Навигация
Понятие базы данных и СУБД
53512
знаков
2
таблицы
1
изображение
1 Понятие базы данных и СУБД
1.1 Предметная область
Основным назначением информационных систем является хранение сведений об окружающем мире и процессах происходящих в нем, которые в конечном итоге предоставляются пользователям. Поскольку для различных групп людей интерес представляют только определенные части реального мира, то и данные каждой информационной системы будут относится к определенной области. Часть реальной системы, подлежащая исследованию с целью ее описания называется предметной областью.
Различают полную предметную область и ее фрагменты, при этом каждый фрагмент может представлять свою предметную область. Например, для университета можно выделить следующие фрагменты: учебный отдел, бухгалтерия, отдел кадров, бюро расписаний и т. д.
Информация, необходимая для описания предметной области, может включать сведения о людях, предметах, документах, событиях, понятиях и т.д.
Каждая предметная область характеризуется множеством объектов – элементов реальных систем и процессов, использующих объекты, а также множеством пользователей, характеризуемых единым взглядом на предметную область. В частности, для бухгалтерии объекты – всевозможные документы. Процессы бухгалтерии – расчет заработной платы, материальный учет, учет банковских операций и др. Наконец пользователи этого фрагмента сотрудники бухгалтерии, работники финансовых органов, руководители предприятия и т. д.
Каждый объект обладает определенным набором свойств, которые запоминаются в информационной системе. При обработке данных часто приходится иметь дело с совокупностью однородных объектов , например, таких, как студенты или факультеты, и записывать информацию об одних и тех же свойствах для каждого из них. Совокупность объектов, обладающих одинаковым набором свойств, называется классом объектов. Для объектов одного класса набор свойств будет одинаков, хотя значения этих свойств для каждого объекта могут быть разными.
Часто класс объектов называют сущностью. Каждая сущность обладает атрибутами. Атрибут – это свойство объекта, характеризующее его экземпляр. Сущность "студент" может иметь атрибуты "имя" , "год рождения", " дата поступления" и т. д. Таким образом сущность можно определить, как множество индивидуальных объектов одного типа (экземпляров), причем все эти объекты различны, т. е. набор атрибутов одинаков, а их значения различны.
1.2 Концепция баз данных 1.2.1 Независимость приложений от организации данных во внешней памятиОсновой любой информационной системы являются хранимые в ней данные. В общем случае данные – это информация, подготовленная для определенных целей, при этом часто подразумевается определенный формат представления.
Во все времена люди фиксировали данные на том или ином материальном носителе (бумага, камень и т. д.) Обычно данные фиксируются совместно с их интерпретацией (семантикой), так как системы письменности естественных языков позволяет это делать достаточно гибко. Например, запись на бумаге "Заработная плата – 1000" содержит данное – "1000" и его семантику (смысл) – "Заработная плата".
Довольно часто данные и их интерпретация бывают разделены. Они могут быть отражены в различных частях носителя (например, таблицы, в которых смысл записывается в верхних строках, а сами данные в последующих) и более того могут находиться на разных носителях. Такое разделение существенно затрудняет работу с данными.
Применение ЭВМ для обработки и хранения данных привело к еще большему разделению данных и интерпретирующей информации. Так как на ранних этапах развития вычислительной техники ее возможности были весьма ограничены, память использовалась только для хранения самих данных. Описание же данных (порядок, тип данных, длина) находились в программах, которые таким образом "знали", например, что с начиная определенного байта адресного пространства внешней памяти четыре байта содержат данное в числовом формате, связанное с заработной платой, а последующие 30 байтов в текстовом формате – содержат фамилию сотрудника.
Такая зависимость между данными и программой, существенно ограничивает возможности и эффективность информационных систем.
В первую очередь это проявляется, когда возникает необходимость в модификации информационной системы. Представьте себе ситуацию, когда к некоторому файлу обращаются несколько программ. В определенный момент времени в предметной области произошли изменения, которые в свою очередь потребовали изменения структуры записей файла, например добавление новых полей в запись файла или изменение длины некоторых полей. В этом случае придется переделывать все программы, даже если некоторым из них, для выполнения своих функций новые или измененные поля не требуются.
По этой причине часто для отдельных приложений создавались свои наборы данных, не смотря на то, что характер информации хранившейся в них был частично или полностью одинаковым. Такое многократное дублирование приводило или к несоответствию данных состоянию предметной области или к противоречию одних данных другим.
Современный подход требует, чтобы описание данных было независимым от программ пользователей, а некоторая система управления данными, которая используя эти описания, размещает их во внешней памяти и впоследствии "знает" где и как они хранятся, обеспечивала бы автоматический интерфейс между данными и приложениями. В этом случае становится возможным, в программах задавать только имена необходимых для обработки данных и форматы их представления, в связи с чем изменения в организации данных существенно не отражаются на прикладном программном обеспечении.
Описания данных часто хранятся вместе с самими данными и называются метаданными. В ряде современных систем метаданные, содержащие так же информацию о пользователях, права доступа, статистику обращения к данным и другие сведения, хранятся в словаре данных.
Такой подход позволяет манипулировать данными достаточно гибко и не требует значительных усилий при расширении и модификации информационных систем.
1.2.2 Эффективность организации данныхПредположим, что мы хотим реализовать информационную систему, поддерживающую учет студентов университета. Система должна выполнять следующие действия: выдавать списки студентов по факультетам и группам, поддерживать возможность перевода студента из одной группы в другую, приема новых студентов и исключения учащихся. Для каждого факультета должна поддерживаться возможность получения имени декана этого факультета, а для группы имя куратора, общей численности факультета, и т.д.
Допустим, мы решили создавать эту информационную систему используя некоторую файловую систему, в которой пользователи представляют файл как последовательность записей. Каждая запись – это последовательность байтов постоянного или переменного размера. Записи можно читать или записывать последовательно, позиционировать файл на запись с указанным номером, структурировать на поля и объявлять некоторые поля ключами записи. Кроме того, имеется возможность выборки записи из файла по ее заданному ключу. Естественно, что в этом случае файловая система поддерживает в том же (или другом, служебном) базовом файле дополнительные, невидимые пользователю, служебные структуры данных. Распространенные способы организации ключевых файлов основываются на технике хеширования и B-деревьев.
Для хранения данных будем использовать один файл СТУДЕНТЫ. Поскольку объектом предметной области в нашем случае является студент, определяем, чтобы в этом файле содержалась одна запись для каждого студента. Исходя из требований к информационной системе, обозначим набор свойств, описывающий объект и отразим его следующими полями в файле:
ФИО_СТУДЕНТА,
АДРЕС,
ДАТА_РОЖДЕНИЯ,
НАИМНОВАНИЕ_ФАКУЛЬТЕА,
ФИО_ДЕКАНА,
НОМЕР_ГРУППЫ,
ФИО_КУРАТОРА.
Функции нашей информационной системы требуют, чтобы обеспечивалась возможность многоключевого доступа к записям этого файла по значениям уникального ключа ФИО_СТУДЕНТА. Кроме того, должна обеспечиваться возможность выбора всех записей с общим значением НАИМЕНОВАНИЕ_ФАКУЛЬТЕТА и НОМЕР_ГРУППЫ т. е. доступ по неуникальному ключу.
Не трудно заметить, что такая организация данных вызывает существенную избыточность хранения данных (для каждого студента одной группы повторяется имя куратора, а для студентов одного факультета наименование факультета и имя декана). Кроме того, если в ходе эксплуатации системы на каком-либо факультете поменяется декан, придется вносить изменения в нескольких сотнях записей, а для того чтобы получить численность факультета, каждый раз при выполнении такой функции надо будет выбрать все записи с заданным значением наименования факультета и посчитать их количество.
Анализ предметной области показывает, что можно выделить еще два класса объектов ФАКУЛЬТЕТЫ и ГРУППЫ с присущими только им свойствами (для факультетов – деканы, а для групп – кураторы). Естественно предположить, что информация о каждом объекте должна находиться в отдельном файле. Поэтому наша систем будет состоять из трех файлов СТУДЕНТЫ, ФАКУЛЬТЕТЫ, ГРУППЫ, со следующей организацией записей:
СТУДЕНТЫ :
СТУД_ФИО_СТУДЕНТА,
СТУД_АДРЕС,
СТУД_ДАТА_РОЖДЕНИЯ,
СТУД_НОМЕР_ГРУППЫ.
ГРУППЫ :
ГРУП_НОМЕР_ГРУППЫ,
ГРУП_ФИО_КУРАТОРА,
ГРУП_ИДЕНТИФИКАТОР_ФАКУЛЬТЕА,
ГРУП_КОЛИЧЕСТВО_СТУДЕНТОВ.
ФАКУЛЬТЕТЫ :
ФАК_ИДЕНТИФИКАТОР_ФАКУЛЬТЕА,
ФАК_НАИМНОВАНИЕ_ФАКУЛЬТЕА,
ФАК_ФИО_ДЕКАНА,
ФАК_КОЛИЧЕСТВО_СТУДЕНТОВ;
Поле СТУД_НОМЕР_ГРУППЫ добавлено в файл СТУДЕНТЫ, а ГРУП_ИДЕНТИФИКАТОР_ФАКУЛЬТЕТА в файл ГРУППЫ для установки связей между файлами. Так например, по значению поля ГРУП_ИДЕНТИФИКАТОР_ФАКУЛЬТЕТА в файле ГРУППЫ можно определить к какому факультету относится та или иная группа. Иначе говоря, один файл ссылается на другой, поля же, использующееся для ссылок называются ключами.
Такой механизм установки информационных связей между файлами называется механизмом дублирования ключей. Таким образом, каждый из файлов будет содержать только не дублированную информацию, необходимости в динамических вычислениях суммарной информации не возникает.
Однако теперь система должна теперь "знать", что она работает с тремя информационно связанными файлами, должна знать структуру и смысл каждого поля (например, что ГРУП_ ДЕНТИФИКАТОР_ ФАКУЛЬТЕТА и ФАК_ ИДЕНТИФИКАТОР_ФАКУЛЬТЕТА означают одно и то же), а также понимать, что в ряде случаев изменение информации в одном файле должно автоматически вызывать модификацию в других, чтобы их общее содержимое было согласованным.
Например, если на факультет принимается новый студент, то необходимо добавить запись в файл СТУДЕНТ, а также соответствующим образом изменить поля ФАК_КОЛИЧЕСТВО_СТУДЕНТОВ и ГРУП_КОЛИЧЕСТВО_СТУДЕНТОВ в файлах ФАКУЛЬТЕТЫ и ГРУППЫ. Иначе говоря данные во всех файлах должны быть согласованными.
Понятие согласованности данных является ключевым понятием баз данных. Фактически, если информационная система (даже такая простая, как в нашем примере) поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных.
Понятно, что даже для такой простой системы ее реализация традиционными методами программирования, требует от разработчиков создания достаточно сложных процедур, которые связывают отдельные файлы в единое целое.
Для поддержания согласованности данных в нескольких файлах недостаточно библиотеки процедур, необходимо, чтобы такая система имела некоторые собственные данные (метаданные) и даже знания, определяющие целостность данных.
Если некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных.
1.2.3 Интеграция данныхВ информационных системах реализованных на множестве локальных приложений, каждое из которых использует свой набор данных, имеет место избыточность (дублирование) данных. Вследствие этого синхронное поддержание данных для всех приложений становится весьма проблематичным, что в может привести к неправильному отражению состояния предметной области и вызвать весьма неприятные последствия.
Рассмотрим следующий пример для двух приложений "Учет кадров" и "Расчет заработной платы" для которых необходимы следующие сведения:
| Учет кадров | Расчет заработной платы |
| Табельный номер | Табельный номер |
| Ф. И. О. Сотрудника | Ф. И. О. Сотрудника |
| Отдел | Отдел |
| Должность | Должностной оклад |
| Стаж работы | Стаж работы |
| Год рождения |
По правилам предметной области первоначально информация о переводе сотрудника на новую должность или в другой отдел, а так же об увольнении поступает в отдел кадров. Если же по каким-либо причинам об этом не будет своевременно известно в бухгалтерии, то в лучшем случае фамилия этого сотрудника окажется не в той ведомости или же возникнет совсем курьезное положение, когда уволенному сотруднику будет начислена заработная плата.
Поэтому существует необходимость в создании системы с единым хранилищем данных, в которой все данные накапливаются и хранятся централизованно, а информация внесенная одним пользователем становится доступной для других. В памяти ЭВМ должна быть создана динамически обновляемая модель предметной области это значит, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. Благодаря интеграции устраняется дублирование данных, повышается уровень их достоверности, упрощаются и становятся эффективнее процедуры обновления данных. Интеграция данных порождает ряд проблем, которые мы рассмотрим ниже.
1.2.4 Что такое база данныхВ общем случае понятие базы данных можно определить как совокупность файлов или файл, состоящий из некоторого числа записей, каждая из которых формируется из полей определенного типа, вместе с набором операций поиска, сортировки, рекомбинации и др.
Однако традиционных возможностей файловых систем оказывается недостаточно для построения даже простых информационных систем. Существует несколько потребностей, которые не покрываются возможностями систем управления файлами:
поддержание логически согласованного набора файлов;
обеспечение языка манипулирования данными;
восстановление информации после разного рода сбоев;
параллельная работа в режиме реального времени нескольких пользователей.
Можно считать, что если прикладная информационная система опирается на некоторую систему управления данными, обладающую этими свойствами, то эта система управления данными является системой управления базами данных. Таким образом, база данных – это совокупность взаимосвязанных данных, используемых несколькими приложениями под управлением СУБД. Система управления базой данных – система программного обеспечения, имеющая средства обработки на языке базы данных, позволяющие обрабатывать обращения к базе данных, которые поступают от прикладных программ и (или) конечных пользователей, и поддерживать целостность базы данных.
Похожие работы
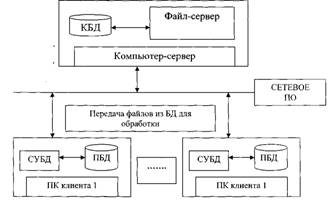
... между ними, заключается в способе формирования запросов: язык QBE предполагает ручное или визуальное формирование запроса, в то время как использование SQL означает программирование запроса. 2. РАЗРАБОТКА ПРИЛОЖЕНИЙ АРХИТЕКТУРЫ КЛИЕНТ-СЕРВЕР ПРИ ПОМОЩИ SQL SQL - это язык манипулирования данными, который работает в одно- или многопользовательской системе. Особенно хорошо SQL работает в ...

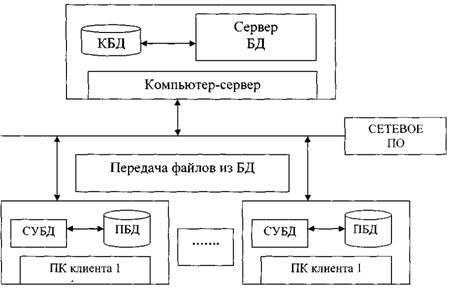
... . Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений. 3.4 Выбор типа базы данных База данных организованна в формате баз данных на платформе SQL Server. Важнейшие характеристики данной СУБД - это: простота администрирования, возможность подключения к Web, быстродействие и функциональные возможности механизма ...
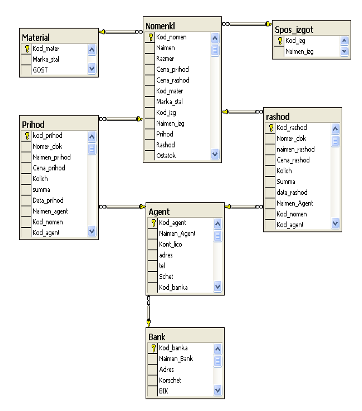
... , а иногда и невозможным. Недостатки MOLAP-модели: · Многомерные СУБД не позволяют работать с большими базами данных. · Многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память. В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения ...
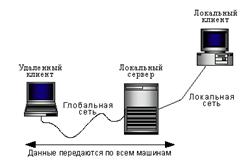
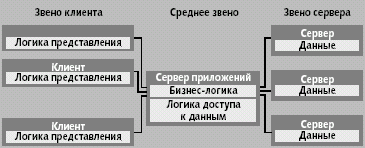
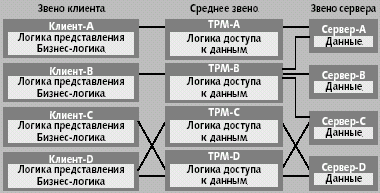
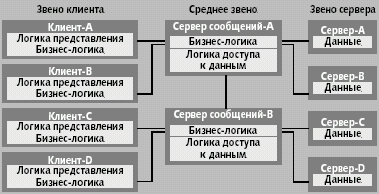
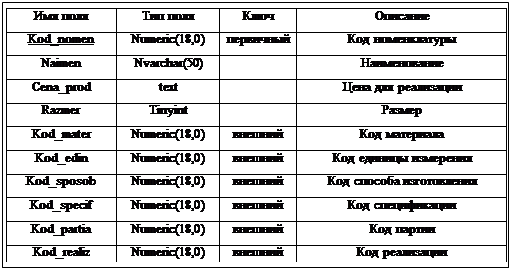
... на будущее. DAO и RDO известны уже достаточно давно, и появление двух разных механизмов было связано с необходимостью оптимизации решения двух отдельных задач: доступа к локальным и удаленным базам данных соответственно. Однако естественное развитие вычислительных систем привело к необходимости создания единого механизма, который обеспечил бы единый подход при работе с БД различных классов. В ...
0 комментариев