Навигация
Более сложные элементы ER-модели
36713
знаков
2
таблицы
4
изображения
2.4. Более сложные элементы ER-модели
Мы остановились только на самых основных и наиболее очевидных понятиях ER-модели данных. К числу более сложных элементов модели относятся следующие:
· Подтипы и супертипы сущностей. Как в языках программирования с развитыми типовыми системами (например, в языках объектно-ориентированного программирования), вводится возможность наследования типа сущности, исходя из одного или нескольких супертипов. Интересные нюансы связаны с необходимостью графического изображения этого механизма.
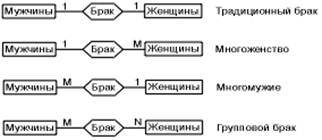
· Связи "many-to-many". Иногда бывает необходимо связывать сущности таким образом, что с обоих концов связи могут присутствовать несколько экземпляров сущности (например, все члены кооператива сообща владеют имуществом кооператива). Для этого вводится разновидность связи "многие-со-многими".
· Уточняемые степени связи. Иногда бывает полезно определить возможное количество экземпляров сущности, участвующих в данной связи (например, служащему разрешается участвовать не более, чем в трех проектах одновременно). Для выражения этого семантического ограничения разрешается указывать на конце связи ее максимальную или обязательную степень.
· Каскадные удаления экземпляров сущностей. Некоторые связи бывают настолько сильными (конечно, в случае связи "один-ко-многим"), что при удалении опорного экземпляра сущности (соответствующего концу связи "один") нужно удалить и все экземпляры сущности, соответствующие концу связи "многие". Соответствующее требование "каскадного удаления" можно сформулировать при определении сущности.
· Домены. Как и в случае реляционной модели данных бывает полезна возможность определения потенциально допустимого множества значений атрибута сущности (домена).
Эти и другие более сложные элементы модели данных "Сущность-Связи" делают ее существенно более мощной, но одновременно несколько усложняют ее использование. Конечно, при реальном использовании ER-диаграмм для проектирования баз данных необходимо ознакомиться со всеми возможностями.
Сущность может быть расщеплена на два или более взаимно исключающих подтипа, каждый из которых включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе подтипизация может продолжаться на более низких уровнях, но опыт показывает, что в большинстве случаев оказывается достаточно двух-трех уровней.
Сущность, на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, т.е. любой экземпляр супертипа должен относиться к некоторому подтипу. Иногда для полноты приходится определять дополнительный подтип ПРОЧИЕ.
Пример: Супертип ЛЕТАТЕЛЬНЫЙ АППАРАТ
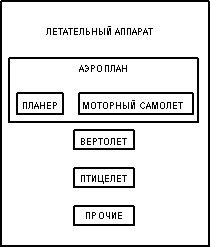
Как полагается это читать? От супертипа: ЛЕТАТЕЛЬНЫЙ АППАРАТ, который должен быть АЭРОПЛАНОМ, ВЕРТОЛЕТОМ, ПТИЦЕЛЕТОМ или ДРУГИМ ЛЕТАТЕЛЬНЫМ АППАРАТОМ. От подтипа: ВЕРТОЛЕТ, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА. От подтипа, который является одновременно супертипа: АЭРОПЛАН, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА и должен быть ПЛАНЕРОМ или МОТОРНЫМ САМОЛЕТОМ.
Иногда удобно иметь два или более разных разбиения сущности на подтипы. Например, сущность ЧЕЛОВЕК может быть разбита на подтипы по профессиональному признаку (ПРОГРАММИСТ, ДОЯРКА и т.д.), а может - по половому признаку (МУЖЧИНА, ЖЕНЩИНА).
2.5. Получение реляционной схемы из ER-схемы
Шаг 1. Каждая простая сущность превращается в таблицу. Простая сущность - сущность, не являющаяся подтипом и не имеющая подтипов. Имя сущности становится именем таблицы.
Шаг 2. Каждый атрибут становится возможным столбцом с тем же именем; может выбираться более точный формат. Столбцы, соответствующие необязательным атрибутам, могут содержать неопределенные значения; столбцы, соответствующие обязательным атрибутам, - не могут.
Шаг 3. Компоненты уникального идентификатора сущности превращаются в первичный ключ таблицы. Если имеется несколько возможных уникальных идентификатора, выбирается наиболее используемый. Если в состав уникального идентификатора входят связи, к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
Шаг 4. Связи многие-к-одному (и один-к-одному) становятся внешними ключами. Т.е. делается копия уникального идентификатора с конца связи "один", и соответствующие столбцы составляют внешний ключ. Необязательные связи соответствуют столбцам, допускающим неопределенные значения; обязательные связи - столбцам, не допускающим неопределенные значения.
Шаг 5. Индексы создаются для первичного ключа (уникальный индекс), внешних ключей и тех атрибутов, на которых предполагается в основном базировать запросы.
Шаг 6. Если в концептуальной схеме присутствовали подтипы, то возможны два способа:
· все подтипы в одной таблице (а)
· для каждого подтипа - отдельная таблица (б)
При применении способа (а) таблица создается для наиболее внешнего супертипа, а для подтипов могут создаваться представления. В таблицу добавляется по крайней мере один столбец, содержащий код ТИПА; он становится частью первичного ключа.
При использовании метода (б) для каждого подтипа первого уровня (для более нижних - представления) супертип воссоздается с помощью представления UNION (из всех таблиц подтипов выбираются общие столбцы - столбцы супертипа).
| Все в одной таблице | Таблица - на подтип |
| Преимущества | |
| Все хранится вместе | Более ясны правила подтипов |
| Недостатки | |
| Слишком общее решение | Слишком много таблиц |
Шаг 7. Имеется два способа работы при наличии исключающих связей:
· общий домен (а)
· явные внешние ключи (б)
Если остающиеся внешние ключи все в одном домене, т.е. имеют общий формат (способ (а)), то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различения связей, покрываемых дугой исключения. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи.
Если результирующие внешние ключи не относятся к одному домену, то для каждой связи, покрываемой дугой исключения, создаются явные столбцы внешних ключей; все эти столбцы могут содержать неопределенные значения.
| Общий домен | Явные внешние ключи |
| Преимущества | |
| Нужно только два столбца | Условия соединения - явные |
| Недостатки | |
| Оба дополнительных атрибута должны использоваться в соединениях | Слишком много столбцов |
Альтернативные модели сущностей:
Вариант 1 (плохой) 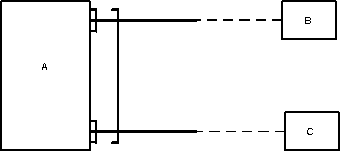
Вариант 2 (существенно лучше, если подтипы действительно существуют) 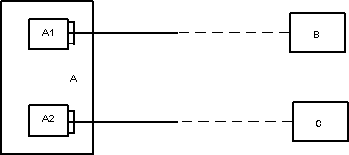
Вариант 3 (годится при наличии осмысленного супертипа D).
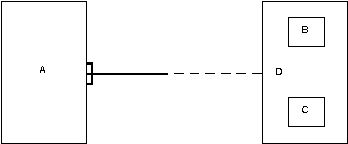
ЗАКЛЮЧЕНИЕ
При проектировании базы данных решаются две основных проблемы:
1. Каким образом отобразить объекты предметной области в абстрактные объекты модели данных, чтобы это отображение не противоречило семантике предметной области и было по возможности лучшим (эффективным, удобным и т.д.)? Часто эту проблему называют проблемой логического проектирования баз данных.
2. Как обеспечить эффективность выполнения запросов к базе данных, т.е. каким образом, имея в виду особенности конкретной системы управления базами данных, расположить данные во внешней памяти, создание каких дополнительных структур (например, индексов) потребовать и т.д.? Эту проблему называют проблемой физического проектирования баз данных.
Проблема проектирования реляционной базы данных состоит в обоснованном принятии решений о том, из каких отношений должна состоять база данных и какие атрибуты должны быть у этих отношений.
СПИСОК ЛИТЕРАТУРЫ
1. Гончаров А. «Microsoft Access ХР». – СПб: Питер, 2003
2. Горев А., Макашарипов С, Ахаян Р. Эффективная работа с СУБД. СПб, «Питер», 2002
3. Джексон Г. Проектирование реляционнных баз данных для использования с ЭВМ: Перевод с английского. М.: Мир, 1991,
4. Кирий В.Г. Информатика. Учебное пособие – Иркутск: ИрГТУ, 1998
5. Ковалевская Е.В., Волосков Н.И., Григоренко Г.П., Желнинский Г.С., Технология реализации на ЭВМ регламентных задач АСУ - М.: 1983
6. Ломтадзе В.В., Шишкина Л.П. Информатика. Учебное пособие. Иркутск: ИрГТУ, 1999
7. Подольский В.И., Григоренко Г.П., Щербакова Н.С., Дик В.В. Обработка учетной информации на ПЭВМ - М.: МЭСИ, 1993
8. Потапкин А.В. MS Visual Basic для пакета Microsoft Office. М, «Эком», 2004
9. Симонович С.В. и др. Информатика. Базовый курс – СПб: Издательство «Питер», 2003
Похожие работы

... позволяют на любом этапе разработки внести изменения в базу данных и модифицировать ее структуру без ущерба для введенных ранее данных. В процессе разработки канонической модели данных предметной области для проектирования реляционной базы данных необходимо выделить информационные объекты (ИО), соответствующие требованиям нормализации данных, и определить связи между ИО с типом отношений один ...
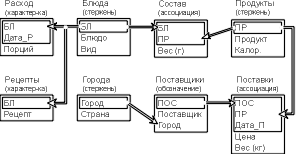
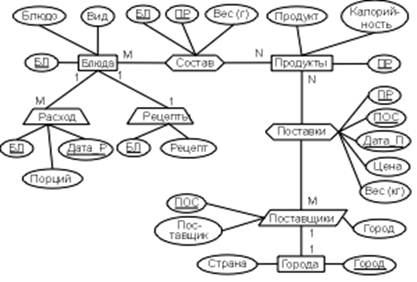
... на завершающей проверочной стадии проектирования БД, мы начнем обсуждение вопросов проектирования с рассмотрения причин, которые заставили Кодда создать основы теории нормализации. Универсальное отношение Предположим, что проектирование базы данных "Питание" (рис. 3.2) начинается с выявления атрибутов и подбора данных, образец которых (часть блюд изготовленных и реализованных 1/9/94 г.) показан ...
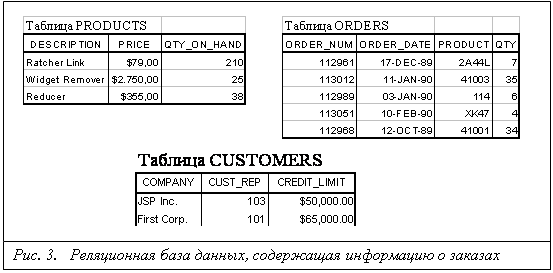


... ЭВМ. Приложения, созданные с помощью SQL и рассчитанные на однопользовательские системы, по мере своего развития могут быть перенесены в более крупные системы. Информация из корпоративных реляционных баз данных может быть загружена в базы данных отдельных подразделений или в личные базы данных. Наконец, приложения для реляционных баз данных можно вначале смоделировать на экономичных персональных ...
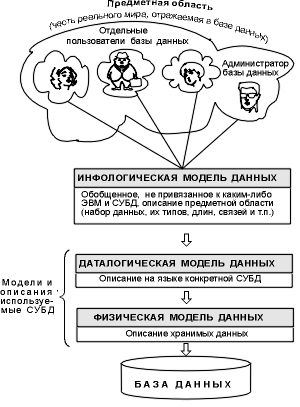
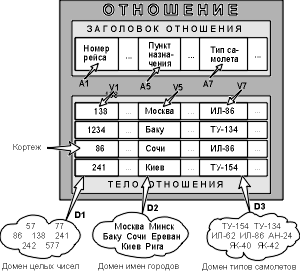
... можно с успехом использовать неформальные эквиваленты этих понятий: Отношение – Таблица (иногда Файл), Кортеж – Строка (иногда Запись), Атрибут – Столбец, Поле. 3.2 Реляционная база данных Реляционная база данных – это совокупность отношений, содержащих всю информацию, которая должна храниться в БД. Однако пользователи могут воспринимать такую базу данных как совокупность таблиц. 1. Каждая ...
0 комментариев