Содержание
Введение.................................................................................................................................................................................... 2
Глава 1.......................................................................................................................................................................................... 5
Системы управления базами данных (СУБД)............................................................................................ 5
1.1 Основные положения.................................................................................................................................................. 5
1.2. Иерархическая и сетевая даталогические модели СУБД.......................................................................... 10
Глава 2........................................................................................................................................................................................ 12
Сетевые структуры...................................................................................................................................................... 12
2.1. Файловая модель....................................................................................................................................................... 13
Глава 3........................................................................................................................................................................................ 17
Реляционные структуры......................................................................................................................................... 17
3.1. Реляционные даталогические модели СУБД................................................................................................... 19
3.2. Объектно-ориентированные СУБД (ООСУБД).............................................................................................. 25
Глава 4........................................................................................................................................................................................ 27
Иерархические стpуктуpы..................................................................................................................................... 27
4.1. Иерархические структуры в реляционных базах данных.......................................................................... 28
4.2. Вложенные рекурсивные иерархические данные........................................................................................... 29
4.3. Отображение данных.............................................................................................................................................. 29
Глава 5........................................................................................................................................................................................ 32
OLE: основные сведения.......................................................................................................................................... 32
5.1. Введение в OLE........................................................................................................................................................... 32
5.2. Связывания и внедрение объектов...................................................................................................................... 33
5.3. Различие между связыванием и внедрением объектов................................................................................. 35
Глава 6........................................................................................................................................................................................ 37
Достоинства и недостатки тестовой системы или методическое обоснование автоматизации процесса обучения............................................................................................................. 37
5.1. Межпредметные связи и компьютерное обучение....................................................................................... 39
Глава 7........................................................................................................................................................................................ 41
Разработка тестирующей программы........................................................................................................ 41
Заключение......................................................................................................................................................................... 44
Список литературы...................................................................................................................................................... 45
ВведениеОсновные идеи современной информационной технологии базируются на концепции баз данных (БД). Согласно данной концепции основой информационной технологии являются данные, организованные в БД, адекватно отражающие реалии действительности в той или иной предметной области и обеспечивающие пользователя актуальной информацией в соответствующей предметной области.
В первых трёх главах рассматриваются новые системы управления базами данных, такие как иерархическая и сетевая даталогические модели, реляционные даталогические модели, объектно-ориентированные СУБД. Обычно различают три класса СУБД, обеспечивающих работу иерархических, сетевых и реляционных моделей. Однако различия между этими классами постепенно стираются, причем, видимо, будут появляться другие классы, что вызывается прежде всего интенсивными работами в области баз знаний (БЗ) и объектно-ориентированной инфотехнологией. Поэтому традиционной классификацией пользуются все реже, но мы пока будем придерживаться именно ее, как наиболее устоявшуюся. Каждая из указанных моделей обладает характеристиками, делающими ее наиболее удобной для конкретных приложений.
Глава 4 «Иерархические структуры» подробнее описывает положительные и отрицательные черты иерархической модели. Окружающий мир переполнен иерархическими данными. Любая группа объектов, в которой один объект может быть «родителем» для произвольного числа других объектов, организована в виде иерархического дерева. При работе с иерархиями используется «семейная» терминология (родители, внуки, предки, потомки), поскольку семья является самым распространённым примером объектов (в данном случае – людей), объединённых иерархическими отношениями. В то же время место объекта в иерархическом дереве - не более чем условное обозначение связи с другими объектами. Иерархическая структура всего лишь помогает сохранить и найти объект.
В пятой главе обзор технологии OLE. С появлением новых более мощных, компьютеров и средств программирования было создано новое поколение элементов на базе OLE. Наиболее привлекательным преимуществом OLE является возможность использования методов других серверов приложений. Намного удобнее использовать функциональность электронных таблиц, таких как Excel, или текстовых процессоров, таких как Word, вместо того чтобы разрабатывать аналогичную функциональность в собственном приложении.
Изначально технология OLE являлась стандартом, обеспечивающим связывание и встраивание объектов. Когда приложение- сервер OLE- активизируется, это происходит внутри контейнера, расположенного в вашем приложении. Визуально при активизировании сервера OLE текущие панели инструментов и меню заменяются панелями инструментов и меню сервера OLE или сливаются с ними. Кроме того, часть формы становится окном сервера OLE, так как сервер принимает на себя управление областью формы. Связыванием называют ассоциирование файла объекта OLE с контейнером OLE. Файл объекта никогда не сохраняется в контейнере, но контейнер OLE ссылается на файл. Одним из преимуществ связывания объектов является то, что множество пользователей, серверов OLE и приложений-контейнеров могут получать доступ к одному документу. При встраивании объектов реальный объект сохраняется в вашем приложении и другие контейнеры OLE не имеют доступа к этому объекту. Преимуществом встраивания является хранение данных как части приложения.
Шестая глава посвящена достоинствам и недостаткам тестовой системы. Одной из форм привлечения преподавателей к использованию компьютера являются тестирующие программы, которые позволяют преподавателю упростить проверку знаний учащихся и в то же время в увлекательной форме преподносят ученикам знания по той или иной дисциплине.
Целью данной дипломной работы является создание программы по компьютерному контролю знаний студентов.
Передо мной были поставлены следующие задачи:
– дать обзор современному состоянию теории баз данных, основным моделям СУБД, применяемым в ПК;
– изучить принципы функционирования и основные возможности технологии OLE;
– разработать способ отображения реляционных структур данных в иерархическом виде;
– дополнить стандартный компонент Delphi OLEContainer возможностью сохранения битового изображения на его поверхности.
Система автоматизированного контроля знаний, рассмотренная в главе 6, позволяет автоматизировать проведение контрольных работ по дисциплинам. Это удобное добавление к традиционным методам контроля, повышающее эффективность усвоения предмета студентом. Межпредметные связи и компьютерное обучение рассмотренные в этой главе представляют собой общеобразовательные цели информатики, среди них: наведение и усиление межпредметных связей, способствование восприятию целостной, системной картины мира, информационных процессов в обществе, природе и познании. Для разумного и плодотворного использования ВТ необходима общеобразовательная и компьютерная грамотность. Отсюда выявляется межпредметная связь с основами информатики и ВТ, с математикой, русским языком, литературой и английским языком. ВТ для учителя выступает и как предмет, и как средство обучения, и как инструмент психолого-педагогических исследований (тестирования).
В седьмой главе изложены проблемы разработки тестирующей программы и их решение.
Глава 1 Системы управления базами данных (СУБД)Основные идеи современной информационной технологии базируются на концепции баз данных (БД). Согласно данной концепции основой информационной технологии являются данные, организованные в БД, адекватно отражающие реалии действительности в той или иной предметной области и обеспечивающие пользователя актуальной информацией в соответствующей предметной области. Первые БД появились уже на заре 1-го поколения ЭВМ представляя собой отдельные файлы данных или их простые coвокупности. По мере увеличения объемов и структурной сложности хранимой информации, а также расширения круга потребителей; информации определилась необходимость создания удобных эффективных систем интеграции хранимых данных и управления ими. В конце 60-х годов это привело к созданию первых коммерческих систем управления базами данных (СУБД), поддерживающих opганизацию и ведение БД. Перед обсуждением последующего материала, нам потребуется ряд основных понятий, используемых в информационных системах различного назначения.
1.1 Основные положенияБаза данных (БД) в строгом смысле слова представляет собой совокупность взаимосвязанных файлов данных определенной организации. БД, как правило, включает целый ряд файлов, но может состоять и из единственного файла. Данные, составляющие БД, отражают характеристики объектов и их отношений в соответствующей прикладной области. Каждый файл, входящий в БД, содержит определенное число записей (изменяемое в процессе функционирования БД), отражающих ту или иную сторону предметной области, на которую ориентирована БД. Как правило, файлы БД содержат большое число однотипных записей. Записи, в свою очередь, состоят из полей, представляющих определенные типы информации об объектах. Поле является наименьшей информационной единицей, непосредственно доступной в записи. Если файл_1 БД (рис. 1) содержит п однотипных записей (имеющих одинаковую структуру полей и их смысловую нагрузку),то j-запись (1<j<n) файла состоит из фиксированного набора (кортежа полей А1—Ак), каждое из которых содержит в общем случае различного типа информацию. При наличии БД прикладные программы могут использовать ее информацию (записи и их поля) для решения конкретных задач в прикладной области, на которую ориентирована данная БД.

| 1 | Поле А1 | Поле А2 | … | Поле Ак | … | Поле S1 | Поле S2 | … | Поле Sd | 1 |
| 2 | Поле А1 | Поле А2 | … | Поле Ак | … | Поле S1 | Поле S2 | … | Поле Sd | 2 |
| ... | … | … | … | … | … | … | … | … | … | … |
| N | Поле А1 | Поле А2 | … | Поле Ак | … | Поле S1 | Поле S2 | … | Поле Sd | p |
| Файл_1 | Файл_М |
|
Рис. 1 Файловая организация баз данных (файлы, записи, поля)
Пользователями БД являются четыре основные категории потребителей ее информации и/или поставщиков информации для нее: (1) конечные пользователи, (2) программисты и системные аналитики, (3) персонал поддержки БД в актуальном состоянии и (4) администратор БД. Хорошо спроектированные системы управления БД (СУБД), используют развитые графические интерфейсы и поддерживают системы отчетов, отвечающие специфике пользователей указанных четырех категорий. В этом случае персонал поддержки БД и конечные пользователи могут легко осваивать и использовать СУБД для обеспечения своих потребностей без какой-либо специальной подготовки, т.е. специфика функционирования данных систем скрыта от пользователя. Более того, хорошо спроектированные СУБД предоставляют опытному пользователю средства для создания собственных БД-приложений, не требуя от него специальной программистской подготовки. Конечным пользователям для обеспечения доступа к информации БД предоставляется графический интерфейс, как правило, в виде системы окон с функциональными меню, позволяющими легко получать необходимую информацию на экран и/или принтер в виде удобно оформленных отчетов.
Программисты и системные аналитики используют СУБД совершенно в ином качестве, обеспечивая разработку новых БД-приложений, поддерживая и модифицируя (при необходимости) уже существующие. Для данной группы пользователей СУБД требуются средства, обеспечивающие указанные функции (создание, откладка, редактирование и т.д.). Пользователи третьей категории нуждаются в интерфейсе, как правило, графическом для обеспечения задач поддержания БД в актуальном состоянии. Эти пользователи состоят в штатах подразделений функциональных и/или обработки информации, обеспечивающих прикладную область, и отвечают за актуальное состояние соответствующей ей БД (контроль текущего состояния, удаление устаревшей информации, добавление новой и т.д.). Программисты выполняют своего рода посреднические функции между БД и конечными пользователями. И если на первых этапах развития БД-технологии они составляли весьма многочисленную группу пользователей, то в процессе развития СУБД и, прежде всего, массового использования ПК эта категория сходит на нет. Особую и ответственную роль выполняет администратор, отвечающий как за актуальность находящейся в БД информации, так и за корректность функционирования и использования БД и СУБД.
В случае больших БД может быть достаточно много конечных пользователей, ряд программистов и несколько администраторов БД; в случае небольших БД (что особенно характерно для ПК) все эти функции могут обеспечиваться одним человеком. Важные функции выполняет администратор БД, отвечающий за выработку требований к БД, ее проектирование, реализацию, эффективное использование и сопровождение. Необходимость в таком специалисте вытекает из принципа независимости данных, а также диктуется важностью БД в деятельности организаций и более крупных объединений — поставщиков и потребителей информации БД. Администратор БД взаимодействует с пользователями в определении требований к базе в процессе выработки требований к системе в целом, пользуется языков описания данных для определения БД в процессе проектирования системы, взаимодействует с программистами, которые создают ПС использующее доступ к БД, отвечает за загрузку БД информацией в процессе реализации системы, контролирует работоспособность БД, используя соответствующие программные и аппаратные средства, и определяет, когда следует реорганизовывать данные в базе или начать работы по созданию новой, более совершенной БД. В целом функции администратора БД сводятся к поддержанию целостности БД, необходимого уровня защиты ее данных и эффективности. Среди его наиболее важных обязанностей — согласование конфликтующих требований, которое требуется достаточно часто, ибо БД обслуживает, как правило, целый ряд различных прикладных процессов.
Как уже отмечалось, БД представляет собой совокупность логически взаимосвязанных файлов данных определенной организации; для определения и обращения к такой файловой совокупности используют средства системы управления БД (СУБД). СУБД представляет собой совокупность лингвистических и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. Тогда как под системой БД понимается СУБД с наполненной соответствующей информацией БД, управляемой ее средствами. Это означает, во-первых, что совокупность файлов БД определяется посредством схемы, не зависящей от программ, которые к ней обращаются, и, во-вторых, что она реализована на основе ВП прямого доступа. Использование СУБД обеспечивает лучшее управление данными, более совершенную организацию файлов и более простое обращение к ним по сравнению с обычными способами хранения информации. Вследствие более совершенных механизмов доступа БД, как правило, имеют более сложную организацию, чем обычные файлы, объединяя данные, ранее хранящиеся во многих отдельных файлах. Размер и сложность не являются определяющими характеристиками БД — наличие СУБД для ПК и даже в среде ряда пакетов (например, табличных процессоров, интегрированных и др.) приводит к созданию большого числа относительно простых и небольших БД, достоинством которых (при наличии соответствующих СУБД) являются простота определения и доступа к данным. Под банком данных (БнД) понимается система лингвистических, программных, аппаратных и организационных средств, основанная на БД-технологии и предназначенная для централизованного накопления и коллективного использования данных в той или иной прикладной области. Тогда как система обработки информации (СОИ) реализует автоматизированный сбор, обработку и хранение информации, включая соответствующие лингвистические, программные, аппаратные, организационные средства и обслуживающий их персонал.
Под целостностью БД понимается актуальное состояние ее данных, отражающих состояние некоторой реальной прикладной области и подчиняющихся правилам непротиворечивости. Под языком БД понимается один или совокупность языков, обеспечивающих описание данных, манипулирование с данными. Конкретный язык БД всегда ассоциируется с конкретной СУБД. СУБД представляет собой средства обработки на языке базы данных, позволяющие обрабатывать обращения к БД, поступающие от прикладных программ и/или конечных пользователей, и поддерживать целостность БД. Таким образом, СУБД имеет свойства, характерные как для компиляторов, так и для ОС, однако по сравнению с первыми обеспечивается более высокий уровень абстрагирования, что оказывается очень полезным как для программистов, так и для конечных пользователей.
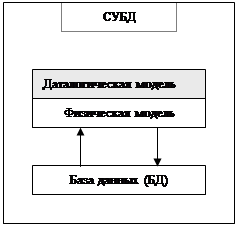
1.2. Иерархическая и сетевая даталогические модели СУБДКаждая БнД содержит и обрабатывает информацию из конкретной прикладной области, представляющей интерес для определенных приложений. Описание предметной области без акцента на ее последующие БнД-реализации определяет инфологическую модель предметной области (рис. 2). Инфологическая модель является исходной для построения даталогической модели БД и служит промежуточной моделью для специалистов предметной области (для которой создается БнД) и администратора БД в процессе проектирования и разработки конкретной БнД.
 | |||||
 | |||||
Рис. 2. Принципиальная организация СОИ на основе БД-технологии
Под даталогической понимается модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физической организации. При этом даталогическая модель разрабатывается с учетом конкретной реализации СУБД, также с учетом специфики конкретной предметной области на основе ее инфологической модели. Для конкретной реализации даталогической модели проектируется физическая модель (рис. 2), oтображающая первую на конкретные программные и аппаратные средства (ОС, внешняя память, работа с данными на физическом уровне и т.д.). Наполненная конкретной информацией физическая модель и составляет собственно БД. Система, обеспечивающая cоответствующее совместное функционирование указанных компонентов и составляет суть конкретной СУБД.
Современные СУБД допускают целый ряд классификаций в зависимости от уровня их рассмотрения (в целом либо по совокупности их функциональных характеристик): по интерфейсу с пользователем в зависимости от поддерживаемых моделей, по назначению и режиму функционирования, по способу обработки информации и т.д. Мы кратко остановимся на моделях даталогического уровня, который берется за основу большинства современных классификаций СУБД.
Обычно различают три класса СУБД, обеспечивающих работу иерархических, сетевых и реляционных моделей. Однако различия между этими классами постепенно стираются, причем, видимо, будут появляться другие классы, что вызывается прежде всего интенсивными работами в области баз знаний (БЗ) и объектно-ориентированной инфотехнологией, о которой будет идти речь ниже. Поэтому традиционной классификацией пользуются все реже, но мы пока будем придерживаться именно ее, как наиболее устоявшуюся. Каждая из указанных моделей обладает характеристиками, делающими ее наиболее удобной для конкретных приложений. Одно из основных различий этих моделей состоит в том, что для иерархических и сетевых СУБД их структура часто не может быть изменена после ввода данных, тогда как для реляционных СУБД структура может изменяться в любое время. С другой стороны, для больших БД, структура которых остается длительное время неизменной, и постоянно работающих с ними приложений с интенсивными потоками запросов на БД-обслуживание именно иерархические и сетевые СУБД могут оказаться наиболее эффективными решениями, ибо они могут обеспечивать более быстрый доступ к информации БД, чем реляционные СУБД.
Глава 2 Сетевые структуры
Если в отношении между данными порожденный элемент имеет более одного исходного элемента, то это отношение уже нельзя описать как древовидную или иерархическую структуру. Его описывают в виде сетевой структуры. Любая сетевая структура может быть приведена к более простому виду введением избыточности. «БД постоянно грозит опасность стать громоздкими, застывшими и слишком сложными системами. Новые приложения порождают новые виды запросов пользователей к базе, что увеличивает набор логических связей между ее элементами. В итоге многие системы БД оказываются очень сложными в построении и эксплуатации. Если разработчики не придумают ясные и простые схемы организации, эти системы будут подобны паутине» [К.Дейт.].
Сетевая модель более симметрична, чем иерархическая модель. Однако процедуры (обновления) значительно сложнее проблема состоит в следующем: всегда имеются две стратегии для определения места одного экземпляра записи, первая начинается с "владельца" и просмотра его цепочки для выбора звена, а другая начинается с "подчиненного звена" и просмотра его цепочки для выбора "владельца". Как пользователь может решить, какую стратегию принять? Выбор и здесь имеет большое значение. Как в иерархических, так и сетевых СУБД при описании данных обычно указываются характеристики записей каждого типа, способствующие более эффективному размещению данных во внешней памяти и более быстрому доступу к ним. К таким характеристикам относятся: размеры полей записи (минимальные, средние, максимальные), состав ключа, допустимый набор символов, интервалы значений и т.д.
Иерархические и сетевые базы данных часто называют базами данных с навигацией. Это название отражает технологию доступа к данным, используемую при написании обрабатывающих программ на языке манипулирования данными. При этом, очевидно, что доступ к данным по путям, не предусмотренным при создании базы данных, может потребовать неразумно большого времени. Повышая эффективность доступа к данным и сокращая таким образом время ответа на запрос, принцип навигации вместе с этим повышает и степень зависимости программ и данных. Обрабатывающие программы оказываются жестко привязанными к текущему состоянию структуры базы данных и должны быть переписаны при ее изменениях. Операции модификации и удаления данных требует переустановки указателей, а манипулирование данными остается записеориентированным. Кроме того, принцип навигации не позволяет существенно повышать уровень языка манипулирования данными, чтобы сделать его доступным пользователю-непрограммисту, или даже программисту-непрофессионалу. Для поиска записи-цели в иерархической или сетевой структуре программист должен вначале опеределить путь доступа, а затем просмотреть все записи, лежащие на этом пути, - шаг за шагом.
Насколько запутанной являются схемы представления иерархических и сетевых баз данных, настолько и трудоемким является проектирование конкретных прикладных систем на их основе. Как показывает, опыт длительные сроки разработки прикладных систем нередко приводят к тому, что они постоянно находятся в стадии разработки и доработки.
Указанные и некоторые другие проблемы, с которыми столкнулись разработчики и пользователи иерархических и сетевых систем послужили стимулом к созданию реляционной модели данных и реляционных СУБД.
2.1. Файловая модельКратко рассмотрим файловую модель, неправомерно относимую довольно часто к СУБД. Файловая модель представляет собой набор файлов данных определенной структуры, но связь между данными этих файлов отсутствует. Естественно, программные средства работы с таким образом организованной инфобазой могут устанавливать связь между данными ее файлов, но на концептуальном уровне файлы модели являются независимыми. Системы, обеспечивающие работу с файловыми инфобазами, называют системами управления файлами (СУФ) и они оказываются весьма эффективными во многих приложениях. СУФ используются на всех классах ЭВМ, но особенно они распространены для обработки информации на ПК. При этом во многих источниках они фигурируют в качестве СУБД. Файловые системы легко осваиваются, достаточно просты и эффективны в использовании и, как правило, для работы с ними используются простые языки запросов либо и вовсе ограничиваются набором программ-утилит. Такие системы обычно поддерживают работу с небольшим числом файлов, содержащих ограниченное число записей с небольшим количеством полей.
Иерархические модели СУБД имеют древовидную структуру, когда каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту (кроме S1-корневого) соответствует один входной и несколько выходных сегментов (рис. 3а). Каждый сегмент структуры лежит на единственном иерархическом пути, начинающемся от корневого сегмента.
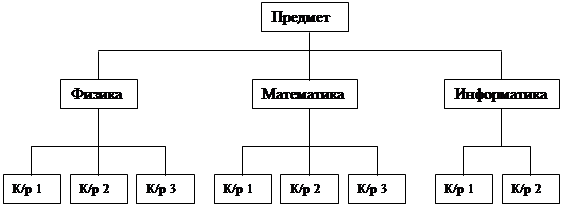
Рис. а)
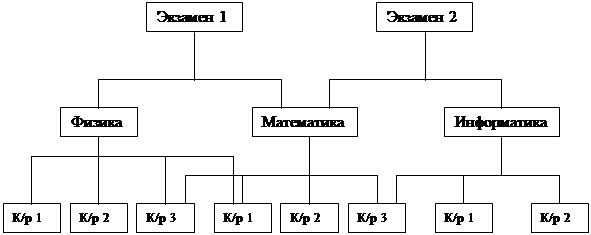
Рис. б)
Рис. 3. Структура иерархической (а) и сетевой (б) СУБД
Для описания такой логической организации данных ЯОД достаточно предусматривать для каждого сегмента данных только идентификацию входного для него сегмента. Так как в иерархической модели каждому входному сегменту данных соответствует N выходных, то такие модели весьма удобны для представления отношений типа 1:N в предметной области. Следует отметить, что в настоящее время не разрабатываются СУБД, поддерживающие на концептуальном уровне только иерархические модели. Как правило, использующие иерархический подход системы допускают связывание древовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым даталогическим моделям СУБД. К основным недостаткам иерархических моделей следует отнести: неэффективность реализации отношений типа N:N, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. В связи с этими недостатками ранее созданные иерархические СУБД подвергаются существенным модификациям, позволяющим поддерживать более сложные типы структур и, в первую очередь, сетевые и их модификации. Сетевая даталогическая модель СУБД во многом подобна иерархической: если в иерархической модели (рис. 3а) для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевой модели для сегментов допускается несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры. На рис. 3б представлен простой пример сетевой структуры, полученной на основе модификации иерархической структуры (рис. 3а). Графическое изображение структуры связей сегментов такого типа моделей представляет собой сеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД средствами ЯОД.
Таким образом, под сетевой СУБД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня. Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям. В рамках сетевых СУБД легко реализуются и иерархические даталогические модели. Сетевые СУБД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких СУБД ограничены связями, определенными для них разработчиками БД-приложений. Более того, подобно иерархическим сетевые СУБД предполагают разработку БД приложений опытными программистами и системными аналитиками.
Среди недостатков сетевых СУБД следует особо выделить проблему обеспечения сохранности информации в БД, решению которой уделяется повышенное внимание при проектировании сетевых БД.
Глава 3 Реляционные структурыРеляционный подход стал широко известен благодаря первым работам Е.Кодда, которые появились около 1970г. В течение долгого времени реляционный подход рассматривался как удобный формальный аппарат анализа баз данных, не имеющий практических перспектив, так как его реализация требовала слишком больших машинных ресурсов. Только с появлением персональных ЭВМ реляционные и близкие к ним системы неожиданно стали распространяться, практически не оставив места другим моделям. Один из самых естественных способов представления данных для пользователей - это двумерная таблица. Она привычна для пользователя, понятна и обозрима, ее легко запомнить. Поскольку любая сетевая структура может быть разложена в совокупность древовидных структур, то и любое представление данных может быть сведено к двумерным плоским файлам. Связи между данными могут быть представлены в форме двумерных таблиц.
Таблица обладает следующими свойствами:
Каждый элемент таблицы представляет собой один элемент данных. Повторяющиеся группы отсутствуют.
Все столбцы в таблице однородные. Это означает, что элементы столбца имеют одинаковую природу.
Столбцам присвоены уникальные имена.
В таблице нет двух одинаковых строк.
Порядок расположения строк и столбцов в таблице безразличен. Таблица такого рода называется отношением. База данных, построенная с помощью отношений, называется реляционной базой данных.
Чем же принципиально отличаются реляционные модели от сетевых и иерархических? Вкратце на это можно ответить следующим образом: иерархические и сетевые модели данных - имеют связь по структуре, а реляционные - имеют связь по значению. Проектирование баз данных традиционно считалось очень трудной задачей. Реляционная технология значительно упрощает эту задачу в трех различных направлениях:
Разделением логического и физического уровней системы она упрощает процесс отображения "уровня реального мира", в структуру, которую система может прямо поддерживать. Поскольку реляционная структура сама по себе концептуально проста, она позволяет реализовывать небольшие и/или простые (и поэтому легкие для создания) базы данных, такие как персональные, сама возможность реализации которых никогда даже бы не рассматривалась в старых более сложных системах.
Теория и дисциплина нормализации может помочь, показывая, что случается, если отношения не структурированы естественным образом.
Реляционная модель данных особенно удобна для использования в базах данных распределенной архитектуры - она позволяет получать доступ к любым информационным элементам, хранящимся в узлах сети ЭВМ. Необходимо обратить особое внимание на высокоуровневый аспект реляционного подхода, который состоит в множественной обработке записей. Благодаря этому значительно возрастает потенциал реляционного подхода, который не может быть достигнут при обработке по одной записи, и прежде всего это касается оптимизации. У системы управления базами данных появляется возможность влиять на эффективность реализации. В настоящее время на рынке программно-математического обеспечения для ПЭВМ представлено более сотни различных СУБД. Они сильно различаются по стоимости, по эффективности работы, по функциональной мощности, по сложности изучения и использования.
Наиболее широкое распространение получили СУБД, использующие реляционную модель данных, теоретической основой которой является логика предикатов первого порядка и теория отношений. Одной из важнейших характеристик как с точки зрения разработчика информационно-управляющих систем, так и их пользователей является быстродействие СУБД, в силу чего практически все фирмы мира-производители СУБД работают над проблемой увеличения реактивности. Большинство известных коммерческих СУБД страдают существенным недостатком : при работе с большими и сверхбольшими базами данных резко снижается время реакции системы при выполнении процедур поиска информации. Кроме того, появляющиеся в периодической печати результаты тестирования коммерческих СУБД не всегда позволяют сделать вывод об эффективности того или иного программного продукта, поскольку почти всегда оцениваемым по времени результатом поиска является первая найденная запись, а время ответа на сложные многоключевые запросы не оценивается, в то время как время поиска всех записей, удовлетворяющих некоторому критерию, линейно зависит от числа записей в базе, от числа записей-целей, от размеров записи, и, следовательно, для больших баз измеряется значительным интервалом времени.
Таким образом проведенный анализ систем управления базами данных, ориентированных на различные модели данных, позволяет сделать вывод: в распределенной интегрированной информационной системе возможно использование СУБД реляционного типа.
3.1. Реляционные даталогические модели СУБДСУБД реляционного типа являются наиболее распространенным на всех классах ЭВМ, а на ПК занимают доминирующее положение. Данная модель позволяет определять: (1) операции по запоминанию и поиску данных; (2) ограничения, связанные с обеспечением целостности данных. Для увеличения эффективности работы во многих СУБД реляционного типа приняты ограничения, соответствующие строгой реляционной модели.
Многие реляционные СУБД представляют файлы БД для пользователя в табличном формате — с записями в качестве строк и их полями в качестве столбцов. В табличном виде информация воспринимается значительно легче. Однако в БД на физическом уровне данные хранятся, как правило, в файлах, содержащих последовательности записей. Основным преимуществом реляционных СУБД является возможность связывания на основе определенных соотношений файлов БД. Со структурной точки зрения реляционные модели являются более простыми и однородными, чем иерархические и сетевые. В реляционной модели каждому объекту предметной области соответствует одно или более отношений. При необходимости определить связь между объектами явно, она выражается в виде отношения, в котором в качестве атрибутов присутствуют идентификаторы взаимосвязанных объектов. В реляционной модели объекты предметной области и связи между ними представляются одинаковыми информационными конструкциями, существенно упрощая саму модель.
СУБД считается реляционной при выполнении следующих двух условий, предложенных еще Э. Коддом : (1) поддерживает реляционную структуру данных и (2) реализует по крайней мере операции селекции, проекции и соединения отношений. В последующем был создан целый ряд реляционных СУБД, в той или иной мере отвечающих данному определению. Многие СУБД представляют собой существенные расширения реляционной модели, другие являются смешанными, поддерживая несколько даталогических моделей.
Суть реляционной СУБД можно пояснить на следующем простом примере (рис. 4).
| Файл авторов публикаций БД | ||||
| № п/п | Автор | Адрес | Телефон | Число публ. |
| … | … | … | … | |
| 6 | Купцов | Москва | 635-6078 | 140 |
| 7 | Бухтяк | Томск | 637-2050 | 140 |
| 8 | Терпугов | Томск | 538-584 | 250 |
| Файл публикаций РБД | ||||
| № п/п | Назв. Публикации | Тип публ. | Дата | Объём в п. л. |
| 6 | Основы … | Статья | 2.95 | 2.5 |
| 7 | Проблема … | Книга | 3.97 | 35 |
| 8 | Теория … | Статья | 6.96 | 3.8 |
| … | … | … | … | |
Рис. 4 Простой пример, иллюстрирующий принцип реляционной модели
В некоторой реляционной БД (РБД) имеются два файла авторов и публикаций, каждый из которых содержит определенное число записей/ состоящих из фиксированного числа полей (соответственно 4 и 5), представляющих данные по соответствующим элементам предметной области (рис. 4). Можно сказать, что определены два отношения (фaйла), имеющие общий элемент — значения поля № п/п. Операции реляцианной алгебры могут объединять два типа записей по этому общему элементу. Например, в результате соединения запись Бухтяк может представится в следующем виде:
Бухтяк<Томск><637-2050><40><Основы...><статья><2.95><2.5>....
т.е. к сведениям об авторе добавляются сведения обо всех его публикациях, имеющихся в РБД. Связь между записями допускается по нескольким полям, позволяя образовывать достаточно сложные операции. Поля данных, связывающие вместе две записи, могут быть уникальными для данной пары, но могут дублироваться и во многих других записях. Они могут повторяться неоднократно, связывая между собой записи. Аналогичным образом можно проиллюстрировать выполнение в реляционной модели операций проекции и селекции.
Реляционная СУБД должна четко отслеживать взаимосвязи записей в БД во избежание потери или искажения информации. С этой целью СУБД постоянно пересчитывает число связей для каждой записи БД в прямом и обратном направлениях, что требует существенных временных затрат для больших БД. Простота и стройность реляционной алгебры делают ее весьма привлекательной для организации реляционных БД, что мы и видим, прежде всего, для класса ПК. Однако в действительности реальные данные предметной области не укладываются в указанную модель (например, отношения могут содержать повторяющиеся записи и т.д.). Поэтому наряду с сугубо реляционными существуют и другие даталогические модели СУБД и их различные модификации и сочетания, обеспечивая широкий круг решаемых на их основе информационных, коммерческих, управленческих, финансовых, вычислительных и других типов задач. Из наиболее известных примеров реляционных СУБД можно отметить такие, как: dBase, DB/2, ORACLE, Paradox и ряд других.
Массовое развитие класса ПК оказало весьма существенное влияние на развитие инфотехнологии и БД-технологии в частности, привнося элементы последней в массовую инфотехнологию. Прежде всего, этому способствовало развитие мощной индустрии по созданию разнообразных СУБД для ПК. Если создание СУБД для ЭВМ общего назначения и (в значительной мере) мини-ЭВМ занимало длительный промежуток времени и число таких коммерческих СУБД было невелико — практически весь их перечень был на слуху у специалистов по компьютерной инфотехнологии, то с появлением класса ПК наряду с мощным развитием для них ПС различного назначения начали быстро появляться СУБД. При этом БД-технология начала активно проникать и в ПС другого назначения (электронные таблицы, интегрированные и статистические пакеты и т.д.). К БД-технологии были приобщены широкие круги пользователей ПК. Во многих разработках для ПК начали применяться собственные СУБД различных организации и назначения. На наш взгляд, ряд причин способствовал такому массовому использованию БД-технологии:
— массовое использование ПК в приложениях, предопределяющих работу с БД;
— резкое уменьшение цикла разработки ПС из-за персонального характера работы;
— наличие достаточно развитых системных и инструментальных средств;
— наличие внешней памяти большой емкости на "винчестерах".
Эти и другие причины обеспечили как широкий спрос на СУБД для ПК, так и хорошие предпосылки для его быстрого удовлетворения. Наряду с мощными фирмами, специализирующимися на разработке коммерческих СУБД к разработкам и/или адаптации уже готовых СУБД для ПК приступили и крупные фирмы, ранее ориентированные в этой области на приложения к ЭВМ других классов (Oracle, IBM, Relational Technology и др.). Все это способствовало интенсивному проникновению БД-технологии в массовую инфообработку. С другой стороны, широкое использование ПК в весьма обширном спектре прикладных областей способствовало выдвижению к СУБД целого ряда актуальных требований и, в первую очередь, по повышению уровня интерфейсов с пользователем и другими приложениями.
Разработанное в настоящее время большое число различного назначения СУБД позволяет создавать и эксплуатировать системы БД на всех классах и типах ЭВМ, поддерживая различные даталогические модели и обеспечивая нужды широкого круга приложений
Средства современных СУБД настолько разнообразны, что способны удовлетворить потребности самого широкого круга пользователей — от профессионала в области разработки систем БД различных типа и назначения до пользователя, не обладающего достаточным уровнем компьютерной грамотности. В первую очередь, это относится к СУБД, созданным для класса ПК. Эти СУБД характеризуются не только своим количеством, но и функциональным разнообразием: от простых файловых систем до функционально полных СУБД, в основном реляционного типа. Многие из коммерческих СУБД поддерживают многопользовательскую работу и работу в сетях ЭВМ, как локальных, так и глобальных. К средствам, непосредственно относящимся к СУБД, можно отнести и многочисленные средства их окружения: генераторы и конверторы данных и программ, компиляторы языков программирования БД-приложений, генераторы создания различного назначения и уровня интерфейсов с БД в рамках традиционных ЯВУ и т.д.
Такое многообразие инструментальных и прикладных средств по СУБД позволяет выбирать наиболее адекватные нуждам пользователя, обеспечивая эффективное использование вычислительных ресурсов и существенное сокращение сроков разработки конкретных БД-технологий. В подавляющем большинстве СУБД для ПК ориентированы на интерактивный режим работы с пользователем, широко используя удобные и дружелюбные системы интерфейсов на основе простых и понятных меню. В СУБД, поддерживающих языки программирования БД-приложений, средства такого интерфейса избавляют пользователя от необходимости знания синтаксиса языка для обеспечения требуемых функций. Ряд популярных СУБД предусматривают несколько уровней интерфейса, обеспечивающих работу с ними различной квалификации пользователей (dBase IV, Paradox, др.). Большое внимание уделено эффективной системе Help-информации по СУБД, включающей электронные краткие обучающие курсы с демонстрацией наиболее часто используемых приемов работы с конкретным пакетом.
Интенсивное расширение компьютерной инфотехнологии ставит перед дальнейшим развитием СУБД целый ряд новых требований, во многом связанных с вопросами стандартизации. Это относится не только к СУБД, но и к ПС других типов. В отношении же СУБД это прежде всего относится к стандартизации эталонной модели управления данными, предусматривающей четкую классификацию основных вопросов стандартизации СУБД в зависимости от функциональных особенностей и уровня описания данных на разных стадиях проектирования. Можно предполагать, что последующее развитие СУБД будет ориентироваться на рекомендации международных стандартов относительно языков БД и средств доступа к удаленным БД, а также интерфейсов с системами программирования. Новые интересные аспекты БД-технологии появляются на основе объектно-ориентированной технологии программирования и обработки информации.
3.2. Объектно-ориентированные СУБД (ООСУБД)В настоящем параграфе рассматриваются основные концепции, понятия, черты и характеристики объектно-ориентированных систем управления БД (ООСУБД) в контексте рассмотренных объектно-ориентированных программирования и технологии. В последние годы в результате проникновения идеологии ООП в СУБД интенсивные разработки теоретического и прикладного характера ведутся по созданию различного назначения ООСУБД. Ввиду не совсем устоявшейся в этом направлении терминологии отметим основные черты и характеристики, определяющие СУБД как объектно-ориентированную. При этом по мере необходимости проводятся сопоставления с рассмотренной выше концепцией ООП.
Характеристики ООСУБД подразделяются на три определяющие группы:
— базовые, определяющие принадлежность СУБД к объектно-ориентированному классу;
— по выбору, позволяющие улучшать ООСУБД, но не являющиеся базовыми;
— открытости, позволяющие пользователю делать осознанный выбор из ряда одинаково приемлемых реализаций ООСУБД.
В первую очередь, ООСУБД должна удовлетворять двум критериям: быть СУБД в ее классическом понимании и быть объектно-ориентированной системой (ООС), т.е. в определенной степени она должна быть совместимой с современными объектно-ориентированными ЯВУ. Первый критерий включает следующие пять характеристик, присущих классической СУБД: сохранность данных, развитое управление внешней памятью, возможность совмещения обработки и поиска данных, поддержка средств восстановления и возможность быстрого доступа к БД по запросу пользователя. Отмеченные характеристики в той или иной мере обсуждались выше. Второй критерий предполагает наличие следующих характеристик, присущих собственно объектно - ориентированной технологии: понятие сложных объектов, идентичность объектов, инкапсуляция, типы или классы, наследование, настройка (сочетающаяся с отложенным присвоением), расширяемость и вычислительная полнота. Характеристики первого критерия хорошо известны пользователям традиционных СУБД (dBase, R-Base, др.)
Сложные объекты строятся из более простых путем применения к ним конструкторов. В качестве простых используются такие объекты. как: целые и действительные числа, символы, символьные строки любой длины, булевы величины и, возможно, другие первичные типы. В качестве конструкторов сложных объектов (объектных конструкторов) могут выступать: кортежи, множества, списки, массивы, таблицы и др. В качестве минимального набора объектных конструкторов от ОООСУБД определяются: множество, кортеж, список или массив. Множество дает естественную возможность представления определенного набора объектов из имеющейся обширной совокупности; тогда как кортеж позволяет представлять определенные свойства объекта. При этом кортежи и множества имеют особое значение, получив широкое применение в качестве объектных конструкторов в реляционных БД (РБД) Список или массив играют важную роль при установлении порядка среди элементов множества. Более того, указанные типы объектных конструкторов играют важную роль во многих приложениях (векторно-матричные задачи, задачи анализа временных рядов и др.).
Объектные конструкторы должны удовлетворять принципу ортогональности: любой конструктор может применяться к любому объекту. Например, конструкторы РБД не обладают данным свойством (так конструктор множества может применяться только к кортежам, а конструктор кортежей — только к первичным типам).
Глава 4 Иерархические стpуктуpы
Дерево представляет собой иерархию элементов, называемую узлами. На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемым исходным узлом для данного узла. Ни один элемент не имеет более одного исходного. Каждый элемент может быть связан с одним или нескольким элементами на более низком уровне. Они называются порожденными. Иерархические структуры относительно просто создаются и поддерживаются. Это важно для ряда приложений, однако множество данных по своей природе не связаны в древовидные структуры. Во многих структурах данных одна запись требует более одного представления (поэтому приходится разрабатывать способы объединения данных, которые по разному представляются различным пользователям, в одну общую схему БД. В результате получаются обычно более сложные структуры по сравнению с древовидными. Поэтому программное обеспечение, сконструированное только для работы с древовидными структурами, имеет ограниченное применение и не редко сильно влияет на возможности увеличения объема и развития БД.
Принципиальным для иерархического представления данных является то, что каждый экземпляр записи приобретает свой смысл только тогда, когда он рассматривается в своем контексте; подчиненный экземпляр записи не может существовать без своего предшественника по иерархии (несимметричность или асимметрия). Асимметрия - основной недостаток иерархического подхода, поскольку она затрудняет работу пользователя. В частности, пользователь вынужден тратить время и усилия на решение проблем, связанных со спецификой модели и никак не следующих из характера задаваемых вопросов. Очевидно, что такие проблемы усугубляются по мере увеличения числа типов записей, представленных в структуре, и по мере роста сложности иерархии. Кроме того, иерархическая модель обладает еще некоторыми нежелательными свойствами аномалии, которые ярко проявляются в связи с выполнением каждой из основных операций запоминания (добавление, удаление, модификация).
Длительный опыт использования иерархических систем показал, что они весьма эффективны лишь для достаточно простых задач, но они практически не пригодны для использования в сложных системах с оперативной обработкой транзакций и распределенной архитектурой. Иерархическая организация не может обеспечить быстродействие, необходимое для работы в условиях одновременного модифицирования файлов несколькими прикладными подсистемами.
4.1. Иерархические структуры в реляционных базах данныхОкружающий мир переполнен иерархическими данными. В это широкое понятие входят компании, состоящие из дочерних компаний, филиалов, отделов и рабочих групп; детали из которых собираются узлы, входящие затем в механизмы; специальности, специализации и рабочие навыки; начальники и подчинённые и т. д. Любая группа объектов, в которой один объект может быть «родителем» для произвольного числа других объектов, организована в виде иерархического дерева. Очевидным примером может послужить иерархия объектов VCL- класс TEdit представляет частный случай TСontrol, потому что TСontrol является его предком. С другой стороны, TEdit можно рассматривать и как потомка TWinControl или TCustomControl, потому что эти классы являются промежуточными уровнями иерархии VCL.
Подобные связи не имеют интуитивного представления в рамках модели реляционных баз данных. Нередко иерархические связи являются рекурсивными (поскольку любая запись может принадлежать любой записи) и произвольными (любая запись может принадлежать другой записи независимо от того, кому принадлежит последняя). В двумерной таблице даже отображение иерархического дерева становится непростым делом, не говоря уже о запросах. Иногда в критерий запроса входит родословная объекта (то есть его родители, родители его родителей и т д.) или его потомство (сюда входят дочерние объекты и всё их потомство).
4.2. Вложенные рекурсивные иерархические данныеТермин «рекурсивные иерархические данные» означает, что базовые и подчинённые данные находятся в одной таблице: одно не ключевое поле записи содержит ключевое значение другой записи, и это означает, что вторая запись принадлежит первой. Не ключевое поле называется внешним ключом, даже если по нему устанавливается связь с другим полем этой же таблицы. Дочерние, подчинённые записи не знают, является ли их базовая запись подчинённой для какой-то другой записи - для них это несущественно. Каждый уровень обладает своим набором базовых и подчинённых записей, и при «раскрытии» конкретной подчинённой записи изменяются только конкретные отображаемые данные.
4.3. Отображение данныхПеремещение вверх и вниз по иерархическому дереву неизбежны, однако вы можете воспользоваться средствами, которые автоматизируют эту задачу. Подумайте, как пользователи будут работать с данными. Возможно, их вообще не интересует иерархическая структура данных, но они захотят искать объект по его предку. Или они будут искать объект по тому имени, которым он представлен в иерархии, или только среди потомков текущего объекта. Возможно, им потребуется узнать только идентификатор найденного объекта или же получить список всех его потомков или предков.
В частности, вам придётся решить основной вопрос – что делать, когда пользователь требует вывести «следующий» объект? Таким объектом может быть: следующий потомок родителя текущего объекта; первый потомок текущего объекта; следующий родитель, если текущий объект является единственным потомком, или даже первый потомок следующего «родственника» (sibling). В визуальном интерфейсе интуитивные ожидания пользователя основаны на положении текущего объекта в иерархии, способе его отображения и действиях самого пользователя, а не только на логическом протоколе, определяемом абстрактной структурой данных приложения.
Помимо компонента TDBGrid, очевидным кандидатом для отображения иерархических данных являются компонент TTreeView. Этот компонент были создан специально для отображения древовидных структур, а не традиционных линейных списков. Он может занимать довольно большую область экрана, поэтому не стоит применять его везде, где пользователь должен выбрать объект иерархии. Кроме того, при работе с этим компонентом желательно загружать в память всю структуру. Компонент можно настроить так, чтобы «ветки» загружались по мере надобности, однако такая гибкость достигается ценой снижения производительности.
Целостность структуры и циклические ссылки
По иронии судьбы рекурсивная иерархия в одной таблице заметно упрощает обеспечение целостности структуры: одно поле таблицы ссылается на другое, принадлежащее этой же таблице. При этом защищаются все потомки объекта. Если же объединяющие значения находятся в нескольких полях или таблицах, в результате чего становится возможной многоуровневая группировка или установка сложных связей, обеспечить целостность структуры будет сложнее
Для программы, работающей с иерархией, наибольшую опасность представляют циклические ссылки. Если объект ссылается на несуществующего родителя, проблему можно заметить и исправить. Но, если родитель объекта оказывается одновременно и его потомком (если объекты разделены несколькими промежуточными поколениями, такую ситуацию будет нелегко обнаружить), программа зацикливается.
Где же выход? Можно проверять каждого «кандидата в предки» и смотреть, не присутствует ли какие-либо из его предков в текущем «семействе» (правда, это будет накладно с точки зрения производительности). Кроме того, в программу можно вставить счётчик-предохранитель, который инициирует исключение после определённого количества циклов поиска. Одно из преимуществ графических иерархических элементов как раз и заключается в том, что пользователь просто не сможет создать циклическую ссылку, так как это противоречит логике работы с элементом.
При работе с иерархиями используется «семейная» терминология (родители, внуки, предки, потомки), поскольку семья является самым распространённым примером объектов (в данном случае – людей), объединённых иерархическими отношениями. Этот пример напомнит вам одну простую истину – хотя вы можете построить систему, предназначенную для обобщённой обработки рекурсивных иерархий, ценность каждого объекта определяется той уникальной информацией, которая в нём хранится. В то же время место объекта в иерархическом дереве - не более чем условное обозначение связи с другими объектами. Иерархическая структура всего лишь помогает сохранить и найти объект.
Глава 5 OLE: основные сведенияСпецифика предметов математики, физики, программирования такова, что контрольные работы, зачёты, проверочные требуют наличия графиков, формул, диаграмм. Поэтому возникает проблема отображения данных. Достаточно трудно написать такую универсальную программу, которая справилась бы с этим. С другой стороны, в Windows 95 содержится много программ, которые позволяют это сделать, например Word.
Существование операционной системы Windows 95 и реализация в ней очень мощного механизма под названием OLE, позволяет решить эту проблему достаточно просто.
5.1. Введение в OLEWindows поддерживает сложный, но чрезвычайно перспективный механизм взаимодействия программ, который называется OLE. Этот механизм широко используется во многих программных продуктах корпорации Microsoft, в том числе в текстовом редакторе Word и таблице Excel. В результате, в документ, подготовленный, например, с помощью Word, можно внедрить график, созданный в Excel. Если в процессе работы над документом возникнет необходимость в редактировании графика, достаточно дважды щелкнуть не нем мышью — Windows откроет Excel и передаст таблице данные, позволяющие изменить график средствами программы, его создавшей. После завершения работы Excel измененный график будет переписан в исходный документ Word.
Последовательное использование OLE смещает акцент в работе пользователя от программы-обработчика информации к конечному документу. Без OLE пользователь вынужден разрабатывать конечный документ по частям. Например, при подготовке рукописи книги к публикации рисунки могут изготавливаться с помощью Paint или CorelDraw, в то время как текст — с помощью Word или WordPerfect, после этого для верстки используется Ventura Xerox Publisher или PageMaker. В этой технологии обрабатывающие программы никак не связаны друг с другом и пользователь должен самостоятельно решать проблемы совместимости форматов данных, передаваемых от одного приложения другому. Применение OLE позволяет рассматривать документ в виде единого стержня, на который «нанизаны» программы-обработчики типа Paint или Word. Пользователь полностью освобожден от необходимости следить за форматами данных и согласовывать их, а переход от одной программы к другой реализуется двойным щелчком мыши.
5.2. Связывания и внедрение объектовПри использовании OLE отдельные объекты (рисунки, графики, текстовые фрагменты, таблицы) могут быть связаны с документом или внедрены в него. Если объект связан с документом, в последнем сохраняется лишь минимально необходимая информация, позволяющая вызвать в нужный момент программу, с помощью которой был создан объект, например, для его печати на принтере или редактировании. Если объект внедрен в документ, он подвергается переработке клиентом перед вставкой в документ и становится во многом независимым от «родной» программы. Например, Word может получить электронную таблицу от Excel, при этом численные данные и формулы преобразуются в текстовые эквиваленты и в таком виде внедряются в документ. Однако связь с программой-обработчиком сохраняется и в этом случае, поэтому пользователь может в любой момент загрузить обрабатывающую программу для редактирования внедренного объекта.
С объектами или заменяющими их пиктограммами связаны действия, которые может произвести двойной щелчок мыши. Над объектами определены два основных действия - отображение и редактирование. При этом над связанным объектом первичным действием будет отображение, а над внедренным - редактирование. Первичное действие обычно связывается с двойным щелчком мыши на пиктограмме упакованного объекта. Некоторые объекты позволяют выбирать первичное действие, для чего они создают соответствующие диалоговые окна. Другое объекты допускают только одно действие. Например, объект, созданный текстовым редактором и внедренный в графику, как правило, поддерживает только редактирование, а звуковые данные после внедрения их в текст поддерживают только отображение (воспроизведение).
Технология связывания и внедрения объектов OLE позволяет создать некоторый объект, например рисунок или звуковой файл, в одном из Windows-приложений и затем вставить его в другой файл. Этот объект может быть либо связанным, в этом случае он существует фактически в отдельном файле, либо внедрённым, и тогда он находится внутри основного файла. Другими словами, данные, картинки, текст и иные объекты, которые вы создаете в разных приложениях, могут быть объединены в один составной документ, который сохраняет связи со всеми исходными приложениями.
Этот составной документ управляется каким-нибудь одним приложением, например Excel или Word для Windows, а связи обеспечивают пути к другим приложениям так, чтобы вы могли редактировать свои объекты, используя приложения, в которых они были созданы.
Таким образом, при правильном применении характеристика OLE позволяет вам централизовать всю свою работу в пределах одного доминирующего приложения и в одном документе, называемом клиентом. Если вам понадобятся какие-либо данные, графика или другая информация, которая находится в других приложениях, вы сможете, оставаясь в своем приложении-клиенте, присоединять, привязывать их из соответствующих приложений, называемых в этом случае приложениями - серверами.
Если вам требуется отредактировать текст, данные или графику, созданные в приложении-сервере, то это можно сделать из документа-клиента с помощью, как правило, двойного щелчка на объекте, подлежащем редактированию. При этом Windows открывает приложение-сервер и ассоциированный с ним объект. После внесения редакторской правки вы просто выходите из приложения-сервера и автоматически возвращаетесь в приложение-клиент и документ, над которым работаете.
5.3. Различие между связыванием и внедрением объектовВ самом общем смысле, связь понимается как соединение, которое позволяет некоторому документу (клиенту) одного Windows-приложения сообщаться с другим Windows-приложением (сервером). Термин "клиент" почти всегда относится к документу, не к приложению. Термин же "сервер" может относиться и к приложению и к документу, а также к тому и другому вместе. Эта терминологическая неопределенность происходит от способа, которым Windows формирует связи.
Исходный документ — это просто файл, который используется для копирования данных, текста или графики в буфер переноса, так что появляется возможность привязывать или внедрять содержимое буфера в другой документ (клиент). Однако действительная связь, возникающая при этом, представляет собой связь между документом-клиентом и приложением-сервером. Эта связь обеспечивает документу-клиенту возможность знать, каким приложением был создан объект и как запускать это приложение-сервер. Здесь мы имеем дело с внедрённым объектом.
В некоторых случаях (в частности, для связывания объектов) создаются еще две связи — между документом-клиентом и исходным документом и между документом-клиентом и объектом в исходном документе, который был скопирован и приклеен. Исходный документ часто называют документом-сервером, поскольку он всегда управляется приложением сервером и обеспечивает данными связанный объект. При существовании этих дополнительных связей изменение данных в исходном объекте автоматически отражается в объекте клиента.
Итак, различие между связанным и внедрённым объектами определяется следующими признаками:
Связанный объект обычно хранит только дескрипторы, которые говорят этому объекту, где найти приложение-сервер, документ-сервер и связанный элемент в документе-сервере (здесь используется слово "элемент" для обозначения области документа, которая копировалась из исходного документа в буфер переноса, а слово "объект" — для зоны в документе-клиенте, которая содержит связанный элемент.) Приложение-сервер затем модернизирует документ-клиент всякий раз, когда изменяется информация в документе-сервере. В некоторых приложениях документы-клиенты сохраняют также последнюю связанную информацию при выходе из документа.
Внедрённый объект представляет собой полномасштабную версию припасенного элемента: он содержит все данные, текст и графику, которые были приклеены из буфера переноса с целью создания этого объекта. Внедрённый объект содержит также связь с приложением-сервером, которая при двойном щелчке на объекте в документе-клиенте позволяет запустить приложение-сервер и затем отредактировать этот объект средствами приложения-сервера.
Глава 6 Достоинства и недостатки тестовой системы или методическое обоснование автоматизации процесса обучения
Одной из форм привлечения преподавателей к использованию компьютера являются тестирующие программы, которые позволяют упростить проверку знаний учащихся и в то же время в увлекательной форме преподносят ученикам знания по той или иной дисциплине.
Возможны три формы организации тестов, которые условно можно назвать «выбери ответ из предлагаемых вариантов», «напиши правильный ответ», «найди связь между объектами».
Организация теста по принципу «выбери ответ из предлагаемых вариантов» обеспечивает относительно простой диалог с тестируемым и, как следствие, быстроту прохождения теста, так как не требует от учащегося особых навыков работы на компьютере. Для выбора ответа достаточно нажать на клавиатуре соответствующую клавишу или щёлкнуть мышью на окне, выбрав его среди предложенных. Такая простота выбора ответа не отвлекает учащегося от предметной сути поставленного перед ним вопроса. Преимущество такой организации тестирующей программы заключается ещё и в простом критерии правильности ответа, данного учащимся. Однако такая организация теста имеет и недостаток наличие «скрытой» подсказки на вопрос – выбирать ответ гораздо легче, чем писать его полностью самостоятельно.
Организация теста по принципу «напиши правильный ответ», предполагает хорошую начальную подготовку учащегося как пользователя персонального компьютера. Решение технических проблем может отвлечь учащегося от предметной сути работы с программой. Кроме того, предполагается абсолютная грамотность при выдаче ответа. Таким образом, скорость прохождения теста во многом зависит от развития навыков работы за компьютером. Помимо этого, ответ на каждый вопрос теста может иметь различную степень подробности. Для многих предметов предусмотренных программой выбор критерия оценки правильности ответа при такой организации теста очень затруднителен, так как требуется решать такие вопросы, как учитывать степень развёрнутости ответа, грамотность и т. п.
Из вышеизложенного следует, что для тестирующей программы наиболее подходит организация по принципу «выбери правильный ответ из предлагаемых».
Программа должна:
1. Объяснять тестируемому правила работы;
2. Тестировать учащегося и выставлять ему оценку по окончании тестирования;
3. Допускать завершение тестирования при любом количестве пройденных вопросов с выставлением оценки по фактическому количеству ответов.
Необходимые для тестирования данные должны быть защищены. Иметь возможность ограничить время проведения теста.
Требования, описанные выше, реализованы в системе TEST. Система TEST позволяет автоматизировать проведение контрольных срезов, работ, зачётов по любым дисциплинам. Система состоит из трёх связанных между собой частей. Первая часть это программа- редактор вопросов, позволяющая преподавателю создавать индивидуальную базу данных вопросов по своим дисциплинам. Вторая часть представляет собой тестирующую программу, предназначенную для студентов. Третья часть предназначена для преподавателя, представляет собой статистику прохождения теста, с помощью этой программы преподаватель может проанализировать результаты прохождения теста и сделать соответствующие выводы, а также настроить основные параметры теста.
Преподаватель может полностью отказаться от проведения письменных контрольных работ: оценки, полученные студентами на письменных контрольных работах, выше оценок, выставляемых системой. Преподаватель может вносить любые изменения, которые будут храниться в базе данных, также он может контролировать проведение теста: просматривать данные студентов, даты проведения, оценки. Результаты теста преподаватель анализирует и подводит итог.
В процессе выполнения контрольной работы универсальность работы на компьютере позволила студентам не ждать остальных и реализовывать свои возможности в большей степени. В работах такого характера студенты самостоятельно занимаются исследовательской деятельностью, что значительно укрепляет полученные знания. Начиная своё маленькое компьютерное исследование с простейших экспериментов, студент постепенно обучается работе с моделями и в дальнейшем способен перейти к более сложным этапам – компьютерному контролю и анализу реального эксперимента. Исключает возможность коллективных ответов на вопросы. Это удобное добавление к традиционным методам контроля, повышается эффективность усвоения предмета студентом.
5.1. Межпредметные связи и компьютерное обучениеОдной из наиболее важных общеобразовательных целей информатики является наведение и усиление межпредметных связей, способствование восприятию целостной, системной картины мира, информационных процессов в обществе, природе и познании.
Электроника и вычислительная техника (ВТ) становятся компонентами содержания обучения различным предметам, средствами оптимизации и повышения эффективности научного процесса. Для разумного и плодотворного использования ВТ необходима общеобразовательная и компьютерная грамотность. Отсюда выявляется межпредметная связь с основами информатики и ВТ, с математикой, русским языком, литературой и английским языком. ВТ для учителя выступает и как предмет, и как средство обучения, и как инструмент психолого-педагогических исследований (тестирования). Умение использовать ВТ становится одним из профессионально необходимых качеств учителя, и если рассматривать процесс компьютеризации обучения как одну из наиболее современных тенденций методики преподавания предметов, то владение принципами и методикой компьютерного обучения должно стать современным требованием квалификационной характеристики преподавателя. ВТ находит широкое применение в преподавании не только как средство, ускоряющее вычисления, но и как средство, моделирующее математическими методами физические процессы и явления, как современное средство наглядности в сочетании её абстрактно-логической стороны с предметно-образной, как средство математической обработки результатов демонстрационного эксперимента и лабораторных работ, контроля и самоконтроля знаний студентов. Компьютерное обучение должно рассматриваться вместе с другими методами и средствами, как компонент электронного обучения в целом. Вся совокупность компонентов компьютерной грамотности учителя позволяет ему не только использовать компьютерную технику на практике по предмету, но и формировать и совершенствовать образовательные основы программирования и знаний ВТ студентов в системе межпредметных связей.
Программы для обработки результатов, которые используют только вычислительные возможности ЭВМ и носят вспомогательный характер, не преследуя педагогических целей. Они позволяют использовать статистический анализ данных измерений. Внедрение ВТ в учебный процесс должно носить системно-функциональный характер, который предполагает установление фундаментальный идей, связывающих в единую систему структурные элементы каждой науки, и их преобразование в курсах предметов с обязательным учётом психолого-педагогических возможностей учащихся на данном этапе обучения.
Глава 7 Разработка тестирующей программыВ моей работе были применены вложенные рекурсивные иерархические данные для отображения предметов, тем и вопросов хранящихся в базе данных. Это означает, что базовые и подчинённые данные хранятся в одной таблице «Data». С помощью компонента TTreeView удобно организовано представление в виде иерархического дерева, что соответствует логике решаемой задачи. Таблица реляционного типа отображает наши данные в виде иерархии. В таблице первое поле ключевое, в нём название тем-родителей: «Механика», «Кинематика», «Кинематика материальной точки», «Физика», «Зачет по механике». Второе поле является подчиненным для первого: раздел «Кинематика материальной точки» содержит Вопрос 1-4.
| Key_Id | Key_Parent | Поле строкового типа |
| 0 | 15 | Механика |
| 2 | 0 | Кинематика |
| 3 | 0 | Динамика |
| 23 | 2 | Кинематика материальной точки |
| 24 | 23 | Вопрос 1 |
| 26 | 23 | Вопрос 2 |
| 27 | 23 | Вопрос 3 |
| 28 | 23 | Вопрос 4 |
| 30 | 30 | Физика |
| 31 | 30 | Зачёт по механике |
| 32 | 31 | Вопрос 1 |
| 33 | 31 | Вопрос 2 |
| 34 | 31 | Вопрос 3 |
| 35 | 31 | Вопрос 4 |
| 36 | 31 | Вопрос 5 |
| 37 | 31 | Вопрос 6 |
На основе таблицы строится иерархия такого типа.
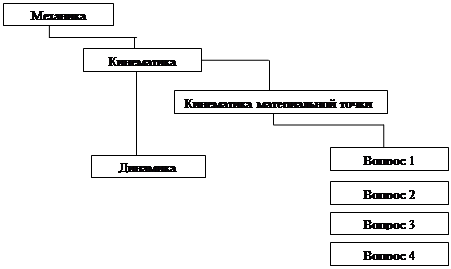
Также база данных содержит следующие таблицы:
Таблица «Факультет» содержит поле название факультета.
| Название |
| ФИЯ |
| ФМИ |
Таблица «Группа» содержит поле номер группы.
| Номер |
| 455 |
| 465 |
| 475 |
| 485 |
Таблица «Статистика» содержит данные о прохождении теста.
| № п/п | Название темы | Дата | Оценка |
| 1 | Кинематика материальной точки | 27.03.99 | 4 |
| 2 | Электродинамика | 12.05.99 | 3 |
| 3 | Механика | 13.05.99 | 2 |
Таблица «Данные студента» - при регистрации данные заносятся в эту таблицу.
| № п/п | Фамилия | Группа | Факультет |
| 1 | Иванов | 455 | ФМИ |
| 2 | Петров | 485 | ФИЯ |
| 3 | Ельцин | 465 | ФМИ |
Таким образом база данных состоит из пяти таблиц.
При решении задачи возникли следующие проблемы:
1. Эффективное хранение информации в базе данных.
Особенность базы в том, что она состоит из полей типа binary, содержащие графические изображения, поэтому при небольшом объёме хранимой информации размер базы становится слишком большим. Хранение информации в стандартном формате bmp оказывается крайне неэффективным. Исследовав большинство распространённых графических форматов jpc, gif, tiff, я пришла к выводу, что наиболее оптимальным с точки зрения сохранения количества сжатия является формат gif. В этом формате и решено было сохранять изображения в базе данных.
Стандартные компоненты Delphi не позволяют хранить графическую информацию в базе данных в формате gif, в связи с этим были использованы продукты компании SkyLine. В своей работе я использовала библиотеку компонентов Image Lib 30 в составе которой есть компоненты, позволяющие хранить информацию в базе данных самых различных форматов.
2. Модификация стандартного компонента Delphi OleContainer.
Так как реализация этого компонента не позволяла сохранять изображения, полученные от программы сервера, был реализован собственный OleContainer расширением стандартного компонента. Свойство Bitmap:TBitmap, которое при перерисовке компонента, копирует на свою канву, канву стандартного компонента OleContainer. Таким образом, с помощью свойства Bitmap, в программе можно использовать изображение OLE-контейнера, который затем и помещается в базу в формате gif.
ЗаключениеИтогом написания дипломной работы явилось создание программного продукта «Системы автоматизированного контроля знаний студентов».
Были решены следующие поставленные передо мной задачи:
– дан обзор современному состоянию теории баз данных, основным моделям СУБД, применяемым в ПК;
– изучены принципы функционирования и основные возможности технологии OLE;
– разработан способ отображения реляционных структур данных в иерархическом виде;
– дополнен стандартный компонент Delphi OLEContainer возможностью сохранения битового изображения на его поверхности.
Программа контроля знаний TEST, которая рассматривалась в 5 главе, работает под управлением операционной системы Windows 95. Справочная система позволит легко и быстро научится работать с системой TEST.
Это удобное добавление к традиционным методам контроля, повышающее эффективность усвоения предмета студентом. Система состоит из трёх связанных между собой частей. Первая часть это программа- редактор вопросов, позволяющая преподавателю создавать индивидуальную базу данных вопросов по своим дисциплинам. Вторая часть представляет собой тестирующую программу, предназначенную для студентов. Третья часть предназначена для преподавателя, представляет собой статистику прохождения теста, настройку параметров, с помощью этой программы преподаватель может проанализировать результаты прохождения теста и сделать соответствующие выводы.
Таким образом, эта система может использоваться преподавателями, вне зависимости от дисциплины и одинаково подходит как для естественно-научных, так и для гуманитарных предметов.
Список литературы
1. В.В. Аладьев, Ю.Я. Хунт, М.Л. Шишаков. Основы информатики. Учебное пособие. – Москва. 1999.
2. В.А. Извозчиков, А. Д. Ревунов. Электронно-вычислительная техника на уроках физики в средней школе. - М.: Просвещение, 1988.
3. А. А Жуков, Л.А Федякина. “Система контроля знаний TSTST”.
// Информатика и образование. -1997.- №2.
4. А.А. Ездов. Лабораторные работы по физике с использованием компьютерной модели. // Информатика и образование. -1996.- №1.
5. М.Г. Ермаков, Л.Е. Андреева. Вопросы разработки тестирующих программ. // Информатика и образование. –1997.- №3.
6. В. М. Карнаухов. Система контроля знаний. // Информатика и образование. -1995.- №6.
7. В. М. Казиев. Системно-алгебраический подход к основам информатики. // Информатика и образование. -1996.- №4.
8. Е.А. Ерёмин. Почему система интересна для образования. // Информатика и образование. -1997.- №1.
9. П. Дарахвелидзе, Е. Марков. Delphi - среда визуального программирования. — BHV Санкт-Петербург: 1996.
10. Джон Матчо, Дэвид Р. Фолкнер. Delphi. — Бином М. 1996.
11. Тодд Миллер, Дэвид Пауэл и др. Использование Delphi 3. – Диалектика Киев. 1997.
12. В.В. Фаронов. Паскаль и Windows. – Москва. 1995.
13. Механизмы Windows 3.1. – Энтроп Москва. 1994.
Похожие работы
... правил, предотвращающих создание операторов SQL, которые выглядят как абсолютно правильные, но не имеют смысла. Несмотря на не совсем точное название, SQL на сегодняшний день является единственным стандартным языком для работы с реляционными базами данных. SQL — это достаточно мощный и в то же время относительно легкий для изучения язык. Роль SQL Сам по себе SQL не является ни системой ...
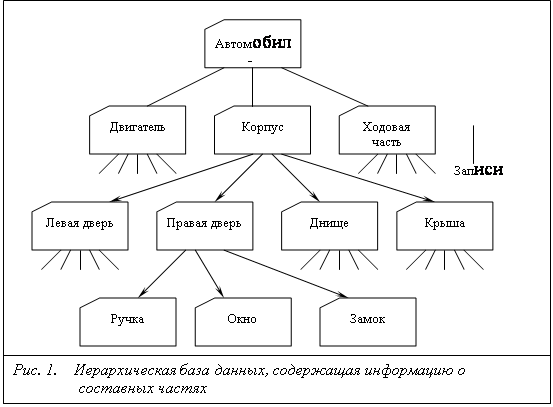
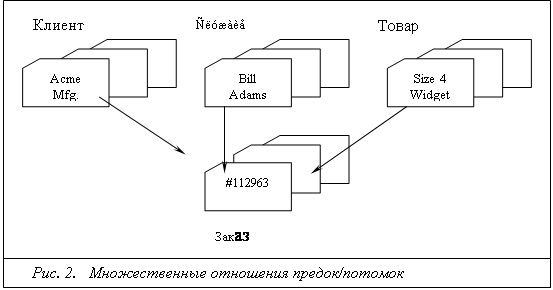
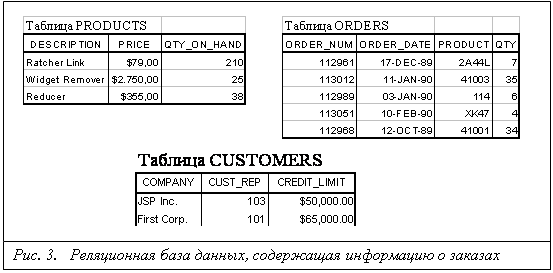


... ЭВМ. Приложения, созданные с помощью SQL и рассчитанные на однопользовательские системы, по мере своего развития могут быть перенесены в более крупные системы. Информация из корпоративных реляционных баз данных может быть загружена в базы данных отдельных подразделений или в личные базы данных. Наконец, приложения для реляционных баз данных можно вначале смоделировать на экономичных персональных ...
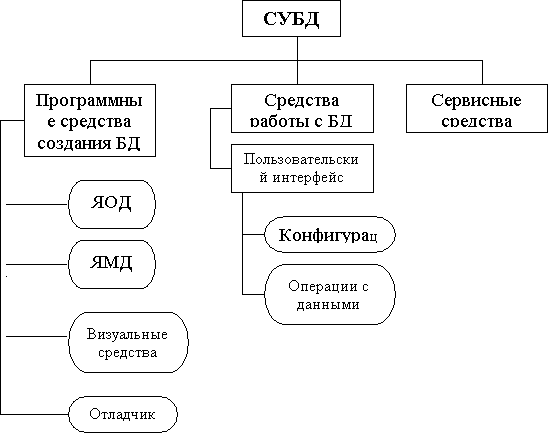

... позволяют на любом этапе разработки внести изменения в базу данных и модифицировать ее структуру без ущерба для введенных ранее данных. В процессе разработки канонической модели данных предметной области для проектирования реляционной базы данных необходимо выделить информационные объекты (ИО), соответствующие требованиям нормализации данных, и определить связи между ИО с типом отношений один ...
... являются поля и записи. Значит если записей в таблице нет, то структура образована только набором полей. Изменяя состав полей базовой таблицы (или их свойства), мы изменяем структуру базы данных и получаем новую базу данных. Свойства полей БД Access. Имя поля – как нужно обращаться к данным. Тип поля – определяет тип данных. Размер поля – определяет предельную длину данных. Формат поля – ...
0 комментариев