Навигация
Развитие систем управления базами данных
39497
знаков
0
таблиц
3
изображения
Введение
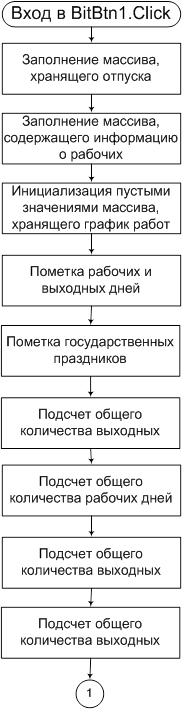


Общая тенденция развития систем управления базами данных показывает, что распределенные системы получают все большее развитие и распространение. Этому способствует как мировая глобализация, которая приводит к ускорению процессов централизации и децентрализации информационных систем, так и технический прогресс в области хранения и передачи данных. Растут объемы и быстродействие накопителей информации. Все большей становится доля оптоволоконных каналов связи, которые позволяют передавать огромные массивы данных с невиданной до сих пор скоростью. Кроме того, ширится выпуск персональных домашних компьютеров и ноутбуков. Все это вкупе с прогрессирующим снижением стоимости коммуникационных услуг ведет к росту количества удаленных рабочих групп (офисов), а также расширению числа работников, выполняющих свои функции вне своего офиса или основного рабочего места. Эти факторы и способствуют развитию распределенных систем и, соответственно, распределенных баз данных.
Распределенные базы данных
По общему мнению, Россия и другие страны СНГ, обладая большой территорией, просто обречены на создание и развитие информационных систем на основе распределенных баз данных. Не секрет, что практически все преуспевающие средние и крупные региональные компании имеют свои представительства в Москве и/или Петербурге. Поэтому при управлении такими предприятиями не обойтись без сложных корпоративных распределенных информационных систем. Ярким примером распределенной базы данных является система DNS:
Практика показывает, что обычно решение вопроса создания корпоративной ИС ищется в уже достаточно освоенной и всем знакомой плоскости клиент-сервер на базе локальной сети с централизованной базой данных.
Выбирается одна из популярных многопользовательских СУБД и доступные средства для быстрой разработки приложений (как правило, это пара Interbase/Delphi). Создается система, включающая в себя одну или несколько баз данных, а также набор обращающихся к ней (к ним) приложений, реализующих прикладные функции, необходимые конечному пользователю. Данная технология весьма неплохо работает в ограниченном масштабе, например, в рамках одного офиса или нескольких удаленных рабочих групп-филиалов, связанных с головным предприятием. Однако время не стоит на месте, компания расширяется и выходит на тот уровень, когда новые задачи требуют децентрализации хранения и обработки данных и, соответственно, качественного скачка в развитии информационной системы. В этом случае технология клиент-сервер, реализованная на основе централизованной базы данных, уже не может удовлетворить новых потребностей. Информационная система становится неработоспособной и ее приходится фактически создавать заново. Очевидно, что обычные системы "клиент-сервер" могут развиваться только по эволюционному экстенсивному пути в ограниченном масштабе и становятся неэффективными, когда экстенсивные пути развития исчерпывают свои возможности. Затраты на модификацию и сопровождение такой системы в критический момент становятся сравнимыми с затратами на создание новой системы. Выходом из тупика может служить применение распределенных баз данных (БД).
В зависимости от архитектуры, можно выделить локальные и распределенные БД. Все части локальной БД размещаются на одном компьютере, а распределенной — на нескольких. Исторически, развитие баз данных, как локальных, так и распределенных, шло от иерархических моделей к сетевым и реляционным.
Первые иерархические и сетевые СУБД были созданы в начале 60-х годов прошлого века. Причиной послужила необходимость управления огромным количеством записей, связанных друг с другом, как правило, иерархическим образом (обслуживание выборов, переписей населения, моделирование ядерных испытаний, погодных и геологических явлений, информационное обеспечение космических полетов и т. д.). Причиной выбора иерархической модели во многом послужило ее подобие уже имевшимся и хорошо отработанным и освоенным на практике многочисленным массивам информации на неэлектронных носителях (банки данных, картотеки, досье, справочники). Среди реализованных на практике СУБД этого типа следует отметить системы IMS (Information Management System) компании IBM, а также TDMS (Time-Shared Date Management System) компании Development Corporation; Mark IV Multi — Access Retrieval System компании Control Data Corporation; System — 2000 разработки SAS-Institute.
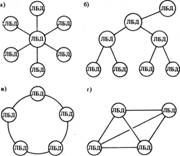
Отношения в иерархической модели данных организованы в виде совокупностей деревьев, где дерево — структура данных, в которой тип сегмента потомка связан только с одним типом сегмента предка (рис. 1.1).
Рис. 1.1. Иерархическая модель БД

В терминологии баз данных, это адекватно наличию жестких связей «один - к – одному» или «один - ко – многим» между записями. К недостаткам и ограничениям иерархической модели данных можно отнести: отсутствие явного разделения логических и физических характеристик модели, что выражается в жесткой привязке БД к носителю-информации, потребность в дополнительных затратах и ухищрениях для описания неиерархических связей, что обуславливает низкую гибкость модели, не позволяющую ей эволюционировать в изменяющихся условиях.
Сетевая модель данных — это представление сетевыми структурами типа запись данных, связанных отношениями «один - к – одному» или «один - ко – многим» (рис. 1.2). Основная идеология и стандартные требования к этой модели были разработаны комитетом Database Task Group (DTBG) на рубеже 60—70-х годов. Впервые сетевая архитектура была реализована в СУБД Integrated Data Store (IDS) компании General Electric и IDMS компании Computer Associates.
Рис. 1.2. Сетевая модель БД
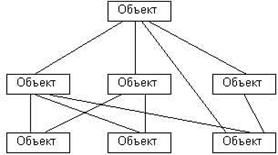
В отличие от иерархической модели, в сетевой допускается наличие нескольких связей от сегмента-потомка к сегментам-предкам.
Сетевая модель допускает также использование в базах данных связей «многие - ко – многим». Это позволяет устранить многие недостатки иерархической модели, такие как: низкую приспособленность к описанию данных неиерархической структуры и слабую гибкость при развитии системы.
Реляционная модель была описана в 1970—1971 годах в работах Е. Ф. Кодда. Она основана на процедурном языке обработки таблиц данных и языке запросов. В сетевой и иерархической моделях использовались жесткие физические подходы к связыванию записей из разных файлов путем применения физических указателей или адреса на диске. Такие базы существенно затрудняют и ограничивают операции над данными. Кроме того, является очевидным, что иерархические и сетевые базы данных весьма чувствительны к аппаратным изменениям. Перенос данных с одного накопителя на другой, или вообще Изменение числа приводит к необходимости внимательно и кропотливо изменять адреса в связях записей на новые. Также такие модели чувствительны к реструктуризации самой базы (добавление или удаление новых полей приводит к изменению физических адресов записей). Все эти проблемы преодолела реляционная модель, основанная на логических отношениях данных. Именно реляционная модель породила все современные известные СУБД, ее детищем является SQL, благодаря использованию реляционной модели возможно создание распределенных баз данных.
Под распределенной БД (Distributed DataBase — DDB) обычно подразумевают базу данных, включающую фрагменты из нескольких баз данных, которые располагаются на различных узлах сети компьютеров, и, возможно, управляются различными СУБД. Распределенная база данных выглядит с точки зрения пользователей и прикладных программ как обычная локальная база данных. В этом смысле слово «распределенная» отражает способ организации базы данных, но не ее внешнюю характеристику.
Согласно принципам, изложенным в трудах известного ученого Дейта, можно выделить:
Похожие работы
... и прикладных программ (логическая независимость данных) и возможность изменения физического расположения и организации данных без изменения общей логической структуры данных и структур данных прикладных программистов (физическая независимость). Рис. 1 2. Системы управления базами данных Использование систем управления базами данных (СУБД) позволяет исключить из прикладных программ ...
... быстро создавать необходимые компоненты приложений, критичные по скорости работы, которые трудно, а иногда невозможно разработать средствами "классических" СУБД. Современный подход к управлению базами данных подразумевает также широкое использование технологии "клиент-сервер". Таким образом, на сегодняшний день разработчик не связан рамками какого-либо конкретного пакета, а в зависимости от ...
... C++, которые позволяют быстросоздавать необходимые компоненты приложений, критичные по скорости работы, которые трудно, а иногда невозможно разработать средствами «классических» СУБД.Современный подход к управлению базами данных подразумевает также широкое использование технологии «клиент-сервер». Таким образом, на сегодняшний день разработчик не связан рамками какого-либо конкретного ...
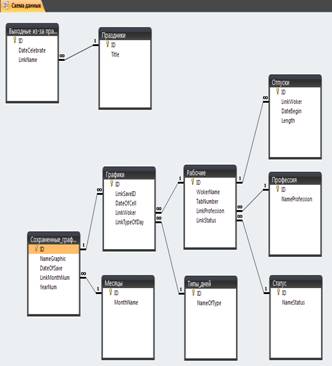
... , обслуживании клиентов в сервисных системах, составление расписаний занятий в учебных заведениях и т.д. Задание В рамках данной курсовой работы необходимо разработать программное обеспечение по управлению базой данных « График учета рабочего времени на шахте им. Т. Кузембаева в цехе «Автоматика»» с использованием СУБД. Программное обеспечение должно обеспечивать просмотр, редактирование, ...
0 комментариев