Навигация
Разработка алгоритма управления оперативной памятью
48910
знаков
4
таблицы
3
изображения
2. Разработка алгоритма управления оперативной памятью
Ниже приведён алгоритм управления оперативной памятью в системе Linux. В основе всего лежат страницы памяти. В ядре они описываются структурой mem_map_t.
typedef struct page {
/* these must be first (free area handling) */
struct page *next;
struct page *prev;
struct inode *inode;
unsigned long offset;
struct page *next_hash;
atomic_t count;
unsigned long flags; /* atomic flags, some possibly updated asynchronously */
struct wait_queue *wait;
struct page **pprev_hash;
struct buffer_head * buffers;
} mem_map_t;
В системе применяется множество ссылок, которые в свою очередь используются для управления ОП. Одна страница может находиться в разных списках, например и в списке страниц в страничном кеше и в списке страниц относящихся к отображенному в память файлу (inode).В структуре, описывающей последний, можно найти и обратную ссылку, что очень удобно.
Все страницы адресуются глобальным указателем mem_map
mem_map_t * mem_map
Адресация происходит наиболее интерестно. Если раньше (в ранних версиях ядра) в структуре page было отдельное поле указывающее на физический адрес (map_nr), то теперь он вычисляется. Алгоритм вычисления можно обнаружить в следующей функции ядра.
static inline unsigned long page_address(struct page * page)
{
return PAGE_OFFSET + PAGE_SIZE * (page - mem_map);
}
Свободные страницы хранятся в особой структуре free_area
static struct free_area_struct free_area[NR_MEM_TYPES][NR_MEM_LISTS];
где первое поле отвечает за тип области: Ядра, Пользователя, DMA и т.д. И обрабатываются по очень интересному алгоритму.
Страницы делятся на свободные непрерывные области размера 2 в степени x умноженной на размер страницы ((2^x)*PAGE_SIZE). Области одного размера лежат в одной области массива.
Таблица 1.
| Свободные Страницы размера PAGE_SIZE*4 ---> | список свободных областей |
| Свободные Страницы размера PAGE_SIZE*2 ---> | список свободных областей |
| Свободные Страницы размера PAGE_SIZE ---> | список свободных областей |
Выделение стараницы выполняется функцией get_free_pages(order). Она выделяет страницы составляющие область размера PAGE_SIZE*(2^order). Делается это следующим образом: ищется область соответствующего размера или больше. Если есть только область большего размера, то она делится на несколько маленьких и берется нужный кусок. Если свободных страниц недостаточно, то некоторые будут сброшены в область подкачки и процесс выделения начнется снова. Возвращает страницу функция free_pages(struct page, order). Высвобождает страницы, начинающиеся с page размера PAGE_SIZE*(2^order). Область возвращается в массив свободных областей в соответствующую позицию и после этого происходит попытка объединить несколько областей для создания одной большего размера.
Отсутствие страницы в памяти обрабатываются ядром особо. Страница может или вообще отсутствовать или находиться в области подкачки.
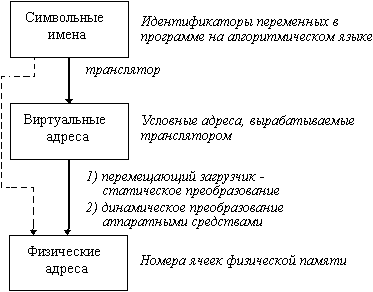
Весь процесс работает с виртуальными адресами, а не с физическими. Преобразование происходит посредством вычислений, используя таблицы дескрипторов, и каталоги таблиц. Linux поддерживает 3 уровня таблиц: каталог таблиц первого уровня (PGD - Page Table Directory),каталог таблиц второго уровня (PMD - Medium Page Table Diractory), и, таблица дескрипторов (PTE - Page Table Entry). Конкретным процессором могут поддерживаться не все уровни, но запас позволяет поддерживать больше возможных архитектур (Intel имеет 2 уровня таблиц, а Alpha - целых 3). Преобразование виртуального адреса в физический происходит соответственно в 3 этапа. Берется указатель PGD, имеющийся в структуре описывающий каждый процесс, преобразуется в указатель записи PMD, а последний преобразуется в указатель в таблице дескрипторов PTE. И, наконец, к реальному адресу, указывающему на начало страницы прибавляют смещение от ее начала. Хороший пример подобной процедуры можно посмотреть в функции ядра partial_clear:
page_dir = pgd_offset(vma->vm_mm, address);
if (pgd_none(*page_dir))
return;
if (pgd_bad(*page_dir)) {
printk("bad page table directory entry %p:[%lx]\n", page_dir, pgd_val(*page_dir));
pgd_clear(page_dir);
return;
}
page_middle = pmd_offset(page_dir, address);
if (pmd_none(*page_middle))
return;
if (pmd_bad(*page_middle)) {
printk("bad page table directory entry %p:[%lx]\n", page_dir, pgd_val(*page_dir));
pmd_clear(page_middle);
return;
}
page_table = pte_offset(page_middle, address);
Все данные об используемой процессом памяти помещаются в структуре: mm_struct
struct mm_struct {
struct vm_area_struct *mmap; /* Список отображенных областей */
struct vm_area_struct *mmap_avl; /* Те же области но уже в виде дерева
для более быстрого поиска */
struct vm_area_struct *mmap_cache; /* Последняя найденная область */
pgd_t * pgd; /*Каталог таблиц*/
atomic_t count;
int map_count; /* Количество областей*/
struct semaphore mmap_sem;
unsigned long context;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, total_vm, locked_vm;
unsigned long def_flags;
unsigned long cpu_vm_mask;
unsigned long swap_cnt; /* количество страниц для свопинга при следующем проходе */
unsigned long swap_address;
/*
* Это архитектурно-зависимый указатель. Переносимая часть Linux
ничего не знает о сегментах. */
void * segments;
};
Замечаем, что помимо вполне понятных указателей на начало данных (start_code, end_code...) кода и стека есть указатели на данные отображенных файлов (mmap).
На уровне процесса работа может вестись как со страницами напрямую, так и через абстрактную структуру vm_area_struct
struct vm_area_struct {
struct mm_struct * vm_mm; /* параметры области виртуальной памяти */
unsigned long vm_start;
unsigned long vm_end;
/* Связянный список областей задачи отсортированный по адресам */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned short vm_flags;
/* AVL-дерево областей, для ускоренного поиска, сортировка по адресам */
short vm_avl_height;
struct vm_area_struct * vm_avl_left;
struct vm_area_struct * vm_avl_right;
/* Для областей используемых при отображении файлов или при работе
с разделяемой памяти, иначе эта часть структуры не используется */
struct vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
struct vm_operations_struct * vm_ops; /*операции над областью */
unsigned long vm_offset;
struct file * vm_file;
unsigned long vm_pte; /* разделяемая память */
};
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
void (*unmap)(struct vm_area_struct *area, unsigned long, size_t);
void (*protect)(struct vm_area_struct *area, unsigned long, size_t, unsigned int newprot);
int (*sync)(struct vm_area_struct *area, unsigned long, size_t, unsigned int flags);
void (*advise)(struct vm_area_struct *area, unsigned long, size_t, unsigned int advise);
unsigned long (*nopage)(struct vm_area_struct * area, unsigned long address, int write_access);
unsigned long (*wppage)(struct vm_area_struct * area, unsigned long address,
unsigned long page);
int (*swapout)(struct vm_area_struct *, struct page *);
pte_t (*swapin)(struct vm_area_struct *, unsigned long, unsigned long);
};
Данная структура возникла из идеи виртуальной файловой системы, поэтому все операции над виртуальными областями абстрактны и могут быть специфичными для разных типов памяти, например при отображении файлов операции чтения одни, а при отображении памяти (через файл /dev/mem) совершенно другие. Первоначально vm_area_struct появилась для обеспечения нужд отображения, но постепенно распространяется и для других целей.
Что делать, когда требуется получить новую область памяти. Есть целых 3 способа.
1. get_free_page()
2. kmalloc - Простенькая (по возможностям) процедура с большими ограничениями по выделению новых областей и по их размеру.
3. vmalloc - Мощная процедура, работающая с виртуальной памятью, может выделять большие объемы памяти.
С каждой из двух процедур в ядре связаны еще по списку свободных/занятых областей, что еще больше усложняет понимание работы с памятью. (vmlist для vmalloc, kmem_cash для kmalloc)
Добавлена поддержка новой архитектуры памяти NUMA. В противовес классической UMA память делится на зоны с разным временем доступа к каждой из них. Это очень полезно и для кластерных решений. В связи с этим появились новые обертки на функции, новые структуры и найти суть стало еще сложнее. Появилась также поддержка памяти до 64Гб.
Ранее для всех файловых систем был один generic_file_read и generic_file_mmap в связи с тотальным засасыванием всего подряд в память при чтении (различия делались уже только на уровне inode->readpage).
Вывод.
В процессе выполнения курсовой работы, было выполнено изучение параметров, характеристик оперативной памяти. Также были изучены виды, типы, структуры и алгоритмы управления оперативной памятью. Далее был предоставлен пример работы операционной системы Linux с оперативной памятью.
Список используемой литературы
1. Рихтер Джеффри "Linux для профессионалов", С-П. Русская редакция 1998.
2. Хендерсон К. "Руководство разработчика баз данных"
3. Г. Майерс "Надежность ПО" Мир, М., 1980
Похожие работы
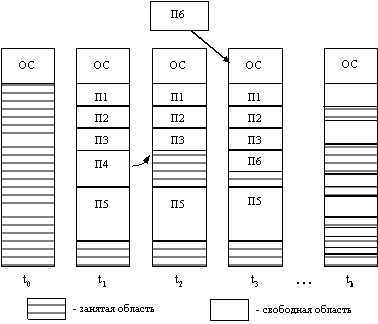
... задачи П4 место загружается задача П6, поступившая в момент t3. Рис. 2.10. Распределение памяти динамическими разделами Задачами операционной системы при реализации данного метода управления памятью является: ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти, при поступлении новой задачи - анализ запроса, просмотр ...
... адресов ячеек памяти —весь объем памяти делится на два или несколько банков. Двойные слова с последовательными адресами располагаются в разных банках. Во время считывания информации из оперативной памяти за один цикл можно организовать параллельное извлечение информации из разных блоков, что уменьшает количество циклов ожидания. Преимущество систем с интерливингом проявляется при ...





... подобные. Также интересно будет следить за борьбой Intel и AMD на рынке процессоров Изучение цен и спроса на оперативную память за последний год Исследование проводилось в городе Владивостоке. В качестве объектов исследования были выбраны модули оперативной памяти, имеющиеся в свободной продаже на рынке. Было определено пять основных типов RAM микросхем (SDRAM DIMM 32 MB <PC-100>, ...

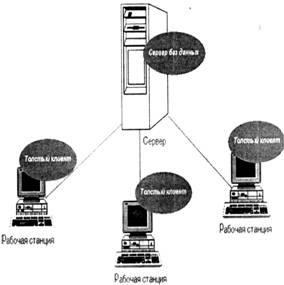
... . Это нормально, если на стороне клиента используется маломощная рабочая станция. Но если клиентский компьютер обладает достаточной мощностью, то часто возникает желание возложить на него больше функций управления базами данных, разгрузив сервер, который является узким местом всей системы. Что собственно говоря и обусловило появление двух- и трехуровневых (звенных) систем. 3.2 Два уровня или ...
0 комментариев