI реализуется обычно через переменные окружения и стандартный ввод/вывод. Выбор механизма передачи параметров определяется методом доступа, который указывается в форме в атрибуте METHOD. Если используется метод GET, то передача параметров происходит с помощью переменных окружения, которые сервер создает при запуске внешней программы. Через них передается приложению как служебная информация (версия программного обеспечения, доменное имя сервера и др.), так сами данные (в переменной QUERY_STRING). При методе POST для передачи используется стандартный ввод. А в переменных окружения фиксируется тип и длина передаваемой информации (CONTENT_TYPE и CONTENT_LENGTH).
Стандартный вывод используется скриптом для возврата данных серверу. При этом вывод состоит из заголовка и собственно данных. Результат работы скрипта может передаваться клиенту без каких-либо преобразований со стороны сервера, если скрипт обеспечивает построение полного HTTP-заголовка, в противном случае сервер модифицирует заголовок в соответствии со спецификацией HTTP. Обязательным для скриптов при генерировании документов "на лету", когда реального документа в файловой системе сервера не остается является только HTTP-заголовок Content-type, в котором указывается тип возвращаемого документа для правильной интерпретации браузером. Обычно в Content-type указывают текстовые типы text/plain и text/html. При использовании такого вида скриптов следует учитывать, что не все серверы и клиенты отрабатывают так, как представляется разработчику скрипта. Так, при указании Content-type: text/html, некоторые клиенты не реализуют сканирования полученного текста на предмет наличия в нем встроенной графики
При применение спецификаци CGI для обмена данными с внешними прикладными программами можно выделить следующие преимущества:
Прозрачность использования; "Языковая" независимость - CGI-программы могут быть написаны на любом языке программирования или командном языке, имеющим средства работы со строками; Процессная изолированность - при запуске CGI-програмы на сервере порождается отдельный процесс и ошибочный CGI-скрипт не может сломать Web-сервер или получить доступ к закрытой информации; Открытость стандарта - CGI интерфейс применим на каждом Web-сервере; Архитектурная независимость - CGI не зависит от особенностей реализации архитектуры сервера (однопоточности, многопоточности и т.д.);Но CGI имеет также и существенные недостатки. Главная проблема заключается в затратах на выполнение CGI-приложений: поскольку на сервере для каждого очередного запроса порождается новый процесс, который завершается после его выполнения, то это приводит к невысокому быстродействию CGI-скрипта и снижает эффективность работы сервера. При использовании CGI-программ для доступа к базам данных из-за неподдержки непрерывного соединения Web-сервера и соответствующей СУБД очень сложно произвести процесс "ведения" пользователя базой данных, так как каждый раз при генерации очередного запроса требуется новое подключение. Но в то же время закрытие соединения после обработки каждого запроса сильно осложняет деятельность хакеров, так как при отсутствии постоянного подключения к БД проникнуть в нее гораздо сложнее. Другое достоинство этого "недостатка" состоит в том, что связь с Web-сервером устанавливается только на короткий промежуток времени, в результате чего он не перегружается и может выполнять другие задачи.
CGI`также ограничен по способности функционирования - спецификация предусматривает только простую "ответную" роль скрипта при генерации результата на запрос пользователя. CGI-программы не имеют взаимосвязей с установлением аутентификации пользователя и проверки его входных данных.
API
В ответ на ограничения и недостатки спецификации CGI была разработана спецификация прикладных модулей API, встроенных в сервер. Данное расширение Web-сервера запускается как динамическая библиотека и выполняет обработку каждого вызова сервера по отдельной структуре памяти, что значительно проще, чем создание отдельного процесса для каждого клиентского запроса. Наиболее известны два API-интерфейса - NSAPI компании Netscape и ISAPI компании Microsoft. Свободно распространяемый популярный Unix-сервер Apache также имеет модуль PHP, реализующий данный интерфейс. Приложения, работающие через API, соединяются с сервером значительно быстрее, чем CGI-программы, так как API выполняется в основном процессе сервера и постоянно находится в состоянии ожидания запросов, поэтому время на запуск программы и порождения нового процесса не требуется. API-интерфейс предоставляет и большую функциональность, чем CGI - можно написать дополнительные процедуры, осуществляющие контроль доступа к файлам, получающие доступ к log-файлам сервера и связывающиеся с другими этапами обработки запроса сервером.
Тем не менее спецификация API не имеет преимуществ CGI-интерфейса и поставщики API-модулей тоже сталкиваются с целым рядом проблем:
"Языковая" зависимость - прикладные программы могут быть написаны только на языках, поддерживаемых в данном API (обычно это С/C++); Perl, наиболее популярный язык для CGI-скриптов, как правило, не используется в существующих поставляемых API-модулях. Неизолированность процесса - так как приложения выполняются в адресном пространстве сервера, то ошибочные программы могут "уронить" сервер или какое-либо приложение. Таким образом вполне возможно (намеренно или нет) сломать систему безопасности сервера. Ограниченность применения - написанные программы в соответствии с данным API могут использоваться только на данном сервере. Архитектурная зависимость - API-приложения зависимы от архитектуры сервера: если сервер поддерживает однопоточность, то многопотоковые приложения не получают никакого преимущества в быстродействии при выполнении. Также при изменении производителем архитектуры сервера, модуль API обычно тоже подвергается изменениям, и прикладные программы соответственно тоже требуют переделки или даже могут быть написаны заново.FastCGI Интерфейс FastCGI сочетает в себе наилучшие аспекты спецификаций CGI и API. Взаимодействие в соответствии с FastCGI происходит сходным образом с CGI. FastCGI-приложения запускаются отдельными изолированными процессами. Отличие состоит в том, что эти процессы являются постоянно работающими и после выполнения запроса не завершаются, а ожидают новых запросов. Вместо использования переменных окружения операционной системы и стандартных потоков ввода/вывода протокол FastCGI объединяет информацию среды, стандартный ввод, вывод и сообщения об ошибках в единственное дуплексное соединение. Это позволяет FastCGI-программам выполняться на удаленных машинах, используя TCP-соединения между Web-сервером и FasstCGI-модулем.
Таким образом, преимущества FastCGI состоят в следующем:
Быстродействие - благодаря постоянному функционированию FsatCGI-процессов обеспечивается обслуживание одним процессом многих запросов, что решает задачу и связанные с ней проблемы порождения нового процесса на отдельный клиентский запрос. Простота применения и легкость миграции из CGI. "Языковая" независимость - как и CGI, FastCGI-приложения могут быть написаны на любых языках программирования или командных языках. Изолированность процессов - "неисправные" FastCGI-программы не могут разрушить ядро сервера или какие-либо другие приложения, а также получить секретную служебную информацию. Совместимость - FastCGI поддерживается во всех открытых продуктах, включая коммерческие серверы Netscape и Microsoft, NCSA сервер и свободно распространяемый Apache. Архитектурная независимость - FastCGI интерфейс не зависит от особенностей реализации серверной архитектуры и прикладные программы могут быть как одно-, так и многопоточными. Распределенность - FastCGI обеспечивает возможность выполнять приложения удаленно, что используется для распределенной загрузки и управления внешними Web-сайтами. Доступ к базам данных на стороне клиента. Java-технологияДля обеспечения доступа к базам данных на стороне Web-клиента применяется Java-технология. Java - это современный объектно-ориентированный язык программирования для разработки приложений, созданный специально для распределенных сред. Технология Java позволяет создавать полноценные приложения для работы с компьютерной графикой, файловыми системами и компьютерными сетями.
Одно из важных свойств Java-технологии - это мобильность, суть которой заключается в том, что написанный на Java код может исполняться на любой компьютерной платформе. Java-приложения компилируются в особый код (так называемый байт-код), исполняемый на виртуальной машине (Java Virtual Machine). Байт-код является универсальным форматом программы, единым для всех аппаратных платформ - и для рабочих станций, и для больших универсальных ЭВМ, и для персональных компьютеров. Java-технология обеспечивает быстрый цикл компиляции и отладки программ. Еще на стадии компиляции проводится выявление многих ошибок и частичная оптимизация программ. Средства разработки, содержащие виртуальную машину внутри себя, обеспечивают контроль приложений на стадии исполнения (переполнение стека, отслеживание границ массивов, поиск резервов для оптимизации и др.).
Пользователю готовых Java-приложений достаточно иметь клиентскую программу, имитирующую работу виртуальной машины. Виртуальная машина представляет собой довольно компактный интерпретатор байт-кода Java. Перед первым запуском нового приложения виртуальная машина проверяет его код на принадлежность к байт-коду (на правильность инструкций Java), безопасность команд для компьютера и локальной сети, соответствие разрешенным операциям, а также на целый ряд дополнительных условий. Это необходимо, поскольку приложения, распространяемые по сети, создаются разными людьми с различными намерениями, причем дурные намерения тоже не исключены. Непосредственно перед запуском виртуальная машина производит сборку модулей и устанавливает связи между именами, при этом поиск недостающих модулей производится не только в системе, но и на серверах Internet. Затем, собственно, и начинается работа приложений.
Технология разработки HTML-документа позволяет написать произвольное количество дополнительных Java-программ, откомпилировать их в мобильные коды и поставить ссылки на соответствующие коды в теле HTML-документа. Такие дополнительные Java-программы называются апплетами (Java-applets). Получив доступ к документу, содержащему ссылки на апплеты, клиентская программа просмотра запрашивает у Web-сервера все мобильные коды. Коды могут начать выполняться сразу после размещения в компьютере клиента или быть активизированы с помощью специальных команд.
Поскольку апплет представляет собой произвольную Java-программу, то, в частности, он может быть специализирован для работы с внешними базами данных. Опираясь на использование классов, апплет может получить от пользователя информацию, характеризующую его запрос к базе данных, в том же виде, как если бы использовался стандартный механизм форм языка HTML, а может применять какой-либо другой интерфейс.
Для взаимодействия Java-апплета с внешним сервером баз данных разработан специализированный протокол JDBC, который, фактически, сочетает функции шлюзования между интерпретатором мобильных Java-кодов и интерфейсом ODBC (Open Data Base Connectivity). JDBC - это разработанный JavaSoft прикладной программный SQL интерфейс API JDBC к базам данных. Этот API позволяет использовать стандартный набор процедур высокого уровня для доступа к различным БД.
JDBC базируется на интерфейсе уровня вызовов X/Open SQL CLI - основе ODBC. Прикладной программный интерфейс JDBC реализуется поверх других SQL-API, включая ODBC. То есть, все базы данных, допускающих работу с ODBC, будут взаимодействовать с JDBC без изменений. При использовании JDBC Internet-пользователи подключаются к Web-серверу и загружают HTML-документ с апплетом. Апплет выполняется на клиентской ЭВМ в среде браузера и устанавливает связь с сервером базы данных. Механизм связи с базами данных является классом Java.
Архитектура JDBC состоит из двух уровней: JDBC API, который обеспечивает связь между приложением и менеджером JDBC и драйвер JDBC API, который поддерживает связь между JDBC менеджером и драйвером (рис.3). Разработчики имеют возможность взаимодействовать напрямую с ODBC посредством моста JDBC-ODBC.
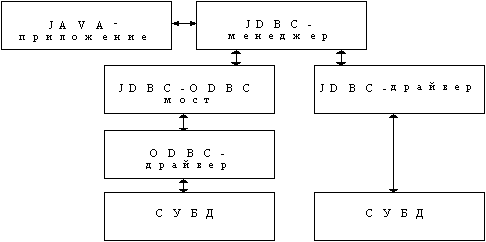
Рис.3. Схема взаимодействия Java-приложений с сервером БД
JDBC API представляет собой набор классов (пакет или package) для установки соединений с базами данных, создания SQL-выражений, обработки результатов. JDBC-драйвера могут быть написаны на Java и загружены как часть апплета или быть написаны используя "родной" код компьютера (как шлюз к существующим библиотекам СУБД API). Примером такого шлюза является JDBC-ODBC мост (JDBC-ODBC bridge). Он транслирует JDBC запросы в вызовы ODBC, что позволяет получить доступ к огромному множеству существующих ODBC драйверов.
Использование Java-апплетов в общем обеспечивает более гибкое решение.Так как апплет - это часть HTML-документа, то для включения нового апплета нужно всего-навсего перекомпоновать документ без задействия Web-cервера. Апплеты передаются по сети только в тот момент, когда их нужно выполнять. При этом они могут загружаться из разных мест и после загрузки взаимодействовать друг с другом.
С другой стороны, байт-код Java исполняется интерпретатором, а не является откомпилированной на данной платформе программой. Отсюда возникает первый очевидный недостаток - это скорость выполнения кода, так как интерпретатор работает гораздо медленнее откомпилированной программы. Собственно, и другие свойства технологии (объектная ориентируемость, использование многопоточности, отсутствие адресной арифметики и т.п.) в большинстве случаев при стандартной комплектации оборудования, только тормозят выполнение программы.
Основной протокол обмена апплетами - HTTP. Это значит, что они передаются по сети точно также, как и другие ресурсы Website, и приобретают свое особое значение только в момент получения их браузером. Учитывая неэффективность реализации HTTP поверх TCP, можно сказать, что и обмен апплетами тоже неэффективен, если для каждого обмена устанавливается свое TCP-соединение. В любом случае загрузка страниц с Java происходит гораздо медленнее, чем без Java.
Java-технология является еще технологией, находящейся в стадии разработки. Интерфейс взаимодействия прикладных программ CGI имеет уже достаточный опыт в применении для обработки данных и доступа к БД. По сравнению с Java, он является не только отлаженным механизмом, но и более простым и удобным средством для разработчиков CGI-программ, так как они могут быть созданы на любом языке, имеющим средства работы со строками.
Выбор средства доступа к базам данных во многом определяется не только эффективностью того или иного механизма, но также и наилучшим его сопряжением с соответствующей СУБД. От того, какие средства предоставляет сама СУБД для доступа к своим базам данных из внешних прикладных программ может зависеть выбор предпочтения. Сейчас разработано достаточно много коммерческих СУБД, но все же хочется обратить внимание на свободно распространяемые продукты, которые часто оказываются не менее эффективными, но из-за "неизвестности" не достаточно широко используются. Одним из таких некоммерческих продуктов является СУБД POSTGRES95, которая устанавливается на большинстве существующих платформ -DEC Alpha AXP on OSF/1 2.0, HP PA-RISC on HP-UX 9.0, i386 Solaris, SUN SPARC on Solaris 2.4, SUN SPARC on SunOS 4.1.3, DEC MIPS on Ultrix 4.4, Intel x86 on Linux 1.2 and Linux ELF, BSD/OS 2.0, 2.01, 2.1, IBM on AIX 3.2.5, SGI MIPS on IRIX 5.3, DG/UX 5.4R3.10 и др.
Постреляционная СУБД POSTGRES95СУБД POSTGRES95 была спроектирована и разработана в Калифорнийском университете г. Беркли под руководством известного специалиста в области баз данных профессора Стоунбрейкера, который в 1975-1980 гг. создал довольно популярную реляционную СУБД Ingres. Направление POSTGRES принадлежит к числу так называемых постреляционных систем - к следующему этапу в развитии реляционных СУБД. В настоящее время основным предметом критики последних является не их недостаточная эффективность, а присущая этим системам некоторая ограниченность (прямое следствие простоты) при использовании в нетрадиционных областях, в которых требуются предельно сложные структуры данных. Другим, часто отмечаемым недостатком реляционных баз данных, является невозможность адекватного отражения семантики предметной области. Поэтому современные исследования в области постреляционных систем, главным образом, посвящены устранению именно этих недостатков, и во многом требования к этим системам означают просто необходимость реализации свойств, отсутствующих в большинстве текущих реляционных СУБД. В их число, например, входит полнота системы типов, поддержка иерархии и наследования типов, возможность управления сложными объектами и т.д. СУБД POSTGRES95, являясь постреляционной системой, сохраняет основные свойства реяционных СУБД и в то же время имеет свои, отличные от других, возможности.
СУБД POSTGRES95 поддерживает темпоральную модель хранения и доступа к данным. То есть для любого объекта данных, созданного в момент времени t1 и уничтоженного в момент времени t2, в БД сохраняются (и доступны пользователям) все его состояния во временном интервале (t1,t2). Обычные же БД хранят мгновенный снимок модели предметной области, и любое изменение в момент времени t некоторого объекта приводит к недоступности этого объекта в предыдущий момент времени. Хотя, на самом деле, в большинстве развитых СУБД предыдущее состояние объекта сохраняется в журнале изменений, но осуществления доступа со стороны пользователя нет.
В связи с этим, в POSTGRES95 пересмотрен механизм журнализации изменений, откатов транзакций и восстановления БД после сбоя. Особенность системы управления памятью заключается в том, что не ведется обычная журнализация и мгновенно обеспечивается корректное состояние БД с утратой состояния в оперативной памяти. Также система управления памятью поддерживает исторические данные, соответствующие возможности работы с которыми заложены в язык POSTQUEL. Запросы могут содержать выборку данных в определенное время, в определенном интервале времени. Например, результатом запроса
SELECT city, population FROM cities['epoch','now'] WHERE city='Moscow';
будет являться следующая таблица:
| city | population |
| Moscow | 7 360 000 |
| Moscow | 8 950 000 |
Кроме этого, имеется возможность создавать версии отношений и допускается их последующая модификация с учетом изменений основных вариантов.
Основное решение этих аспектов состоит в том, что при модификации кортежа изменения производятся не на месте его хранения, а заводится новая запись, куда помещаются измененные поля. Эта запись, содержащая также и данные, характеризующие транзакцию, производившую изменения (в том числе и время ее завершения), подшивается в список к изменявшемуся кортежу.
Одним из основных положений реляционной модели данных является требование нормализации отношений: поля кортежей могут содержать лишь атомарные значения. Приведение исходного табличного представления предметной области к первой нормальной форме является основным шагом в процессе проектирования реляционной базы данных. В СУБД POSTGRES95 реализована "ненормализованная" реляционная модель данных, которая допускает хранение в качестве элемента кортежа многомерных массивов фиксированной и переменной длины, и других данных, в том числе абстрактных, определенных пользователями типов:
CREATE TABLE salary (name text,pay_by_quarter int4[ ], schedule char16[ ][ ]);
Это свойство POSTGRES95 сближает ее со свойствами объектно-ориентированных СУБД, хотя семантические возможности модели данных POPSTGRES95 существенно слабее.
Язык запросов СУБД POSTGRES95 - POSTQUEL- является вариантом нового стандарта языка SQL-3. Он имеет операторы для определения схемы базы данных (CREATE TABLE, ALTER TABLE), манипулирования данными (UPDATE- заменить, DELETE - удалить, SELECT- выбрать, INSERT- вставить и др.), операторы управления транзакциями, предоставлений и ограничений доступа и др. POSTQUEL, кроме этого, предоставляет много дополнительных возможностей. В их число входят расширенная система типов (кроме обычных типов int, float, real, smallint, char(N), varcha(N), date, time и др. реализована возможность создания пользователями произвольного числа своих типов), поддерживается иерархия и наследование классов, предоставляется возможность определения собственных функций, операторов и агрегатов. В таблицах могут храниться данные размером более 8 KB. Это позволяет осуществлять, так называемый, интерфейс больших объектов (Large Objects Interface), который применяет файл-ориентированный доступ к данным, объявленных как тип large. POSTQUEL не поддерживает подзапросы, но они могут легко быть осуществлены с помощью самостоятельно написанных SQL-функций.
POSTQUEL поддерживает два типа функций: SQL-функции и функции, написанные на языке программирования, например, на Си. Кроме функций, пользователь может создавать свои агрегаты и операторы. POSTGRES95 позволяет легко вводить новые структуры, используя не физическую, а логическую модель хранения данных. В системных каталогах POSTGRES95, в отличие от стандартных реляционных систем, хранится информация не только об отношениях и атрибутах, но также и информация о типах, функциях, методах доступа и т.п. В POSTGRES95 системные каталоги представлены следующими классами: pg_database - базы данных; pg_class - отношения; pg_attribut - атрибуты; pg_proc - процедуры (и на Си, и на SQL); pg_type - типы; pg_aggregate - функции и агрегаты; и др. Каждый класс располагается в файле с соответствующим именем, которое начинается с pg_, куда помещаются все вносимые пользователем изменения при создании таблиц, типов, функций и т.д. Между классами установлены отношения, которые позволяют связывать различные структуры и осуществлять внутренние операции между ними.
Архитектура СУБД POSTGRES95Архитектура СУБД POSTGRES95 основана на модели "клиент-сервер". Сессия с СУБД состоит из следующих взаимодействующих процессов:
postmaster - управляющий процесс-демон, который руководит взаимодействием между внешними и внутренними процессами; он выделяет совместно используемый буффер динамической памяти и выполняет другие инициализации во время запуска. postgres - внутренний серверный процесс базы данных, исполняющий запросы клиента. Postmaster всегда запускает новый postgres-процесс для каждого клиентского приложения. Этот серверный процесс выполняется на машине сервера. внешняя прикладная программа, которая может находиться на другом компьюторе (например, рабочей станции). Она соединяется с postgres через postmaster.Один раз запущенный процесс-демон postmaster управляет установленным набором баз данных на серевере. Внешняя прикладная программа, желающая получить доступ к одной из этих баз данных, вызывает библиотеку функций прикладного программного интерфейса LIBPQ (рис.4). С помощью этих функций запрос по сети передается postmaster'у, который порождает серверный процесс и соединяет внешнюю программу с сервером. С этого момента клиентские и серверные процессы взаимодействуют без помощи postmaster'a. Таким образом, postmaster постоянно работает, ожидая запросов, в то время, как происходят и завершаются соединения с внешними приложениями. Прикладной программный интерфейс LIBPQ позволяет одной клиентской программе совершать во время одной сессии множественные соединения с сервером БД. Но тем не менее, внешняя программа - это однопотоковый процесс. Многопоточность процессов библиотекой LIBPQ не поддерживается. Другой особенностью архитектуры СУБД POSTGRES95 является то, что postmaster и postgres серверные процессы всегда выполняются на одной и той же машине - сервере базы данных, тогда как внешние программы могут находиться на любых машинах сети.
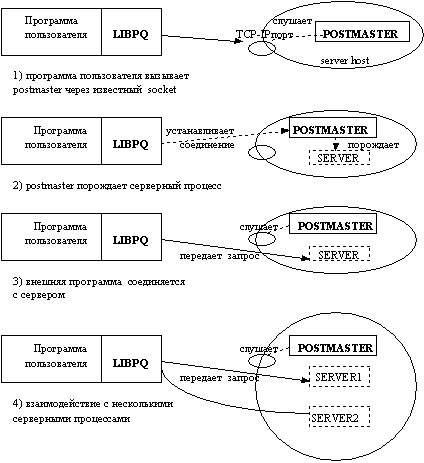
Рис. 4. Схема взаимодействия процессов POSTGRES95
Таким образом, СУБД POSTGRES95 позволяет осуществлять доступ клиентским прикладным программам к своим базам данных не только в локальном, но и удаленном режиме. Но система безопасности СУБД не предоставляет эту возможность всем пользователям. Для разрешения удаленного соединения с базами данных необходимо установить режим аутентификации для данного пользователя. По умолчанию в файле конфигурации этот режим отключен, и доступ разрешен только программам, расположенным в директории на машине сервера БД. Для установления аутентификации необходимо в файле pq_hba указать имена машин, с которых возможен удаленный доступ прикладным программам, и соответствующие базы данных, к которым разрешается удаленный доступ:
# <name> <address> <mask>
all 127.0.0.1 0.0.0.0
all 194.85.135.66 0.0.0.0
После этого необходимо произвести заново компиляцию системы.
Доступ к базам данных под управлением СУБД POSTGRES95В СУБД POSTGRES95 реализованы две основные возможности доступа к своим базам данных:
через psql - интерфейс командной строки командной оболочки Shell; из прикладной программы, написанной на языке программирования Си (или другом языке) с использованием функций прикладного интерфейса LIBPQ.Psql - это интерактивный терминальный монитор, позволяющий пользователю формулировать, редактировать и выполнять наборы команд - операторов языка POSTQUEL. Он запускается в режиме командной строки ОС UNIX с указанием имени базы данных:
% psql polyn
Пользователь может непосредственно из командной строки монитора вводить одну за другой SQL-команды, а может передавать запрос в виде файла с SQL-операторами через командную строку ОС UNIX:
% psql <>
Интерфейс командной строки psql обычно используют администраторы баз данных для создания, модификации и удаления отношений, заведения и предоставления прав новым пользователям и т.д. Он достаточно удобен для ввода больших массивов информации в базу данных и вывода простых отчетов. Интерактивный монитор не позволяет генерировать сложные формы отчетов, так как с его помощью нельзя сделать разборку полученного результата для формирования новых запросов, и поэтому его использование в прикладных программах достаточно ограниченно.
LIBPQ - прикладной программный интерфейс POSTGRES95. Он представлен набором библиотечных функций (подпрограмм), которые позволяют клиентским программам посылать запросы серверу СУБД и получать от него соответствующие результаты. Для этого в прикладную программу включают главный файл библиотеки libpq-fe.h , встраивают функции LIBPQ и производят компиляцию кода программы с библиотеками POSTGRES95. Схема доступа к базам данных из внешних программ достаточно простая. С помощью специальной функции PQsetdb устанавливается TCP-соединение по определенному порту (как правило, - 5432) прикладной программы с процессом-демоном postmaster'ом. При этом функции передаются параметры значений имени базы данных, IP-адреса сервера, порта соединения. Далее при успешном соединении происходит выполнение в рамках функции PQexec SQL-операторов языка запросов POSTQUEL - открытие транзакции с базой данных, выполнение запроса и закрытие транзакции. После этого происходит завешение соединения с базой данных. При выполнении запроса по выбору данных из БД POSTGRES95 создает временную таблицу, в которую помещает полученный результат. Используя SQL-операторы, связанные с курсорами, и специальные функции LIBPQ по работе с кортежами, полями отношений, достаточно просто осуществляется доступ к элементам результирующей таблицы, что приводит к генерации произвольных отчетов по запросам пользователей. Ниже приведен фрагмент Cи-программы, реализующей запрос к базе данных "polyn":
pghost= "ns.polyn.kiae.su"
pgport= "5432";
pgoptions=NULL;
pgtty=NULL;
dbname= "polyn"
/*установка соединения с базой данных */
conn = PQsetdb(pghost, pgport, pgoptions, pgtty, dbname);
/* проверка статуса выполнения соединения */
if (PQstatus(conn)== CONNECTION_BAD)
{ printf("connection to database '%s' failed", dbname);
printf("%s", PQerrorMessage(conn));
PQfinish(conn);
exit(1);
}
/* начало транзакции с БД*/
res=PQexec(conn,"BEGIN");
/* проверка статуса выполнения функции */
if (PQresultStatus(res)!=PGRES_COMMAND_OK)
{ printf("BEGIN command failed");
PQclear(res);
PQfinish(conn);
exit(1); }
PQclear(res);
/* выполнение SQL-опреатора установки курсора на результат запроса выбора поля isotop из отношения isotop */
res=PQexec(conn,"DECLARE myportal CURSOR FOR select isotop.isotop from isotop ");
/* выполнение оператора чтения по курсору */
res=PQexec(conn,"FETCH ALL in myportal");
/* определение количества кортежей и атрибутов в результирующей таблице */
ntups = PQntuples(res);
nflds = PQnfields(res);
/* вывод имен атрибутов */
for (i=0; i %s
",PQfname(res,i));
}
/* вывод элементов результирующего отношения */
for(i=0; i%s\n",PQgetvalue(res,i,j));
}
}
PQclear(res);
/* закрытие курсора */
res=PQexec(conn,"CLOSE myportal");
PQclear(res);
/* закрытие транзакции */
res=PQexec(conn,"END");
PQclear(res);
/* закрытие соединения*/
PQfinish(conn);
Для осуществления доступа к базам данных POSTGRES95 из World Wide Web можно использовать любые описанные выше механизмы - CGI, FastCGI, API, Java. Например, API-модуль сервера Apache PHP поддерживает взаимодействие с библиотеками POSTGRES95, а также разработаны два ODBC-драйвера, PostODBC и OpenLink ODBC, которые упрощают разработку программ-шлюзов. Но все же не стоит забывать и о достаточно удобном и простом средстве построения интерактивных приложений - Common Gataway Interface, который не требует никакого дополнительного программного обеспечения и достаточно легок в применении. В качестве примера использования CGI для доступа к базам данных под управлением POSTGRES95 можно привести созданную для РНЦ "Курчатовский институт" информационную систему базы численных данных о радиационном загрязнении 30-км зоны вокруг ЧАЭС "Проба" на Web-сервере Apache. Создание информационной системы было направлено на выполнение следующих задач:
Ввод новой информации в БД для ведения базы данных. Генерация отчетов по запросам пользователей.Структура взаимодействия программного обеспечения информационной системы выглядит следующим образом (рис. 5). Согласно технологии WWW, сервер протокола HTTP Apache, работающий, как правило, по 80-му порту стека протоколов TCP-IP, принимает запросы от пользователя с помощью клиентских программ просмотра гипертекстовых документов (Netscape Navigator, Internet Explorer, Lynx и др.). Формализованный доступ к данным в рамках информационной системы осуществляется на основе HTML-форм. С их помощью введенные в поля формы данные передаются на сервер Apache, который вызывает указанную в форме CGI-программу для обработки этих параметров и передает ей управление. CGI-скрипт с помощью функций прикладного интерфейса СУБД POSTGRES95 преобразует данные в SQL-запрос, устанавливает соединение с сервером СУБД и передает ему запрос на выполнение. Сервер СУБД выполняет запрос, обращаясь к БД "Проба" и возвращает результат CGI-скрипту, который, в свою очередь, формирует "на-лету" HTML-документ и через сервер Apache передает его клиенту.
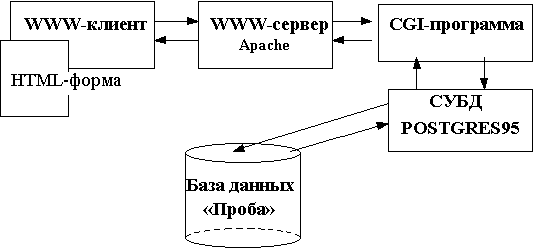
Рис. 5. Структура взаимодействия программного обеспечения информационной системы
Все навигационные HTML-страницы информационной системы сгенерированны CGI-программами, так как все HTML-формы - для введения поисковых критериев (рис.6) и ввода новых данных для обновления БД (рис.7)- содержат значения из файлов словарей, что обеспечивает более удобный интерфейс и более быстрое заполнение форм.
Для данной информационной системы недостатки CGI, связанные с порождением нового процесса не так существенны - потеря происходит лишь в незначительных затратах времени на ожидание ответа сервера. Но если необходима аутентификация каждого пользователя и его ведение во время сеанса взаимодействия с базой данных, то, на взгляд автора, FastCGI является наилучшим решением этого вопроса. То есть использование того или иного средства зависит прежде всего от поставленной задачи для реализации - что необходимо в первую очередь обеспечить при ее решении
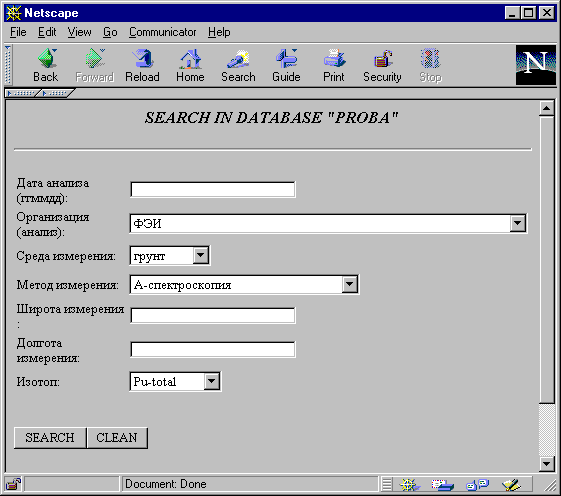
Рис. 6. Интерфейсная страница для поиска данных
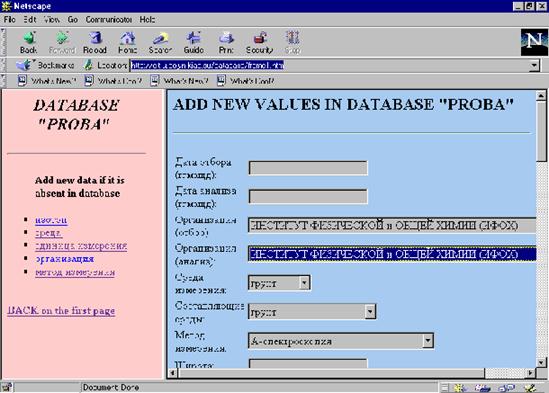
Рис. 7. HTML-страница для обновления базы данных
Таким образом, на сегодняшний день существует достаточно средств, обеспечивающих как хранение накопленных массивов информации, так и осуществляющих удобный доступ к ним через интерфейс World Wide Web. И не всегда их необходимо приобретать по коммерческим расценкам. Internet предоставляет много ресурсов бесплатно - необходимо иметь только желание и определенную настойчивость для их получения. Свободно распространяемая СУБД POSTGRES95 является тому очевидным примером. А средства доступа из WWW выбирайте сами - все они достаточно функциональны и выбор зависит в основном от целей, которые вы преследуете.
Список литературы С.Д. Кузнецов. Введение в СУБД. "СУБД" 2-3,1996г. С.Д.Кузнецов. Доступ к базам данных с использованием технологии WWW. "СУБД" 5-6, 1996 г. http://oozoo.vnet.net/postgres95/ http://www.fastcgi.com
0 комментариев