КАЗАНСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ КУЛЬТУРЫ И ИСКУССТВ
Кафедра информатики
Вступительный реферат по теме:
Стратегия поиска в Автоматизированных информационно-поисковых системах
Выполнил:
Султанов Ильнур Ильдусович
Казань, 2004
Содержание
Введение 4
Проблемы поиска информации 6
Поисковые алгоритмы 8
Оценка качества 17
Дополнительные возможности предоставляемые поисковыми машинами 19
Лингвистика 21
Заключение 23
Список литературы 24
Глоссарий: 25
Введение
Проблема поиска и сбора информации одна из важнейших проблем информационно поисковых систем. Конечно, нельзя сравнивать в этом отношении, скажем, средние века, когда поиск информации был проблемой потому, что этой информации было мало, и требовались усилия только для того, чтобы найти хоть что-то по более или менее значительному интересующему вопросу. Проблема поиска информации приобрела новый характер в 20-м столетии, с началом развития века информационных технологий. Теперь она заключается не в том, что информации мало и поэтому ее трудно найти, а в том, что ее теперь наоборот становится все больше и больше, и от этого найти ответ на интересующий вопрос может оказаться тоже довольно сложной задачей [2].
Так, сначала появилась возможность пойти в библиотеку и, потратив там время на выбор нужной книги по каталогу, найти необходимую информацию. Но каталоги не решают полностью проблем поиска информации даже в рамках одной библиотеки, так как в каталожную запись входит относительно мало информации: заголовок, автор, место издания и т.п. Проблема поиска информации значительно усложняется при использование виртуальных источников. Здесь используется технология онлайновых каталогов, в результате применения которой пользователь имеет возможность выполнять поиск в каталогах сразу нескольких библиотек, чем, на самом деле, еще больше усложняет себе задачу, но, с другой стороны, увеличивает шансы решить ее [1].
На современном этапе все информационное пространство, в котором мы живем, все больше погружается в Интернет. Интернет становится основной формой существования информации, не отменив традиционных, такие как журналы, радио, телевидение, телефон, всевозможные справочные службы.
В данной работе объектом исследования является Автоматизированная информационно поисковая система. Это система где хранится информационный массив, из которого пользователю выдается нужная информация, осуществляющаяся либо автоматически, либо вручную.
Предмет исследования включает в себя те свойства, стороны и отношения объекта исследования, которые необходимо изучить. Предмет обозначает границы, в пределах которых объект изучается в данном конкретном исследовании. Предметом исследования является стратегия информационного поиска.
Цель исследования: Цель исследования ставится, обзор и выявление поисковых сервисов (возможностей предоставляемые на сегодняшний день), написание рекомендации к проведению поиска, анализ развития поисковых систем.
Для выполнения поставленной цели в рамках исследования необходимо решение следующих задач:
аналитический обзор поисковых систем;
определение механизма поиска в поисковых системах;
создание информационной системы, по АИПС;
оценка эффективности созданной системы;
разработка рекомендаций к проведению поиска используя информационную систему.
Проблемы поиска информацииКлюч проблемы заключается в том, что выросло количество пользователей не обладающие профессиональными навыками при поиске информации на языке запросов. Естественно с такой проблемой столкнулся не только интернет, но и электронные библиотеки (ЭБ) и электронные каталоги (ЭК). К таким системам относятся библиотеки НЭБ-НСН, Интегрум - Техно в России, Лексис-Нексис, Рейтер на Западе.
Более строгая организация каталогов в библиотеках, полное единство форматов (или почти полное) внутри одной библиотеки не является решением проблемы современных поисковых систем. Поиск это искусство. Ясно, что в области искусства нельзя добиться гарантированного, или массового результата.
Существует убеждение, что каждое новое поколение программ поиска совершенней предыдущего. И иная точка зрения, что «все новое - это хорошо забытое старое». Думаю, что применительно к поисковым системам истина лежит где-то посередине.
Но что же поменялось в действительности за последние годы? Не алгоритмы и не структуры данных, не математические модели. Поменялась парадигма использования систем. Системой поиска стали пользоваться пользователи не имеющие профессиональные навыки.
Особенно поисковые системы стали востребованы с возникновением интернета. В процессе эволюции поисковых систем, стали очевидны следующие изменения. Во-первых, люди не только «думают словами», но и «ищут словами». В ответе системы они ожидают увидеть слово, набранное в строке запроса. Второе: «человека ищущего» трудно «переучить искать», так же как трудно переучить говорить или писать. Научная мысль 60-х – 80-х об итеративном уточнении запросов, о понимании естественного языка, о поиске по смыслу, о генерации связного ответа на вопрос, пока не удаётся создать и не выдерживает критики.
Поисковые алгоритмы
Как и любая программа, поисковая система оперирует со структурами данных и исполняет алгоритм. Есть четыре класса поисковых алгоритмов. Три алгоритма из четырех требуют «индексирования», предварительной обработки документов, при котором создаются вспомогательный файл, сиречь «индекс», призванный упростить и ускорить сам поиск. Это алгоритмы инвертированных файлов, суффиксных деревьев, сигнатур. В вырожденном случае предварительный этап индексирования отсутствует, а поиск происходит при помощи последовательного просмотра документов. Такой поиск называется прямым.
Прямой поиск
Ниже представлена простейшая его версия знакома многим.
| char* strstr(char *big, char *little) { char *x, *y, *z; for (x = big; *x; x++) { for (y = little, z = x; *y; ++y, ++z) { if (*y != *z) break; } if (!*y) return x; } return 0; } | ПРЯМОЙ ПОИСК ТЕКСТА. В этой функции языка C текст строки big просматривают слева направо и для каждой позиции x запускают последовательное сравнение с искомой подстрокой little. Для этого, двигая одновременно два указателя y и z, попарно сравнивают все символы. Если мы успешно дошли до конца искомой подстроки, значит она найдена! |
Несмотря на кажущуюся простоту, последние 30 лет прямой поиск интенсивно развивается. Было выдвинуто немалое число идей, сокращающих время поиска в разы. При этом надо учесть, что новые алгоритмы и их улучшенные варианты появляются постоянно.
Хотя прямой просмотр всех текстов – довольно медленное занятие, не следует думать, что алгоритмы прямого поиска не применяются в интернете. Норвежская поисковая система Fast (www.fastsearch.com) использовала чип, реализующий логику прямого поиска упрощенных регулярных выражений, и разместила 256 таких чипов на одной плате. Это позволяло Fast-у обслуживать довольно большое количество запросов в единицу времени.
Кроме того, есть масса программ, комбинирующих индексный поиск для нахождения блока текста с дальнейшим прямым поиском внутри блока. Например, весьма популярный, в том числе и в Рунете, glimpse.
У прямых алгоритмов есть положительные черты. Например, неограниченные возможности по приближенному и нечеткому поиску. Ведь любое индексирование всегда сопряжено с упрощением и нормализацией терминов, а, следовательно, с потерей информации. Прямой же поиск работает непосредственно по оригинальным документам безо всяких искажений.
Инвертированный файл
Эта простейшая структура данных. Первая категория людей знает, что это такое, по «конкордансам» - алфавитно упорядоченным исчерпывающим спискам слов из одного текста или принадлежащих одному автору (например «Конкорданс к стихам А. С. Пушкина», «Словарь-конкорданс публицистики Ф. М. Достоевского»). Вторые имеют дело с той или иной формой инвертированного списка всякий раз, когда строят или используют «индекс БД по ключевому полю».
П

Рис. 1
Перед нами упорядоченный по алфавиту список слов. Для каждого слова перечислены все «позиции», в которых это слово встретилось. Поисковый алгоритм состоит в отыскании нужного слова и загрузке в память уже развернутого списка позиций.
Чтобы сэкономить на дисковом пространстве и ускорить поиск, обычно прибегают к двум приемам. Во-первых, подробность самой позиции. Чем подробнее задана такая позиции, например, в случае с «Симофонией» это «книга+глава+стих», тем больше места потребуется для хранения инвертированного файла.
В наиподробнейшем варианте в инвертированном файле можно хранить и номер слова, и смещение в байтах от начала текста, и цвет и размер шрифта, да много чего еще. Чаще же просто указывают только номер документа, скажем, книгу Библии, и число употреблений этого слова в нем. Именно такая упрощенная структура считается основной в классической теории информационного поиска – Information Retrieval (IR).
Второй (никак не связанный с первым) способ сжатия: упорядочить позиции для каждого слова по возрастанию адресов и для каждой позиции хранить не полный ее адрес, а разницу от предыдущего. Вот как будет выглядеть такой список для нашей странички в предположении, что мы запоминаем позицию вплоть до номера главы:
ЖЕНЩИНА: [Быт.1],[+11],[0],[+2],[+4],[+2],[+4],..
Дополнительно на разностный способ хранения адресов накладывают какой-нибудь способ упаковки: зачем отводить небольшому целому числу фиксированное «огромное» количество байт, ведь можно отвести ему почти столько байт, сколько оно заслуживает. Здесь уместно упомянуть коды Голомба или встроенную функцию популярного языка Perl: pack(“w”).
В литературе встречается и более тяжелая система упаковочных алгоритмов самого широкого спектра: арифметический, Хафман, LZW, и т.д. Прогресс в этой области идет непрерывно. На практике в поисковых системах они используются редко: выигрыш невелик, а мощности процессора расходуются неэффективно.
В результате всех описанных ухищрений размер инвертированного файла, как правило, составляет от 7 до 30 процентов от размера исходного текста, в зависимости от подробности адресации.
занесены в «Красную книгу»
Неоднократно предлагались другие, отличные от инвертированного и прямого поиска алгоритмы и структуры данных. Это, прежде всего, суффиксные деревья, а также сигнатуры.
Первый из них функционировал и в интернете, будучи запатентованным алгоритмом поисковой ситемы OpenText.
Мне доводилось встречать суффиксные индексы в отечественных поисковых системах.
Второй - метод сигнатур - представляет собой преобразование документа к поблочным таблицам хеш-значений его слов - "сигнатуре" и последовательному просмотру "сигнатур" во время поиска.
Широкого распространения эти два метода не получили.
МАТЕМАТИЧЕСКИЕ МОДЕЛИ
Приблизительно 3 из 5 поисковых систем и модулей функционируют безо всяких математических моделей. Их разработчики не ставят перед собой задачу реализовывать абстрактную модель. Принцип здесь: лишь бы программа хоть что-нибудь находила.
Как только речь заходит о повышении качества поиска, о большом объеме информации, о потоке пользовательских запросов, кроме эмпирически проставленных коэффициентов полезным оказывается оперировать каким-нибудь пусть и несложным теоретическим аппаратом. Модель поиска – это некоторое упрощение реальности, на основании которого получается формула (сама по себе никому не нужная), позволяющая программе принять решение: какой документ считать найденным и как его ранжировать. После принятия модели коэффициенты приобретают физический смысл и становятся понятней.
Все многообразие моделей традиционного информационного поиска (IR) принято делить на три вида: теоретико-множественные (булевская, нечетких множеств, расширенная булевская), алгебраические1[1] (векторная, обобщенная векторная, латентно-семантическая, нейросетевая) и вероятностные.
Булевское семейство моделей самое известное, реализующие полнотекстовый поиск. Есть слово - документ считается найденным, нет – не найденным. Собственно, классическая булевская модель – это мостик, связывающий теорию информационного поиска с теорией поиска и манипулирования данными.
Критика булевской модели, вполне справедливая, состоит в ее крайней жесткости и непригодности для ранжирования. Поэтому еще в 1957 году Joyce и Needham (Джойс и Нидхэм) предложили учитывать частотные характеристики слов, чтобы «... операция сравнения была бы отношением расстояния между векторами...».
Векторная модель и была с успехом реализована в 1968 году отцом-основателем науки об информационном поиске Джерардом Солтоном (Gerard Salton)2[2] в поисковой системе SMART (Salton's Magical Automatic Retriever of Text). Ранжирование в этой модели основано на естественном статистическом наблюдении, что чем больше локальная частота термина в документе (TF) и больше «редкость» (т.е. обратная встречаемость в документах) термина в коллекции (IDF), тем выше вес данного документа по отношению к термину. Обозначение IDF ввела Karen Sparck-Jones (Карен Спарк-Джоунз) в 1972 в статье про различительную силу (term specificity). С этого момента обозначение TF*IDF широко используется как синоним векторной модели.
Наконец, в 1977 году Robertson и Sparck-Jones (Робертсон и Спарк-Джоунз) обосновали и реализовали вероятностную модель (предложенную еще в 1960), также положившую начало целому семейству. Релевантность в этой модели рассматривается как вероятность того, что данный документ может оказаться интересным пользователю. При этом подразумевается наличие уже существующего первоначального набора релевантных документов, выбранных пользователем или полученных автоматически при каком-нибудь упрощенном предположении. Вероятность оказаться релевантным для каждого следующего документа рассчитывается на основании соотношения встречаемости терминов в релевантном наборе и в остальной, «нерелевантной» части коллекции. Хотя вероятностные модели обладают некоторым теоретическим преимуществом, ведь они располагают документы в порядке убывания "вероятности оказаться релевантным", на практике они так и не получили большого распространения.
Важно заметить, что в каждом из семейств простейшая модель исходит из предположения о взаимонезависимости слов и обладает условием фильтрации: документы, не содержащие слова запроса, никогда не бывают найденными. Продвинутые («альтернативные») модели каждого из семейств не считают слова запроса взаимонезависимыми, а, кроме того, позволяют находить документы, не содержащие ни одного слова из запроса.
П
| Сингулярным разложением действительной матрицы A размеров m*n называется всякое ее разложение вида A = USV, где U - ортогональная матрица размеров m*m, V - ортогональная матрица размеров n*n, S - диагональная матрица размеров m*n, элементы которой sij= 0, если i не равно j, и sii = si >= 0. Величины si называются сингулярными числами матрицы и равны арифметическим значениям квадратных корней из соответствующих собственных значений матрицы AAT. В англоязычной литературе сингулярное разложение принято называть SVD-разложением. |
оиск «по смыслу»
Способность находить и ранжировать документы, не содержащие слов из запроса, часто считают признаком искусственного интеллекта или поиска по смыслу и относят априори к преимуществам модели.
Для примера опишу лишь одну, самую популярную модель, работающую по смыслу. В теории информационного поиска данную модель принято называть латентно-семантически индексированием (иными словами, выявлением скрытых смыслов). Эта алгебраическая модель основана на сингулярном разложении прямоугольной матрицы, ассоциирующей слова с документами. Элементом матрицы является частотная характеристика, отражающая степень связи слова и документа, например, TF*IDF. Вместо исходной миллионно-размерной матрицы авторы метода, предложили использовать 50-150 «скрытых смыслов»3[3], соответствующих первым главным компонентам ее сингулярного разложения.
Доказано, что если оставить в рассмотрении первые k сингулярных чисел (остальные приравнять нулю), мы получим ближайшую из всех возможных аппроксимацию исходной матрицы ранга k (в некотором смысле ее «ближайшую семантическую интерпретацию ранга k»). Уменьшая ранг, мы отфильтровываем нерелевантные детали; увеличивая, пытаемся отразить все нюансы структуры реальных данных.
Операции поиска или нахождения похожих документов резко упрощаются, так как каждому слову и каждому документу сопоставляется относительно короткий вектор из k смыслов (строки и столбцы соответствующих матриц). Однако по причине малой ли осмысленности «смыслов», или по какой иной4[4], но использование LSI в лоб для поиска так и не получило распространения. Хотя во вспомогательных целях (автоматическая фильтрация, классификация, разделение коллекций, предварительное понижение размерности для других моделей) этот метод, по-видимому, находит применение.
Оценка качестваК
| Consistency checking has shown that the overlap of relevant documents between any two assesors is on the order of 40% on average…cross-assesor recall and precision of about 65% …This implies a practical upper bound on retrieval system performance of 65% …[1] Donna Harman What we have learned, and not learned, from TREC [harman] |
акова бы ни была модель, поисковая система нуждаетсяв «тюнинге» - оценке качества поиска и настройке параметров. Оценка качества – идея, фундаментальная для теории поиска. Ибо именно благодаря оценке качества можно говорить о применимости или не применимости той или иной модели и даже обсуждать их теоретичеcкие аспекты.
В частности, одним из естественных ограничений качества поиска служит наблюдение, вынесенное в эпиграф: мнения двух «асессоров» (специалистов, выносящих вердикт о релевантности) в среднем не совпадают друг с другом в очень большой степени! Отсюда вытекает и естественная верхняя граница качества поиска, ведь качество измеряется по итогам сопоставления с мнением асессора.
Обычно5[5] для оценки качества поиска меряют два параметра:
точность (precision) – доля релевантного материала в ответе поисковой системы
полнота (recall) – доля найденных релевантных документов в общем числе релевантных документов коллекции
Именно эти параметры использовались и используются на регулярной основе для выбора моделей и их параметров в рамках созданной Американским Интститутом Стандартов (NIST) конференции по оценке систем текстового поиска (TREC - text retrival evaluation conference)6[6]. Начавшаяся в 1992 году консорциумом из 25 групп, к 12-му году своего существования конференция накопила значительный материал, на котором до сих пор оттачиваются поисковые системы. К каждой очередной конференции готовится новый материал (т.н. «дорожка») по каждому из интересующих направлений. «Дорожка» включает коллекцию документов и запросов. Приведу примеры:
Дорожка произвольных запросов (ad hoc) – присутствует на всех конференциях
Многоязычный поиск
Маршрутизация и фильтрации
Высокоточный поиск (с единственным ответом, выполняемый на время)
Взаимодействие с пользователем
Естестственно-языковая «дорожка»
Ответы на «вопросы»
Поиск в «грязных» (только что отсканированных) текстах
Голосовой поиск
Поиск в очень большом корпусе (20GB, 100GB и т.д.)
WEB корпус (на последних конференциях он представлен выборкой по домену .gov)
Распределенный поиск и слияние результатов поиска из разных систем
Дополнительные возможности предоставляемые поисковыми машинами
Как видно из «дорожек» TREC, к самому поиску тесно примыкает ряд задач, либо разделяющих с ним общую идеологию (классификация, маршрутизация, фильтрация, аннотирование), либо являющихся неотъемлемой частью поискового процесса (кластеризация результатов, расширение и сужение запросов, обратная связь, «запросо-зависимое» аннотирование, поисковый интерфейс и языки запросов). Нет ни одной поисковой системы, которой бы не приходилось решать на практике хотя бы одну из этих задач.
Зачастую наличие того или иного дополнительного свойства является решающим доводом в конкурентной борьбе поисковых систем. Например, краткие аннотации состоящие из информативных цитат документа, которыми некоторые поисковые системы сопровождают результаты соей работы, помогают им оставаться на полступеньки впереди конкурентов.
Обо всех задачах и способах их решения рассказать невозможно. Для примера рассмотрим «расширение запроса», которое обычно производится через привлечение к поиску ассоциированных терминов. Решение этой задачи возможно в двух видах – локальном (динамическом) и глобальном (статическом). Локальные техники опираются на текст запроса и анализируют только документы, найденные по нему. Глобальные же «расширения» могут оперировать тезаурусами, как априорными (лингвистическими), так и построенными автоматически по всей коллекции документов. По общепринятому мнению, глобальные модификации запросов через тезаурусы работают неэффективно, понижая точность поиска. Более успешный глобальный подход основан на построенных вручную статических классификациях, например, ВЕБ-директориях. Этот подход широко использутся в интернет-поисковиках в операциях сужения или расширения запроса.
Нередко реализация дополнительных возможностей основана на тех же самых или очень похожих принципах и моделях, что и сам поиск. Сравните, например, нейросетевую поисковую модель, в которой используется идея передачи затухающих колебаний от слов к документам и обратно к словам (амплитуда первого колебания – все тот же TF*IDF), с техникой локального расширения запроса. Последняя основанна на обратной связи (relevance feedback), в которой берутся наиболее смыслоразличительные (контрастные) слова из документов, принадлежащих верхушке списка найденного.
К сожалению, локальные методы расширения запроса, несмотря на эффектные технические идеи типа «Term Vector Database» и очевидную пользу, все еще остаются крайне дорогими.
Лингвистика
Немного в стороне от статистических моделей и структур данных стоит класс алгоритмов, традиционно относимых к лингвистическим. Точно границы между статистическим и лингвистическими методами провести трудно. Условно можно считать лингвистическими методы, опирающиеся на словари (морфологические, синтаксические, семантические), созданные человеком. Хотя считается доказанным, что для некоторых языков лингвистические алгоритмы не вносят существенного прироста точности и полноты (например, английский), все же основная масса языков требует хотя бы минимального уровня лингвистической обработки. Приведу только список задач, решаемый лингвистическими или окололингвистическими приемами:
автоматическое определение языка документа
токенизация (графематический анализ): выделение слов, границ предложений
исключение неинформативных слов (стоп-слов)
лемматизация (нормализация, стемминг): приведение словоизменительных форм к «словарной». В том числе и для слов, не входящих в словарь системы
разделение сложных слов (компаундов) для некоторых языков (например, немецкого)
дизамбигуация: полное или частичное снятие омонимии
выделение именных групп
Еще реже в исследованиях и на практике можно встретить алгоритмы словообразовательного, синтаксического и даже семантического анализа. При этом под семантическим анализом чаще подразумевают какой-нибудь статистический алгоритм (LSI, нейронные сети), а если толково-комбинаторные или семантические словари и используются, то в крайне узких предметных областях.
ЗаключениеПрежде всего, очевидно, что поиск в большом информационном массиве, не может быть сколько-нибудь корректно выполнен, будучи основан на анализе одного лишь текста документа. Ведь внетекстовые (off-page) факторы играют порой и большую роль, чем текст самой страницы. Положение на сайте, посещаемость, авторитетность источника, частота обновления, цитируемость страницы и ее авторов – все эти факторы играют важную роль.
Cтав основным источником получения справочной информации для человека, поисковые системы стали основным источником трафика для интернет -сайтов. Как следствие, они немедленно подверглись «атакам» недобросовестных авторов, желающих оказаться в первых страницах результатов поиска. Искусственная генерация входных страниц, насыщенных популярными словами, техника клоакинга, «слепого текста» и многие другие приемы, предназначенные для обмана поисковых систем.
Кроме проблемы корректного ранжирования, создателям поисковых систем пришлось решать задачу обновления и синхронизации колоссальной по размеру коллекции с гетерогенными форматами, способами доставки, языками, кодировками, массой бессодержательных и дублирующихся текстов. Необходимо поддерживать базу в состоянии максимальной свежести, может быть учитывать индивидуальные и коллективные предпочтения пользователей. Многие из этих задач никогда прежде не рассматривались в традицонной науке информационного поиска.
Список литературыАшманов И. С. Национальные особенности поисковых систем // Журнал "Компьютер в школе", № 01, 2000 год // Издательство "Открытые системы" (www.osp.ru)
Антонов А.В., Мешков В.С. Аналитические проблемы поисковых систем и «лингвистические анализаторы» // НТИ.Сер.1.- 2000.- №6.-С.1-5
Войскунский В.Г. Оценка функциональной эффективности документального поиска: и размытые шкалы оценка пертинентности // НТИ. Сер. 2.- 1992.-№5.-С.19-27
Кноп К. Поиск в Интернете как хроническое заболевание // Мир Internet. - 2002. - N 10. - С. 33-35
Конжаев А. Стратегия информационного поиска // http://www.msiu.ru.
Попов С. Поиск информации и принятие решения // НТИ. Сер.2.-2001.-№1.-С.1-4
Степанов В.К Русскоязычные поисковые механизмы в Интернет // ComputerWorld Россия.-1997.-N11.-C.37-40.
Сегалович И. Как работают поисковые системы // Мир Internet. - 2002. - N 10. - С. 24-32
Глоссарий:
++ асессор (assesor, эксперт) – специалист в предметной области, выносящий заключение о релевантности документа, найденного поисковой системой
++ булевская модель (boolean, булева, булевая, двоичная) – модель поиска, опирающаяся на операции пересечения, объединения и вычитания множеств
++ векторная модель – модель информационного поиска, рассматривающая документы и запросы как векторы в пространстве слов, а релевантность как расстояние между ними
++ вероятностная модель – модель информационного поиска, рассматривающая релевантность как вероятность соответствия данного документа запросу на основании вероятностей соответствия слов данного документа идеальному ответу
++ внетекстовые критерии (off-page, вне-страничные) – критерии ранжирования документов в поисковых системах, учитыващие факторы, не содержащиеся в тексте самого документа и не извлекаемые оттуда никаким образом
++ входные страницы (doorways, hallways) – страницы, созданные для искусственного повышения ранга в поисковых системах (поискового спама). При попадании на них пользователя перенаправляют на целевую страницу
++ дизамбигуация (tagging, part of speech disambiguation, таггинг) – выбор одного из нескольких омонимов c помощью контекста; в английском языке часто сводится к автоматическому назначению грамматической категории «часть речи»
++ дубликаты (duplicates) – разные документы с идентичным, с точки зрения пользователя, содержанием; приблизительные дубликаты (near duplicates, почти-дубликаты), в отличие от точных дубликатов, содержат незначительные отличия
++ иллюзия свежести – эффект кажущейся свежести, достигаемый поисковыми системами в интернете за счет более регулярного обхода тех документов, которые чаще находятся пользователями
++ инвертированный файл (inverted file, инверсный файл, инвертированный индекс, инвертированный список) – индекс поисковой системы, в котором перечислены слова коллекции документов, а для каждого слова перечислены все места, в которых оно встретилось
++ индекс (index, указатель) – см. индексирование
++ индекс цитирования (citation index) – число упоминаний (цитирований) научной статьи, в традиционной библиографической науке рассчитывается за промежуток времени, например, за год
++ индексирование (indexing, индексация) – процесс составления или приписывания указателя (индекса) – служебной структуры данных, необходимой для последующего поиска
++ информационный поиск (Information Retrieval, IR) – поиск неструктурированной информации, единицой представления которой является документ произвольных форматов. Предметом поиска выступает информационная потребность пользователя, неформально выраженная в поисковом запросе. И критерий поиска, и его результаты недетермированы. Этими признаками информационный поиск отличается от «поиска данных», который оперирует набором формально заданных предикатов, имеет дело со структурированной информацией и чей результат всегда детерминирован. Теория информационного поиска изучает все составляющие процесса поиска, а именно, предварительную обработку текста (индексирование), обработку и исполнение запроса, ранжирование, пользовательский интерфейс и обратную связь.
++ клоакинг (cloaking) – техника поискового спама, состоящая в распознании авторами документов робота (индексирующего агента) поисковой системы и генерации для него специального содержания, принципиально отличающегося от содержания, выдаваемого пользователю
++ контрастность термина – см. различительная сила
++ латентно-семантическое индексирование – запатентованный алгоритм поиска по смыслу, идентичный факторному анализу. Основан на сингулярном разложении матрицы связи слов с документами
++ лемматизация (lemmatization, нормализация) – приведение формы слова к словарному виду, то есть лемме
++ накрутка поисковых систем – см. спам поисковых систем
++ непотизм – вид спама поисковых систем, установка авторами документов взаимных ссылок с единственной целью поднять свой ранг в результатах поиска
++ обратная встречаемость в документах (inverted document frequency, IDF, обратная частота в документах, обратная документная частота) – показатель поисковой ценности слова (его различительной силы); обратная говорят, потому что при вычислении этого показателя в знаменателе дроби обычно стоит число документов, содержащих данное слово
++ обратная связь – отклик пользователей на результат поиска, их суждения о релевантности найденных документов, зафиксированные поисковой системой и использующиеся, например, для итеративной модификации запроса. Следует отличать от псевдо-обратной связи – техники модификации запроса, в которой несколько первых найденных документов автоматически считаются релевантными
++ омонимия – см. полисемия
++ основа – часть слова, общая для набора его словообразовательных и словоизменительных (чаще) форм
++ поиск по смыслу – алгоритм информационного поиска, способный находить документы, не содержащие слов запроса
++ поиск похожих документов (similar document search) – задача информационного поиска, в которой в качестве запроса выступает сам документ и необходимо найти документы, максимально напоминающие данный
++ поисковая система (search engine, SE, информационно-поисковая система, ИПС, поисковая машина, машина поиска, «поисковик», «искалка») – программа, предназначенная для поиска информации, обычно текстовых документов
++ поисковое предписание (query, запрос) – обычно строчка текста
++ полисемия (polysemy, homography, многозначность, омография, омонимия) - наличие нескольких значений у одного и того же слова
++ полнота (recall, охват) – доля релевантного материала, заключенного в ответе поисковой системы, по отношению ко всему релевантному материалу в коллекции
++ почти-дубликаты (near-duplicates, приблизительные дубликаты) – см. дубликаты
++ прюнинг (pruning) – отсечение заведомо нерелевантных документов при поиске с целью ускорения выполнения запроса
++ прямой поиск – поиск непосредственно по тексту документов, без предварительной обработки (без индексирования)
++ псевдо-обратная связь – см. обратная связь
++ различительная сила слова (term specificity, term discriminating power, контрастность, различительная сила) – степень ширины или узости слова. Слишком широкие термины в поиске приносят слишком много информации, при это существенная часть ее бесполезна. Слишком узкие термины помогают найти слишком мало документов, хотя и более точных.
++ регулярное выражение (regualr expression, pattern, «шаблон», реже «трафарет», «маска») – способ записи поискового предписания, позволяющий определять пожелания к искомому слову, его возможные написания, ошибки и т.д. В широком смысле – язык, позволяющий задавать запросы неограниченной сложности
++ релевантность (relevance, relevancy) – соответствие документа запросу
++ сигнатура (signature, подпись) – множество хеш-значений слов некоторого блока текста. При поиске по методу сигнатур все сигнатуры всех блоков коллекции просматриваются последовательно в поисках совпадений с хеш-значениями слов запроса
++ словоизменение (inflection) – образование формы определенного грамматического значения, обычно обязательного в данном грамматическом контексте, принадлежащей к фиксированному набору форм (парадигме), характерного для слов данного типа. В отличие от словообразования никогда не приводит к смене типа и порождает предсказуемое значение. Словоизменение имен называют склонением (declension), а глаголов – спряжением (conjugation)
++ словообразование (derivation) – образование слова или основы из другого слова или основы. Чаще приводит к смене типа и к образованию слов, имеющих идеосинкразическое значение
++ смыслоразличительный – см. различительная сила
++ спам поисковых систем (spam, спамдексинг, накрутка поисковых систем) – попытка воздействовать на результат информационного поиска со стороны авторов документов
++ статическая популярность – см. PageRank
++ стемминг – поцесс выделения основы слова
++ стоп-слова (stop-words) – те союзы, предлоги и другие частотные слова, которые данная поисковая система исключила из процесса индексирования и поиска для повышения своей производительности и/или точности поиска
++ суффиксные деревья, суффиксные массивы (suffix trees, suffix arrays, PAT-arrays) – индекс, основанный на представлении всех значимых суффиксов текста в структуре данных, известной как бор (trie). Суффиксом в этом индексе называю любую «подстроку», начинающуюся с некоторой позиции текста (текст рассматривается как одна непрерывная строка) и продолжающуюся до его конца. В реальных приложениях длина суффиксов ограничена, а индексируются только значимые позиции – например, начала слов. Этот индекс позволяет выполнять более сложные запросы, чем индекс, построенный на инвертированных файлах
++ токенизация (tokenization, lexical analysis, графематический анализ, лексический анализ) – выделение в тексте слов, чисел, и иных токенов, в том числе, например, нахождение границ предложений
++ точность (precision) - доля релевантного материала в ответе поисковой системы
++ хеш-значение (hash-value) – значение хеш-функции (hash-function), преобразующей данные произвольной длины (обычно, строчку) в число фиксированного порядка
++ частота (слова) в документах (document frequency, встречаемость в документах, документная частота) – число документов в коллекции, содержащих данное слово
++ частота термина (term frequency, TF) – частота употреблений слова в документе
++ шингл – (shingle) – хеш-значение непрерывной последовательности слов текста фиксированной длины
++ PageRank – алгоритм расчета статической (глобальной) популярности страницы в интернете, назван в честь одного из авторов - Лоуренса Пейджа. Соответствует вероятности попадания пользователя на страницу в модели случайного блуждания
++ TF*IDF – численная мера соответствия слова и документа в векторной модели; тем больше, чем относительно чаще слово встретилось в документе и относительно реже в коллекции
1 В отечественной литературе алгебраические модели часто называют линейными
2 Gerard Salton (Sahlman) 1927-1995. Он же Селтон, он же Залтон и даже Залман, он же Жерар, Герард, Жерард или даже Джеральд в зависимости от вкуса переводчика и допущенных опечаток
http://www.cs.cornell.edu/Info/Department/Annual95/Faculty/Salton.html
http://www.cs.virginia.edu/~clv2m/salton.txt
3
для больших коллекций число «смыслов» увеличивают до 300
4 После наших экспериментов с LSI получилось, что «смысл номер 1» в Рунете - все англоязычные документы, «смысл номер 3» – все форумы и т.п.
5 но не обязательно – есть и «альтернативные» метрики!
6 материалы конференции публично доступны по адресу trec.nist.gov/pubs.html
Похожие работы
... системы заключается в автоматизации и замене ручного труда автоматизированным трудом с высвобождением персонала. Конкретно будет разрабатываться автоматизированная информационная система для управления портфелем реальных инвестиций предприятия СФ ОАО «ВолгаТелеком». Разработка данной системы приведет к экономии затрат, связанных с проведением анализа и оценки инвестиционных решений и компоновки ...
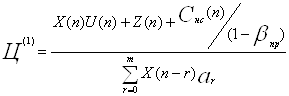
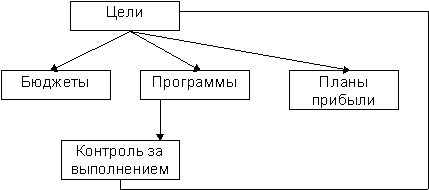
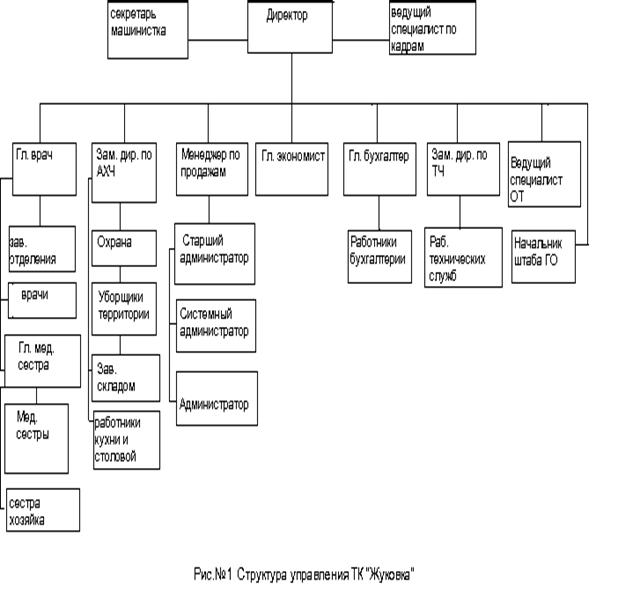
... я хотела бы посвятить именно приемному отделению ТК «Жуковка». Я считаю, что будет вполне целесообразно разработать и внедрить на данном предприятии автоматизированную информационную систему планирования сбыта, что в свою очередь ускорит и существенно облегчит работу приемного отделения ТК «Жуковка». План-схема приемного отделения и структура работы службы приема и размещения ТК «Жуковка» ...
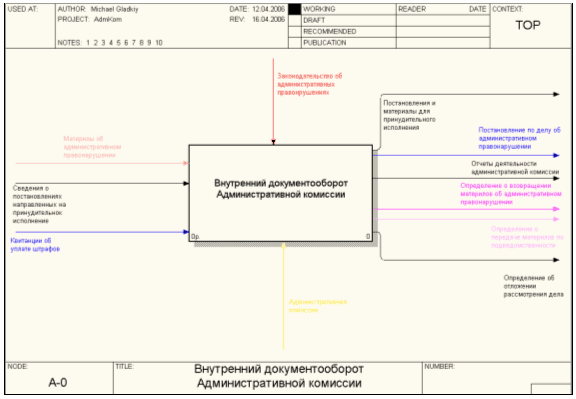
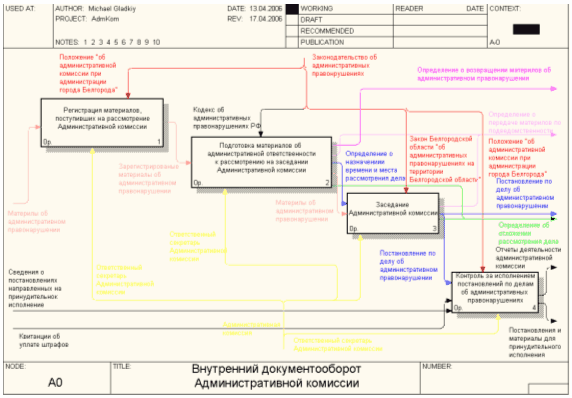
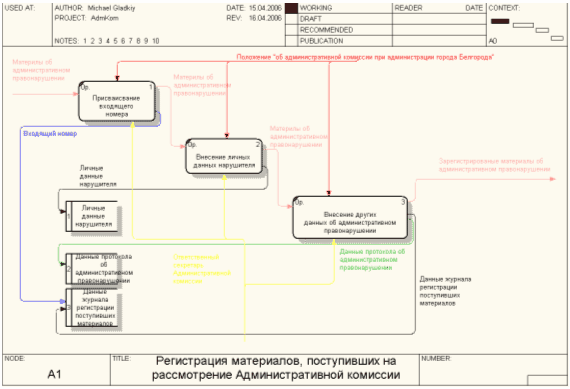
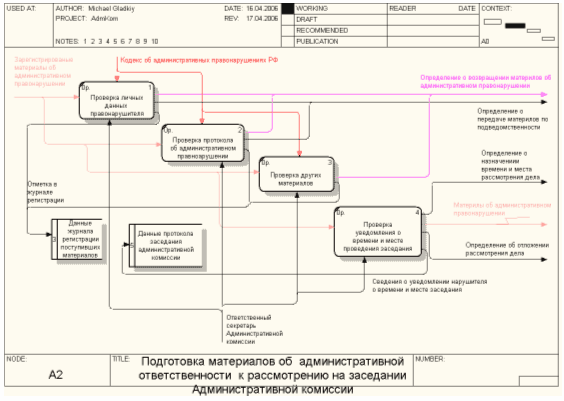
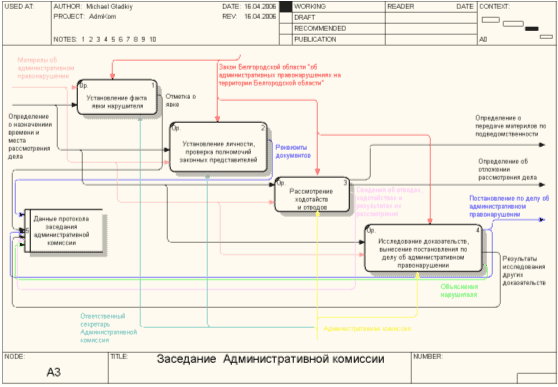
... мерах. 2.4 Техническое задание и проектирование 2.4.1 Полное наименование системы и условное обозначение Полное наименование системы - "Автоматизированная информационная система ведения внутреннего документооборота Административной комиссии при администрации г. Белгорода". Сокращенное название АИС ВВДАК 2.4.2 Основания для создания Разработка данной системы осуществлена в рамках ...
... самая важная функция бизнеса. Информационная система решает жизненно важные для организации управленческие задачи и с этой целью потребляет ресурсы предприятия. В отличие от системы управления и информационной системы, автоматизированная информационная система, административные механизмы, меняются не каждый день, а только в процессе принятия формальных организационных решений. Работы по развитию ...
0 комментариев