Навигация
Анализ эффективности MPI-программ
60039
знаков
6
таблиц
8
изображений
Оглавление
1.Введение. 3
2. Обзор существующих моделей параллельного программирования. 5
3. Обзор средств отладки эффективности MPI-программ. 9
3.1 Общие проблемы всех средств трассировки. 10
3.2 Обзор основных средств отладки. 11
3.2.1 AIMS - Automated Instrumentation and Monitoring System.. 11
3.2.2 Vampir, VampirTrace. 12
3.2.3 Jumpshot 14
3.2.4 Pablo Performance Analysis Toolkit Software. 15
3.2.5 Paradyn. 17
3.2.6 CXperf 18
4. Характеристики и методика отладки DVM-программ. 20
4.1 Основные характеристики производительности. 20
4.2 Методика отладки эффективности. 22
4.3 Рекомендации по анализу. 23
5. Средство анализа эффективности MPI программ. 27
5.1. Постановка задачи. 27
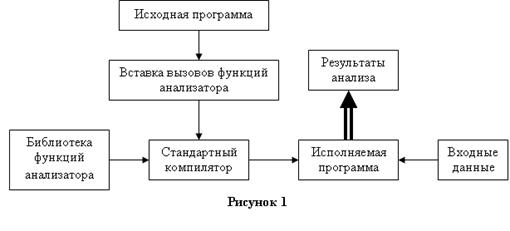
5.2 Этапы работы анализатора. 28
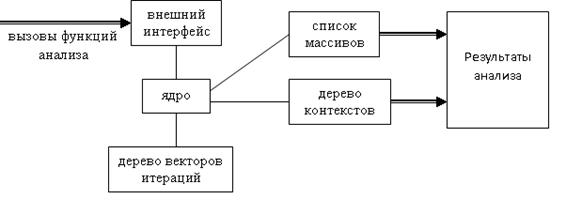
5.3 Устройство анализатора. 29
5.3.1 Сбор трассы.. 29
5.3.2 Анализ. 30
5.3.3 Визуализация. 35
Заключение. 37
Список литературы.. 39
Приложение 1. 40
Приложение 2. 40
1.Введение
Сегодня невозможно представить себе эффективную организацию работы без применения компьютеров в таких областях, как планирование и управление производством, проектирование и разработка сложных технических устройств, издательская деятельность, образование - словом, во всех областях, где возникает необходимость в обработке больших объемов информации. Однако наиболее важным по-прежнему остается использование их в том направлении, для которого они собственно и создавались, а именно, для решения больших задач, требующих выполнения громадных объемов вычислений. Такие задачи возникли в середине прошлого века в связи с развитием атомной энергетики, авиастроения, ракетно-космических технологий и ряда других областей науки и техники.
В наше время круг задач, требующих для своего решения применения мощных вычислительных ресурсов, еще более расширился. Это связано с тем, что произошли фундаментальные изменения в самой организации научных исследований. Вследствие широкого внедрения вычислительной техники значительно усилилось направление численного моделирования и численного эксперимента. Численное моделирование, заполняя промежуток между физическими экспериментами и аналитическими подходами, позволило изучать явления, которые являются либо слишком сложными для исследования аналитическими методами, либо слишком дорогостоящими или опасными для экспериментального изучения. При этом численный эксперимент позволил значительно удешевить процесс научного и технологического поиска. Стало возможным моделировать в реальном времени процессы интенсивных физико-химических и ядерных реакций, глобальные атмосферные процессы, процессы экономического и промышленного развития регионов и т.д. Очевидно, что решение таких масштабных задач требует значительных вычислительных ресурсов[12].
Вычислительное направление применения компьютеров всегда оставалось основным двигателем прогресса в компьютерных технологиях. Не удивительно поэтому, что в качестве основной характеристики компьютеров используется такой показатель, как производительность - величина, показывающая, какое количество арифметических операций он может выполнить за единицу времени. Именно этот показатель с наибольшей очевидностью демонстрирует масштабы прогресса, достигнутого в компьютерных технологиях.
В настоящее время главным направлением повышения производительности ЭВМ является создание многопроцессорных систем с распределенной памятью. Создание прикладных программ для подобных распределенных систем наталкивается на ряд серьезных трудностей. Разработка параллельной программы требует выбора или создания подходящего вычислительного метода. При этом для достижения требуемой эффективности приходится многократно проходить путь от спецификации алгоритма к программе на языке программирования, который для параллельных вычислительных систем оказывается гораздо более сложным, чем для последовательных.
При переходе от одного процессора к нескольким резко возрастает сложность программирования. И многие традиционные подходы здесь уже не работают. Причём если на мультипроцессорной системе достаточно правильно распределить вычисления, то в случае распределённой системы необходимо ещё распределить данные, и самое главное, нужно, чтобы распределение данных и вычислений было согласованным.
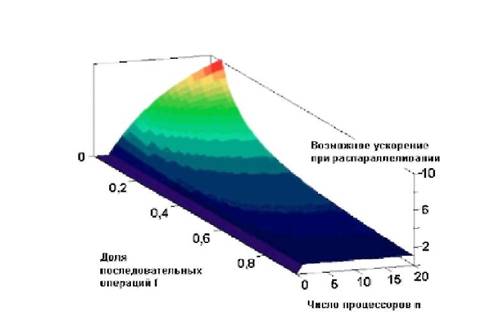
Одной из ключевых проблем является проблема эффективности компьютерной программы. Важно видеть, какой эффект дает распараллеливание нашей программы и что можно сделать, чтобы максимизировать этот эффект.
Эффективность выполнения параллельных программ на многопроцессорных ЭВМ с распределенной памятью определяется следующими основными факторами:
· степенью распараллеливания программы - долей параллельных вычислений в общем объеме вычислений;
· равномерностью загрузки процессоров во время выполнения параллельных вычислений;
· временем, необходимым для выполнения межпроцессорных обменов;
· степенью совмещения межпроцессорных обменов с вычислениями;
· эффективностью выполнения вычислений на каждом процессоре (а она может варьироваться значительно в зависимости от степени использования кэша).
Методы и средства отладки производительности параллельной программы существенно зависят от той модели, в рамках которой разрабатывается параллельная программа.
2. Обзор существующих моделей параллельного программирования
Для организации доступа к данным на многопроцессорных ЭВМ требуется взаимодействие между её процессорами. Это взаимодействие может происходить либо через общую память, либо через механизм передачи сообщений – две основные модели параллельного выполнения программы. Однако эти модели являются довольно низкоуровневыми. Поэтому главным недостатком выбора одной из них в качестве модели программирования является то, что такая модель непривычна и неудобна для программистов, разрабатывающих вычислительные программы.
Можно отметить системы автоматического распараллеливания, которые вполне успешно использовались на мультипроцессорах. А использование этих систем на распределённых системах существенно затруднено тем, что
Во-первых, поскольку взаимодействие процессоров через коммуникационную систему требует значительного времени (латентность – время самого простого взаимодействия - велика по сравнению со временем выполнения одной машинной команды), то вычислительная работа должна распределяться между процессорами крупными порциями.
Во-вторых, в отличие от многопроцессорных ЭВМ с общей памятью, на системах с распределенной памятью необходимо произвести не только распределение вычислений, но и распределение данных, а также обеспечить на каждом процессоре доступ к удаленным данным - данным, расположенным на других процессорах. Для обеспечения эффективного доступа к удаленным данным требуется производить анализ индексных выражений не только внутри одного цикла, но и между разными циклами. К тому же, недостаточно просто обнаруживать факт наличия зависимости по данным, а требуется определить точно тот сегмент данных, который должен быть переслан с одного процессора на другой.
В третьих, распределение вычислений и данных должно быть произведено согласованно.
Несогласованность распределения вычислений и данных приведет, вероятнее всего, к тому, что параллельная программа будет выполняться гораздо медленнее последовательной. Согласованное распределение вычислений и данных требует тщательного анализа всей программы, и любая неточность анализа может привести к катастрофическому замедлению выполнения программы.
В настоящее время существуют следующие модели программирования:
Модель передачи сообщений. MPI.[1]
В модели передачи сообщений параллельная программа представляет собой множество процессов, каждый из которых имеет собственное локальное адресное пространство. Взаимодействие процессов - обмен данными и синхронизация - осуществляется посредством передачи сообщений. Обобщение и стандартизация различных библиотек передачи сообщений привели в 1993 году к разработке стандарта MPI (Message Passing Interface). Его широкое внедрение в последующие годы обеспечило коренной перелом в решении проблемы переносимости параллельных программ, разрабатываемых в рамках разных подходов, использующих модель передачи сообщений в качестве модели выполнения.
В числе основных достоинств MPI по сравнению с интерфейсами других коммуникационных библиотек обычно называют следующие его возможности:
· Возможность использования в языках Фортран, Си, Си++;
· Предоставление возможностей для совмещения обменов сообщениями и вычислений;
· Предоставление режимов передачи сообщений, позволяющих избежать излишнего копирования информации для буферизации;
· Широкий набор коллективных операций (например, широковещательная рассылка информации, сбор информации с разных процессоров), допускающих гораздо более эффективную реализацию, чем использование соответствующей последовательности пересылок точка-точка;
· Широкий набор редукционных операций (например, суммирование расположенных на разных процессорах данных, или нахождение их максимальных или минимальных значений), не только упрощающих работу программиста, но и допускающих гораздо более эффективную реализацию, чем это может сделать прикладной программист, не имеющий информации о характеристиках коммуникационной системы;
· Удобные средства именования адресатов сообщений, упрощающие разработку стандартных программ или разделение программы на функциональные блоки;
· Возможность задания типа передаваемой информации, что позволяет обеспечить ее автоматическое преобразование в случае различий в представлении данных на разных узлах системы.
Однако разработчики MPI подвергаются и суровой критике за то, что интерфейс получился слишком громоздким и сложным для прикладного программиста. Интерфейс оказался сложным и для реализации, в итоге, в настоящее время практически не существует реализаций MPI, в которых в полной мере обеспечивается совмещение обменов с вычислениями.
Появившийся в 1997 проект стандарта MPI-2 [2] выглядит еще более громоздким и неподъемным для полной реализации. Он предусматривает развитие в следующих направлениях:
· Динамическое создание и уничтожение процессов;
· Односторонние коммуникации и средства синхронизации для организации взаимодействия процессов через общую память (для эффективной работы на системах с непосредственным доступом процессоров к памяти других процессоров);
· Параллельные операции ввода-вывода (для эффективного использования существующих возможностей параллельного доступа многих процессоров к различным дисковым устройствам).
Вкратце о других моделях:
Модель неструктурированных нитей. Программа представляется как совокупность нитей (threads), способных выполняться параллельно и имеющих общее адресное пространство. Имеющиеся средства синхронизации нитей позволяют организовывать доступ к общим ресурсам. Многие системы программирования поддерживают эту модель: Win32 threads, POSIX threads, Java threads.
Модель параллелизма по данным. Основным её представителем является язык HPF [3]. В этой модели программист самостоятельно распределяет данные последовательной программы по процессорам. Далее последовательная программа преобразуется компилятором в параллельную, выполняющуюся либо в модели передачи сообщений, либо в модели с общей памятью. При этом каждый процессор производит вычисления только над теми данными, которые на него распределены.
Модель параллелизма по управлению. Эта модель возникла в применении к мультипроцессорам. Вместо терминов нитей предлагалось использовать специальные конструкции – параллельные циклы и параллельные секции. Создание, уничтожение нитей, распределение на них витков параллельных циклов или параллельных секций – всё это брал на себя компилятор. Стандартом для этой модели сейчас является интерфейс OpenMP [4].
Гибридная модель параллелизма по управлению с передачей сообщений. Программа представляет собой систему взаимодействующих MPI – процессов, каждый из которых программируется на OpenMP.
Модель параллелизма по данным и управлению – DVM (Distributed Virtual Machine, Distributed Virtual Memory) [5]. Эта модель была разработана в Институте прикладной математики им. М. В. Келдыша РАН.
Похожие работы
... уровням программы добавляется новый – визуальный. Использование трехмерной графики, распознавания речи, жестов, позволяет создавать принципиально новые пользовательские интерфейсы. 5. Диалоговая оболочка отладчика MPI-программ 5.1 Постановка задачи Целью данной дипломной работы является создание диалоговой оболочки отладчика MPI-программ для DVM-системы. Целью создаваемых средств ...
... работать с системой. Исходная программа поступает на вход инструментатору, который генерирует внутреннее представление и модифицирует программу для динамического анализа. Задача анализатора – собрать информацию о программе, необходимую экспертным модулям для распараллеливания программы. Пользуясь этой информацией, экспертные модули могут принять решения о распараллеливании конкретных циклов, о ...
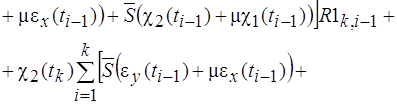
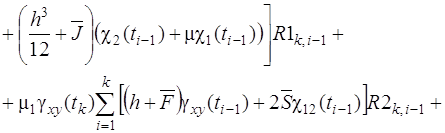
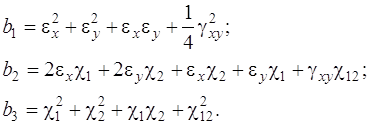
... необходимости строить локальную сети обмена данными, а достаточно сэмулировать этот процесс. Глава 4. Алгоритмы решения задач устойчивости для подкрепленных пологих оболочек, основанные на распараллеливании процесса вычисления При исследовании устойчивых подкрепленных оболочек с учетом геометрической нелинейности приходится многократно решать системы алгебраических уравнений. Коэффициенты ...
... 5k управления ресурсами (программно-аппаратный комплекс) массивно-параллельного компьютера обязана обрабатывать подобные ситуации в обход катастрофического общего рестарта с потерей контекста исполняющихся в данный момент задач. 2.4.1 Массивно-параллельные суперкомпьютеры серии CRY T3 Основанная в 1972 году фирма Cry Research Inc. (сейчас Cry Inc.), прославившаяся разработкой векторного ...
0 комментариев