Навигация
Скорость операций обновления
16057
знаков
6
таблиц
13
изображений
2.2 Скорость операций обновления
На уровне логического моделирования мы определяем реляционные отношения и атрибуты этих отношений. На этом уровне мы не можем определять какие-либо физические структуры хранения (индексы, хеширование и т.п.). Единственное, чем мы можем управлять - это распределением атрибутов по различным отношениям. Можно описать мало отношений с большим количеством атрибутов, или много отношений, каждое из которых содержит мало атрибутов. Таким образом, необходимо попытаться ответить на вопрос - влияет ли количество отношений и количество атрибутов в отношениях на скорость выполнения операций обновления данных. Такой вопрос, конечно, не является достаточно корректным, т.к. скорость выполнения операций с базой данных сильно зависит от физической реализации базы данных. Тем не менее, попытаемся качественно оценить это влияние при одинаковых подходах к физическому моделированию.
В базах данных, требующих постоянных изменений (складской учет, системы продаж билетов и т.п.) производительность определяется скоростью выполнения большого количества небольших операций вставки, обновления и удаления.
Рассмотрим операцию вставки записи в таблицу. Вставка записи производится в одну из свободных страниц памяти, выделенной для данной таблицы. Если для таблицы не созданы индексы, то операция вставки выполняется фактически с одинаковой скоростью независимо от размера таблицы и от количества атрибутов в таблице. Если в таблице имеются индексы, то при выполнении операции вставки записи индексы должны быть перестроены. Таким образом, скорость выполнения операции вставки уменьшается при увеличении количества индексов у таблицы и мало зависит от числа строк в таблице.
Рассмотрим операции обновления и удаления записей из таблицы. Прежде, чем обновить или удалить запись, ее необходимо найти. Если таблица не индексирована, то единственным способом поиска является последовательное сканирование таблицы в поиске нужной записи. В этом случае, скорость операций обновления и удаления существенно увеличивается с увеличением количества записей в таблице и не зависит от количества атрибутов. Но на самом деле неиндексированные таблицы практически никогда не используются. Для каждой таблицы обычно объявляется один или несколько индексов, соответствующий потенциальным ключам. При помощи этих индексов поиск записи производится очень быстро и практически не зависит от количества строк и атрибутов в таблице (хотя, конечно, некоторая зависимость имеется). Если для таблицы объявлено несколько индексов, то при выполнении операций обновления и удаления эти индексы должны быть перестроены, на что тратится дополнительное время. Таким образом, скорость выполнения операций обновления и удаления также уменьшается при увеличении количества индексов у таблицы и мало зависит от числа строк в таблице.
Можно предположить, что чем больше атрибутов имеет таблица, тем больше для нее будет объявлено индексов. Эта зависимость, конечно, не прямая, но при одинаковых подходах к физическому моделированию обычно так и происходит. Таким образом, можно принять допущение, что чем больше атрибутов имеют отношения, разработанные в ходе логического моделирования, тем медленнее будут выполняться операции обновления данных, за счет затраты времени на перестройку большего количества индексов.
3 Функциональные модели и блок-схемы решения задачи
Функциональные модели и блок-схемы решения задачи представлены на рисунках 1, 2, 3, 4, 5.
Условные обозначения:
POS – позиция вставки;
LST – список сотрудников;
AT – добавляемый элемент;
FM – фамилия сотрудника;
PAYM – оклад сотрудника.
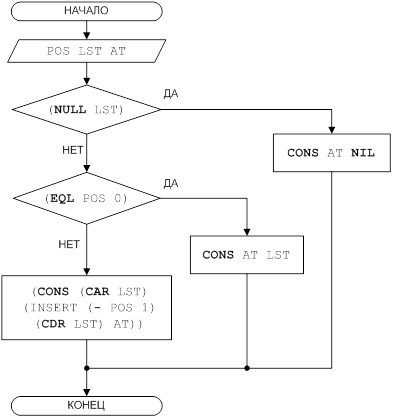
Рисунок 1 – Блок-схема решения задачи для функции INSERT
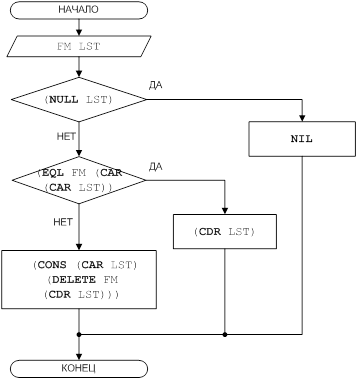
Рисунок 2 – Блок-схема решения задачи для функции DELETE
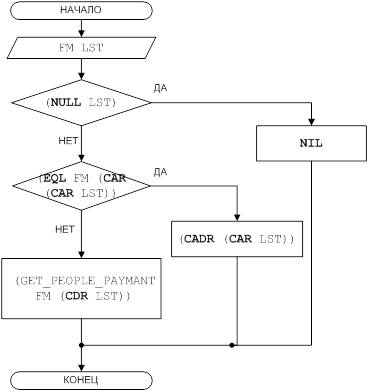
Рисунок 3 – Блок-схема решения задачи для функции GET_PEOPLE_PAYMANT
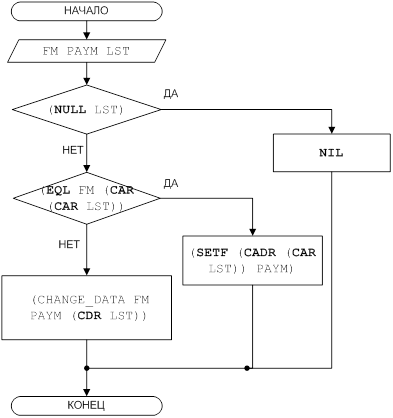
Рисунок 4 – Блок-схема решения задачи для функции CHANGE_DATA
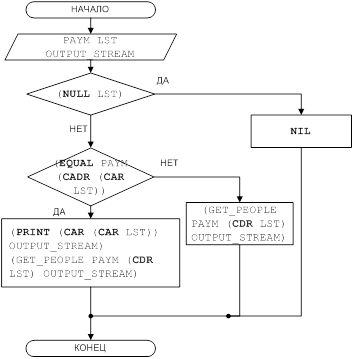
Рисунок 5 – Блок-схема решения задачи для функции GET_PEOPLE
4 Программная реализация решения задачи
;ПОЛУЧАЕМ ИЗ ФАЙЛА СПИСОК СОТРУДНИКОВ
(SETF EMPLOYEE 0)
(SETQ INPUT_STREAM (OPEN " D:\\EMPLOYEE.TXT" :DIRECTION :INPUT))
(SETQ EMPLOYEE (READ INPUT_STREAM))
(CLOSE INPUT_STREAM)
;ОСНОВНЫЕ ОПЕРАЦИИ: ВСТАВКА, УДАЛЕНИЕ, ВЫБОРКА, ИЗМЕНЕНИЕ
;ВСТАВКА
(DEFUN INSERT (POS LST AT)
(COND
((NULL LST) (CONS AT NIL))
((EQL POS 0) (CONS AT LST))
(T (CONS (CAR LST) (INSERT (- POS 1) (CDR LST) AT)))
)
)
;ВСТАВКА ЭЛЕМЕНТА AT В ПОЗИЦИЮ POS СПИСКА LST
;УДАЛЕНИЕ
(DEFUN DELETE (FM LST)
(COND
((NULL LST) NIL)
((EQL FM (CAR (CAR LST))) (CDR LST))
(T (CONS (CAR LST) (DELETE FM (CDR LST))))
)
)
;УДАЛЕНИЕ ПО ФАМИЛИИ ЗАПИСИ ИЗ СПИСКА
;ВЫБОРКА ЗАРПЛАТЫ СОТРУДНИКА ПО ЕГО ФАМИЛИИ
(DEFUN GET_PEOPLE_PAYMANT (FM LST)
(COND
((NULL LST) NIL)
((EQUAL FM (CAR (CAR LST))) (CADR (CAR LST)))
(T (GET_PEOPLE_PAYMANT FM (CDR LST)))
)
)
;ВЫБОРКА ЛЮДЕЙ С ЗАРПЛАТОЙ PAYM
(DEFUN GET_PEOPLE (PAYM LST OUTPUT_STREAM)
(COND
((NULL LST) NIL)
((EQUAL PAYM (CADR (CAR LST)))
(PROGN
(PRINT (CAR (CAR LST)) OUTPUT_STREAM)
(GET_PEOPLE PAYM (CDR LST) OUTPUT_STREAM)
)
)
(T (GET_PEOPLE PAYM (CDR LST) OUTPUT_STREAM))
)
)
;ИЗМЕНИЕ ЗАРПЛАТЫ СОТРУДНИКА
;ИЩЕМ СОТРУДНИКА ПО ЕГО ФАМИЛИИ
;МЕНЯЕМ ДАННЫЕ
(DEFUN CHANGE_DATA (FM PAYM LST)
(COND
((NULL LST) NIL)
((EQUAL FM (CAR (CAR LST))) (SETF (CADR (CAR LST)) PAYM))
(T (CHANGE_DATA FM PAYM (CDR LST)))
)
)
;----------------------------------------------------------------------
;ДОБАВЛЯЕМ СОТРУДНИКОВ
;ПОЛУЧАЕМ ИЗ ФАЙЛА НОВЫХ СОТРУДНИКОВ
(SETF NEW_EMPLOYEE 0)
(SETQ INPUT_STREAM (OPEN " D:\\ADD EMPLOYEE.TXT" :DIRECTION :INPUT))
(SETQ NEW_EMPLOYEE (READ INPUT_STREAM))
(CLOSE INPUT_STREAM)
;ДОБАВЛЯЕМ
(DO
((I 0))
((>= I (LENGTH NEW_EMPLOYEE)) EMPLOYEE)
(SETQ EMPLOYEE (INSERT 0 EMPLOYEE (NTH I NEW_EMPLOYEE)))
(SETQ I (+ I 1))
)
;ЗАПИСЫВАЕМ РЕЗУЛЬТАТ ДОБАВЛЕНИЯ СОТРУДНИКОВ
(SETQ OUTPUT_STREAM (OPEN " D:\ADD_RESULT.TXT" :DIRECTION :OUTPUT))
(PRINT EMPLOYEE OUTPUT_STREAM)
(TERPRI OUTPUT_STREAM)
(CLOSE OUTPUT_STREAM)
;----------------------------------------------------------------------
;УДАЛЯЕМ СОТРУДНИКОВ
ПОЛУЧАЕМ ФАМИЛИИ СОТРУДНИКОВ КОТОРЫХ НАДО УДАЛИТЬ
(SETF FM 0)
(SETQ INPUT_STREAM (OPEN " D:\\DEL_EMPLOYEE.TXT" :DIRECTION :INPUT))
(SETQ FM (READ INPUT_STREAM))
(CLOSE INPUT_STREAM)
;УДАЛЯЕМ
(DO
((I 0))
((>= I (LENGTH NUM)) EMPLOYEE)
(SETQ EMPLOYEE (DELETE (NTH I FM) EMPLOYEE ))
(SETQ I (+ I 1))
)
;ЗАПИСЫВАЕМ РЕЗУЛЬТАТ УДАЛЕНИЯ СОТРУДНИКОВ
(SETQ OUTPUT_STREAM (OPEN " D:\DEL_RESULT.TXT" :DIRECTION :OUTPUT))
(PRINT EMPLOYEE OUTPUT_STREAM)
(TERPRI OUTPUT_STREAM)
(CLOSE OUTPUT_STREAM)
;----------------------------------------------------------------------
;ВЫБОРКА ЗАРПЛАТЫ СОТРУДНИКА ПО ЕГО ФАМИЛИИ
(SETF FM 0)
(SETQ INPUT_STREAM (OPEN " D:\\FM.TXT" :DIRECTION :INPUT))
(SETQ FM (READ INPUT_STREAM))
(CLOSE INPUT_STREAM)
(SETQ RES NIL)
;ВЫБИРАЕМ ЗАРПЛАТУ
(DO
((I 0))
((>= I (LENGTH FM)) EMPLOYEE)
(SETQ RES (INSERT I RES (GET_PEOPLE_PAYMANT (NTH I FM) EMPLOYEE) ))
(SETQ I (+ I 1))
)
;ЗАПИСЫВАЕМ РЕЗУЛЬТАТ ВЫБОРКИ ЗАРПЛАТЫ СОТРУДНИКОВ
(SETQ OUTPUT_STREAM (OPEN " D:\PAYMANT.TXT" :DIRECTION :OUTPUT))
(PRINT RES OUTPUT_STREAM)
(TERPRI OUTPUT_STREAM)
(CLOSE OUTPUT_STREAM)
;----------------------------------------------------------------------
;ВЫБОРКА ЛЮДЕЙ С ЗАРПЛАТОЙ PAYM
(SETF PAYM 0)
(SETQ INPUT_STREAM (OPEN " D:\\PAYM.TXT" :DIRECTION :INPUT))
(SETQ PAYM (READ INPUT_STREAM))
(CLOSE INPUT_STREAM)
;ЗАПИСЫВАЕМ РЕЗУЛЬТАТ ВЫБОРКИ СОТРУДНИКОВ ПО ЗАРПЛАТЕ
(SETQ OUTPUT_STREAM (OPEN " D:\\PEOPLE.TXT" :DIRECTION :OUTPUT))
;ВЫБИРАЕМ ЛЮДЕЙ
(GET_PEOPLE PAYM EMPLOYEE OUTPUT_STREAM)
(TERPRI OUTPUT_STREAM)
(CLOSE OUTPUT_STREAM)
;----------------------------------------------------------------------
;ИЗМЕНИЕ ЗАРПЛАТЫ СОТРУДНИКА
;ИЩЕМ СОТРУДНИКА ПО ЕГО ФАМИЛИИ
;МЕНЯЕМ ДАННЫЕ
(SETF FM 0)
(SETQ INPUT_STREAM (OPEN " D:\\CHANGE.TXT" :DIRECTION :INPUT))
(SETQ FM (READ INPUT_STREAM))
(CLOSE INPUT_STREAM)
(CHANGE_DATA (CAR FM) (CADR FM) EMPLOYEE)
;ЗАПИСЫВАЕМ РЕЗУЛЬТАТ ИЗМЕНЕНИЯ ЗАРПЛАТЫ
(SETQ OUTPUT_STREAM (OPEN " D:\\NEW_EMPLOYEE.TXT" :DIRECTION :OUTPUT))
(PRINT EMPLOYEE OUTPUT_STREAM)
(TERPRI OUTPUT_STREAM)
(CLOSE OUTPUT_STREAM)
;----------------------------------------------------------------------
5 Пример выполнения программы
Пример 1.
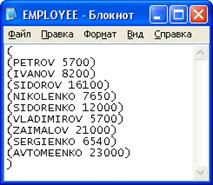
Рисунок 6 - Список сотрудников
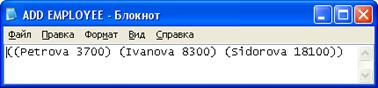
Рисунок 7 - Список сотрудников, которых нужно добавить

Рисунок 8 - Результат операции добавления
Пример 2.

Рисунок 9 - Список сотрудников

Рисунок 10 - Список сотрудников, которых нужно удалить
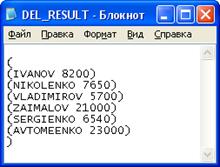
Рисунок 11 – Результат операции удаления
Пример 3.

Рисунок 12 - Список сотрудников

Рисунок 13 – Список сотрудников, оклад которых нужно узнать
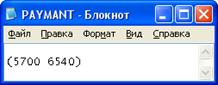
Рисунок 14 – Результат операции выбора зарплаты по заданной фамилии
Пример 4.

Рисунок 15 - Список сотрудников
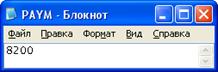
Рисунок 16 – Оклад
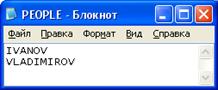
Рисунок 17 – Результат операции выбора сотрудника по заданному окладу
Пример 5.
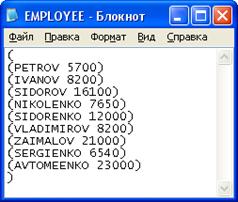
Рисунок 18 - Список сотрудников
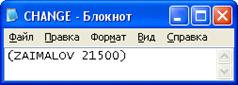
Рисунок 19 - Новый оклад сотрудника
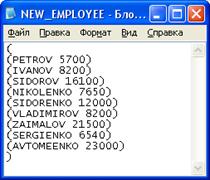
Рисунок 20 - Результат операции модификации
Заключение
Хранение и использование информации с использованием баз данных имеет решающее значение в настоящее время в большинстве предметных областей. Одно из назначений базы данных - предоставление информации пользователям.
Итогом работы можно считать созданную функциональную модель реализации основных операций над базами данных: выбор, добавление, модификация и удаление данных. Созданная функциональная модель и ее программная реализация могут служить органической частью решения более сложных задач.
Список использованных источников и литературы
1. База данных – Википедия [Электронный ресурс] – Режим доступа: http://ru.wikipedia.org/wiki/База_данных
2. Бронштейн, И.Н. Справочник по математике для инженеров и учащихся втузов [Текст] / И.Н. Бронштейн, К.А. Семендяев. – М.: Наука, 2007. – 708 с.
3. Дейт, К.Д. Введение в системы базы данных [Текст] / К.Д. Дейт – М.: Вильямс, 2006. С.1328.
4. Конноли Т. Базы данных. Проектирование, реализация и сопровождение. Теория и практика. [Электронный ресурс] / Т. Конноли, Б.Каролин – М.: Вильямс, 2003. С. 1436.
5. Симанков, В.С. Основы функционального программирования [Текст] / В.С. Симанков, Т.Т. Зангиев, И.В. Зайцев. – Краснодар: КубГТУ, 2002. – 160 с.
6. .Степанов, П.А. Функциональное программирование на языке Lisp. [Электронный ресурс] / П.А.Степанов, А.В.Бржезовский. – М.: ГУАП, 2003. С. 79.
7. Хомоненко, А.Д. Базы данных. Учебник для высших учебных заведений [Текст] / А.Д. Хомоненко, В.М. Цыганков, М.Г. Мальцев. – М.: Корона, 2004. С.736.
8. Хювенен Э. Мир Лиспа [Текст] / Э. Хювенен, Й. Сеппянен. – М.: Мир, 1990. – 460 с.
Похожие работы
... , а иногда и невозможным. Недостатки MOLAP-модели: · Многомерные СУБД не позволяют работать с большими базами данных. · Многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память. В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения ...
... 2.2 Понятия языка Лисп ________________________________ 2.2.1 Атомы и списки _____________________________ 2.2.2 Внутреннее представление списка _____________ 2.2.3 Написание программы на Лиспе _______________ 2.2.4 Определение функций _______________________ 2.2.5 Рекурсия и итерация _________________________ 2.2.6 Функции интерпретации выражений ____________ 2.2.7 Макросредства ...
... то его реализация позволила не только функционального оперировать графами, но и их визуализации [7]. Впоследствии предпринимались попытки создания универсального языка, который бы заложил долгосрочную базу под будущие языки обработки графов. Один из таких языков – GXL (Graph Transformation Languge), построенный на базе существовавшего, на тот момент, математического языка обработки деревьев TXL ( ...

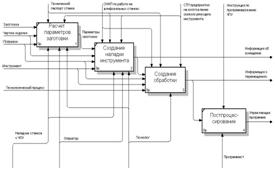
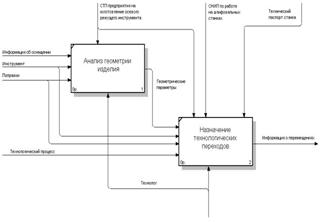
... ряде прикладных программ. Сферы применения Лиспа многообразны: наука и промышленность, образование и медицина, от декодирования генома человека до системы проектирования авиалайнеров. 3. Технологическая реализация системы подготовки обработки детали станка с ЧПУ 3.1 Описание кодов программного модуля Любой проект в Delphi состоит из нескольких частей (набора файлов, каждый из которых ...
0 комментариев