Планування і диспетчеризація процесів і задач в ОС
Способи виділення пам’яті під новий розділ. Їх переваги і недоліки
Дисципліни заміщення сегментів. Організація, переваги і недоліки
Транслятори, компілятори й інтерпретатори — загальна схема роботи
Призначення й особливості побудови таблиць ідентифікаторів
Призначення й особливості побудови таблиць ідентифікаторів. Комбіновані способи побудови таблиць ідентифікаторів
Способи внутрішнього представлення програм
Навигация
Транслятори, компілятори й інтерпретатори — загальна схема роботи
Системне програмне забезпечення
61090
знаков
3
таблицы
11
изображений
6. Транслятори, компілятори й інтерпретатори — загальна схема роботи
Визначення транслятора, компілятора, інтерпретатора
Транслятор – це програма, що переводить вхідну програму на вихідній (вхідній) мові в еквівалентну їй вихідну програму на результуючій (вихідній) мові.
Компілятор — це транслятор, що здійснює переклад вихідної програми в еквівалентну їй об'єктну програму мовою машинних команд або мовою ассемблера.
Таким чином, компілятор відрізняється від транслятора лише тим, що його результуюча програма завжди повинна бути написана мовою машинних кодів чи мовою ассемблера. Результуюча програма транслятора, у загальному випадку, може бути написана на будь-якій мові. Відповідно, усякий компілятор є транслятором, але не навпаки — не всякий транслятор буде компілятором.
Необхідність компіляторів з’явилася одночасно з появою мов програмування високого рівня.
Інтерпретатор — це програма, що сприймає вхідну програму вихідною мовою і виконує її.
Інтерпретатор, так само як і транслятор, аналізує текст вихідної програми. Однак він не породжує результуючої програми, а відразу ж виконує вихідну відповідно до її змісту, заданим семантикою вхідної мови.
Етапи трансляції. Загальна схема роботи транслятора


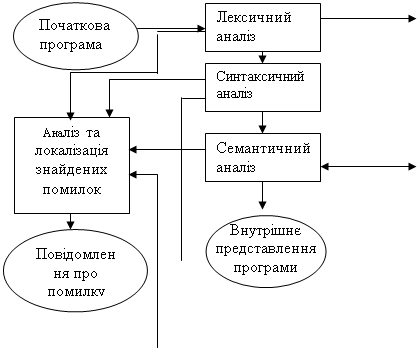 | |||

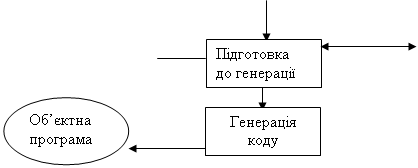
Рис. 1. Загальна схема роботи компілятора
На мал.1 представлена загальна схема роботи компілятора. З неї видно, що в цілому процес компіляції складається з двох основних етапів — синтезу й аналізу.
На етапі аналізу виконується розпізнавання тексту вихідної програми, створення і заповнення таблиць ідентифікаторів. Результатом його роботи служить деяке внутрішнє представлення програми, зрозуміле компілятору.
На етапі синтезу на підставі внутрішнього представлення програми й інформації, що міститься в таблиці (таблицях) ідентифікаторів, породжується текст результуючої програми. Результатом цього етапу є об'єктний код.
7. Призначення й особливості побудови таблиць ідентифікаторів
Призначення й особливості побудови таблиць ідентифікаторів
Компілятор повинний мати можливість зберігати всі знайдені ідентифікатори і зв'язані з ними характеристики на протязі всього процесу компіляції, щоб мати можливість використовувати їх на різних фазах компіляції.
Для цієї мети у компіляторах використовуються спеціальні сховища даних, називані таблицями символів або таблицями ідентифікаторів.
Будь-яка таблиця ідентифікаторів складається з набору полів, кількість яких дорівнює числу різних ідентифікаторів, знайдених у вхідній програмі. Кожне поле містить у собі повну інформацію про даний елемент таблиці. Компілятор може працювати з однією або декількома таблицям ідентифікаторів — їхня кількість залежить від реалізації компілятора.
У таблицях ідентифікаторів може зберігатися наступна інформація:
для змінних:
ім'я змінної;
тип даних змінною;
область пам'яті, зв'язана із змінною;
для констант:
назва константи (якщо воно є);
значення константи;
тип даних константи (якщо потрібно);
для функцій:
ім'я функції;
кількість і типи формальних аргументів функції;
тип результату, що повертається;
адреса коду функції.
Як правило, кожен елемент у вхідній програмі однозначно ідентифікується своїм іменем. Тому компілятору часто доводиться виконувати пошук необхідного елемента в таблиці ідентифікаторів по його імені, у той час як процес заповнення таблиці виконуються нечасто – нові ідентифікатори описуються в програмі набагато рідше, ніж використовуються. Звідси можна зробити висновок, що таблиці ідентифікаторів повинні бути організовані таким чином, щоб компілятор мав можливість максимально швидкого пошуку потрібного йому елемента.
Найпростіші методи побудови таблиць ідентифікаторів
Найпростіший спосіб організації таблиці полягає в тому, щоб додавати елементи в порядку їх надходження. Тоді таблиця ідентифікаторів буде представляти невпорядкований масив інформації, кожна комірка якого буде містити дані про відповідний елементі таблиці.
Пошук потрібного елемента в таблиці буде в цьому випадку полягати в послідовному порівнянні шуканого елемента з кожним елементом таблиці, поки не буде знайдений придатний. Тоді, якщо за одиницю прийняти час, затрачуваний компілятором на порівняння двох елементів (як правило, це порівняння рядків), то для таблиці, що містить N елементів, у середньому буде виконане N/2 порівнянь.
Заповнення такої таблиці буде відбуватися елементарно просто — додаванням нового елемента в її кінець, і час, необхідний на додавання елемента (Тз), не буде залежати від числа елементів у таблиці N. Але якщо N дуже велике, то пошук зажадає значних витрат часу. Такий спосіб організації таблиць ідентифікаторів є неефективним.
Пошук може бути виконаний більш ефективно, якщо елементи таблиці впорядковані (відсортовані) в прямому чи зворотному алфавітному порядку. Ефективним методом пошуку в упорядкованому списку з N елементів є бінарний або логарифмічний пошук. Символ, який варто знайти, порівнюється з елементом (N+l)/2 всередині таблиці. Якщо цей елемент не є шуканим, то ми повинні переглянути тільки блок елементів, пронумерованих від 1 до (N+l)/2-l, чи блок елементів від (N+l)/2+1 до N у залежності від того, менше чи більше шуканий елемент від того, з яким його порівняли. Потім процес повторюється над потрібним блоком у два рази меншого розміру. Так продовжується доти, поки або елемент не буде знайдений, або алгоритм не дійде до чергового блоку, що містить один чи два елементи (з якими уже можна виконати пряме порівняння шуканого елемента).
Тому що на кожнім кроці число елементів, що можуть містити шуканий елемент, скорочується наполовину, то максимальне число порівнянь дорівнює l+log2(N).
Недоліком методу є вимога впорядкування таблиці ідентифікаторів.
Таким чином, при організації логарифмічного пошуку в таблиці ідентифікаторів ми отримуємо істотне скорочення часу пошуку потрібного елемента за рахунок збільшення часу на розміщення нового елемента в таблицю. Оскільки додавання нових елементів у таблицю ідентифікаторів відбувається істотно рідше , ніж звертання до них, то цей метод варто визнати більш ефективним, чим метод організації невпорядкованої таблиці.
Похожие работы
... , що вхідна мова і системне забезпечення такого пакету можуть бути достатньо легко реалізовані силами прикладного програміста. Тому у разі, коли подібний пакет задовольняє конкретних користувачів, його розробка є цілком виправданою. 3. ВИСНОВОК Сучасний український ринок прикладного програмного забезпечення є, значною мірою, ринком піратського ПО. Це пов'язано з тим, що український спожива


... і MS Excel загальні відомості про електронні таблиці, призначення і можливості, вікно електронної таблиці, вікна книг Термін «електронна таблиця» вживається для позначення простої у використанні комп'ютерної програми Excel, що призначена для обробки інформаційних даних за допомогою таких операцій, як: ■ проведення різних обчислень із використанням потужного апарату функцій і формул; &# ...
... процедур, правил і документації, необхідних для використання програмних продуктів. Усі програми, з якими працюють на сучасних комп’ютерах, можна розділити на 3 категорії: Програмне забезпечення Системні програми Інструментальні системи Прикладні програми · СИСТЕМНІ ПРОГРАМИ- ті, що використовуються для забезпечення працездатності комп’ютера, експлуатації інших програмних продукт ...
... також усі індійські цифри (0–9), латинські букви (a-z, A-Z), символи табуляції, символ переходу на нову стрічку, пробіл та синтаксичні знаки (!,?,,/, %,$,@,^,_). 3. Розробка транслятора вхідної мови програмування 3.1 Вибір технології програмування Необхідно вибрати ефективні методи розв’язку загальних задач, таких як розпізнавання лексем, синтаксичний розбір, семантичний аналіз та ...
0 комментариев