Навигация
Технологии расширения команд процессора
49482
знака
0
таблиц
0
изображений
7. Технологии расширения команд процессора
Первой такой выделенной технологией можно считать MultiMedia eXtension (MMX) – расширение базового набора команд процессора (57 команд для обработки графики и звука). Одной командой можно обрабатывать множество данных, что существенно повышает производительность (SIMD – Single Instruction, Many Data – одна команда, много данных).
При работе с ММХ – командами данные хранятся в регистрах сопроцессора, что означает невозможность выполнения операции с плавающей запятой при одновременном выполнении ММХ – программы. Кроме того, ММХ – команды предназначены только для работы с целыми числами.
Из технологии SIMD вышли две конкурирующих системы для поточной обработки данных.
Так, в процессоры AMD K6 – 2, кроме блока ММХ – команд, был добавлен блок 3D Now!, отвечающий за обработку трехмерных изображений. В него включено 27 новых команд для обработки чисел с плавающей запятой, и, в отличие от ММХ, 3D Now! Не поддерживает работу с процессором.
В процессорах Pentium III появился универсальный мультимедийный ускоритель, работающий по принципу SIMD, но не зависящий от ядра. Это стало возможно благодаря новому блоку SSE (Streaming SIMD Extensions – поточное SIMD – расширение). В него входят 70 команд, оперирующих 8 специальными 128 – битными регистрами. SSE позволяет выполнять одновременные операции над содержимым двух регистров.
8. Hyper – Threading
До недавнего времени повышение скорости работы процессоров связывали исключительно с увеличением их тактовой частоты и размера кэша. Но одновременное выполнение нескольких потоков также приводит к росту скорости работы процессора, причем более существенному. Именно в обработке нескольких потоков заключается суть новой технологии Hyper – Threading.
Как известно, процессор оперирует набором нескольких команд, которые необходимо выполнить. Для этой цели используется счетчик команд, который указывает на ячейки памяти, где хранится следующая для исполнения команда. После каждой команды значение этого регистра увеличивается до самого завершения потока. По окончании выполнения потока в счетчик команд заносится адрес следующей подлежащей исполнению инструкции. Потоки могут прерывать друг друга, но процессор запоминает значение счетчика команд в стеке и загружает в счетчик новое значение. Общеизвестный способ решения данной проблемы состоит в использовании двух процессоров – если один процессор в каждый момент времени может выполнять один поток, то два процессора за то же время могут выполнять уже два потока. Способность распределить выполнение нескольких потоков по ресурсам компьютера называют многопоточностью.
Что-то подобное многопоточности предлагает и новая технология от компании Intel под названием Hyper – Threading. Появилась она в ответ на проблему неполного использования исполнительных блоков процессора. Hyper – Threading – это название технологии одновременной многопоточности (Simultaneous Multi – Threading – SMT). Один физический процессор, по сути, эмулирует ОС как два логических. В процессоре с Hyper – Threading каждый логический процессор имеет свой набор регистров (включая и отдельный счетчик команд), а чтобы не усложнять технологию, в ней не реализуется одновременное исполнение некоторых команд в двух потоках.
9. Классический поток команд процессора
Когда команды извлекаются из кэша (или оперативной памяти), их необходимо декодировать и отправить на исполнение. Эти операции (получение команд, декодирование и отправка на исполнение) выполняются на препроцессоре. Из препроцессора они направляются на постпроцессор, где и выполняются. После этого результат попадает обратно в кэш (оперативную память).
Как видно, весь процесс обработки команды состоит из четырех шагов, что и определяет так называемый 4 – ступенчатый процесс (конвейер).
1. Извлечение из кэша (оперативной памяти).
2. Декодирование (разборка команды).
3. Исполнение команды (применение действий).
4. Запись в кэш (оперативную память).
Каждую из этих ступеней команда должна проходить ровно за один такт. Поэтому чем быстрее каждая из ступеней выполняет свои функции, тем быстрее работает весь процессор и тем выше его тактовая частота. Выполнение всех этих четырех команд определяет цикл. Большинство процессоров действительно исполняют команды за один цикл, но существуют сложные команды, для которых требуется несколько циклов. При исполнении сложных команд различные устройства задействуют собственные исполнительные конвейеры, тем самым, добавляя еще несколько ступеней к основному конвейеру процессора. Количество ступеней определяет глубину конвейера.
10. Поток команд процессора
В отличие от классического варианта, когда весь конвейер состоит из четырех ступеней, в большинстве современных процессоров конвейер разбивается на семь и более ступеней (гиперконвейерная обработка), для чего требуется более высокая тактовая частота.
Технология гиперконвейерой обработки предполагает удвоение длины конвейера по сравнению с предыдущей микроархитектурой Р6. например, один из основных элементов конвейера – блок предсказания ветвлений и восстановления работы – разбит на 20 тактов.
В Pentium IV на ступени исполнения используется меньшее количество функциональных блоков процессора. Но каждый из них обладает более длинным и более коротким конвейером. Процессор Pentium IV может одновременно выполнять на разных ступенях по 126 инструкций. Кроме того, в Pentium IV кэш первого уровня разделен и его кэш команд находится фактически на препроцессоре. Он называется кэшем с отслеживанием (trace cache) и оказывает влияние и на конвейер, и на основной поток команд. Эта кэш - память содержит декодированные команды х86 (микрокоманды), что устраняет задержку на расшифровку кодов команд. Исполнительные устройства процессора получают непрерывный поток команд, а общее время восстановления работы при неправильном предсказании ветвления существенно сокращается.
В процессорах с микроархитектурой х86, таких как Pentium III или Athlon, команды поступают в декодер из кэша команд, где они разбиваются на меньшие части (микрокоманды). Эти микрокоманды применяются при внеочередном исполнении команд, исполнительное устройство выполняет их планирование, исполнение и сброс. Такое разбиение имеет место, когда процессор выполняет инструкцию.
КЭШ L1
↓
Декодирование
инструкций
↓
Планирование
↓
Исполнение
↓
Сброс
(обобщенная схема работы процессора х86)
Кэш команд Pentium IV принимает транслированные и декодированные микрокоманды, готовые к передаче на внеочередное исполнение, и формирует из них мини – программы («отслеживания» - traces).
Декодирование
инструкций
↓
Тrace Сache
↓
Планирование
↓
Исполнение
↓
Сброс
(схема работы процессора Pentium IV)
По мере выполнения препроцессором накопленных отслеживаний кэш с отслеживаниями посылает до трех микрокоманд за такт на внеочередное устройство исполнения. В этом случае команды не нужно транслировать или декодировать. И только в случае промаха кэше первого уровня (L1) препроцессор начнет выбирать и декодировать инструкции из кэша второго уровня (L2) – к основному конвейеру добавляется дополнительные 8 ступеней.
Кэш с отслеживаниями работает в двух режимах:
- исполнительном (execute mode);
- построения отслеживающих сегментов (trace segment build mode).
В режиме исполнения кэш L1 передает команды исполнительным устройствам. Когда наступает промах этого кэша, он переходит в режим отслеживающих сегментов. В этом режиме препроцессор выбирает команды из кэша L2, транслирует их в микрокоманды, создает отслеживающий сегмент, который затем перемещается в кэш с отслеживающими и далее выполняется. Кэш – память уровня L2 с улучшенной передачей данных объемом 256 Кб ускоряет обмен информацией между кэш – памятью уровня 2 и ядром процессора.
Улучшенная система динамического исполнения – сложное устройство предположительного исполнения, хранящие команды для исполнительных устройств. Эта система позволяет исполнительным устройствам выбирать команды из большого набора предстоящих операций.
Как было отмечено выше, процессор начинает декодирование лишь в случае промаха кэша L1. Поэтому он разработан таким образом, чтобы декодировать только одну х86 – команду за такт. Так как длинный х86 – команды декодируются в 2 или 3 микрокоманды, то чтобы не засорять кэш с отслеживаниями, поступают следующим образом. Как только при создании отслеживающего сегмента кэш с отслеживаниями встречает длинную х86 – инструкцию, он вставляет в отслеживающий сегмент метку, которая указывает ячейки оперативной памяти с последовательностью микрокоманд данной инструкции. В режиме исполнения, когда кэш с отслеживаниями будет передавать поток инструкций на ступень исполнения, при попадании на такую метку он приостановит работу и на время передаст управление потоком команд микрокоду оперативной памяти.
Похожие работы
... работающих с мультимедиа и сопроцессором, эффективность процессора Pentium MMX меньше, чем у процессора Pentium с той же тактовой частотой [10]. Выпуск процессоров Pentium MMX возвестил о победе мультимедиа на персональных компьютерах. Кстати, MMX является сокращением от MultiMedia eXtensions (расширения для мультимедиа). В мае 1997 г. фирма Intel объявила о начале выпуска процессоров Pentium II. ...
... емкостью 320 Кбайт. Начиная с 1984 года выпускались гибкие диски 5,25 дюйма высокой плотности (1,2Мбайт). В наши дни диски размером 5,25 дюйма не используются, и соответствующие дисководы в базовой конфигурации персональных компьютеров после 1994 года не поставляются. Гибкие диски размером 3,5 дюйма выпускают с 1980 года. Односторонний диск обычной плотности имел емкость 180 Кбайт, двусторонний ...
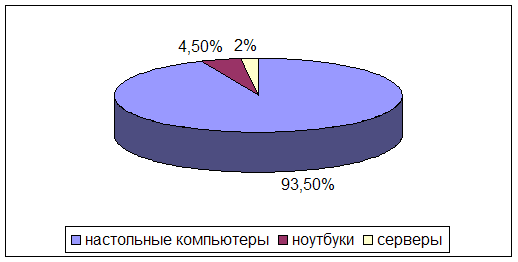
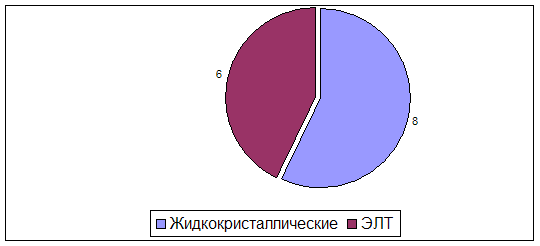
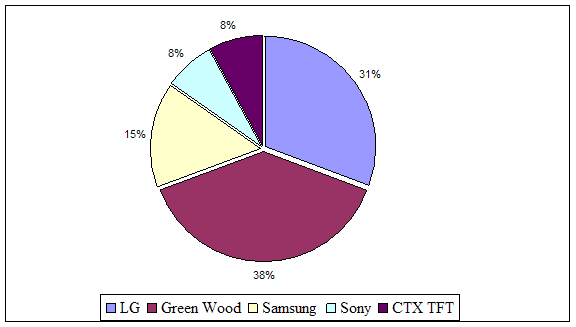
... , что привлекает покупателей. По маркам лидируют мониторы фирм LG, Green Wood, Samsung Syng Master. Эти мониторы зарекомендовали себя как наиболее надежные и долговечные. 2.3 Контроль качества персональных компьютеров и комплектующих Объектом исследования являются настольные компьютеры: 3. Компьютер Proxima на базе процессора Celeron 4. Компьютер ...
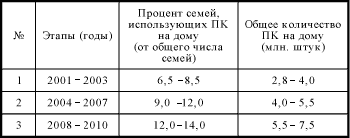

... надёжность наших компьютеров.[4] 4. Выбор конфигураций ПК Проблема выбора персонального компьютера стоит достаточно остро не только для рядового пользователя, но и зачастую актуальна профессионалу в IT. Выбор персонального компьютера в первую очередь обусловлен суммой, которую будущий владелец готов выделить на покупку. В случае ограниченных ресурсов важно определиться с задачами, которые ...
0 комментариев