Running - Это самый простой из методов упаковки информации . Предположите что Вы имеете строку текста, и в конце строки стоит 40 пробелов. Налицо явная избыточность имеющейся информации. Проблема сжатия этой строки решается очень просто - эти 40 пробелов ( 40 байт ) сжимаются в 3 байта с помощью упаковки их по методу повторяющихся символов (running). Первый байт, стоящий вместо 40 пробелов в сжатой строке, фактически будет явлться пробелом ( последовательность была из пробелов ) . Второй байт - специальный байт "флажка" который указывает что мы должны развернуть предыдущий в строке байт в последовательность при восстановлении строки . Третий байт - байт счета ( в нашем случае это будет 40 ). Как Вы сами можете видеть, достаточно чтобы любой раз, когда мы имеем последовательность из более 3-х одинаковых символов, заменять их выше описанной последовательностью , чтобы на выходе получить блок информации меньший по размеру, но допускающий восстановление информации в исходном виде.
Оставляя все сказанное выше истинным , добавлю лишь то, что в данном методе основной проблемой является выбор того самого байта "флажка", так как в реальных блоках информации как правило используются все 256 вариантов байта и нет возможности иметь 257 вариант - "флажок". На первый взгляд эта проблема кажется неразрешимой , но к ней есть ключик , который Вы найдете прочитав о кодировании с помощью алгоритма Хаффмана ( Huffman ).
LZW - История этого алгоритма начинается с опубликования в мае 1977 г. Дж. Зивом ( J. Ziv ) и А. Лемпелем ( A. Lempel ) статьи в журнале "Информационные теории " под названием " IEEE Trans ". В последствии этот алгоритм был доработан Терри А. Велчем ( Terry A. Welch ) и в окончательном варианте отражен в статье " IEEE Compute " в июне 1984 . В этой статье описывались подробности алгоритма и некоторые общие проблемы с которыми можно
столкнуться при его реализации. Позже этот алгоритм получил название - LZW (Lempel - Ziv - Welch) .
Алгоритм LZW представляет собой алгоритм кодирования последовательностей неодинаковых символов. Возьмем для примера строку " Объект TSortedCollection порожден от TCollection.". Анализируя эту строку мы можем видеть, что слово "Collection" повторяется дважды. В этом слове 10 символов - 80 бит. И если мы сможем заменить это слово в выходном файле, во втором его включении, на ссылку на первое включение, то получим сжатие информации. Если рассматривать входной блок информации размером не более 64К и ограничится длинной кодируемой строки в 256 символов, то учитывая байт "флаг" получим, что строка из 80 бит заменяется 8+16+8 = 32 бита. Алгоритм LZW как-бы "обучается" в процессе сжатия файла. Если существуют повторяющиеся строки в файле , то они будут закодированны в таблицу. Очевидным преимуществом алгоритма является то, что нет необходимости включать таблицу кодировки в сжатый файл. Другой важной особенностью является то, что сжатие по алгоритму LZW является однопроходной операцией в противоположность алгоритму Хаффмана ( Huffman ) , которому требуется два прохода.
Huffman - Сначала кажется что создание файла меньших размеров из исходного без кодировки последовательностей или исключения повтора байтов будет невозможной задачей. Но давайте мы заставим себя сделать несколько умственных усилий и понять алгоритм Хаффмана ( Huffman ). Потеряв не так много времени мы приобретем знания и дополнительное место на дисках.
Сжимая файл по алгоритму Хаффмана первое что мы должны сделать - это необходимо прочитать файл полностью и подсчитать сколько раз встречается каждый символ из расширенного набора ASCII. Если мы будем учитывать все 256 символов, то для нас не будет разницы в сжатии текстового и EXE файла.
После подсчета частоты вхождения каждого символа, необходимо просмотреть таблицу кодов ASCII и сформировать мнимую компоновку между кодами по убыванию. То есть не меняя местонахождение каждого символа из таблицы в памяти отсортировать таблицу ссылок на них по убыванию. Каждую ссылку из последней таблицы назовем "узлом". В дальнейшем ( в дереве ) мы будем позже размещать указатели которые будут указывает на этот "узел". Для ясности давайте рассмотрим пример:
Мы имеем файл длинной в 100 байт и имеющий 6 различных символов в
себе . Мы подсчитали вхождение каждого из символов в файл и получили
следующее :
+-----------------+-----+-----+-----+-----+-----+-----+
| cимвол | A | B | C | D | E | F |
+-----------------+-----+-----+-----+-----+-----+-----|
| число вхождений | 10 | 20 | 30 | 5 | 25 | 10 |
+-----------------+-----+-----+-----+-----+-----+-----+
Теперь мы берем эти числа и будем называть их частотой вхождения для каждого символа. Разместим таблицу как ниже.
+-----------------+-----+-----+-----+-----+-----+-----+
| cимвол | C | E | B | F | A | D |
+-----------------+-----+-----+-----+-----+-----+-----|
| число вхождений | 30 | 25 | 20 | 10 | 10 | 5 |
+-----------------+-----+-----+-----+-----+-----+-----+
Мы возьмем из последней таблицы символы с наименьшей частотой. В нашем случае это D (5) и какой либо символ из F или A (10), можно взять любой из них например A. Сформируем из "узлов" D и A новый "узел", частота вхождения для которого будет равна сумме частот D и A :
Частота 30 10 5 10 20 25
Символа C A D F B E
| |
+--+--+
++-+
|15| = 5 + 10
+--+
Номер в рамке - сумма частот символов D и A. Теперь мы снова ищем два символа с самыми низкими частотами вхождения. Исключая из просмотра D и A и рассматривая вместо них новый "узел" с суммарной частотой вхождения. Самая низкая частота теперь у F и нового "узла". Снова сделаем операцию слияния узлов :
Частота 30 10 5 10 20 25
Символа C A D F B E
| | |
| | |
| +--+| |
+-|15++ |
++-+ |
| |
| +--+ |
+----|25+-+ = 10 + 15
+--+
Рассматриваем таблицу снова для следующих двух символов ( B и E ). Мы продолжаем в этот режим пока все "дерево" не сформировано, т.е. пока все не сведется к одному узлу.
Частота 30 10 5 10 20 25
Символа C A D F B E
| | | | | |
| | | | | |
| | +--+| | | |
| +-|15++ | | |
| ++-+ | | |
| | | | |
| | +--+ | | +--+ |
| +----|25+-+ +-|45+-+
| ++-+ ++-+
| +--+ | |
+----|55+------+ |
+-++ |
| +------------+ |
+---| Root (100) +----+
+------------+
Теперь когда наше дерево создано, мы можем кодировать файл . Мы должны всегда начинать из корня ( Root ) . Кодируя первый символ (лист дерева С) Мы прослеживаем вверх по дереву все повороты ветвей и если мы делаем левый поворот, то запоминаем 0-й бит, и аналогично 1-й бит для правого поворота. Так для C, мы будем идти влево к 55 ( и запомним 0 ), затем снова влево (0) к самому символу . Код Хаффмана для нашего символа C - 00. Для следующего символа ( А ) у нас получается - лево,право,лево,лево , что выливается в последовательность 0100. Выполнив выше сказанное для всех символов получим
C = 00 ( 2 бита )
A = 0100 ( 4 бита )
D = 0101 ( 4 бита )
F = 011 ( 3 бита )
B = 10 ( 2 бита )
E = 11 ( 2 бита )
Каждый символ изначально представлялся 8-ю битами ( один байт ), и так как мы уменьшили число битов необходимых для представления каждого символа, мы следовательно уменьшили размер выходного файла . Сжатие складывется следующим образом :
+----------+----------------+-------------------+--------------+
| Частота | первоначально | уплотненные биты | уменьшено на |
+----------+----------------+-------------------+--------------|
| C 30 | 30 x 8 = 240 | 30 x 2 = 60 | 180 |
| A 10 | 10 x 8 = 80 | 10 x 3 = 30 | 50 |
| D 5 | 5 x 8 = 40 | 5 x 4 = 20 | 20 |
| F 10 | 10 x 8 = 80 | 10 x 4 = 40 | 40 |
| B 20 | 20 x 8 = 160 | 20 x 2 = 40 | 120 |
| E 25 | 25 x 8 = 200 | 25 x 2 = 50 | 150 |
+----------+----------------+-------------------+--------------+
Первоначальный размер файла : 100 байт - 800 бит;
Размер сжатого файла : 30 байт - 240 бит;
240 - 30% из 800 , так что мы сжали этот файл на 70%.
Все это довольно хорошо, но неприятность находится в том факте, что для восстановления первоначального файла, мы должны иметь декодирующее дерево, так как деревья будут различны для разных файлов . Следовательно мы должны сохранять дерево вместе с файлом . Это превращается в итоге в увеличение размеров выходного файла .
В нашей методике сжатия и каждом узле находятся 4 байта указателя, по этому, полная таблица для 256 байт будет приблизительно 1 Кбайт длинной. Таблица в нашем примере имеет 5 узлов плюс 6 вершин ( где и находятся наши символы ) , всего 11 . 4 байта 11 раз - 44 . Если мы добавим после небольшое количество байтов для сохранения места узла и некоторую другую статистику - наша таблица будет приблизительно 50 байтов длинны. Добавив к 30 байтам сжатой информации, 50 байтов таблицы получаем, что общая длинна архивного файла вырастет до 80 байт . Учитывая , что первоначальная длинна файла в рассматриваемом примере была 100 байт - мы получили 20% сжатие информации. Не плохо . То что мы действительно выполнили - трансляция символьного ASCII набора в наш новый набор требующий меньшее количество знаков по сравнению с стандартным.
Что мы можем получить на этом пути ?
Рассмотрим максимум которй мы можем получить для различных разрядных комбинацй в оптимальном дереве, которое является несимметричным.
Мы получим что можно иметь только :
4 - 2 разрядных кода;
8 - 3 разрядных кодов;
16 - 4 разрядных кодов;
32 - 5 разрядных кодов;
64 - 6 разрядных кодов;
128 - 7 разрядных кодов;
Необходимо еще два 8 разрядных кода.
4 - 2 разрядных кода;
8 - 3 разрядных кодов;
16 - 4 разрядных кодов;
32 - 5 разрядных кодов;
64 - 6 разрядных кодов;
128 - 7 разрядных кодов;
--------
254
Итак мы имеем итог из 256 различных комбинаций которыми можно кодировать байт. Из этих комбинаций лишь 2 по длинне равны 8 битам. Если мы сложим число битов которые это представляет, то в итоге получим 1554 бит или 195 байтов. Так в максимуме , мы сжали 256 байт к 195 или 33%, таким образом максимально идеализированный Huffman может достигать сжатия в 33% когда используется на уровне байта Все эти подсчеты производились для не префиксных кодов Хаффмана т.е. кодов, которые нельзя идентифицировать однозначно. Например код A - 01011 и код B - 0101 . Если мы будем получать эти коды побитно, то получив биты 0101 мы не сможем сказать какой код мы получили A или B , так как следующий бит может быть как началом следующего кода, так и продолжением предыдущего.
Необходимо добавить, что ключем к построению префиксных кодов служит обычное бинарное дерево и если внимательно рассмотреть предыдущий пример с построением дерева , можно убедится , что все получаемые коды там префиксные.
Одно последнее примечание - алгоритм Хаффмана требует читать входной файл дважды, один раз считая частоты вхождения символов , другой разпроизводя непосредственно кодирование.
P.S. О "ключике" дающем дорогу алгоритму Running.
---- Прочитав обзорную информацию о Huffman кодировании подумайтенад тем, что на нашем бинарном дереве может быть и 257 листиков.
Список литературы
1) Описание архиватора Narc фирмы Infinity Design Concepts, Inc.;
2) Чарльз Сейтер, 'Сжатие данных', "Мир ПК", N2 1991;
Приложение
{$A+,B-,D+,E+,F-,G-,I-,L+,N-,O-,R+,S+,V+,X-}
{$M 16384,0,655360}
{******************************************************}
{* Алгоритм уплотнения данных по методу *}
{* Хафмана. *}
{******************************************************}
Program Hafman;
Uses Crt,Dos,Printer;
Type PCodElement = ^CodElement;
CodElement = record
NewLeft,NewRight,
P0, P1 : PCodElement; {элемент входящий одновременно}
LengthBiteChain : byte; { в массив , очередь и дерево }
BiteChain : word;
CounterEnter : word;
Key : boolean;
Index : byte;
end;
TCodeTable = array [0..255] of PCodElement;
Var CurPoint,HelpPoint,
LeftRange,RightRange : PCodElement;
CodeTable : TCodeTable;
Root : PCodElement;
InputF, OutputF, InterF : file;
TimeUnPakFile : longint;
AttrUnPakFile : word;
NumRead, NumWritten: Word;
InBuf : array[0..10239] of byte;
OutBuf : array[0..10239] of byte;
BiteChain : word;
CRC,
CounterBite : byte;
OutCounter : word;
InCounter : word;
OutWord : word;
St : string;
LengthOutFile, LengthArcFile : longint;
Create : boolean;
NormalWork : boolean;
ErrorByte : byte;
DeleteFile : boolean;
{-------------------------------------------------}
procedure ErrorMessage;
{ --- вывод сообщения об ошибке --- }
begin
If ErrorByte <> 0 then
begin
Case ErrorByte of
2 : Writeln('File not found ...');
3 : Writeln('Path not found ...');
5 : Writeln('Access denied ...');
6 : Writeln('Invalid handle ...');
8 : Writeln('Not enough memory ...');
10 : Writeln('Invalid environment ...');
11 : Writeln('Invalid format ...');
18 : Writeln('No more files ...');
else Writeln('Error #',ErrorByte,' ...');
end;
NormalWork:=False;
ErrorByte:=0;
end;
end;
procedure ResetFile;
{ --- открытие файла для архивации --- }
Var St : string;
begin
Assign(InputF, ParamStr(3));
Reset(InputF, 1);
ErrorByte:=IOResult;
ErrorMessage;
If NormalWork then Writeln('Pak file : ',ParamStr(3),'...');
end;
procedure ResetArchiv;
{ --- открытие файла архива, или его создание --- }
begin
St:=ParamStr(2);
If Pos('.',St)<>0 then Delete(St,Pos('.',St),4);
St:=St+'.vsg';
Assign(OutputF, St);
Reset(OutPutF,1);
Create:=False;
If IOResult=2 then
begin
Rewrite(OutputF, 1);
Create:=True;
end;
If NormalWork then
If Create then Writeln('Create archiv : ',St,'...')
else Writeln('Open archiv : ',St,'...')
end;
procedure SearchNameInArchiv;
{ --- в дальнейшем - поиск имени файла в архиве --- }
begin
Seek(OutputF,FileSize(OutputF));
ErrorByte:=IOResult;
ErrorMessage;
end;
procedure DisposeCodeTable;
{ --- уничтожение кодовой таблицы и очереди --- }
Var I : byte;
begin
For I:=0 to 255 do Dispose(CodeTable[I]);
end;
procedure ClosePakFile;
{ --- закрытие архивируемого файла --- }
Var I : byte;
begin
If DeleteFile then Erase(InputF);
Close(InputF);
end;
procedure CloseArchiv;
{ --- закрытие архивного файла --- }
begin
If FileSize(OutputF)=0 then Erase(OutputF);
Close(OutputF);
end;
procedure InitCodeTable;
{ --- инициализация таблицы кодировки --- }
Var I : byte;
begin
For I:=0 to 255 do
begin
New(CurPoint);
CodeTable[I]:=CurPoint;
With CodeTable[I]^ do
begin
P0:=Nil;
P1:=Nil;
LengthBiteChain:=0;
BiteChain:=0;
CounterEnter:=1;
Key:=True;
Index:=I;
end;
end;
For I:=0 to 255 do
begin
If I>0 then CodeTable[I-1]^.NewRight:=CodeTable[I];
If I<255 then CodeTable[I+1]^.NewLeft:=CodeTable[I];
end;
LeftRange:=CodeTable[0];
RightRange:=CodeTable[255];
CodeTable[0]^.NewLeft:=Nil;
CodeTable[255]^.NewRight:=Nil;
end;
procedure SortQueueByte;
{ --- пузырьковая сортировка по возрастанию --- }
Var Pr1,Pr2 : PCodElement;
begin
CurPoint:=LeftRange;
While CurPoint <> RightRange do
begin
If CurPoint^.CounterEnter > CurPoint^.NewRight^.CounterEnter then
begin
HelpPoint:=CurPoint^.NewRight;
HelpPoint^.NewLeft:=CurPoint^.NewLeft;
CurPoint^.NewLeft:=HelpPoint;
If HelpPoint^.NewRight<>Nil then HelpPoint^.NewRight^.NewLeft:=CurPoint;
CurPoint^.NewRight:=HelpPoint^.NewRight;
HelpPoint^.NewRight:=CurPoint;
If HelpPoint^.NewLeft<>Nil then HelpPoint^.NewLeft^.NewRight:=HelpPoint;
If CurPoint=LeftRange then LeftRange:=HelpPoint;
If HelpPoint=RightRange then RightRange:=CurPoint;
CurPoint:=CurPoint^.NewLeft;
If CurPoint = LeftRange then CurPoint:=CurPoint^.NewRight
else CurPoint:=CurPoint^.NewLeft;
end
else CurPoint:=CurPoint^.NewRight;
end;
end;
procedure CounterNumberEnter;
{ --- подсчет частот вхождений байтов в блоке --- }
Var C : word;
begin
For C:=0 to NumRead-1 do
Inc(CodeTable[(InBuf[C])]^.CounterEnter);
end;
function SearchOpenCode : boolean;
{ --- поиск в очереди пары открытых по Key минимальных значений --- }
begin
CurPoint:=LeftRange;
HelpPoint:=LeftRange;
HelpPoint:=HelpPoint^.NewRight;
While not CurPoint^.Key do
CurPoint:=CurPoint^.NewRight;
While (not (HelpPoint=RightRange)) and (not HelpPoint^.Key) do
begin
HelpPoint:=HelpPoint^.NewRight;
If (HelpPoint=CurPoint) and (HelpPoint<>RightRange) then
HelpPoint:=HelpPoint^.NewRight;
end;
If HelpPoint=CurPoint then SearchOpenCode:=False else SearchOpenCode:=True;
end;
procedure CreateTree;
{ --- создание дерева частот вхождения --- }
begin
While SearchOpenCode do
begin
New(Root);
With Root^ do
begin
P0:=CurPoint;
P1:=HelpPoint;
LengthBiteChain:=0;
BiteChain:=0;
CounterEnter:=P0^.CounterEnter + P1^.CounterEnter;
Key:=True;
P0^.Key:=False;
P1^.Key:=False;
end;
HelpPoint:=LeftRange;
While (HelpPoint^.CounterEnter < Root^.CounterEnter) and
(HelpPoint<>Nil) do HelpPoint:=HelpPoint^.NewRight;
If HelpPoint=Nil then { добавление в конец }
begin
Root^.NewLeft:=RightRange;
RightRange^.NewRight:=Root;
Root^.NewRight:=Nil;
RightRange:=Root;
end
else
begin { вставка перед HelpPoint }
Root^.NewLeft:=HelpPoint^.NewLeft;
HelpPoint^.NewLeft:=Root;
Root^.NewRight:=HelpPoint;
If Root^.NewLeft<>Nil then Root^.NewLeft^.NewRight:=Root;
end;
end;
end;
procedure ViewTree( P : PCodElement );
{ --- просмотр дерева частот и присваивание кодировочных цепей листьям --- }
Var Mask,I : word;
begin
Inc(CounterBite);
If P^.P0<>Nil then ViewTree( P^.P0 );
If P^.P1<>Nil then
begin
Mask:=(1 SHL (16-CounterBite));
BiteChain:=BiteChain OR Mask;
ViewTree( P^.P1 );
Mask:=(1 SHL (16-CounterBite));
BiteChain:=BiteChain XOR Mask;
end;
If (P^.P0=Nil) and (P^.P1=Nil) then
begin
P^.BiteChain:=BiteChain;
P^.LengthBiteChain:=CounterBite-1;
end;
Dec(CounterBite);
end;
procedure CreateCompressCode;
{ --- обнуление переменных и запуск просмотра дерева с вершины --- }
begin
BiteChain:=0;
CounterBite:=0;
Root^.Key:=False;
ViewTree(Root);
end;
procedure DeleteTree;
{ --- удаление дерева --- }
Var P : PCodElement;
begin
CurPoint:=LeftRange;
While CurPoint<>Nil do
begin
If (CurPoint^.P0<>Nil) and (CurPoint^.P1<>Nil) then
begin
If CurPoint^.NewLeft <> Nil then
CurPoint^.NewLeft^.NewRight:=CurPoint^.NewRight;
If CurPoint^.NewRight <> Nil then
CurPoint^.NewRight^.NewLeft:=CurPoint^.NewLeft;
If CurPoint=LeftRange then LeftRange:=CurPoint^.NewRight;
If CurPoint=RightRange then RightRange:=CurPoint^.NewLeft;
P:=CurPoint;
CurPoint:=P^.NewRight;
Dispose(P);
end
else CurPoint:=CurPoint^.NewRight;
end;
end;
procedure SaveBufHeader;
{ --- запись в буфер заголовка архива --- }
Type
ByteField = array[0..6] of byte;
Const
Header : ByteField = ( $56, $53, $31, $00, $00, $00, $00 );
begin
If Create then
begin
Move(Header,OutBuf[0],7);
OutCounter:=7;
end
else
begin
Move(Header[3],OutBuf[0],4);
OutCounter:=4;
end;
end;
procedure SaveBufFATInfo;
{ --- запись в буфер всей информации по файлу --- }
Var I : byte;
St : PathStr;
R : SearchRec;
begin
St:=ParamStr(3);
For I:=0 to Length(St)+1 do
begin
OutBuf[OutCounter]:=byte(Ord(St[I]));
Inc(OutCounter);
end;
FindFirst(St,$00,R);
Dec(OutCounter);
Move(R.Time,OutBuf[OutCounter],4);
OutCounter:=OutCounter+4;
OutBuf[OutCounter]:=R.Attr;
Move(R.Size,OutBuf[OutCounter+1],4);
OutCounter:=OutCounter+5;
end;
procedure SaveBufCodeArray;
{ --- сохранить массив частот вхождений в архивном файле --- }
Var I : byte;
begin
For I:=0 to 255 do
begin
OutBuf[OutCounter]:=Hi(CodeTable[I]^.CounterEnter);
Inc(OutCounter);
OutBuf[OutCounter]:=Lo(CodeTable[I]^.CounterEnter);
Inc(OutCounter);
end;
end;
procedure CreateCodeArchiv;
{ --- создание кода сжатия --- }
begin
InitCodeTable; { инициализация кодовой таблицы }
CounterNumberEnter; { подсчет числа вхождений байт в блок }
SortQueueByte; { cортировка по возрастанию числа вхождений }
SaveBufHeader; { сохранить заголовок архива в буфере }
SaveBufFATInfo; { сохраняется FAT информация по файлу }
SaveBufCodeArray; { сохранить массив частот вхождений в архивном файле }
CreateTree; { создание дерева частот }
CreateCompressCode; { cоздание кода сжатия }
DeleteTree; { удаление дерева частот }
end;
procedure PakOneByte;
{ --- сжатие и пересылка в выходной буфер одного байта --- }
Var Mask : word;
Tail : boolean;
begin
CRC:=CRC XOR InBuf[InCounter];
Mask:=CodeTable[InBuf[InCounter]]^.BiteChain SHR CounterBite;
OutWord:=OutWord OR Mask;
CounterBite:=CounterBite+CodeTable[InBuf[InCounter]]^.LengthBiteChain;
If CounterBite>15 then Tail:=True else Tail:=False;
While CounterBite>7 do
begin
OutBuf[OutCounter]:=Hi(OutWord);
Inc(OutCounter);
If OutCounter=(SizeOf(OutBuf)-4) then
begin
BlockWrite(OutputF,OutBuf,OutCounter,NumWritten);
OutCounter:=0;
end;
CounterBite:=CounterBite-8;
If CounterBite<>0 then OutWord:=OutWord SHL 8 else OutWord:=0;
end;
If Tail then
begin
Mask:=CodeTable[InBuf[InCounter]]^.BiteChain SHL
(CodeTable[InBuf[InCounter]]^.LengthBiteChain-CounterBite);
OutWord:=OutWord OR Mask;
end;
Inc(InCounter);
If (InCounter=(SizeOf(InBuf))) or (InCounter=NumRead) then
begin
InCounter:=0;
BlockRead(InputF,InBuf,SizeOf(InBuf),NumRead);
end;
end;
procedure PakFile;
{ --- процедура непосредственного сжатия файла --- }
begin
ResetFile;
SearchNameInArchiv;
If NormalWork then
begin
BlockRead(InputF,InBuf,SizeOf(InBuf),NumRead);
OutWord:=0;
CounterBite:=0;
OutCounter:=0;
InCounter:=0;
CRC:=0;
CreateCodeArchiv;
While (NumRead<>0) do PakOneByte;
OutBuf[OutCounter]:=Hi(OutWord);
Inc(OutCounter);
OutBuf[OutCounter]:=CRC;
Inc(OutCounter);
BlockWrite(OutputF,OutBuf,OutCounter,NumWritten);
DisposeCodeTable;
ClosePakFile;
end;
end;
procedure ResetUnPakFiles;
{ --- открытие файла для распаковки --- }
begin
InCounter:=7;
St:='';
repeat
St[InCounter-7]:=Chr(InBuf[InCounter]);
Inc(InCounter);
until InCounter=InBuf[7]+8;
Assign(InterF,St);
Rewrite(InterF,1);
ErrorByte:=IOResult;
ErrorMessage;
If NormalWork then
begin
WriteLn('UnPak file : ',St,'...');
Move(InBuf[InCounter],TimeUnPakFile,4);
InCounter:=InCounter+4;
AttrUnPakFile:=InBuf[InCounter];
Inc(InCounter);
Move(InBuf[InCounter],LengthArcFile,4);
InCounter:=InCounter+4;
end;
end;
procedure CloseUnPakFile;
{ --- закрытие файла для распаковки --- }
begin
If not NormalWork then Erase(InterF)
else
begin
SetFAttr(InterF,AttrUnPakFile);
SetFTime(InterF,TimeUnPakFile);
end;
Close(InterF);
end;
procedure RestoryCodeTable;
{ --- воссоздание кодовой таблицы по архивному файлу --- }
Var I : byte;
begin
InitCodeTable;
For I:=0 to 255 do
begin
CodeTable[I]^.CounterEnter:=InBuf[InCounter];
CodeTable[I]^.CounterEnter:=CodeTable[I]^.CounterEnter SHL 8;
Inc(InCounter);
CodeTable[I]^.CounterEnter:=CodeTable[I]^.CounterEnter+InBuf[InCounter];
Inc(InCounter);
end;
end;
procedure UnPakByte( P : PCodElement );
{ --- распаковка одного байта --- }
Var Mask : word;
begin
If (P^.P0=Nil) and (P^.P1=Nil) then
begin
OutBuf[OutCounter]:=P^.Index;
Inc(OutCounter);
Inc(LengthOutFile);
If OutCounter = (SizeOf(OutBuf)-1) then
begin
BlockWrite(InterF,OutBuf,OutCounter,NumWritten);
OutCounter:=0;
end;
end
else
begin
Inc(CounterBite);
If CounterBite=9 then
begin
Inc(InCounter);
If InCounter = (SizeOf(InBuf)) then
begin
InCounter:=0;
BlockRead(OutputF,InBuf,SizeOf(InBuf),NumRead);
end;
CounterBite:=1;
end;
Mask:=InBuf[InCounter];
Mask:=Mask SHL (CounterBite-1);
Mask:=Mask OR $FF7F; { установка всех битов кроме старшего }
If Mask=$FFFF then UnPakByte(P^.P1)
else UnPakByte(P^.P0);
end;
end;
procedure UnPakFile;
{ --- распаковка одного файла --- }
begin
BlockRead(OutputF,InBuf,SizeOf(InBuf),NumRead);
ErrorByte:=IOResult;
ErrorMessage;
If NormalWork then ResetUnPakFiles;
If NormalWork then
begin
RestoryCodeTable;
SortQueueByte;
CreateTree; { создание дерева частот }
CreateCompressCode;
CounterBite:=0;
OutCounter:=0;
LengthOutFile:=0;
While LengthOutFile LengthArcFile do
UnPakByte(Root);
BlockWrite(InterF,OutBuf,OutCounter,NumWritten);
DeleteTree;
DisposeCodeTable;
end;
CloseUnPakFile;
end;
{ ------------------------- main text ------------------------- }
begin
DeleteFile:=False;
NormalWork:=True;
ErrorByte:=0;
WriteLn;
WriteLn('ArcHaf version 1.0 (c) Copyright VVS Soft Group, 1992.');
ResetArchiv;
If NormalWork then
begin
St:=ParamStr(1);
Case St[1] of
'a','A' : PakFile;
'm','M' : begin
DeleteFile:=True;
PakFile;
end;
'e','E' : UnPakFile;
else ;
end;
end;
CloseArchiv;
end.
Список литературы
Для подготовки данной работы были использованы материалы с сайта http://www.hostmake.ru/
Похожие работы
... данных будет нести больше смысла, если его отсортировать каким‑либо образом. Часто требуется сортировать данные несколькими различными способами. Во‑вторых, многие алгоритмы сортировки являются интересными примерами программирования. Они демонстрируют важные методы, такие как частичное упорядочение, рекурсия, слияние списков и хранение двоичных деревьев в массиве. Наконец, сортировка ...
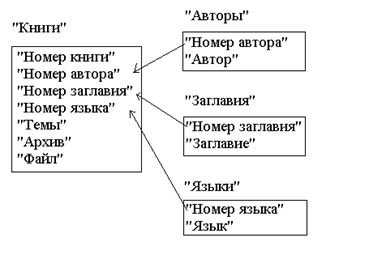
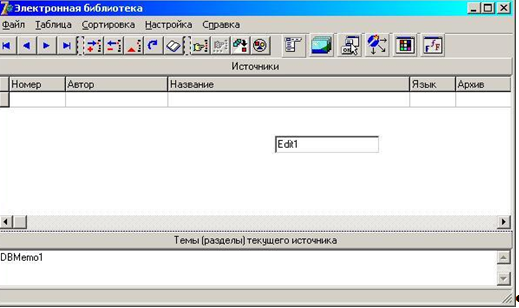
... , и на практике 5NF не используется. Заметим, что зависимость соединения является обобщением как многозначной зависимости, так и функциональной зависимости. 4. РАЗРАБОТКА БАЗЫ ДАННЫХ 4.1 Предметная область базы данных База данных предназначена для хранения информации об электронных источниках литературы в виде файлов, упакованных в архивы. Файлы архивов физически располагаются на сервере ...
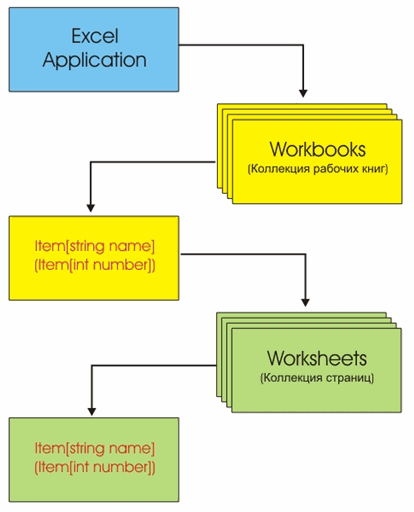
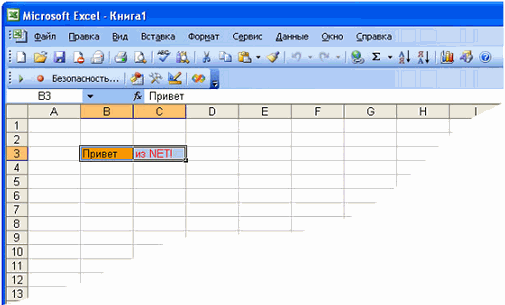
... нужно привести к типу System.Int32, чтобы поместить его в реестр. После чтения из реестра с помощью GetDef() значение должно быть преобразовано обратно к типу AcedCompressionMode. Описание демонстрационного проектаа Чтобы проиллюстрировать различные способы работы с бинарными данными с помощью рассмотренных выше классов, разработано небольшое приложение, которое представляет собой примитивный ...
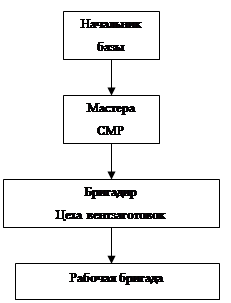



... данной предметной области и согласованные с заказчиком системы; · Структура процесса сбора, обработки и передачи данных в ИС должна соответствовать процессам, которые выполняются на рабочем месте мастера строительно-монтажных работ. Внутримашинная информационная база представляет собой физически реализованную базу данных. Носителем данных является жесткий диск, на котором находится СУБД ...
0 комментариев