Журнализация
Каждый потомок имеет только одного предка;
Типичное разделение функций между клиентами и серверами
Значение должно быть как можно меньше
Просканировать таблицу поставщиков P, каждый раз выполняя подзапрос с новым значением номера поставщика, взятым из таблицы P
Гиперкубов (все хранимые в базе данных ячейки должны иметь одинаковую размерность, то есть находиться в максимально полном базисе измерений) и
Другое расширение связано с созданием отдельных таблиц фактов для всех возможных сочетаний уровней обобщения различных измерений
Навигация
Значение должно быть как можно меньше
Базы данных и информационные технологии
237727
знаков
39
таблиц
0
изображений
4. Значение должно быть как можно меньше.
Первые три условия означают, что отображение wi будет сжимающим. А в силу четвёртого условия кодируемое изображение R и его образ W (R) будут похожи друг на друга. В идеале R = W (R). А это означает, что наше изображение R и будет являться неподвижной точкой W. Именно здесь используется подобие различных частей изображения (отсюда и название – «фрактальная компрессия»). Как оказалось, практически все реальные изображения содержат такие похожие друг на друга, с точностью до аффинного преобразования, части.
Таким образом, для компрессии изображения W нужно:
1. Разбить изображение на ранговые области ri (непересекающиеся области, покрывающие все изображение).
2. Для каждой ранговой области ri найти область di (называемую доменной), и отображение wi, с указанными выше свойствами.
3. Запомнить коэффициенты аффинных преобразований W, положения доменных областей di, а также разбиение изображения на домены.
Соответственно, для декомпрессии изображения нужно будет:
1. Создать какое-то (любое) начальное изображение R0.
2. Многократно применить к нему отображение W (объединение wi).
3. Так как отображение W сжимающее, то в результате, после достаточного количества итераций, изображение придёт к аттрактору и перестанет меняться. Аттрактор и является нашим исходным изображением. Декомпрессия завершена.
Именно это и позволяет при развертывании увеличивать его в несколько раз. Особенно впечатляют примеры, в которых при увеличении изображений природных объектов проявляются новые детали, действительно этим объектам присущие (например, когда при увеличении фотографии скалы она приобретает новые, более мелкие неровности).
4. Оценка коэффициента сжатия и вычислительных затратРазмер данных для полного определения ранговой области рассчитывается по формуле:
|
| (10) |
где X – количество бит, необходимых для хранения координат нижнего левого угла домена, T – количество бит, необходимых для хранения типа аффинного преобразования, U и V – для хранения коэффициентов контраста и яркости.
|
| (11) |
где Nb и Mb – количество бит, необходимых для хранения каждой из координат, рассчитываются по следующим формулам:
|
| (12) |
Здесь CEIL – функция округления до максимального целого, Md и Nd – количество доменов, умещающихся по горизонтали и вертикали, которые рассчитываются по формулам:
| (13) |
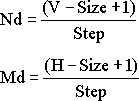
где V и H – вертикальный и горизонтальный размеры изображения, Size – размер доменного блока, Step – шаг поиска доменной области.
Для хранения преобразования T необходимо 3 бита.
Для хранения U и V необходимо 9 и 7 бит соответственно.
Для примера возьмём изображение размером 256x256 пикселей, и будем исследовать доменную область с шагом 4 пикселя.
Nd = Md = (256 - 8 + 1) / 4 = 62
Nb = Mb = CEIL (log2 62) = 6
Х = 12
Z = 12 + 3 + 6 + 6 = 27
Коэффициент сжатия S составляет
S = (8 * 8 * 8) / 27 = 19
Коэффициент сжатия не так велик, как хотелось бы, но и параметры сжатия далеко не оптимальны, и коэффициент может увеличиваться в разы.
А теперь оценим вычислительную сложность данного алгоритма. На этапе компрессии мы должны перебрать все доменные области – 1'024 штуки, для каждой – все ранговые – 58'081 штука (при шаге 1), а для каждой из них, в свою очередь, – все 8 преобразований. Итого получается 1'024 х 58'081 х 8 = 475'799'552 действия. При этом эти действия не тривиальны и включают несколько матричных операций, которые, в свою очередь, включают операции умножения и деления чисел с плавающей точкой.
К сожалению, даже на современном ПК (а именно для таких машин хотелось реализовать алгоритм) понадобится недопустимо много времени для того, чтобы сжать изображение размером всего 256 х 256 пикселов. Очевидно, что рассмотренный алгоритм нуждается в оптимизации.
Лекция 5. Нормальные формы отношенийВ процессе проектирования базы данных возникают вопросы: хорошо ли спроектированы отношения между сущностями? Правильно ли они отражают предметную область?
На стадии физической реализации базы данных отношения преобразуются в таблицы, атрибуты становятся столбцами таблиц, для ключевых атрибутов создаются уникальные индексы, домены преображаются в типы данных, принятые в конкретной СУБД.
При этом также возникают вопросы: хорошо ли спроектированы таблицы? Правильно ли выбраны индексы?
Для ответа на этот вопрос необходимо рассмотреть понятие нормальной формы.
Рассмотрим в качестве примера предметной области некоторую организацию, выполняющую проекты. Модель предметной области опишем следующим неформальным текстом:
1. Сотрудники организации выполняют проекты.
2. Проекты состоят из нескольких заданий.
3. Каждый сотрудник может участвовать в одном или нескольких проектах, или временно не участвовать ни в каких проектах.
4. Над каждым проектом может работать несколько сотрудников, или временно проект может быть приостановлен, тогда над ним не работает ни один сотрудник.
5. Над каждым заданием в проекте работает ровно один сотрудник.
6. Каждый сотрудник числится в одном отделе.
7. Каждый сотрудник имеет телефон, находящийся в отделе сотрудника.
8. О каждом сотруднике необходимо хранить табельный номер и фамилию. Табельный номер является уникальным для каждого сотрудника.
9. Каждый отдел имеет уникальный номер.
10. Каждый проект имеет номер и наименование. Номер проекта является уникальным.
11. Каждая работа из проекта имеет номер, уникальный в пределах проекта. Работы в разных проектах могут иметь одинаковые номера.
Начинающий проектировщик будет использовать отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ (Номер сотрудника, ФИО, номер отдела, телефон, номер проекта, название проекта, номер задания), имеющее сложный ключ).
Действительно, зачем разбивать данное отношение на несколько более мелких отношений, если оно заключает в себе все данные? А разбивать надо потому, что при использовании универсального отношения возникает несколько проблем:
1. Проблема избыточности. Даже одного взгляда на отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ достаточно, чтобы увидеть, что данные хранятся в ней с большой избыточностью. Во многих строках повторяются фамилии сотрудников, номера телефонов, наименования проектов. Кроме того, в данном отношении хранятся вместе независимые друг от друга данные - и данные о сотрудниках, и об отделах, и о проектах, и о работах по проектам. Пока никаких действий с отношением не производится, это не страшно. Но как только состояние предметной области изменяется, то, при попытках соответствующим образом изменить состояние базы данных, возникает большое количество проблем.
2. Аномалии обновления. Вследствие избыточности можно обновить телефон отдела для одного сотрудника, оставляя его неизменным в других строках. Следовательно, при обновлениях необходимо просматривать всю таблицу для нахождения и изменения всех подходящих строк. Причина аномалии - избыточность данных, также порожденная тем, что в одном отношении хранится разнородная информация.
Вывод - увеличивается сложность разработки базы данных. База данных, основанная на такой модели, будет работать правильно только при наличии дополнительного программного кода в виде триггеров.
3. Аномалии включения. В отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ нельзя вставить данные о сотруднике, который пока не участвует ни в одном проекте. Действительно, если, например, во втором отделе появляется новый сотрудник, скажем, Пушников, и он пока не участвует ни в одном проекте, то мы должны вставить в отношение кортеж (4, Пушников, 2, 33-22-11, null, null, null). Это сделать невозможно, т.к. атрибут Н_ПРО (номер проекта) входит в состав сложного ключа, и, следовательно, не может содержать null-значений. Точно также нельзя вставить данные о проекте, над которым пока не работает ни один сотрудник.
Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и о проектах, и о работах по проекту).
Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно.
4. Аномалии удаления. При удалении некоторых данных может произойти потеря другой информации. Например, если закрыть проект "СУЭД" и удалить все строки, в которых он встречается, то будут потеряны все данные о сотруднике Петрове П.П.. Кроме того будет потеряна информация о том, что в отделе номер 2 имеется телефон под номером 25-54-54.
Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и о проектах, и о работах по проекту).
Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно.
1НФ (Первая Нормальная Форма)Говорят, что отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ находится в 1НФ.
Первая нормальная форма (1НФ) - это обычное отношение. Любое отношение автоматически уже находится в 1НФ. Свойства 1НФ:
· В отношении нет одинаковых кортежей.
· Кортежи не упорядочены.
· Все значения атрибутов атомарны.
В 1 НФ модель данных не адекватна модели предметной области. Следовательно, первой нормальной формы недостаточно для правильного моделирования данных.
Для устранения указанных аномалий (а на самом деле для правильного проектирования модели данных!) применяется метод нормализации отношений. Нормализация основана на понятии функциональной зависимости атрибутов отношения. Функциональная зависимость - семантическое понятие, она возникает, когда по значениям одних данных в предметной области можно определить значения других данных. Например, зная табельный номер сотрудника, можно определить его фамилию, по номеру отдела можно определить телефона.
В отношении СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ можно привести следующие примеры функциональных зависимостей:
от ключа {Н_СОТР, Н_ПРО} зависят следующие атрибуты ФИО, номер отдела, телефон, название проекта, номер задания;
от номера сотрудника зависят следующие атрибуты ФИО, номер отдела, телефон;
от номера проекта зависит наименование проекта;
от номера отдела зависит номер телефона;
Замечание. Эти зависимости отражают взаимосвязи, обнаруженные между объектами предметной области.
2НФ (Вторая Нормальная Форма)Отношение находится во второй нормальной форме (2НФ) тогда и только тогда, когда оно находится в 1НФ и нет неключевых атрибутов, зависящих от части сложного ключа. (Неключевой атрибут - это атрибут, не входящий в состав никакого потенциального ключа).
Замечание. Если ключ отношения является простым, то отношение автоматически находится в 2НФ.
Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ не находится в 2НФ, т.к. есть атрибуты, зависящие от части сложного ключа: зависимость атрибутов, характеризующих сотрудника от табельного номера сотрудника является зависимостью от части сложного ключа, зависимость наименования проекта от номера проекта является зависимостью от части сложного ключа.
Для того, чтобы устранить зависимость атрибутов от части сложного ключа, нужно произвести декомпозицию отношения на несколько отношений. При этом те атрибуты, которые зависят от части сложного ключа, выносятся в отдельное отношение.
Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ декомпозируем на три отношения - СОТРУДНИКИ_ОТДЕЛЫ, ПРОЕКТЫ, ЗАДАНИЯ.
Отношение СОТРУДНИКИ_ОТДЕЛЫ (Н_СОТР, ФИО, Н_ОТД, ТЕЛ):
Функциональные зависимости:
Зависимость атрибутов, характеризующих сотрудника от табельного номера сотрудника:
Н_СОТР ![]() ФАМ, Н_ОТД, ТЕЛ
ФАМ, Н_ОТД, ТЕЛ
Зависимость номера телефона от номера отдела:
Н_ОТД ![]() ТЕЛ
ТЕЛ
| Н_СОТР | ФАМ | Н_ОТД | ТЕЛ |
| 1 | Иванов | 1 | 25-45-45 |
| 2 | Сидоров | 1 | 25-45-45 |
| 3 | Петров | 2 | 25-54-54 |
Отношение ПРОЕКТЫ (Н_ПРО, ПРОЕКТ):
Функциональные зависимости:
Н_ПРО ![]() ПРОЕКТ
ПРОЕКТ
| Н_ПРО | ПРОЕКТ |
| 1 | СУЭД |
| 2 | Разработка ИС «Архив» |
Отношение ЗАДАНИЯ (Н_СОТР, Н_ПРО, Н_ЗАДАН):
Функциональные зависимости:
{Н_СОТР, Н_ПРО} ![]() Н_ЗАДАН
Н_ЗАДАН
| Н_СОТР | Н_ПРО | Н_ЗАДАН |
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 1 | 3 |
| 1 | 2 | 1 |
| 2 | 2 | 2 |
Отношения, полученные в результате декомпозиции, находятся в 2НФ. Действительно, отношения СОТРУДНИКИ_ОТДЕЛЫ и ПРОЕКТЫ имеют простые ключи, следовательно автоматически находятся в 2НФ, отношение ЗАДАНИЯ имеет сложный ключ, но единственный неключевой атрибут Н_ЗАДАН функционально зависит от всего ключа {Н_СОТР, Н_ПРО}.
Часть аномалий обновления устранена. Так, данные о сотрудниках и проектах теперь хранятся в различных отношениях, поэтому при появлении сотрудников, не участвующих ни в одном проекте просто добавляются кортежи в отношение СОТРУДНИКИ_ОТДЕЛЫ. Точно также, при появлении проекта, над которым не работает ни один сотрудник, просто вставляется кортеж в отношение ПРОЕКТЫ.
Фамилии сотрудников и наименования проектов теперь хранятся без избыточности. Если сотрудник сменит фамилию или проект сменит наименование, то такое обновление будет произведено единожды.
Тем не менее, часть аномалий разрешить не удалось.
1. В отношение СОТРУДНИКИ_ОТДЕЛЫ нельзя вставить кортеж (4, Пушников П.П., 1, 33-22-11), т.к. при этом получится, что два сотрудника из 1-го отдела (Иванов и Пушников) имеют разные номера телефонов, а это противоречит модели предметной области. В этой ситуации можно предложить два решения, в зависимости от того, что реально произошло в предметной области. Другой номер телефона может быть введен по двум причинам - по ошибке человека, вводящего данные о новом сотруднике, или потому что номер в отделе действительно изменился.
Причина аномалии - избыточность данных, порожденная тем, что в одном отношении хранится разнородная информация (о сотрудниках и об отделах).
Вывод - увеличивается сложность разработки базы данных. База данных, основанная на такой модели, будет работать правильно только при наличии дополнительного программного кода в виде триггеров.
2. Одни и те же номера телефонов повторяются во многих кортежах отношения. Поэтому если в отделе меняется номер телефона, то такие изменения необходимо одновременно выполнить во всех местах, где этот номер телефона встречаются, иначе отношение станет некорректным. Таким образом, обновление базы данных одним действием реализовать невозможно. Необходимо написать триггер, который при обновлении одной записи корректно исправляет номера телефонов в других местах.
Причина аномалии - избыточность данных, также порожденная тем, что в одном отношении хранится разнородная информация.
Вывод - увеличивается сложность разработки базы данных. База данных, основанная на такой модели, будет работать правильно только при наличии дополнительного программного кода в виде триггеров.
3. При удалении некоторых данных по-прежнему может произойти потеря другой информации. Например, если удалить сотрудника Петрова П.П., то будет потеряна информация о том, что в отделе номер 2 находится телефон 25-54-54.
Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и об отделах).
Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно.
Заметим, что при переходе ко второй нормальной форме отношения стали почти адекватными предметной области.
3НФ (Третья Нормальная Форма)Атрибуты называются взаимно независимыми, если ни один из них не является функционально зависимым от другого.
Отношение находится в третьей нормальной форме (3НФ) тогда и только тогда, когда отношение находится в 2НФ и все неключевые атрибуты взаимно независимы.
Отношение СОТРУДНИКИ_ОТДЕЛЫ не находится в 3НФ, т.к. имеется функциональная зависимость неключевых атрибутов (зависимость номера телефона от номера отдела):
Для того, чтобы устранить зависимость неключевых атрибутов, нужно вновь произвести декомпозицию отношения на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.
Отношение СОТРУДНИКИ_ОТДЕЛЫ декомпозируем на два отношения - СОТРУДНИКИ, ОТДЕЛЫ.
Отношение СОТРУДНИКИ (Н_СОТР, ФИО, Н_ОТД):
Функциональные зависимости:
Зависимость атрибутов, характеризующих сотрудника от табельного номера сотрудника:
Н_СОТР ![]() ФАМ, Н_ОТД, ТЕЛ
ФАМ, Н_ОТД, ТЕЛ
| Н_СОТР | ФАМ | Н_ОТД |
| 1 | Иванов | 1 |
| 2 | Сидоров | 1 |
| 3 | Петров | 2 |
Отношение ОТДЕЛЫ (Н_ОТД, ТЕЛ):
Функциональные зависимости: зависимость номера телефона от номера отдела.
| Н_ОТД | ТЕЛ |
| 1 | 25-45-45 |
| 2 | 25-54-54 |
Обратим внимание на то, что атрибут Н_ОТД, не являвшийся ключевым в отношении СОТРУДНИКИ_ОТДЕЛЫ, становится ключом в отношении ОТДЕЛЫ. Именно за счет этого устраняется избыточность, связанная с многократным хранением одних и тех же номеров телефонов.
Вывод. Таким образом, все обнаруженные аномалии обновления устранены. Реляционная модель, состоящая из четырех отношений СОТРУДНИКИ, ОТДЕЛЫ, ПРОЕКТЫ, ЗАДАНИЯ, находящихся в третьей нормальной форме, является адекватной описанной модели предметной области.
Алгоритм нормализации (приведение к 3НФ)Итак, алгоритм нормализации (т.е. алгоритм приведения отношений к 3НФ) описывается следующим образом.
Шаг 1 (Приведение к 1НФ). На первом шаге задается одно или несколько отношений, отображающих понятия предметной области. По модели предметной области выписываются обнаруженные функциональные зависимости. Все отношения автоматически находятся в 1НФ.
Шаг 2 (Приведение к 2НФ). Если в некоторых отношениях обнаружена зависимость атрибутов от части сложного ключа, то проводим декомпозицию этих отношений на несколько отношений следующим образом: те атрибуты, которые зависят от части сложного ключа выносятся в отдельное отношение вместе с этой частью ключа. В исходном отношении остаются все ключевые атрибуты:
Шаг 3 (Приведение к 3НФ). Если в некоторых отношениях обнаружена зависимость некоторых неключевых атрибутов других неключевых атрибутов, то проводим декомпозицию этих отношений следующим образом: те неключевые атрибуты, которые зависят других неключевых атрибутов выносятся в отдельное отношение. В новом отношении ключом становится детерминант функциональной зависимости:
Замечание. На практике, при создании логической модели данных, как правило, не следуют прямо приведенному алгоритму нормализации. Опытные разработчики обычно сразу строят отношения в 3НФ. Кроме того, основным средством разработки логических моделей данных являются различные варианты ER-диаграмм. Особенность этих диаграмм в том, что они сразу позволяют создавать отношения в 3НФ. Тем не менее, приведенный алгоритм важен по двум причинам. Во-первых, этот алгоритм показывает, какие проблемы возникают при разработке слабо нормализованных отношений. Во-вторых, как правило, модель предметной области никогда не бывает правильно разработана с первого шага. Эксперты предметной области могут забыть о чем-либо упомянуть, разработчик может неправильно понять эксперта, во время разработки могут измениться правила, принятые в предметной области, и т.д. Все это может привести к появлению новых зависимостей, которые отсутствовали в первоначальной модели предметной области. Тут как раз и необходимо использовать алгоритм нормализации хотя бы для того, чтобы убедиться, что отношения остались в 3НФ и логическая модель не ухудшилась.
В большинстве случаев 3НФ достаточно, чтобы разрабатывать вполне работоспособные базы данных. Однако существуют нормальные формы более высоких порядков, а именно, нормальная форма Бойса-Кодда (НФБК), четвертая нормальная форма (4НФ), пятая нормальная форма (5НФ).
НФБК (Нормальная Форма Бойса-Кодда)При приведении отношений при помощи алгоритма нормализации к отношениям в 3НФ неявно предполагалось, что все отношения содержат один потенциальный ключ. Это не всегда верно. Рассмотрим следующий пример отношения, содержащего два ключа.
Пример 1. Пусть требуется хранить данные о поставках товаров некоторыми поставщиками. Предположим, что наименования поставщиков являются уникальными. Кроме того, каждый поставщик имеет свой уникальный номер. Данные о поставках можно хранить в следующем отношении:
| Номер поставщика PNUM | Наименование поставщика PNAME | Номер товара DNUM | Поставляемое количество VOLUME |
| 1 | Фирма 1 | 1 | 100 |
| 1 | Фирма 1 | 2 | 200 |
| 1 | Фирма 1 | 3 | 300 |
| 2 | Фирма 2 | 1 | 150 |
| 2 | Фирма 2 | 2 | 250 |
| 3 | Фирма 3 | 1 | 1000 |
Данное отношение содержит два потенциальных ключа - {PNUM, DNUM} и {PNAME, DNUM}. Видно, что данные хранятся в отношении с избыточностью - при изменении наименования поставщика, это наименование нужно изменить во всех кортежах, где оно встречается. Можно ли эту аномалию устранить при помощи алгоритма нормализации, описанного в предыдущей главе? Для этого нужно выявить имеющиеся функциональные зависимости:
– наименование поставщика зависит от номера поставщика.
- номер поставщика зависит от наименования поставщика.
- поставляемое количество зависит от первого ключа отношения.
- наименование поставщика зависит от первого ключа отношения.
- поставляемое количество зависит от второго ключа отношения.
- номер поставщика зависит от второго ключа отношения.
Данное отношение не содержит неключевых атрибутов, зависящих от части сложного ключа. Действительно, от части сложного ключа зависят атрибуты PNAME и PNUM, но они сами являются ключевыми. Таким образом, отношение находится в 2НФ.
Кроме того, отношение не содержит зависимых друг от друга неключевых атрибутов, т.к. неключевой атрибут всего один - VOLUME. Таким образом, показано, что отношение "Поставки" находится в 3НФ.
Таким образом, описанный ранее алгоритм нормализации неприменим к данному отношению. Очевидно, однако, что аномалия данного отношения устраняется путем декомпозиции его на два следующих отношения:
Таблица 2 - Отношение "Поставщики"
| Номер поставщика PNUM | Наименование поставщика PNAME |
| 1 | Фирма 1 |
| 2 | Фирма 2 |
| 3 | Фирма 3 |
Таблица 3 - Отношение "Поставки-2"
| Номер поставщика PNUM | Номер детали DNUM | Поставляемое количество VOLUME |
| 1 | 1 | 100 |
| 1 | 2 | 200 |
| 1 | 3 | 300 |
| 2 | 1 | 150 |
| 2 | 2 | 250 |
| 3 | 1 | 1000 |
Определение 1. Отношение ![]() находится в нормальной форме Бойса-Кодда (НФБК) тогда и только тогда, когда детерминанты всех функциональных зависимостей являются потенциальными ключами.
находится в нормальной форме Бойса-Кодда (НФБК) тогда и только тогда, когда детерминанты всех функциональных зависимостей являются потенциальными ключами.
Замечание. Если отношение находится в НФБК, то оно автоматически находится и в 3НФ. Действительно, это сразу следует из определения 3НФ.
Отношение "Поставки" не находится в НФБК, т.к. имеются зависимости (PNUM ![]() PNAME и PNAME
PNAME и PNAME ![]() PNUM), детерминанты которых не являются потенциальными ключами.
PNUM), детерминанты которых не являются потенциальными ключами.
Для того чтобы устранить зависимость от детерминантов, не являющихся потенциальными ключами, необходимо провести декомпозицию, вынося эти детерминанты и зависимые от них части в отдельное отношение. Отношения "Поставщики" и "Поставки-2", полученные в результате декомпозиции находятся в НФБК.
Замечание. Приведенная декомпозиция отношения "Поставки" на отношения "Поставщики" и "Поставки-2" не является единственно возможной. Альтернативной декомпозицией является декомпозиция на следующие отношения:
Таблица 4 - Отношение "Поставщики"
| Номер поставщика PNUM | Наименование поставщика PNAME |
| 1 | |
| Фирма 1 | |
| 2 | |
| Фирма 2 | |
| 3 | |
| Фирма 3 |
На первый взгляд, такая декомпозиция хуже, чем первая. Действительно, наименования поставщиков по-прежнему повторяются, и при изменении наименования поставщика, это наименование придется менять одновременно в нескольких местах (тем более сразу в двух отношениях!). Кажется, что ситуация стала еще хуже, чем была до декомпозиции. Однако такое ощущение возникает от того, что мы интуитивно считаем, что наименования поставщиков могут меняться, а номера - нет. Если же предположить, что номера поставщиков тоже могут меняться (почему бы нет - директор приказал перенумеровать поставщиков!), то первая декомпозиция получается такой же "плохой" как и вторая - повторяющиеся номера придется менять одновременно в нескольких местах и также сразу в двух отношениях.
На самом деле никакого противоречия тут нет. В отношении "Поставки-3" атрибут "Наименование поставщика" (PNAME) является внешним ключом, служащим для связи с отношением "Поставщики". Поэтому, при изменении наименования поставщика, это изменение производится в отношении "Поставщики" и каскадно (см. стратегии поддержания ссылочной целостности в гл. 3) распространяется на отношение "Поставки-3" совершенно так, как изменение номера поставщика каскадно распространяется на отношение "Поставки-2". Поэтому, формально обе декомпозиции совершенно равноправны. В реальной работе разработчик выберет, конечно, первую декомпозицию, но тут важно подчеркнуть, что его выбор основан совсем на других соображениях, не имеющих отношения к формальной теории нормальных форм.
Замечание. Отношение "Поставки-2", полученное в результате декомпозиции имеет всего один потенциальный ключ. Поэтому, для анализа отношения "Поставки-2" не требуется привлекать определение НФБК, достаточно определения 3НФ. Хотя отношение "Поставщики" имеет два потенциальных ключа, но, т.к. других атрибутов в нем нет, оно уже так просто устроено, что упростить его дальше нельзя. Возникает вопрос, имеются ли нетривиальные примеры отношений в НФБК, не находящиеся в 3НФ и не такие простые, как отношение "Поставщики"?
Пример 2. Предположим, что нам по-прежнему необходимо учитывать поставки, но каждый акт поставки должен иметь некоторый уникальный номер (назовем его "сквозной номер поставки"). Отношение может иметь следующий вид:
Таблица 6 - Отношение "Поставки-с-номером"
| Номер поставщика PNUM | Номер детали DNUM | Поставляемое количество VOLUME | Сквозной номер поставки NN |
| 1 | 1 | 100 | 1 |
| 1 | 2 | 200 | 2 |
| 1 | 3 | 300 | 3 |
| 2 | 1 | 150 | 4 |
| 2 | 2 | 250 | 5 |
| 3 | 1 | 1000 | 6 |
Одним потенциальным ключом данного отношения является, как и раньше, пара атрибутов {PNUM, DNUM}. Другим ключом, в силу уникальности сквозного номера, является атрибут NN. В данном отношении имеются следующие функциональные зависимости:
Зависимость атрибутов от первого ключа отношения:
{PNUM, DNUM} ![]() VOLUME,
VOLUME,
{PNUM, DNUM} ![]() NN,
NN,
Зависимость атрибутов от второго ключа отношения:
NN ![]() PNUM,
PNUM,
NN ![]() DNUM,
DNUM,
NN ![]() VOLUME,
VOLUME,
Зависимости, являющиеся следствием зависимостей от ключей отношения:
{PNUM, DNUM} ![]() {VOLUME, NN},
{VOLUME, NN},
NN ![]() {PNUM, DNUM},
{PNUM, DNUM},
NN ![]() {PNUM, VOLUME},
{PNUM, VOLUME},
NN ![]() {DNUM, VOLUME},
{DNUM, VOLUME},
NN ![]() {PNUM, DNUM, VOLUME}.
{PNUM, DNUM, VOLUME}.
Как можно заметить, детерминанты всех зависимостей являются потенциальными ключами, поэтому данное отношение находится в НФБК. Особенностью данного отношения является то, что оно имеет два совершенно независимых потенциальных ключа.
4НФ (Четвертая Нормальная Форма)Рассмотрим следующий пример. Пусть требуется учитывать данные об абитуриентах, поступающих в ВУЗ. При анализе предметной области были выделены следующие требования:
· Каждый абитуриент имеет право сдавать экзамены на несколько факультетов одновременно.
· Каждый факультет имеет свой список сдаваемых предметов.
· Один и тот же предмет может сдаваться на нескольких факультетах.
· Абитуриент обязан сдавать все предметы, указанные для факультета, на который он поступает, несмотря на то, что он, может быть, уже сдавал такие же предметы на другом факультете.
Предположим, что нам требуется хранить данные о том, какие предметы должен сдавать каждый абитуриент. Попытаемся хранить данные в одном отношении "Абитуриенты-Факультеты-Предметы":
Таблица 7 - Отношение "Абитуриенты-Факультеты-Предметы"
| Абитуриент | Факультет | Предмет |
| Иванов | Математический | Математика |
| Иванов | Математический | Информатика |
| Иванов | Физический | Математика |
| Иванов | Физический | Физика |
| Петров | Математический | Математика |
| Петров | Математический | Информатика |
В данный момент в отношении хранится информация о том, что абитуриент Иванов поступает на два факультета (математически и физический), а абитуриент Петров - только на математический. Кроме того, можно сделать вывод, что на математическом факультете нужно сдавать математику и информатику, а на физическом - математику и физику.
Кажется, что в отношении имеется аномалия обновления, связанная с тем, что дублируются фамилии абитуриентов, наименования факультетов и наименования предметов. Однако эта аномалия легко устраняется стандартным способом - вынесением всех наименований в отдельные отношения, оставляя в исходном отношении только соответствующие номера:
Таблица 8 - Модифицированное отношение "Абитуриенты-Факультеты-Предметы"
| Номер Абитуриента | Номер Факультета | Номер Предмета |
| 1 | 1 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 1 |
| 1 | 2 | 3 |
| 2 | 1 | 1 |
| 2 | 1 | 2 |
Теперь каждое наименование встречается только в одном месте.
И все-таки как в исходном, так и в модифицированном отношении имеются аномалии обновления, возникающие при попытке вставить или удалить кортежи.
Аномалия вставки. При попытке добавить в отношение "Абитуриенты-Факультеты-Предметы" новый кортеж, например (Сидоров, Математический, Математика), мы обязаны добавить также и кортеж (Сидоров, Математический, Информатика), т.к. все абитуриенты математического факультета обязаны иметь один и тот же список сдаваемых предметов. Соответственно, при попытке вставить в модифицированное отношении кортеж (3, 1, 1), мы обязаны вставить в него также и кортеж (3, 1, 2).
Аномалия удаления. При попытке удалить кортеж (Иванов, Математический, Математика), мы обязаны удалить также и кортеж (Иванов, Математический, Информатика) по той же самой причине.
Таким образом, вставка и удаление кортежей не может быть выполнена независимо от других кортежей отношения.
Кроме того, если мы удалим кортеж (Иванов, Физический, Математика), а вместе с ним и кортеж (Иванов, Физический, Физика), то будет потеряна информация о предметах, которые должны сдаваться на физическом факультете.
Декомпозиция отношения "Абитуриенты-Факультеты-Предметы" для устранения указанных аномалий не может быть выполнена на основе функциональных зависимостей, т.к. это отношение не содержит никаких функциональных зависимостей. Это отношение является полностью ключевым, т.е. ключом отношения является все множество атрибутов. Но ясно, что какая-то взаимосвязь между атрибутами имеется. Эта взаимосвязь описывается понятием многозначной зависимости.
Определение 2. Пусть ![]() - отношение, и
- отношение, и ![]() ,
, ![]() ,
, ![]() - некоторые из его атрибутов (или непересекающиеся множества атрибутов).
- некоторые из его атрибутов (или непересекающиеся множества атрибутов).
Тогда атрибуты (множества атрибутов) ![]() и
и ![]() многозначно зависят от
многозначно зависят от ![]() (обозначается
(обозначается ![]() ), тогда и только тогда, когда из того, что в отношении
), тогда и только тогда, когда из того, что в отношении ![]() содержатся кортежи
содержатся кортежи ![]() и
и ![]() следует, что в отношении
следует, что в отношении ![]() содержится также и кортеж к
содержится также и кортеж к![]() .
.
Замечание. Меняя местами кортежи ![]() и
и ![]() в определении многозначной зависимости, получим, что в отношении
в определении многозначной зависимости, получим, что в отношении ![]() должен содержаться также и кортеж
должен содержаться также и кортеж ![]() . Таким образом, атрибуты
. Таким образом, атрибуты ![]() и
и ![]() , многозначно зависящие от
, многозначно зависящие от ![]() , ведут себя "симметрично" по отношению к атрибуту
, ведут себя "симметрично" по отношению к атрибуту ![]() .
.
В отношении "Абитуриенты-Факультеты-Предметы" имеется многозначная зависимость Факультет![]() Абитуриент|Предмет.
Абитуриент|Предмет.
Словами это можно выразить так - для каждого факультета (для каждого значения из ![]() ) каждый поступающий на него абитуриент (значение из
) каждый поступающий на него абитуриент (значение из ![]() ) сдает один и тот же список предметов (набор значений из
) сдает один и тот же список предметов (набор значений из ![]() ), и для каждого факультета (для каждого значения из
), и для каждого факультета (для каждого значения из ![]() ) каждый сдаваемый на факультете экзамен (значение из
) каждый сдаваемый на факультете экзамен (значение из ![]() ) сдается одним и тем же списком абитуриентов (набор значений из
) сдается одним и тем же списком абитуриентов (набор значений из ![]() ). Именно наличие этой зависимости не позволяет независимо вставлять и удалять кортежи. Кортежи обязаны вставляться и удаляться одновременно целыми наборами.
). Именно наличие этой зависимости не позволяет независимо вставлять и удалять кортежи. Кортежи обязаны вставляться и удаляться одновременно целыми наборами.
Замечание. Если в отношении ![]() имеется не менее трех атрибутов
имеется не менее трех атрибутов ![]() ,
, ![]() ,
, ![]() и есть функциональная зависимость
и есть функциональная зависимость ![]() , то есть и многозначная зависимость
, то есть и многозначная зависимость ![]() .
.
Действительно, действуя формально в соответствии с определением многозначной зависимости, предположим, что в отношении ![]() содержатся кортежи
содержатся кортежи ![]() и
и ![]() . В силу функциональной зависимости
. В силу функциональной зависимости ![]() отсюда следует, что
отсюда следует, что ![]() . Но тогда кортеж
. Но тогда кортеж ![]() в точности совпадает с кортежем
в точности совпадает с кортежем ![]() и, следовательно, содержится в отношении
и, следовательно, содержится в отношении ![]() . Таким образом, имеется многозначная зависимость
. Таким образом, имеется многозначная зависимость ![]() .
.
Таким образом, понятие многозначной зависимости является обобщением понятия функциональной зависимости.
Определение 3. Многозначная зависимость ![]() называется нетривиальной многозначной зависимостью, если не существует функциональных зависимостей
называется нетривиальной многозначной зависимостью, если не существует функциональных зависимостей ![]() и
и ![]() .
.
В отношении "Абитуриенты-Факультеты-Предметы" имеется именно нетривиальная многозначная зависимость Факультет![]() Абитуриент|Предмет. В силу нетривиальности этой зависимости мы не можем воспользоваться теоремой Хеза для декомпозиции отношения. Однако Фейджином Р. [52] доказана следующая теорема:
Абитуриент|Предмет. В силу нетривиальности этой зависимости мы не можем воспользоваться теоремой Хеза для декомпозиции отношения. Однако Фейджином Р. [52] доказана следующая теорема:
Теорема (Фейджина). Пусть ![]() ,
, ![]() ,
, ![]() - непересекающиеся множества атрибутов отношения
- непересекающиеся множества атрибутов отношения![]() .
.
Декомпозиция отношения ![]() на проекции
на проекции ![]() и
и ![]() будет декомпозицией без потерь тогда и только тогда, когда имеется многозначная зависимость
будет декомпозицией без потерь тогда и только тогда, когда имеется многозначная зависимость ![]() .
.
Замечание. Если зависимость ![]() является тривиальной, т.е. существует одна из функциональных зависимостей
является тривиальной, т.е. существует одна из функциональных зависимостей ![]() или
или ![]() , то получаем теорему Хеза.
, то получаем теорему Хеза.
Доказательство теоремы.
Необходимость. Пусть декомпозиция отношения ![]() на проекции
на проекции ![]() и
и ![]() является декомпозицией без потерь. Докажем что
является декомпозицией без потерь. Докажем что ![]() .
.
Предположим, что отношение ![]() содержит кортежи
содержит кортежи ![]() и
и ![]() . Необходимо доказать, что кортеж
. Необходимо доказать, что кортеж ![]() также содержится в
также содержится в ![]() . По определению проекций, кортеж
. По определению проекций, кортеж ![]() содержится в
содержится в ![]() , а кортеж
, а кортеж ![]() содержится в
содержится в ![]() . Тогда кортеж
. Тогда кортеж ![]() содержится в естественном соединении
содержится в естественном соединении ![]() , а в силу того, что декомпозиция является декомпозицией без потерь, этот кортеж содержится и в
, а в силу того, что декомпозиция является декомпозицией без потерь, этот кортеж содержится и в ![]() . Необходимость доказана.
. Необходимость доказана.
Достаточность. Пусть имеется многозначная зависимость ![]() . Докажем, что декомпозиция отношения
. Докажем, что декомпозиция отношения ![]() на проекции
на проекции ![]() и
и ![]() является декомпозицией без потерь.
является декомпозицией без потерь.
Как и в доказательстве теоремы Хеза, нужно доказать, что ![]() для любого состояния отношения
для любого состояния отношения ![]() .
.
Включение ![]() доказывается как в теореме Хеза. Такое включение выполняется всегда для любой декомпозиции отношения
доказывается как в теореме Хеза. Такое включение выполняется всегда для любой декомпозиции отношения ![]() .
.
Докажем включение ![]() . Пусть кортеж
. Пусть кортеж ![]() . Это означает, что в проекции
. Это означает, что в проекции ![]() содержится кортеж
содержится кортеж ![]() , а в проекции
, а в проекции ![]() содержится кортеж
содержится кортеж ![]() . По определению проекции, найдется такое значение
. По определению проекции, найдется такое значение ![]() атрибута
атрибута ![]() , что отношение
, что отношение ![]() содержит кортеж
содержит кортеж ![]() . Аналогично, найдется такое значение
. Аналогично, найдется такое значение ![]() атрибута
атрибута ![]() , что отношение
, что отношение ![]() содержит кортеж
содержит кортеж ![]() . Тогда по определению многозначной зависимости кортеж
. Тогда по определению многозначной зависимости кортеж ![]() . Включение доказано. Достаточность доказана. Теорема доказана.
. Включение доказано. Достаточность доказана. Теорема доказана.
Определение 4. Отношение ![]() находится в четвертой нормальной форме (4НФ) тогда и только тогда, когда отношение находится в НФБК и не содержит нетривиальных многозначных зависимостей.
находится в четвертой нормальной форме (4НФ) тогда и только тогда, когда отношение находится в НФБК и не содержит нетривиальных многозначных зависимостей.
Отношение "Абитуриенты-Факультеты-Предметы" находится в НФБК, но не в 4НФ. Согласно теореме Фейджина, это отношение можно без потерь декомпозировать на отношения:
Таблица 12 - Отношение "Факультеты-Абитуриенты"
| Факультет | Абитуриент |
| Математический | Иванов |
| Физический | Иванов |
| Математический | Петров |
В полученных отношениях устранены аномалии вставки и удаления, характерные для отношения "Абитуриенты-Факультеты-Предметы".
Заметим, что полученные отношения остались полностью ключевыми, и в них по-прежнему нет функциональных зависимостей.
Отношения с нетривиальными многозначными зависимостями возникают, как правило, в результате естественного соединения двух отношений по общему полю, которое не является ключевым ни в одном из отношений. Фактически это приводит к попытке хранить в одном отношении информацию о двух независимых сущностях. В качестве еще одного примера можно привести ситуацию, когда сотрудник может иметь много работ и много детей. Хранение информации о работах и детях в одном отношении приводит к возникновению нетривиальной многозначной зависимости Работник![]() Работа|Дети.
Работа|Дети.
Функциональные и многозначные зависимости позволяют произвести декомпозицию исходного отношения без потерь на две проекции. Можно, однако, привести примеры отношений, которые нельзя декомпозировать без потерь ни на какие две проекции.
Теорема Фейджина (другая формулировка). Отношение ![]() удовлетворяет зависимости соединения
удовлетворяет зависимости соединения ![]() тогда и только тогда, когда имеется многозначная зависимость
тогда и только тогда, когда имеется многозначная зависимость ![]() .
.
Т.к. теорема Фейджина является взаимно обратной, то ее можно взять в качестве определения многозначной зависимости. Таким образом, многозначная зависимость является частным случаем зависимости соединения, т.е., если в отношении имеется многозначная зависимость, то имеется и зависимость соединения. Обратное, конечно, неверно.
Определение 6. Зависимость соединения ![]() называется нетривиальной зависимостью соединения, если выполняется два условия:
называется нетривиальной зависимостью соединения, если выполняется два условия:
· Одно из множеств атрибутов ![]() не содержит потенциального ключа отношения
не содержит потенциального ключа отношения ![]() .
.
· Ни одно из множеств атрибутов не совпадает со всем множеством атрибутов отношения ![]() .
.
Для удобства работы сформулируем это определение так же и в отрицательной форме:
Определение 7. Зависимость соединения ![]() называется тривиальной зависимостью соединения, если выполняется одно из условий:
называется тривиальной зависимостью соединения, если выполняется одно из условий:
· Либо все множества атрибутов ![]() содержат потенциальный ключ отношения
содержат потенциальный ключ отношения ![]() .
.
· Либо одно из множеств атрибутов совпадает со всем множеством атрибутов отношения ![]() .
.
Определение 8. Отношение ![]() находится в пятой нормальной форме (5НФ) тогда и только тогда, когда любая имеющаяся зависимость соединения является тривиальной.
находится в пятой нормальной форме (5НФ) тогда и только тогда, когда любая имеющаяся зависимость соединения является тривиальной.
Определения 5НФ может стать более понятным, если сформулировать его в отрицательной форме:
Определение 9. Отношение ![]() не находится в 5НФ, если в отношении найдется нетривиальная зависимость соединения.
не находится в 5НФ, если в отношении найдется нетривиальная зависимость соединения.
Возвращаясь к примеру 3, становится понятно, что не зная ничего о том, какие потенциальные ключи имеются в отношении и как взаимосвязаны атрибуты, нельзя делать выводы о том, находится ли данное отношение в 5НФ (как, впрочем, и в других нормальных формах). По данному конкретному примеру можно только предположить, что отношение в примере 3 не находится в 5НФ. Предположим, что анализ предметной области позволил выявить следующие зависимости атрибутов в отношении ![]() :
:
(i) Отношение ![]() является полностью ключевым (т.е. потенциальным ключом отношения является все множество атрибутов).
является полностью ключевым (т.е. потенциальным ключом отношения является все множество атрибутов).
(ii) Имеется следующая зависимость (довольно странная, с практической точки зрения): если в отношении ![]() содержатся кортежи
содержатся кортежи ![]() ,
, ![]() и
и ![]() , то отсюда следует, что в отношении
, то отсюда следует, что в отношении ![]() содержится также и кортеж
содержится также и кортеж ![]() .
.
Утверждение. Докажем, что при наличии ограничений (i) и (ii), отношение находится в 4НФ, но не в 5НФ.
Доказательство. Покажем, что отношение ![]() находится в 4НФ. Согласно определению 4НФ, необходимо показать, что отношение находится в НФБК и не содержит нетривиальных многозначных зависимостей. Т.к. отношение является полностью ключевым, то оно автоматически находится в НФБК. Если бы в отношении имелась многозначная зависимость (необязательно нетривиальная), то, согласно теореме Фейджина, отношение можно было бы декомпозировать без потерь на две проекции. Но пример 3 показывает, что таких декомпозиций нет (здесь мы воспользовались тем, что для доказательства возможности декомпозиции необходимо доказать ее для всех возможных состояний отношения, а для доказательства невозможности достаточно привести один контрпример). Поэтому в отношении нет никаких многозначных зависимостей.
находится в 4НФ. Согласно определению 4НФ, необходимо показать, что отношение находится в НФБК и не содержит нетривиальных многозначных зависимостей. Т.к. отношение является полностью ключевым, то оно автоматически находится в НФБК. Если бы в отношении имелась многозначная зависимость (необязательно нетривиальная), то, согласно теореме Фейджина, отношение можно было бы декомпозировать без потерь на две проекции. Но пример 3 показывает, что таких декомпозиций нет (здесь мы воспользовались тем, что для доказательства возможности декомпозиции необходимо доказать ее для всех возможных состояний отношения, а для доказательства невозможности достаточно привести один контрпример). Поэтому в отношении нет никаких многозначных зависимостей.
Покажем, что отношение не находится в 5НФ. Для этого нужно привести пример нетривиальной зависимости соединения. Естественным кандидатом на нее является ![]() . Если это действительно зависимость соединения, то она нетривиальна. Действительно, ни одно из множеств атрибутов
. Если это действительно зависимость соединения, то она нетривиальна. Действительно, ни одно из множеств атрибутов ![]() ,
, ![]() и
и ![]() не совпадает с множеством всех атрибутов отношения
не совпадает с множеством всех атрибутов отношения ![]() и не содержит потенциального ключа.
и не содержит потенциального ключа.
Но является ли такая декомпозиция именно зависимостью соединения? Для этого нужно показать, что декомпозиция на три проекции ![]() ,
, ![]() и
и ![]() является декомпозицией без потерь для любого состояния отношения
является декомпозицией без потерь для любого состояния отношения ![]() (именно здесь содержится ключевая тонкость, обычно пропускаемая при анализе конкретного состояния отношения
(именно здесь содержится ключевая тонкость, обычно пропускаемая при анализе конкретного состояния отношения ![]() в примере 3, и именно здесь нам понадобятся знания о предметной области, выраженные в утверждении (ii)).
в примере 3, и именно здесь нам понадобятся знания о предметной области, выраженные в утверждении (ii)).
Как и в предыдущих доказательствах, нужно доказать, что ![]() для любого состояния отношения
для любого состояния отношения ![]() .
.
Включение ![]() доказывается как в теореме Хеза. Такое включение выполняется всегда для любой декомпозиции отношения
доказывается как в теореме Хеза. Такое включение выполняется всегда для любой декомпозиции отношения ![]() .
.
Докажем включение ![]() .
.
Пусть кортеж ![]() . Это означает, что в проекции
. Это означает, что в проекции ![]() содержится кортеж
содержится кортеж ![]() , в проекции
, в проекции ![]() содержится кортеж
содержится кортеж ![]() , а в проекции
, а в проекции ![]() содержится кортеж
содержится кортеж ![]() . По определению проекции, найдутся такие значения
. По определению проекции, найдутся такие значения ![]() ,
, ![]() ,
, ![]() атрибутов
атрибутов ![]() ,
, ![]() и
и ![]() соответственно, что отношение
соответственно, что отношение ![]() содержит кортежи
содержит кортежи ![]() ,
, ![]() и
и ![]() . Но тогда по условию (ii) в отношении
. Но тогда по условию (ii) в отношении ![]() содержится также и кортеж
содержится также и кортеж ![]() . Этим доказано необходимое включение. Утверждение доказано.
. Этим доказано необходимое включение. Утверждение доказано.
В предыдущей главе был описан алгоритм нормализации как алгоритм приведения отношений к 3НФ. Теперь мы можем продолжить этот алгоритм, доведя его до алгоритма приведения к 5НФ.
Шаг 4 (Приведение к НФБК). Если имеются отношения, содержащие несколько потенциальных ключей, то необходимо проверить, имеются ли функциональные зависимости, детерминанты которых не являются потенциальными ключами. Если такие функциональные зависимости имеются, то необходимо провести дальнейшую декомпозицию отношений. Те атрибуты, которые зависят от детерминантов, не являющихся потенциальными ключами выносятся в отдельное отношение вместе с детерминантами.
Шаг 5 (Приведение к 4НФ). Если в отношениях обнаружены нетривиальные многозначные зависимости, то необходимо провести декомпозицию для исключения таких зависимостей.
Шаг 5 (Приведение к 5НФ). Если в отношениях обнаружены нетривиальные зависимости соединения, то необходимо провести декомпозицию для исключения и таких зависимостей.
ВыводыОбобщением 3НФ на случай, когда отношение имеет более одного потенциального ключа, является нормальная форма Бойса-Кодда.
Отношение ![]() находится в нормальной форме Бойса-Кодда (НФБК) тогда и только тогда, когда детерминанты всех функциональных зависимостей являются потенциальными ключами.
находится в нормальной форме Бойса-Кодда (НФБК) тогда и только тогда, когда детерминанты всех функциональных зависимостей являются потенциальными ключами.
Нормализация отношений вплоть до нормальной формы Бойса-Кодда основывалась на понятии функциональной зависимости и теореме Хеза, гарантировавшей, что декомпозиция будет происходить без потерь информации.
Дальнейшая нормализация связана уже с обобщением понятия функциональной зависимости.
Атрибуты (множества атрибутов) ![]() и
и ![]() многозначно зависят от
многозначно зависят от ![]() , (
, (![]() ), тогда и только тогда, когда из того, что в отношении
), тогда и только тогда, когда из того, что в отношении ![]() содержатся кортежи
содержатся кортежи ![]() и
и ![]() следует, что в отношении
следует, что в отношении ![]() содержится также и кортеж к
содержится также и кортеж к![]() .
.
Корректность дальнейшей декомпозиции основывается на теореме Фейджина, которая говорит о том, что декомпозиция отношения на две проекции является декомпозицией без потерь тогда и только тогда, когда в отношении имеется некоторая многозначная зависимость.
Если в отношении имеется функциональная зависимость, то автоматически имеется и тривиальная многозначная зависимость, определяемая этой функциональной зависимостью.
Многозначная зависимость ![]() называется нетривиальной многозначной зависимостью, если не существует функциональных зависимостей
называется нетривиальной многозначной зависимостью, если не существует функциональных зависимостей ![]() и
и ![]() .
.
Отношение ![]() находится в четвертой нормальной форме (4НФ) тогда и только тогда, когда отношение находится в НФБК и не содержит нетривиальных многозначных зависимостей.
находится в четвертой нормальной форме (4НФ) тогда и только тогда, когда отношение находится в НФБК и не содержит нетривиальных многозначных зависимостей.
Имеют место зависимости специального вида, когда отношение не может быть подвергнуто декомпозиции без потерь на две проекции, но может быть декомпозировано на большее число проекций. Такие зависимости называются зависимостями соединения и являются обобщением понятия многозначной зависимости.
Отношение ![]() находится в пятой нормальной форме (5НФ) тогда и только тогда, когда любая имеющаяся зависимость соединения является тривиальной.
находится в пятой нормальной форме (5НФ) тогда и только тогда, когда любая имеющаяся зависимость соединения является тривиальной.
При разработке базы данных можно выделить несколько уровней моделирования:
· Сама предметная область
· Модель предметной области
· Логическая модель данных
· Физическая модель данных
· Собственно база данных и приложения
Ключевые решения, определяющие качество будущей базы данных закладываются на этапе разработки логической модели данных. "Хорошие" модели данных должны удовлетворять определенным критериям:
· Адекватность базы данных предметной области
· Легкость разработки и сопровождения базы данных
· Скорость выполнения операций обновления данных (вставка, обновление, удаление)
· Скорость выполнения операций выборки данных
Первая нормальная форма (1НФ) - это обычное отношение. Отношение в 1НФ обладает следующими свойствами:
· В отношении нет одинаковых кортежей.
· Кортежи не упорядочены.
· Атрибуты не упорядочены.
· Все значения атрибутов атомарны.
Отношения, находящиеся в 1НФ являются "плохими" в том смысле, что они не удовлетворяют выбранным критериям - имеется большое количество аномалий обновления, для поддержания целостности базы данных требуется разработка сложных триггеров.
Отношение ![]() находится во второй нормальной форме (2НФ) тогда и только тогда, когда отношение находится в 1НФ и нет неключевых атрибутов, зависящих от части сложного ключа.
находится во второй нормальной форме (2НФ) тогда и только тогда, когда отношение находится в 1НФ и нет неключевых атрибутов, зависящих от части сложного ключа.
Отношения в 2НФ "лучше", чем в 1НФ, но еще недостаточно "хороши" - остается часть аномалий обновления, по-прежнему требуются триггеры, поддерживающие целостность базы данных.
Отношение ![]() находится в третьей нормальной форме (3НФ) тогда и только тогда, когда отношение находится в 2НФ и все неключевые атрибуты взаимно независимы.
находится в третьей нормальной форме (3НФ) тогда и только тогда, когда отношение находится в 2НФ и все неключевые атрибуты взаимно независимы.
Отношения в 3НФ являются самыми "хорошими" с точки зрения выбранных нами критериев - устранены аномалии обновления, требуются только стандартные триггеры для поддержания ссылочной целостности.
Переход от ненормализованных отношений к отношениям в 3НФ может быть выполнен при помощи алгоритма нормализации. Алгоритм нормализации заключается в последовательной декомпозиции отношений для устранения функциональных зависимостей атрибутов от части сложного ключа (приведение к 2НФ) и устранения функциональных зависимостей неключевых атрибутов друг от друга (приведение к 3НФ).
Корректность процедуры нормализации (декомпозиция без потери информации) доказывается теоремой Хеза.
Операторы SQLОснову языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям.
Можно выделить следующие группы операторов (перечислены не все операторы SQL):
Операторы определения объектов базы данных· CREATE SCHEMA - создать схему базы данных
· DROP SHEMA - удалить схему базы данных
· CREATE TABLE - создать таблицу
· ALTER TABLE - изменить таблицу
· DROP TABLE - удалить таблицу
· CREATE DOMAIN - создать домен
· ALTER DOMAIN - изменить домен
· DROP DOMAIN - удалить домен
· CREATE COLLATION - создать последовательность
· DROP COLLATION - удалить последовательность
· CREATE VIEW - создать представление
· DROP VIEW - удалить представление
Операторы манипулирования данными· SELECT - отобрать строки из таблиц
· INSERT - добавить строки в таблицу
· UPDATE - изменить строки в таблице
· DELETE - удалить строки в таблице
· COMMIT - зафиксировать внесенные изменения
· ROLLBACK - откатить внесенные изменения
Наиболее важными для пользователя являются операторы манипулирования данными (DML).
INSERT - вставка строк в таблицуПример 1. Вставка одной строки в таблицу Р (поля PNUM и PNAME):
INSERT INTO
P (PNUM, PNAME)
VALUES (4, "Иванов");
Пример 2. Вставка в таблицу нескольких строк, выбранных из другой таблицы (в таблицу TMP_TABLE вставляются данные о поставщиках из таблицы P, имеющие номера, большие 2):
INSERT INTO
TMP_TABLE (PNUM, PNAME)
SELECT PNUM, PNAME
FROM P
WHERE P.PNUM>2; UPDATE - обновление строк в таблице
Пример 3. Обновление нескольких строк в таблице Р (присвоить значение Пушников полю PNAME в записях, в которых в поле PNUM стоит значение 1):
UPDATE P
SET PNAME = "Пушников"
WHERE P.PNUM = 1; DELETE - удаление строк в таблице
Пример 4. Удаление нескольких строк в таблице:
DELETE FROM P
WHERE P.PNUM = 1;
Пример 5. Удаление всех строк в таблице:
DELETE FROM P; Оператор SELECT
Оператор SELECT является фактически самым важным для пользователя и самым сложным оператором SQL. Он предназначен для выборки данных из таблиц, т.е. он, собственно, и реализует одно их основных назначение базы данных - предоставлять информацию пользователю.
Оператор SELECT всегда выполняется над некоторыми таблицами, входящими в базу данных.
Замечание. На самом деле в базах данных могут быть не только постоянно хранимые таблицы, а также временные таблицы и так называемые представления. Представления - это просто хранящиеся в базе данные SELECT-выражения. С точки зрения пользователей представления - это таблица, которая не хранится постоянно в базе данных, а "возникает" в момент обращения к ней. С точки зрения оператора SELECT и постоянно хранимые таблицы, и временные таблицы и представления выглядят совершенно одинаково. Конечно, при реальном выполнении оператора SELECT системой учитываются различия между хранимыми таблицами и представлениями, но эти различия скрыты от пользователя.
Результатом выполнения оператора SELECT всегда является таблица. Таким образом, по результатам действий оператор SELECT похож на операторы реляционной алгебры. Любой оператор реляционной алгебры может быть выражен подходящим образом сформулированным оператором SELECT. Сложность оператора SELECT определяется тем, что он содержит в себе все возможности реляционной алгебры, а также дополнительные возможности, которых в реляционной алгебре нет.
Отбор данных из одной таблицыПример 6. Выбрать все данные (ставим *) из таблицы Р (ключевые слова SELECT… FROM…):
SELECT *
FROM P;
Замечание. В результате получим новую таблицу, содержащую полную копию данных из исходной таблицы P.
Пример 7. Выбрать все строки (ставим *) из таблицы Р, удовлетворяющих некоторому условию (ключевое слово WHERE…) (где в поле PNUM стоит значение, большее 2):
SELECT *
FROM P
WHERE P.PNUM > 2;
Замечание. В качестве условия в разделе WHERE можно использовать сложные логические выражения, использующие поля таблиц, константы, сравнения (>, <, = и т.д.), скобки, союзы AND (и) и OR(или), отрицание NOT (не).
Пример 8. Выбрать значения некоторого поля (например, все значения (*) поля NAME) из исходной таблицы Р (указание списка отбираемых колонок):
SELECT P.NAME
FROM P;
Замечание. В результате получим таблицу с одной колонкой, содержащую все наименования поставщиков.
Замечание. Если в исходной таблице присутствовало несколько поставщиков с разными номерами, но одинаковыми наименованиями, то в результатирующей таблице будут строки с повторениями - дубликаты строк автоматически не отбрасываются.
Пример 9. Выбрать некоторые колонки из исходной таблицы, удалив из результата повторяющиеся строки (ключевое слово DISTINCT):
SELECT DISTINCT P.NAME
FROM P;
Замечание. Использование ключевого слова DISTINCT приводит к тому, что в результатирующей таблице будут удалены все повторяющиеся строки.
Пример 10. Использование скалярных выражений и переименований колонок в запросах (ключевое слово AS…):
SELECT
TOVAR.PRICE,
"=" AS EQU,
TOVAR.KOL*TOVAR.PRICE AS SUMMA
FROM TOVAR;
В результате получим таблицу с колонками, которых не было в исходной таблице TOVAR:
| TNAME | KOL | PRICE | EQU | SUMMA |
| Болт | 10 | 100 | = | 1000 |
| Гайка | 20 | 200 | = | 4000 |
| Винт | 30 | 300 | = | 9000 |
Пример 11.Упорядочение результатов запроса (ключевое слово ORDER BY…):
SELECT
PD.PNUM,
PD.DNUM,
PD.VOLUME
FROM PD
ORDER BY DNUM;
В результате получим следующую таблицу, упорядоченную по полю DNUM:
| PNUM | DNUM | VOLUME |
| 1 | 1 | 100 |
| 2 | 1 | 150 |
| 3 | 1 | 1000 |
| 1 | 2 | 200 |
| 2 | 2 | 250 |
| 1 | 3 | 300 |
Пример 12. Упорядочение результатов запроса по нескольким полям с возрастанием или убыванием (ключевые слова ASC, DESC):
SELECT
PD.PNUM,
PD.DNUM,
PD.VOLUME
FROM PD
ORDER BY
DNUM ASC,
VOLUME DESC;
В результате получим таблицу, в которой строки идут в порядке возрастания значения поля DNUM, а строки, с одинаковым значением DNUM идут в порядке убывания значения поля VOLUME:
| PNUM | DNUM | VOLUME |
| 3 | 1 | 1000 |
| 2 | 1 | 150 |
| 1 | 1 | 100 |
| 2 | 2 | 250 |
| 1 | 2 | 200 |
| 1 | 3 | 300 |
Замечание. Если явно не указаны ключевые слова ASC или DESC, то по умолчанию принимается упорядочение по возрастанию (ASC).
Отбор данных из нескольких таблицПример 13. Естественное соединение таблиц (способ 1 - явное указание условий соединения):
SELECT
P.PNUM,
P.PNAME,
PD.DNUM,
PD.VOLUME
FROM P, PD
WHERE P.PNUM = PD.PNUM;
В результате получим новую таблицу, в которой строки с данными о поставщиках соединены со строками с данными о поставках деталей:
| PNUM | PNAME | DNUM | VOLUME |
| 1 | Иванов | 1 | 100 |
| 1 | Иванов | 2 | 200 |
| 1 | Иванов | 3 | 300 |
| 2 | Петров | 1 | 150 |
| 2 | Петров | 2 | 250 |
| 3 | Сидоров | 1 | 1000 |
Замечание. Соединяемые таблицы перечислены в разделе FROM оператора, условие соединения приведено в разделе WHERE. Раздел WHERE, помимо условия соединения таблиц, может также содержать и условия отбора строк.
Пример 14. Естественное соединение таблиц (способ 2 - ключевые слова JOIN… USING…):
SELECT
P.PNUM,
P.PNAME,
PD.DNUM,
PD.VOLUME
FROM P JOIN PD USING PNUM;
Замечание. Ключевое слово USING позволяет явно указать, по каким из общих колонок таблиц будет производиться соединение.
Пример 15. Естественное соединение таблиц (способ 3 - ключевое слово NATURAL JOIN):
SELECT
P.PNUM,
P.PNAME,
PD.DNUM,
PD.VOLUME
FROM P NATURAL JOIN PD;
Замечание. В разделе FROM не указано, по каким полям производится соединение. NATURAL JOIN автоматически соединяет по всем одинаковым полям в таблицах.
Пример 16. Естественное соединение трех таблиц:
SELECT
P.PNAME,
D.DNAME,
PD.VOLUME
FROM
P NATURAL JOIN PD NATURAL JOIN D;
В результате получим следующую таблицу:
| PNAME | DNAME | VOLUME |
| Иванов | Болт | 100 |
| Иванов | Гайка | 200 |
| Иванов | Винт | 300 |
| Петров | Болт | 150 |
| Петров | Гайка | 250 |
| Сидоров | Болт | 1000 |
Пример 17. Прямое произведение таблиц:
SELECT
P.PNUM,
P.PNAME,
D.DNUM,
D.DNAME
FROM P, D;
В результате получим следующую таблицу:
| PNUM | PNAME | DNUM | DNAME |
| 1 | Иванов | 1 | Болт |
| 1 | Иванов | 2 | Гайка |
| 1 | Иванов | 3 | Винт |
| 2 | Петров | 1 | Болт |
| 2 | Петров | 2 | Гайка |
| 2 | Петров | 3 | Винт |
| 3 | Сидоров | 1 | Болт |
| 3 | Сидоров | 2 | Гайка |
| 3 | Сидоров | 3 | Винт |
Замечание. Т.к. не указано условие соединения таблиц, то каждая строка первой таблицы соединится с каждой строкой второй таблицы.
Использование имен корреляции (алиасов, псевдонимов)Иногда приходится выполнять запросы, в которых таблица соединяется сама с собой, или одна таблица соединяется дважды с другой таблицей. При этом используются имена корреляции (алиасы, псевдонимы), которые позволяют различать соединяемые копии таблиц. Имена корреляции вводятся в разделе FROM и идут через пробел после имени таблицы. Имена корреляции должны использоваться в качестве префикса перед именем столбца и отделяются от имени столбца точкой. Если в запросе указываются одни и те же поля из разных экземпляров одной таблицы, они должны быть переименованы для устранения неоднозначности в именованиях колонок результатирующей таблицы. Определение имени корреляции действует только во время выполнения запроса.
Пример 19. Отобрать все пары поставщиков таким образом, чтобы первый поставщик в паре имел статус, больший статуса второго поставщика:
SELECT
P1.PNAME AS PNAME1,
P1.PSTATUS AS PSTATUS1,
P2.PNAME AS PNAME2,
P2.PSTATUS AS PSTATUS2
FROM
P P1, P P2
WHERE P1.PSTATUS1 > P2.PSTATUS2;
В результате получим следующую таблицу:
| PNAME1 | PSTATUS1 | PNAME2 | PSTATUS2 |
| Иванов | 4 | Петров | 1 |
| Иванов | 4 | Сидоров | 2 |
| Сидоров | 2 | Петров | 1 |
Использование агрегатных функций в запросах
Пример 21. Получить общее количество поставщиков (ключевое слово COUNT):
SELECT COUNT(*) AS N
FROM P;
В результате получим таблицу с одним столбцом и одной строкой, содержащей количество строк из таблицы P:
| N |
| 3 |
Пример 22. Получить общее, максимальное, минимальное и среднее количества поставляемых деталей (ключевые слова SUM, MAX, MIN, AVG):
SELECT
SUM(PD.VOLUME) AS SM,
MAX(PD.VOLUME) AS MX,
MIN(PD.VOLUME) AS MN,
AVG(PD.VOLUME) AS AV
FROM PD;
В результате получим следующую таблицу с одной строкой:
SM | MX | MN | AV |
| 2000 | 1000 | 100 | 333.33333333 |
Пример 23. Для каждой детали получить суммарное поставляемое количество (ключевое слово GROUP BY…):
SELECT
PD.DNUM,
SUM(PD.VOLUME) AS SM
GROUP BY PD.DNUM;
Этот запрос будет выполняться следующим образом. Сначала строки исходной таблицы будут сгруппированы так, чтобы в каждую группу попали строки с одинаковыми значениями DNUM. Потом внутри каждой группы будет просуммировано поле VOLUME. От каждой группы в результатирующую таблицу будет включена одна строка:
| DNUM | SM |
| 1 | 1250 |
| 2 | 450 |
| 3 | 300 |
Замечание. В списке отбираемых полей оператора SELECT, содержащего раздел GROUP BY можно включать только агрегатные функции и поля, которые входят в условие группировки. Следующий запрос выдаст синтаксическую ошибку:
SELECT
PD.PNUM,
PD.DNUM,
SUM(PD.VOLUME) AS SM
GROUP BY PD.DNUM;
Причина ошибки в том, что в список отбираемых полей включено поле PNUM, которое не входит в раздел GROUP BY. И действительно, в каждую полученную группу строк может входить несколько строк с различными значениями поля PNUM. Из каждой группы строк будет сформировано по одной итоговой строке. При этом нет однозначного ответа на вопрос, какое значение выбрать для поля PNUM в итоговой строке.
Замечание. Некоторые диалекты SQL не считают это за ошибку. Запрос будет выполнен, но предсказать, какие значения будут внесены в поле PNUM в результатирующей таблице, невозможно.
Пример 24. Получить номера деталей, суммарное поставляемое количество которых превосходит 400 (ключевое слово HAVING…):
Замечание. Условие, что суммарное поставляемое количество должно быть больше 400 не может быть сформулировано в разделе WHERE, т.к. в этом разделе нельзя использовать агрегатные функции. Условия, использующие агрегатные функции должны быть размещены в специальном разделе HAVING:
SELECT
PD.DNUM,
SUM(PD.VOLUME) AS SM
GROUP BY PD.DNUM
HAVING SUM(PD.VOLUME) > 400;
В результате получим следующую таблицу:
| DNUM | SM |
| 1 | 1250 |
| 2 | 450 |
Замечание. В одном запросе могут встретиться как условия отбора строк в разделе WHERE, так и условия отбора групп в разделе HAVING. Условия отбора групп нельзя перенести из раздела HAVING в раздел WHERE. Аналогично и условия отбора строк нельзя перенести из раздела WHERE в раздел HAVING, за исключением условий, включающих поля из списка группировки GROUP BY.
Использование подзапросовОчень удобным средством, позволяющим формулировать запросы более понятным образом, является возможность использования подзапросов, вложенных в основной запрос.
Пример 25. Получить список поставщиков, статус которых меньше максимального статуса в таблице поставщиков (сравнение с подзапросом):
SELECT *
FROM P
WHERE P.STATYS <
(SELECT MAX(P.STATUS) FROM P);
Замечание. Т.к. поле P.STATUS сравнивается с результатом подзапроса, то подзапрос должен быть сформулирован так, чтобы возвращать таблицу, состоящую ровно из одной строки и одной колонки.
Замечание. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий:
1. Выполнить один раз вложенный подзапрос и получить максимальное значение статуса.
2. Просканировать таблицу поставщиков P, каждый раз сравнивая значение статуса поставщика с результатом подзапроса, и отобрать только те строки, в которых статус меньше максимального.
Пример 26. Использование предиката IN. Получить список поставщиков, поставляющих деталь номер 2:
SELECT *
FROM P
WHERE P.PNUM IN
(SELECT DISTINCT PD.PNUM FROM PD
WHERE PD.DNUM = 2);
Замечание. В данном случае вложенный подзапрос может возвращать таблицу, содержащую несколько строк.
Замечание. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий:
1. Выполнить один раз вложенный подзапрос и получить список номеров поставщиков, поставляющих деталь номер 2.
2. Просканировать таблицу поставщиков P, каждый раз проверяя, содержится ли номер поставщика в результате подзапроса.
Пример 27. Использование предиката EXIST. Получить список поставщиков, поставляющих деталь номер 2:
SELECT *
FROM P
WHERE EXIST
(SELECT *
FROM PD
WHERE
PD.PNUM = P.PNUM AND
PD.DNUM = 2);
Замечание. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий:
Похожие работы

... и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных; 3. возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Однако реляционные системы далеко не ...
... функционирования. На данный момент существует достаточно большое количество разновидностей информационных систем. Классификация информационных систем обычно осуществляется на основе каких-либо выделенных признаков. Например, с точки зрения управленческого уровня, на котором осуществляется использование ИС, принято делить корпоративные ИС на следующие виды: 1. ИС для обеспечения текущих бизнес- ...
... : - между потребностями современного информационного общества в качественно новых членах, обладающих творческим мышлением и владеющих информационными технологиями и ограниченными возможностями современной школы в этом направлении; - между совершенствованием содержательной основы информационных технологий обучения и отсутствием научно-обоснованных исследований по данной проблеме. Информационные ...
... . Такая стратегия характерна для крупных организаций. Таким образом, каждая организация, учреждение, фирма проходит свой собственный путь с целью совершенствования документационного обеспечения управления на базе внедрения новых информационных технологий. Для мелких и средних предприятий целесообразен первый подход. Он является в настоящее время наиболее распространенным. В крупных организациях с ...
0 комментариев