А.Ф. Оськин, В.И. Шайков
Нынешний этап развития исторической науки, как и науки вообще, характеризуется все возрастающим потоком информации. Обработку больших объемов информации с помощью компьютера нельзя эффективно организовать только путем совершенствования технических средств - увеличивая объемы памяти, сокращая время обращения к внешним носителям и т.д.. Необходимо совершенствовать также и методы организации информации, разрабатывая эффективные алгоритмы ее кодирования.
Что же такое информация? Одно из возможных определений этого понятия рассматривает информацию как "содержание связи между взаимодействующими материальными объектами, проявляющееся в изменении состояния этих объектов"[1].
Интересно отметить, что в теории информации отсутствует строгое определение понятия "информация". Необходимым и достаточным условием построения этой теории оказалось введение понятия количества информации.
Как же определяют количество информации? В классической теории информации игнорируются ценность, срочность и смысловое содержание информации, т.е. не принимаются в расчет качественные характеристики сообщений. Когда же не учитываются качественные характеристики, то имеет смысл говорить не о количестве информации, а о ее объеме. Следует отметить, что с этой точки зрения историческая информация имеет ряд особенностей. Для историка весьма важным является задача создания и сохранения в машиночитаемом архиве наиболее полной электронной копии нарративного источника. Если учесть сложность и неоднородность информации, характерные для исторического источника, а также быстро увеличивающееся число архивов, хранящих информацию в машиночитаемой форме, актуальной становится задача разработки принципов хранения информации. При этом весьма важным представляется поиск путей качественного улучшения методов кодирования и хранения информации.
Рассмотрению одного из таких методов и посвящена настоящая статья. В дальнейшем под информацией мы будем понимать наборы числовых данных, поскольку хранимым образом любого источника может быть число или множество чисел. При этом под количеством информации мы будем подразумевать ее объем, т.е. количество байтов памяти, необходимых для записи элементов числовых множеств.
Большинство используемых в настоящее время методов кодирования основывается на учете статистической информации о кодируемом множестве. В работе В.А. Амелькина[2]приведена одна из возможных классификаций методов кодирования. В соответствии с этой классификацией, выделяются следующие группы методов:
упаковки (код Бодо);
статистические методы;
алгоритмическое и комбинаторное кодирование.
Методы упаковки.
Как показано в той же работе, для кодирования множества A, состоящего из p элементов, при использовании равномерного двоичного кода, длина S кодовых сообщений равна:
S =[ log (p) ] + 1 (1)
При кодировании информации по методу Бодо в исходной матрице X= отыскивается максимальный элемент, для которого в соответствии с формулой (1)
So = [ log (max(xi,j))] + 1 (2)
рассчитывается требуемое для его хранения число двоичных разрядов. При этом, для хранения каждого элемента таблицы xi,j отводится So двоичных разрядов. Для хранения всей таблицы необходимо (n*m*So) двоичных единиц. (Здесь n- число строк, а m- число столбцов исходной матрицы).
Существуют модификации этого метода, позволяющего повысить степень упаковки. К недостаткам метода следует отнести то, что он эффективен лишь на матрицах специального вида с незначительными различиями по абсолютному значению внутри строки и значительному - внутри столбцов (или наоборот).
Статистические методы.
В эту группу входят методы, основанные на учете статистических данных о кодируемом множестве. Исторически первым в этой группе был код Морзе.
В 1948-49 г.г. сразу двумя исследователями Шенноном и Фано независимо друг от друга был предложен метод кодирования, основанный на учете условных вероятностей появления сообщений. При этом сообщениям, имеющим большую вероятность ставились в соответствие более короткие кодовые сообщения, чем соообщениям, имеющим меньшую вероятность.
Идеи статистического кодирования получили свое дальнейшее развитие в работах Хаффмена. Код Хаффмена более эффективен чем Шеннона-Фано и в настоящее время широко используется при построении разнообразных программупаковщиков.
Алгоритмическое и комбинаторное кодирование.
Основная идея комбинаторного кодирования заключается в задании множества кодируемых сообщений не посредством перечисления всех элементов множества, а путем определения процедуры вычисления номера для некоторого сообщения.
Описываемые ниже методы нумерующего кодирования относятся именно к этой группе.
В основе предлагаемого нами метода кодирования лежит метод полиадических чисел, описанный в книге В.И. Амелькина[3]. Метод полиадических чисел использует полиадическую систему счисления, т.е. такую позиционную систему счисления, в которой в качестве основания приняты не постоянные числа p, а набор некоторых целых чисел l1, l2, ..., lm, на разность которых не накладывается никаких ограничений, т. е. li - lj при i = j может быть больше нуля, равно нулю или меньше нуля[4].
В такой системе счисления число L1, a2, ..., am можно представить в виде:
L = a1*l2*l3* ... *lm + a2*l3*l4* ... *lm + am-1*lm + am (3)
При этом каждая цифра ai < li, а каждый i-ый разряд имеет весовой коэффициент:
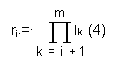
В работе В.И. Амелькина[5] сформулирована теорема существования и единственности такого разложения.
Использование полиадической системы счисления позволяет построить следующий алгоритм упаковки. Пусть задана целочисленная матрица A=ai,j , i=1,..,m, j=1,..,n.
С помощью преобразования
![]()
где
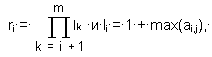
эту матрицу можно заменить двумя векторами N=nj и L=li, причем существует обратное преобразование
ai,j = [ nj / ri ] - [ nj / (lj*ri) ] * li , (6)
позволяющее по N и L восстановить любой элемент ai,j с погрешностью E=0. (Квадратными скобками здесь обозначена операция выделения целой части). Так как для хранения векторов N и L требуется меньше двоичных единиц, чем для хранения исконой матрицы, коэффициент сжатия
![]()
оказывается больше единицы. Здесь So- число двоичных единиц, требуемых для хранения исходной матрицы, Si- число двоичных единиц, требуемых для хранения элементов векторов N и L.
Как показали приведенные нами численные эксперименты, описанный выше алгоритм не обладает высокой эффективностью. К его недостаткам можно также отнести сложности, возникающие при реализации программ- упаковщиков на его основе.
В этой связи, мы поставили перед собой задачу совершенствования описанного алгоритма с целью повышения его эффективности и создания таких его версий, которые легко реализовывались бы в виде программ.
В нашем алгоритме кодируемая информация представляется в виде множества значений переменных байтового типа. Значения объединены в группы по четыре числа. Пусть таких групп в исходном информационном массиве выделено m (m>>4).
Выполнив для указанного массива описанную выше процедуру кодирования, получим два вектора - N с m элементами и L, состоящий из 4-х элементов.
Для повышения эффективности алгоритма (а под эффективностью мы здесь и в дальнейшем понимаем, в первую очередь, повышение коэффициента сжатия), выполним следующее преобразование.
Каждый из элементов полученного вектора N представим в виде 4-х разрядного двухсотпятидесятишестиричного числа и к полученной 4-х строчной матрице вновь применим процедуру полиадиического кодирования.
Многократно повторив описанную последовательность шагов, можно существенно повысить коэффициент сжатия исходной информации. В приведенных ниже таблицах показаны этапы сжатия исходной информации, представляющей собой некоторый набор латинских литер.
Таблицы рассчитывались с помощью табличного процессора из интегрированного пакета Works 2.0.
Приведенный пример подтверждает высокую эффективность описанного алгоритма.
Очевидно также, что на базе описываемого подхода могут быть реализованы быстрые и эффективные программы-упаковщики.
Таблица 1. Пример нумерационного кодирования
Исходный массив Компоненты вектора L
87 89..................................79 89 90
90 85..................................85 66 91
85 66..................................78 79 86
94 80..................................70 72 95
65425359 66869630 59435990 66715627 <- Вектор N
Первая итерация
3 3...................................3 3 4
230 252.................................138 249 253
79 89.................................235 255 256
207 126.................................214 235 236
59770275 61101706 54248612 60959743 <- Вектор N
Восьмая итерация
0 0....................................0 0 1
228 234..................................210 233 235
124 188....................................9 245 246
163 138....................................0 255 256
14390435 14784650 13227264 14736383 <- Вектор N
Список литературы
1.И.И. Гришкин. Понятие информации (логико- методологический аспект). М. 1973.
2.В.А. Амелькин Методы нумерационного кодирования. Новосибирск, 1986.
3.В.А. Амелькин Методы нумерационного кодирования. Новосибирск, 1986.
4.Там же.
5.В.А. Амелькин Методы нумерационного кодирования. Новосибирск
Похожие работы



... зловещую команду: YOU KILL ATONES Кардано использовал квадратную решетку, которая своими вырезами однократно покрывает всю площадь квадрата при ее самосовмещениях. На основе такой решетки он построил шифр перестановки. Нельзя не упомянуть в историческом обзоре имени Матео Ардженти, работавшего в области криптографии в начале XVII в. Он составил руководство по криптографии на 135 листах, ...
... лучше учитывают и такую исторически сложившуюся особенность российских Интернет-ресурсов, как сосуществование нескольких кодировок кириллицы.2. Обзор и характеристика поисковых систем сети Internet 2.1 Rambler Для поиска русскоязычной информации в Интернете лучше использовать русские поисковые системы. В этом опыте и в следующих других мы будем искать информацию с помощью нескольких систем ...
... общие рассуждения фактами, аргументами и, наоборот, вывести определенные суждения на основании конкретного, фактического изложения материала”. Авторы отмечают, что по ответам “чувствуется отсутствие должного умения работы с историческим документом даже в такой несложной сфере, как наиболее полное извлечение необходимой по заданию информации из текста, не говоря уже о более глубоком анализе. ...
... породил то же явление и в науке. Однако, как бы ни дискутировали ученые, а время требует свое, и реформа идет своим чередом. О дальнейших изменениях в современном историческом образовании речь пойдет дальше. 4. Переход от линейного к концентрическому преподаванию истории в школе Систему школьного исторического образования наряду с содержанием и основными принципами его отбора ...
0 комментариев