Навигация
Проблемы компьютерного анализа текста
46708
знаков
0
таблиц
1
изображение
2.2 Проблемы компьютерного анализа текста
Компьютерный анализ текста на естественном языке активно развивается в последние годы многими коллективами. Доступные сегодня вычислительные мощности позволяют применять для обработки больших массивов документов широкий класс математических методов, способствующих эффективному решению задач поиска, классификации, кластерного анализа, выявления скрытых закономерностей в данных.
К сожалению, внедрение математических методов в обработку текста происходит в то время, когда собственно лингвистическая составляющая алгоритмов представлена явно недостаточно, и это не позволяет достичь высокого качества работы прикладных систем. Устойчивый уклон в область статистических методов анализа привел к тому, что компьютерная лингвистика оказалась невостребованной. В самом деле, во всех известных русскоязычных системах подобного класса из лингвистического обеспечения используется лишь морфологический словарь, позволяющий отождествлять различные словоформы, тогда как алгоритмы синтаксического анализа реализованы исключительно в автоматических переводчиках и вызывают множество нареканий в связи с невысокой точностью.
Поговорим о проблемах компьютерной лингвистики, касающихся, прежде всего грамматического разбора текста на естественном языке. Создание качественного синтаксического анализатора позволяет надеяться на эффективное решение задачи поиска в информации на естественном языке.
Сложность практической реализации приемлемого анализатора текста обусловлена наличием тесной связи между синтаксисом и надъязыковой семантикой. Для решения проблем (называемых синтаксической омонимией) необходимо создание специального толково-комбинаторного словаря, включающего в себя синтаксическую и семантическую информацию о сочетаемости слов.
Формально целью синтаксического разбора является построение дерева зависимостей между словами во фразе. В случае удачи предложение сворачивается в полносвязное дерево с единственной корневой вершиной. Поскольку одна словоформа может соответствовать нескольким грамматическим формам слова, в том числе для различных слов (например, "стали" у существительного "сталь" и глагола "стать"), в ходе анализа необходимо производить свертку предложения для всех возможных вариантов. Те же из них, которые приводят к максимальной свертке фразы (с минимальным числом висячих вершин), предлагается считать наиболее достоверными при разборе предложения.
Порядок применения правил разбора управляется его алгоритмом, который на каждом шаге проверяет возможность применения следующего правила к очередному фрагменту фразы (двум-трем словам, знакам препинания). В случае удачи фрагмент сворачивается. Обычно это приводит к его замене одним главным словом, т. е. удалением подчиненных слов. После чего разбор продолжается. Если дальнейшее применение правил невозможно, на любом из шагов совершается откат. При этом последний свернутый фрагмент восстанавливается, и предпринимается попытка применить другие правила. Окончательным вариантом разбора следует считать такую последовательность применения правил, которая приводит к максимальной свертке предложения.
Так как процессу разбора соответствует целое дерево вариантов свертки фразы, то производительность алгоритма падает экспоненциально с ростом числа используемых правил и количества слов в предложении. Сложные предложения могут порождать тысячи вариантов разбора, ввиду чего на практике приходится ограничивать допустимое число рассматриваемых вариантов.
Наиболее просто решается проблема выделения в тексте именных групп - устойчивых словосочетаний, состоящих из существительных и связанных с ними прилагательных, например "развитие сельского хозяйства". Такие группы характеризуют содержание текста и служат для тематического индексирования, автоматической рубрикации, уточнения запроса при поиске.
В ходе полного синтаксического разбора фразы возможно установление синтаксических ролей именных групп в предложении. Это позволяет ранжировать их по степени значимости для автора, что соответствует пониманию ключевых идей текста. Наиболее важными являются слова из группы подлежащего, затем сказуемого, прямого дополнения, косвенного дополнения, обстоятельства - таковы особенности русского языка.
Смысловая связь между понятиями предложения в общем случае может быть описана глаголом-предикатом, аргументами которого выступают данные понятия. Установление таких синтактико-семантических связей позволяет сформировать логическую схему ситуации, описываемой во фразе.
Однако для этого требуется словарь моделей управления глаголов. В таком словаре для всех глаголов (около 20 тыс. в русском языке) должно быть указано, какими падежами и с какими предлогами производится это управление.
Вершиной компьютерного анализа текста является автоматическое реферирование. Наличие семантической сети понятий, соединенных глаголами, позволяет сформулировать основные идеи текста документа, отраженные в часто встречающихся понятиях и связях, в виде простых предложений.
Словарь моделей управления и семантической сети с дифференцированными связями значительно облегчает подобный синтез. Отдельной проблемой является выбор оптимального порядка фраз. Возможно, при этом будет полезно знание коммуникативной структуры текста - иерархии тем и рем, которая отражает логику изложения автором материала. Задача тема-рематического анализа решается в ходе синтаксического разбора фразы: понятия из группы подлежащего представляют темы; понятия-дополнения глагола - ремы, которые могут стать темами последующих фраз; обстоятельства - лишь некий фон, на котором развертываются описываемые события.
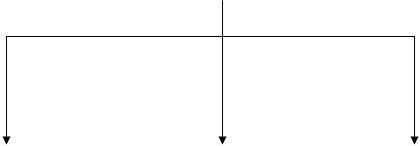
Общая схема подобного анализа текста приведена на рисунке.

Общая схема синтаксического анализа текста в информационно-поисковой системе
В заключение хотелось бы отметить, что, несмотря на ограниченность синтаксических анализаторов, работающих пока без привлечения семантики, их применение уже сейчас открывает качественно новые возможности для систем компьютерного анализа текста. Синтаксический анализатор русского языка, реализующий выделение именных групп и снятие омонимии, уже внедряется в поисковые системы.
Похожие работы
... помощи или способом манипулирования “значимыми другими”. 3. Исследовательская деятельность проводилась с целью выявления индивидуально-психологических особенностей личности суицидентов, а так же особенности ситуаций, которые могли оказать влияние на состояние индивидов в предсуицидный период. В ходе анализа были выявлены следующие особенности личности суицидента: Сужение когнитивной сферы. - ...
... . Таким образом предлагается рассматривать компьютерную технологию обучения как основную составляющую информационной технологий обучения. 1.2 Дидактические принципы, свойства и особенности использования компьютерных технологий в педагогическом процессе Применение средств КТ в современном образовании основано на дидактических принципах, свойствах и особенностях их использования. Под ...



... распространением на территории России глобальной сети Интернет. Так же необходимо осуществить следующие организационные и правовые меры: - по подбору в подразделения, занимающиеся расследованием преступлений в сфере компьютерной информации только специалистов имеющих исчерпывающие знания в данной области и дальнейшее постоянное и динамичное повышение их квалификации; - закрепить, в рамках ...
... знаний и Интернет-технологии. Каждая из этих технологий лежит в основе конкретных психодиагностических задач, которые и определяют ключевые направления работ в области компьютерной психодиагностики [15]: 1. Конструирование психодиагностических методик в рамках традиционной психометрической парадигмы на основе технологии анализа данных, в рамках психосемантического подхода на основе субъектной ...
0 комментариев