Статистичні гіпотези та їх перевірка
Про перевагу тієї або іншої з порівнюваних груп судять, як правило, з різниці між середніми, середніми частками або іншими вибірковими показниками — величинами випадковими і такими, що є статистичними оцінками відповідних генеральних показників.
Питання про достовірність відмінностей розв'язується зазвичай на основі перевірки за вибірковими характеристиками тієї або іншої статистичної гіпотези.
В області клінічних досліджень широке використання отримала так звана нульова гіпотеза Н0 . Значення її зводиться до припущення, що різниця між генеральними параметрами порівнюваних груп дорівнює нулю і відмінності, що спостерігаються між вибірковими характеристиками, носять виключно випадковий характер.
Так, наприклад, якщо одна вибірка була вилучена з нормального розподілу генеральної сукупності з параметрами М1 і a1, а інша — з сукупності з параметрами M2 і а2, то нульова гіпотеза полягає в тому, що Ml = M2, тобто М1 — M2 = 0. Протилежна нульовій – альтернативна гіпотеза – полягає в тому, що середні вважаються або просто нерівними М1—M2≠0 (двосторонній тест), або дослідник орієнтований у напрямі ефекту одного методу над іншим, а можливість переваги іншого виключається, наприклад М1>M2 (односторонній тест).
При такому підході не ставиться задача кількісної оцінки наявних відмінностей, достатньо лише перевірити, чи належать обидві групи з певною імовірністю до різних генеральних сукупностей. Слід зазначити, що під час вирішення інших статистичних задач нульова гіпотеза матиме інше формулювання.
Перевіряється статистична гіпотеза за допомогою величин або, іншими словами, статистик, функції розподілу яких відомі і табульовані (наприклад,
t-розподіл Стьюдента, розподіл Хі-квадрат та ін.).
Ці величини у кожному конкретному випадку дозволяють виявити, чи задовольняють вибіркові показники висунутій гіпотезі. Процедура перевірки гіпотези була пов'язана з об'ємом вибірки (або відповідним числом ступенів свободи) і рівнем значущості а. Рівень значущості або вірогідність помилки I роду, що допускається під час оцінювання прийнятої гіпотези, може розрізнятися (5, 1, 0,1%), але в медико-біологічних додатках, якщо спеціально не обумовлено інше значення, він зазвичай приймається рівним 5%.
Якщо результати значущі на рівні 1—5%, зазвичай говорять про наявність статистичної значущості, на рівні менше 1% – про високу статистичну значущість.
З рівнем значущості була пов'язана величина, названа ступенем недовіри до нульової гіпотези. Вона є величиною, що доповнює рівень значущості до одиниці (1-а).
Близький до нуля рівень значущості, а отже, близький до одиниці ступінь недовіри інтерпретуються як вагомий довід проти нульової гіпотези. Близький до одиниці рівень значущості показує, що ступінь недовіри близький до нуля, тобто доводи проти Н0 слабкі, що вказує на узгодженість наявних даних з нульовою гіпотезою.
Важливим є також питання про справедливість нульової гіпотези. Для оцінки справедливості Н0 розраховується р-значення. Можна сказати, що воно оцінює імовірність при багатократному повторенні дослідження отримання такого ж або ще більш екстремального значення критерію за умови справедливості нульової гіпотези, тобто за відсутності відмінностей між порівнюваними групами.
Якщо в результаті перевірки нульової гіпотези вона була знехтувана на рівні значущості а, то для відображення наявності статистично значущих відмінностей результат порівняння може бути записаний у вигляді р<а. Це означає, що при справедливості нульової гіпотези помилка порівняння можлива не більш, ніж в а•100% випадків, а отже, малоймовірна.
Проте запис вигляду Р<0,05, що часто використовується, означає лише те, що рівень значущості результатів не більше, ніж 5%. Набагато більше інформації про ступінь значущості полягатиме, наприклад, у записі подвійної нерівності 0,01 < р < 0,05.
Р-значення може задаватися не тільки нерівністю. Його значення можна розрахувати точно, і ця процедура є в деякому розумінні зворотною до звичайної процедури перевірки гіпотези.
Для цього розраховується величина тестової статистики, а потім, наприклад, за таблицями, що відносяться до даного критерію (або в результаті підстановки значення статистики критерію в її функцію розподілу) визначається рівень імовірності, відповідний оціненому значенню тестової статистики.
При такій процедурі, приймаючи рішення відкинути (прийняти) гіпотезу Н0, ми вказуємо точне значення рівня, яке дорівнює p-значенню, на якому відбувається відхилення (прийняття) нульової гіпотези. Вказівка точного p-значення є більш інформативною, ніж оформлення результатів перевірки гіпотези у вигляді нерівності типу р < а.
Як зазначалося, частіше за все в області клінічних досліджень перевіряються гіпотези про статистичну значимість відмінностей, проте потрібно мати на увазі, що у статистиці існують й інші варіанти, наприклад, гіпотези про згоду (або форми) розподілів, гіпотези про значущість кореляції, гіпотези про величину параметрів розподілу тощо.
Незалежно від конкретного формулювання гіпотези, можна дати стислий опис типових етапів процедури перевірки статистичних гіпотез. Дані дії лежать в основі всіх статистичних перевірок:
• вибрати рівень значимості а;
• сформулювати нульову гіпотезу (зазвичай як висновок, який хотілося б відкинути) Н0 і обов'язково відповідну їй альтернативну гіпотезу НА;
• вибрати тестову статистику або, іншими словами, відповідний критерій для перевірки сформульованої гіпотези;
• обчислити значення тестової статистики за наявними даними;
• визначити за допомогою розподілу тестової статистики або зазвичай за наявними таблицями її розподілу критичну область, імовірність потрапляння в яку при справедливості нульової гіпотези дорівнює а;
• зробити висновок, порівнявши розраховане значення статистики з вибраним критичним значенням. Якщо отримане значення статистики лежить у критичній області, то слід відхиляти нульову гіпотезу і прийняти альтернативну. В протилежному випадку приймається нульова гіпотеза.
При цьому важлива правильна інтерпретація отриманих результатів перевірки гіпотези. Те, що значення критерію вийшло незначущим, не є чітким доказом справедливості нульової гіпотези.
Це означає лише, що наявні дані їй не суперечать. Не можна забувати, що, перевіряючи статистичну гіпотезу, ми маємо справу лише з обмеженою вибіркою з генеральної сукупності. Тому всі висновки, що робляться під час перевірки статистичних гіпотез, носять характер імовірності. От чому значення імовірності помилок I і II роду мають таке велике значення для цієї процедури.
Для перевірки гіпотез у біометрії можливі 2 види критеріїв: параметричні (побудовані на підставі параметрів даної сукупності) і непараметричні (побудовані безпосередньо за варіантами даної сукупності та їх частотами).
Перші служать для перевірки гіпотез про параметри сукупності, розподілені за відомим законом (зазвичай в біометрії за нормальним законом), інші – для перевірки гіпотез незалежно від форми розподілу сукупностей. Так, при нормальному розподілі ознаки параметричні критерії мають більшу потужність, ніж непараметричні, тому якщо відомо, що порівнювані вибірки були взяті з нормально розподілених сукупностей, перевагу слід віддавати параметричним критеріям.
У разі дуже великих відмінностей розподілу ознаки від нормального закону, при малих об'ємах вибірки, а також для аналізу порядкових даних слід застосовувати непараметричні критерії. Якщо варіюючи ознаки виражаються не числами, а умовними знаками, використання непараметричних критеріїв виявляється єдино можливим.
Перевірити, чи була взята дана вибірка з нормально розподіленої сукупності в свою чергу можна за допомогою спеціальних статистичних тестів, наприклад, за допомогою коефіцієнтів асиметрії та ексцесу. На практиці для перевірки нормальності розподілу частіше за все використовується критерій Хі-квадрат.
Розглянемо схему перевірки даного критерію. Для проведення розрахунків за цим критерієм потрібно вміти будувати вибірковий розподіл випадкової величини.
Для цього отримані в ході дослідження результати потрібно подавати у вигляді варіаційного ряду, або ряду розподілу. Варіаційний ряд є подвійним рядом чисел, що показує для кожного значення ознаки (варіанти), скільки разів воно (вона) зустрічається в даній сукупності (частота варіанти). Це визначення більшою мірою відноситься до так званого безінтервального варіаційного ряду.
Проте, якщо загальну варіацію ознаки (в межах від мінімальної до максимальної варіанти) розбити на проміжки (класи) і підрахувати частоту потрапляння варіант даної сукупності в ці інтервали, отримаємо інтервальний варіаційний ряд.
Графічно варіаційні ряди можуть бути подані у вигляді полігонів розподілу для безінтервальних рядів і гістограм розподілу частот для інтервальних рядів.
Даний критерій погодження ефективний за умови наявності не менше 50 елементів у вибірці. В підручниках часто говориться, що для успішного використання критерію Хі-квадрат найменша частота в інтервалах варіаційного ряду має бути рівною 5.
Якщо ж в якому-небудь інтервалі варіаційного ряду міститься менше 5 частот, то цей клас рекомендують об'єднати з сусіднім класом. Проте, згідно з грунтовними дослідженнями У. Кокрена, така умова є надмірно обмежувальною, і для розподілів, які широко використовуються, достатньо вимагати, щоб частоти були не менше 1.
Загальна формула цього критерію має вигляд:
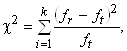
де ![]() — число класів,
— число класів,![]() — фактичні частоти, оцінені за вибіркою, що вивчається,
— фактичні частоти, оцінені за вибіркою, що вивчається, ![]() — частоти, розраховані за теоретичним розподілом (рис. 1).
— частоти, розраховані за теоретичним розподілом (рис. 1).
А нульова гіпотеза в даному випадку полягає в припущенні, що відмінності між спостережуваними і теоретичними частотами носять винятково випадковий характер.
Треба попередити, що критерій погодження Хі-квадрат може застосовуватися для перевірки відповідності вибіркового розподілу будь-якого теоретичного, а не тільки нормального розподілу. Можна навіть сказати, що цей критерій визначає міру розбіжності між даними і моделлю, обраною для їх опису.
По осі абсцис – класи варіаційного ряду; по осі ординат – частоти потрапляння значень змінної у відповідні класи. Темні стовпчики – теоретичний нормальний розподіл частот, світлі – вибірковий.
Для оцінки отриманої величини Хі-квадрат необхідно знати кількість ступенів свободи, що саме і залежить від того, який тип теоретичного розподілу бере участь у розрахунках.
Так, при нормальному розподілі кількість ступенів свободи n=к—3, де к — число інтервалів ряду. Обчислене значення Хі-квадрат не повинне перевищувати табличне при заданих значеннях р і а, тоді ми маємо право зробити висновок про неістотну відмінність теоретичного та емпіричного розподілів.
При повному збігу емпіричних частот з обчисленими значення Хі-квадрат дорівнювало б 0.
Побудова рядів розподілу — один з можливих способів опису отриманих даних. А середнє арифметичне і дисперсія — одні з основних характеристик варіюючих об'єктів.
Проте треба мати на увазі, що ці характеристики не є універсальними; для статистичного опису даних як узагальнюючі характеристики сукупності корисними (особливо, якщо сукупність не була розподілена за нормальним законом) можуть виявитися і так звані структурні показники.
На практиці часто використовують такі структурні показники, як медіана, мода, квантилі (квартилі, децилі, перцентилі), мінімальне значення, максимальне значення, розмах варіації й інші.
Так, медіана визначається як середня, щодо якої ряд розподілу поділяється на 2 рівні частини: в обидва боки від медіани розташовується однакова кількість варіант.
Вище, не даючи точного визначення, ми вже говорили про закон розподілу випадкових величин, описуючи в медичних додатках нормальний розподіл, що часто зустрічається.
Проте хотілося б ще раз підкреслити, що це зовсім не єдиний відомий тип розподілу. Крім того, говорячи про побудову вибіркової гістограми розподілу і перевірку нормальності розподілу за допомогою критерію погодження, ми також торкалися теми побудови вибіркової щільності розподілу випадкової величини. Дамо тепер формальне визначення.
Функція F(x), що пов'язує значення xt змінної випадкової величини X з їх імовірністю ph, називається законом розподілу (або функцією розподілу) цієї випадкової величини.
Таким чином, закон розподілу, або його ще називають інтегральною функцією розподілу, описує розподіл імовірності випадкової змінної X. Закон розподілу можна задати у вигляді таблиці, побудувати у вигляді графіка або описати відповідною формулою.
Значення функції F(x) в точці х дорівнює імовірності Р (Х<х) того, що дана випадкова величина X приймає значення менші і рівні даному значенню х.
Така функція дуже зручна для наочного і короткого подання розподілу імовірності випадкових змінних незалежно від їх характеру. Інтегральна функція розподілу відповідає експериментальній кривій накопичення частот.
Наприклад, нехай деяка випадкова величина X може приймати значення тільки на відрізку числової осі від хх до х2. Тоді вірогідність того, що випадкова величина приймає значення менше х1 або більше х2, дорівнює нулю.
Вірогідність того, що випадкова величина приймає значення менше або рівне х2, дорівнює одиниці. А для всіх значень х, що належать відрізку [х1,х2], функція F(x) є неспадаючою, що змінює свої значення від нуля до одиниці.
З поняттям закону розподілу випадкової величини нерозривно пов'язане поняття щільності розподілу. Так, щільність розподілу безперервної випадкової величини можна уявити як граничну криву р(х), яка апроксимуватиме вибіркову гістограму розподілу даної випадкової величини при нескінченному збільшенні об'єму вибірки (рис. 2).
Формально щільність розподілу р(х) є похідною відповідної функції розподілу F(x).
Визначимо імовірність події, яка полягає в тому, що одне випадково взяте спостереження X потрапить в інтервал [ха,хв], така імовірність чисельно дорівнює площі криволінійної трапеції під кривою р(х) в інтервалі від ха до хв.
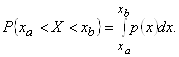
Оскільки функція розподілу визначається як імовірність, вона може приймати значення в інтервалі від 0 до 1.
Інша важлива властивість – інтеграл щільності розподілу, взятий по всій області можливих значень (або, не обмежуючи спільності, інтеграл від - до + нескінченності), дорівнює 1.
Нормальний розподіл відіграє дуже важливу роль у статистиці, проте він не є єдиним відомим розподілом. Так, під час перевірки статистичних гіпотез часто використовуються ще 3 типи розподілів, пов'язані з нормальним:
-розподіл Фішера;
-розподіл Хі-квадрат;
-розподіл Стьюдента.
Ці розподіли табульовані, і відповідні таблиці наведені в різних підручниках зі статистики.
Далі ми наводимо короткі відомості про деякі інші закони розподілу дискретних і безперервних випадкових величин, які також можуть зустрітися в реальних додатках.
Криві цієї щільності розподілу були наведені на рис. 3. Для кожного типу розподілу за допомогою критерію Хі-квадрат може бути перевірена гіпотеза про те, що ваша вибірка була розподілена саме за цим законом.
Похожие работы
... . 6 Порівняння вибіркової середньої з гіпотетичною генеральною середньою нормальної сукупності (при відомій генеральній дисперсії) Нехай генеральна сукупність розподілена нормально з дисперсією , причому невідома генеральна середня приблизно дорівнює значенню . Потрібно по вибірковій середній , що отримано з вибірки обсягом , при заданому рівні значущості перевірити нульову гіпотезу : ...
... ння і навички, які пов'язані з майбутньою навчальною діяльністю. Попередня діагностика потрібна для визначення прирощення навченості студента за певний період часу. Поточне оцінювання — це систематична перевірка і оцінювання освітніх результатів студента з конкретних тем та на окремих заняттях. До поточного оцінювання належать: опитування; використання тестів; розв'язування задач; робота з комп' ...
... ідних груп банків з метою забезпечення достовірності подальших статистичних досліджень. Розділ 2 2.1 Оцінка однорідності статистичної сокупності комерційних банків за допомогою показників їх діяльності Перевіримо однорідність досліджуваної сукупності за допомогою розрахунків показників варіації: Вибіркове середнє визначаємо за формулою середньої арифметичної зваженої: Дисперс ...
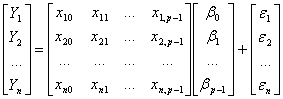


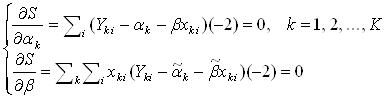
... Запорізька, Луганська та Харківська. Тенденції росту захворюваності в цих областях мають лінійну залежність , (k = 1, 2, 3, 4 відповідно областям, i = 1, 2,…,16). Рис 3.1.3. Тенденції росту захворюваності в областях південної України F = 2,495 < F0,05;3;56 = 2,77, тобто гіпотеза H0: β1= β2 = β3 = β4 не відхиляється – тенденція росту в цих областях однакова. Рис ...
0 комментариев