Навигация
Распознавание образов (на примере цифр)
23868
знаков
0
таблиц
4
изображения
Факультет математики и компьютерных наук
Кафедра информационной безопасности
Курсовая работа
по дисциплине «Языки программирования»
на тему «Распознавание образов (на примере цифр)»
Т 2009 г.
Оглавление
Введение
Глава 1. Принципы распознавания образов
1.1 Система распознавание образов
1.2 Нейронные сети
1.2.1 Распознавание образов
Глава 2. Описание программного средства
2.1 Алгоритм
2.2 Техническая реализация
2.3 Описание пользовательского интерфейса
Заключение
Приложение 1
Список литературы
Введение
Программа предназначена для распознавания цифр .
Основой программы является нейросеть, имитирующая искусственный интеллект, тем самым, позволяя обучать программу и запоминать образы цифр, для верного распознавания их при последующем использовании программы.
Актуальность программы обусловлена популярностью на рынке программных продуктов подобного типа (для распознавания образов) и их широкого применения в КПК, смартфонах, ноутбуках, т.д.. Программное обеспечение для распознавания образов разрабатывается многими компаниями и является одним из инновационных продуктов на современном рынке.
Глава 1
Принципы распознавания образов
1.1 Система распознавания образов
Задача распознавания (точнее, классификации) объекта ставится следующим образом. Имеется некоторый способ кодирования объектов (например, рукописных букв), принадлежащих заранее известному конечному множеству классов C={C1 ,...,Cq}, и некоторое конечное множество объектов (обучающее множество), про каждый из которых известно, какому классу он принадлежит. Нужно построить алгоритм, который по любому входному объекту, не обязательно принадлежащему обучающему множеству, решает, какому классу этот объект принадлежит, и делает это достаточно хорошо. Качество распознавания оценивается как вероятность (т.е.частота) ошибки классификации на другом конечном множестве объектов с заранее известными ответами (тестовом множестве).
Типичная система распознавания состоит из трех частей: извлечение признаков, собственно распознавание и принятие решения.
Извлечение признаков - это преобразование входных объектов к единообразному, компактному и удобному виду с потерей подавляющей части содержащейся в объекте информации, слабо влияющей на классификацию. Удобным оказывается представление объекта точкой стандартного евклидова пространства Rd, принадлежащей некоторому фиксированному компакту (кубу, шару, сфере, ...). Размерность d должна быть достаточно большой для успешного (в смысле качества) распознавания и достаточно малой для успешного (в смысле скорости) распознавания - реально это порядка нескольких десятков. Способ извлечения признаков зависит от природы и исходной кодировки объектов и подбирается вручную. Например, траекторию мыши или пера, исходно закодированную последовательностью произвольной длины (порядка сотни), состоящей из пар координат точки, удобно кодировать последовательностью фиксированной длины пар коэффициентов аппроксимирующих траекторию полиномов небольшой степени (порядка десятка), да еще и свободные члены можно отбросить, как не влияющие на классификацию. Желаемые значения F в точках пространства признаков, соответствующих обучающему множеству, известны, так что остается только построить в некотором смысле аппроксимирующее отображение. Качество аппроксимации будет проверяться не на всей области определения, а только на тестовом множестве. Интерпретацией вычисленных вероятностей занимается отдельная от распознавания процедура принятия решений, которая строится вручную и не зависит ни от природы входных объектов, ни от пространства признаков, ни от обучающих данных. Она зависит только от того, для чего эта система распознавания предназначена. Например, если она используется как безответственная гадалка, то она просто выдает номер наиболее вероятного класса. Если она используется как ответственная гадалка, то она выдает номер наиболее вероятного класса, если его вероятность существенно больше вероятностей других классов, и отвечает ``не знаю'' в противном случае. Если она используется для генерации гипотез, то она выдает номера нескольких (например, пяти) наиболее вероятных классов и их вероятности.
В прошлом веке на уроках чистописания первоклассников сначала долго заставляли рисовать палочки, крючочки и кружочки, и только потом учили складывать из них буквы. В реальной жизни люди тоже пишут (и распознают!) буквы как последовательности небольших типовых элементов, но не столь единообразных, как в прописях. Например, две вертикальные палочки, перечеркнутые горизонтальной, - это, вероятно, буква `Н'. И если вертикальные палочки - не совсем палочки или не совсем вертикальные, то все равно `Н'. Но если они сверху сближаются, то больше похоже на `А', а если горизонтальная палочка находится высоко, то на `П'.
При машинном распознавании удобнее выделять не только и не столько палочки и крючочки, сколько способы их стыковки друг с другом: направленные в разные стороны галочки, петельки, Т-образные ветвления и т.п. Предположим, что эта черновая работа проделана, и изучаемый фрагмент рукописного текста закодирован в виде последовательности таких характеристических элементов, упорядоченных как-то слева направо сверху вниз. Вопрос: насколько эта последовательность похожа на букву `А'? Тот же вопрос для всех остальных распознаваемых символов.
Попробуем смоделировать построение одной буквы в виде последовательности элементов. Во-первых, буква может иметь несколько существенно различных написаний (например, `А' треугольное, `А' треугольное с завитушками, `А' круглое, ...) и их нужно моделировать отдельно. Во-вторых, даже одно написание одной буквы в зависимости от почерка порождает разные последовательности характеристических элементов. В-третьих, кроме правильных написаний бывают неправильные (рука дрогнула, клякса, ручка плохо пишет, ...). Всех возможностей не предусмотришь, поэтому будем моделировать только несколько наиболее часто встречающихся вариантов и то, что получается из них небольшими возмущениями.
Выписывание последовательности Qi1,...,QiL из L характеристических элементов поручим детерминированному конечному автомату с L+1 состояниями с1,...,сL+1, который в каждом l-м, l L, состоянии Cl порождает элемент Qil и переходит в следующее состояние. А для порождения возможных ``небольших возмущений'' последовательности превратим автомат в стохастический: в i-м состоянии он может порождать любой элемент Qj с вероятностью bij и с вероятностью aij
переходить в близкое к i+1-му j-е состояние. Как правило, aij > 0 только при i j i+2, т.е. кроме перехода в следующее состояние допускаются проскакивание его и задержка в текущем состоянии. Существенно, что aij=0 при i > j. Такие модели называются LR-моделями (left-right, слева направо). Вероятности bi,ij и ai,i+1 унаследованных от детерминированного автомата действий естественно полагать близкими к 1, а остальные положительные вероятности - близкими к 0, хотя это и не обязательно. Заметим, что каждое состояние детерминированного автомата имело точный смысл (``выписано столько-то элементов такой-то последовательности''), а у стохастического автомата этот точный смысл уже утерян.
Автоматы для нескольких вариантов написания символа объединяются в один автомат, моделирующий символ: к их несвязному объединению добавляется общее начальное состояние C0, которое не порождает никакого характеристического элемента и из которого возможны переходы в начальные и вторые состояния всех вариантов, а их конечные состояния склеиваются.
Такая модель символа позволяет ответить на вопрос, насколько какая-то последовательность характеристических элементов похожа на этот символ: настолько, какова вероятность порождения ее моделью символа. Эти вероятности можно вычислить для всех символов и проанализировав их решить, на какой символ эта последовательность более всего похожа, т.е. классифицировать ее.
Распознавание последовательности объектов (например, слов) существенно отличается от распознавания отдельных объектов (например, букв) тем, что разных длинных последовательностей настолько много, что для обучения узнаванию каждой последовательности в лицо требуется абсолютно неприемлемое время. Еще более наглядный пример - распознавание молекул ДНК, являющихся очень длинными словами в алфавите из четырех букв. Поэтому для распознавания последовательностей применяется следующая схема.
- Последовательность более или менее успешно сегментируется на индивидуальные объекты или на кусочки объектов. Алгоритмы сегментации существенно зависят от природы объектов.
- Каждый объект (или набор смежных кусочков) более или менее успешно распознается, например, одним из методов, описанных в разделе
- Из ответов распознавателя объектов склеивается результат распознавания последовательности в целом. Алгоритмы склеивания могут быть специфичны для данных объектов (например, для распознавания слов на известном языке можно пользоваться словарем, а для распознавания слов на никому не известном языке, а могут быть и универсальны.
Тривиальный алгоритм распознавания - сегментировать, распознать каждый кусочек и в качестве общего ответа выдать последовательность наиболее вероятных ответов - работает плохо. Он не исправляет ошибок сегментации и адекватен только распознаванию случайной последовательности независимых хорошо разделенных объектов. Но во всех интересных задачах распознавания последовательности не случайны, а в случае рукописного текста - еще и плохо разделимы.
Похожие работы
... , бистабильность восприятия. В дальнейшем планируется разработка программных моделей более сложных нейронных сетей и их комбинаций с целью получения наиболее эффективных алгоритмов для задачи распознавания образов. Литераура. 1.Горбань А.Н.,Россиев Д.А..Нейронные сети на персональном компьюере. 2. Минский М.Л.,Пайперт С..Персепроны.М.: Мир.1971 3. Розенблатт Ф.Принципы ...
... его, человек высказывает гипотезы, продвигающие его к знанию распознающей деятельности в природе, что позволяет ему успешно решать стоящие задачи. Рассматриваемый курс “Основы построения систем распознавания образов” и должен научить пониманию того, что лежит в основе современных гипотез распознавательной деятельности и как на этой основе упомянутые задачи решаются.1.1.2. Краткая история вопроса ...

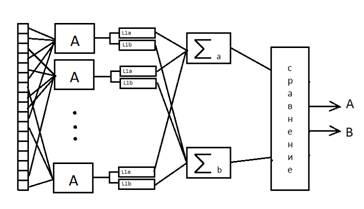
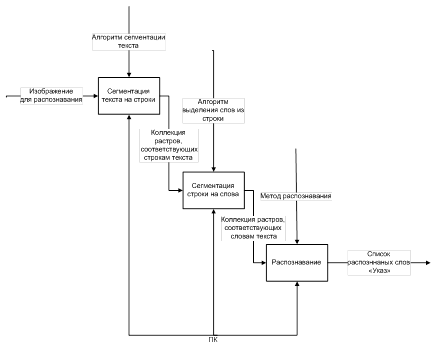
... буквами. При превышении некоторого порога слово "вырезается" из строки. Процесс продолжается до конца строки. Алгоритм сегментации текста представлен в графической части 2.2 Алгоритм распознавания слова. Персептрон Распознавание слова "Указ" в разработанном приложении, реализовано на базе персептрона. Алгоритм обучения персептрона – без учета правильности ответа. Персептрон построен по ...
... мнению академика Российской академии медицинских наук Сергея Колесникова, на показатели смертности влияет множество природных и социальных факторов. «Прежде всего это образ жизни, который формирует 50% состояния здоровья, генетические данные, экология и медицинская помощь», рассказал он в интервью газете ВЗГЛЯД. «И если в рамках нацпроекта «Здравоохранение» власти стали уделять внимание сердечно- ...
0 комментариев