Содержание
Введение
1. Задача унификации 2. Преобразование выражения в префиксную форму 3. Определение классов для реализации алгоритма 4. Операции класса Lisp_item 4.1 Операция выполнения унификации (unifikacia) 4.2 Операция проверки применимости продукций(Primen_prod) 4.3 Операция замены свободных переменных (zamena) 5. Операции класса podst 5.1 Операция проверки применимости (primenima) 6. Операции класса trojka 6.1 Операция проверки применимости (primenima) ВыводыЛитература
Введение
Тема курсовой работы по дисциплине "Проектирование интеллектуальных систем" - "Унификация алгебраических выражений".
Целью изучения дисциплины является подготовка специалистов в области автоматизации сложноформализуемых задач. Задачей изучения дисциплины является приобретение знаний о фундаментальных алгоритмах, применяемых при построении систем искусственного интеллекта, а также методов разработки программных приложений, реализующих эти системы.
Принципиальное отличие интеллектуальных систем от любых других систем автоматизации заключается в наличии базы знаний о предметной среде, в которой решается задача. Неинтеллектуальная система при отсутствии каких-либо входных данных прекращает решение задачи, интеллектуальная же система недостающие данные извлекает из базы знаний и решение выполняет.
По А. Н. Колмогорову, любая материальная система, с которой можно достаточно долго обсуждать проблемы науки, литературы и искусства, обладает интеллектом. Такое определение показывает, что данная дисциплина находится во взаимосвязи практически со всеми учебными дисциплинами. Тем не менее, следует подчеркнуть связи со следующими дисциплинами: "Программирование", "Математический анализ", "Линейная алгебра и аналитическая геометрия", "Дискретная математика", "Логическое программирование", "Экспертные системы", "Интерфейсы интеллектуальных систем".
1. Задача унификации
Формально задача записывается следующим образом: для данной теоремы Т в форме продукции вида
Н Þ С,
где Н – гипотеза;
С – заключение, и некоторого выражения Е необходимо проверить, можно ли сделать Н и Е полностью идентичными путем последовательных подстановок свободных переменных в Е. Если выражение Е с помощью подстановок свободных переменных удается привести к виду Н, то Е можно заменить выражением С. После этого в выражении С свободные переменные заменяют соответствующими им фрагментами из выражения Е.
Например, для продукции (теоремы) (a + b)2 = a2 + 2ab + b2 исходное выражение x2 + (y + √3)2 с помощью свободных переменных a = y и b = √3 можно преобразовать к виду x2 + (a + b)2. Фрагмент выражения (a + b)2 полностью совпадает с левой частью продукции, следовательно вместо него можно подставить правую часть продукции. В результате будет получено выражение x2 + a2 + 2ab + b2. Для завершения преобразования необходимо свободные переменные a и b заменить соответствующими им фрагментами выражения Е. окончательно будет получено: x2 + y2 + 2y√3 + (√3)2 .
Фундаментальная идея алгоритма связана с процедурой просмотра выражения: вначале делается попытка применить какую-либо продукцию ко всему выражению; если не удается применить ни одну продукцию, выбирается фрагмент выражения и проверяется применимость продукций к этому фрагменту и т.д.. Выполнение процедуры унификации прекращается, когда уже никакая продукция не может быть применена ни к какому подвыражению. Для изучения или разработки алгоритма унификации удобно представлять выражение и продукции в виде деревьев. Для приведенного выше примера деревья продукций и выражения будут иметь вид:
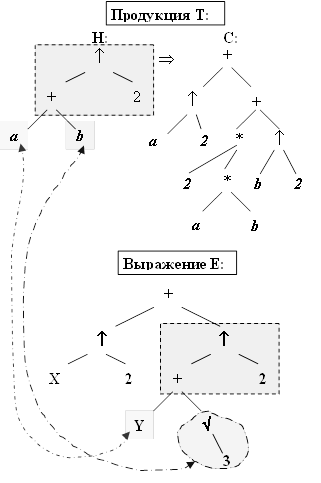
Рисунок 1 -Представление продукции и выражения в виде дерева ( -символ операции возведения в степень)
На рисунке одинаковыми цветными прямоугольниками выделены совпадающие фрагменты деревьев продукции и выражения; штрихпунктирными линиями – соответствие между свободными переменными и фрагментами дерева выражения.
Алгоритм унификации выполняет обход дерева выражения, начиная с корня дерева. Для очередного узла дерева выполняются следующие действия:
- выполняется проверка на совпадение операции из узла дерева выражения Е с операцией в корне левой части очередной продукции Т. Если совпадают, то выполняется переход к следующему шагу. В противном случае, по окончании просмотра всех продукций, выполняется переход к следующему узлу дерева выражения Е;
- если в левой части продукции операндами операции являются переменные, то им сопоставляются ветви дерева выражения Е, отходящие от узла с совпавшей операцией (так, как показано на рисунке);
- фрагмент дерева выражения Е, соответствующий левой части продукции, заменяется деревом из правой части продукции (см. рисунок 2);

Рисунок 2 -Выражение Е после замены фрагмента на правую часть выражения
- в полученном дереве выражения Е выполняется замена свободных переменных сопоставленными фрагментами исходного дерева (см. рисунок 3).
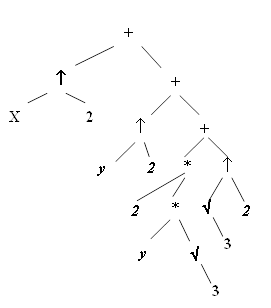
Рисунок 3 -Выражение Е после замены свободных переменных соответствующими фрагментами
Таким образом, выполнение унификации предполагает построение дерева выражения. В наибольшей степени заданию выражения в форме дерева соответствует префиксная форма записи. Например, рассмотренные выше продукция и выражение в префиксной форме будут иметь следующий вид:
( (+ a b ) 2) => (+ ( a 2) (+ (* 2 (* a b)) ( b 2)) );
(+ ( x 2) ( (+ y (√ 3)) 2)).
В каждой скобке присутствуют два или три элемента: знак операции или имя функции и один или два операнда. Операции соответствуют узлам дерева, а операнды – ветвям дерева. Такая фиксированная структура упрощает построение алгоритма унификации, но требует введения алгоритма преобразования выражения, заданного в инфиксной записи, в префиксную форму записи.
2. Преобразование выражения в префиксную форму
Это преобразование является частным случаем задачи трансляции выражений. Неформальное определение алгоритма заключается в следующем.
Алгоритмом используется два стека: стек операндов и стек операций. Строка с выражением сканируется слева направо. Если очередным элементом выражения является операнд – константа или переменная, - то он безусловно заносится в стек операндов. Если очередной элемент выражения открывающая скобка, то она безусловно заносится в стек операций. Закрывающая скобка вызывает действия, задаваемые в третьей строке таблицы.
Если очередной элемент выражения операция или скобка, то действия определяются в зависимости от соотношения приоритетов данной операции и операции на вершине стека операций (таблица 1). Обозначения: Op(E) – очередная операция из выражения Е; Op(stack) – операция на вершине стека операций. Значения приоритетов и количество операндов в операциях определяются с помощью справочника операций. Соблюдаются следующие соглашения о приоритетах:
- приоритет открывающей скобки из выражения выше приоритета любой операции на вершине стека;
- приоритет любой операции из выражения выше приоритета открывающей скобки на вершине стека операций;
- приоритет любой операции на вершине стека выше приоритета закрывающей скобки из выражения.
Таблица 1 - Связь между соотношением приоритетов операций и действиями алгоритма
| Op(E) Ä Op(stack) | Описание действий |
| > | 1)Op(E) занести в стек операций; 2)перейти к следующему элементу выражения Е |
| = | 1)сформировать тройку: - операция - с вершины стека операций; - один или два операнда - с вершины стека операндов; 2)ссылку на тройку поместить на вершину стека операндов; 3)Op(E) занести в стек операций; 4)перейти к следующему элементу выражения Е |
| < | 1)сформировать тройку: - операция - с вершины стека операций; - один или два операнда - с вершины стека операндов; 2)ссылку на тройку поместить на вершину стека операндов; 3)снова провести сравнение приоритетов и выбрать действие в соответствии с таблицей. |
Если очередной символ в выражении закрывающая скобка, а на вершине стека операций открывающая скобка, то удалить открывающую скобку из стека и перейти к следующему символу в выражении.
Работа алгоритма заканчивается, если при очередном обращении стек операций оказывается пустым. На вершине стека операндов будет находиться ссылка на выражение в префиксной форме.
Действия алгоритма иллюстрируются таблицей, в которой отображаются состояния стеков и другая информация после выполнения алгоритмом очередного шага для выражения a+b+c/(m-d). Символ $ используется как признак конца(дна) стека или входной строки.
Таблица 2 - Состояния основных структур алгоритма
| Стек операций | Стек операндов | Символ входной строки | Соотно-шение приори-тетов | Описание |
| $ | $ | a | ||
| $ | $a | + | > | |
| $+ | $a | b | ||
| $+ | $ab | + | = | Выделение тройки: (+ a b) |
| $+ | $(+ a b) | c | ||
| $+ | $(+ a b)c | / | > | |
| $+/ | $(+ a b)c | ( | > | |
| $+/( | $(+ a b)c | m | ||
| $+/( | $(+ a b)cm | - | > | |
| $+/(- | $(+ a b)cm | d | ||
| $+/(- | $(+ a b)cmd | ) | < | Выделение тройки: (- m d) |
| $+/( | $(+ a b)c(- m d) | ) | Удаление скобки | |
| $+/ | $(+ a b)c(- m d) | $ | < | Выделение тройки: (/ c (- m d)) |
| $+ | $(+ a b) (/ c (- m d)) | $ | < | Выделение тройки: (+ (+ a b) (/ c (- m d))) |
| $ | $(+ (+ a b) (/ c (- m d))) | $ | Конец работы |
3. Определение классов для реализации алгоритма
На рисунке 4 приведена диаграмма классов для реализации алгоритма унификации, на которой показана структура вызовов операций классов. Цифры над линиями указывают возможную последовательность вызовов. В рассматриваемой реализации алгоритма предполагается, что выражение представлено в префиксной форме. Описываться будут только те структуры данных и операции, которые связаны с принципом работы алгоритма унификации.

Рисунок 4- Диаграмма классов для алгоритма унификации
В рассматриваемом примере реализации алгоритма унификации основную структурную единицу задает класс Lisp_item. Имя класса указывает на то, что проводится аналогия с понятием символа языка LISP. Суть заключается в том, что в LISP символ может обозначать константу, переменную, список, функцию или выражение, которое можно обрабатывать. Чтобы конкретизировать, что задает экземпляр класса Lisp_item, в его состав вводится атрибут typ. Атрибут itm будет задавать ссылку на объект (константу, переменную или тройку – выражение, состоящее из операции и двух операндов). Причем, любой из операндов может быть экземпляром класса Lisp_item.
Таблица 3- Назначение операций класса Lisp_item
| Имя операции | Описание |
| unifikacia(ArrayList sp, ref ArrayList SV, TextBox tbox) | Выполняет унификацию данного экземпляра Lisp_item, где sp – список продукций (подстановок); SV – формируемый список свободных переменных; tbox – компонента для вывода текстовых сообщений. |
| Primen_prod(ArrayList sp, ref ArrayList SV, TextBox tbox) | Проверяет применимость к данному экземпляру класса Lisp_item продукций из заданного списка SV. Назначение остальных параметров то же, что и в предыдущем случае. |
| zamena(ArrayList SV) | Выполняет замену свободных переменных в результирующем выражении на соответствующие им фрагменты исходного выражения. SV – список свободных переменных |
Для задания продукций (подстановок), используемых для унификации выражений, применяется класс podst. В соответствии с определением продукции атрибутами класса являются left_part и right_part. При этом и левая, и правая части могут представлять произвольные выражения и задаются как объекты класса Lisp_item.
Таблица 4- Назначение операций класса podst
| Имя операции | Описание |
| primenima(Lisp_item E, ref ArrayList SV) | Определяет применимость левой части продукции к заданному выражению. Е – унифицируемое выражение; SV – формируемый список свободных переменных. |
| zamena(ArrayList SV) | Выполняет замену свободных переменных в правой части удачно примененной продукции. |
Для работы с выражением в префиксной форме предназначен класс trojka. Атрибуты этого класса предназначены для определения основных элементов и признаков выражения в префиксной форме: operation – символ операции; priority – приоритет операции; is_func – операция является функцией; op1, op2 – операнды.
Таблица 5- Назначение операций класса trojka
| Имя операции | Описание |
| primenima(Lisp_item E, ref ArrayList SV) | Определяет применимость тройки из левой части продукции к тройке заданного выражения. Е – унифицируемое выражение; SV – формируемый список свободных переменных. |
4. Операции класса Lisp_item 4.1 Операция выполнения унификации (unifikacia)
Действия данной операции определяются схемой на рисунке 5 и складываются из следующего. Вначале проверяется применимость продукций ко всему выражению.
Если удается удачно применить какую-либо продукцию из заданного списка, то выполняется выход. В противном случае, операция унификации (unifikacia) вызывается для каждого из операндов выражения.
4.2 Операция проверки применимости продукций(Primen_prod)Действия данной операции определяются схемой на рисунке 6 и складываются из следующего. Организуется цикл просмотра списка продукций.
Для очередной продукции из списка (rpod) вызывается операция проверки применимости продукции (Primenima). Если операция возвращает истинное значение, то вызывается операция замены свободных переменных в правой части продукции.
Если же ни одной продукции применить не удалось, то возвращается ложное значение.
4.3 Операция замены свободных переменных (zamena)Действия данной операции определяются схемой на рисунке 7 и складываются из следующего. Состав выполняемых действий зависит от типа обрабатываемого элемента выражения.
В случае константы никаких действий не выполняется.
В случае простой переменной выполняется ее поиск в списке свободных переменных, после чего она заменяется соответствующим фрагментом выражения. Если обрабатываемый элемент является тройкой (операция и два операнда), то данная операция замены (zamena) свободных переменных выполняется для каждого из операндов тройки.
5. Операции класса podst 5.1 Операция проверки применимости (primenima)
Действия данной операции определяются схемой на рисунке 8 и складываются из следующего. Вначале выполняется проверка соответствия типов левой части продукции и унифицируемого выражения. При несовпадении выполняется выход с возвратом значения false. При совпадении типов дальнейшие действия определяются типом левой части продукции.
Если левая часть – константа, то выполняется сравнение значений констант из левой части продукции и заданного выражения. Результат сравнения возвращается как результат выполнения операции.
Если левая часть продукции – переменная, то формируется элемент списка свободных переменных и помещается в список. Для задания элементов списка свободных переменных используется класс sv_perem, атрибутами которых являются:
nm_sv – имя свободной переменной;
fragment - фрагмент выражения, соответствующий переменной (тип Lisp_item).
Если левая часть – тройка, то выполняется выделение выражений тройки из левой части продукции и унифицируемого выражения, после чего вызывается операция класса trojka для проверки применимости тройки из продукции к тройке из выражения (primenima).
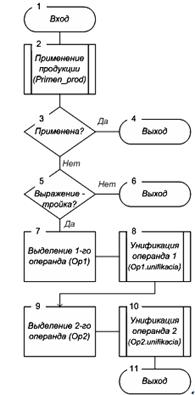
Рисунок 5 -Схема алгоритма операции Lisp_item.unifikacia
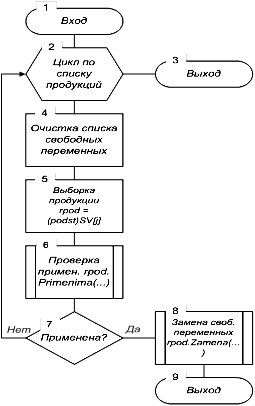
Рисунок 6 - Схема алгоритма операции Lisp_item.Primen_prod
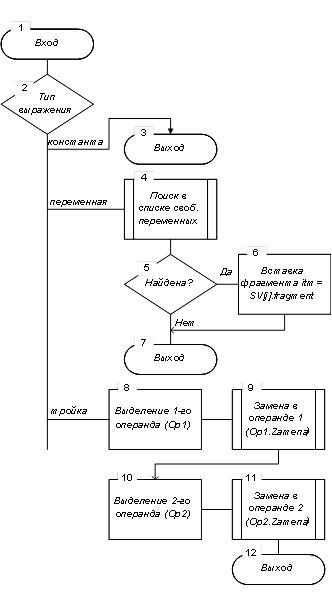
Рисунок 7 - Схема алгоритма операции Lisp_item.zamena
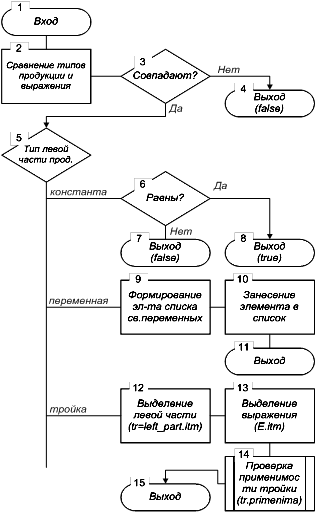
Рисунок 8 - Схема алгоритма операции podst.primenima
6. Операции класса trojka 6.1 Операция проверки применимости (primenima)
Действия данной операции определяются схемой на рисунке 9 и складываются из следующего. Тройка из продукции будет считаться удачно примененной к тройке из унифицируемого выражения, если, во-первых, совпадают операции троек; во-вторых, правила применимости выполняются для первых и вторых операндов троек.
При совпадении операций троек, анализируется тип первого операнда.
В случае константы выполняется сравнение значений констант, стоящих на месте первого операнда в сравниваемых тройках. При несовпадении – выполняется выход.
Если первый операнд переменная, то ей сопоставляется первый операнд из тройки унифицируемого выражения и заносится в список свободных переменных.
Если первый операнд тройка, то для этого объекта вызывается описываемая операция primenima. При неудачном завершении этой операции выполняется выход из операции со значением false.
Поскольку в тройке может отсутствовать второй операнд (например, функции с одним аргументом, или одноместные операции типа (not x)), то если это подтверждается, то работа операции завершается со значением true. Если же второй операнд присутствует, то прежде всего проверяется возможное условие совпадения первого и второго операндов.
Если же в тройке из продукции операнды различны, то выполняется обработка второго операнда. Алгоритм обработки аналогичен алгоритму обработки первого операнда.
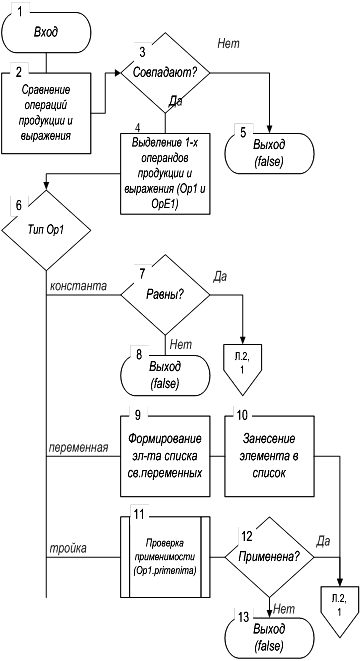
Рисунок 9, лист 1- Схема алгоритма операции trojka.primenima
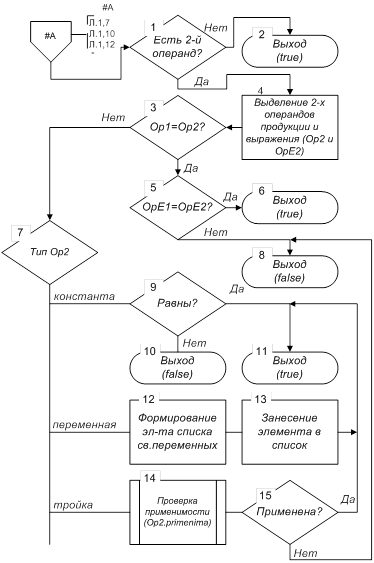
Рисунок 9, лист 2.
Выводы
Таким образом, процесс унификации выражения складывается из трех последовательно выполняемых этапов:
преобразование выражения в инфиксной форме в выражение в префиксной форме Þ унификация выражения в префиксной форме Þ преобразование результата унификации из префиксной формы в инфиксную форму.
Что касается последнего преобразования, то оно реализуется в виде несложной рекурсивной процедуры.
Литература
1. Уоссермен Ф., Нейрокомпьютерная техника, - М.,Мир, 1992.
2. Горбань А.Н. Обучение нейронных сетей. - М.: ПараГраф, 1990
3. Горбань А.Н., Россиев Д.А. Нейронные сети на персональном компьютере. - Новосибирск: Наука, 1996
4. Gilev S.E., Gorban A.N., Mirkes E.M. Several methods for accelerating the training process of neural networks in pattern recognition // Adv. Modelling & Analysis, A. AMSE Press. – 1992. – Vol.12, N4. – P.29-53
5. С. Короткий. Нейронные сети: алгоритм обратного распространения.
6. С. Короткий, Нейронные сети: обучение без учителя. Artificial Neural Networks: Concepts and Theory, IEEE Computer Society Press, 1992.
7. Заенцев И. В. Нейронные сети: основные модели./Учебное пособие к курсу "Нейронные сети" для студентов 5 курса магистратуры к. электроники физического ф-та Воронежского Государственного университета – e-mail: ivz@ivz.vrn.ru
8. Лорьер Ж.Л. Системы искусственного интеллекта. – М.: Мир, 1991. – 568 с.
9. Искусственный интеллект. – В 3-х кн. Кн. 2. Модели и методы: Справочник/ Под ред. Поспелова Д. А. – М.: Радио и связь, 1990. – 304 с.
10. Бек Л. Введение в системное программирование.- М.: Мир, 1988.
11. Шлеер С., Меллор С. Объектно-ориентированный анализ: моделирование мира в состояниях. – К.: Диалектика, 1993. – 240 с.
12. Буч Г. Объектно-ориентированный анализ и проектирование с примерами приложений на С++. - http://www.nexus.odessa.ua/files/books/booch.
13. Аджиев В. MS: корпоративная культура разработки ПО – http:// www.osp.ru
14. Трофимов С.А. Case-технологии. Практическая работа в Rational Rose. – М.: ЗАО "Издательство БИНОМ", 2001.
15. Новичков А. Эффективная разработка программного обеспечения с использованием технологий и инструментов компании RATIONAL. – http://www.interface.ru
16. Selic B., Rumbaugh J. Использование UML при моделировании сложных систем реального времени. - http://www.interface.ru.
Похожие работы
... . В частности: (8) Из (7) и (8) следует, что в M нет двух неравных натуральных чисел. Доказательство закончено. 3.2 Рекурсия Особое место для систем функционального программирования приобретает рекурсия, поскольку она позволяет учитывать значения функции на предыдущих шагах. С теоретической точки зрения рекурсивные определения являются теоретической основой всей современной ...
... порядка рис.7,б, которая хуже схемы рис.7,а по характеристикам быстродействия и сложности. Ухудшение характеристик оправдывается только возможностью реализации схемы на заданных стандартных элементах. 8. Комбинационные схемы Логическая схема (рис.8) с n входами и k выходами реализует систему переключательных функций y0 ...yk-1. Каждая функция yi(x0 ...xk-1) однозначно соответствует ...
... . Реакции узлов более высокого уровня менее зависят от позиции и более устойчивы к искажениям. Структура Неокогнитрон имеет иерархическую структуру, ориентированную на моделирование зрительной системы человека. Он состоит из последовательности обрабатывающих слоев, организованных в иерархическую структуру (рис. 10.8). Входной образ подается на первый слой и передается через плоскости, ...
... индексного параметрического метода расчета сравнительной полезности и экономичности продукции. 4. Концепция теории экономико-технологического развития Предлагаемая теория является нормативной, предусматривающей выбор таких значений разнородных параметров процесса развития производства, которые обеспечат достижение численно заданного норматива сравнительной эффективности и конкурентности ...
0 комментариев