Суперкомпьютеры : прошлое, настоящее и будущее
Впервые термин "суперЭВМ" был использован в начале 60-х годов, когда группа специалистов Иллинойского университета (США) под руководством доктора Д. Слотника предложила идею реализации первой в мире параллельной вычислительной системы. Проект, получивший название SOLOMON, базировался на принципе векторной обработки, который был сформулирован еще Дж. фон Нейманом, и концепции матричной параллельной архитектуры, предложенной С. Унгером в начале 50-х годов.
Дело в том, что большинство суперкомпьютеров демонстрирует поражающую воображение производительность благодаря именно этому (векторному) виду параллелизма. Любой программист, разрабатывая программы на привычных языках высокого уровня, наверняка неоднократно сталкивался с так называемыми циклами DO. Но мало кто задумывался, какой потенциал увеличения производительности заключается в этих часто используемых операторах. Известный специалист в области систем программирования Д.Кнут показал, что циклы DO занимают менее 4% кода программ на языке FORTRAN, но требуют более половины счетного времени задачи.
Идея векторной обработки циклов такого рода заключается в том, что в систему команд компьютера вводится векторная операция, которая работает со всеми элементами векторов-операндов. При этом реализуются сразу две возможности ускорения вычислений: во-первых, сокращается число выполняемых процессором команд объектного кода, поскольку отпадает необходимость в пересчете индексов и организации условного перехода и, во-вторых, все операции сложения элементов векторов-операндов могут быть выполнены одновременно в силу параллелизма обработки.
Важно отметить еще одну особенность векторной обработки, связанную с количеством элементарных операций цикла : чем больше параллельных операций входит в векторизуемый цикл, тем ощутимее выигрыш в скорости выполнения вычислений, так как сокращается доля непроизводительных временных затрат на выборку, дешифрацию и запуск на исполнение векторной команды.
Первой суперЭВМ, использующей преимущества векторной обработки, была ILLIAC IV (SIMD архитектура). В начале 60-х годов группа все того же Слотника, объединенная в Центр передовых вычислительных технологий при Иллинойском университете, приступила к практической реализации проекта векторной суперЭВМ с матричной структурой. Изготовление машины взяла на себя фирма Burroughs Corp. Техническая сторона проекта до сих пор поражает своей масштабностью : система должна была состоять из четырех квадрантов, каждый из которых включал в себя 64 процессорных элемента (ПЭ) и 64 модуля памяти, объединенных коммутатором на базе сети типа гиперкуб. Все ПЭ квадранта обрабатывают векторную инструкцию, которую им направляет процессор команд, причем каждый выполняет одну элементарную операцию вектора, данные для которой сохраняются в связанном с этим ПЭ модуле памяти. Таким образом, один квадрант ILLIAC IV способен одновременно обработать 64 элемента вектора, а вся система из четырех квадрантов - 256 элементов. В 1972 г. первая система ILLIAC IV была установлена в исследовательском центре NASA в Эймсе. Результаты ее эксплуатации в этой организации получили неоднозначную оценку. С одной стороны, использование суперкомпьютера позволило решить ряд сложнейших задач аэродинамики, с которыми не могли справиться другие ЭВМ. Даже самая скоростная ЭВМ для научных исследований того времени - Control Data CDC 7600, которую, к слову сказать, проектировал "патриарх суперЭВМ" Сеймур Крей , могла обеспечить производительность не более 5 MFLOPS, тогда как ILLIAC IV демонстрировала среднюю производительность примерно в 20 MFLOPS. С другой стороны, ILLIAC IV так и не была доведена до полной конфигурации из 256 ПЭ; практически разработчики ограничились лишь одним квадрантом. Причинами явились не столько технические сложности в наращивании числа процессорных элементов системы, сколько проблемы, связанные с программированием обмена данными между процессорными элементами через коммутатор модулей памяти. Все попытки решить эту задачу с помощью системного программного обеспечения потерпели неудачу, в результате каждое приложение требовало ручного программирования передач коммутатора, что и породило неудовлетворительные отзывы пользователей.
Если бы разработчикам ILLIAC IV удалось преодолеть проблемы программирования матрицы процессорных элементов, то, вероятно, развитие вычислительной техники пошло бы совершенно другим путем и сегодня доминировали бы компьютеры с матричной архитектурой. Однако ни в 60-х годах, ни позднее удовлетворительное и универсальное решение двух таких принципиальных проблем, как программирование параллельной работы нескольких сотен процессоров и при этом обеспечение минимума затрат счетного времени на обмен данными между ними, так и не было найдено. Потребовалось еще примерно 15 лет усилий различных фирм по реализации суперЭВМ с матричной архитектурой, чтобы поставить окончательный диагноз: компьютеры данного типа не в состоянии удовлетворить широкий круг пользователей и имеют весьма ограниченную область применения, часто в рамках одного или нескольких видов задач.
По мере освоения средств сверхскоростной обработки данных разрыв между совершенствованием методов векторизации программ, т.е. автоматического преобразования в процессе компиляции последовательных языковых конструкций в векторную форму, и чрезвычайной сложностью программирования коммутации и распределения данных между процессорными элементами привел к достаточно жесткой реакции пользователей в отношении матричных суперЭВМ - широкому кругу программистов требовалась более простая и "прозрачная" архитектура векторной обработки с возможностью использования стандартных языков высокого уровня типа FORTRAN. Решение было найдено в конце 60-х годов, когда фирма Control Data, с которой в то время сотрудничал Крей, представила машину STAR-100, основанную на векторно-конвейерном принципе обработки данных. Отличие векторно-конвейерной технологии от архитектуры матричных ЭВМ заключается в том, что вместо множества процессорных элементов, выполняющих одну и ту же команду над разными элементами вектора, применяется единственный конвейер операций, принцип действия которого полностью соответствует классическому конвейеру автомобильных заводов Форда. Даже такая архаичная по современным понятиям суперЭВМ, как STAR-100, показала предельную производительность на уровне 50 MFLOPS. При этом существенно, что векторно-конвейерные суперЭВМ значительно дешевле своих матричных "родственников". К примеру, разработка и производство ILLIAC IV обошлись в 40 млн. долл. при расходах на эксплуатацию порядка 2 млн. долл. в год, тогда как рыночная стоимость первых суперкомпьютеров фирм CRAY и Control Data находилась в пределах 10 - 15 млн. долл., в зависимости от объема памяти, состава периферийных устройств и других особенностей конфигурации системы.
Второй существенной особенностью векторно-конвейерной архитектуры является то, что конвейер операций имеет всего один вход, по которому поступают операнды, и один выход результата, тогда как в матричных системах существует множество входов по данным в процессорные элементы и множество выходов из них. Другими словами, в компьютерах с конвейерной обработкой данные всех параллельно исполняемых операций выбираются и записываются в единую память, в связи с чем отпадает необходимость в коммутаторе процессорных элементов, ставшем камнем преткновения при проектировании матричных суперЭВМ.
Следующий удар по позициям суперЭВМ с матричной архитектурой нанесли две машины фирмы Control Data Corp. - CYBER-203 и CYBER-205. Пиковая производительность первой составила 100, а второй - уже 400 MFLOPS.
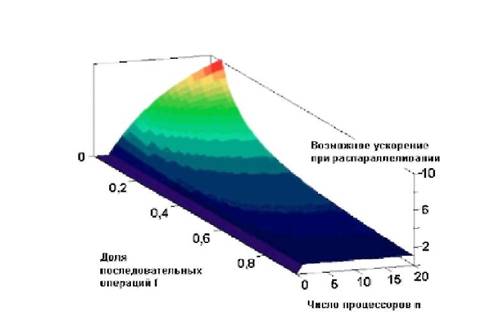
CRAY-1 совершает переворот Векторно-конвейерный суперкомпьютер STAR-100 и машины серии CYBER- 200, образно говоря, явились только "нокдауном" для матричной архитектуры. Нокаутирующий удар был нанесен в 1974 г., когда Крей, к тому времени покинувший корпорацию CDC и основавший собственную фирму Cray Research, объявил о выпуске CRAY-1 - векторно-конвейерной суперЭВМ, ставшей эпохальным событием в мире вычислительной техники. Эта малогабаритная машина (ее высота немного превосходит средний человеческий рост, а занимаемая процессором площадь чуть больше 2,5 кв.м), имела производительность 160 MFLOPS и емкость оперативной памяти 64 Мбайт. После непродолжительной пробной эксплуатации в Лос-Аламосской лаборатории, где новинка получила самые высокие отзывы программистов и математиков, Cray Research наладила серийный выпуск машин CRAY-1, которые активно раскупались в США. Любопытно, что администрация США в должной степени оценила стратегическую ценность CRAY-1 и контролировала поставки этого компьютера даже в дружественные государства. Появление CRAY-1 вызвало интерес не только у пользователей, нуждающихся в средствах сверхскоростной обработки данных, но и у специалистов по архитектуре суперкомпьютеров. Для многих неожиданным (а для разработчиков CYBER-205 даже неприятным) стал тот факт, что с большинством задач маленький компьютер CRAY-1 справлялся быстрее, чем значительно превосходящий его по габаритам и пиковой производительности CYBER-205. Так, при тестировании на пакете решения линейных уравнений LINPACK Джек Донгарра из Национальной лаборатории в Аргонне оценил производительность CRAY-1S в пределах 12 - 23 MFLOPS в зависимости от способа программирования, тогда как CYBER-205 показал производительность лишь 8,4 MFLOPS. Объяснение нашлось, как только вспомнили о законе Амдала (G.Amdahl), который известный архитектор системы IBM/360 сформулировал в 1967 г. в виде следующего постулата: "Производительность вычислительной системы определяется самым медленным ее компонентом". Применительно к векторным суперЭВМ парадокс Амдала преломляется следующим образом. Любая задача, выполняемая в суперЭВМ, состоит из двух взаимосвязанных частей - векторных команд, сгенерированных компилятором при векторизации исходной программы, и скалярных операций, которые компилятор не сумел перевести в векторную форму. Если представить себе суперкомпьютер, который умеет одинаково быстро производить скалярные и векторные операции, то парадокс Амдала "не срабатывает" и такая система с равной скоростью будет выполнять задачи любой степени векторизации. Но само собой, что скалярная обработка занимает больше времени, плюс ко всему CRAY-1 при цикле 12,5 нс обладает большим быстродействием скалярной обработки по сравнению с компьютером CYBER-205, у которого цикл равен 20 нс.
Существует еще одна причина, по которой CRAY-1 превосходит CYBER-205 по скорости решения большинства прикладных задач. Впервые в практике сверхскоростной обработки данных, а возможно, и вообще в вычислительной технике CRAY-1 был разработан как компьютер с полностью законченной архитектурой "регистр-регистр". Все операции обработки данных, которые выполняет центральный процессор этой машины, выбирают операнды и записывают результаты вычислений, используя не оперативную память, как это было сделано в CYBER-205 и более ранних суперкомпьютерах, а специально предназначенные для этой цели программно-адресуемые регистры. Для реализации этой архитектуры в CRAY-1 было введено принципиальное новшество - векторные регистры, которые адресовались командами центрального процессора подобно обычным регистрам данных, но могли запомнить до 64 элементов вектора каждый при 64- разрядном формате отдельных элементов. Естественно, что по сравнению с CYBER-205 каждая отдельная векторная команда в CRAY-1 выполнялась быстрее, поскольку операции типа "регистр-регистр" отличаются от операций типа "память-память" меньшими временными затратами на чтение операндов и запись результата. Однако решающие преимущества CRAY-1 перед суперЭВМ CDC и матричными суперкомпьютерами определяются не столько лучшей сбалансированностью показателей производительности, сколько простотой и удобством эксплуатации, а также высоким качеством системного программного обеспечения. При разработке своей первой суперЭВМ Крей принял во внимание то важное обстоятельство, что большинство существующих пакетов прикладных программ написано на языках последовательного типа, чаще всего на языке FORTRAN. Поэтому в состав программного обеспечения CRAY-1 был включен интеллектуальный FORTRAN-компилятор CFT, способный обнаруживать параллелизм в программах последовательного действия и преобразовывать их в векторизованный код. Естественно, что при таком подходе все имеющееся у пользователя программное обеспечение с незначительными доработками может быть перенесено на суперЭВМ.
Кроме векторизации циклических конструкций, в компиляторе CFT суперкомпьютера CRAY-1 было введено еще одно принципиальное новшество - автоматический поиск в исходной программе и построение многоконвейерных цепочек. Суть его заключается в следующем: если в программе встречаются две связанные векторные операции (т.е. результат первой служит операндом второй), то в отличие от случая связанных скалярных операций, когда выполнение второй операции начинается только после завершения предыдущей, обе векторные команды могут обрабатываться практически параллельно, что удваивает производительность системы.
В целом CRAY-1 продемонстрировал то, как надо сочетать простоту и эффективность технических решений в области аппаратного и программного обеспечения суперкомпьютера с простотой и удобством его использования и, в первую очередь программирования в привычной для большинства разработчиков среде "классических" последовательных языков типа FORTRAN.
Спустя некоторое время, специалисты из Fujitsu, Hitachi и Nippon Electric (NEC) в короткие сроки сумели выдать настоящий ответ Крею из шести моделей суперЭВМ, мало уступающих CRAY-1 по основным характеристикам, а кое в чем и превосходящих свой американский прототип.
Дело в том, что в начале 70-х годов Япония включилась в гонку суперкомпьютеров, объявив о начале государственной программы создания ЭВМ сверхвысокой производительности. В качестве основных исполнителей этой программы были выбраны три ведущие компьютерные фирмы Японии. Корпорация NEC образовала совместное предприятие с Honeywell под названием Honeywell-NEC Supercomputers (HNS), а фирма Fujitsu сумела заключить соглашение с Джином Амдалом, который к тому времени ушел из IBM и основал собственную компанию Amdahl Corp. Плодом этого союза стала машина AMDAHL V/6, открывшая эру компьютеров на больших интегральных схемах и заставившая всерьез поволноваться руководство IBM, когда выяснилось, что эксплуатационные характеристики AMDAHL V/6 не оставляют серьезных шансов на победу ни одному из компьютеров IBM того времени. Обладая технологией и опытом разработки ЭВМ на БИС, которых американцы в ту пору не имели, так как CYBER-200 и CRAY-1 были разработаны на микросхемах средней степени интеграции, японские фирмы пошли в наступление на фронте суперкомпьютеров.
В начале 80-х годов свет увидели сразу три семейства суперЭВМ японского производства, причем каждый суперкомпьютер из Страны Восходящего Солнца имел свою архитектурную изюминку. Во-первых, во всех японских суперЭВМ по сравнению с CRAY-1 было увеличено число скалярных и векторных регистров (например, NEC SX располагает 256 скалярными и 256 векторными регистрами против восьми регистров обоих типов в CRAY-1). За счет этого удалось снизить нагрузку на оперативную память системы, а также, что значительно существеннее, получить большие возможности для эффективной векторизации программ. Еще одно интересное новшество ввели разработчики суперЭВМ семейства NEC SX, объединив векторную архитектуру "регистр-регистр" с принципом многоконвейерной обработки, ранее реализованном в суперкомпьютерах STAR-100, CYBER-203 и CYBER-205 фирмы Control Data.
Правда, здесь следует отметить следующее : во-первых, многоконвейерная обработка требует установки дополнительных модулей, что увеличивает стоимость центрального процессора, во-вторых, исполнение одной векторной команды на нескольких параллельных конвейерах приводит к возрастанию доли непроизводительных временных затрат на запуск команды, подготовку операндов и запись результата. Например, если конвейер, выполняющий одну элементарную операцию за пять тактов, заменить на четыре таких же конвейера, то при длине векторов в 100 элементов векторная команда ускоряется всего в 3,69, а не в 4 раза. Эффект "отставания" роста производительности от увеличения числа конвейеров особенно заметен, когда процессор затрачивает значительное время на обмен данными между конвейером и памятью. Это обстоятельство не было должным образом оценено при разработке CYBER-205, и в результате архитектура "память-память" данной модели настолько ухудшила динамические параметры четырех конвейеров ее векторного процессора, что для достижения производительности, близкой к 200 MFLOPS, потребовалась очень высокая степень векторизации программ (порядка 1 тыс. элементов в векторе), т.е. потенциально самая мощная суперЭВМ 70-х годов реально могла эффективно обрабатывать только ограниченный класс задач. Конечно, подобный просчет негативно отразился на рыночной судьбе CYBER-205 и на всей программе суперЭВМ компании Control Data. После CYBER-205 фирма CDC прекратила попытки освоения рынка суперЭВМ.
Использование в суперкомпьютерах NEC SX архитектуры "регистр-регистр" позволило нейтрализовать недостатки многоконвейерной обработки, и модель NEC SX-2 с 16 векторными конвейерами стала первой суперЭВМ, преодолевшей рубеж в миллиард операций с плавающей точкой за секунду - ее пиковая производительность составила 1,3 GFLOPS. Фирма Hitachi пошла по другому пути. В суперкомпьютерах серии S-810 ставка была сделана на параллельное выполнение сразу шести векторных команд. Далее Hitachi, продолжает линию этого семейства моделями S-810/60 и S-810/80; последняя занимает достойное третье место по результатам тестирования производительности на пакете LINPACK, уступая только грандам из CRAY и NEC. Относительную коммерческую стабильность суперкомпьютеров Hitachi можно объяснить тем, что они, как и суперЭВМ фирмы Fujitsu, полностью совместимы с системой IBM/370 по скалярным операциям. Это позволяет применять программы, созданные на IBM VS FORTRAN и в стандарте ANSI X3.9 (FORTRAN 77), а также использовать стандартную операционную среду MVS TSO/SPF и большинство системных расширений IBM, включая управление вводом/выводом для IBM-совместимых дисковых и ленточных накопителей. Другими словами, японские суперЭВМ фирм Hitachi и Fujitsu первыми в мире суперкомпьютеров использовали дружественный интерфейс для пользователей наиболее распространенной в то время вычислительной системы - IBM/370.
Натиск японских производителей был впечатляющим, но тут С. Крей наносит своевременный контрудар - в 1982 г. на рынке появилась первая модель семейства суперкомпьютеров CRAY X-MP, а двумя годами позже в Ливерморской национальной физической лаборатории им. Лоуренса был установлен первый экземпляр суперЭВМ CRAY-2. Машины от Cray Research опередили конкурентов в главном - они ознаменовали зарождение нового поколения ЭВМ сверхвысокой производительности, в которых векторно-конвейерный параллелизм дополнялся мультипроцессорной обработкой. Крей применил в своих компьютерах неординарные решения проблемы увеличения производительности. Сохранив в CRAY-2 и CRAY X-MP архитектуру и структурные наработки CRAY- 1, он сокрушил конкурентов сразу на двух фронтах: достиг рекордно малой длительности машинного цикла (4,1 нс ) и расширил параллелизм системы за счет мультипроцессорной обработки. В итоге Cray Research сохранила за собой звание абсолютного чемпиона по производительности: CRAY-2 продемонстрировала пиковую производительность 2 GFLOPS, обогнав NEC SX-2 - самую быструю японскую суперЭВМ - в полтора раза. Для решения проблемы оптимизации машинного цикла Крей пошел дальше японцев, которые уже владели технологией ECL-БИС, позволившей в Fujitsu VP достичь длительности машинного цикла в 7,5 нс. Помимо того что в CRAY-2 были использованы быстродействующие ECL-схемы, конструктивное решение блоков ЦП обеспечивало максимальную плотность монтажа компонентов. Для охлаждения такой уникальной системы, которая выделяла ни много ни мало 195 кВт, была использована технология погружения модулей в карбид фтора - специальный жидкий хладагент производства американской фирмы 3M.
Второе революционное решение, реализованное в суперкомпьютере CRAY- 2, заключалось в том, что объем оперативной памяти был доведен до 2 Гбайт. С.Крею удалось выполнить критерий балансировки производительности и емкости оперативной памяти по Флинну: "Каждому миллиону операций производительности процессора должно соответствовать не менее 1 Мбайт емкости оперативной памяти". Суть проблемы заключается в том, что типичные задачи гидро- и аэродинамики, ядерной физики, геологии, метеорологии и других дисциплин, решаемые с помощью суперЭВМ, требуют обработки значительного объема данных для получения результатов приемлемой точности. Eстественно, при таких объемах вычислений относительно малая емкость оперативной памяти вызывает интенсивный обмен с дисковой памятью, что в полном соответствии с законом Амдала ведет к резкому снижению производительность системы.
Все-таки новый качественный уровень суперкомпьютера CRAY-2 определялся не столько сверхмалой длительностью машинного цикла и сверхбольшой емкостью оперативной памяти, сколько мультипроцессорной архитектурой, заимствованной у другой разработки Cray Research - семейства многопроцессорных суперЭВМ CRAY X-MP. Его три базовые модели - X-MP/1, X-MP/2 и X-MP/4 - предлагали пользователям одно-, двух- или четырехпроцессорную конфигурацию системы с производительностью 410 MFLOPS на процессор. Спектр доступных вариантов расширялся за счет возможности установки памяти разного объема (от 32 до 128 Мбайт на систему). Такой ориентированный на рынок подход к построению суперкомпьютера впоследствии принес фирме Cray Research ощутимый коммерческий эффект. Мультипроцессорная архитектура суперкомпьютеров производства CRAY была разработана с учетом достижений и недостатков многопроцессорных мэйнфреймов, в первую очередь фирмы IBM. В отличие от "классических" операционных систем IBM, которые используют для взаимодействия процессов механизм глобальных переменных и семафоров в общей памяти, мультипроцессорная архитектура CRAY предполагает обмен данными между процессорами через специальные кластерные регистры, кроме того, для обслуживания взаимодействия процессов в архитектуре CRAY предусмотрены аппаратно-реализованные семафорные флажки, которые устанавливаются, сбрасываются и анализируются с помощью специальных команд, что также ускоряет межпроцессорный обмен и в итоге увеличивает системную производительность. В результате этих новшеств коэффициент ускорения двухпроцессорной суперЭВМ CRAY X-MP/2 по отношению к однопроцессорной CRAY X-MP/1 составляет не менее 1,86.
В отличие от семейства CRAY X-MP, модели которого работают под управлением операционной системы COS (Cray Operating System), CRAY-2 комплектовалась новой операционной системой CX-COS, созданной фирмой Cray Research на базе Unix System V.
Во второй половине 80-х годов Control Data, "сошедшая с дистанции" после неудачи с моделью CYBER-205 вновь появляется на рынке сперЭВМ. Строго говоря, за разработку новой восьмипроцессорной суперЭВМ взялась ETA Systems - дочерняя фирма CDC, - однако в этом проекте был задействован практически весь потенциал Control Data. Вначале проект под названием ETA-10, получивший поддержку правительства через контракты и дотации потенциальным пользователям вызвал оживление среди специалистов по сверхскоростной обработке. Ведь новая суперЭВМ должна была достичь производительности в 10 GFLOPS, т.е. в пять раз превзойти CRAY-2 по скорости вычислений. Первый образец ETA-10 с одним процессором производительностью 750 MFLOPS был продемонстрирован в 1988 г., однако дальше дела пошли хуже. Во втором квартале 1989 г. Control Data объявила о свертывании деятельности компании ETA Systems из-за нерентабельности производства.
Не остался в стороне от проблем сверхвысокой производительности и гигант компьютерного мира - фирма IBM. Не желая уступать своих пользователей конкурентам из Cray Research, компания приступила к программе выпуска старших моделей семейства IBM 3090 со средствами векторной обработки (Vector Facility). Самая мощная модель этой серии - IBM 3090/VF-600S оснащена шестью векторными процессорами и оперативной памятью емкостью 512 Мбайт. В дальнейшем эта линия была продолжена такими машинами архитектуры ESA, как IBM ES/9000-700 VF и ES/9000-900 VF, производительность которых в максимальной конфигурации достигла 450 MFLOPS.
Еще одна известная в компьютерном мире фирма - Digital Equipment Corp. - в октябре 1989 г. анонсировала новую серию мэйнфреймов с векторными средствами обработки. Старшая модель VAX 9000/440 оснащена четырьмя векторными процессорами, повышающими производительность ЭВМ до 500 MFLOPS.
Высокая стоимость суперЭВМ и векторных мэйнфреймов оказалась не по карману достаточно широкому кругу заказчиков, потенциально готовых воспользоваться компьютерными технологиями параллельных вычислений. К их числу относятся мелкие и средние научные центры и университеты, а также производственные компании, которые нуждаются в высокопроизводительной, но сравнительно недорогой вычислительной технике.
С другой стороны, такие крупнейшие производители суперЭВМ, как Cray Research, Fujitsu, Hitachi и NEC, явно недооценили потребности "средних" пользователей, сосредоточившись на достижении рекордных показателей производительности и, к сожалению, еще более рекордной стоимости своих изделий. Весьма гибкой оказалась стратегия Control Data, которая после неудачи с CYBER-205 основное внимание уделила выпуску научных компьютеров среднего класса. На конец 1988 г. производство машин типа CYBER-932 вдвое превысило выпуск старших моделей серии CYBER-900 и суперЭВМ с маркой CDC. Основным конкурентом Control Data на рынке малогабаритных параллельных компьютеров, которые получили общее название "мини-суперЭВМ", стала будущий лидер в мире мини-суперкомпьютеров фирма Convex Computer. В своих разработках Convex первой реализовала векторную архитектуру с помощью сверхбольших интегральных схем (СБИС) по технологии КМОП. В результате пользователи получили серию относительно недорогих компьютеров по цене менее 1 млн. долл., обладающих производительностью от 20 до 80 MFLOPS. Спрос на эти машины превзошел все ожидания. Явно рискованные инвестиции в программу Convex обернулись быстрым и солидным доходом от ее реализации. История развития суперкомпьютеров однозначно показывает, что в этой сложнейшей области инвестирование высоких технологий, как правило, дает положительный результат - надо только, чтобы проект был адресован достаточно широкому кругу пользователей и не содержал слишком рискованных технических решений. Convex, которая, получив такое преимущество на старте, стала успешно развиваться. Сначала она выпустила на рынок семейство Convex C-3200, старшая модель которого C-3240 имеет производительность 200 MFLOPS, а затем - семейство Convex C-3800, состоящее из четырех базовых моделей в одно-, двух- , четырех- и восьмипроцессорной конфигурации. Самая мощная машина этой серии Convex C-3880 имеет производительность, достойную "настоящей" суперЭВМ 80-х годов, и при тестировании на пакете LINPACK обогнала по скорости вычислений такие системы, как IBM ES/9000-900 VF, ETA-10P и даже CRAY-1S. Отметим, что Cray Research, выпускает мини-суперЭВМ CRAY Y-EL, также реализованную на технологии КМОП-СБИС. Этот компьютер может поставляться в одно-, двух- или четырехпроцессорной конфигурации и обеспечивает производительность 133 MFLOPS на процессор. Объем оперативной памяти изменяется в зависимости от пожеланий заказчика в диапазоне 256-1024 Мбайт.
Доминирование векторных суперкомпьютеров в государственных программах и устойчивое положение "царя горы", занятое Cray Research, явно не устраивало сторонников MIMD-параллелизма. Первоначально в этот класс были включены многопроцессорные мэйнфреймы, а впоследствии к ним добавились суперЭВМ третьего поколения с мультипроцессорной структурой. И те и другие основаны на сформулированном фон Нейманом принципе управления вычислительным процессом по командам программы, или управления потоком команд (Instruction Flow). Однако примерно с середины 60-х годов математики стали обсуждать проблему разбиения задачи на большое число параллельных процессов, каждый из которых может обрабатываться независимо от других, а управление выполнением всей задачи осуществляется путем передачи данных от одного процесса к другому. Этот принцип, известный как управление потоком данных (Data Flow), в теории выглядит очень многообещающим. Теоретики DataFlow-параллелизма предполагали, что систему можно будет организовать из небольших и потому дешевых однотипных процессоров. Достижение сверхвысокой производительности целиком возлагалось на компилятор, осуществляющий распараллеливание вычислительного процесса, и ОС, координирующую функционирование процессоров. Внешняя простота принципа MIMD-параллелизма вызвала к жизни множество проектов.
Из наиболее известных разработок систем класса MIMD стоит упомянуть IBM RP3 (512 процессоров, 800 MFLOPS), Cedar (256 процессоров, 3,2 GFLOPS; компьютер одноименной фирмы), nCUBE/10 (1024 процессора, 500 MFLOPS) и FPS-T (4096 процессоров, 65 GFLOPS). К сожалению, ни один из этих проектов не завершился полным успехом и ни одна из упомянутых систем не показала объявленной производительности. Дело в том, что, как и в случае с матричными SIMD-суперкомпьютерами, слишком много технических и программных проблем было связано с организацией коммутатора, обеспечивающего обмен данными между процессорами. Кроме того, процессоры, составляющие MIMD- систему, оказались на практике не столь уж маленькими и дешевыми. Как следствие, наращивание их числа приводило к такому увеличению габаритов системы и удлинению межпроцессорных связей, что стало совершенно очевидно: при существовавшем в конце 80-х годов уровне элементной базы реализация MIMD-архитектуры не может привести к появлению систем, способных конкурировать с векторными суперкомпьютерами.
Неординарное решение проблемы коммутационной сети процессоров MIMD- системы предложила мало кому известная фирма Denelcor, которая выполнила разработку многопроцессорной модели HEP-1. Этот суперкомпьютер был задуман как MIMD-система, содержащая от 1 до 16 исполнительных процессорных элементов и до 128 банков памяти данных по 8 Мбайт каждый. Система из 16 процессоров должна была обладать максимальной производительностью 160 MFLOPS при параллельной обработке 1024 процессов (по 64 процесса в каждом из 16 ПЭ). Любопытной архитектурной особенностью HEP-1 было то, что MIMD-обработка множества процессов выполнялась без использования коммутационной сети, которую заменила так называемая "вертушка Флинна".
Напомним, что идея "вертушки Флинна" заключается в организации мультипроцессора как нелинейной системы, состоящей из группы процессоров команд (ПрК), каждый из которых "ведет" свой поток команд, и общего для всех ПрК набора арифметических устройств, циклически подключаемых к каждому из ПрК для выполнения их команд. Нетрудно заметить, что эффект "вертушки Флинна" состоит в сокращении объема, занимаемого арифметическими устройствами в многопроцессорной системе, поскольку на "арифметику" может приходиться до 60% аппаратных ресурсов центрального процессора.
На первый взгляд структура HEP-1 практически не отличается от классической "вертушки Флинна" - такой же циклический запуск команд, принадлежащих разным процессам, и те же общие для множества процессов арифметические устройства. Однако на входе исполнительных устройств переключаются не процессоры команд, а процессы с помощью специального механизма выборки, сохранения и восстановления слов состояния каждого исполняемого процесса. Во-вторых, в HEP-1 применяются конвейерные исполнительные устройства, что позволяет арифметическим устройствам обрабатывать существенно больше операций, чем прототипам мэйнфреймов. Казалось бы, наконец найдено решение, объединяющее достоинства MIMD- архитектуры и конвейерной обработки данных (отсюда название "MIMD-конвейеризация") и к тому же исключающее основной недостаток MIMD-структуры - наличие сетевого коммутатора процессоров. Однако после довольно успешных тестов суперЭВМ HEP-1 и одобрительных отзывов аналитиков запущенный в производство проект следующей подобной машины HEP-2 был закрыт по причине отсутствия заказов. Подобно множеству других проектов создания суперкомпьютеров с MIMD- архитектурой, программа HEP не получила одобрения пользователей из-за недостатков системного ПО. Дело в том, что в отличие от векторных суперкомпьютеров, которые успешно справляются с задачами, представленными на стандартных языках последовательного типа, для эффективного программирования MIMD-систем потребовалось введение в обиход совершенно новых языков параллельного программирования.
Если проектировщикам суперкомпьютеров класса MIMD удастся разрешить проблемы системного ПО, доступных языков параллельного программирования, а также компиляторов для этих языков, то в развитии вычислительной техники надо ожидать весьма крутого и драматического поворота событий.
После коммерческого успеха моделей CRAY X-MP фирма Cray Research выпустила модифицированное семейство суперкомпьютеров CRAY Y-MP, обладающих большим числом процессоров (до восьми) и пониженной длительностью машинного цикла (6 нс). Старшая модель этого семейства CRAY Y-MP/832 имела пиковую производительность 2666 MFLOPS и занимала двенадцатую позицию в рейтинге Дж. Донгарра по результатам тестирования на пакете LINPACK.
Первые же пять позиций принадлежали представителям CRA Y-MP C90, старшая модель которого - 16-процессорная машина CRAY Y-MP C90/16256 - имела оперативную память емкостью 2 Гбайт и могла демонстрировать производительность на уровне 16 GFLOPS. Все 16 процессоров и оперативная память этого компьютера размещались в одной стойке весьма скромных размеров: 2,95x2,57x2,17 м3. Подсистема ввода/вывода CRAY Y-MP C90 имела до 256 каналов с общей пропускной способностью 13,6 Гбайт/с, встроенный кремниевый диск емкостью 16 Гбайт и поддерживала дисковую память общей емкостью до 4 Тбайт. "Суперпараметры" модели CRAY Y-MP C90 эффектно дополняются развитым программным обеспечением, центральным ядром которого являются компиляторы CF77 Fortran, Cray Standard C Compiler, Cray ADA и Pascal.
Примерно в это время Сеймур Крей оставляет основанную им фирму Cray Research и создает новую компанию Cray Computer в целях разработки суперкомпьютеров нового поколения CRAY-3 и CRAY- 4. Причинами этого шага стали два обстоятельства: во-первых, руководство Cray Research не хотело подвергать фирму финансовому и моральному риску в случае неудачи новых проектов, а во-вторых, сам Крей предпочел заниматься пионерскими разработками, оставив для Cray Research задачу закрепления рыночного успеха уже созданных продуктов. В результате, освободившись от бремени проектирования CRAY-3 и CRAY-4, его прежнее детище сосредоточилось на "шлифовке" аппаратного и программного обеспечения семейства CRAY Y-MP, а новое занялось поиском технических решений, позволяющих кардинально повысить производительность векторно-конвейерной обработки. Дело в том, что в конце 80-х годов Крей сумел предугадать ситуацию, которая сложилась в области векторных суперкомпьютеров к середине 90-х: архитектурные и программные возможности увеличения производительности за счет многопроцессорной обработки и совершенствования операционных систем и компиляторов для суперЭВМ этого класса оказались практически исчерпаны, а их традиционная элементная база - ECL и BiCMOS БИС со степенью интеграции порядка 10 тыс. вентилей на кристалл - не позволяет преодолеть порог длительности машинного цикла в 2-3 нс. В основу проекта CRAY-3 была заложена идея перехода на принципиально новую элементную базу - БИС на основе арсенида галлия, которая теоретически позволяет обеспечить субнаносекундную продолжительность машинного цикла. Затея казалась весьма рискованной, тем более что в конце 80-х годов в мире не существовало промышленно освоенной технологии для производства подобной элементной базы. Во всяком случае проект CRAY-3 "затормозился" именно из-за неудовлетворительного состояния технологии разработки и производства GaAs-микросхем, а также сборки из них отдельных модулей. Тем не менее после примерно пяти лет работы над проектом CRAY-3 "вышел в свет" и сразу оказался в тройке рекордсменов производительности, обогнав все конкурирующие суперкомпьютеры по тактовой частоте.
Примерно в середине 90-х годов сумашедший темп развития суперкомпьютеров был потерян. В качестве основных причин следует привести следующие : огромный спад государственной поддержки программы развития суперЭВМ, как результат прекращения ‘холодной войны’, плюс отсутствия рынка сбыта супермашин, что объясняется наличием вполне подходящих мини-суперЭВМ гораздо более дешевых и доступных. Большинство производителей стараются переориентироваться на создании архитектур с массовым параллелизмом (MPP).
1994г. Компания Cray Computer сообщила о выпуске в первой половине следующего года суперкомпьютера Cray-4 в четырех- и восьмипроцессорных конфигурациях. Фирма NEC представила на американском рынке свой суперкомпьютер SX-4, поставки которого начнутся в 1995 г. Выпуск массово-параллельного компьютера NCube 3, продемонстрированного компанией NCube и ориентированного на научный рынок, намечен на II квартал будущего года.
1995г. Пожалуй, самым впечатляющим событием стал крах фирмы Cray Computer. Эти новости мало для кого оказались сюрпризом: не составляло тайны существование многочисленных долгов, накопившихся в результате того, что Cray Computer не смогла продать ни одного компьютера Cray-3 за два года, прошедших со дня представления системы.
Примерно в это же время Cray Research объявила о выпуске новой серии суперкомпьютеров CRAY T90, в которых впервые отсутствуют кабельные соединения. В этих системах, получивших на стадии разработки название Triton, количество процессоров варьировалось от 1 до 32, а максимальная производительность достигала 60 млрд. операций в секунду. По сравнению с 16-процессорными компьютерами CRAY C90, быстродействие которых достигает 16 Гфлопс, новые машины имеют в 3-5 раз лучшее соотношение производительность/стоимость.
В Японии же, Fujitsu представляет два векторных параллельных суперкомпьютера на базе КМОП-технологии : VX и VPP оснащены запатентованными БИС на КМОП-структурах, объемом памяти 8 Гбайт для модели VX и 32 Гбайт - для VPP300. При максимальной конфигурации (16 процессоров) производительность VPP300 составляет 35,2 Гфлопс, а модели VX при четырех процессорах - 8,8 Гфлопс.
Компания Parsytec Computer GmbH продемонстрировала первую систему с массовым параллелизмом GC/Power Plus на базе RISC- процессоров PowerPC 601. Количество процессорных элементов в GC/Power Plus может меняться от 32 до 1024, при этом производительность составляет от 2,5 до 80 GFLOPS
В 1996 г. Cray начинает коммерческий выпуск новой модели масштабируемых суперкомпьютеров CRAY T3E с пиковой производительностью 1,2 TFLOPS. Основная характеристика, на которой акцентировали внимание разработчики, - масштабируемость, не имеющая аналогов в истории суперкомпьютеров. Минимальная конфигурация, содержащая восемь микропроцессоров, допускает увеличение их количества в 256 раз. Увеличение производительности может быть также достигнуто кластеризацией систем.
Тем не менее, проектирование MIMD машин по-прежнему в большей степени являлось искусством, правда следует отметить явное движение в это области. Так, MIMD-суперкомпьютеру Paragon с распределенной памятью, разработанному Intel, удалось выжить и вполне успешно существовать (построен на коммерческих микропроцессорах от Intel ) : с быстродействием 140 Гфлопс установлен в лаборатории Sandia и 150 Гфлопс установлен в Oak Ridge National Lab. Еще одним примером может служить система HP Exemplar SPP1600, которая была построена на микропроцессорах RISC PA-7200 и основана на архитектурном принципе MIMD с разделением памяти.
Fujitsu выпусакет семейство суперкомпьютеров VPP700 Series. Их конфигурация может наращиваться от базовой, включающей 8 процессорных блоков, до 256- процессорной с совокупной производительностью в 500 Гфлопс. IBM продолжает развивать свое семейство RS/6000 Scalable Powerparallel (SP). Она строит свой самый мощный параллельный компьютер с 472 процессорами и максимальной производительностью в 200 Гфлопс (превоначально планировалось, что в восьми корпусах разместятся 512 узлов, а общее число процессоров достигнет 4096).
Спустя год, опять анонсировала суперкомпьютер CRAY Т3Е-900 на более быстрых процессорах, чем у предшествующей модели CRAY Т3Е. За счет этого достигнута рекордная производительность 1,8 TFLOPS. Тогда это единственная в мире система, мощность которой превысила триллион FLOPS. Новый суперкомпьютер представляет собой не кластер множества независимых узлов, а единую систему с централизованным управлением и сильносвязанными процессорными элементами. Максимальное число процессоров CRAY T3E-900 достигает 2048.
1997г. может быть отмечен, как появлением корпорации Sun Microsystems на рынке суперкомпьютеров. Предпосылкой для этого служит выпуск нового семейства Ultra-Sparc III, на базе которого Sun планирует выпустить системы. При этом следует отметить, что Sun отдала предпочтение SMP (симметричной многопроцессорной) архитектуре : так, cуперкомпьютер UltraHPC может быть сконфигурирован на базе 64 процессоров Ultrasparc II (250 Mhz) и способен обеспечивать производительность до 32 Gflops; в то время, как большинство производителей суперЭВМ ‘исповедуют’ NUMA (архитектура с неоднородным доступом к памяти).
А как обстоят дела со всем этим в России ? Нет большого секрета и в том, что сегодня компьютерная индустрия России находится в коматозном состоянии.. К середине 80-х годов в СССР существовала достаточно стройная государственная программа по суперкомпьютерам, которая, помимо финансирования довольно широкого спектра проектов, включала действия по модернизации производства элементной базы и оснащению заводов необходимым технологическим оборудованием. В случае успеха этой программы в 1989 - 1991 гг. на свет должен был появиться целый ряд вполне современных суперкомпьютеров с производительностью от 100 MFLOPS до 1,2 GFLOPS. Кроме того, советская суперкомпьютерная программа предполагала значительное продвижение в области MIMD-систем. Строго говоря, к этому времени СССР уже обладал компьютерами "Эльбрус-2", параметры которых вполне соответствовали определению "суперЭВМ". Фаворитом суперкомпьютерной программы стал коллектив разработчиков этой машины - Институт точной механики и вычислительной техники им. Лебедева АН СССР (ИТМиВТ), известный такими запоминающимися проектами, как "БЭСМ", "Чегет" и "Эльбрус- 1". Именно в этом институте были заложены два (из четырех) основных проекта государственной программы - "Эльбрус-3" и "Модульный конвейерный процессор" (МКП). Одно направление возглавил проект "Эльбрус-3", основанный на совершенно новой архитектуре широкой команды (Very Long Instruction Word, VLIW). Архитектура этого типа интересна тем, что центральный процессор выбирает из памяти и запускает на исполнение сразу несколько операций, упакованных компилятором в одно командное слово. Пиковая производительность полной конфигурации системы (16 процессоров) ожидалась на уровне 10 GFLOPS, что было бы совсем неплохо. Второе направление развития советских суперЭВМ предполагало достижение более скромных показателей производительности (около 1 GFLOPS на процессор) за счет применения проверенного практикой принципа векторно-конвейерной обработки, но без копирования зарубежных суперкомпьютеров. В ИТМиВТ параллельно с VLIW-системой "Эльбрус-3" стартовал проект МКП под официальным названием "Эльбрус-3Б", который предполагалось завершить созданием системы из 2-20 процессоров, обладающей суммарной пиковой производительностью 2-10 GFLOPS. Направление разработки векторно-конвейерных суперЭВМ оригинальной структуры было выбрано и для суперкомпьютеров Единой системы. Головной институт программы "ЕС ЭВМ" - Научно- исследовательский центр электронной вычислительной техники (НИЦЭВТ) - в 1986 г. анонсировал начало проекта по созданию суперкомпьютера ЕС1191 с производительностью 1,2 GFLOPS. Хотя эта машина по своим характеристикам и уступала "Эльбрусам", но потенциально ее конструктивные особенности могли оказаться весьма привлекательными для пользователей. Во-первых, оригинальное решение системы из четырех скалярных процессоров и одного общего векторного процессора позволило значительно уменьшить занимаемый объем: вся центральная часть машины размещалась в стойке, примерно равной по габаритам распространенному мэйнфрейму ЕС1066. Во-вторых, ЕС1191 реализовывала дружественный интерфейс пользователя ЕС ЭВМ (берущий начало от ОС фирмы IBM) с применением всего разнообразия системных и прикладных програмных продуктов. И наконец, "козырной картой" ЕС1191 была воздушная система охлаждения, которая резко снижала затраты на производство и эксплуатацию машины по сравнению с жидкостным охлаждением "Эльбрусов".
Если в разработке суперкомпьютера ЕС1191 инженеры НИЦЭВТ отошли от практики повторения зарубежных прототипов, то в полном соответствии с принципом "свято место пусто не бывает" идея быстрого достижения результата за счет повторения уже пройденного пути не могла не найти своих сторонников. Коллектив специалистов под руководством академика В. А. Мельникова принялся за разработку суперЭВМ "Электроника СС БИС", которая базировалась на структурных решениях и системе команд машин CRAY. В принципе, это направление хотя и предполагает постоянное отставание от прототипа (кто-кто, а российские пользователи хорошо ощутили разрыв между машинами ЕС ЭВМ и компьютерами IBM современного уровня), но практически "обречено на успех", особенно при детальном копировании оригинала. Во всяком случае Китай получил очень неплохие суперкомпьютеры VH-1 и VH-2 за счет копирования машин CRAY-1 и CRAY X-MP.
Все суперкомпьютерные проекты советского периода использовали однотипную элементную базу - матричные большие интегральные схемы по технологии ECL (эмиттерно-связанная логика) со степенью интеграции 1500 вентилей на кристалл и быстродействием порядка 0,5 нс на вентиль. Конечно, по сравнению с современными достижениями микроэлектронной технологии эти параметры, мягко говоря, не впечатляют, но для середины 80-х годов они были "вполне на уровне" и не отставали от элементной базы японских суперкомпьютеров Fujitsu, NEC или Hitachi.
К сожалению, именно на все это наложились известные события 1991 - 1992 гг., и вместо самой внушительной порции выделенных средств суперкомпьютерные проекты получили анархию в договорных отношениях между институтами и заводами. В результате "Эльбрус-3Б" и "Электроника СС БИС" сегодня существуют в виде опытных образцов, завершение проекта "Эльбрус-3" сильно затянулось, а работы над ЕС1191 заморожены.
Правда говорить о кончине российских суперкомпьютеров пока, по- видимому, преждевременно. Дело гораздо сложнее и значительно драматичнее, чем может показаться. Во-первых, еще существуют два ведущих компьютерных центра России - ИТМиВТ и НИЦЭВТ, которые в принципе способны справиться с задачей создания суперЭВМ, плюс в обоих институтах пока сохранилось небольшое, но вполне дееспособное ядро наиболее квалифицированных специалистов. Когда в 1991 г. стало ясно, что проект ЕС1191 не удастся завершить из-за нехватки средств на изготовление опытных образцов суперкомпьютера, было принято решение о замораживании проекта и развертывании на его основе работ по созданию семейства малогабаритных суперкомпьютеров ЕС119Х.Х, использующих все архитектурные, структурные и даже большую часть схемотехнических решений ЕС1191 (в базовых моделях этого семейства используется 60 - 70% БИС, разработанных для ЕС1191). В итоге всего через год - небольшой коллектив инженеров завершил проектирование первой модели этого семейства - суперскалярной мини-суперЭВМ ЕС1195. В результате этих усилий родилась достаточно быстрая (50 MFLOPS при 256 Мбайт оперативной памяти) и весьма компактная (для ее установки требуется менее одного квадратного метра площади) машина, которая была впервые продемонстрирована на выставке "Информатика-93". Завершена разработка и началось изготовление второй базовой модели семейства ЕС119Х.Х - векторного суперкомпьютера ЕС1191.01, пиковая производительность которого составляет 500 MFLOPS. Наконец, проектируется гибридная система ЕС1191.10, объединяющая достоинства векторно-конвейерной и MPP-обработки. Ее минимальная конфигурация позволит получить производительность на уровне 2 GFLOPS. Все модели семейства ЕС119Х.Х предназначены для работы под Unix или OS/2 и сконструированы в так называемом "офисном исполнении.
Впрочем, разработчики ЕС119Х.Х отчетливо понимают, что у их детища есть "ахиллесова пята" - устаревшая элементная база (ECL-чипы со степенью интеграции 1500 вентилей на кристалл). Поэтому в развитие идей ЕС119Х.Х начались работы по созданию семейства суперкомпьютеров "АМУР" на базе КМОП-микросхем со степенью интеграции 200 тыс. вентилей на кристалл. Эта программа рассчитана на три года и должна завершиться выпуском трех базовых моделей суперкомпьютеров, позволяющих строить масштабируемые вычислительные системы с производительностью от 50 MFLOPS до 20 GFLOPS. Существенной особенностью всех базовых моделей семейства "АМУР" является использование единого комплекта из семи чипов (по сути, микропроцессоров) и размещение процессоров на одной плате, подобной "материнской" плате персонального компьютера. Естественно, что перечисленные особенности суперкомпьютеров "АМУР" означают значительное снижение затрат на производство и эксплуатацию этих машин, т.е. в конечном счете уменьшение их рыночной стоимости.
Похожие работы


... . Доступ к данному ресурсу осуществляется круглосуточно. Портал электронных ресурсов Южного Федерального Университета предоставляет доступ к базам данных и полнотекстным материалам, принадлежащим Южному федеральному университету. Заключение. История развития сетевых технологий и проектов, основанных на них, очень интересна. В ней присутствуют определенные закономерности. Развитие ми
... реализованной платформой с производительностью до нескольких TFlops, стопроцентно совместимой с предыдущими поколениями систем nCube. 2.1 Основные принципы архитектуры a) Распределенная память В суперкомпьютерах nCube используется архитектура распределенной памяти, позволяющая оптимизировать доступ к оперативной памяти, вероятно, наиболее критичному ресурсу вычислительной системы. ...
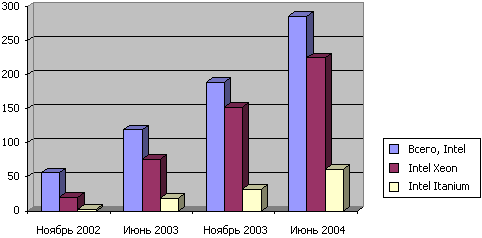
... создавать суперкомпьютеры, на сборку которых раньше уходили годы, причем их стоимость также значительно уменьшается. Эту тенденцию невозможно игнорировать, поскольку сегодня суперкомпьютеры, ранее доступные только для проектов с огромными бюджетами, могут использоваться в самых разных областях». Самая высокопроизводительная кластерная система в мире Используемый в Национальной лаборатории им. ...
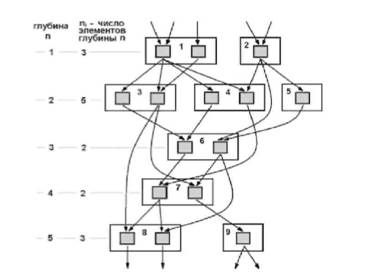
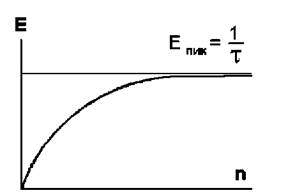
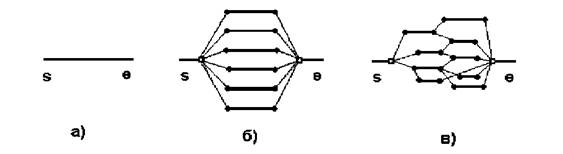
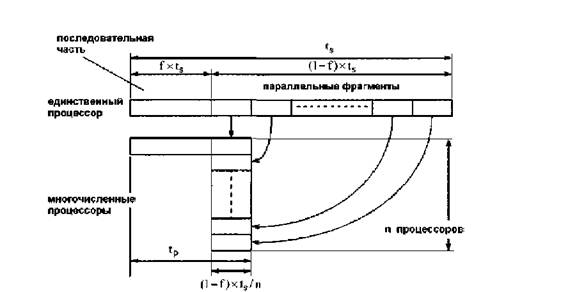
... 5k управления ресурсами (программно-аппаратный комплекс) массивно-параллельного компьютера обязана обрабатывать подобные ситуации в обход катастрофического общего рестарта с потерей контекста исполняющихся в данный момент задач. 2.4.1 Массивно-параллельные суперкомпьютеры серии CRY T3 Основанная в 1972 году фирма Cry Research Inc. (сейчас Cry Inc.), прославившаяся разработкой векторного ...
0 комментариев