Навигация
Расширяемый язык разметки XML
104439
знаков
0
таблиц
2
изображения
2.2 Расширяемый язык разметки XML
Вторая половина 90-х годов прошедшего века ознаменовалась радикальными переменами в технологиях Web. Менее чем за пятилетнюю историю своего существования Web приобрел многие сотни миллионов пользователей на всех континентах, в его среде сформированы и поддерживаются огромные информационные ресурсы. Эта глобальная информационная система интенсивно вторгается в другие области информационных технологий, стала одним из важных звеньев инфраструктуры информационного общества.
Вместе с тем ряд ограничений, свойственных действующим технологиям Web (Web первого поколения или Web-1), стал сдерживающим фактором дальнейшего его развития. Новые подходы в области технологий Web, которые начали конструктивно воплощаться в жизнь на пороге XXI века, направлены, прежде всего на преодоление этих ограничений и создание технологической платформы[1], которая бы обеспечила потенциал для появления нового поколения Web (Web второго поколения или Web-2) и возможностей его развития на длительную перспективу. Основополагающую роль в технологическом переоснащении Web стал играть разработанный консорциумом W3C новый язык разметки XML. Язык XML (Extensible Markup Language, расширяемый язык разметки) – это метаязык, являющийся подъязыком SGML и определяющий процедуру порождения языков разметки для специфических целей.
Консорциум W3C, созданный для проведения единой технической политики в рамках Web и развития его технологий, ведет в настоящее время разработку и поддерживает более полутора сотен стандартов. Конечно же, невозможно представить их здесь в достаточно полном виде и приходится ограничиться лишь обсуждением концептуальных аспектов наиболее важных из них. Для основательного изучения стандартов платформы XML нужно обратиться к их оригинальным спецификациям и другим материалам консорциума W3C.
Следует заметить, что аббревиатуру XML довольно часто используют для обозначения не только самого языка XML, но и некоторых других связанных с ним понятий — определяющего язык стандарта W3C, информационных ресурсов XML, комплекса основанных на языке XML стандартов консорциума W3C, составляющих платформу XML.
В то время как язык XML все чаще используют в среде Web по прямому своему назначению — как выразительное средство для представления информационных ресурсов в этой среде, он вместе с тем энергично внедряется в другие технологии. Развитые выразительные возможности языка, а главное, его поддержка механизмами среды Web позволяют использовать XML в качестве языка-посредника для определения форматов обмена данными между различными системами, которые используют Internet в качестве коммуникационной среды.
Главная сфера применения стандартов платформы XML — это представление слабоструктурированных данных[2] Web-сайтов в форме XML-документов. Собственно, для этой цели и создавался язык XML. Применение XML в этой области позволяет не только представлять в среде Web гипермедийные страницы в форме XML-документов, но и поддерживать связанные с ними метаданные[3]. Благодаря этому можно создать такие поисковые машины Web, которые будут обеспечивать в результате обработки пользовательского поискового запроса гораздо более низкий уровень информационного шума по сравнению с нынешними HTML-технологиями.
Одной из важнейших целей создания платформы XML является привнесение в среду Web метаданных, описывающих свойства поддерживаемых в ней информационных ресурсов[4]. Речь идет прежде всего об описании структуры XML-документов и их смыслового содержания (семантики). Необходимость решения этой задачи аргументируется стремлением к получению возможностей автоматической проверки правильности структуры XML-документов и снижения уровня информационного шума при отыскании нужных данных в Web с помощью различных поисковых машин. Имеется в виду, что при наличии явного описания структуры документов проверку их правильности может осуществлять браузер. Описание семантики документов может быть полезным подспорьем для новых или модернизированных существующих поисковых машин, а также для разнообразных нуждающихся в нем Web-приложений.
Однако чаще всего не учитывается еще одно важное назначение метаданных, описывающих информационные ресурсы Web. Метаданные необходимы для создания принципиально новых высокоуровневых приложений Web, в частности основанных на интеграции информационных технологий и обеспечивающих интеграцию неоднородных информационных ресурсов. Приведенный ниже рис. 1. иллюстрирует упрощенную архитектуру системы, в которой метаданные используются для обеспечения интеграции неоднородных информационных ресурсов.
Пространства имен XML
Простейшая возможность задания семантики — использование пространства имен. В отличие от языка HTML, обеспечивающего форматную разметку текста, которая определяет его представление на экране, XML служит для структурной разметки.
Разметка в XML позволяет выделять в тексте содержательные структурные единицы, называемые элементами XML-документа. Для выделения каждого типа элементов используется свой тег, указывающий имя типа элемента. Поэтому с каждым таким тегом можно ассоциировать семантику соответствующих элементов XML-документа (адрес организации, номер телефона и т. д.).
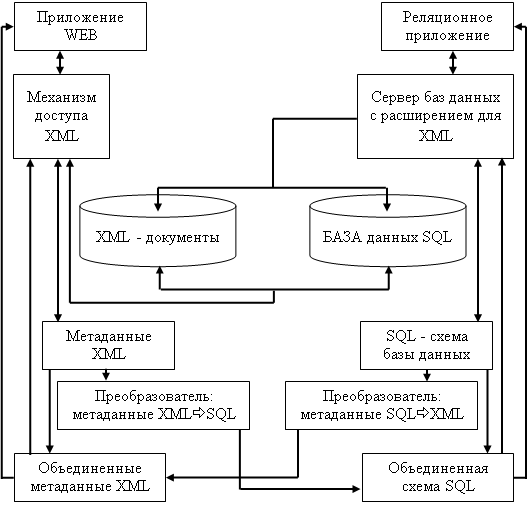
Рис. 1. Упрощенная архитектура системы, обеспечивающей интеграцию информационных ресурсов XML и SQL
Если некоторое сообщество разработчиков и пользователей XML-документов договорится о единой интерпретации имен, принадлежащих некоторому набору, то этот унифицированный набор, возможно, с каким-либо описанием их смысла (например, в виде обычного текста на естественном языке или представленный каким-либо иным образом), может использоваться как пространство имен. Адрес документа, представляющего в Web этот набор имен, будет рассматриваться как уникальный идентификатор пространства имен, и на него можно ссылаться в XML-документе, где используются принадлежащие этому пространству имена. И тем самым им придается некоторый смысл.
Заметим, что ресурс Web, адрес которого символизирует некоторое пространство имен, может не содержать никакого явного описания смысла принадлежащих ему имен и даже просто не существовать. В таком случае мы имеем дело с определением семантики имен данного пространства по умолчанию.
Примером достижения консенсуса о составе пространства имен является набор элементов метаданных для описания семантики представленных в Web документов, названный Дублинским ядром (Dublin Core, DC).
Дублинское ядро с принятой в нем семантикой элементов метаданных может использоваться в рамках платформы XML различными способами. Например, можно применять DC в качестве пространства имен для некоторого типа XML-документов или в RDF-спецификации (Resource Definition Framework, стандарт схемы описания источников).
RDF-спецификации представляют собой более высокий уровень семантического описания информационных ресурсов. Информационные ресурсы в RDF — это ресурсы Web, идентифицируемые уникальным образом с помощью их URI (Uniform Resource Identifier, обобщение концепции URL в WWW). Они могут также представлять собой коллекции других информационных ресурсов или литералов, называемые контейнерами. Допускаются контейнеры типа мультимножества, последовательности и альтернативы.
Для того чтобы RDF-спецификация семантики информационных ресурсов была полной, необходимо ассоциировать с нею описание семантики используемых в этой спецификации свойств, которое в терминологии стандарта RDF называется схемой.
Метаданные, представленные средствами RDF, могут использоваться для более эффективного поиска ресурсов поисковыми машинами Web, в электронных библиотеках, в описаниях коллекций страниц Web, составляющих некоторый виртуальный документ, для представления содержания информационных ресурсов в конкретных предметных областях, а также для поддержки различных Web-приложений, нуждающихся в семантической информации о ресурсах.
В задачу RDF не входит стандартизация каких-либо наборов семантических свойств, и они могут быть различными в разных случаях.
В последнее время начали создаваться сервисы регистрации и поддержки пространств имен в интересах различных сообществ разработчиков и пользователей. Зарегистрированное пространство имен является своего рода стандартом для сообществ клиентов сервиса регистрации.
Перспективы XML
XML — отнюдь не модное направление, а естественный результат развития Web-технологий, следствие стремления к более эффективному использованию уникальных возможностей открытой глобальной информационной среды, которую они поддерживают. Создание платформы XML — это новая эпоха в развитии Всемирной паутины, это — начало нового, более наукоемкого и технологически более совершенного этапа в ее истории. Сегодня XML, несомненно, стал стандартом де-факто. Все ведущие поставщики программного обеспечения не только Web, но и систем баз данных, включают в свои программные продукты поддержку языка XML или даже создают специализированные системы.
Большую работу по продвижению стандартов платформы XML в практику ведет крупный Международный, некоммерческий консорциум OASIS (Organization for Structured Information Standards, Организация по стандартизации структурированной информации) (Приложение 2.
Международная организация OASIS
), в составе, которого более 600 корпоративных и индивидуальных членов из различных стран мира. Эта деятельность является основной задачей консорциума. OASIS разрабатывает, координирует разработки и распространяет информацию о методологиях применения, технологиях и реализациях этих стандартов. В его задачу входит также создание приложений для «вертикальной» индустрии (например, разработки описания типов документов (Document Type Definition, DTD), схем XML и пространств имен XML), спецификаций интероперабельности (в частности, создание спецификаций профилей, включающих стандарты рассматриваемой категории), тестов на соответствие рассматриваемым стандартам.
Распространению стандартов XML-платформы существенным образом способствует политика W3C, направленная на обеспечение доступности их спецификаций, создание ряда свободно распространяемых синтаксических анализаторов для языка, то большое внимание, которые создатели стандартов XML уделяют обеспечению преемственности для существующей HTML-платформы и накопленных на ее основе ресурсов.
Хотя язык XML и базирующиеся на нем стандарты получают все более широкое распространение, имеются вместе с тем факторы, которые сдерживают массовое распространение XML в среде Web.
Во-первых, существует связанная с экономическими и иными причинами естественная инерционность столь масштабной среды, какой является сегодняшний Web. Эта инерция может преодолеваться только постепенно.
Во-вторых, пока еще не завершена работа над двумя важнейшими стандартами платформы XML, которые позволяют строить из отдельных XML-документов и их компонентов гипермедийную среду. Речь идет о стандартах XPointer (XML Pointer Language, язык указателей XML) и XLink (XML Linking Language, язык ссылок XML). Эти стандарты решают задачу определения гиперссылок в языке XML. Возможности стандартов XPointer и XLink предусматривают существенно более богаты возможности работы с гиперссылками, чем у имеющихся в HTML.
Технологии XML начинают распространяться и в нашей стране. В этой связи приобретает важное значение русскоязычная терминология в этой области.
Платформа XML имеет благоприятные перспективы для широкого практического применения. В пользу этого свидетельствуют не только богатые функциональные возможности рассмотренного семейства стандартов, но и высокая активность в области разработки и развития стандартов, а также производства программного обеспечения, на них основанного.
2.2. Расширяемый язык разметки гипертекста XHTMLАктивное распространение технологий XML порождает весьма острую проблему обеспечения преемственности в развитии среды Web, создания возможностей, позволяющих использовать огромные информационные ресурсы, накопленные в рамках технологий HTML.
Один из подходов к решению этой проблемы реализован в стандарте XHTML 1.0 (The Extensible Hypertext Markup Language, расширяемый язык разметки гипертекста), одобренном W3C в январе 2000 г. Как и HTML, XHTML является подмножеством языка SGML, однако XHTML, в отличие от предшественника, соответствует спецификации XML.
Идея предлагаемого подхода заключается в создании на основе XML языка разметки, эквивалентного по его функциональности языку HTML. Аналогичным образом в настоящее время разработаны многие другие языки разметки конкретизации XML. Создание таких языков сводится, по существу, к разработке соответствующего определения типа документов (DTD).
Авторы стандарта XHTML 1.0 трактуют функцию определяемого в нем языка как переформулировку HTML в XML (более точно, речь идет о принятом W3C в декабре 1999 г. стандарте HTML 4.01 и об XML 1.0).
XHTML является преемником HTML. Потребность в более строгой версии HTML возникла из-за того, что веб-контент сегодня всё больше становится ориентированным на нетрадиционные виды устройств (например, мобильные телефоны), в которых зачастую ограничены ресурсы, в том числе и для обработки гибкого, нетребовательного HTML (чем свободнее синтаксис языка, тем сложнее его разбирать).
Практически все современные браузеры поддерживают XHTML. Он также совместим и со старыми браузерами, т. к. в основе XHTML лежит HTML. Такая совместимость, к сожалению, в числе прочего, замедляет процесс перехода от HTML к XHTML.
Настоящая сила XHTML проявляется в его сочетании с каскадными таблицами стилей. Это позволяет отделить оформление документа от его содержимого.
Отличия переходного (англ. transitional) XHTML от HTML незначительны и предназначены лишь для приведения его в соответствие с XML. Самое главное требование заключается в том, чтобы все тэги были правильно вложены и семантически развиты. Кроме того, в XHTML все теги должны записываться строчными буквами, все атрибуты (включая численные) должны быть заключены в кавычки (что не является обязательным в SGML и, следовательно, в HTML, где кавычки не требуются для чисел и некоторых символов, включая все буквы). Также все элементы должны быть закрыты, включая те, которые не имеют закрывающего тега (закрываются добавлением слэша ('/') в конец тега). Минимизация атрибутов (к примеру <option selected> или <td nowrap>) также воспрещена. Детальнее об отличиях можно узнать из спецификации XHTML http://www.w3.org/.
В стандарте XHTML предлагается три варианта целевого языка для представления HTML-документов и тем самым три версии DTD:
· XHTML Strict (строгий XHTML);
· XHTML Transitional (переходный XHTML);
· XHTML Frameset (XHTML с фреймами).
Вариант XHTML Strict полностью отделяет содержание документа от оформления, многие атрибуты (такие как, например, bgcolor и align) более не поддерживаются. Предназначен для чисто структурной разметки без применения элементов форматирования. Для целей форматирования можно при этом дополнительно использовать язык каскадных таблиц стилей (CSS).
Вариант XHTML Transitional будет, вероятно, наиболее популярным. Он допускает использование таблиц стилей, но имеется в виду, что будет внесена некоторая небольшая коррекция в разметку с тем, чтобы документ мог восприниматься и старыми браузерами, которые не поддерживают таблиц стилей. Предназначен для лёгкой миграции из HTML и для тех, кто использует инлайн-фрэймы.
Вариант XHTML Frameset обеспечивает поддержку фреймов. Это позволяет разбить окно браузера на несколько разделов (фреймов), с которыми ассоциируется некоторый набор функций управления.
Но существуют и специализированные дополнительные версии XHTML:
XHTML 1.1 Модульный (Module-based): авторы могут импортировать дополнительные свойства в их разметку. Эта версия также поддерживает руби-разметку, необходимую для дальневосточных языков.
XHTML Основной (Basic): специальная облегчённая версия XHTML для устройств, которые не могут использовать полный набор элементов XHTML — в основном используется в миниатюрных устройствах, таких как мобильные телефоны. Подразумевается, что он заменит WML и C-HTML.
XHTML мобильного профиля (Mobile Profile): основанный на XHTML Basic, добавляет специфические элементы для мобильных телефонов. Он является еще одним шагом вперед на пути к мобильным сервисам 3G. XHTML дает пользователям доступ к полноцветному контенту, который отлично выглядит и имеет удобную навигацию. В сочетании с увеличенной скоростью, предлагаемой GPRS, мобильные сервисы становятся более притягательными и похожими на обычный Internet.
Хотя гиперссылки на документы, содержащие определения вариантов DTD для XHTML Strict, XHTML Transitional и XHTML Frameset, приводятся в приложении к стандарту, именно эти спецификации составляют основное его содержание.
В стандарте XHTML значительное внимание уделено вопросам поддержки развития языка HTML. Предполагается, что XHTML 1.0 определяет начальную версию развивающегося семейства типов документов, которые позволяют воспроизводить HTML, выделять его подмножества и расширять этот язык.
Обеспечение модульности языка воплощается в проекте новой версии стандарта — XHTML 1.1.
Прародителями XHTML 2.0 являются HTML 4, XHTML 1.0 и XHTML 1.1, но он не рассчитан на обратную совместимость с ними. Кроме того, первый Рабочий проект пока не включает реализации XHTML 2.0 ни в форме DTD, ни в виде XML-схемы. Эти реализации будут включены на более поздних этапах, как только будут урегулированы принципиальные вопросы.
В спецификации XHTML вводится специальное пространство имен XHTML. Однако для именования элементов и атрибутов в документах допускается использование наряду с ним также и других пространств имен, например пространства имен MathML (математический язык разметки) или RDF (Resource Definition Framework).
Пространство имен XHTML
XHTML более доступен, так как он использует пространство имен практически идентичное с HTML 4.01 и, таким образом, большая часть DTD уже "зашита" в браузере. DTD (Document Type Definition) критически важен для XML-документов. Другой вопрос связанный с XML: пространство имен этого языка очень велико и определяется именно DTD написанным специально для конкретной его разновидности. Для браузера во время разбора соответствующего XML-кода эти документы должны быть доступны. Преимущество XHTML module в том что пространство имен может быть сокращенно до того списка который вы используете на сайте.
Валидация XHTML документов
Валидным (т.е. отвечающим всем правилам) XHTML-документом считается документ, удовлетворяющий технической спецификации. В идеале, все браузеры должны следовать веб-стандартам и, в соответствии с ними, валидные документы должны отображаться во всех браузерах на всех платформах. Валидация XHTML-документа рекомендована даже несмотря на то, что она не гарантирует кросс-браузерной совместимости. Документ может быть проверен на соответствие спецификации с помощью онлайновой Службы валидации разметки W3C. Валидация обнаружит и разъяснит ошибки в XHTML-разметке.
Валидный документ должен содержать определение типа документа (DTD). DTD должен быть расположен до всех других элементов документа.
Валидный XHTML-документ, по правилам W3C, может быть снабжён специальным баннером, подтверждающим правильность XHTML-разметки.
Авторы стандарта рассматривают миграцию к XHTML как следующий шаг в эволюции Web-технологий. В настоящее время W3C продолжает работу по развитию XHTML. Одной из важных задач при этом признается обеспечение модульности языка.
Глава 3. СПЕЦИФИКАЦИИ ТЕХНОЛОГИЙ WEB 3.1 О спецификации HTML
Спецификация состоит из следующих разделов.
Во введении описывается место языка HTML в схеме World Wide Web, приводится краткая история развития языка HTML, описывается, что можно сделать с использованием HTML 4.0 и содержатся некоторые подсказки относительно создания документов в формате HTML.
Краткое руководство по SGML дает читателям понимание отношения языка HTML к языку SGML и предоставляет информацию о чтении Определений типов документов HTML (Document Type Definition - DTD).
Главным содержанием руководства является справочник по языку HTML, в котором определены все элементы и атрибуты языка.
Этот документ упорядочен по разделам, а не по грамматике языка HTML. Разделы сгруппированы в три категории: структура, представление и интерактивность. Хотя конструкции языка HTML трудно разделить на эти три категории, такая модель отражает опыт Рабочей группы HTML, говорящий о том, что разделение структуры документа и его представления обеспечивает большую эффективность документов и лучшие возможности поддержки.
Информация о языке включает следующую:
· Какие символы могут отображаться в документе HTML.
· Основные типы данных документа HTML.
· Элементы, управляющие структурой документа HTML, включая текст, списки, таблицы, ссылки и объекты, изображения и апплеты.
· Элементы, управляющие представлением документа в формате HTML, включая таблицы стилей, шрифты, цвета, горизонтальные разделители и другое визуальное представление, а также фреймы (кадры) для многооконного представления.
· Элементы, управляющие интерактивностью документа HTML, включая формы для ввода данных пользователя и скрипты для активных документов.
· Формальное SGML-определение HTML: SGML-определение HTML;
три DTD: строгое, переходное и с кадрами; список ссылок на символы.
В первом приложении содержится информация об изменениях по отношению к HTML 3.2 с целью помочь авторам при переносе файлов в формат HTML 4.0. Во втором приложении содержатся замечания о производительности и применении, целью которых является помощь разработчикам в создании средств для использования HTML 4.0.
Список нормативных и информативных документов.
Три указателя предоставляют читателям быстрый доступ к определению: понятия, элементы и атрибуты.
Этот документ написан читателями с двумя типами мышления: авторами и разработчиками. Мы надеемся, что спецификация предоставит авторам средства, необходимые им для создания эффективных, привлекательных и доступных документов и не обременяющие их подробностями применения HTML. Разработчики, однако, должны найти здесь всю необходимую для разработки соответствующих средств информацию.
Эту спецификацию можно использовать несколькими способами:
Прочесть от начала до конца. Эта спецификация начинается с общего представления языка HTML, а количество технических подробностей постепенно повышается.
Обращаться к необходимой информации. Для обеспечения максимальной скорости получения информации о синтаксисе и семантике в оперативную версию спецификации включены следующие возможности:
Каждая ссылка на элемент или атрибут связана с его определением в спецификации. Каждый элемент или атрибут определяется только в одном месте.
На каждой странице имеются ссылки на указатели, поэтому Вы всегда сможете найти определение элемента или атрибута, использовав не больше двух ссылок.
На первых страницах трех разделов руководства к исходному оглавлению добавляется более подробная информация о каждом разделе.
Названия элементов представляются символами в верхнем регистре (например, BODY). Названия атрибутов представляются символами в нижнем регистре (например, lang, onsubmit). Помните, что в HTML имена элементов и атрибутов не учитывают регистр; это используется для более легкого чтения.
В названиях элементов и атрибутов в этом документе используется разметка, поэтому агентами пользователей они могут генерироваться особым образом.
В каждом определении атрибута устанавливается тип его значения. Если имеется несколько возможных значений, приводится список значений, разделенных вертикальной чертой (|).
После информации о типе в каждом определении атрибута в квадратных скобках ("[]") указывается, учитывается ли в значениях регистр. Подробнее см. раздел информации о регистре.
Информативные замечания выделены, чтобы отличаться от остального текста и могут генерироваться агентами пользователей особым образом.
Все примеры, иллюстрирующие нежелательное использование, помечены как "ПРИМЕР НЕЖЕЛАТЕЛЬНОГО ИСПОЛЬЗОВАНИЯ". В примеры нежелательного использования входят также рекомендуемые альтернативные решения. Все примеры, иллюстрирующие недопустимое использование, помечены как "ПРИМЕР НЕДОПУСТИМОГО ИСПОЛЬЗОВАНИЯ".
В примерах и замечаниях используется разметка, поэтому некоторыми агентами пользователей они могут генерироваться особым образом.
3.2 О спецификации XMLРасширяемый Язык Разметки (XML) является поднабором SGML и полностью описан в спецификации. Он создан с целью обеспечения обслуживания, передачи и обработки в WEB исходного SGML теми же способами, которые в данный момент имеются в HTML. XML был разработан для облегчения создания конкретных реализаций и для взаимодействия с SGML и HTML.
Роль W3C в составлении Рекомендаций заключается в том, чтобы привлечь внимание к данной спецификации и способствовать её широкому распространению. Это расширит функциональность и возможности Web.
Этот документ специфицирует синтаксис, создаваемый путём подразделения существующих широко распространённых международных стандартов обработки текста для использования в World Wide Web.
Extensible Markup Language, сокращённо XML, описывает класс объектов данных, называемых XML-документы, и частично описывает поведение обрабатывающих их компьютерных программ. XML является профилем приложения или ограниченным вариантом SGML - The Standard Generalized Markup Language. По структуре документы XML являются "соответствующими" документами SGML.
Документы XML состоят из единиц хранения, называемых экземпляры, которые содержат разбираемые или неразбираемые данные.
Разбираемые данные состоят из символов, некоторые из которых образуют символьные данные, а другие - разметку. Разметка кодирует описание схемы и логической структуры единиц хранения документа. XML предоставляет механизм наложения ограничений на схему и логическую структуру единиц хранения.
XML был разработан XML Working Group (ранее известной как SGML Editorial Review Board), сформированной под руководством World Wide Web Consortium (W3C) в1996 году.
Её возглавил Jon Bosak из Sun Microsystems при активном участии XML Special Interest Group (ранее известной как SGML Working Group), также организованной W3C. Члены XML Working Group указаны в Приложении. Dan Connolly является контактёром рабочей Группы с W3C.
Цели создания XML:
1. XML будет широко распространён в Internet.
2. XML будет поддерживать большой диапазон приложений.
3. XML будет совместим с SGML.
4. Он будет лёгким для написания программ, обрабатывающих документы XML.
5. Количество свойств по выбору (optional) в XML будет сведено к абсолютному минимуму, в идеале - к нулю.
6. Документы XML должны быть разборчивыми и ясными по смыслу.
7. Дизайн XML должен выполняться быстро.
8. Дизайн XML должен быть формальным и кратким.
9. Документы XML должны легко создаваться.
10. Краткость в разметке XML имеет минимальное значение.
Эта спецификация, вместе с ассоциированными стандартами, предоставляет всю информацию, необходимую для понимания XML и создания компьютерных программ его обработки.
Символы – это разбираемый экземпляр содержит текст, последовательность символов, которая может представлять символьные данные или разметку. Текст состоит из смеси символьных данных и разметки.
Комментарии могут появляться в любом месте документа вне прочей разметки; кроме того, они могут появляться внутри объявления типа документа в тех местах, которые допускаются грамматикой. Они не являются частью символьных данных документа: процессор XML может, но не должен, давать приложению возможность запрашивать текст комментариев.
Инструкции процесса (ИП) позволяют вводить в текст документа инструкции для приложений. Разделы CDATA могут появляться там же, где и символьные данные; они используются для escape-блоков текста, содержащего символы, которые иначе будут распознаваться как разметка.
Документы XML должны начинаться объявлением XML, которое специфицирует используемую версию XML.
Поскольку будущие версии ещё не сформированы, эта конструкция даётся как средство предоставления возможности автоматического распознавания версии и должна, следовательно, быть включена обязательно. Процессоры могут сигнализировать об ошибке, если получат документ, помеченный неподдерживаемой версией.
Функцией разметки в документе XML является обязанность описывать структуру хранения данных и логическую структуру и ассоциировать пары атрибут-значение с их логическими структурами. XML предоставляет механизм объявления типа документа для определения ограничений в логической структуре и для поддержки использования предопределённых единиц хранения.
Документ XML является правильным/valid, если он имеет ассоциированное объявление типа документа и если документ выполняет ограничения, выраженные в нём.
Объявление типа документа XML содержит или указывает на объявления разметки, предоставляющие грамматику для класса документов. Эта грамматика известна как определение типа документа или DTD. Объявление типа документа может указывать на внешний поднабор (особый вид внешнего экземпляра), содержащий объявления разметки, или может непосредственно содержать объявления разметки во внутреннем поднаборе, или может иметь и то, и другое. DTD документа состоит из обоих соединённых поднаборов. Объявление разметки это объявление типа элемента, объявление списка атрибутов и объявление экземпляра, или объявление нотации. Эти объявления могут полностью или частично содержаться внутри экземпляров параметров.
Каждый документ XML содержит один или более элементов, ограниченных либо начальными и конечными тэгами, либо - для пустых элементов - тэгами пустых элементов. Каждый элемент имеет тип, идентифицируется по имени, которое иногда называется "generic identifier" (GI) - родовой идентификатор, и может иметь набор спецификаций атрибутов. Каждая спецификация атрибутов имеет имя и значение.
Начало каждого непустого элемента XML обозначается начальным тэгом. Окончание каждого элемента, начатого начальным тэгом, обязано быть отмечено конечным тэгом, содержащим имя, отражающее тип элемента, как это было дано в начальном тэге. Текст между начальным и конечным тэгами называется содержимым элемента.
Элемент без содержимого называется пустым. Пустой элемент представлен либо начальным тэгом, после которого непосредственно следует конечный тэг, либо тэгом пустого элемента. Тэг пустого элемента имеет особую форму.
Структура элемента документа XML может, для целей проверки, быть ограничена путём использования объявлений типа элемента и списка атрибутов. Объявление типа элемента ограничивает содержимое элемента.
Объявление типа элемента часто ограничивают типы элементов, которые могут появляться в качестве потомков элемента.
Тип элемента имеет содержимое элемента, если элементы данного типа обязаны содержать только дочерние элементы (а не символьные данные), которые могут быть, по усмотрению, разделены пробелами.
В этом случае ограничение включает модель содержимого, простую грамматику, управляющую разрешёнными типами дочерних элементов и порядком, в котором они могут появляться.
Тип элемента имеет смешанное содержимое, если элементы этого типа могут содержать символьные данные, перемежаемые дочерними (необязательными) элементами.
Атрибуты используются для ассоциирования пар имя-значение с элементами. Спецификации атрибутов могут появляться только в начальных тэгах и тэгах пустых элементов; поэтому продукции, используемые для их распознавания, появляются в разделе.
Прежде чем значение атрибута передаётся приложению или проверяется на правильность, процессор XML обязан нормализовать значение атрибута путём применения к нему нижеприведённого алгоритма или путём использования некоторых других методов так, чтобы значение, передаваемое приложению, было тем же, что и произведённое алгоритмом.
Документ XML может состоять из одной или более единиц хранения. Они называются экземплярами; они имеют содержимое и все (исключая экземпляр документа и внешний поднабор ОТД) идентифицируются по name\имени экземпляра. Содержимое разбираемого экземпляра называется его замещающим текстом; этот текст считается неотъемлемой частью документа.
Неразбираемый экземпляр это ресурс, чьё содержимое может, или может не быть, текстом, и, если это текст, может не быть XML. Каждый неразбираемый экземпляр имеет ассоциированную нотацию, идентифицируемую по имени. Помимо требования к процессору XML сделать идентификаторы экземпляра и нотации доступными приложению, XML не накладывает никаких ограничений на содержимое неразбираемых экземпляров.
Общие экземпляры это экземпляры для использования внутри содержимого документа. В этой спецификации ОЭ иногда называются неквалифицированным термином экземпляр, если это не приводит к неоднозначности.
Экземпляры параметров это разбираемые экземпляры для использования внутри ОТД. Эти два типа экземпляров используют разные формы ссылок и распознаются в различных контекстах. Следовательно, они занимают разные пространства имён; экземпляр параметра и общий экземпляр с одни именем - это два разных экземпляра.
Ссылка символа ссылается на специфический символ в наборе символов ISO/IEC 10646, например, ссылка на символ, не доступный напрямую из устройства ввода. Ссылка экземпляра ссылается на содержимое именованного экземпляра.
Если процессор XML обнаруживает ссылку на разбираемый экземпляр, то, для того чтобы проверить документ, процессор обязан включить его (экземпляра) замещающий текст. Если экземпляр является внешним, а процессор не пытается проверить документ XML, то процессор может, но это не является необходимым, включить замещающий текст экземпляра. Если непроверяющий процессор не включает замещающий текст, он обязан информировать приложение, что он обнаружил, но не прочитал, экземпляр.
Это правило базируется на том, что автоматическое распознавание, предоставляемое механизмом экземпляров SGML и XML, первоначально созданным для поддержки модульности в авторизации, не обязательно подходит для других приложений, особенно для просмотра документов. Браузеры, например, при обнаружении ссылки на внешний разбираемый экземпляр, могут избрать визуальное предупреждение о том, что экземпляр существует, и запрашивать его для показа только по требованию.
Литеральное значение экземпляра это закавыченная строка, реально представленная в объявлении экземпляра, соответствующая нетерминальному EntityValue. Определение: Замещающий текст это содержимое экземпляра после замещения мнемоник символов и ссылок экземпляров параметров.
Нотации идентифицируют по имени формат не разбираемых экземпляров, формат элементов, которые породили атрибут нотации, или приложение, которому адресуется инструкция процесса. Объявления нотации предоставляют имя нотации для использования в объявлениях экземпляра и списка атрибутов и в спецификациях атрибутов, а также внешний идентификатор для нотации, который может позволить процессору XML или его клиентскому приложению локализовать вспомогательное приложение, способное обработать данные в данной нотации.
Соответствующие процессоры XML делятся на два класса: проверяющие и непроверяющие. Проверяющие и непроверяющие процессоры оба обязаны выводить сообщения о нарушениях ограничений правильно сформированности данной спецификации в содержимом экземпляра документа и любых других разбираемых экземплярах, которые они читают.
Проверяющие процессоры обязаны, по выбору пользователя, сообщать о нарушениях ограничений, выраженных объявлениями в ОТД, и невозможности выполнения ограничений правильности, данных в этой спецификации. Чтобы выполнить это, проверяющие процессоры XML обязаны читать и обрабатывать все ОТД и все внешние разбираемые экземпляры, на которые имеются ссылки в документе.
От непроверяющих процессоров требуется лишь проверить экземпляр документа, включая весь внутренний поднабор ОТД, на правильное формирование.
Поскольку не требуется проверять документ на правильность/верность, необходимо обработать все объявления, прочитанные во внутреннем поднаборе ОТД и во всех экземплярах параметров, которые прочитаны, до первой ссылки на экземпляр параметра, который не прочитан; то есть информация в этих объявлениях обязана использоваться для нормализации значений атрибутов, включения замещающего текста внутренних экземпляров поддержки значений по умолчанию в атрибутах.
Формальная грамматика XML даётся в данной спецификации с использованием нотации Extended Backus-Naur Form (EBNF). Каждое правило грамматики определяет один символ.
Похожие работы
... панель управления, логотип и название фирмы выполняются в виде графических элементов. После создания макета можно приступить к его реализации с помощью языка HTML и иных средств, предлагаемых современными технологиями WWW. Завершив создание Web-узла, необходимо разместить его в Internet. Здесь возможны два варианта: первый — использовать компьютер, который вместе с Web-сервером и Web-узлом ...
... охватывало бы вопросы воспитания, взаимодействия учителей с родителями учеников и самими учениками, вопросы самоподготовки желающих учиться учеников, помощи отстающим и т.п. 5. РАЗРАБОТКА ШКОЛЬНОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ (ШИС) НА ОСНОВЕ IT-ТЕХНОЛОГИЙ ДЛЯ МОУ СОШ № 97 Поставленные в предыдущем разделе задачи могут быть решены путем организации широчайшего (относительно родителей, учеников и ...
... ресурсов рассматривалась в двух контекстах. Первый контекст - повторное использование (reusability) существующих и доступных по сети ресурсов. Второй контекст - облегчение разработки корпоративных информационных систем, отдельные компоненты которых создаются разными, территориально распределенными группами, каждая из которых в силу исторических причин использует наиболее привычную для нее ...

... получить информацию о компании, горящих турах, ее услугах, а также контактную информацию и обратную связь для клиентов и партнеров. При переходе по ссылкам информация будет отображаться на холсте сайта. 2. Проектирование дистанционной информационной системы 2.1 Структурная схема веб-интерфейса пользователя ДИС Для удобного доступа к информации разработана структурная схема веб-интерфейса, ...
0 комментариев