А.Н. Целых, Р.П. Тимошенко
Моделирование процессов принятия решений становится центральным направлением автоматизации деятельности лица, принимающего решения (ЛПР). К задачам ЛПР относится принятие решений в геоинформационной системе. Современную геоинформационную систему можно определить как совокупность аппаратно-программных средств, географических и семантических данных, предназначенную для получения, хранения, обработки, анализа и визуализации пространственно-распределенной информации.
Экологические геоинформационные системы позволяют работать с картами различных экологических слоев и автоматически строить аномальную зону по заданному химическому элементу. Это достаточно удобно, так как эксперту-экологу не нужно в ручную рассчитывать аномальные зоны и производить их построение. Однако, для полного анализа экологической обстановки эксперту-экологу требуется распечатывать карты всех экологических слоев и карты аномальных зон для каждого химического элемента. В геоинформационной системе [1] построение аномальных зон производилось для тридцати четырех химических элементов. Сначала он должен получить сводную карту загрязнения почвы химическими элементами. Для этого путем последовательного копирования на кальку со всех карт, строится карта загрязнения почвы химическими элементами [2]. Затем полученную карту таким же образом сопоставляют с картами гидрологии, геологии, геохимических ландшафтов, глин. На основании сопоставления строится карта качественной оценки опасности окружающей среды для человека. Таким образом осуществляется мониторинг окружающей среды.
Этот процесс требует много времени и высокой квалификации эксперта, для того, чтобы точно и объективно оценить обстановку. При таком большом объеме информации, одновременно, обрушивающейся на эксперта могут возникать ошибки. Поэтому возникла необходимость в автоматизации процесса принятия решений. Для этого существующая геоинформационная система была дополнена подсистемой принятия решений.
Особенностью разработанной подсистемы является то, что одна часть данных с которыми работает программа, представлена в виде карт. Другая часть данных обрабатывается и на их основе строится карта, которая затем также подлежит обработке. Для реализации системы принятия решений был избран аппарат теории нечетких множеств. Это вызвано тем, что с помощью нечетких множеств можно создавать методы и алгоритмы способные моделировать приемы принятия решений человеком в ходе решения различных задач. В качестве математической модели слабоформализованных задач выступают нечеткие алгоритмы управления, позволяющие получать решение хотя приближенные, но не худшие, чем при использовании точных методов.
Под нечетким алгоритмом управлению будем понимать упорядоченную последовательность нечетких инструкций (могут иметь место и отдельные четкие инструкции), обеспечивающую функционирование некоторого объекта или процесса.
Методы теории нечетких множеств позволяют, во-первых, учитывать различного рода неопределенности и неточности, вносимые субъектом и процессами управления, и формализовать словесную информацию человека о задаче; во-вторых, существенно уменьшить число исходных элементов модели процесса управления и извлечь полезную информацию для построения алгоритма управления.
Сформулируем основные принципы построения нечетких алгоритмов. Нечеткие инструкции, используемые в нечетких алгоритмах, формируются или на основе обобщения опыта специалиста при решении рассматриваемой задачи, или на основе тщательного изучения и содержательного ее анализа.
Для построения нечетких алгоритмов учитываются все ограничения и критерии, вытекающие из содержательного рассмотрения задачи, однако полученные нечеткие инструкции используются не все: выделяются наиболее существенные из них, исключаются возможные противоречия и устанавливается порядок их выполнения, приводящий к решению задачи.
С учетом слабоформализованных задач существуют два способа получения исходных нечетких данных - непосредственный и как результат обработки четких данных. В основе обоих способов лежит необходимость субъективной оценки функций принадлежности нечетких множеств.
Рассмотрим модель классификации на основе которой строится система принятия решений [3]. Модель описывает разбиение многомерного пространства признаков факторов, наиболее существенно влияющих на выбор управляющих решений, на нечеткие области, соответствующие этим решениям. Модель представляется в виде тройки (W, Q, H), в которой W=![]() - множество признаков факторов, Q={L1,...,Li,...,Lk} - разбиение W на нечеткие эталонные классы Li ,H={ h1,...,hi,...,hk } - множество управляющих решений hi , соответствующих классам Li .
- множество признаков факторов, Q={L1,...,Li,...,Lk} - разбиение W на нечеткие эталонные классы Li ,H={ h1,...,hi,...,hk } - множество управляющих решений hi , соответствующих классам Li .
Путем экспертного опроса или исходя из содержательного анализа задачи выделяются признаки-факторы X, Y, Z (для простоты рассматриваем только три) и формируется пространство W=![]() . Эта процедура является неформальной и существенно зависит от предметной области, квалификации специалистов экспертов. С каждым из выделенных признаков связывается своя лингвистическая переменная со своими значениями. Лингвистические переменные, соответствующие признакам X, Y, Z, обозначим соответственно через A, B, C, а их значения – через
. Эта процедура является неформальной и существенно зависит от предметной области, квалификации специалистов экспертов. С каждым из выделенных признаков связывается своя лингвистическая переменная со своими значениями. Лингвистические переменные, соответствующие признакам X, Y, Z, обозначим соответственно через A, B, C, а их значения – через
{![]() }, {
}, {![]() }, {
}, {![]() }.
}.
Для всех выделенных значений ![]() ,
, ![]() ,
, ![]() путем экспертного опроса строятся функции принадлежности
путем экспертного опроса строятся функции принадлежности ![]() ,
, ![]() ,
, ![]() на соответствующих базовых шкалах X, Y, Z. Строится качественная структура модели в виде решающей таблицы, имеющей nmp строк и 4 столбца. Строки таблицы соответствуют всевозможным наборам (
на соответствующих базовых шкалах X, Y, Z. Строится качественная структура модели в виде решающей таблицы, имеющей nmp строк и 4 столбца. Строки таблицы соответствуют всевозможным наборам (![]() ,
, ![]() ,
, ![]() ), первые три столбца обозначены символами лингвистических переменных A, B, C, четвертый столбец обозначен символом Н. В столбцах A, B, C проставляются всевозможные наборы (
), первые три столбца обозначены символами лингвистических переменных A, B, C, четвертый столбец обозначен символом Н. В столбцах A, B, C проставляются всевозможные наборы (![]() ,
, ![]() ,
, ![]() ), то в столбце H для каждого такого набора специалист-эксперт проставляет одно из возможных управляющих решений hi, которое он принял бы в ситуации, словесно описанной соответствующим набором. В итоге формируется модель (W, Q, H), в которой каждый класс Li характеризуется функцией принадлежности
), то в столбце H для каждого такого набора специалист-эксперт проставляет одно из возможных управляющих решений hi, которое он принял бы в ситуации, словесно описанной соответствующим набором. В итоге формируется модель (W, Q, H), в которой каждый класс Li характеризуется функцией принадлежности ![]() , задаваемой следующей нечеткой логической формулой:
, задаваемой следующей нечеткой логической формулой:
![]() ,
,
где Li - множество наборов (![]() ,
, ![]() ,
, ![]() ), которым в решающей таблице соответствует решение hi ,
), которым в решающей таблице соответствует решение hi ,![]() .
.
В основе программной реализации лежит вышеописанный алгоритм. При программной реализации используется 5 лингвистических переменных и число строк решающей таблицы составляет 162.
Нечеткие модель в силу относительной простоты требуют меньше времени и объема памяти для своей реализации по сравнению с известными методами математического программирования.
Необходимо также отметить, что программа реализована в операционной среде Windows 3.1, что позволяет использовать дополнительные возможности этой ОС. Программа написана на языке Borland C++, который является языком объектно-ориентированного программирования (ООП) [4].
Работу программы можно разделить на две части. Первая часть это логическая обработка данных проб почвы и построение сводной карты загрязнения почвы химическими элементами. Вторая часть обработка карт, характеризующих различные экологические слои и построение карты, качественной оценки состояния окружающей среды.
Логическая обработка данных проб почвы и построение сводной карты загрязнения почвы химическими элементами.
Программа являлась развитием уже существующей версии программы “ТагЭко”, дополняет существующую программу новыми функциями. Для работы новых функций необходимы данные содержащиеся в предыдущей версии программы. Этим обусловлено использование методов доступа к данным разработанных в предыдущей версии программы. Используется функция для получения информации, хранящейся в базе данных. Это необходимо для получения координат каждой точки пробы, хранящейся в базе данных. Также используется функция для расчета величины аномального содержания химического элемента в ландшафте. Таким образом через эти данные и эти функции происходит взаимодействие предыдущей программы с подсистемой принятия решений. В случае изменения в базе данных значения пробы или координат пробы это будет автоматически учитываться в подсистеме принятия решений.
Необходимо отметить, что при программировании используется динамический стиль выделения памяти и данные хранятся в виде односвязных, либо двусвязных списков. Это обусловлено тем, что заранее неизвестно количество проб или количество участков поверхности на которые будет разбита карта.
Построение карты качественной оценки влияния окружающей среды на человека.
Построение карты происходит согласно алгоритму, описанному выше. Пользователь указывает интересующую его область, а также шаг с которым будет производиться анализ карт. Перед началом обработки данных производится считывание информации из WMF файлов и формирование списков, элементами которых являются указатели на полигоны. Для каждой карты составляется свой список. Затем после формирования списков полигонов производится формирование карты загрязнения почвы химическими элементами. По окончании формирования всех карт и ввода исходных данных формируются координаты точек, в которых будет производиться анализ карт. Данные, получаемые функциями опроса заносятся в специальную структуру. Завершив формирование структуры программа производит ее классификацию. Каждая точка сетки опроса получает номер эталонной ситуации. Этот номер с указанием номера точки заносится в двусвязный список, чтобы потом можно было бы построить карту графически. Специальная функция анализирует этот двусвязный список и производит графическое построение изолиний вокруг точек, имеющих одинаковые классификационные ситуации. Она считывает точку из списка и анализирует значение номера ее ситуации с номерами соседних точек, и в случае совпадения объединяет рядом расположенные точки в зоны.
В результате работы программы вся территория г.Таганрога окрашивается в один из трех цветов. Каждый цвет характеризует качественную оценку экологической обстановки в городе. Так красный цвет указывает на “особо опасные участки”, желтый на “опасные участки”, зеленый на “безопасные участки”. Таким образом информация представляется в доступной для пользователя и удобной для восприятия форме.
Список литературы
Берштейн Л.С., Целых А.Н. Гибридная экспертная система с вычислительным модулем для прогноза экологических ситуаций. Труды международного симпозиума “Интеллектуальные системы - ИнСис - 96”, г.Москва, 1996г.
Алексеенко В.А. Геохимия ландшафта и окружающая cреда. - М.:Недра, 1990. -142с.:ил.
Мелихов А.Н., Баронец В.Д. Проектирование микропроцессорных средств обработки нечеткой информации. – Ростов-на-Дону. Издательство Ростовского университета, 1990. - 130с.
Неформальное введение в С++ и TURBO VISIO. С. - Петербург: Петрополь, 1992. - 384с.
Похожие работы
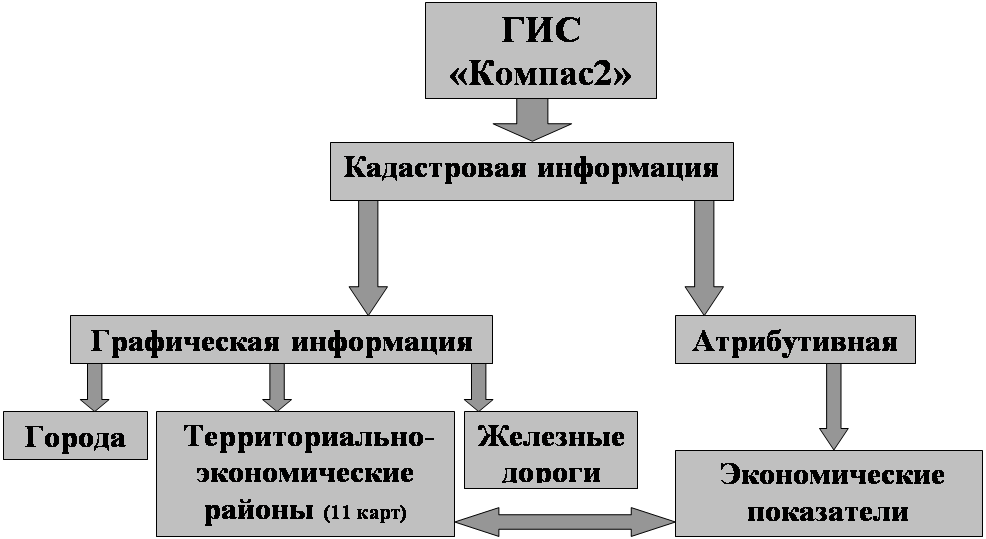
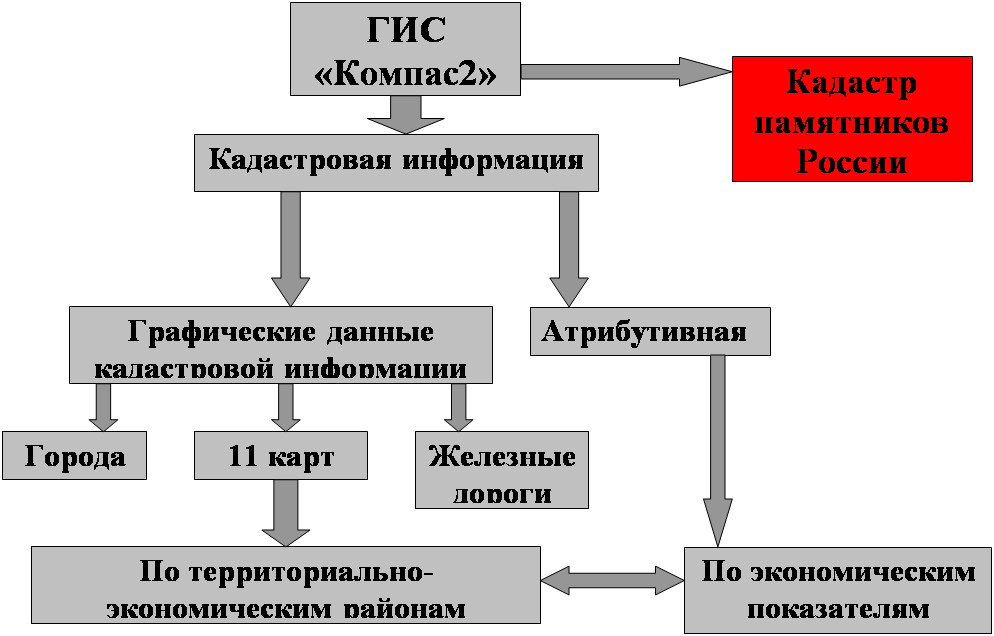
... кадастра памятников России и привязки его к ГИС «Компас-2», я изучил возможности, функции ГИС «Компас-2», а также возможность использования его для создания различных видов природных кадастров. Компас-2 – это сетевая система для представления, моделирования и анализа географической информации Функциональные возможности системы КОМПАС 2: публикация географической информации (ГИ) в сетях ...

... Architect, Visible Analyst Workbench, EasyCASE), так и новые версии и модификации перечисленных систем. 3 Глава. Разработка концептуальной модели информационной системы для поддержки принятия управленческих решений при формировании маркетинговой стратегии региона Процесс создания и внедрения любой ИС принято разделять на четыре последовательные фазы: анализ, глобальное проектирование ( ...

... систем электронной торговли; 5. Устранение промежуточных звеньев в системе интеграции организация - внешняя среда. 31. основные разделы искусственного интеллекта Одно из направлений информатики - интеллектуализация информационных систем. Интеллектуальные системы и технологии применяются для тиражирования профессионального опыта и решения сложных научных, производственных и экономических ...
... приходит, с карты начинается и картой кончается». «Карта... способствует выявлению географических закономерностей». «Карта является как бы вторым языком географии...». По К.А. Салищеву, картографический метод исследования заключается в использовании разнообразных карт для описания, анализа и познания явлений, для получения новых знаний и характеристик, изучения процессов развития, установления ...
0 комментариев