Иван Бодягин (Merle)
ВведениеВвиду того, что в следующей версии MS SQL Server, выход которой ожидается в 2005 году, нововведений просто безумное количество, слона приходится есть по частям. Данный кусочек посвящен новой функциональности называемой «оконные функции» (Window Functions), также известной широкой общественности под именем «аналитических», или OLAP-функций.
Сама по себе идея не нова. С подачи IBM, Oracle, Informix и Compaq аналитические функции были добавлены в ANSI SQL 99. В Oracle поддержка подобной функциональности, со своими специфичными расширениями, появилась с версии 8i R2, в DB2 – с версии 7.1, да и имеющиеся в T-SQL на данный момент функции CUBE и ROLUP также можно отнести к аналитическим.
С одной стороны, Microsoft и так поставляет вместе c SQL Server достаточно мощный механизм для анализа данных – Analysis Services. Отчасти по этой причине Microsoft не спешила поддерживать инициативу введения некоторых OLAP-функций в стандарт SQL.
Но с другой стороны, при необходимости некоторого анализа данных не всегда есть возможность и желание поднимать еще один сервис. К тому же, строго говоря, аналитические функции не совсем правильно относить к OLAP, они не предназначены для многомерного анализа данных, работы с гиперкубами и сложными иерархиями, эти функции осуществляют лишь статистический анализ данных в готовой выборке... Тем не менее, это достаточно мощный и удобный инструмент, и поэтому, в конце концов, Microsoft также не осталась в стороне.
Сначала несколько слов о том, что же из себя представляют и как работают аналитические функции в общем виде. Одно из главных отличий аналитических функций от обычных, скалярных, заключается в том, что этот класс операторов работает с готовой выборкой. Сначала формируется выборка, выполняются все объединения, условия WHERE, GROUP BY, HAVING – все, кроме сортировки, и только затем к практически готовому набору данных применяется аналитическая функция. Именно поэтому аналитические функции можно указывать лишь в списке выборки или в условии сортировки.
В общем случае принцип работы аналитических функций можно представить примерно следующим образом. Допустим, что у нас есть результирующий набор данных, полученный вышеописанным способом – выполнено все, кроме сортировки. На каждую запись в этом наборе накладывается так называемое «окно», размеры и положение которого определяются в соответствии с некоторым аналитическим условием (собственно отсюда и название этого класса функций – «оконные функции», window functions). В это виртуальное «окно» попадают несколько других записей из того же набора, то есть целая группа записей. При этом «окно» может быть сформировано таким образом, что в него попадут вовсе не соседние записи, а практически произвольные записи из набора, и даже сама текущая запись, на основании которой формируется «окно», может в это «окно» не попасть (в дальнейшем термин «окно» будет использоваться для обозначения именно такого набора записей). Когда «окно» сформировано, аналитическая функция вычисляет агрегированное значение по записям, входящим в «окно», и переходит к следующей записи. Для этой записи формируется новое «окно», снова вычисляется агрегированное значение - и так для всех записей в выборке. При этом размер и положение «окна» от записи к записи может меняться, в таких случаях используют термин «скользящее окно» (sliding window).
Спектр применения аналитических функций достаточно широк - это различного рода распределения (ранговое (ranking), кумулятивное и т.д.), процентирование (percentile), линейная регрессия, стандартные отклонения, дисперсии, нарастающие итоги, а также прочая низшая математика и высшая бухгалтерия. :)
Строго говоря, практически все, что можно получить с помощью аналитических функций, можно получить и без них, с помощью обычного T-SQL, но это будет заведомо более громоздко и зачастую не так эффективно.
Текущая реализацияНа данный момент в MS SQL Server 2005 реализованы два типа аналитических функций – агрегатные и функции ранжирования.
Агрегатные функцииПоскольку аналитическая функция возвращает агрегированный результат обработки записей, попавших в «окно», то самые обычные агрегатные функции теперь имеют возможность выступить в качестве аналитических. Отличие состоит в том, что «обычные» агрегаты уменьшают степень детализации результирующего набора, а в аналитическом варианте степень детализации не уменьшается. Это относится не только к агрегатам, но и к другим типам аналитических функций. Разберем на примере.
Допустим, у нас есть таблица с операциями клиентов, содержащая ID транзакции, ID клиента и сумму сделки, всего 15 записей...
| CREATE TABLE sample ( ID_Trans int IDENTITY(1,1) PRIMARY KEY, ID_Customer int NOT NULL, Amount int NOT NULL ) GO INSERT INTO sample (ID_Customer, Amount) SELECT 1, 100 union all SELECT 2, 100 union all SELECT 3, 100 union all SELECT 1, 110 union all SELECT 1, 120 union all SELECT 2, 200 union all SELECT 2, 220 union all SELECT 3, 300 union all SELECT 3, 330 union all SELECT 3, -100 union all SELECT 2, 400 union all SELECT 1, 101 union all SELECT 2, 202 union all SELECT 1, 100 union all SELECT 2, 200 |
Сравним результат выполнения двух запросов. В одном SUM выступает в качестве обычного агрегата:
| SELECT ID_Customer, sum(Amount) FROM sample GROUP BY ID_Customer --- Результат вполне предсказуем: 1 531 2 1322 3 630 |
А в другом уже в качестве аналитической функции:
| SELECT ID_Trans, ID_Customer, sum(Amount) OVER (PARTITION BY ID_Customer) FROM sample --- А здесь получим следующее: 4 1 531 5 1 531 1 1 531 12 1 531 14 1 531 15 2 1322 11 2 1322 13 2 1322 2 2 1322 6 2 1322 7 2 1322 8 3 630 9 3 630 10 3 630 3 3 630 |
При просмотре результатов второго запроса можно заметить, что сервер не стал ругаться на указание колонки ID_Trans в выборке, несмотря на отсутствие агрегирующей функции или группировки по этой колонке. Для «обычных» агрегатов хотя бы одно из этих условий обязательно должно соблюдаться, поскольку в противном случае возникнет неоднозначность –Но на аналитические агрегаты вышеописанное ограничение не распространяется, поскольку степень детализации не уменьшается и, как следствие, не возникает неоднозначности. Что и можно наблюдать на примере второго запроса – результат агрегирующей функции просто продублировался для каждой записи внутри группы, поскольку результат агрегата для каждой записи внутри «окна» совпадает.
Самое время разобраться с синтаксисом – он довольно прост. После функции указывается конструкция
| OVER ([PARTITION BY <value_expression> , ... [n]]) |
где <value_expression> – список полей, по которым производится группировка, при этом использование алиасов или выражений не допускается. Собственно, таким образом и формируется «окно» для работы аналитической функции. В «окно» попадают все записи, сгруппированные по указанной колонке. Эта группировка делает практически то же самое, что и оператор GROUP BY, но с парой отличий. Во-первых, как уже говорилось, такая группировка производится по уже сформированной выборке, а во-вторых, она распространяется только на тот агрегат, после которого идет конструкция OVER (…), а не на все колонки. И если есть необходимость использовать две аналитические функции в одном запросе, то для каждой функции конструкция OVER (…) указывается отдельно.
Строго говоря, результат запроса с аналитической суммой полностью аналогичен результату такого запроса, написанного в «старом стиле»:
| SELECT s.ID_Trans, s.ID_Customer, t.sum_amount FROM sample s INNER JOIN (SELECT sum(Amount) sum_amount, ID_Customer FROM sample GROUP BY ID_Customer ) t ON s.ID_Customer = t.ID_Customer |
Более того, планы обоих запросов также абсолютно идентичны. Но, во-первых, запись с применением аналитических агрегатов выглядит короче и понятнее, а во вторых, не стоит забывать, что мы имеем дело все еще не с финальной версией продукта и, возможно, к релизу сервер научится их оптимизировать.
В качестве аналитических функций могут также выступать и собственноручно написанные агрегаты.
Функции ранжированияПомимо обычных агрегатов, для аналитических запросов вводятся функции ранжирования. Эти функции возвращают ранг каждой записи внутри «окна». В общем случае рангом является некое число отражающее положение или «вес» записи относительно других записей в том же наборе. Формируется «окно» точно так же, как и в случае агрегатных функций – с помощью группировки. Однако, поскольку результат работы функций ранжирования зависит от порядка обработки записей, то обязательно должен быть указан порядок записей внутри «окна» посредством конструкции ORDER BY. В зависимости от используемой функции некоторые записи могут получать один и тот же ранг. Функции ранжирования являются не детерминированными, то есть при одних и тех же входных значениях они могут возвращать разный результат.
На данный момент имееется 4 функции ранжирования, рассмотрим их по порядку:
ROW_NUMBER()
Сбылась голубая мечта жаждущих нумерации записей на сервере. :) Теперь такая возможность появилась, однако это не основное назначение данной функции… Все-таки она призвана нумеровать записи в указанном порядке внутри «окна». Но если в конструкции OVER опустить секцию PARTITION BY, то за «окно» будет принята вся выборка – что дает возможность пронумеровать все записи в должном порядке, причем порядок нумерации может не совпадать с порядком записей в результирующей выборке, то есть оператор ORDER BY внутри OVER(…), определяющий порядок сортировки записей внутри «окна», и, соответственно, порядок нумерации записей может не совпадасть с оператором ORDER BY в конструкции SELECT, определяющей порядок выдачи записей клиенту. Нумерация всегда начинается с единицы.
RANK()
Эта функция предназначена для ранжирования записей внутри «окна», но опять-таки, если колонка для группировки не задана явным образом, то за «окно» принимается вся выборка. Рангом каждой записи является количество уже ранжированных записей с более высоким рангом, чем текущая, плюс единица. Если встретятся несколько записей с одинаковым значением, по которому производится ранжирование, то этим записям будет присвоен одинаковый ранг. Однако при этом следующая запись с новым значением получит такой ранг, как будто бы предыдущие записи получили свой уникальный номер, то есть образуется дырка.
Звучит запутанно... :) Однако если по-простому, то это та же нумерация, что и в ROW_NUMBER(), которая начинается с той же единицы. Различие в том, что одинаковые записи получают одинаковый номер, а следующая отличающаяся от них запись получает такой номер, как если бы ROW_NUMBER() и использовалась, и все предыдущие записи получили свои уникальные номера. Таким образом, образуется дырка в нумерации, равная количеству одинаковых записей минус единица.
DENSE_RANK()
Эта функция выполняет «плотное» ранжирование, то есть делает ровно то же самое, что и предыдущая, но без «дырок» в нумерации.
NTILE()
Данная функция позволяет разделить записи внутри «окна» на указанное количество групп. Для каждой записи она вернет номер группы, к которой принадлежит данная запись. Нумерация групп также начинается с единицы. Если количество записей в «окне» не делится на количество групп, то получится два типа групп с разным количеством записей, отличающимся на единицу, при этом сначала будут выведены группы с большим количеством записей, а затем – с меньшим.
Для демонстрации различий функций ранжирования можно выполнить следующий запрос:
| SELECT ID_Customer, Amount, ROW_NUMBER() OVER(PARTITION BY ID_Customer ORDER BY Amount DESC) N_Row, RANK() OVER(PARTITION BY ID_Customer ORDER BY Amount DESC) RANK, DENSE_RANK() OVER(PARTITION BY ID_Customer ORDER BY Amount DESC) DENSE_RANK, NTILE(2) OVER(PARTITION BY ID_Customer ORDER BY Amount DESC) NTILE –- выведем только одну группу для экономии места FROM sample WHERE ID_Customer = 2 ID_Cust Amnt N_Row RANK D_RANK NTILE ------------------------------------------------------- 2 400 1 1 1 1 2 220 2 2 2 1 2 202 3 3 3 2 2 200 4 4 4 2 2 200 5 4 4 3 2 100 6 6 5 4 |
Некоторые примеры использования
Как уже говорилось, практически все, что можно сделать с помощью аналитических функций, можно сделать и без них, но с их использованием требуемого эффекта можно добиться проще и, зачастую, оптимальнее...
Поскольку теперь появилась возможность нумеровать записи в выборке, можно воспользоваться этим для постраничной выдачи результата. Запрос будет выглядеть примерно так:
| WITH Numbered ( SELECT ROW_NUMBER() OVER(ORDER BY name) N_Row, * FROM sysobjects ) SELECT * FROM Numbered WHERE N_Row between @First AND @Last |
Как ни странно, этот запрос будет выполняться примерно в два раза быстрее классического:
| EXECUTE ('SELECT * FROM (SELECT TOP ' + @Count + ' * FROM (SELECT TOP ' + @Last + ' * FROM sysobjects ORDER BY name ASC ) SO1 ORDER BY name DESC) SO2 ORDER BY name') |
Так что сбылась еще одна мечта, об эффективной и простой постраничной выборке.. :)
Еще один пример, где использование аналитических функций может быть и удобным, и эффективным. Нередко требуется вывести, например, два самых крупных заказа для каждого клиента. Может случиться так, что заказов с максимальной суммой окажется больше двух. Для случая, когда заказов должно быть именно два, запрос может выглядеть так:
| WITH Ranked as ( SELECT *, Row_Number() OVER (PARTITION BY ID_Customer ORDER BY amount DESC) [rank] FROM sample ) SELECT * FROM Ranked WHERE [rank] < 3 |
Такой запрос на этих данных примерно в 10 раз эффективнее, чем этот же запрос, выполненный в «старом стиле»:
| SELECT * FROM sample s1 WHERE ID_Trans in ( SELECT top 2 ID_Trans FROM sample s2 WHERE s1.ID_Customer = s2.ID_Customer ORDER BY amount DESC ) |
Более того, разница в скорости будет ощутимо расти с увеличением количества данных в таблице, поскольку в первом случае алгоритм довольно прост – внутренним запросом нумеруются записи внутри групп, практически за одну сортировку, а затем фильтром во внешнем запросе отсекаются все лишние записи. Во втором же случае, внутренний подзапрос выполняется заново, для каждой записи в таблице. Все это очень хорошо видно на планах запросов. На втором плане количество ожидаемых выполнений подзапроса – пятнадцать, так как в тестовой табличке 15 записей.
План запроса с аналитической функцией:
| Операция Стоимость Количество ---------------------------------------------------------- |--Filter(WHERE:([Expr1003]<(3))) 0.022873 1 |--Sequence Project(...) 0.022866 1 |--Segment 0.022866 1 |--Segment 0.022866 1 |--Sort(ORDER BY:(...)) 0.022864 1 |--Clustered Index Scan(...) 0.006423 1 |
План запроса без использования аналитической функции:
| Операция Стоимость Количество ----------------------------------------------------------- |--Nested Loops(Left Semi Join …) 0.18998 1 |--Clustered Index Scan(…) 0.00642 1 |--Filter(WHERE:(…)) 0.18350 15 |--Top(TOP EXPRESSION:((2))) 0.18348 15 |--Filter(WHERE:(…)) 0.18348 15 |--Sort(ORDER([Amount] DESC)) 0.18343 15 |--Clustered Index Scan(…) 0.00665 15 |
Ложка дегтя
Все это, конечно, здорово и замечательно, но есть некоторые негативные моменты, которые уменьшают радость от получения нового инструмента. Он, конечно, хорош, но пока что еще очень беден и не развит. Не считая встроенных агрегирующих функций, в SQL 2005 реализовано всего 4 ранжирующих функции, в то время как в ANSI SQL 2003 больше 30 различных типов аналитических функций...
Обидно и другое.. Как можно заметить, в синтаксисе для аналитических агрегатов отсутствует возможность указать сортировку внутри «окна». Для обычных, встроенных агрегатов это не имеет никакого значения, но в SQL Server 2005 появится возможность писать свои собственные агрегаты на CLR-совместимых языках, которыми, при желании, можно было бы расширить список функций, и вот для этих самодельных агрегирующих функций подобная возможность могла бы быть весьма полезной. Без возможности указать порядок сортировки записей в «окне» невозможно использовать целый класс агрегирующих функций, зависимых от порядка обработки данных. В принципе, ничто не мешает в процессе работы собственной агрегирующей функции складывать данные в некоторую коллекцию, сортировать их там должным образом, а затем обрабатыватать в требуемом порядке, но, очевидно, это не идеальное решение, так как приходится выполнять работу сервера.
Самое забавное, что при написании пользовательской агрегирующей функции можно указать с помощью специального атрибута, зависит ли результат от порядка обработки записей, но в отсутствие возможности указать этот самый порядок обработки, данный атрибут бесполезен. Видимо, те ребята, которые писали поддержку пользовательских агрегирующих функций, предусмотрели возможность создания функций, зависимых от порядка обработки данных, а вот у тех, кто писал аналитические функции, руки пока не дошли. Очень хочется верить, что к релизу дойдут...
Так же навевает грустные мысли очень бедный механизм указания «окна» для аналитической функции. На данный момент есть только один способ задать это «окно» – группировка. То есть, «окно» можно задать только с помощью указания колонки, одинаковые значения записей в которой являются признаком принадлежности к «окну». Однако возможности указания «окна» могут быть гораздо шире, но в текущей версии все это великолепие пока что отсутств
Похожие работы
].[OrdersQueue]( [QueueID] [int] IDENTITY(1,1) NOT NULL, [OrderID] [int] NOT NULL ) Новые возможности T-SQL В начале статьи будут рассмотрены новые функции и операторы T-SQL в SQL Server 2005 и примеры их использования, изменения, затронувшие имевшийся ранее оператор TOP, после чего рассказано о новой возможности обработки ошибок в T-SQL. Общие табличные выражения Общие табличные ...
... продукции российских софтверных компаний: ПроМТ, ABBYY, ИНЭК, Лаборатория Касперского и более 100 других. Общая архитектура "1С: Комплексная автоматизация 8" А) стандартные: Общие механизмы Система 1С: Предприятие 8 имеет в своей основе ряд механизмов, определяющих концепцию ...
... данных базы и их представление. С помощью встроенных средств и инструментов базы данных создается пользовательский интерфейс, позволяющий управлять процессами ввода, хранения, обработки, обновления и представления информации базы данных.[2] 4 ЭТАПЫ РАЗРАБОТКА ПРОГРАММНОГО ПРОДУКТА Данная программа создана для учета успеваемости студентов. Для работы с программой необходимо нужные группы или ...
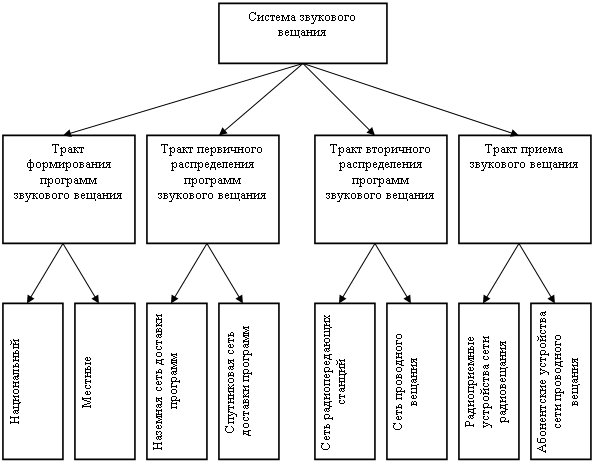
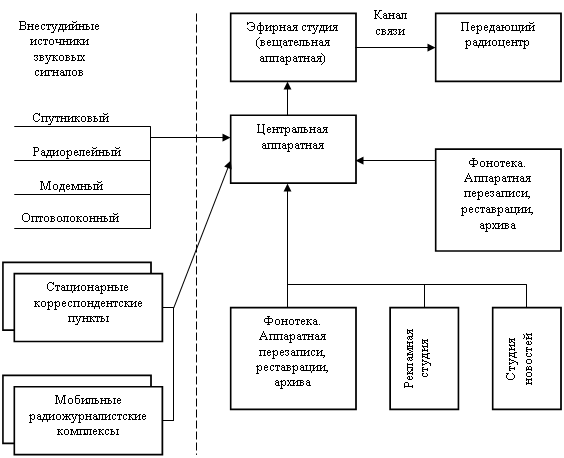
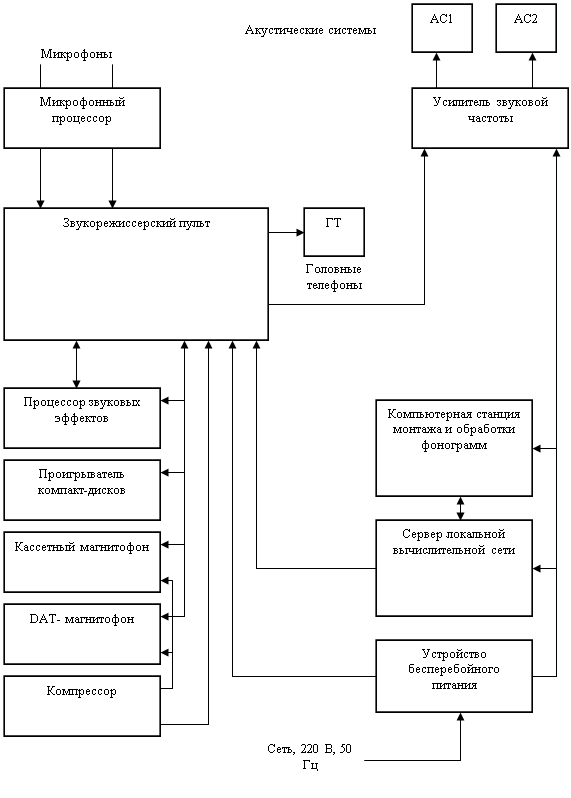
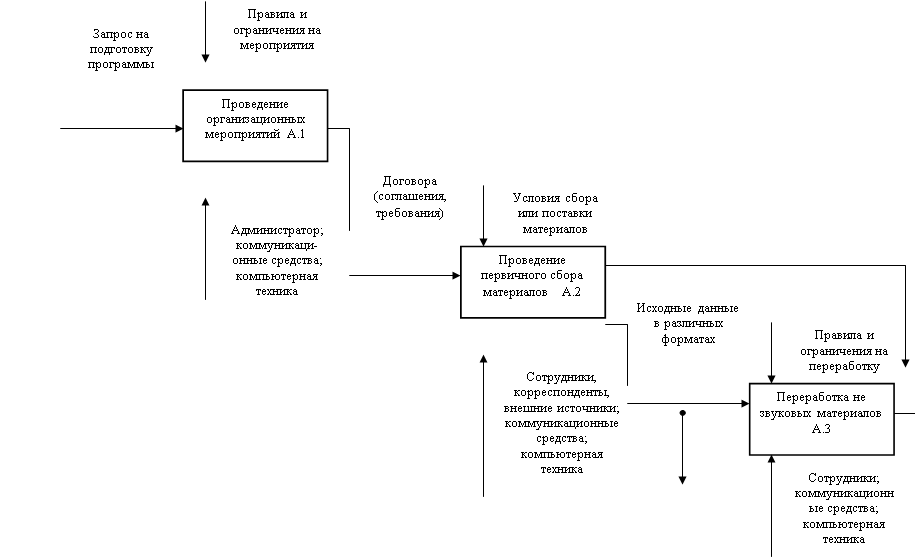
... Выдача справки пользователь может получить дополнительные сведения о предметной области и структуре таблиц базы данных. 3. Экономические расчеты Спроектированное в данном проекте автоматизированное рабочее места специалиста по формированию программ радиовещания позволяет автоматизировать деятельность играющего важную роль в бизнес-процессе радиостанции работника, дает возможность повысить ...
0 комментариев