Ivan Bodyagin
Несколько общих словЭтот очерк посвящен трудностям, с которыми сталкивается разработчик при попытке построить полноценное асинхронное приложение, а также той посильной помощи, которую может оказать компания Microsoft в этом нелегком предприятии благодаря следующей версии SQL Server с кодовым именем Yukon и сопутствующих библиотек.
Безусловно, тема асинхронности весьма обширна, и ее невозможно охватить в одной статье, даже если ограничиваться исключительно рамками SQL Server-а, но я и не ставил перед собой задачи охватить все. Здесь будет дан краткий обзор новой функциональности, которая появится в MS SQL Server с выходом новой версии, наиболее важной на мой взгляд, и несколько примеров использования этой функциональности...
АсинхронностьЯ несколько раз подкрадывался к своим знакомым и пытался неожиданно спросить, что же они понимают под асинхронностью – выяснилось, что все понимают, что это такое, но никто не может дать четкого определения.
Так что же такое асинхронность? Формальное определение говорит, что это такая характеристика процессов, не совпадающих во времени. Коротко, емко, но непонятно... Если же упростить, то это возможность свалить часть работы на кого-то другого, а за результатом прийти потом, занимаясь в промежутке своими делами. И это относится как к однотипной работе, так и к совершенно разноплановой. Наверное, уместно было бы прибегнуть к аналогии... Допустим, существует два способа отдать автомобиль в сервис – синхронный и асинхронный. В синхронном варианте можно приехать на сервис, пообщаться с механиком, загнать вместе с ним машину в бокс, помочь ему дружеским советом, рассказать пару свежих анекдотов или услышать их от него... Тоже в общем-то с пользой проведенное время. Если же просто отдать ключи механику при встрече и забрать машину, когда она будет готова, проведя промежуток времени между двумя этими событиями по своему усмотрению, то это уже будет асинхронный способ ремонта...
Точно так же обстоит дело и в приложении. Поток можно распараллелить на несколько потоков, как выполняющих одну и ту же работу, разделив ее на части, так и совершенно разную, например, одновременно считывать что-то с диска и решать вычислительные задачи.
Интуитивно все ощущают, что асинхронные приложения во всех отношениях лучше, но почему-то пишут их только в самом крайнем случае.
Асинхронное приложение снижает зависимость между процессами – вы в достаточно широких пределах не зависите от того, как долго механик возится с вашей машиной, если вернуться к нашей аналогии. Оно лучше масштабируется – при увеличении нагрузки достаточно подключить второй процессор или второй сервер. В общем случае оно надежнее – если один сервер вышел из строя, то остальные продолжают выполнять работу. Этот список можно продолжать довольно долго. Но всю эту радужную картину рушит одно – асинхронные приложения чертовски сложно разрабатывать.
Главная проблема асинхронных приложений состоит в сложности коммуникации между независимыми процессами. Вот такой забавный парадокс: выясняется, что асинхронные приложения необходимо уметь правильно синхронизировать, и от качества этой синхронизации зависит очень многое. В идеальном варианте обмен информации между асинхронными потоками сам по себе должен быть асинхронным, обеспечивать транзакционность, гарантию доставки, гарантию очередности, групповую обработку и много других скучных вещей... В одном отдельно взятом приложении может и не потребоваться вся эта функциональность, но практически любой крупный проект с поддержкой асинхронной работы включает в себя разработку некоего фреймфорка для реализации асинхронности, что само по себе задача не тривиальная...
Однако Microsoft с выпуском SQL Server 2005 и сопутствующих клиентских библиотек решил взять часть этой нудной работы на себя.
Асинхронные возможности сервераДля начала рассмотрим, какие возможности предоставляет новый SQL Server сам по себе, без учета возможностей клиента и ADO.Net 2.0
Начнем, пожалуй, издалека. Фраза о работе с очередями недаром вынесена в название этой статьи, так как механизм очередей является неотъемлемой частью хорошей реализации асинхронности. Как правило, в асинхронном приложении есть, условно говоря, «основной поток», который раздает некоторые задания «служебным потокам» и впоследствии забирает от них результаты. Одним из важных моментов является именно процесс выдачи задания и получения результатов. Дело в том, что служебные потоки не всегда находятся в распоряжении главного. Тому есть множество причин. Число потоков, с которыми можно работать эффективно, ограничено, и свободных потоков, готовых выполнить задание, может просто не быть, или же служебный поток может вовсе находиться на другой машине... Если основной поток при обмене информацией будет взаимодействовать непосредственно со служебными, то ему придется ждать служебные потоки, а это подрывает саму идею асинхронности. И тут на помощь приходят очереди. Они позволяют разорвать зависимость основного потока от служебных. Основному потоку достаточно поместить задания в очередь и идти дальше по своим делам. Служебные потоки, как только у них появится такая возможность, заберут из очереди задание и будут его выполнять, после чего опять-таки поместят результаты в соответствующую очередь, дабы основной поток забрал их, когда у него появится время. И даже если служебный поток находится на другой машине, то при наличии очередей не составит никакого труда инициировать транспортную транзакцию при поступлении задания в очередь, опять-таки не заставляя основной поток ждать
В грядущей версии SQL Server есть готовый механизм очередей (как одна из основных частей Service Broker). Однако если по каким-то причинам разработчику приходится строить очередь самостоятельно, то и для этого появились некоторые новые возможности.
Output или расширения обработки очередейПосвященная этой функциональности глава в разделе BOL «новые возможности» называется Queue Processing Extensions - расширения обработки очередей. Но на самом деле, это всего лишь одно из самых очевидных применений данного механизма. Суть функциональности заключается в следующем: теперь у ряда операторов, занимающихся манипуляцией с данными, а именно INSERT, UPDATE и DELETE, появилось новое ключевое слово OUTPUT. С помощью этой конструкции можно после выполнения оператора получить результат его работы и перенаправить этот результат в какую-нибудь таблицу или просто вернуть клиентскому приложению. Если говорить проще, появился доступ к триггерным псевдотабличкам inserted и deleted прямо из запроса. Иными словами, теперь есть возможность узнать, что же именно было изменено DML-оператором, не обращаясь лишний раз к серверу.
Основное предназначение данной конструкции, как следует из названия раздела, это работа с очередями, но подробнее об этом будет сказано чуть позже, а пока разберем непосредственно механику.
Простейший пример может выглядеть примерно так:| -- создаем тестовую таблицу: -- CREATE TABLE OutputTest ( ID int IDENTITY, [Time] datetime default getDate(), Limit as Left(Data, 8), Data char(50)) -- собственно, проверяем, как оно работает: -- INSERT INTO OutputTest (Data) OUTPUT INSERTED.* VALUES (NewID()) -- наслаждаемся результатом: -- ID Time Limit Data 1 2005-05-21 19:40:43.087 5C1D39E9 5C1D39E9-8E28-4ED7-B5E8-938EA84FFE18 |
Как легко заметить, вся магия заключается в конструкции OUTPUT INSERTED.*, обратите внимание, что в тестовой таблице присутствует колонка identity, колонка со значением по умолчанию и колонка с вычисляемым значением. При этом данные, полученные из inserted-таблички, содержат уже посчитанные значения в этих колонках. То есть табличка inserted содержит фактические значения вставляемых данных уже после внутренних вычислений, однако триггеры не учитываются, то есть отработка output происходит после внутренних вычислений, но перед выполнением триггеров. Например, при наличии триггера INSTEAD OF на таблице, изменяющая эту таблицу операция в output вернет все данные, которые должны там быть, даже если в результате работы триггера никаких изменений не произойдет.
| ПРЕДУПРЕЖДЕНИЕ На самом деле тут есть одно исключение, если на табличке висит триггер INSTEAD OF, то значение IDENTITY в OUTPUT INSERTED вычислено не будет. |
К выборке output можно применять различные выражения и подзапросы, в том случае если они возвращают одно значение. Например, если есть необходимость в момент изменения записи узнать, сколько времени прошло с момента последнего обновления, то запрос может выглядеть примерно так:
| UPDATE OutputTest SET Data = newID(), [Time] = GetDate() OUTPUT DateDiff(ss, DELETED.[Time], INSERTED.[Time]) Diff |
В результате выполнения такого запроса получится рекордсет с одной записью, в которой будет содержаться количество секунд, прошедшее между изменениями записи.
В предыдущих примерах результат работы output отправлялся прямо в клиентское приложение, но можно перенаправить его и в таблицу – обычную, временную и табличную переменную. Сделать это довольно просто:
| DECLARE @tmp_output TABLE ( ID_t int, Time_t datetime, Limit_t nvarchar(8), Data_t nvarchar(50)) INSERT INTO OutputTest (Data) OUTPUT inserted.* INTO @tmp_output VALUES (newid()) |
В данном случае вывод был перенаправлен в табличную переменную. В то же время, на таблицы, в которые производится вывод, наложено несколько ограничений:
На них не должно быть назначено триггеров. В принципе, триггер может быть назначен, но должен быть в состоянии Disabled.
Они не должны быть связаны внешним ключом с другими таблицами, и на эту таблицу не должны ссылаться внешние ключи.
Не должно быть CHECK-ограничений и правил (rules) в состоянии Enabled.
Вывод не может быть перенаправлен во view или функцию. Очевидно, это связано с запретом триггеров в целевой таблице.
Сложно сказать, с чем эти ограничения связаны, но, скорее всего, это вызвано стремлением максимально облегчить и ускорить вставку данных. Поскольку механизм output работает до триггеров, на довольно низком уровне, то желание избавиться от тяжелой функциональности вполне объяснимо.
И еще несколько общих ограничений механизма output:
Секционированные представления и удаленные таблицы не могут быть источником output.
В случае оператора INSERT источником output не могут быть view.
Порядок записей, выдаваемых output, не гарантируется.
Если вызов output происходит в триггере, и вывод из output не перенаправляется в таблицу, то, очевидно, опция disallow results from triggers не должна быть установлена, в противном случае произойдет исключение.
Также, если не происходит перенаправления вывода output, то изменяемая таблица не должна иметь активных триггеров на данную операцию модификации. Например, если происходит INSERT c output, без перенаправления вывода в таблицу, то триггеров на INSERT быть не должно, хотя UPDATE и DELETE триггеры вполне могут быть.
Как это использовать
Как ясно из названия данной функциональности, Microsoft предлагает использовать ее для работы с очередями. Во-первых, конструкцию DELETE … OUTPUT удобно применять для разгребания очереди, выполняя чтение и удаление прочитанной записи одним движением.
| DELETE FROM output_test OUTPUT deleted.* |
В комбинации с хинтом READPAST, можно организовать разгребание очереди из нескольких потоков одновременно, если есть такая необходимость. Ранее для этого приходилось использовать как минимум два запроса с явным блокированием нужных записей.
Во-вторых, механизм output можно использовать и для формирования очередей. В данном случае это сильно напоминает работу обычного триггера, в задачу которого входит складывать измененные данные в отдельную таблицу. Но триггер будет срабатывать для всех изменений без исключения, а output можно использовать только в определенных DML-операторах. Иными словами, если таблица может изменяться из двух мест, то триггер будет срабатывать в обоих случаях, а output можно использовать только для одного из них. Да и использовать output, наверное, будет проще, чем триггер.
Применить данный механизм с пользой можно и в отрыве от очередей. Как уже упоминалось ранее, результат output возвращается после подсчета значений по умолчанию, identity и вычисляемых столбцов, и это может оказаться довольно полезным.
Однако основную проблему коммуникации между асинхронными процессами такой подход не решает – это всего лишь небольшой синтаксический сахарок, несколько облегчающий работу с собственноручно написанными очередями, но не более того. В идеале же механизм обмена, как уже говорилось, должен обеспечивать транзакционность, отсутствие дубликатов, автоматическую работу с очередями, обработку групп сообщений, гарантировать очередность и т.д… Все это богатство было реализовано и вошло в следующую версию SQL Server под именем Service Broker.
Service Broker
При первом взгляде на Service Broker возникает вопрос: "А что во что, собственно, встроено, СУБД в подсистему сообщений или наоборот. :)"
С одной стороны, полноценная подсистема работы с сообщениями должна иметь собственное надежное хранилище, без этого невозможно реализовать все богатство, описанное в предыдущем разделе. И ребята из Редмонда с присущим им размахом решили, что раз СУБД у них уже есть, то почему бы ей не послужить в роли хранилища данных для подсистемы рассылки сообщений? С другой же стороны, использовать SQL Server исключительно в роли хранилища для одной подсистемы, пусть и очень мощной, тоже как-то неправильно... Так и родилось то, что мы исследуем сейчас: без SQL Server-а работа подсистемы сообщений невозможна, но при наличии подсистемы сообщений SQL Server перестает быть просто хранилищем данных, как это было в недавнем прошлом.
Вышеупомянутая подсистема (под названием Service Broker) представляет собой очень мощный механизм, способный принести немало пользы. Описание этого сервиса может составить целую книгу. Кстати, вскоре одна такая выйдет, однако здесь будет описана лишь небольшая часть этой функциональности, необходимая для понимания дальнейшего материала.
| СОВЕТ Книга, целиком посвященная Service Broker и выходящая в самое ближайшее время, называется The Rational Guide To SQL Server 2005 Service Broker Beta Preview (http://www.mannpublishing.com/Catalog/BookDetail.aspx?BookID=37). Она написана Роджером Уолтером (Roger Wolter), основная работа которого заключается как раз в руководстве группой, разрабатывающей этот самый Service Broker. Так что лучше него вряд ли кто-нибудь об этом механизме расскажет. :) |
Эта книга содержит много интересных и захватывающих подробностей, которые, к сожалению, выходят за рамки статьи, но рассмотрим вкратце, как все работает – процесс создания, посылки и получения сообщения.
Работа с Service Broker-ом реализована через набор объектов, которые управляются посредством обычных DDL операторов CREATE, ALTER, DROP - ничего нового. Команды по работе с этими объектами также являются небольшим DML расширением T-SQL. Например, команда получения сообщения возвращает обычный реляционный набор данных и мало чем отличается от SELECT, так что тут не должно быть никаких сложностей. В посылке и получении сообщения участвуют следующие объекты (здесь приведены далеко не все, лишь необходимый минимум):
QUEUE (очередь): Service Broker использует очереди для того, чтобы не было зависимости между отправителем и получателем сообщения. Отправитель просто помещает сообщение в очередь и идет заниматься своими делами, не дожидаясь получателя, а доставку сообщения возлагает на плечи собственно Service Broker-а, будучи уверенным, что тот справится. Получатель же может забрать и обработать сообщение, когда ему будет удобно, зная, что его деятельность никоим образом не влияет на эффективность работы отправителя, а все сообщения выстроены в должном порядке. При этом есть возможность запустить несколько «получателей» одновременно, добиваясь тем самым параллельной обработки очереди для достижения большей эффективности.
DIALOG (диалог): Одной из частей подсистемы доставки сообщений является диалог. Эту конструкцию можно рассматривать как двунаправленный поток (stream) между двумя конечными точками, по которому курсируют сообщения. Все сообщения в диалоге добираются до получателя ровно в том порядке, в котором были отосланы отправителем. Этот порядок сохраняется, невзирая ни на какие сбои, транзакции, архивирования базы, погодные условия, курс доллара и прочие внезапные факторы.
На самом деле, диалог является частным случаем общения (conversation). Conversation – это не объект, а более низкоуровневое понятие – постоянный, надежный канал связи. В MSSQL 2005 диалог – единственный тип общения, но в следующих версиях обещают добавить monolog (монолог), однонаправленный поток один-ко-многим, и, возможно, что-то еще. Однако в текущей версии диалог и общение можно считать синонимами.
Каждое сообщение включает в себя метку общения, которая уникально определяет диалог (а в будущем и другие типы потоков), ассоциированный с этим сообщением, что позволяет легко определить, откуда пришло сообщение, если поддерживается несколько каналов связи.
MESSAGE TYPE (тип сообщения): Любое сообщение должно быть ассоциировано с определенным типом. Это метка, которая передается вместе с сообщением и позволяет получателю понять, какого типа сообщение к нему приехало. По желанию, если сообщение представляет собой XML, то метка может быть ассоциирована с произвольной XML-схемой. В этом случае при получении производится проверка соответствия сообщения этой схеме, и если сообщение проверку не проходит, то оно отвергается.
CONTRACT (контракт): Контракт – это набор типов сообщений, при этом для каждого типа сообщения в контракте указывается, кому из участников диалога сообщение данного типа может принадлежать: отправителю, получателю или им обоим. Каждый диалог обязательно ассоциируется с контрактом. Иными словами, если тип сообщения не соответствует ни одному типу из контракта, ассоциированного с диалогом, то передать такое сообщение по этому диалогу не получится.
SERVICE (сервис): Сервис связывает несколько контрактов с очередью. Имя сервиса является синонимом для конечной точки диалога. Таким образом, контракт определяет, сообщения каких типов могут быть посланы через очередь посредством диалога, а сервис является конечной точкой, через которую сообщение попадает в очередь.
Схематично, весь этот зоопарк можно изобразить примерно следующим образом:
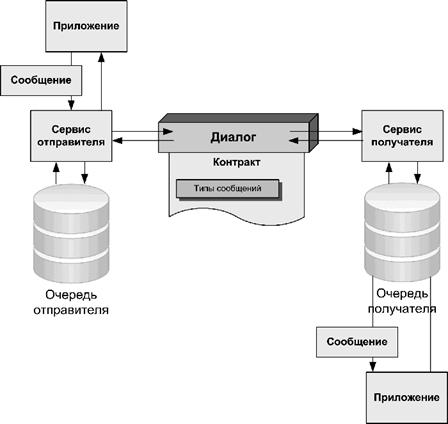
Отправитель и получатель – достаточно условные понятия, они имеют смысл только на этапе создания канала общения. После того, как канал создан, сообщения могут свободно гулять в обоих направлениях. Иными словами, отправитель – это та сторона, которая создает диалог. При этом само создание диалога не вызывает создания физического канала связи, канал создается лишь в тот момент, когда необходимо доставить первое сообщение, и удерживается до тех пор, пока диалог не завершится.
Через сервис отправителя сообщение попадает в очередь отправителя, если соответствует одному из типов сообщения, упомянутых в контракте. После этого оно передается в очередь получателя, где при получении также проходит проверку, после чего забирается оттуда собственно получателем. Если же получатель желает как-то ответить, то он в свою очередь формирует сообщение и отправляет его через свой сервис, и оно путешествует обратно тем же манером.
Теперь самое время приступить к практическим экспериментам. Для начала создадим все необходимые объекты:
| -- тип сообщения, просто текст, для простоты безо всяких проверок и xml -- CREATE MESSAGE TYPE [TestType] VALIDATION = NONE -- теперь можно создать контракт, разрешающий сообщения этого типа -- для любой из сторон -- CREATE CONTRACT [TestContract] ([TestType] SENT BY ANY) -- для отправляющей стороны необходимо создать очередь -- и сервис на основе этой очереди -- CREATE QUEUE [SourceQueue] CREATE SERVICE [SourceService] ON QUEUE [SourceQueue] -- Для принимающей стороны так же нужно создать принимающую очередь -- и принимающий сервис, причем принимающий сервис обязательно -- должен иметь контракт, хотя для отправляющего это не обязательно -- CREATE QUEUE [TargetQueue] CREATE SERVICE [TargetService] ON QUEUE [TargetQueue] ([TestContract]) |
Все, объекты готовы. Теперь можно приступать собственно к передаче сообщения. В данном примере рассматривается самый простой вариант: из отправляющего сервиса сообщение попадает в очередь получателя и забирается оттуда.
Сначала займемся получателем. Для получения сообщения служит команда RECEIVE, которая сильно напоминает обычный SELECT, только вместо имени таблицы указывается имя очереди. К слову, и команда SELECT для очереди работает (поскольку с точки зрения базы данных очередь – это обычная таблица), показывая ее содержимое, но ничего из нее не удаляя. Команда же RECEIVE выбирает данные из очереди, удаляя выбранные сообщения. Однако если очередь пуста, RECEIVE отработает вхолостую и вернет пустой набор данных, а хотелось бы, чтобы кто-то караулил очередь, и RECEIVE бы срабатывала, как только в очереди что-то появится. К счастью, в этом нет ничего сложного, достаточно обернуть RECEIVE в WAITFOR. Итак, в отдельном окне выполняем следующую команду для своевременного получения сообщения:
| WAITFOR(RECEIVE cast(message_body as nvarchar(MAX)) FROM [TargetQueue]) |
После выполнения этой команды подключение замрет в ожидании сообщения из очереди. Теперь самое время заняться отправителем. У него задачка посложнее, надо начать диалог и передать сообщение с идентификатором открытого диалога.
| DECLARE @convHandler uniqueidentifier -- начало диалога -- BEGIN DIALOG @convHandler FROM SERVICE [SourceService] TO SERVICE 'TargetService' ON CONTRACT [TestContract]; -- посылка сообщения -- SEND ON CONVERSATION @convHandler MESSAGE TYPE [TestType] (N'Message!!!') -- завершение диалога -- END CONVERSATION @convHandler |
Если после отправки сообщения вернуться в окошко, где ожидали его получения, можно увидеть, что сообщение успешно получено.
Стоит заметить, что TargetService при создании диалога взят в кавычки, а SourceService – нет. Дело в том, что TargetService может быть создан на совершенно другом сервере, и просто отсутствовать на сервере, где начинается диалог такого сервиса.
Как можно видеть из примера, в каком именно диалоге отправлять сообщение, определяется некой меткой (handler), которая возвращается при создании диалога, и представляет собой GUID. Если ее в какой-то момент потерять, то завершить диалог можно будет только административными методами, узнав этот GUID из служебных представлений (catalog view). Эта же метка приезжает к получателю вместе с сообщением, и выбрав эту метку из очереди, можно отправить сообщение обратно в том же диалоге.
Асинхронные триггеры
Теперь рассмотрим, как можно использовать коммуникативные возможности Service Broker на сервере. Например, можно использовать его для реализации асинхронных триггеров, причем не только для DML- и DDL-операций, но и для событий, отслеживаемых профайлером (trace events), и если DML-триггеры придется реализовывать отчасти с применением обычных, то для DDL-триггеров и событий профайлера предусмотрен специальный механизм.
Асинхронные DML-триггеры
Начнем с DML, идея которых, в общем-то, должна быть очевидна. Допустим, у нас есть очень большая таблица (Very_Big_Table), для отчетов по которой надо периодически считать некие агрегатные значения. Поскольку таблица очень большая, то агрегаты считаются очень долго. Отчет не всегда должен быть актуальным, но всегда – согласованным, и строиться должен максимально быстро. Это значит, что в идеале агрегаты должны быть посчитаны заранее. Делать пересчет данных в обычном триггере накладно для операций обновления, так как расчет агрегатов происходит долго, как уже было упомянуто. И тут на помощь приходит Service Broker. В обычном триггере на изменение Very_Big_Table создается диалог (строго говоря, мало что мешает создать диалог заранее, разве что проблемы с запоминанием метки при развертывании) и отправляется сообщение, о том что таблица изменилась. Это занимает минимум времени, а изменяющий процесс идет дальше заниматься своими делами. Получатель же начинает не торопясь пересчитывать эти занудные агрегаты, чтобы к моменту, когда понадобится отчет, все уже было готово.
Вот как это может выглядеть. Сначала создадим необходимые тестовые таблички:
| CREATE TABLE Very_Big_Table(ID int IDENTITY, Data bigint, [Time] DateTime) GO -- заполним таблицу данными -- INSERT INTO Very_Big_Table(Data, [Time]) SELECT object_id, create_date FROM sys.objects GO -- табличка для вычисленного агрегата -- CREATE TABLE Big_Aggregate(Agg bigint, [Time] DateTime) GO -- Ну и проинициализируем ее -- INSERT INTO Big_Aggregate(Agg, [Time]) SELECT Sum(Data), GetDate() FROM Very_Big_Table |
Теперь триггер на изменение очень большой таблички. Здесь мы сильно мудрствовать не будем, воспользуемся уже готовыми метаданными из предыдущего примера:
| CREATE TRIGGER AsyncAggregate ON Very_Big_Table FOR INSERT, UPDATE, DELETE AS DECLARE @convHandler uniqueidentifier BEGIN DIALOG @convHandler FROM SERVICE [SourceService] TO SERVICE 'TargetService' ON CONTRACT [TestContract]; SEND ON CONVERSATION @convHandler MESSAGE TYPE [TestType] (N'The data hase been changed') END CONVERSATION @convHandler GO |
Передавать в сообщении никакой ценной информации нам не надо, так как принимающая сторона должна просто узнать, о том, что таблица поменялась, а признаком этого служит сам факт доставки сообщения. Более того, в данной ситуации нет необходимости даже вызывать команду SEND, так как закрытие диалога (END CONVERSATION) вызывает посылку специального сообщения об этом печальном событии на принимающую сторону. Однако в реальной ситуации может понадобиться передать некоторую информацию, и если ее необходимо структурировать, то придется воспользоваться XML.
Теперь займемся принимающей стороной. Для начала создадим процедуру пересчета агрегата:
| CREATE PROCEDURE AggRecalculate AS -- очистка очереди -- RECEIVE * FROM [TargetQueue] -- небольшая задержка для имитации действительно долгого расчета -- WAITFOR DELAY '00:00:02' UPDATE Big_Aggregate SET Agg = (SELECT SUM(Data) FROM Very_Big_Table), [Time] = GetDate() GO |
Процедура готова, но есть одна проблема. Как выполнить эту процедуру при появлении сообщения в очереди? Конечно, можно, как и раньше, обернуть RECEIVE в WAITFOR, но в этом случае кто-то должен запусить процедуру, чтобы она начала ждать сообщений из очереди. И мало того, сообщение-то у нас может быть не одно. Значит, нужно чтобы после получения кто-то активизировал процедуру снова. Другими словами, нужен некий монитор, который следил бы за состоянием очереди и при появлении в ней сообщений вызывал нашу процедуру. К счастью, все уже сделано за нас. Такой монитор имеется в Service Broker, и для его включения достаточно немного изменить параметры очереди, указав, какую процедуру надо вызвать при получении сообщения:
| ALTER QUEUE [TargetQueue] WITH ACTIVATION( STATUS = ON, PROCEDURE_NAME = AggRecalculate, MAX_QUEUE_READERS = 1, EXECUTE AS OWNER) |
Ключевое слово здесь, конечно же, ACTIVATION, то есть активация. Однако если параметр STATUS у нее выставлен в OFF, она не сработает. Как несложно догадаться, в параметре PROCEDURE_NAME указывается имя процедуры, которая будет вызвана при активации, а в EXECUTE AS – от имени какого пользователя эта процедура будет вызвана. Параметр MAX_QUEUE_READERS определяет максимальное количество процедур, которое одновременно может быть запущено для разгребания очереди. Если во время работы процедуры поступили новые сообщения, то запускается еще один экземпляр этой процедуры, и так до максимального разрешенного количества или опустошения очереди.
Теперь все готово для эксперимента, можно приступать. Сначала обновим нашу «очень_большую_таблицу», и тут же заберем данные из таблички агрегатов, затем подождем чуть-чуть и снова заберем агрегированные данные, чтобы увидеть, как они изменились после работы процедуры перерасчета, автоматически запущенной Service Broker-ом.
| UPDATE Very_Big_Table SET Data = Data + 10 WHERE ID=1 SELECT * FROM Big_Aggregate WAITFOR DELAY '00:00:05' SELECT * FROM Big_Aggregate -- Результат: -- Agg Time -------------------- ----------------------- 76577545551 13:44:37.987 76577545561 13:59:24.630 |
Как можно заметить, все отлично сработало, произошло асинхронное обновление агрегатной таблицы. Вся прелесть в том, что агрегатная таблица может находиться на совершенно другом сервере в другой стране, надо только настроить подключение соответствующим образом, что совсем не сложно.
Асинхронные DDL и SQL-Trace триггеры (Event Notification)
Для реализации асинхронных триггеров на DDL-операции и события профайлера существует специальный механизм, Event Notification (извещение о событии).
| ПРИМЕЧАНИЕ Надо учитывать, что в связи с асинхронностью данного механизма породившие это извещение изменения в базе или на сервере, не отменятся в случае отката извещения, как это было бы в DDL-триггере. Они – уже свершившийся факт. И еще один нюанс: поскольку события профайлера работают вне транзакций, то даже если изменение на сервере, вызвавшее посылку сообщения, не увенчается успехом, то само сообщение все равно будет доставлено до получателя, однако для DDL-событий это не работает, так как DDL-операции работают в рамках транзакции и в случае отмены DDL транзакции сообщение отправлено не будет. |
Как не сложно догадаться, этот механизм отслеживает события, на которые есть подписчики, и посылает соответствующее сообщение. Для того чтобы механизм сообщений заработал, достаточно создать очередь и сервис получателя с предопределенным контрактом [http://schemas.microsoft.com/SQL/Notifications/PostEventNotification], все остальное - и контракт, и диалог, и сервис с очередью отправителя, уже реализовано. Затем надо создать объект EventNotification, связывающий нужное событие с сервисом – и готово. На практике, допустим, для асинхронного аудита подключений к серверу и отключений от оного, это может выглядеть следующим образом:
| -- сначала создадим очередь получателя, при желании -- здесь можно назначить процедуру обработки новых сообщений -- CREATE QUEUE [LoginQueue] GO -- затем необходимо создать сервис со специальным контрактом, -- в котором уже есть необходимые типы сообщений -- CREATE SERVICE [LoginService] ON QUEUE [LoginQueue]( [http://schemas.microsoft.com/SQL/Notifications/PostEventNotification]) GO -- Ну а теперь можно создать и сам Event Notification, связывающий -- серверные события с сервисом доставки сообщения -- CREATE Event Notification auditLogin ON SERVER FOR Audit_Login, Audit_Logout TO SERVICE 'LoginService', 'current database' |
Здесь ‘current database’ – это константа, которая говорит о том, что в качестве механизма доставки будет использоваться экземпляр Service Broker-а, установленный в текущей базе. Указание этого экземпляра является необходимым параметром при создании уведомления.
Вот, в общем-то, и все. Теперь осталось только получить красивый XML из очереди после очередного входа/выхода из системы и придумать, что с ним делать. Получить его можно все тем же, уже знакомым способом:
| RECEIVE cast(message_body as xml) FROM [LoginQueue] |
Сам XML представляет собой результат вызова той же самой функции Eventdata(), что используется и в DDL-триггерах.
Комбинируя рассмотренную функциональность, можно добиться довольно причудливого поведения, например, активируя очередь, по таймеру проверять загрузку процессора и занимаемую сервером память. И если нагрузка на сервер достаточно низка, то отсылать другое сообщение, которое приведет к запуску долгой расчетной процедуры...
Асинхронные возможности клиентских приложений
Теперь самое время рассмотреть подробнее, какие возможности для работы с базой данных в асинхронном режиме есть у клиентского приложения.
Как можно было убедиться из предыдущих примеров, отправить задание на выполнение кому-то другому – это полдела, надо еще вовремя получить извещение о том, что асинхронная операция закончена. При разработке механизмов взаимодействия клиента с сервером этому вопросу было уделено должное внимание.
Асинхронное выполнение запросов
Помимо выполнения асинхронных операций на сервере и работы с очередями, в ADO.Net 2.0 добавлена специальная функциональность по асинхронной работе с БД со стороны клиента. Эта функциональность поддерживается только провайдером SqlClient (OleDB и остальные его не поддерживают). Зато (приятная новость) со стороны сервера жестких ограничений нет, и асинхронные запросы будут работать с SQL Server от Microsoft, начиная с седьмой версии, при условии, что режим работы с ними – не Shared Memory, а операционная система – Windows 2000/XP/2003.
Строго говоря, и в предыдущей версии Framework-а организация асинхронной обработки данных не была такой уж большой проблемой. Однако при этом приходилось выделять дополнительный поток и блокировать его в ожидании выполнения запроса. Для клиентских приложений это не представляет большой проблемы, но для серверных решений, вынужденных обслуживать множество клиентов одновременно, это может послужить источником неприятностей. Вся же прелесть данной реализации заключается в том, что дополнительный поток не создается. Вместо этого для достижения должного эффекта используются возможности асинхронного сетевого ввода/вывода. Вместо того, чтобы создавать новый поток и заставлять его ждать синхронной операции ввода/вывода для отправки запроса в БД и получения ответа, используются асинхронные возможности сетевого протокола Windows 2000/XP/2003 (с этим и связаны ограничения на использование ОС и режима Shared Memory для версий сервера ниже SQL 2005), позволяющие одному потоку отослать запрос и идти дальше по своим делам.
Для выполнения запросов в асинхронном режиме разработчики добавили несколько методов, однако придерживались минималистской политики, и добавили лишь самые необходимые методы. Поэтому далеко не все синхронные варианты Execute* обзавелись асинхронными аналогами, точнее, только три из них. Это ExecuteReader, получивший BeginExecuteReader и EndEsecuteReader, ExecuteNonQuery, получивший BeginExecuteNonQuery и EndExecuteNonQuery, и ExecuteXmlReader, получивший, как не сложно догадаться BeginExecuteXmlReader и EndExecuteXmlReader. Предполагается следующая схема применения этого богатства: метод Begin* получает все входные параметры и передает их для исполнения серверу, оставляя после себя потоку на память лишь некий объект, реализующий специальный интерфейс по имени IAsyncResult. Этот интерфейс может быть использован для отслеживания состояния выполнения операции. Из метода же End* с помощью этого оставленного объекта можно получить обратно результат выполнения запроса, когда тот будет готов.
| СОВЕТ Интерфейс IAsyncResult далеко не нов, как и сопутствующие методы синхронизации. Вся эта механика должна быть хорошо знакома тем, кто сталкивался с асинхронными делегатами, асинхронной работой с файлами и другими многопоточными задачами в .Net. |
Одним из ключевых моментов при выполнении асинхронных операций является способ, с помощью которого инициатор операции может узнать о ее завершении. Для столь ответственного мероприятия ADO.Net предоставляет целых три способа:
Функция обратного вызова (callback). Все методы Begin* имеют перегруженный вариант, принимающий на вход делегат вместе с неким пользовательским объектом, в котором, в случае необходимости, можно передать текущее состояние. После того, как результат будет готов, произойдет вызов делегата. При этом необходимо учитывать, что делегат будет вызван из другого потока, поэтому могут потребоваться некоторые дополнительные действия для обеспечения синхронизации.
Объект синхронизации. Объект IAsyncResult, возвращаемый всеми методами Begin*, содержит свойство WaitHandle с событием, и это событие может быть использовано такими примитивами синхронизации, как WaitHandle.WaitAny и WaitHandle.WaitAll. Это позволяет вызывающему потоку дожидаться выполнения нескольких или всех запущенных операций, причем не только запросов к БД, но и, возможно, других асинхронных процедур или вызовов ОС, которые также обслуживаются вышеупомянутыми примитивами.
Опрос (Polling). Объект IAsyncResult, помимо других полезных качеств, обладает свойством IsComplete, которое возвращает true или false в зависимости от того, завершена ли асинхронная операция. Соответственно, клиентский поток, занимаясь своими делами, может периодически опрашивать это свойство, и при получении положительного ответа, идти на поклон к методу End* за вожделенным результатом.
Можно также без излишних заморочек вызвать соответствующий метод End*, что блокирует вызывающий поток до получения результата, как в старом добром, абсолютно синхронном варианте. В глубине души-то он по-прежнему асинхронный, но из вызывающего потока это совершенно не будет ощущаться.
| ПРИМЕЧАНИЕ Для выполнения асинхронных операций в строке подключения должна присутствовать ключевая фраза Asynchronous Processing = true (или async=true). В противном случае при попытке выполнить асинхронную операцию будет сгенерировано исключение. Однако если выполнение асинхронных операций не предполагается, то эту опцию рекомендуется попусту не использовать, так как это вызывает довольно заметный расход ресурсов на подключение, вплоть до того, что если в приложении предполагается активно использовать как синхронные, так и асинхронные запросы, то рекомендуется использовать две разные строки подключения, для синхронных и асинхронных запросов, соответственно. |
Вышеописанную функциональность можно использовать, например, при выполнении одновременно двух запросов к БД и последующей обработке их результатов на клиенте, что будет особенно эффективно, если базы физически находятся на разных серверах. Кроме того, можно выполнять асинхронные запросы из разных частей одной ASP.Net-страницы, что позволяет обновлять их параллельно. Вообще технология ASP.Net - довольно благодатная почва для использования асинхронных запросов. Это серверный механизм, который частенько вынужден иметь дело с огромным количеством обращений клиентов. В таких условиях потоки – вещь жутко дефицитная, и было бы непозволительной роскошью разбрасываться ими для ожидания выполнения запросов к базе. Новая функциональность здесь очень кстати, особенно в сочетании с асинхронными HttpHandler-ами.
Вот небольшой пример, позволяющий продемонстрировать некоторые возможности асинхронных запросов к серверу – примитивнейший индикатор выполнения длительного запроса, показывающий, что сервер чем-то занят, и не дающий пользователю впадать в панику.
Для начала – небольшая табличка, которая пригодится во всех последующих примерах:
| CREATE TABLE AsyncTest( ID int IDENTITY, [Time] datetime default getDate(), Data char(50)) GO INSERT INTO AsyncTest(Data) VALUES (NewID()) INSERT INTO AsyncTest(Data) VALUES (NewID()) INSERT INTO AsyncTest(Data) VALUES (NewID()) |
А теперь собственно пример:
| using System; using System.Data; using System.Data.SqlClient; namespace Rsdn.AsyncDemo { class AsyncTest { public void GetData() { using (SqlConnection connection = new SqlConnection( "Data Source=localhostctpapril;Initial Catalog = cavy;" + "Integrated Security=SSPI;" + "Asynchronous Processing=true;")) { SqlCommand cmd = new SqlCommand( "WAITFOR DELAY '00:00:10' SELECT ID, [Time]," + "Data FROM dbo.AsyncTest"," connection); connection.Open(); // отсылаем асинхронный запрос на выполнение // IAsyncResult result = cmd.BeginExecuteReader(); // основной поток работает в цикле, каждую секунду проверяя, // не готов ли результат и выводя очередную точку в индикатор // while (!result.IsCompleted) { Console.Write("."); System.Threading.Thread.Sleep(1000); } // получаем готовый результат для отображения // SqlDataReader rdr = cmd.EndExecuteReader(result); while (rdr.Read()) Console.WriteLine(Environment.NewLine + rdr[0] + "t" + rdr[2] + "t" + rdr[1]); } } } } |
Как можно видеть, пример не слишком сложный. Из ключевых особенностей можно отметить
| Asynchronous Processing = true |
в строке подключения. Эта строка обеспечивает работу с базой данных в асинхронном режиме. Еще один момент - WAITFOR DELAY в запросе, для имитации длительности его выполнения, дальнейшее должно быть очевидно из комментариев.
Несколько слов о некоторых особенностях данного механизма:
Как уже было замечено ранее, для использования асинхронного режима в строке подключения надо указать Asynchronous Processing = true (или просто async = true), но, как уже было замечено выше, пользоваться этой возможностью надо без фанатизма.
Каждому вызову Begin* обязательно должен соответствовать вызов метода End*, небрежность может привести к утечке ресурсов.
Если на сервер будет передан ошибочный запрос, который распознается как ошибочный до начала выполнения, то исключение будет выброшено методом Begin*, в противном случае, запрос считается выполненным, и исключение выбрасывается при вызове метода End*. К этому надо быть готовым.
В текущей бета-версии метод SqlCommand.Cancel() в асинхронном режиме не поддерживается, и неизвестно, будет ли поддерживаться в релизе.
Извещение об изменениях в результатах запроса (Query Notification)
Довольно часто возникает желание уведомить клиентское приложение о том, что в базе произошли некие изменения. На самом деле такое желание возникает гораздо чаще, чем встречается реальная необходимость в подобной функциональности. Но, тем не менее, бывают случаи, когда это действительно нужно. Поэтому в MS SQL Server 2005 и ADO.Net 2.0 была реализована поддержка подобного сценария.
Со стороны SQL Server в этом предприятии участвуют собственно ядро сервера (Sql Engine), Service Broker и специальная хранимая процедура sp_DispatcherProc. Со стороны ADO.Net участвуют классы SqlNotificationRequest и SqlDependency из пространства имен System.Data.SqlClient. Кеш ASP.Net также поддерживает эту функциональность. Для этого используется класс System.Web.Caching.Cache.
В общем виде сценарий использования уведомлений об изменении запрошенных данных выглядит примерно так:
У объекта SqlCommand, который содержит запрос, в процессе его инициализации заполняется свойство Notification, которое содержит подписку на оповещение об изменениях запрошенного набора данных (это свойство (Notification) передается на сервер вместе с запросом).
После получения пакета с таким свойством сервер регистрирует подписку на изменения и выполняет пришедший запрос в обычном порядке, отсылая результат клиенту.
Ядро сервера следит за всеми DML-операциями, которые могут привести к изменению результата запроса, и если сервер подозревает, что результат был изменен, ServiceBroker-у посылается специальное сообщение об этом.
Далее, в зависимости от применяемого сценария, сообщение может быть сразу отправлено клиентскому приложению или же помещено в очередь, чтобы клиентское приложение забрало его само.
| ПРИМЕЧАНИЕ Чтобы все это великолепие работало, необходим, во-первых, включенный Service Broker, во-вторых, пользователь, от имени которого выполняется запрос, должен обладать правами SUBSCRIBE QUERY NOTIFICATIONS, и в третьих, клиентский код должен выполняться с правами System.Data.SqlClient.SqlNotificationPermission. |
SqlDependency
Для начала рассмотрим реализацию самого простого сценария, когда все работает «по умолчанию», и сервер сам извещает клиентское приложение о том, что произошли некие изменения:
| using System; using System.Data; using System.Data.SqlClient; namespace Rsdn.AsyncDemo { class DependencyTest { public void GetData() { using (SqlConnection connection = new SqlConnection( "Data Source=localhostctpapril;Initial Catalog=cavy;" + "Integrated Security=SSPI;")) { SqlCommand cmd = new SqlCommand("SELECT ID, [Time], + "Data FROM dbo.AsyncTest", connection); // создаем объект SqlDependency, и регистрируем его в SqlCommand // SqlDependency depend = new SqlDependency(cmd); // подписываем обработчик события на оповещение об изменениях в // результатах запроса, выполненного через SqlCommand depend.OnChange += new OnChangeEventHandler(OnDataChange); connection.Open(); SqlDataReader rdr = cmd.ExecuteReader(); while (rdr.Read()) Console.WriteLine(rdr[0] + "t" + rdr[2] + "t" + rdr[1]); } Console.WriteLine("Press Enter to continue"); Console.ReadLine(); } /// <summary> /// Обработчик события изменения данных на сервере в запрошенном наборе. /// </summary> public void OnDataChange(object sender, SqlNotificationEventArgs e) { Console.WriteLine(String.Format( "{0}Result has changed{0}Source {1}{0}Type {2}{0}Info {3}{0}", Environment.NewLine, e.Source, e.Type, e.Info)); // Если не случилось ошибки, то обработчик надо зарегистрировать заново // и получить новый набор данных. if (e.Info != SqlNotificationInfo.Invalid) GetData(); else Console.WriteLine("The query is invalid for notification"); } } } |
В данном случае после каждого изменения данных в запрошенном наборе он будет автоматически обновляться. Этот пример полностью функционален и практически готов к использованию. Обратите внимание, что вся магия, по сути, заключена в двух выделенных строчках, ну и, естественно, обработчике события изменения данных, во всем остальном пример ничем не отличается от самого простого варианта использования SqlCommand.
Как все это работает
Сначала, как уже было вкратце описано, сервер получает стандартный пакет с текстом запроса и небольшим довеском. Этот довесок содержит имя сервиса ServiceBroker-а (который будет использоваться для доставки), строку, являющуюся идентификатором извещения и величину таймаута извещения. Всех этих параметров в примере нет, они задаются неявно, при создании экземпляров класса SqlDependency. Текст запроса может содержать несколько T-SQL-запросов. Запросы могут также находиться внутри процедуры или функции. Изменения в результатах всех этих запросов будут отслеживаться. Механизм отслеживания изменений, как это ни странно, совсем не нов, он присутствует в SQL Server с прошлой версии и используется для индексированных представлений. Точно так же, как индексированное представление узнает об изменениях данных в таблицах, из которых она состоит, механизм извещения узнает о том, что изменились данные результата запроса. Механизм хороший и проверенный, но, к сожалению, обладающий рядом довольно серьезных ограничений. Практически все ограничения, накладываемые на индексированные представления, справедливы и для механизма извещений. Обратите внимание, что в примере имя таблицы в запросе включает еще и имя схемы, а имена полей перечислены явно, иначе пример не заработал бы.
| ПРИМЕЧАНИЕ Полный список ограничений можно найти здесь: http://msdn2.microsoft.com/library/aewzkxxh(en-us,vs.80).aspx |
После того, как сервер определит, что произошли изменения, затрагивающие данные в результате запроса, в отличие от механизма индексированных представлений, копия измененных данных не создается. Вместо этого формируется сообщение для ServiceBroker-а, который использует для доставки этого сообщения адресату специально для этого созданный контракт [http://schemas.microsoft.com/SQL/Notifications/PostQueryNotification] и сервис [http://schemas.microsoft.com/SQL/Notifications/QueryNotificationService]. Адресатом является хранимая процедура sp_DispatcherProc, которая смотрит, кто именно на это сообщение подписан, и рассылает подписчикам извещения об изменении данных.
| ПРИМЕЧАНИЕ Поскольку процедура sp_DispatcherProc реализована на .Net, то для того, чтобы данный способ извещения работал, на сервере должно быть разрешено выполнение .Net-процедур. |
Вся прелесть заключается в том, что клиенту нет никакой необходимости держать постоянное соединение с сервером (что хорошо видно на примере). Это извещение доставляется подписчику отдельно от подключения к базе, по HTTP или TCP/IP. В принципе протокол можно задать явно, но по умолчанию, если клиентская ОС поддерживает HTTP (как Windows 2003 или Windows XP SP2), то используется HTTP, в противном случае – TCP. Естественно, для того чтобы это работало, клиент должен быть доступен серверу по сети, что надо учитывать при развертывании подобных систем. Для более тонкой настройки при инициализации SqlDependency можно указать параметры соединения, как уже упоминалось, протокол, а также тип аутентификации (на данный момент none или Integrated) и таймаут подписки. Сейчас эти настройки передаются в конструкторе, впоследствии будут сделаны соответствующие свойства, и количество настроек, возможно, будет увеличено.
Следует учитывать, что обработчик события об изменении данных (OnDataChange() в данном примере) будет вызван из другого потока, так что надо быть готовым к тому, что вызов произойдет еще в момент получения данных основным потоком. Как только сервер доберется до клиента и доставит ему сообщение, подписка на изменения удаляется. По этой причине в данном примере подписка реализована внутри метода GetData(), который вызывается каждый раз, когда приходит извещение.
Сообщение об изменениях приходит только один раз, вне зависимости от того, сколько строк было изменено, удалено или добавлено. Сообщение также не содержит никакой информации об измененных строках и их количестве. Единственное, что известно об изменениях – в свойстве Info объекта SqlNotificationEventArgs содержится информация о том, какие именно действия привели к посылке сообщения об изменении данных. При посылке извещения сервер предпочитает подстраховаться и послать сообщение лишний раз, чем не послать его вообще. Сообщение будет послано не только в случае реального изменения данных, но и если одна из таблиц, участвующих в запросе, была удалена, изменена или обрезана, и даже в том случае, когда выполнение DML-оператора над запрошенным набором не привело к реальному изменению данных, например: UPDATE tbl SET a = a WHERE b = @XСтоит сказать пару слов об обработке ошибок. Дело в том, что если на сервер будет послан корректный с точки зрения T-SQL запрос, отследить изменения для которого по каким-либо причинам невозможно (например, запрос не удовлетворяет строгим ограничениям внутреннего механизма извещения), то исключение сгенерировано не будет, а просто немедленно будет вызван обработчик изменения данных с признаком Invalid Query. Поэтому в реальных приложениях обработчик обязательно должен учитывать подобный вариант развития событий.
Полный список возможных причин посылки извещения и вероятных ошибок можно увидеть в содержимом enum-а SqlNotificationInfo. При формировании запроса, с целью экономии ресурсов и повышения производительности механизма извещений, рекомендуется использовать параметры, так как в этом случае сервер может сформировать один запрос на извещение для нескольких одинаковых запросов с разными параметрами. Это не означает, что клиенты будут получать извещения при изменении данных, затрагивающих чужой запрос, они по-прежнему будут получать извещения об изменениях, которые затрагивают только их данные. Например, есть два клиента, сформировавших два запроса и пославших их серверу одновременно:
Клиент 1:
| ... SqlCommand cmd = new SqlCommand( "select id, [tm], Data from dbo.AsyncTest where id = @id") cmd.Parameters.AddWithValue("@id", 2); ... |
Клиент 2:
| ... SqlCommand cmd = new SqlCommand( "select id, [tm], Data from dbo.AsyncTest where id = @id") cmd.Parameters.AddWithValue("@id", 3); ... |
На эти два запроса ядром сервера будет сформирован один запрос на отслеживание изменений, но первый клиент получит извещение только в том случае, если поменялась запись с ID = 2, а второй – если поменялась запись с ID = 3
| СОВЕТ Список подписчиков, ожидающих извещения, можно просмотреть с помощью специального системного представления sys.dm_qn_subscriptions. |
SqlNotificationRequest
Механизм извещений этого класса работает по такому же принципу, что и SqlDependency, но на чуть более низком уровне, со всеми вытекающими из этого последствиями. То есть за несколько большую гибкость необходимо расплатиться чуть большей работой при реализации. Однако основное ограничение по-прежнему присутствует, так как серверный механизм определения изменений и помещения сообщения в очередь все тот же. Главное отличие от SqlDependency состоит в том, что в данном случае работа сервера ограничивается помещением сообщения в очередь, а уж о том, чтобы забрать сообщение из этой очереди клиент должен позаботиться сам. Соответственно, никакие серверные .Net-процедуры не используются, а значит можно обойтись и без разрешения выполнения .Net-процедур. Также нет необходимости обеспечивать доступность клиента с сервера, но расплачиваться за это приходится постоянным соединением клиента с сервером, что при большом числе клиентов может быть достаточно накладным.
В качестве сервиса ServiseBroker-а, используемого для доставки сообщения, можно использовать как стандартный сервис, предназначенный для извещения об изменениях в результатах запроса: [http://schemas.microsoft.com/SQL/Notifications/QueryNotificationService], так и создать свой собственный:
| -- Сначала создаем очередь -- CREATE QUEUE NotifyTestQueue GO -- Затем на базе этой очереди создаем сервис -- Используется тот же самый контракт, специально -- предназначенный для извещений об изменениях в результатах запроса. CREATE SERVICE NotifyTestService ON QUEUE NotifyTestQueue ([http://schemas.microsoft.com/SQL/Notifications/PostQueryNotification]) GO |
Сам же код клиента, который делает примерно то же самое, что и предыдущий пример, используя очередь и сервис, созданные выше, может выглядеть следующим образом:
| using System; using System.Data; using System.Data.Sql; using System.Data.SqlClient; namespace Rsdn.AsyncTest { public class NotificationTest { private string _connectionString = "Data Source=localhostctpapril;Initial Catalog=cavy;" + "Integrated Security=SSPI;Pooling=false"; public void GetData() { using (SqlConnection connection = new SqlConnection(_connectionString)) { connection.Open(); SqlCommand cmd = new SqlCommand( "SELECT ID, [Time], Data FROM dbo.AsyncTest", connection); // Инициализируем объект SqlNotificationRequest // SqlNotificationRequest notifyRequest = new SqlNotificationRequest(); notifyRequest.UserData = "Any User Data"; notifyRequest.Options = "service=NotifyTestService"; notifyRequest.Timeout = 600; // И передаем его на сервер вместе с SqlCommand // cmd.Notification = notifyRequest; SqlDataReader rdr = cmd.ExecuteReader(); while (rdr.Read()) Console.WriteLine(rdr[0] + "t" + rdr[2] + "t" + rdr[1]); } // Вызов метода, который будет караулить очередь на предмет // появления извещений об изменении данных в результате запроса // WaitForChanges(); } public void WaitForChanges() { using (SqlConnection connection = new SqlConnection(_connectionString)) { connection.Open(); SqlCommand cmd = new SqlCommand( "WAITFOR (Receive convert(xml, message_body) from NotifyTestQueue)", connection); // Timeout выставляем в бесконечность, или, по крайней мере, // больше, чем Timeout notifyRequest'а, чтобы клиент гарантированно // дождался изменений. cmd.CommandTimeout = 0; // В этом месте поток ожидает поступления извещения об изменении. // object o = cmd.ExecuteScalar(); Console.WriteLine(o); } } } } |
Разберем этот код подробнее.
Использование метода GetData опять-таки, как и в предыдущем примере, мало отличается от стандартного использования объекта SqlCommand, создается лишь дополнительный объект SqlNotificationRequest, который явно инициализируется всеми данными, необходимыми для запуска механизма извещений. Затем этот объект передается на сервер вместе с SqlCommand.
Здесь стоит обратить внимание на свойство Options. Очевидно, через него можно задать дополнительные опции извещения. В примере указан используемый сервис, однако там же можно задать используемую базу, экземпляр Service Broker-а и еще ряд параметров.
На этом работа метода GetData() завершается и дело переходит к методу WaitForChanges(). Этот метод тоже не отличается излишней сложностью. На сервер отправляется запрос WAITFOR(RECEIVE …), ожидающий поступления сообщений из указанной очереди или таймаута. Ключевая особенность - в процессе ожидания соединение с БД открыто. Как можно заметить на примере, это не обязательно должно быть то же самое подключение, что использовалось при отправке запроса, но, тем не менее, оно должно быть, то есть клиент обязан сам получить сообщение.
Само сообщение представляет собой XML-строку, это требование стандартного контракта [http://schemas.microsoft.com/SQL/Notifications/PostQueryNotification], используемого в данном механизме. На самом деле сообщение из предыдущего примера представляет собой такой же XML, но класс SqlDependency разбирает его и предоставляет доступ к данным уже через свойства некоего объекта, здесь же разбор XML придется делать самостоятельно. Сам XML представляет собой примерно следующую конструкцию:
| <qn:QueryNotification xmlns:qn="http://schemas.microsoft.com/SQL/Notifications/QueryNotification" id="142" type="change" source="data" info="update" database_id="9" sid="0x0105000000000005150000001BB462FDDA7A03005D16C93DEB030000"> <qn:Message>Any User Data</qn:Message> </qn:QueryNotification> |
Здесь ID – это номер подписки в списке sys.dm_qn_subscriptions, type, source и info - та же информация, что и в случае SqlDependency, database_id, очевидно, идентификатор базы, где все происходит, а sid – идентификатор пользователя, вызвавшего изменения. Узел <qn:Message>, как можно заметить, содержит произвольные данные пользователя, которые были указаны при инициализации SqlNotificationRequest.
Надо заметить, что ожидание события в методе WaitForCange(), производимое через WAITFOR(RECEIVE …) само по себе не вызывает никаких накладных расходов. Основные ресурсы отнимает удержание подключения и, с точки зрения сервера, они довольно велики. К дополнительным накладным расходам следует отнести и тот факт, что в реальном приложении, как минимум, метод WaitForChange() должен выполняться в отдельном потоке, иначе подобная функциональность имеет довольно мало смысла. И если с расходами на подключение справиться довольно сложно, то создание дополнительного потока можно обойти.
Асинхронный вариант использования SqlNotification
Попытаемся теперь применить знания об асинхронных подключениях для некоторого улучшения механизма извещений об изменениях в результатах запроса. Слегка переделанный класс для получения извещений с использованием асинхронных запросов может выглядеть примерно так:
| using System; using System.Data; using System.Data.Sql; using System.Data.SqlClient; namespace Rsdn.NotifyTest { public class AsyncNotification { private string _connectionString = "Data Source=localhostctpapril;Initial Catalog=cavy;" + "Integrated Security=SSPI;Pooling=false;"; public void GetData() { using (SqlConnection syncConnect = new SqlConnection(_connectionString)) { syncConnect.Open(); SqlCommand cmd = new SqlCommand("SELECT ID, [Time]," + "Data FROM dbo.AsyncTest", syncConnect); // Инициализируем объект SqlNotificationRequest // SqlNotificationRequest notifyRequest = new SqlNotificationRequest(); notifyRequest.UserData = "Any User Data"; notifyRequest.Options = "service=NotifyTestService"; notifyRequest.Timeout = 600; // И передаем его на сервер вместе с SqlCommand // cmd.Notification = notifyRequest; SqlDataReader rdr = cmd.ExecuteReader(); while (rdr.Read()) Console.WriteLine(rdr[0] + "t" + rdr[2] + "t" + rdr[1]); rdr.Close(); } // асинхронное подключение создаем отдельно, без using, не закрывая // SqlConnection asyncConnect = new SqlConnection( _connectionString + "Asynchronous Processing=true;"); SqlCommand cmd2 = new SqlCommand( "WAITFOR (Receive convert(xml, message_body) from NotifyTestQueue)", asyncConnect); asyncConnect.Open(); cmd2.BeginExecuteReader( new AsyncCallback(Callback), cmd2, CommandBehavior.CloseConnection); } public void Callback(IAsyncResult result) { SqlDataReader DR = null; try { // Объект SqlCommand, для вызова асинхронного EndExecuteReader, был // передан при вызове BeginExecuteReader, иначе из этого метода // добраться до него было бы проблематично SqlCommand cmd = (SqlCommand)result.AsyncState; DR = cmd.EndExecuteReader(result); if (DR.Read()) Console.WriteLine(DR[0]); DR.Close(); } catch (Exception ex) { // Так как этот метод вызывается совсем из другого потока, то здесь // единственный шанс отловить и обработать какое-либо исключение. // Console.WriteLine( String.Format("Last error: {0}", ex.Message)); } finally { if (DR != null && !DR.IsClosed) { DR.Close(); } } } } } |
Постоянное соединение с БД удерживать по-прежнему необходимо, но потребность в создании отдельного потока для ожидания изменений данных отпала. Первая часть процедуры GetData практически полностью повторяет аналогичную процедуру из предыдущего примера, но после закрытия подключения для первого запроса вместо вызова WaitForChanges() создается подключение с возможностью выполнения асинхронных команд. Обратите внимание на выражение Asyncronous Processing = true, добавленное в строку подключения. Далее создается обычный SqlCommand, со знакомым уже запросом WAITFOR(RECEIVE …), и открывается подключение к БД. После этого выполняется первая часть асинхронной команды, передающая текст запроса на выполнение. В качестве дополнительных параметров указывается функция обратного вызова Callback(), сам объект SqlCommand, который затем передастся в Callback() как одно из свойств IAsyncResult, и CommandBehaviour указывается такой, чтобы закрыть подключение после завершения чтения данных – ведь внутри Callback() объект SqlCommand будет уже недоступен. На этом функция GetData() завершает свою работу, и основной поток идет заниматься своими делами.
В тот момент, когда в очередь попадает извещение, ожидание заканчивается. Сетевой драйвер оповещает, что асинхронная операция закончена. Вызывается метод Callback(), в который в качестве параметра передается IAsyncResult, позволяющий, во-первых, получить ответ от сервера, а во-вторых, содержащий в одном из полей и сам объект SqlCommand, метод которого EndExecuteReader добывает этот самый результат. Иными словами, мы сначала извлекаем из IAsyncResult объект SqlCommand, а затем в SqlCommand.EndExecueReader передаем все тот же IAsyncResult, чтобы получить SqlDataReader с результатом. В данном случае результат представляет собой знакомую уже XML-строку.
Отдельного замечания здесь заслуживает обработка исключений. Поскольку метод Callback() вызывается из другого потока, то если не перехватить и не обработать исключение здесь, то больше этого сделать будет негде, так как «выше» пользовательского кода больше нет.
Использование оповещения ASP.Net 2.0
Как известно, в ASP.Net существует совершенно замечательный объект Cache, который позволяет легко и непринужденно кэшировать практически что угодно, с весьма гибко настраиваемым механизмом обновления кэша – как по времени, так и по изменениям источников данных. К сожалению, предыдущие версии не поддерживали основной источник данных, БД. В этой версии благодаря классу SqlDependency эта печальная традиция нарушена. Простейший пример реализации данного механизма в ASP.Net 2.0 вообще не требует ни строчки кода, а пишется исключительно в декларативном стиле:
| <form id="form1" runat="server"> <asp:GridView ID="grdItems" Runat="server" DataSourceId="SqlDataSource1"/> <asp:SqlDataSource ID="SqlDataSource1" Runat="server" EnableCaching="true" SqlCacheDependency ="CommandNotification" ConnectionString="Data Source=localhostctpapril;" + "Initial Catalog=cavy;Integrated Security=SSPI;" SelectCommand="SELECT ID, tm, Data FROM dbo.NotifyTest" /> </form> |
Вся магия заключается в строчке SqlCacheDependency = “CommandNotification”. Узрев директиву CommandNotification при компиляции .aspx-страницы, сервер самостоятельно формирует запрос с необходимостью оповещения и регистрирует обработчик событий с очисткой кэша при получении извещения об изменении данных. Этот пример, конечно, эффектен, но не слишком показателен, и в реальных приложениях, надеюсь, мало кто пишет в таком стиле. Для использования новых возможностей в явном виде достаточно создать экземпляр объекта SqlCacheDependency, который расположен в System.Web.Cache, и указать его в качестве CacheDependency при помещении данных в кэш.
Пара слов напоследок
Вышеописанные механизмы довольно неплохо работают, но обладают очевидным недостатком – далеко не все изменения можно отследить и оповестить о них клиента. Естественно, ничто не мешает сделать свою реализацию, благо в описанных механизмах нет ничего сложного. Но очевидно, собственная реализация будет не столь эффективна и потребует несколько большего объема ручной работы. Главная сложность – придумать собственную систему регистрации клиентов, чтобы те получали извещения только о нужных изменениях. Возможно, в большинстве сложных случаев лучшим окажется компромиссный вариант, когда информация о сколь угодно сложных изменениях скидывается триггером в некую табличку, а клиенты, желающие получить информацию об этих изменениях, подписываются на нужные обновления в этой простой таблице с помощью SqlDependency.
Здесь была предпринята попытка охватить как можно больше возможностей асинхронной работы, чтобы понять, с чем имеет смысл ознакомиться поближе. Но, тем не менее, очень многое осталось за рамками статьи, например, наличие в Service Broker-е полноценного .Net API, так что для работы с ним нет никакой необходимости учить SQL. Да и вообще, в этом механизме есть множество уникальных возможностей, заслуживающих самого пристального изучения. Само добавление подсистемы сообщений в СУБД, как уже говорилось, выводит систему из рамок простого хранилища данных на новый уровень, не говоря уже о других изменениях.
В статье не была упомянута еще одна технология – MARS (Multilpe Active ResultSet). Это новая возможность ADO.Net 2.0, позволяющая при одном открытом соединении с БД работать с множеством объектов SqlCommand, что тоже имеет некоторое отношение к асинхронности.
Список литературы
A First Look at SQL Server 2005 Service Broker http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnsql90/html/sqlsvcbroker.asp
Write Ahead Blog (Блог одного из разработчиков Service Broker-а) http://blogs.msdn.com/rushidesai/default.aspx
Asynchronous Command Execution in ADO.NET 2.0 http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnvs05/html/async2.asp
Query Notifications in ADO.NET 2.0 http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnvs05/html/async2.asp
Для подготовки данной работы были использованы материалы с сайта http://www.rsdn.ru/
0 комментариев