Яков Фельдман
Введение в проблему
Мой опыт работы в крупных (богатых и технологически продвинутых) американских компаниях (таких как MCI WorldCom и Sprint) убедил меня в том, что в мире информационных техологий хорошо работают только демонстрационые примеры на больших презентациях. Слишком много внимания уделяется процессу презентации на идеальных данных - и слишком мало - процессу обращения в системе реальных данных.
Процесс идет обычно по одному из следующих сценариев.
Покупается готовый программный продукт. Продукт дорог. Купить его может только крупное предприятие. Приспособить процесс к продукту можно лишь отчасти. В конечном счете все равно приходится приспосабливать продукт к процессу.
Если предприятие очень богатое, оно платит разработчикам продукта и они доводят продукт под потребителя.
Если предприятие крупное но не очень богатое, оно пытается довести продукт своими силами и попадает в вариант (2)
Система разрабатывается и поддерживается своими силами. Вариант, реально существующий в жизни средних предприятий. Частные задачи существуют сами по себе. Чем больше задач и чем шире они реально используются, тем хуже качество информации в целом.
Первая причина - децентрализация ввода данных. Если раньше (В эпоху mainframe) за качество вводимой информации отвечали специалисты, то теперь любой инженер (конструктор, технолог, экономист) вводит те данные которыми владеет.
Вторая причина - децентрализованная разработка программ и структур данных во обеспечение этих программ. При централизованном вводе данных все пользователи - под контролем. При децентрализованном - каждый пользователь может ставить задачу "своему" программисту. Так на едином информационном пространстве возникает хаос задач и испоьзуемых ими данных.
Эти причины усиливают друг друга - если в структурах заложен ввод одного и того же документа дважды, то высока вероятность, что один раз его введут с ошибкой и два противоречащих друг другу документа будут существовать в системе на равных. И наоборот. Противоречия в информации блокируют возможность совершенствования структур в процессе работы. Представьте себе, что мы обнаружили необходимость двойного ввода до наполнения базы. Здесь эту ошибку легко исправить. А если у нас в системе уже существуют пары равноправных противоречащих друг другу информационных образов одного и того же реального документа? Тогда, если мы хотим оставить только один образ из двух, по каждой такой паре надо принять отдельное решение. В реальной жизни число таких необходимых решений столь велико, что никто дажет не ставит подобных проблем и ошибка проектирования становится вечной.
Для мелких предприятий наиболее вероятным является использование локальных приложений в среде типа Microsoft Office. Но если на этом предприятии оказываются люди понимающие в программировании, то они хотели бы разработать интегрированную информационную систему. Иногда они даже начинают такие разработки, но большая трудоемкость процесса не дает им далеко продвинуться.
Предлагаемая нами технология (Условное название D2C3) значительно понижает стоимость разработки и поддержки интегрированных информационных систем при высоком качестве проектных решений по структурам данных и очень высоком качестве информационного наполнения этих структур. Чем достигается такой результат?
Как решать проблему
В предлагаемой нами технологии (под которую разработана программная поддержка) результат достигается последовательным проведением двух больших принципов
Персональная ответственность каждого пользователя за вводимую им информацию.
Персональная ответственность одного эксперта за все структуры данных.
и двух малых принципов
Отделенность системы поддержки данных от системы презентации
Автоматическая настройка системы поддержки данных
Разумеется для практического исполнения этих принципов необходима программная поддержка. Средства такой поддержки уже разработаны и находятся в процессе тестирования.
Список литературы
Для подготовки данной работы были использованы материалы с сайта http://www.members.tripod/com
Похожие работы
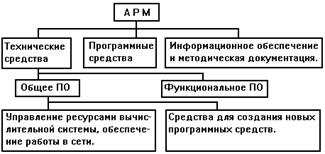
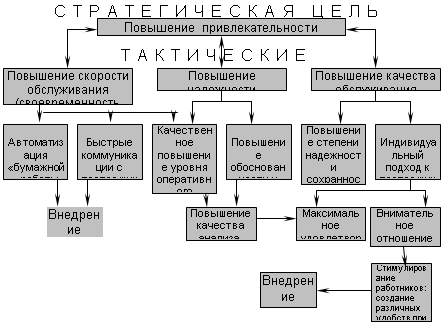
логического оборудования на всех стадиях производства. 1 Исследование и выбор базового метода при построении системы информационного обеспечения отдела бухгалтерии Анализируя сущность АРМ (автоматизированное рабочее место), специалисты определяют их чаще всего как профессионально-ориентированные малые вычислительные системы, расположенные непосредственно на рабочих местах специалистов и ...
... функционирования. На данный момент существует достаточно большое количество разновидностей информационных систем. Классификация информационных систем обычно осуществляется на основе каких-либо выделенных признаков. Например, с точки зрения управленческого уровня, на котором осуществляется использование ИС, принято делить корпоративные ИС на следующие виды: 1. ИС для обеспечения текущих бизнес- ...
... СУБД; можно управлять распределением областей внешней памяти, контролировать доступ пользователей к БД и т.д. в масштабах индивидуальной системы, масштабах ограниченного предприятия или масштабах реальной корпоративной сети. В целом, набор серверных продуктов одиннадцатого выпуска компании Sybase представляет собой основательный, хорошо продуманный комплект инструментов, которые можно ...
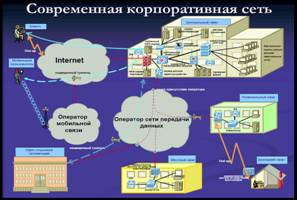
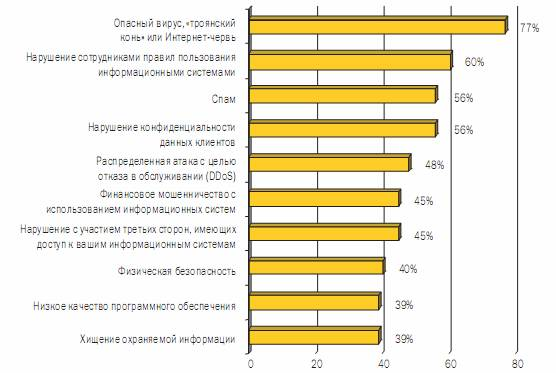
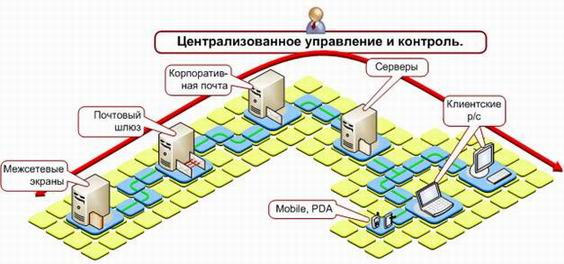
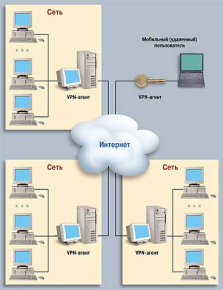
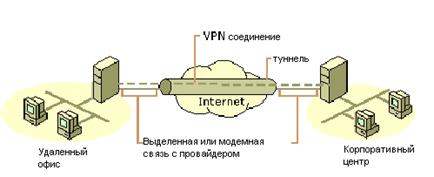
... в основу методики и выведена формула для получения количественной оценки уровня защищенности, обеспечиваемого СЗИ. 4. Применение методики определения уровня защищенности и обоснования эффективности средстВ защиты КИС 4.1 Описание защищаемой корпоративной системы Разработанная нами методика позволяет оценить уровень защищенности КИС при определенном наборе средств СЗИ и, соответственно ...
0 комментариев