Навигация
Построитель вопросительных предложений
21979
знаков
2
таблицы
2
изображения
Курсовая работа
Построитель вопросительных предложений
Содержание
Введение
1. Теоретическая часть
1.1 Генерация учебно-тренировочных задач на основе текста учебного материала
1.2 Постановка вопросов к членам предложения
2. Описание алгоритмов решения задачи
2.1 Выделение отдельных членов предложения
2.2 Построение дерева синтаксического подчинения
2.3 Генерация вопросов
2.3.1 Задание вопроса к слову
2.3.2 Построение вопросительного предложения
Заключение
Список литературы
Приложение 1. Листинг программы разбиения предложения на отдельные слова и поиска вопросительных слов к ним
Приложение 2. Список сокращений
Введение
Информационные технологии в образовании играют все более существенную роль. Современный учебный процесс трудно представить без использования компьютерных учебников, задачников, тестирующих и контролирующих систем. Одной из главных задач в таких системах является автоматическая генерация вопросительных предложений к различным частям лекционных материалов.
Цель нашей работы заключается в обеспечении автоматизации процесса составления различных тестов, проверок и задач. Для этого требуется рассмотреть несколько способов решения подобных задач и на их основе составить основной алгоритм решения поставленной перед нами задачи.
Задача генерации вопросительных предложений разбивается на несколько более простых подзадач:
1. разбор предложения (выделение отдельных членов предложения, построение дерева синтаксического подчинения);
2. построение вопросительных предложений на основе полученных результатов;
3. вывод результатов.
В нашей работе наиболее подробно будет рассмотрен только второй пункт. Так же будут затронуты проблемы разбора предложения.
1. Теоретическая часть
1.1 Генерация учебно-тренировочных задач на основе текста учебного материала
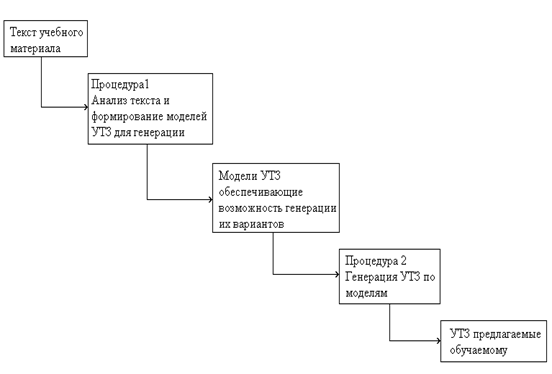
Рис. 1
Значительную долю учебного материала КУ и КОС составляет текст. Поэтому идея генерации УТЗ на его основе представляется весьма логичной. Схема, иллюстрирующая её воплощение изображена на рис. 1. В неё входят две процедуры. Первая применяется в процессе разработки КУ (КОС), вторая – при его эксплуатации. Очевидно, вторая процедура должна быть автоматической. "Идеальная" реализация рассматриваемой схемы имеет место, когда первая процедура является автоматической, т.е анализ текста и формирование моделей УТЗ для генерации производиться авторской системой без участия человека. [1]
Методы анализа текстов на естественном языке и построения на их основе моделей представления ПО находятся в фокусе исследований в области прикладной лингвистики и искусственного интеллекта. К числу ключевых проблем, связанных с развитием этих методов, относятся:
·сложность моделирования семантики;
·наличие так называемых "не-факторов", присущих человеческим представлениям и отражаемых в текстах (неточности, неполноты, несогласованности и др.)
·неоднозначность соответствия между естественно - языковыми и формализованным представлениям (одна и таже мысль может быть выражена по-разному; дополнительные трудности анализа вызывают синонимия и омонимия);
·необходимость учета контекста.
Особо отметим последнюю проблему. Человек понимает текст благодаря тому, что он обладает знаниями о ПО, к который данный текст относится. Эти знания составляют контекст, позволяющий прояснить смысл положений, содержащихся в тексте, а также извлечь из него мысли, которые имелись в виду, но не были выражены явно.
Таким образом, исходный фрагмент текста, поступающий на вход анализатора, недостачею для построения его адекватной семантической модели. Наряду с ним необходимо использовать базу знаний, отражающую как общие, так и специфичные для данной ПО представления. Создание такой базы знаний – непростая задача, на сегодняшний день в полной мере нерешенная.
Исходя из сказанного, мы считаем не рациональным стремиться во что бы то ни стало добиться автоматической Процедуры 1.
Распределение ролей между компьютерной системой и человеком в рамках интерактивной процедуры формирований УТЗ может быть разным. Чем выше степень автоматизации, тем эффективнее инструментарий и тем сложнее его реализация.
1.2 Постановка вопросов к членам предложения
Идея методов генерации вопросов к членам предложения заключается в следующем. Из текста выбирается предложение. Для него составляется грамматическая спецификация, служащая ядром модели задачи. С помощью нее в модели описываются члены предложения, к которым имеет смысл ставить вопросы. Для каждого из них определяется семантический класс, содержащий естественно-языковые выражения, представляющие некорректные альтернативные варианты ответа или его неисключающие компоненты.
По сути формулировка вопроса к какому-то члену предложения строится на основе исходного предложения путем удаления из него данного члена и подчиненных ему синтаксических единиц, добавления вопросительного слова или словосочетания, а также изменения порядка оставшихся членов.
Основные этапы интерактивной процедуры формирования модели УТЗ приведены в таблице 1.
Таблица 1.
| Этапы, выполняемые автором | Этапы, выполняемые системой |
| 1. Составление запроса на выборку предложений | |
| 2. Анализ текста учебного материала и формирование множества предложений, релевантных запросу | |
| 3. Выбор предложения из сформированного множества | |
| 4. Обработка предложения с целью упрощения его структуры | |
| 5. Составление грамматической спецификации предложения. При необходимости возврат на предыдущий этап для корректировки предложения | |
| 6. Выбор членов предложения, к которым имеет смысл ставить вопросы | |
| 7. Для каждого выбранного члена указание вопросительного слова или словосочетания. Продолжение работы в рамках процедуры либо выход из нее | |
Отметим, что не все предложения подходят для генерации вопросов. К потенциально применимым относятся предложения, являющиеся повествовательными, синтаксически членимыми и полными в плане грамматической структуры. Предпочтение при выборе стоит отдавать простым двусоставным предложениям с прямым порядком слов. Осложненные и сложные предложения также могут использоваться, однако сложность их синтаксической структуры необходимо ограничить.
Выбор предложения на третьем этапе производится автором либо реализуется автоматически. Во втором случае критерием служит максимум степени релевантности предложения поисковому запросу.
Обработка предложения на четвертом этапе может включать:
· разбиение сложного предложения на части, соответствующие простым предложениям;
· замена местоимений наименованиями обозначаемых имя сущностей;
· преобразование неполного предложения к эквивалентному ему полному;
· удаление несущественных в смысловом отношении фрагментов;
· раскрытие неоднозначностей, интерпретация которых зависит от контекста.
Развитые программные средства анализа текста, автоматически выполняющие грамматический разбор предложений, могут использоваться на пятом этапе. Вариант разбора, предложенный системой, корректируется и дополняется автором.
Наличие в инструментарии представительного тезауруса позволяет частично автоматизировать решение задач седьмого этапа. Вопросительное слово или словосочетание выбирается в зависимости от типа предложений, грамматической роли члена, к которому ставиться вопрос, типа ассоциируемой с ним предикативной единицы, а также связей между этим членом и другими синтаксическими элементами предложения.
2. Описание алгоритмов решения задачи
2.1 Выделение отдельных членов предложения
Выделение отдельных слов в предложении является простой задачей по поиску лексем в строке. За этот этап отвечает следующий алгоритм:
1. ввод исходной строки;
2. если рассматриваемый символ в строке пробел, то пропускаем все пробелы, пока не встретим букву;
3. если рассматриваемый символ буква, то добавляем его и каждый следующий символ, если он буква, к слову, пока не встретим какой-либо знак препинания;
4. увеличиваем счетчик слов на 1 и добавляем полученное слово в массив;
5. если исходная строка не закончилась, переходим к шагу 2, иначе заканчиваем работу.
Данному алгоритму соответствует нижеприведенная программа:
char res[20]; // Буфер для хранения слова
char *tmp; // Ссылка на исходную строку
int words(){
char *r;
memset(res,0,20); // Обнуление буфера слова
r=res;
if(*tmp==0)return 0; // Если исходная строка пуста или закончилась, выход из подпрограммы
while(*tmp==' '||*tmp=='\t')tmp++; // Пропуск пробелов
if(islower(*tmp)||isupper(*tmp)) // Если рассматриваемый символ буква…
{
while(islower(*tmp)||isupper(*tmp))*r++=*tmp++; // Добавляем к буферу слова очередной символ, если он буква
tmp++;
}
return 1;
}
Функция words() возвращает в качестве результата два значения: 1 и 0. 1 возвращается в том случае, когда найдено слово. Если же просмотр строки закончился или строка изначально была пуста, возвращается 0. Поэтому данная функция должна вызываться в цикле вида :
while(words()!=0){
arr[i]=(word *)calloc(1,sizeof(word)); // Добавление новой записи в массив
memset(arr[i]->wrd,0,20);
strcpy(arr[i]->wrd,res); // Запись результата работы функции в массив
i++; // Увеличение количества найденых слов
}
Так как мы рассматриваем только простые предложения и предполагаем, что числительные и порядковые пишутся словами, то функция words() не учитывает знаки препинания и цифры.
После выделения слов в предложении идет этап анализа полученных результатов. То есть, для каждого слова создается список его параметров (часть речи, падеж, род, число и т.д.), которые хранятся в структуре вида:
struct word{
char wrd[20]; //слово
char qwrd[40]; //вопрос к слову
char params[6]; // параметры слова
}.
Если же какой-то параметр не учитывается или у данного слова его нет, то в масиве params он обозначается как число 255 (или FF в шестнадцатиричной системе). Остальные значения могуь лежать в интервале от 0 до 254.
Похожие работы
... на все предлагаемые вопросы, необходимо знать операторы задания шаблонов. Приведем несколько примеров. Примеры использование символов задания шаблонов Использование символов Образец Поиск в Microsoft Access Вопросительный знак ( ? ); в качестве шаблона для любого символа. За?ор Забор Затор Звездочка ( * ); в качестве шаблона для любой группы символов. Д*нь День ...
0 комментариев