Навигация
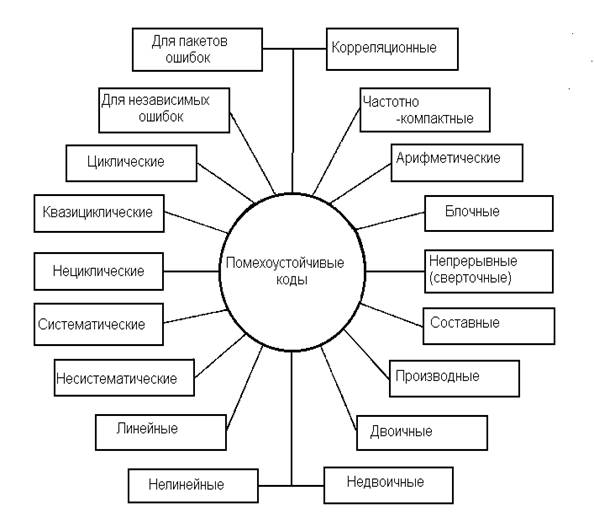
Особенности практического применения способов кодирования. Способы декодирования с обнаружением ошибок
11870
знаков
2
таблицы
5
изображений
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ИНФОРМАТИКИ И РАДИОЭЛЕКТРОНИКИ
кафедра РЭС
реферат на тему:
«Особенности практического применения способов кодирования. Способы декодирования с обнаружением ошибок»
МИНСК, 2009
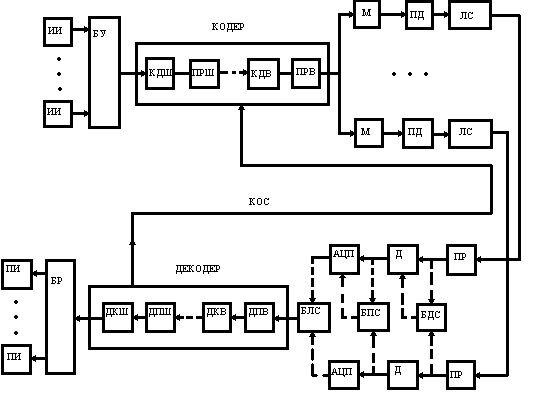
Задача кодирования заключается в формировании по информационным словам a(x) кодовых слов (x) циклического (n,k)-кода, который по своей структуре может быть несистематическим и систематическим.
Формирование кодовых слов несистематического кода заключается в умножении многочлена a(x), отображающего информационную последовательность длины k, на порождающий многочлен, т.е. (x)=a(x)(g(x). Формирование кодовых слов систематического кода заключается в преобразовании информационной последовательности a(x) в соответствии с выражением (x)=a(x)xr+r(x).
Проверочная последовательность r(x) определяется двумя способами:
при использовании "классического" способа кодирования ![]() ;
;
при использовании способа кодирования, рекомендованного МККТТ ![]() ,
,
где x(1)r-1 - единичный многочлен степени (r-1).
Указанные выше математические операции выполняют кодеры несистематического и систематического кодов.
Способы декодирования с обнаружением ошибок
Процедура декодирования циклического кода с обнаружением ошибок, по аналогии с процессом кодирования, использует два способа:
- при кодировании "классическим" способом декодирование основано на использовании свойства делимости без остатка кодового многочлена (x) циклического (n,k)-кода на порождающий многочлен g(x). Поэтому алгоритм декодирования включает в себя деление принятого кодового слова, описываемого многочленом ![]() на g(x), вычисление и анализ остатка r(x). Если r(x)=0, то принятое кодовое слово считается неискаженным. Если r(x)0, то принятое кодовое слово стирается и формируется сигнал "ошибка".
на g(x), вычисление и анализ остатка r(x). Если r(x)=0, то принятое кодовое слово считается неискаженным. Если r(x)0, то принятое кодовое слово стирается и формируется сигнал "ошибка".
- при кодировании способом МККТТ декодирование основано на свойстве получения определенного контрольного остатка R0(x) при делении принятого кодового многочлена (x) на порождающий многочлен. Поэтому, если полученный при делении остаток ![]() , то принятое кодовое слово считается неискаженным. Если остаток
, то принятое кодовое слово считается неискаженным. Если остаток ![]() , то принятое кодовое слово стирается и формируется сигнал "ошибка". Значение контрольного остатка определяется из выражения
, то принятое кодовое слово стирается и формируется сигнал "ошибка". Значение контрольного остатка определяется из выражения ![]() .
.
Способы декодирования с исправлением ошибок и схемная реализация декодирующих устройств
Декодирование циклического кода в режиме исправления ошибок можно осуществлять различными способами. Ниже излагаются два способа, являющиеся наиболее простыми.
В основу первого способа положено использование таблицы синдромов (декодирования), в которой каждому многочлену или образцу ошибок ei(x), соответствует определенный синдром Si(x), представляющий остаток от деления принятого кодового слова ![]() и соответствующего ему ei(x) на g(x). Процедура декодирования следующая. Принятое кодовое слово
и соответствующего ему ei(x) на g(x). Процедура декодирования следующая. Принятое кодовое слово ![]() делится на g(x), определяется Si(x) и соответствующий ему многочлен ei(x), а затем
делится на g(x), определяется Si(x) и соответствующий ему многочлен ei(x), а затем ![]() суммируется с ei(x). В результате получаем исправленное кодовое слово, т.е.
суммируется с ei(x). В результате получаем исправленное кодовое слово, т.е. ![]() .
.
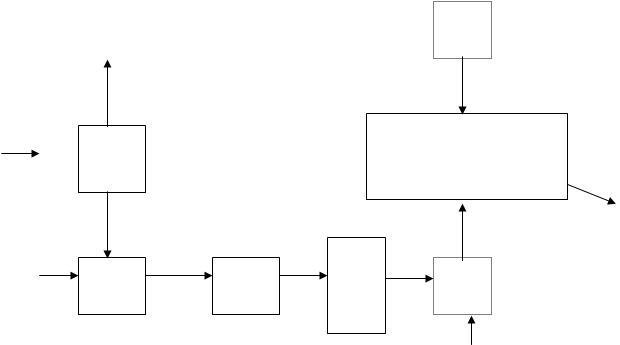
В состав декодера входят: вычислитель синдрома (ВС), два регистра сдвига RG1 и RG2, постоянное запоминающее устройство (ПЗУ), которое содержит ![]() слова длины n, соответствующие многочленам ошибок ei(x).
слова длины n, соответствующие многочленам ошибок ei(x).
Принятое кодовое слово ![]() поступает на вход вычислителя синдрома, где осуществляется деление его на g(x) и формирование Si(x), и одновременно - на вход RG2, где
поступает на вход вычислителя синдрома, где осуществляется деление его на g(x) и формирование Si(x), и одновременно - на вход RG2, где ![]() накапливается. Синдром Si(x) используется в качестве адреса, по которому из ПЗУ в регистр RG1 записывается ei(x), соответствующий синдрому Si(x). Перечисленные операции завершаются за n тактов. В течение последующих n тактов происходит поэлементное суммирование содержимого RG2 и RG1, т.е. операция
накапливается. Синдром Si(x) используется в качестве адреса, по которому из ПЗУ в регистр RG1 записывается ei(x), соответствующий синдрому Si(x). Перечисленные операции завершаются за n тактов. В течение последующих n тактов происходит поэлементное суммирование содержимого RG2 и RG1, т.е. операция ![]() , и исправление. ошибок.
, и исправление. ошибок.
В основе второго способа исправления ошибок, позволяющего значительно сократить объем используемых табличных синдромов и существенно упростить схему декодера, лежат следующие положения:
1. Синдром Si(x), соответствующий принятому кодовому слову равен остатку от деления ![]() на g(x), а также остатку от деления соответствующего многочлена ошибок ei(x) на g(x), т.е.
на g(x), а также остатку от деления соответствующего многочлена ошибок ei(x) на g(x), т.е. ![]() .
.
2. Если Si(x) соответствует ![]() и ei(x), то x( Si(x) является синдромом, который соответствует
и ei(x), то x( Si(x) является синдромом, который соответствует ![]() и
и ![]() или
или 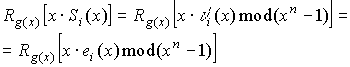 .
.
Похожие работы


... модуляцией, можно сделать вывод, что помехоустойчивость приемника, использующего в качестве информационного параметра фазу, почти приближена к вероятности ошибки приемника Котельникова. 3. Оптимальная фильтрация. Отметим, что оптимальный приемник, является корреляционным, сигнал на его выходе представляет собой функцию корреляции принимаемого и ожидаемого сигналов, благодаря чему ...
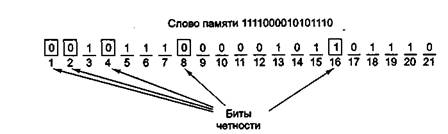
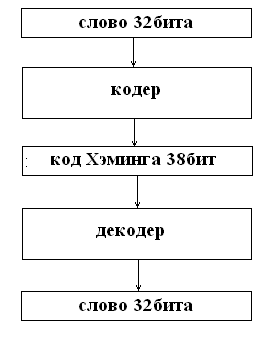
... кодирования можно разработать устройство, которое поможет понять принцип работы метода Хэмминга. Кодер – декодер будем разрабатывать на основе ИМС К555ВЖ1. 2.1 Разработка устройства кодирования информации методом Хемминга Кодер, преобразует 32х битное слово в 38ми разрядный код Хэмминга, после чего слово хранится в памяти или передаётся по шинам и т.д. В процессе передачи или хранения в ...
... и исправления ошибок в текстах на естественных языках (назовем их автокорректорами - АК, хотя терминология ещё не сложилась) получают все большее распространение. Они используются, в частности, в пакетах WINWORD и EXCEL для проверки орфографии текстовой информации. Говоря точнее, АК производят автоматически лишь обнаружение ошибок, а собственно коррекция ведется обычно при участии человека. 1. ...
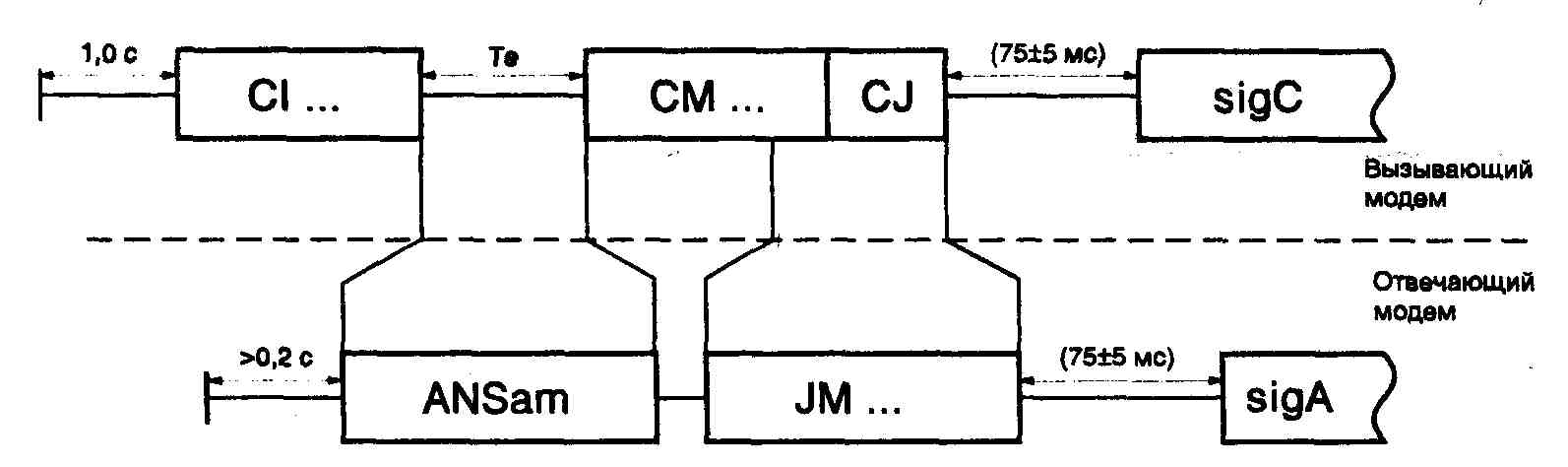
... ITU-T серии V, реализованный в обоих модемах. На этом этапе соединение устанавливается согласно Рекомендациям V.25 и V.8. Если оба модема поддерживают протокол V.34, то они переходят ко второй фазе, в ходе которой производится классификация канала связи. В течение 3 и 4 фазы происходит обучение адаптивного эквалайзера, эхокомпен-сатора и ряда других систем модема. После установления соединения ...
0 комментариев