Навигация
Розробка транслятора вхідної мови програмування
36049
знаков
2
таблицы
1
изображение
3. Розробка транслятора вхідної мови програмування
3.1 Вибір технології програмуванняНеобхідно вибрати ефективні методи розв’язку загальних задач, таких як розпізнавання лексем, синтаксичний розбір, семантичний аналіз та організація вводу / виводу, обчислення арифметичних виразів та організація вкладених операторів. Для реалізації лексичного аналізу в курсовій роботі використано метод перебору, тобто до чергової лексеми додається наступна буква, а тоді здійснюється пошук лексеми в таблицях ключових слів, та ідентифікаторів, якщо лексема не знайдена, тоді видається повідомлення про помилку. Під час аналізу поточних лексем здійснюється перевірка на наявність коментарів та рядкових констант при виводі. Окремим проходом формується таблиця лексем, в яку коментарі не вносяться. Таблиця лексем містить рядок, в якому була знайдена лексема, саму лексему, клас лексеми та її код. Синтаксичний аналіз базується на перевірці послідовності класів лексем, наприклад, якщо після оператора присвоєння слідує синтаксична лексема, чи після математичного оператора слідує лексема з класу порівнянь, то буде сформовано повідомлення по помилку. Для розробки синтаксичного аналізатора використано модель автомата з магазинною пам’яттю. На фазі семантичного аналізу здійснюється перевірка на відповідність типів. На цьому етапі перевіряється, чи не використовуються в одному виразі змінні одного типу, та чи не застосовано до них недопустимих операцій. Генератор коду починає свою роботу, якщо на попередніх фазах не було виявлено помилок. В залежності від коду лексеми в асемблерний файл вставляється конкретний набір процедур. Для реалізації обчислень арифметичних виразів використовується переведення їх у постфіксну форму, після чого такий вираз обчислюється з використанням математичного співпроцесора. Для переведення виразу у постфіксну форму використовується структура даних стек. Стек реалізований на масиві. В даному випадку використано стандартний набір функцій: Init (створення нового стеку), Empty (перевірка чи стек порожній), Full (перевірка чи стек повний), Push (заштовхування елементу у вершину стеку), Pop (вилучення елементу із вершини стеку). Ввід та вивід реалізовано за допомогою 21‑го переривання, функції 02h для посимвольного виводу тa 0Аh для вводу в буфер з подальшим розпізнаванням. Цикл реалізовано за допомогою команди далекого переходу (far ptr). Логічні операції виконуються над аргументами побітово, з використанням асемблерних команд AND, OR, NOT.
3.2 Проектування таблиць транслятора та вибір структур данихДля реалізації лексичного аналізу створюємо таблицю, в яку поміщаємо всі зарезервовані слова (char table[31] [10]), в курсовій роботі їх використовується 31‑е, і таблицю (char name[20] [7]) для ідентифікаторів, які будуть введені користувачем. Ім’я програми в цю таблицю не заноситься. Для реалізації таблиці лексем описана така структура:
struct Ltable
{
int num;
char slovo[30];
int klas;
char atribute;
int code;
};
Поле num призначене для зберігання рядка, в якому знаходиться лексема;
Поле slovo призначене для зберігання самої лексеми;
Поле klas призначене для зберігання класу до якого належить лексема;
Поле atribute призначене для зберігання атрибуту лексеми – «і» для ідентифікаторів цілого типу, «b» для логічних ідентифікаторів та «0» для всіх решта;
Поле code призначене для зберігання коду лексеми.
Сама таблиця лексем є масивом таких структур.
Лексеми мають такі класи:
Клас лексем блоку 1
клас операторів вводу виводу 2
клас операторів присвоєння 3
клас математичних операторів 4
клас операторів порівняння 5
клас логічних операторів 6
клас ідентифікаторів 7
клас операторів циклу 8
клас лексем оголошення 9
клас лексем опису і аргументів виводу 10
клас синтаксичних лексем 11
клас констант 12
Відомості про класи з таблиці лексем використовуються при синтаксичному аналізі. Інформація з поля atribute використовується при семантичному аналізі.
Ключові слова мають такі коди:
Program 0
Var 1
Start 2
Finish 3
Input 4
Output 5
For 6
DownTo 7
+ 8
– 9
Mul 10
Div 11
Mod 12
:= 13
== 14
!= 15
Le 16
Ge 17
!! 18
&& 19
|| 20
(21
) 22
; 23
24
<< 25
>> 26
Integer 27
Bool 28
Усі ідентифікатори та цифрові константи отримують код 30. Коди використовуються генератором коду для формування відповідних процедур мовою асемблер.
Для реалізації стеку використано таку структуру:
struct stacktype
{char data[20] [10];
int prior[20];
int kod[20];
int top;
};
Поле data використовується для зберігання символу операції;
Поле prior використовується для зберігання пріоритету операції;
Поле kod використовується для зберігання коду операції;
Поле top вказує на вершину стеку.
Для запам’ятовування виразу в постфікс ній формі використовується така структура:
struct Form
{
char post[25] [10];
int cod[25];
};
Поле post призначене для зберігання ідентифікаторів, констант і символів операцій;
Поле cod призначене для зберігання коду лексеми, що міститься у відповідному полі post.
3.3 Розробка лексичного аналізатораЛексичний аналіз – перша фаза трансляції, призначена для групування символів вхідного ланцюга в більш крупні конструкції, що називаються лексемами. З кожною лексемою зв’язано два поняття:
Клас лексеми, що визначає загальну назву для категорії елементів, що мають спільні властивості (наприклад, ідентифікатор, ціле число, рядок символів і т. д.).
Значення лексеми, що визначає підрядок символів вхідного ланцюга, що відповідають розпізнаному класу лексеми. В залежності від класу, значення лексеми може бути перетворено у внутрішнє представлення вже на етапі лексичного аналізу. Так, наприклад, роблять з числами, перетворюючи їх в машинне двійкове представлення, що забезпечує більш компактне зберігання і перевірку правильності діапазону на ранній стадії аналізу.
Лексичний аналізатор (сканер) не обов’язково обробляє всю програму до початку всіх інших фаз. Якщо лексичний аналіз не виділяється як окрема фаза компіляції, а є частиною синтаксичного аналізу, то лексична обробка тексту програми виконується по мірі необхідності по запиту синтаксичного аналізатора.
В даній курсовій роботі реалізовано стандартний алгоритм, коли з вхідного файлу видобувається по одному символу, котрий дописується до поточної лексеми. Після цього відбувається перевірка на наявність лексеми в таблиці ключових слів та таблиці ідентифікаторів. Якщо лексема не виявлена, то формується повідомлення про помилку. Під час цього встановлюються прапорці при знаходженні коментарів чи рядкових констант для виводу, тоді перевірка не відбувається, оскільки там може міститися все, що завгодно. Окремо, щоб вони не були попущені і не було видане повідомлення по помилку, встановлюються прапорці при обробці оголошень ідентифікаторів. Перевірка на закриття блоку програми відбувається при завантаженні вхідного файлу.
На фазі лексичного аналізу можуть бути сформовані такі помилки:
– не розпізнана лексема;
– перевизначення ідентифікатора;
– неправильний ідентифікатор (не починається з великої літери);
– ідентифікатор є зарезервованим словом;
Після лексичного аналізу буде сформована таблиця лексем з такими полями:
num – містить рядок, у якому була знайдена лексема;
slovo – містить символи, якими описується лексема;
klas – містить клас лексеми;
atribute – містить атрибут ідентифікатора («і» для цілих змінних, «b» лдя логічних змінних і «0» для не ідентифікаторів);
code – містить код лексеми;
Коментарі в таблицю лексем не заносяться.
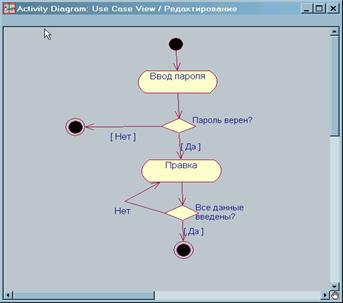
3.4 Розробка граф-схеми алгоритмуБлок під номером 2 описує частину коду програми, в якому реалізований вибір наступної букви із файлу з програмою. Оскільки пробіл та символ нового рядка в лексеми не входять, то в блоці 3 здійснюється перевірка чи поточний символ не є пробілом або символом переходу на новий рядок. Якщо умова перевірки справджується, то слід вибрати наступну лексему, а цю просто пропустити. Якщо умова перевірки не виконується, то поточний символ додається до лексеми. Якщо лексему не вдається розпізнати (блок 4), то слід перейти до наступного символу, якщо лексема розпізнана, то вона заноситься до таблиці лексем (блок 5).
Після цього, у блоці 6 виконується перевірка на закінчення вхідного файлу, якщо умова не виконується, то слід перейти до наступного символу, якщо умова виконана, то етап лексичного аналізу завершений.
Граф-схема алгоритму лексичного аналізу (1 аркуш) розроблена згідно усіх правил ЄСКД та поміщена у додатках.
3.5 Опис програми реалізації лексичного аналізатора
Програма по одному символу видобуває із вхідного тексту, котрий дописується до поточної лексеми, якщо зустрічається пробіл чи символ переходу на новий рядок, то вони пропускаються. Після цього відбувається перевірка на наявність лексеми в таблиці ключових слів та таблиці ідентифікаторів. Якщо лексема не виявлена, то формується повідомлення про помилку. Під час цього встановлюються прапорці при знаходженні коментарів чи рядкових констант для виводу, тоді перевірка не відбувається, оскільки в такому випадку лексеми можуть бути якими-завгодно. Окремо, щоб вони не були попущені і не було видане повідомлення по помилку, встановлюються прапорці при обробці оголошень ідентифікаторів.
В програмі використовуються такі прапорці:
kom_flag – використовується для виділення коментарів. Якщо знайдений символ початку коментаря, то прапорець встановлюється в одиницю і ігноруються будь-які знайдені лексеми, поки не буде знайдений символ кінця коментаря, тоді прапорець скидається в одиницю.
name_flag – використовується для виділення імені програми. Встановлюється в одиницю, коли знайдено ключове слово початку програми. Скидається в нуль після першої знайденої лексеми, котра приймається за ім’я програми.
var_flag – використовується для виділення місця, де можуть бути описані ідентифікатори. Встановлюється в одиницю коли знайдено лексему оголошення змінних, скидається, коли знайдено ключове слово початку блоку. Всі лексеми, крім зарезервованих, котрі будуть знайдені вносяться в таблицю ідентифікаторів з присвоєнням відповідних атрибутів.
number_flag – використовується для виділення символьних констант. Якщо прапорець встановлений в одиницю, то використання символьних констант дозволяється (наприклад після оператора присвоєння), якщо прапорець в нулі, то в цьому місці символьні константи використовувати не можна (наприклад після лексем відкриття і закриття блоку).
bool_flag – використовується для надання атрибутів ідентифікаторам при їх описі. При знаходженні відповідної лексеми прапорець встановлюється в одиницю, а прапорець цілих змінних скидається в нуль. Поки прапорець встановлений, змінним присвоюється атрибут «b». Скидається при знаходженні лексеми оголошення цілих змінних чи початку блоку програми.
int_flag – використовується для надання атрибутів ідентифікаторам при їх описі. При знаходженні відповідної лексеми прапорець встановлюється в одиницю, а прапорець булевих змінних скидається в нуль. Поки прапорець встановлений, змінним присвоюється атрибут «і». Скидається при знаходженні лексеми оголошення булевих змінних чи початку блоку програми.
io_flag – використовується для виділення рядкових констант для виводу. Алгоритм аналогічний як для коментарів, але з занесенням лексеми до таблиці лексем.
blok_flag – використовується для підрахунку відкритих і закритих блоків.
3.6 Розробка синтаксичного та семантичного аналізатораСинтаксичний розбір (розпізнавання) є першим етапом синтаксичного аналізу. Саме при його виконанні здійснюється підтвердження того, що вхідний ланцюжок символів є програмою, а окремі підланцюжки складають синтаксично правильні програмні об'єкти. Вслід за розпізнаванням окремих підланцюжків здійснюється аналіз їх семантичної коректності на основі накопиченої інформації. Потім проводиться додавання нових об'єктів в об'єктну модель програми або в проміжне представлення.
Розбір призначений для доказу того, що аналізований вхідний ланцюжок, записаний на вхідній стрічці, належить або не належить безлічі ланцюжків породжуваних граматикою даної мови. Виконання синтаксичного розбору здійснюється розпізнавачами, тому даний процес також називається розпізнаванням вхідного ланцюжка. Мета доказу в тому, щоб відповісти на питання: чи належить аналізований ланцюжок безлічі правильних ланцюжків заданої мови. Відповідь «так» дається, якщо така приналежність встановлена. Інакше дається відповідь «ні». Отримання відповіді «ні» пов'язано з поняттям відмови. Єдина відмова на будь-якому рівні веде до загальної відмови.
Щоб одержати відповідь «так» щодо всього ланцюжка, треба його одержати для кожного правила, що забезпечує розбір окремого підланцюжка. Оскільки безліч правил утворюють ієрархічну структуру, можливо з рекурсіями, то процес отримання загальної позитивної відповіді можна інтерпретувати як збір за певним принципом відповідей для листків, що лежать в основі дерева розбору, що дає позитивну відповідь для вузла, що містить цей листок. Далі аналізуються оброблені вузли, і вже в них одержані відповіді складаються в загальну відповідь нового вузла. І так далі до самої вершини. Даний принцип обробки сильно нагадує бюрократичну систему, використовувану в організаційному управлінні будь-якого підприємства. Так підіймається вгору інформація, підтверджуюча виконання вказівки начальника організації. До цього, тими ж шляхами, вниз спускалася і розділялася початкова вказівка.
Основним завданням семантичного аналізатора є перевірка типів. Також семантичний аналізатор повинен знаходити вирази, що використовуються без присвоєння та видавати попередження.
Сама програма перевірки типів базується на інформації про синтаксичні конструкції мови, представлення типів і правилах присвоєння типів конструкціям мови.
3.7 Розробка дерев граматичного розборуКоренем дерева є не термінальний символ <Program>. Безпосередньо його листками є термінал Program та нетермінали <Blok>, <Declaration>, <Ident>. Листками нетерміналу <Blok> є термінали Start і Finish та нетермінали <Statement>, <Equation>, з листком <Cycle> існує двосторонній зв’язок. Нетермінал <Declaration> має термінальний листок Var та нетермінальний <Type> (листки Integer і Bool) і зв’язок з нетерміналом <Ident>. <Ident> має три листки – <Small_letter>, <Big_letter> і <Number>. <Statement> має два листки – <Input> (листок Input) і <Output> (листок Output) і зв’язок з нетерміналом <Equation>. <Equation> має зв’язок з нетерміналом <Ident>, нетермінальні листки <Compare>, <Const>, <Operation_a>, <Operation_m>, <Operation_l> і термінальний листок»:=». <Cycle> має два термінальні листки – For і DownTo і нетермінальний – <Const>. Від <Const> відходять два зв’язки, один до нетерміналу <Number>, другий до термінального символу» –». <Compare> має чотири термінальні листки – «==», "!=», «Le» і «Ge». <Operation_a> має листки «+»,» –»; <Operation_m> має листки «Mul», «Div» і «Mod». <Operation_l> має листки»!!», «And» і «||». Листками нетерміналу <Small_letter> є усі малі літери латинської абетки, <Big_letter> – великі літери латинської абетки. <Number> має десять термінальних листків – «0», «1», «2», «3», «4», «5», «6», «7», «8», «9».
Дерево граматичного розбору розроблено згідно правил, даних у формі розширеної нотації Бекуса-Наура, та оформлено згідно правил ЄСКД. Граф схема дерева граматичного розбору (1 аркуш) міститься в додатках.
3.8 Розробка граф-схеми алгоритмуДругий блок описує частину програми, де з таблиці лексем вибирається чергова лексема. Далі лексема проходить перевірку на її приналежність до одного з класів. В третьому блоці перевіряється чи належить лексема до класу лексем блоку. Якщо так, то вибираються лексеми, що стоять до і після заданої і ланцюжок перевіряється на коректність. Такий алгоритм роботи усіх ділянок програми, на які описані блоками 4, 6, 8, 10, 12, 14, 16, 18, 20, 22. У таблиці наведено усі перевірки, що ведуть до розгалуження алгоритму.
Таблиця 3.1. Блоки галуження
| Номер блоку | Перевірка, що здійснюється |
| 3 | Лексема блоку? |
| 5 | Лексема вводу / виводу? |
| 7 | Лексема присвоєння? |
| 9 | Лексема математичного, логічного, порівняльного оператора? |
| 11 | Лексема ідентифікатор? |
| 13 | Лексема циклу? |
| 15 | Лексема оголошення? |
| 17 | Лекскма аргументу виводу? |
| 19 | Синтаксична лексема? |
| 21 | Лексема рядкова константа? |
| 23 | Остання лексема? |
Після перевірки чи лексема є останньою здійснюється перехід до натупної лексеми, якщо твердження хибне, і закінчується робота синтаксичного аналізатора, якщо твердження істинне.
Граф-схема алгоритму синатксичного аналізу (2 аркуші) розроблена згідно усіх правил ЄСКД та поміщена у додатках.
3.9 Опис програми реалізації синтаксичного та семантичного аналізатораНа вхід синтаксичного аналізатора подається таблиця лексем, створена на етапі лексичного аналізу. Потім по черзі перебираємо лексеми та аналізуємо класи лексем, що слідують за ними. Якщо після чергової лексеми слідує лексема, що має некоректний клас (наприклад після лексеми класу вводу / виводу слідує лексема класу математичних операторів), то формується повідомлення про помилку. Також здійснюється перевірка чи не йдуть підряд дві лексеми однакового класу (за винятком синтаксичних та операції множення на від’ємне число), якщо це справджується то виводиться повідомлення про помилку.
При знаходженні оператора присвоєння, математичних та логічних операторів чи операторів порівняння здійснюється перевірка атрибутів усіх ідентифікаторів, що входять у даний вираз. Якщо у виразі використовуються дані різних типів, то формується повідомлення про помилку.
На цьому етапі використовуються прапорці вводу / виводу для виділення лексем, що є аргументами виводу.
При кожному знаходженні помилки лічильник помилок збільшується на одиницю.
3.10 Розробка генератора кодуОстанньою стадією розробки компілятора є генератор коду, який дістає на вхід проміжне представлення вихідної програми і виводить еквівалентну цільову програму.
Традиційно, до генератора коду висуваються жорсткі вимоги. Вихідний код повинен бути коректним і високоякісним, що означає ефективне використання ресурсів цільової машини. Крім того, ефективно повинен бути розроблений і сам генератор коду.
Математично, проблема генерації оптимального коду є нерозв’язною. На практиці ми вимушені користуватись евристичними технологіями, які дають хороший, але не обов’язково оптимальний код. Вибір евристики дуже важливий, оскільки детально розроблений алгоритм розробки генератора коду може давати код, що працю в декілька раз швидше, ніж код отриманий недостатньо продуманим алгоритмом.
Хоча дрібні деталі генератора колу залежать від цільової машини і операційної системи, такі питання, як керування пам’яттю, вибір інструкцій, розподіл регістрів і порядок обчислень, властиві усім задачам, зв’язаним з генерацією коду.
Вхідний потік генератора коду являє собою проміжне представлення вихідної програми, отримане на початковій стадії компіляції, разом із таблицею символів, яка використовується для обчислення адрес часу виконання об’єктів даних, зазначених в проміжному представленні іменами.
Результатом генератора коду являється цільова програма. Подібно до проміжного коду, результат генератора коду може приймати різні види: абсолютний машинний код, переміщуваний машинний код, або асемблерна мова. Перевагою генерації абсолютної програми в машинному коді є те, що такий код поміщається у фіксоване місце пам’яті і негайно виконується. Невеликі програми при цьому швидко компілюються і виконуються.
Генерація переміщуваної програми у машинному коді (об’єктного модуля) забезпечує можливість роздільної компіляції підпрограм. Багато переміщуваних модулів можуть бути після цього зв’язані в одне ціле і завантажені на виконання спеціальною програмою – завантажувачем. Додаткові затрати на зв’язування і завантаження компенсуються можливістю роздільної компіляції підпрограм і викликом інших, раніше скомпільованих підпрограм із об’єктних модулів. Якщо цільова машина не обробляє переміщення автоматично, компілятор має надати завантажувачеві явну інформацю про переміщення для зв’язування сегментів роздільно скомпільованиз підпрограм.
Отримання на виході генератора коду програми на мові асемблера трохи полегшує процес генерації коду; в результаті ми можемо створювати символьні інструкції і використовувати можливості макросів асемблера. Плата за цю порстоту – додатковий крок в обробці асемблерної програми після генерації коду[1].
3.11 Розробка граф-схеми алгоритмуДругий блок описує ділянку програми, де визначається код чергової лексеми. Після цього іде серія перевірок коду лексеми і вставка відповідного коду.
Таблиця 3.2. Блоки перевірок
| Номер блоку | Перевірка, що здійснюється |
| 3 | Код = 0 (початок програми)? |
| 5 | Код = 1 (початок сегменту даних)? |
| 7 | Код = 27 (опис цілих змінних)? |
| 9 | Код = 28 (опис логічних змінних)? |
| 11 | Код = 2 (початок блоку)? |
| 13 | Код =6 (опис циклу)? |
| 15 | Код = 3 (кінець блоку)? |
| 17 | Код = 13 (операція присвоєння)? |
| 19 | Код = 4 (ввід даних)? |
| 21 | Код = 5 (вивід даних)? |
| 23 | Код = 14 (перевірка на рівність)? |
| 25 | Код =15 (перевірка на нерівність)? |
| 27 | Код = 16 (перевірка чи менше-рівне)? |
| 29 | Код = 17 (перевірка чи більше-рівне)? |
| 31 | Остання лексема? |
Після кожного такого блоку перевірки іде блок вставки відповідного коду (блоки 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30). Якщо перевірка справдилась, то вставляється код, якщо ні, то здійснюється наступна перевірка. Алгоритм закінчується, коли перебрано усі лексеми.
Граф-схема алгоритму генератора коду (2 аркуші) розроблена згідно усіх правил ЄСКД та поміщена у додатках.
3.12 Опис програми реалізації генератора кодуГенератор коду починає свою роботу, якщо після фаз лексичного, синтаксичного та семантичного аналізу лічильник помилок дорівнює нулю. Програма починає по черзі перебирати лексеми із таблиці лексем. У відповідності до коду знайденої лексеми у проміжне представлення програми буде вставлено відповідний еквівалентний асемблерний текст. Наприклад, при зустрічі ключового слова Program, в асемблерний файл вставляється текст з описом моделі та сегментів, а при зустрічі ключового слова Var, вставляється опис сегменту даних.
Реакція на лексеми розроблена так, що пустий код не буде включений в асемблерний файл. Для того щоб уникнути помилок, імена ідентифікаторів, дані у вхідній програмі користувачем, вносяться у асемблерний файл із змінами. Наприклад, невідомо, як буде працювати згенерований код, якщо у ньому будуть зустрічатись створені користувачем змінні end, loop.
Для внесення змін у асемблерний файл використовуються функції fputs та fputc із бібліотеки stdio.h. Для створення об’єктного модуля та виконавчого файлу за допомогою виклику system із бібліотеки stdlib.h запускаються на виконання tasm.exe та tlink.exe із відповідними параметрами.
4. Опис інтерфейсу та інструкції користувача
Середовище М9 запускається за допомогою файлу М9.exe. Для того, щоб написати програму, слід натиснути кнопку Make program. Тепер у вікні текстового редактора слід ввести текст програми і зберегти. Програма компілюється натисканням кнопки Compile. Аби запустити утворений виконавчий файл слід натиснути кнопку Run.
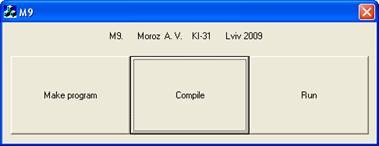
Рис. 4.1. Оболонка М9
5. Відлагодження та тестування програми 5.1 Виявлення лексичних помилок
Повідомлення про лексичну помилку виводиться, коли лексичний аналізатор знаходить лексему, що не відповідає лексиці мови програмування та ні одному з імен описаних користувачем змінних. Для перевірки розробленого компілятора на виявлення лексичних помилок внесемо в текст програми помилку – лексему Error. Результат тестування в додатку В1.
5.2 Виявлення синтаксичних помилок
Повідомлення про синтаксичну помилку виводиться, коли синтаксичний аналізатор знаходить ланцюжок лексем, що не відповідає граматиці заданої мови. Для перевірки компілятора на виявлення синтаксичних помилок внесемо в текст програми зайву операцію додавання. Результат тестування в додатку В2.
5.3 Виявлення семантичних помилокПовідомлення про семантичну помилку виводиться семантичним аналізатором, коли у виразі не співпадають типи використовуваних змінних. Для перевірки компілятора на виявлення семантичних помилок внесемо в текст програми вираз з використанням змінних різних типів. Результат тестування в додатку В3.
5.4 Загальна перевірка коректності роботи транслятораЗагальна перевірка полягає у здатності розробленого компілятора виконувати свої функції. Компілятор повинен транслювати програму у проміжне представлення на асемблерній мові та створити об’єктний і виконуваний файли за допомогою файлів tasm.exe та tlink.exe. Для перевірки вводимо коректний текст програми та виконуємо усі дії зазначені у розділі 4. Результат тестування в додатку В4.
Висновки
Підчас виконання курсової роботи:
1. Складено формальний опис мови програмування М9 у формі розширеної нотації Бекуса-Наура, дано опис усіх символів та ключових слів.
2. Створено компілятор мови програмування М9, а саме:
2.1.1. Розроблено лексичний аналізатор, здатний розпізнавати лексеми, що є описані в формальному описі мови програмування, та додані під час безпосереднього використання компілятора.
2.1.2. Розроблено синтаксичний аналізатор на основі автомата з магазинною пам’яттю. Складено таблицю переходів для даного автомата згідно правил записаних в нотації у формі Бекуса-Наура.
2.1.3. Розроблено генератор коду, який починає свою роботу після того, як лексичним, синтаксичним та семантичним аналізатором не було виявлено помилок у програмі, написаній мовою М9. Проміжним кодом генератора є програма на мові Assembler(i8086). Вихідним кодом є машинний код, що міститься у виконуваному файлі
3. Проведене тестування компілятора за допомогою тестових програм за наступними пунктами:
3.1.1. Виявлення лексичних помилок.
3.1.2. Виявлення синтаксичних помилок.
3.1.3. Загальна перевірка роботи компілятора.
Тестування не виявило помилок в роботі компілятора, а всі помилки в тестових програмах мовою М9 були виявлені і дано попередження про їх наявність.
В результаті виконання даної курсової роботи було успішно засвоєно методи розробки та реалізації компонент системного програмного забезпечення.
Список використаної літератури
1. Ахо и др. Компиляторы: принципы, технологии и инструменты.: Пер с англ. – М.: Издательський дом «Вильямс». 2003. – 768 с.: ил. Парал. тит. англ.
2. Шильдт Г. С++. – Санкт-Петербург: BXV, 2002. – 688 с.
3. Компаниец Р.И., Маньков Е.В., Филатов Н.Е. Системное программирование. Основы построения трансляторов. – СПб.: КОРОНА принт, 2004. – 256 с.
4. Б. Керниган, Д. Ритчи «Язык программирования Си». – Москва «Финансы и статистика», 1992. – 271 с.
5. Л. Дао. Программирование микропроцессора 8088. Пер.с англ.‑М. «Мир», 1988.
6. Ваймгартен Ф. Трансляция языков программирования. – М.: Мир, 1977.
[1] В даний час наявність мови структурованих запитів SQL знімає питання про те, чи є інтерпретація запитів задачею, всього лише схожою з компіляцією.
Похожие работы
... , що вхідна мова і системне забезпечення такого пакету можуть бути достатньо легко реалізовані силами прикладного програміста. Тому у разі, коли подібний пакет задовольняє конкретних користувачів, його розробка є цілком виправданою. 3. ВИСНОВОК Сучасний український ринок прикладного програмного забезпечення є, значною мірою, ринком піратського ПО. Це пов'язано з тим, що український спожива
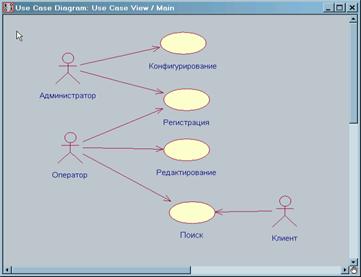
... адміністратор локальної мережі, який є у штатному розкладі і займається усіма проблемами, зв’язаними з комп’ютерами. Рисунок 1.2 – Функціональна схема автоматизованого робочого місця науково-технічної бібліотеки Метою розробки АРМ є - скорочення часу обробки оперативних даних, зменшення кількості помилок при обробці інформації. Основні функціональні вимоги до розроблюваного автоматизованого ...
... оформления : ДСТУ 3008–95. – Киев: Госстандарт Украины, 1995. – 38 с. – (Государственный стандарт Украины). Додаток До пояснювальної записки дипломного проекту "Розробка автоматизованого робочого місця управління замовленнями у малому бізнесі (ПП "Сігма")" Вихідний код програми Public Class frmГлавная Inherits System.Windows.Forms.Form Private Готов As Boolean = False Private ...




... . Механізм переривань забезпечує ефективна взаємодія пристроїв уведення-висновку з мікропроцесором. Переривання цікавлять нас тому, що обробка переривань - це прерогатива програмування на мові асемблера. У високорівневих мовах відсутні засоби роботи з перериваннями на машинному рівні. Переривання звичайно викликаються зовнішніми пристроями. Переривання сигналізує мікропроцесору, щоб він призупинив ...
0 комментариев