Навигация
Применение скрытых Марковских моделей
19560
знаков
1
таблица
2
изображения
3.1.2 Применение скрытых Марковских моделей
Первым этапом решения задачи чтения по губам является выделение контуров губ; это производится с помощью алгоритма выделения контуров губ на цветном изображении, основанного на алгоритме радиального расширения.
Для работы алгоритма выделения контуров губ необходима подготовка изображений. Изображения переводятся в цветовое пространство (r/g,b/g), что позволяет избежать влияния освещения. На основе нескольких изображений с выделенными областями кожи лица и губ стоятся цветовые классы. Описание цветового класса представляет собой параметры эллипса, внутри которого находится большинство точек класса на двумерной гистограмме в пространстве цветов (r/g,b/g). На основе определенных цветовых классов строится оценочная функция; функция принадлежности цветовому классу кожи учитывается с обратным знаком.
В дальнейшем осуществляется поиск контура с помощью оценочной функции. Первый шаг алгоритма находит приблизительное положение центра области губ на изображении. Второй шаг находит эллипс, описывающий область губ. Третий шаг находит уточненный контур, с помощью модифицированного алгоритма радиального расширения. Схема алгоритма удобна для применения к видеопоследовательностям. В этом случае вместо первого шага для поиска положения центра области губ можно воспользоваться положением центра области губ на предыдущем кадре видеопоследовательности. Процедура выделения контуров губ определяет эллипс, описывающий область рта и набор координат точек. Контур выделяется на наборе изображений, отражающем большинство возможных состояний губ. Для распознавания движений губ необходимо выделить вектора признаков из полученных данных.
Процедура поиска контура губ находит n точек, пронумерованных от p1 до pn по часовой стрелке. Используемые координаты точек нормализуются: средняя точка эллипса считается началом координат, ось x направлена по направлению большего радиуса эллипса, большой радиус эллипса считается единицей. Кроме координат точек, в процессе выделения контуров губ находятся параметры эллипса, описывающего область губ на исходном изображении. Параметры эллипса позволяют сделать выводы о таких общих параметрах области рта, как открыт рот или закрыт. Нумерация контура начинается с места пересечения контура губ левым большим радиусом эллипса.
Затем выполняем поиск углов (рис. 2). Среди полученных точек необходимо определить правый и левый угол. Несмотря на нумерацию точек, это не всегда точки p1 и pn/2. Правым углом считается точка, находящаяся в правой половине контура (между pn/4 и p3n/4), у которой угол α является наименьшим. Угол α - это угол между средними qnext и qprev. Здесь qnext= (pi+1+…+ pi+k)/k, qprev=(pi-1+…+ pi-k)/k, k=n/5. Аналогичное правило используется для левого угла.
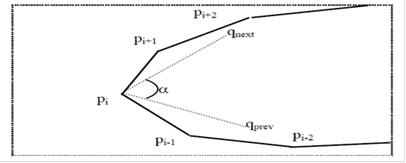
Рисунок 2 - Поиск углов
Следующим шагом после нахождения углов является преобразование набора исходных данных в набор векторов признаков. В качестве нескольких первых элементов в векторе признаков используются признаки, полученные отдельно от координат - отношение высоты эллипса области губ к его ширине. Дальнейшие элементы вектора признаков - это координаты левого и правого угла контура, координаты верхней и нижней точек контура, координаты остальных точек контура. Рассмотрим варианты анализа полученных данных методом главных компонент. Выделение базиса методом главных компонент позволяет найти основные направления, по которым изменяются вектора признаков. Это дает возможность значительно понизить размерность векторов признаков. Метод главных компонент применяется к набору векторов признаков, полученных из набора данных, отражающих большинство возможных состояний губ.
Каждому вектору признаков необходимо поставить в соответствие символ скрытой Марковской модели. Для этого используем метод векторной квантизации. С помощью этого метода пространство векторов признаков разбивается на кластеры, по принципу близости к центрам кластеров - кодовым словам. Набор кодовых слов называется кодовой книгой. Основная сложность метода состоит в построении кодовой книги векторов. Размер кодовой книги определяется количеством состояний губ в исходных данных. Кодовая книга известного размера k строится алгоритмом K средних.
На первом шаге алгоритма случайным образом выбираются k векторов, считающихся кодовыми словами (центрами кластеров). На следующем шаге каждый входной вектор приписывается к тому кластеру, чье кодовое слово находится на наименьшем расстоянии от него. На третьем шаге кодовые слова каждого кластера пересчитываются. Каждое кодовое слово делается равным среднему арифметическому среди всех векторов кластера. Второй и третий шаги повторяются до тех пор, пока изменения кодовых слов не станут достаточно малы.
Этот алгоритм медленный, но применение анализа главных компонент перед квантованием позволяет понизить размерность и, тем самым, значительно ускорить процесс построения кодовой книги. Новые исходные данные перед использованием в процессе распознавания квантуются: каждому вектору ставится в соответствие ближайший вектор из кодовой книги, и в дальнейшем вместо вектора в качестве символа скрытой Марковской модели используется его индекс в кодовой книге.
Распознавание по изображению не может работать на уровне визем, так как виземы для различных фонем достаточно близки. При этом распознавание на основе последовательностей визем - дифонов, трифонов - гораздо более надежно. Для распознавания используется система эргодических скрытых Марковских моделей. Каждому дифону соответствует своя СММ. СММ инициализируются равными вероятностями для символов и переходов между состояниями. Обучение системы СММ производится с помощью последовательности квантованных векторов признаков. Исходные данные вручную разбиваются по обучаемым дифонам, после чего соответствующая СММ обновляется по алгоритму Баума-Велша. Результирующая СММ выдает максимальные значения вероятности на последовательностях, близких к набору для обучения своего дифона.
В результате работы строится эффективный алгоритм построения векторов признаков губ для задачи распознавания речи. Алгоритм позволяет преобразовать данные контуров губ в наборы признаков, пригодных для распознавания. Алгоритм обладает свойствами надежности и устойчивости и легко интегрируется с системой распознавания речи на основе скрытых Марковских моделей.
Похожие работы
... Образ внешнего человека в функционально-семиотическом аспекте (на материале русского языка) // Вест. Омск. ун-та. 2001. Вып. 1. С.68-70 Коротун, 2002 Коротун О.В. Образ-концепт «внешний человек» в русской языковой картине мира: Автореф. дис. … канд. филол. наук. Омск, 2002. Котрюрова, 1997 Котюрова М.П. Стилистический и прагматический подходы к тексту: некоторые основания их дифференциации // ...
... . И.П. Павлову, первому из русских ученых, 7 октября 1904 г. была присуждена Нобелевская премия в знак признания его работ по физиологии пищеварения. Потребность организма в пище проявляется в виде физиологической реакции голода. У человека голод приобретает выраженную субъективную окраску — от относительного безразличия к пище до яркой эмоциональной реакции. Физиологической основой голода ...
... вокруг сотовых телефонов идут давно, количество их растет, из средств роскоши они перешли в категорию обыденных товаров. Угрожают ли мобильники здоровью человека? Результаты измерений некоторых моделей сотовых телефонов, проведенных Центром электромагнитной безопасности, показали, что на расстоянии 5 см от антенны уровень плотности потока мощности составлял до 7 Вт/см, что в несколько тысяч раз ...
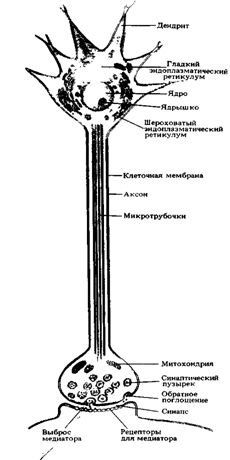
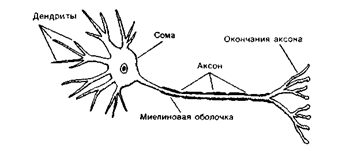
... мозгу (1), где через вставочный нейрон передаются на эфферентные волокна (эфф. нерв), по которым доходят до эффектора. Пунктирные линии - распространение возбуждения от низших отделов центральной нервной системы на ее вышерасположенные отделы (2, 3,4) до коры мозга (5) включительно. Наступающее вследствие этого изменение состояния высших отделов мозга в свою очередь воздействует (см. стрелки) на ...
0 комментариев