Навигация
Паралельне введення-виведення
47464
знака
3
таблицы
11
изображений
3.4 Паралельне введення-виведення.
Останній приклад 6 показує, можна було вирішити ту ж задачу простіше:
===== Example6.cpp =====
#include <mpi.h>
#include <stdio.h>
#include <string.h>
int do_decrypt_pass(int param)
{
if (param % 2 == 0) return 1;
else return 0;
}
int main(int argc, char* argv[])
{
char in_line[256],acc_name[256],acc_pass[256];
FILE * file_in;
int myrank, size;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
file_in = fopen("pass.txt","r");
printf("[%d]: file open\n",myrank); fflush(stdout);
char* p;
for (int i=0; i<= myrank;i++) fgets(in_line,256,file_in);
while (!feof(file_in))
{
if (p = strtok(in_line,"::")) sprintf(acc_name,"%s",p);
if (p = strtok(NULL,"::")) sprintf(acc_pass,"%s",p);
printf("[%d] Read: %s:: %s\n",myrank,acc_name,acc_pass); fflush(stdout);
int result = do_decrypt_pass(myrank);
if (result ==1) {printf ("[+] Proc %d got: %s:: %s\n",myrank,acc_name,acc_pass);fflush(stdout);}
else {printf ("[-] Proc %d couldn't break: %s in set limits\n",myrank,acc_name);fflush(stdout);}
for (int i=0; i< size;i++) fgets(in_line,256,file_in);
}
printf ("[%d]: Process exits\n",myrank);fflush(stdout);
MPI_Finalize();
return 0;
}
===== Example6.cpp =====
У коді немає нічого нового, тому розбір його залишаємо на самостійне проробку.
Example6 output (np =)
[0]: file open
[0] Read: apc:: 12345
[1]: file open
[1] Read: admin:: aa5632
[-] Proc 1 couldn't break: admin in set limits
[1] Read: vasya:: 1234nasja
[+] Proc 0 got: apc:: 12345
[0] Read: root:: ***
[+] Proc 0 got: root:: ***
[0] Read: man:: aa6321
[-] Proc 1 couldn't break: vasya in set limits
[1] Read: demeter:: 3ss9951
[2]: file open
[2] Read: bionicman:: 3995d
[+] Proc 2 got: bionicman:: 3995d
[2] Read: jmanderley:: 1a2_+3
[+] Proc 2 got: jmanderley:: 1a2_+3
[2] Read: wheeljack:: *3472364%s
[+] Proc 0 got: man:: aa6321
[0] Read: dalain:: 4nas5t
[+] Proc 0 got: dalain:: 4nas5t
[0] Read: cewl:: asfuh$Kjsfhdf&34kd
[-] Proc 1 couldn't break: demeter in set limits
[1] Read: nobode:: *
[-] Proc 1 couldn't break: nobode in set limits
[1] Read: hacker::
[+] Proc 2 got: wheeljack:: *3472364%s
[2] Read: lamer:: password
[+] Proc 2 got: lamer:: password
[2] Read: LASTONE:: LASTPASS
[+] Proc 2 got: LASTONE:: LASTPASS
[2]: Process exits
[+] Proc 0 got: cewl:: asfuh$Kjsfhdf&34kd
[0]: Process exits
[-] Proc 1 couldn't break: hacker in set limits
[1]: Process exits
Хоча в MPICH існує власна бібліотека вводу-виводу ROMIO, ми не користаємося нею, а просто відкриваємо файл у режимі read-only.
Завдання 1: довести, що даний метод не суперечить темі лабораторної роботи (у відповідь на питання: «А чому не з ROMIO?»);)
4. Додаток
Як корисний додаток рекомендується почитати MPICH User Guide (поставляється разом з пакетом) – у ньому міститься інформація про установку і настроювання MPICH а також інформація з настроювання MSDEV для написання MPICH-програм. У каталозі з лабораторною роботою є файли з прикладами, а також кілька текстів інших MPI-програм для ознайомлення.
Література
1. MPI Forum: http://www.mpi-forum.org
2. MPICH: http://www-unix.mcs.anl.gov/mpi/mpich
3. http://parallel.ru
4. http://www.csa.ru, http://www.ptc.spbu.ru, http://www.hpc.nw.ru, http://www.hi-hpc.nw.ru
5. Книга «Параллельное программирование для многопроцессорних вичислительних систем» (С. Немнюгин, О. Стесик, Изд БХВ-Петербург, 2002).
6. www.google.com і www.yandex.ru для пошуку всього інші.
Завдання
Крім виконання всіх завдань, викладених вище, потрібно реалізувати одну з нижчеперелічених алгоритмів у моделі MPI.
Зломщик паролів
Довести зломщик паролів до прийнятного виду і реалізувати його в схемі клієнт-сервер з використанням TCP/IP (БЕЗ MPI). Порівняти продуктивність і трудовитрати.
Напишіть сортування перерахуванням.
Напишіть сортування методом пухирця.
Напишіть сортування методом quick sort.
Напишіть програму множення матриць методом Фокса (Fox).
Постановка задачі
Над полем P задані матриці:
![]() ,
,![]()
Потрібно знайти матрицю
![]() , де
, де ![]() .
.
Опис алгоритму:
Нехай маємо топологію типу ґрати
![]() ,
,![]() .
.
Нехай також ![]() .
.
Матриця A розбивається на блоки
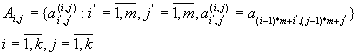
Аналогічно розбиваються матриці B і C.
Програма для процесора ![]() :
:

У результаті на процесорі ![]() :
: ![]()
Напишіть програму множення матриць методом Кэннона (Cannon)
Матриця A розбивається на блоки
Аналогічно розбиваються матриці B і C.
Програма для процесора ![]() :
:

У результаті на процесорі ![]() :
:![]()
Напишіть програму розвязок систем лінійних рівнянь (методи Зейделя/Якобі).
Кінцево-різницевий алгоритм рішення диференціальний рівнянь
Запрограмуйте двовимірний кінцево-різницевий алгоритм рішення диференціальний рівнянь і проведіть вимір продуктивності для різної кількості процесорів.
Напишіть програму транспонування матриці Nx на M процесорах.
Кожному процесу передається N/M рядків, а він повертає N/M колонок. Спробуйте використовувати різні види обміну і порівняєте результати. Проведіть вимір продуктивності.
Напишіть паралельну програму в який створюються N груп процесів і обмін між цими групами виконується по кільцю.
Необхідно буде розібратися з групами процесів і комунікаторами (MPI_Group_create, MPI_Comm_create, etc)
Проведіть дослідження швидкодії глобальний операцій MPI для різної кількості процесів і різних розмірів повідомлень.
Напишіть програми, у яких колективні операції обміну реалізовані за допомогою підпрограм двохточкового обміну. Оцініть трудовитрати і продуктивність.
Для даного масиву напишіть програму обчислення мінімального/максимального елемента масиву, не використовуючи операції приведення MPI. Зробіть те ж з використанням операцій приведення. Порівняєте.
Напишіть програму обчислення скалярного добутку векторів a і b.
Напишіть програму обчислення матричного добутку.
Дано матриці A і B. Напишіть програму обчислення матриці AB-BA.
Дано матрицю A і вектори a,b. Напишіть обчислення p = (a,Ab)
Дано матрицю A і вектори a,b. Напишіть обчислення c = a - Ab
Маємо файл, що містить записи для кожного працівника. Кожна запис включає прізвище, ім'я, рік народження і рік прийому на роботу. Напишіть програму, у якій один із процесів розподіляє всім іншим приблизно однакової порції інформації, а ці процеси формують список співробітників, стаж яких складає більш 5 років.
Результати пересилаються головному процесу, що їх виводить у файл. Використовувати ідею, але не код(!) приклада 5.
Похожие работы
... і окремих процесів. Виробничий цикл складного виробу дорівнює найбільшій сумі циклів взаємозв'язаних послідовних процесів. 3. Економічне значення і способи скорочення виробничого циклу. Виробничий цикл є важливим показником рівня організації виробничого процесу, що істотно впливає на його ефективність. Скорочення виробничого циклу зменшує незавершене виробництво і відповідно оборотні кошти пі ...
0 комментариев