Навигация
СОДЕРЖАНИЕ
ВВЕДЕНИЕ. 3
1. СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ.. 4
1.1. Системы управления базами данных. 4
1.2. Настольные (локальные) СУБД.. 5
1.3. СУБД структуры «сервер-клиент». 7
2. БАЗА ДАННЫХ MS ACCESS. 17
2.1. Microsoft Access - функционально полная реляционная СУБД.. 17
2.2. Предназначение СУБД Access. 18
ЗАКЛЮЧЕНИЕ. 35
СПИСОК ЛИТЕРАТУРЫ.. 37
ВВЕДЕНИЕ
Базы данных (БД) составляют в настоящее время основу компьютерного обеспечения информационных процессов, входящих практически во все сферы человеческой деятельности.
Действительно, процессы обработки информации имеют общую природу и опираются на описание фрагментов реальности, выраженное в виде совокупности взаимосвязанных данных. Базы данных являются эффективным средством представления структур данных и манипулирования ими. Концепция баз данных предполагает использование интегрированных средств хранения информации, позволяющих обеспечить централизованное управление данными и обслуживание ими многих пользователей. При этом БД должна поддерживаться в среде ЭВМ единым программным обеспечением, называемым системой управления базами данных (СУБД). СУБД вместе с прикладными программами называют банком данных.
Одно из основных назначений СУБД – поддержка программными средствами представления, соответствующего реальности.
Предметной областью называется фрагмент реальности, который описывается или моделируется с помощью БД и ее приложений. В предметной области выделяются информационные объекты – идентифицируемые объекты реального мира, процессы, системы, понятия и т.д., сведения о которых хранятся в БД.
В мире существует множество систем управления базами данных. Несмотря на то, что они могут по-разному работать с разными объектами и предоставляют пользователю различные функции и средства, большинство СУБД опираются на единый устоявшийся комплекс основных понятий. В качестве такого объекта мы выберем СУБД Microsoft Access, входящую в пакет Microsoft Office.
1. СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ 1.1. Системы управления базами данных
Для взаимодействия пользователя с БД используеся системы управления базами данных (СУБД), которые обеспечивают:
- набор средств для поддержки таблиц и соотношений между ними;
- развитый пользовательский интерфейс, позволяющий вводить и модифицировать информацию, производить поиск и представлять результаты;
- средства программирования высокого уровня, позволяющие создавать собственные приложения.
Подход к постоению СУБД значительно видоизменялся на протяжении почти 40 лет. На смену ВЦ предприятия и АСУП на их основе пришли персональные компьютеры и настольные (персональные) системы управления базами данных, затем с развитием коммуникаций появились распределенные системы и концепции управления крупными предприятиями - корпорациями на основе бизнес-процессов.
При этом в условиях динамичного изменения бизнес-процессов в последние годы сформулировался ряд определенных требований к функциональным возможностям тех СУБД, производители которых стремятся поддерживать свои продукты на высоком, конкурентоспособном уровне.
1.Создаваемые средствами СУБД приложения должны обладать высокой степенью мобильности и легко переноситься на разные компьютерные и сетевые платформы.
2.Коммуникационный обмен данными становится асинхронным, а информационные процессы длительными, и поэтому возникает необходимость журнализации состояния баз данных и проведения возможного отката/восстановления для расширенных временных рамок (дни, недели).
3.Средства СУБД должны допускать возможность гибкого варьирования архитектуры различных ИС для соблюдения разумного компромисса при разделении функциональных возможностей системы между рабочими станциями клиентов и серверами.
4.Создание "менеджеров процессов" может быть эффективным только в таких условиях, когда средства программирования СУБД объектно-ориентированы и возможно создание стабильных приложений при динамичном изменении маршрутизации сквозь эти задачи.
5.Производителям СУБД следует обеспечить соответствие поставляемых ими продуктов открытым стандартам взаимодействия.
6.Расширение бизнес-процессов за пределы одной компании и необходимость создания глобальных информационных связей выдвигает серьезную задачу поддержки высокой степени готовности систем, работающих 24 часа в сутки все 365 дней в году.
Перечисленные требований к СУБД как к интегрирующим звеньям информационных систем новой архитектуры позволяют взглянуть на существующие ныне на рынке продукты разных производителей под соответствующим углом зрения. Адекватность предлагаемых сегодня СУБД новым требованиям определит для их будущих владельцев и клиентов преимущества создаваемых ИС, их гибкость, мобильность, возможность легкой перестройки и, в конечном счете, способность к выживанию.
1.2. Настольные (локальные) СУБДВажным этапом в развитии настольных систем управления базами данных стали СУБД dBASE III и dBASE III PLUS фирмы Ashton Tate (Ребус в отечественном варианте), которые по существу стали стандартом для программных продуктов данного класса. После версии "третья с плюсом" разрабатывался проект dBASE IV, результатом которого стал пакет-монстр, трудный в освоении и малоэффективный, что привело фирму к краху.
Фирма Fox Software начинала с FохBase. Поначалу этот продукт мало отличался от dBASE: он лишь значительно быстрее работал и имел ряд полезных функций, которых у dBASE не было (русская "пиратская" версия FoxBase называлась "Карат-М"). Потом появился FoxPro - этот продукт оказался достаточно мощным, и очень многие программисты перешли на него. В последствии этот продукт купила MicroSoft и выпустила свою версию FoxPro 2.5, затем превратив его в визуальный объектно-ориентированный продукт Visual FoxPro 3.0. с последующим развитием.
Компания Nantucket производила компилятор Clipper. Пакет Clipper имел преимущество перед другими XBASE-продуктами по той простой причине, что позволял создавать исполняемые модули (ЕХЕ-файлы). Кроме того, у него было одно важное свойство, актуальное и по сей день: он позволял быстро и довольно простыми средствами создавать корпоративные программы средней сложности (АРМ "Кадры", "Финансы", "Библиотека" и пр.). Второе очевидное преимущество - простота освоения. В Clipper многие компоненты были уже готовы или собирались из кусочков за считанные минуты, для DOS по тем временам это было большое достижение. Недостатком являлось то,что у Clipper не было своей среды разработки. Программы набирались в каком-нибудь редакторе, а потом компилировались и запускались. Развивая его как язык программирования, фирма Nantucket намеревалась сделать из Clipper нечто, подобное языку Си++. Ориентация на объектно-ориентированный язык программирования привела к тому, что Clipper nepeстал быть самим собой. Пропала простота освоения, а требования к ресурсам неимоверно возросли. Проект потерпел неудачу, эту фирму купила компания Computer Associates и новый производитель выпустил Windows-вариант доработанного продукта под названием Visual Objects.
Постепенно настольные системы становятся сетевыми, поскольку стоит даже небольшую организацию рассадить по нескольким удаленным друг от друга офисам - и вот уже без схемы «клиент-сервер» работать нельзя. Перерастание локальной информационной системы в клиент-серверную - нормальный процесс, но, конечно, работа в архитектуре «клиент-сервер» не самоцель. Нужно использовать ее только тогда, когда это дает действитепьный выигрыш, действительную отдачу. Поэтому основные производители настольных СУБД выстроили ряд продуктов – приложений современных 32-разрядных операционных систем: «настольная СУБД с возможностью подключения к распределенной базе данных с использованием стандартного языка SQL» – «визуальная объектно-ориентированная среда разработки» – «распределенная СУБД структуры «сервер - клиент» (например, Microsoft Access - FoxPro - SQL Server).
Современные настольные СУБД входят в состав интегрированных программных продуктов типа Office: MS Access из состава Office 95 и 97, Paradox 7.0 из состава Corel Office 97, Approach из состава Lotus SmartSuite 97.
1.3. СУБД структуры «сервер-клиент»Построение распределенных систем имеет важное значение, особенно в условиях бессистемного оснащения предприятия компьютерной техникой, когда многие уже, как правило, работают (или им необходимо работать) с системами, состоящими из множества компьютеров разного типа (серверов, мини-компьютеров, больших машин).
Централизованное хранение данных и доступ к центральной БД в условиях географически распределенной системы приводят к необходимости установления соединений между центральным сервером, хранящим данные, и компьютерами-клиентами. Большинство компьютеров-клиентов отделены от центрального сервера медленными и недостаточно надежными линиями связи, и работа в режиме удаленного клиента становится почти невозможной. Этим можно объяснить существующую ситуацию, когда в узлах распределенной системы функционируют группы автоматизированных рабочих мест (АРМ), абсолютно не связанные друг с другом.
Содержательная сторона задачи обычно требует обмена данными между группами АРМ, так как изменения в какие-либо данные могут вноситься в одной группе, а использоваться они могут в другой. На практике обмен информацией реализуется регламентной передачей файлов - через модемное соединение или «с курьером».
То, что данные доставляются к месту назначения не системными средствами, а путем экспорта/импорта файлов, приводит к необходимости участия человека в процессе обмена, а это влечет за собой малую оперативность поступления данных и необходимость реализации внешних механизмов контроля целостности и непротиворечивости. В результате возрастает вероятность появления ошибок. Кроме того, реализация всех алгоритмов обмена данными и контроля в этом случае возлагается на прикладных программистов, проектирующих АРМ. Объем работ по программированию и отладке подпрограмм обмена соответствует числу различных АРМ. Это также приводит к повышению вероятности сбоев в системе.
В современной технологии АРМ объединены в локальную сеть. АРМ - клиент выдает запросы на выборку и обновление данных, а СУБД исполняет их. Запросы клиента в соответствии с требованиями задачи сгруппированы в логические единицы работы (транзакции). Если все операции с базой данных, содержащиеся внутри транзакции, выполнены удачно, транзакция в целом также выполняется успешно (фиксируется). Если хотя бы одна из операций с БД внутри транзакции произведена неудачно, то все изменения в БД, происшедшие к этому моменту из транзакции, отменяются (происходит откат транзакции). Такое функционирование обеспечивает логическую целостность информации в базе данных.
При распределенной обработке изменения, проводимые приложением-клиентом, могут затрагивать более чем один сервер СУБД. Для поддержания целостности и в этом случае необходимо применение того или иного транзакционного механизма, реализуемого системными средствами, а не прикладной программой.
Но основной недостаток систем, построенных на распределенных транзакциях, - высокие требования к надежности и пропускной способности линий связи. Поэтому альтернативой распределенным транзакциям считается репликация (дублирование) данных. В таких системах одна и та же информация хранится в различных узлах. Согласование значений и распространение данных по узлам осуществляется автоматически. В зависимости от условий, специфицированных разработчиком, репликация может производиться либо сразу после наступления некоторого события (скажем, модификации строки таблицы), либо через заранее заданные интервалы времени (каждую минуту, каждый час и т.д.), либо в определенный момент времени (например, ночью, когда загрузка и стоимость линий связи минимальная). Если узел, в который выполняется репликация, в данный момент недоступен, информация об этом сохраняется в вызывающем узле, и репликация осуществляется после восстановления связи. Более того, гарантируется сохранение заданного вызывающим узлом порядка ее выполнения.
Транзакция может вносить изменения (то есть добавлять, удалять и изменять записи) в одну или несколько таблиц базы данных. Выбранные для репликации таблицы специальным образом помечаются. Для каждой такой таблицы или группы ее строк, выбранной по заданному условию, определяется один узел (СУБД), в котором данные таблицы являются первичными. Это тот узел, в котором происходит наиболее активное обновление данных. Репликационному серверу, обслуживающему БД с первичными данными, задается описание тиражирования (replication definition). В этом описании, к примеру, могут быть заданы интервалы значений первичного ключа таблицы или какое-нибудь другое условие, при выполнении которого измененные данные будут тиражироваться из этого узла к подписчикам. Если условие не задано, то описание тиражирования действует для всех записей таблицы. Возможность тиражирования группы записей таблицы означает, в частности, что часть записей может быть первичными данными в каком- то одном узле, а еще часть - в других узлах. В одном или нескольких узлах (СУБД), которым нужны измененные данные, в обслуживающем его репликационном сервере создается подписка (subscription) на соответствующее описание тиражирования. Здесь будет поддерживаться (с небольшой задержкой) копия первичных данных.
Современные СУБД используют так называемый системный журнал, в который вносятся записи об изменениях в базе данных и завершении транзакций. Журнал используется сервером БД для отката или прокрутки транзакций после сбоев и для резервного копирования. Измененые данные из журнала передаются репликационному серверу, обслуживающему этот узел. Репликационный сервер в соответствии с описанием тиражирования и подписками отправляет данные в специальном эффективном протоколе по месту назначения, то есть соответствующим репликационным серверам в удаленных узлах.
Именно в этом сечении - между репликационными серверами - связь может быть медленной или недостаточно надежной. Передаваемые данные в составе транзакции при недоступности узла-получателя записываются в стабильные очереди на диске и затем передаются по мере возможности. Данные могут передаваться в удаленный узел по маршруту, содержащему несколько репликационных серверов. В частности, такая возможность лежит в основе построения иерархических систем репликации.
В одной базе данных могут содержаться как первичные данные, так и данные-копии. Приложение-клиент, работающее со своей СУБД, может вносить изменения напрямую (операторами INSERT, DELETE, UPDATE) только в первичные данные. Для изменения копии данных предназначен механизм асинхронного вызова процедур. Для работы этого механизма в нескольких базах данных создаются процедуры с одинаковым именем и параметрами, но, возможно, с различным текстом. В одной базе данных процедура помечается как предназначенная к репликации. Вызов этой процедуры вместе со значениями параметров через журнал и механизм репликации передается к узлам-подписчикам, и в их базах данных вызывается одноименная процедура с теми же значениями параметров.
СУБД, хранящая вторичные данные, может быть любой из ряда доступных через шлюз: будь то Oracle, Informix, DB2, RMS, ISAM и т.п.. СУБД, хранящая первичные данные, требует наличия менеджера журнала транзакций (Log Transfer Manager - LTM). Сейчас разработаны LTM для Sybase SQL Server и Oracle; на очереди другие СУБД. Интерфейс LTM является открытым, и в скором времени, возможно, подобные модули будут созданы для нестандартных источников данных.
Вообще, тиражирование данных может найти самое разнообразное применение:
- для разгрузки сервера, выполняющего активное обновление данных (OLTP) от сложных запросов, связанных с поддержкой принятия решений (decision-support);
- для консолидации данных от подразделений в центре;
- для обмена данными по медленным или ненадежным линиям связи;
- для поддержания резервной базы данных;
-для построения сети равноправных узлов, обменивающихся данными.
Следует подчеркнуть, что репликационный сервер тиражирует транзакции, а не отдельные изменения в базе данных. Метод тиражирования транзакций гарантирует целостность внутри транзакции и, как следствие, невозможность нарушения ссылочной целостности. Схема обновления первичных данных и копий данных исключает возможность возникновения конфликтов; последние могут быть вызваны только неправильным проектированием системы или сбоем.
Большинство производителей современных промышленных СУБД в той или иной мере обеспечивают поддержку распределенной обработки транзакций. Распределенная обработка данных основывается на синхронных или асинхронных механизмах обработки распределенных транзакций. Эти механизмы могут использоваться и совместно. Поскольку каждый механизм обладает своими сильными и слабыми сторонами, выбор его зависит от требований конкретной подзадачи.
Исторически первым появился метод синхронного внесения изменений в несколько БД, называемый двухфазной фиксацией (2РС, two- phase commit). Этот механизм реализован сейчас практически всеми производителями СУБД. Суть метода двухфазной фиксации состоит в том, что при завершении транзакции серверы БД, участвующие в ней, получают команду «приготовиться к фиксации транзакции». После получения подтверждений от всех серверов транзакция фиксируется на кадом из них. Таким образом, в любой момент времени обеспечивается целостность данных в распределенной системе. Платой за это являются требование доступности всех участвующих серверов и линий связи во время проведения транзакции, а также невозможность работы приложений-клиентов при недоступности, например, удаленного сервера. Кроме того, необходимо высокое быстродействие линий связи для обеспечения приемлемого времени реакции у приложения-клиента.
В распределенной системе идеальным являлось бы состояние, когда каждая программа-клиент обращается только к тем серверам, которые находятся в пределах ее локальной сети, а передача данных и обеспечение целостности осуществляются системными средствами и не требуют специальных действий со стороны прикладной программы. Такое распределение функций возможно и на практике реализуется с помощью механизма асинхронного тиражирования транзакций.
Синхронное проведение изменений в участвующих в распределенной транзакции базах данных не всегда является необходимым требованием. Рассмотрим, например, случай ввода данных с измерительного оборудований в цехе и последующего анализа этой информации на уровне управления. Здесь очень важно обеспечить достаточно малый (но, возможно, ненулевой) интервал времени между изменениями в исходных данных и в их копии на другом узле системы, где происходит построение отчетов.
Механизм асинхронного тиражирования транзакций (репликации) гарантирует доставку измененных данных на вторичные серверы непосредственно после завершения транзакции, если сервер доступен, или же тотчас после подключения сервера к сети. Такой способ предполагает хранение дублирующей информации в различных узлах сети и по сравнению с другими подходами к репликации существенно разгружает трафик сети, минимизирует время отклика системы, а также позволяет оптимизировать нагрузку на серверы.
В зависимости от условий, специфицированных разработчиком, репликация может производиться либо сразу после наступления некоторого события (скажем, модификации строки таблицы), либо через заранее заданные интервалы времени (каждую минуту, каждый час и т.д.), либо в определенный момент времени (например, ночью, когда загрузка и стоимость линий связи минимальная). Если узел, в который выполняется репликация, в данный момент недоступен, информация об этом сохраняется в вызывающем узле, и репликация осуществляется после восстановления связи. Более того, гарантируется сохранение заданного вызывающим узлом порядка ее выполнения.
Основные преимущества такого решения - повышение надежности системы (за счет контролируемого дублированмя данных) и увеличение ее производительности из-за существенного снижения сетевого трафика. Причем для уменьшения объема передаваемых данных обычно реплицируется не полный образ таблицы (или ее подмножества), а только информация об изменениях, происшедших с момента последней репликации.
Надо отметить, что асинхронная репликация не делает линии связи более надежными или скоростными. Она лишь перекладывает задачи трансляции данных и обеспечения их целостности «с плеч» прикладной программы и пользователя на системный уровень.
Асинхронная репликация, в отличие от 2РС, не гарантирует полной синхронности информации на всех серверах в любой момент времени. Синхронизация происходит через некоторый, обычно небольшой интервал времени, величина которого определяется быстродействием соответствующего канала связи. Для большинства задач кратковременное наличие устаревших данных в удаленных узлах не критично и вполне допустимо.
Вместе с тем асинхронная репликация транзакций принципиально обеспечивает целостность информации, так как объектом обмена данными здесь является логическая единица работы - транзакция, а не просто данные из измененных таблиц.
Все современные серверы БД используют блокировки, чтобы обеспечить параллелизм в многопользовательской среде. Речь может идти о блокировках на уровне страниц, строк или таблиц, причем характер используемой блокировки чаще всего определяется в момент описания таблиц. Действительно, пользователи и разработчики корпоративных информационных систем все больше внимания уделяют эффективности базовой СУБД. В частности, речь идет о способах реализации систем блокировки, которые в значительной степени влияют на качество исполнения проектов. Система блокировок синхронизирует доступ пользователей к базе данных, а в идеале гарантирует непротиворечивость данных и истинность результатов выполнения запросов. В то время как один пользователь блокирует область базы данных, например, для просмотра и·возможной модификации данных, последние должны быть защищены от воздействия со стороны других пользователей, возможно пытающихся вносить изменения в той же области данных.
Задача масштабирования рано или поздно встает в любой организации, и это вполне объяснимо. Никто и никогда не покупает аппаратуру про запас, с большими резервами по вычислительной мощности. В то же время объемы хранимых данных и количество реально работающих приложений имеют тенденцию к неуклонному увеличению. Поэтому лучше всего изначально остановить свой выбор на такой аппаратной конфигурации, которая в дальнейшем будет легко наращиваться и развиваться.
В настоящее время этому требованию в наибольшей степени отвечают компьютеры с симметричной многопроцессорной (SMP) или массивно-параллельной (МРР) архитектурой, на которых при увеличении количества процессоров обеспечивается практически линейный рост производительности. Обработка нескольких запросов, вложенных циклов внутри одного запроса, загрузка и сортировка данных, создание индексов и т.д. - все это выполняется параллельно на различных процессорах. Более того, одновременно реализуется эффективная динамическая балансировка загрузки системных ресурсов (процессоров, оперативной и дисковой памяти).
Виртуальным-процессором (ВП) называется процесс сервера баз данных. ВП можно сравнить с операционной системой - поток по отношению к нему выступает как процесс, подобно тому как сам ВП является процессом с точки зрения операционной системы.
В отличие от операционной системы, которая должна обеспечивать выполнение произвольных процессов, ВП подразделяются на несколько классов, каждый из которых спроектирован для наиболее оптимального выполнения задач определенного вида. Например, ВП CPU работают на потоки обслуживания клиентов, реализующие оптимизацию и логику выполнения запросов; ВП АIO выполняют операции асинхронного обмена с диском; ВП TLI контролируют сетевое взаимодействие.
Сервер поддерживает очереди потоков для каждого класса ВП. Как только ВП освобождается, он выбирает из очереди следующий поток, тем самым достигается равномерная загрузка. Переключение же ВП с одного потока на другой выполняется значительно быстрее, чем переключение ОС с одного процесса на другой. Кроме того, многопотоковая архитектура способствует более рациональному использованию ресурсов ОС, поскольку потоки разделяют ресурсы ВП, на котором они выполняются, - память, коммуникационные порты, файлы.
Начальное число ВП каждого класса задается в конфигурационном файле. Но если потребности в каких-то видах увеличиваются, то инструменты администрирования позволяют динамически, не останавливая сервер, запустить дополнительные ВП. Например, если растет очередь потоков к ВП CPU, то можно увеличить их число. Точно так же возможно добавление виртуальных процессоров обмена с дисками, сетевых процессоров.
Разделение данных между виртуальными процессорами и потоками сервера реализовано на основе разделяемой памяти - механизма, обеспечиваемого операционной системой. Разделение данных позволяет:
- снизить общее потребление памяти, поскольку участвующим в разделении процессам, то есть виртуальным процессорам, нет нужды поддерживать свои копии информации, находящейся в разделяемой памяти;
- сократить число обменов с дисками, потому что буферы ввода-вывода сбрасываются на диск не для каждого процесса в отдельности, а образуют один общий для всего сервера баз данных пул; виртуальный процессор зачастую избегает выполнения операций ввода с диска, поскольку нужная таблица уже прочитана другим процессором;
- организовать быстрое взаимодействие между процессами; через разделяемую память, в частности, обмениваются данными потоки, участвующие в параллельной обработке сложного запроса; разделяемая память используется также для организации взаимодействия между локальным клиентом и сервером.
2. БАЗА ДАННЫХ MS ACCESS 2.1. Microsoft Access - функционально полная реляционная СУБД
Программное обеспечение для работы с базами данных используется на персональных компьютерах уже довольно давно. К сожалению, эти программы либо были элементарными диспетчерами хранения данных и не имели средств разработки приложений, либо были настолько сложны и трудны, что даже хорошо разбирающиеся в компьютерах люди избегали работать с ними до тех пор, пока не получали полных, ориентированных на пользователя приложений.
Microsoft Access - это функционально полная реляционная СУБД. В ней предусмотрены все необходимые вам средства для определения и обработки данных, а также для управления ими при работе с большими объемами информации. Что касается легкости использования, то Microsoft Access совершил здесь настоящий переворот, и многие для создания своих собственных баз данных и приложений обращаются именно к нему.
Система управления базами данных предоставляет вам возможность контролировать задание структуры и описание своих данных, работу с ними и организацию коллективного пользования этой информацией. СУБД также существенно увеличивает возможности и облегчает каталогизацию и ведение больших объемов хранящейся в многочисленных таблицах информации. СУБД включает в себя три основных типа функций: определение (задание структуры и описание) данных, обработка данных и управление данными. Все эти функциональные возможности в полной мере реализованы в Microsoft Access. В практике, как правило, необходимо решать и задачи с использованием электронных таблиц и текстовых процессоров. Например, после подсчета или анализа данных необходимо их представить в виде определенной формы или шаблоны. В итоге пользователю приходится комбинировать программные продукты для получения необходимого результата. В этом смысле все существенно упростят возможности, предоставляемые Microsoft Access.
2.2. Предназначение СУБД AccessСУБД Access предназначена для разработки баз данных реляционного типа для локального их использования на персональных компьютерах и для работы с этими базами.
При проектировании базы данных, в первую очередь, необходимо определить, что именно нужно хранить.
Данная СУБД была выбрана по следующим причинам:
- простота средств реализации,
- легкость освоения инструментарием разработчика (VBA),
- наглядность визуализации информации.
Также «Microsoft Access» предоставляет большое количество внутренних средств по оптимизации работы проектируемого приложения. К ним относятся:
- загрузка модулей по требованию;
- оптимизация дерева вызовов;
- использование файлов MDE;
- автоматическая поддержка компилированного состояния;
- использование библиотек Windows API;
- индивидуальная настройка системы;
- эффективное использование индексов;
- встроенный оптимизатор запросов.
Система управления базами данных (СУБД) обычно поддерживает 4 основных типа отношений между таблицами:
- один-к-одному (одной записи в первой таблице соответствует одна запись во второй);
- один-ко-многим (одной записи в первой таблице соответствует много записей во второй);
- много-к-одному (многим записям в первой таблице соответствует одна запись во второй);
- много-ко-многим (одной записи в первой таблице соответствует много запией во второй и одной записи во второй таблице соответствует много записей в первой).
Связь любого из этих типов может быть обязательной, если в данной связи должен участвовать каждый экземпляр сущности, необязательной – если не каждый экземпляр сущности должен участвовать в данной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны.
В СУБД Access процесс создания реляционной базы данных включает создание схемы данных. Схема данных наглядно отображает таблицы и связи между ними, а также обеспечивает использование связей при обработке данных. В схеме данных устанавливаются параметры обеспечения целостности связей в базе данных.
Таким образом, осуществляется неразрывная связь внемашинного проектирования базы данных с этапом ее создания с помощью СУБД. В схеме данных, построенной по нормализованной модели данных предметной области, могут быть установлены одно-однозначные и одно-многозначные связи. Для таких связей обеспечивается поддержание целостности взаимосвязанных данных, при которой не допускается наличия в базе данных подчиненной записи без связанной с ней главной, при первоначальной загрузке базы данных и ее корректировках. Связи, определенные в схеме данных, используются автоматически при разработке многотабличных форм, запросов, отчетов, существенно упрощая процесс их конструирования.
Взаимосвязи таблиц
При создании в Access схемы данных в ней определяются и запоминаются связи между таблицами. Это позволяет системе автоматически использовать связи, один раз определенные в схеме данных, при создании форм, запросов, отчетов на основе взаимосвязанных таблиц, а пользователь освобождается от необходимости указывать эти связи при конструировании этих объектов. Схема данных базы графически отображается в своем окне, где таблицы представлены списками полей, а связи - линиями между полями разных таблиц.
Одно-многозначные (1:М) или одно-однозначные (1:1) связи. Схема данных прежде всего ориентирована на работу с таблицами, отвечающими требованиям нормализации, между которыми могут быть установлены одно-многозначные (1:М) или одно-однозначные (1:1) связи, для которых может автоматически поддерживаться связная целостность. Поэтому схему данных целесообразно строить в соответствии с информационно-логической моделью.
При построении схемы данных Access автоматически определяет по выбранному полю связи тип отношения между таблицами. Если поле, по которому нужно установить связь, является уникальным ключом как в одной таблице, так и в другой, Access выявляет отношение один-к-одному. Если поле связи является уникальным ключом в одной таблице (главной таблицы связи), а в другой таблице (подчиненной таблице связи) является не ключевым или входит в составной ключ, то есть значения его могут повторяться, Access выявляет отношение один-ко-многим между записями главной таблицы к подчиненной. В этом случае можно задать автоматическое поддержание целостности связей.
Отношение многие-ко-многим. Отношение многие-ко-многим предполагает, что каждой записи в одной таблице соответствует несколько записей в другой. При этом каждая сторона отношения выглядит как отношение один-ко-многим.
Однако если рассматривать взаимосвязь таблиц с двух сторон, становится очевидным, что ни одна из таблиц не может быть главной и для их связывания необходима третья таблица.
Связующая таблица представляет собой промежуточную таблицу, которая служит мостом между двумя таблицами в отношении многие-ко-многим. Ее ключ состоит из ключевых полей этих таблиц, с каждой из которых она связана отношением один-ко-многим. Помимо ключевых полей, связующая таблица должна содержать хотя бы одно поле, которого нет в связываемых таблицах, но которое имеет значение для каждой из них. Таким образом, отношение многие-ко-многим складывается из отношений многие-к-одному и один-ко-многим.
Связи-объединения. Между двумя таблицами может быть установлена связь-объединение по некоторому полю связи. Для связи-объединения может быть выбран один из трех способов объединения записей:
· Способ 1 - объединение только тех записей, в которых связанные поля обеих таблиц совпадают (производится по умолчанию);
· Способ 2 - объединение тех записей, в которых связанные поля обеих таблиц совпадают, а также объединение всех записей из первой таблицы, для которых нет связанных во второй, с пустой записью второй таблицы;
· Способ 3 - объединение тех записей, в которых связанные поля обеих таблиц совпадают, а также объединение всех записей из второй таблицы, для которых нет связанных в первой, с пустой записью первой таблицы.
Такой тип связи может быть определен, если связь характеризуется отношением 1:1 или 1:М, а также если тип отношения не может быть определен системой, то есть если не выполняются условия для этих отношений. Например, при выборе в главной таблице в качестве поля связи неключевого поля или поля, входящего в составной ключ, Access сообщает, что тип отношения не может быть определен. В этом случае между таблицами возможно установление только связи-объединения.
Связь-объединение обеспечивает объединение записей таблиц, имеющих одинаковые значения в поле связи. Причем производится объединение каждой записи из одной таблицы с каждой записью из другой таблицы при условии равенства значений в поле связи. Кроме того, если выбран второй или третий вариант в результат объединения могут быть добавлены записи из таблицы, для которых нет логически связанных записей в другой таблице. Последние два варианта часто необходимы при решении практических задач. Примером такой задачи может быть формирование записей студентов с результатами успеваемости как в случае полученной оценки по предмету, так и при отсутствии оценки. При отсутствии оценки соответствующее поле будет пустым.
Создание схемы данных
Создание схемы данных начинается в окне Базы данных (Database) с выполнения команды Сервис|Схема данных (Tools|Relationships) или нажатия кнопки Схема данных (Relationships) на панели инструментов базы данных.
Включение таблиц в схему данных. После нажатия кнопки Схема данных (Relationships) открывается окно Добавление таблицы (Show Table) , в котором можно выбрать таблицы и запросы, включаемые в схему данных. Для размещения таблицы в окне Схема данных (Relationships) надо выделить ее в окне Добавление таблицы (Show Table) и нажать кнопку Добавить (Add). Для выделения нескольких таблиц надо, удерживая клавишу , щелкнуть мышью на каждой из этих таблиц. Включив все нужные таблицы в схему данных, нажать кнопку Закрыть (Close).
В результате в окне Схема данных (Relationships) будут представлены все включенные таблицы со списком своих полей. Далее можно приступать к определению связей между ними.
Создание связей между таблицами. При определении связей в схеме данных удобно использовать информационно-логическую модель в каноническом виде, по которой легко определить главную и подчиненную таблицу каждой одно-многозначной связи, поскольку в такой модели главные объекты всегда размещены выше подчиненных. Эти связи являются основными в реляционных базах данных, т. к. одно-однозначные связи используются лишь в редких случаях, когда приходится разделять большое количество полей, определяемых одним и тем же ключом, по разным таблицам, имеющим разный регламент обслуживания.
Устанавливая в окне схемы данных связи типа 1:М между парой таблиц, надо выделить в главной таблице уникальное ключевое поле, по которому устанавливается связь. Далее, при нажатой кнопке мыши, протащить курсор в соответствующее поле подчиненной таблицы.
При создании связи по составному ключу необходимо выделить все поля, входящие в ключ главной таблицы, и перетащить их на одно из полей связи в подчиненной таблице. Для выделения всех полей, входящих в составной уникальный ключ, необходимо отмечать поля при нажатой клавише . После создания связи откроется окно Изменение связей (Edit Relationships). При этом в строке Тип отношения (Relationship Type) автоматически установится тип один-ко-многим (One-To-Many).
При составном ключе связи в окне Изменение связей (Edit Relationships) необходимо для каждого поля ключа в главной таблице ТАБЛИЦА/ЗАПРОС (Table/Query) выбрать соответствующее поле подчиненной таблицы, названной СВЯЗАННАЯ ТАБЛИЦА/ЗАПРОС (Related Table/Query).
Обеспечение целостности данных
При создании схемы данных пользователь включает в неё таблицы и устанавливает связи между ними. Для связей типа 1:1 и 1:М можно задать параметр обеспечения связной целостности данных, а также автоматическое каскадное обновление и удаление связанных записей.
Обеспечение связной целостности данных означает, что Access при корректировке базы данных обеспечивает для связанных таблиц контроль за соблюдением следующих условий:
· В подчиненную таблицу не может быть добавлена запись с несуществующим в главной таблице значением ключа связи;
· В главной таблице нельзя удалить запись, если не удалены связанные с ней записи в подчиненной таблице;
· Изменение значений ключа связи в записи главной таблицы невозможно, если в подчиненной таблице имеются связанные с ней записи.
При попытке пользователя нарушить эти условия в операциях добавления и удаления записей или обновления ключевых данных в связанных таблицах Access выводит соответствующее сообщение и не допускает выполнения операции.
Установление между двумя таблицами связи типа 1:М или 1:1 и задание для нее параметров целостности данных возможно только при следующих условиях:
· Связываемые поля имеют одинаковый тип данных, причем имена полей могут быть различными;
· Обе таблицы сохраняются в одной базе данных Access;
· Главная таблица связывается с подчиненной по первичному простому или составному ключу (уникальному индексу) главной таблицы.
Access автоматически отслеживает целостность связей при добавлении и удалении записей и изменении значений ключевых полей, если между таблицами в схеме данных установлена связь с параметрами обеспечения целостности. При действиях, нарушающих целостность связей таблиц, выводится сообщение. Access не позволяет установить параметр целостности для связи таблиц, если ранее введенные в таблицы данные не отвечают требованиям целостности.
Каскадное обновление и удаление связанных записей
Если для выбранной связи обеспечивается поддержание целостности, можно задать режим каскадного обновления связанных полей и режим каскадного удаления связанных записей.
В режиме каскадного обновления связанных полей при изменении значения поля связи в записи главной таблицы, Access автоматически изменит значения в соответствующем поле в подчиненных записях.
В режиме каскадного удаления связанных записей при удалении записи из главной таблицы будут автоматически удаляться все связанные записи в подчиненных таблицах. При удалении записи из главной таблицы выполняется каскадное удаление подчиненных записей на всех уровнях, если этот режим задан на каждом уровне.
При удалении записей непосредственно в таблице или через форму выводится предупреждение о возможности удаления связанных записей.
Язык SQL (аббревиатура Structured Query Language) – это язык структурированных запросов, стандартный язык, предназначенный для создания баз данных, добавления новых и поддержки имеющихся данных, а также извлечения требуемой информации. Язык SQL с самого начала был создан, чтобы работать с данными из тех баз, которые следуют реляционной модели.
Каждому запросу MS Access можно сопоставить эквивалентную инструкцию SQL. В MS Access пользователи, знакомые с языком SQL, могут использовать его для просмотра и изменения запросов в режиме конструктора, определения свойств форм и отчетов, создания специальных запросов (запросы объединения, запросы к серверу и управляющие запросы), создания подчиненных запросов.
При создании каждого запроса MS Access автоматически составляет эквивалентную ему инструкцию SQL. Изменения, внесенные в инструкцию SQL, автоматически отражаются в бланке конструктора.
Просмотрим или изменим инструкцию SQL:
1. Выполнив анализ предметной области, создадим групповой запрос «Список студентов группы ДФД-31» на основании таблиц «Студент» и «Группа» (рис. 21), в который включим список следующих полей таблиц:
Группа.[Обозначение группы], Студент.[Номер зачетной книжки], Студент.Фамилия, Студент.Имя, Студент.Отчество, Студент.Год рождения, Студент.Адрес, Студент.[Домашний телефон], Студент.[Балл при поступлении].
В поле Группа.[Обозначение группы] используем условие отбора по коду группы: «ДФД-31».
Групповой запрос «Список студентов группы ДФД-31» в MS Access в режиме конструктора
2. Выберем Режим SQL в меню Вид или через кнопку «Режим SQL» на панели инструментов. На экране появится текущий запрос в режиме SQL эквивалентный созданному в режиме конструктора (рис. 22).
Запрос «Список студентов группы ДФД-31» в MS Access в режиме SQL
3. В этот запрос можно внести изменения, и эти изменения будут отражены в бланке конструктора. Например, попробуем удалить в текстовом окне режима SQL записи Студент.Адрес, Студент.[Домашний телефон], Студент.[Балл при поступлении].
Результат выполнения измененного запроса «Список студентов группы ДФД-31»
Основной инструкцией языка SQL, всегда содержащейся в запросе, является команда SELECT [2].
В простейшей форме эта команда занимается поиском информации в таблице. Она имеет следующий формат:
SELECT field1, field 2, …
FROM Table;
Здесь field1, field 2,… – список столбцов таблицы Table, которые должны быть представлены в результате запроса.
Для получения всей таблицы вместо списка столбцов необходимо поставить символ «*» (звездочка).
Команда SELECT имеет следующие параметры:
A. DISTINCT (получить список без повторений)
Формат: SELECT DISTINCT field1, field2, …
FROM Table;
B. ALL (получить список со всеми повторениями)
Формат: SELECT ALL field1, field2, …
FROM Table;
C. WHERE (извлечь нужные строки)
Формат: SELECT field1, field2, …
FROM Table WHERE predicate;
Здесь predicate – логическое выражение, которое может быть истинно или ложно для каждой записи таблицы.
D. ORDER BY (рассортировать выходные данные)
Формат: SELECT field1, field2, …
FROM Table
ORDER BY field1 DESC;
Это означает, что выходные данные будут рассортированы по столбцу field1 в порядке убывания (порядок возрастания задается по умолчанию или с помощью слова ASC).
E. GROUP BY (группировать выходные данные)
Формат: SELECT field1, field2, …
FROM Table
GROUP BY [field1, field2, …]
ORDER BY field1 DESC;
Группировка – это объединение записей в соответствии со значениями некоторого заданного поля.
Агрегатные функции
Существуют следующие основные агрегатные функции:
· Count – определение численности;
· Sum – определение суммы;
· First/Last – определение первого/последнего значения;
· Min/Max – определение минимума/максимума;
· Avg – определение среднего значения.
Для обозначения связи двух таблиц дополнительно к команде FROM используются атрибуты INNER JOIN и ON.
Так как в сложном запросе появляется несколько таблиц, то появляется необходимость указывать поле с обозначением таблицы, например, см. рис. 22.
С помощью атрибута INNER JOIN мы указали, что таблица «Студент» связана с таблицей «Группа». А с помощью атрибута ON мы указали, как именно связаны между собой две таблицы «Студент» и «Группа»: по полю Код группы (FROM Группа INNER JOIN Студент ON Группа.[Код группы] = Студент.[Код группы]).
С помощью атрибута WHERE мы указали, что нужно извлечь только строки, которые содержат запись в поле Группа.[Обозначение группы] «ДФД-31»: WHERE (((Группа.[Обозначение группы])="ДФД-31")).
ПРИМЕЧАНИЕ. Обратите внимание на то, что в качестве имени поля всегда используется то имя, которое было присвоено полю в процессе создания таблицы в режиме конструктора, а не надпись, которую мы видим на экране в таблице в режиме заполнения.
Похожие работы
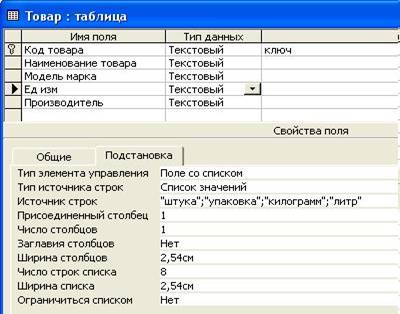
... обработки в полях не оказывается никаких значений, система обеспечивает полную поддержку пустых значений. 1 Основные понятия о базах данных MS Access 1.1 Краткая характеристика MS Access Microsoft Access является настольной СУБД (система управления базами данных) реляционного типа. Достоинством Access является то, что она имеет очень простой графический интерфейс, который позволяет ...
... на создание таблицы создает новую таблицу на основе всех или части данных из одной или нескольких таблиц. Запрос на создание таблицы полезен при создании таблицы для экспорта в другие базы данных Microsoft Access или при создания архивной таблицы, содержащей старые записи. 4.1.3 Формы Формы являются типом объектов базы данных, который обычно используется для отображения данных в базе данных ...
... формат отображения даты в отчете. 1. Отчет сохраните с именем « Экзамен» 4. Просмотрите отчет 5. Аналогично созданию отчета “Экзамен” создайте отчет “Зачет” Упражнение 11 Система управления базами данных MS Access Тема: Создание кнопок управления. Кнопки используются в формах для выполнения определенного действия или ряда действий. Задание 1 1. Создать кнопки выхода из ...
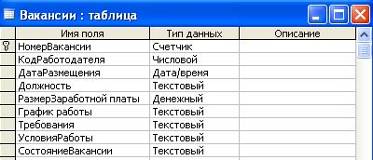
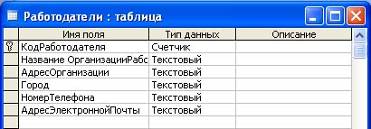
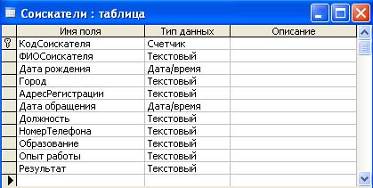
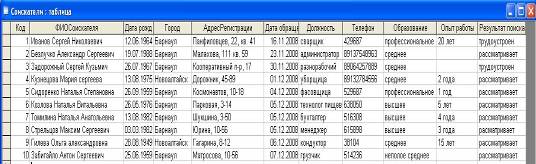
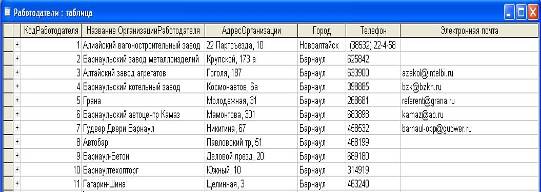
ы. Цель работы – изучить технологию создания базы данных. Задачи работы: 1. Изучение основных процессов в деятельности биржи труда на примере биржи труда «Шанс» (г. Барнаул) 2. Создание таблиц 3. Создание схемы данных 4. Заполнение таблиц данными 5. Формирование запросов 6. Формирование отчетов Данная работа была проведена на домашнем персональном компьютере (оперативная ...
0 комментариев