Навигация
3. Сбои самого сервера
Разумеется, серверные программы, как и любое другое ПО, не являются идеальной программой. Идеальной, конечно, в смысле отсутствия ошибок. Если "железо" работает нормально, сервер может сам "сломаться" и либо просто перестать работать, либо испортить базу данных.
Раньше код сервера содержал вызов обычной функции позиционирования по файлу БД (seek), которая не могла адресовать более 4-гигабайт (в те далекие времена просто не было файловых систем, которые поддерживали файлы больше 4-х гигабайт). Когда в функцию передавалось такое большое число, оно обрезалось по старшим разрядам. Происходила такая ситуация при операции расширения файла БД, т.е. при записи новых страниц, а следовательно файл БД оказывался "затертым" новой информации с самого начала, т.е. с нулевой страницы (страница заголовка БД). Если новых страниц к записи было много, то уничтожалась начальная часть БД, где как правило содержатся системные таблицы, страницы информации о транзакциях и т.п. Причем борьба с пресловутым размером файла в 4 гигабайта дольше всего велась на Linux, что связано не только с кодом СУБД, но и с поддержкой файлов таких размеров самой операционной системой и ее файловыми системами. На Windows, Firebird и Yaffil этой проблемы уже нет, т.е. файл БД может иметь размер и 10, и 20 и больше гигабайт.
В любом случае, при работе на Unix или Windows следует внимательно изучить возможности ядра и конкретной (используемой) файловой системы - способны ли они работать с файлами больше 4-х гигабайт, а также проверить версию IB/FB/YA, чтобы быть уверенным в корректной работе с такими файлами, или наоборот, сразу предусмотреть разбиение БД на многофайловую, например "кусками" по 2-3 гигабайта.
В отношении файловых систем Windows известна следующая особенность: на FAT32 поддерживаются файлы размером не более 4 гигабайт (чаще всего указанное повреждение БД и происходит при использовании этой, фактически уже устаревшей, файловой системы). Допустим, размер вашей БД достиг 3-х гигабайт, и вы хотите перенести ее на NTFS, чтобы избежать ограничения в 4 Гб. Проблема в том, что с FAT32 на NTFS скопируется только 2 гигабайта из 3-х, из-за особенностей Windows. Это еще раз подчеркивает необходимость знания ограничений используемых файловых систем и их взаимодействия на одном компьютере.
4. Остановка во время сборки мусора
Если во время принудительного завершения работы сервера были активные подключения и сервер занимался сборкой мусора, то база данных может быть повреждена (и чаще всего это так и происходит). Уменьшить вероятность таких повреждений можно только отключив автоматическую сборку мусора, а в случае принудительной сборки мусора предварительно делать "быстрый" backup, чтобы резервная копия базы данных оказалась самой свежей в случае сбоя и повреждения БД.
5. Повреждения индексов
Повреждения индексов могут происходить как по всем вышеперечисленным причинам, так и из-за ряда багов сервера при работе с индексами. Поскольку индексы не являются 100% необходимым видом объектов для функционирования базы данных, их повреждения обнаруживаются значительно позже, чем повреждения других объектов БД (например, данных таблиц). И клиентские приложения могут продолжать функционировать в такой ситуации как и прежде.
Однако, при повреждении индексов возможно искажение данных, получаемых приложениями. Если в индексе повреждено несколько ключей, и сервер не выдал сообщения об ошибке при выполнении запроса, использующего такой индекс, в результат запроса не попадут записи, на которые ссылаются те самые поврежденные ключи. То есть, часть записей может "пропасть". Обнаружить разницу в выдаваемом количестве записей можно только используя запросы с полным перебором записей
SELECT * FROM TABLE
и с перебором по индексу
SELECT * FROM TABLE
WHERE FIELD > 0
где FIELD - столбец, по которому есть возможно поврежденный индекс, а > 0 - условие, которое однозначно будет выбирать все записи.
Можно этого и не делать, а при подозрении на "пропадание записей" сразу посмотреть в log-файл, и перестроить те индексы, о повреждениях которых там сообщается.
В log-файл пишутся только порядковые номера индексов (а не их имена) для конкретных таблиц. Процесс backup поврежденные или неповрежденные индексы (за исключением повреждений индексов по системным таблицам) не интересуют, т.к. индексы в backup хранятся только в виде описания в системных таблицах (restore создает индексы по этим описаниям в самом конце процесса restore). Backup считывает записи в натуральном порядке и индексы не использует, поэтому все существующие (committed) записи обязательно попадут в backup. Однако, если поврежден уникальный индекс, то в определенных условиях существует вероятность повторной вставки записи в таблицу с уже существующим (уникальным) значением столбца. Эта ситуация может привести к невосстановимому backup, т.е. процесс restore остановится в момент создания уникального индекса, обнаружив дубликат уникального значения в восстановленных записях. Но такая проблема также не является катастрофической - процесс создания индексов выполняется самым последним, т.е. после того как абсолютно все объекты БД уже восстановлены в базе данных процессом restore. Если вдруг обнаружена проблема неуникальных данных при создании индекса, можно попробовать найти такую запись (и затем удалить лишнюю) запросом
SELECT ID, COUNT(*) FROM TABLE
GROUP BY ID
HAVING (COUNT(*)) > 1
где id - столбец, по которому есть не создаваемый уникальный индекс. После этого можно активировать индексы, которые не были восстановлены.
Похожие работы
... , а иногда и невозможным. Недостатки MOLAP-модели: · Многомерные СУБД не позволяют работать с большими базами данных. · Многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память. В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения ...
... числе на промышленных предприятиях, больше подходят клиент-серверные СУБД. Мы рассмотрим особенности таких распространенных СУБД, как Oracle и MS SQL Server. Глава 4. Язык SQL в системах управления базами данных SQL (англ. Structured Query Language — язык структурированных запросов) — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных ...
... ); Pisa в университетах Глазго и Св. Эндрю (Universities of Glasgo and St. Andrew). Среди исследовательских институтов, в которых существовали мощные группы, ориентированные на исследования в области объектно-ориентированных баз данных, входили OGI (Oregon Graduate Institute ), MCC (Microelectronics and Computer Technology Corporation ) и французский исследовательский центр INRIA . На базе ...
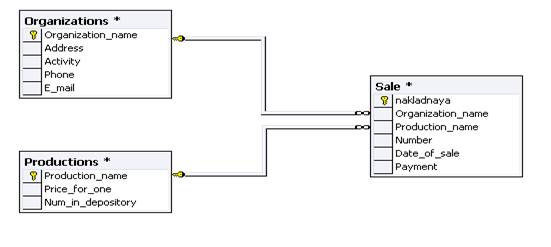
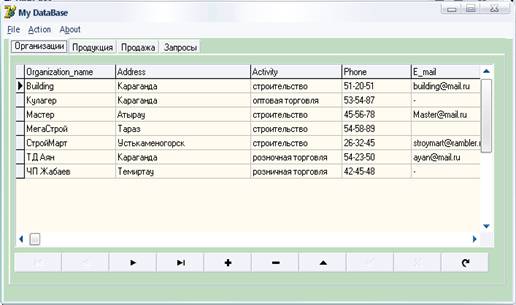
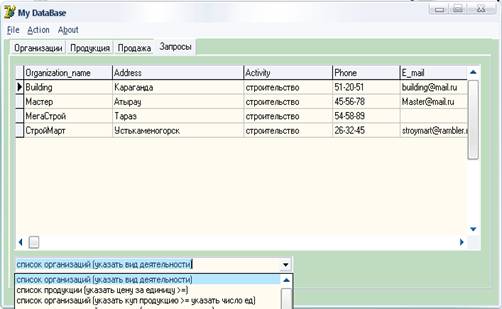
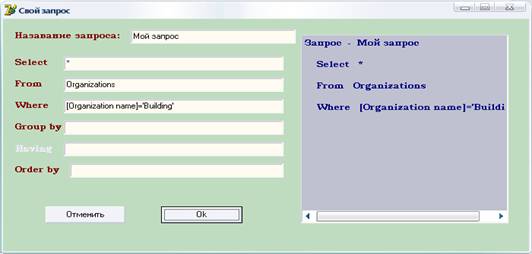
... "Понимание SQL", Москва, 2003 г 2. Т. Карпова - Базы данных: модели, разработка, реализация. Питер, 2001 3. Курс лекций по разработке баз данных, Терлецкая А.М., 2007 г Приложения Приложение А Концептуальная модель данных Приложение Б. Листинг программного кода Unit1 procedure TForm1. TabControl1Change (Sender: TObject); begin case Tabcontrol1. TabIndex of 0: // ...
0 комментариев