Навигация
Выбор числа корректирующих разрядов производится из соотношения
67921
знак
3
таблицы
20
изображений
1. Выбор числа корректирующих разрядов производится из соотношения
![]()
или
![]()
2. Выбор образующего многочлена производят, исходя из следующих соображений: для обнаружения трехкратной ошибки
![]()
поэтому степень образующего многочлена не может быть меньше четырех; многочлен третьей степени, имеющий •число ненулевых членов больше или равное трем, позволяет обнаруживать все двойные ошибки, многочлен первой степени ![]() обнаруживает любое количество нечетных ошибок, следовательно, многочлен четвертой степени, получаемый в результате умножения этих многочленов, обладает их корректирующими свойствами: может обнаруживать две ошибки, а также одну и три, т. е. все трехкратные ошибки.
обнаруживает любое количество нечетных ошибок, следовательно, многочлен четвертой степени, получаемый в результате умножения этих многочленов, обладает их корректирующими свойствами: может обнаруживать две ошибки, а также одну и три, т. е. все трехкратные ошибки.
3. Построение образующей матрицы производят либо нахождением остатков от деления единицы с нулями на образующий многочлен, либо умножением строк единичной матрицы на образующий многочлен.
4. Остальные комбинации корректирующего кода находят суммированием по модулю 2 всевозможных сочетаний строк образующей матрицы.
5. Обнаружение ошибок производится по остаткам от деления принятой комбинации ![]() на образующий многочлен
на образующий многочлен ![]() . Если остатка нет, то контрольные разряды отбрасываются и информационная часть кода используется по назначению. Если в результате деления получается остаток, то комбинация бракуется. Заметим, что такие коды могут обнаруживать 75% любого количества ошибок, так как кроме двойной ошибки обнаруживаются все нечетные ошибки, но гарантированное количество ошибок, которое код никогда не пропустит, равно 3.
. Если остатка нет, то контрольные разряды отбрасываются и информационная часть кода используется по назначению. Если в результате деления получается остаток, то комбинация бракуется. Заметим, что такие коды могут обнаруживать 75% любого количества ошибок, так как кроме двойной ошибки обнаруживаются все нечетные ошибки, но гарантированное количество ошибок, которое код никогда не пропустит, равно 3.
Пример: Исходная кодовая комбинация - 0101111000, принятая - 0001011001 (т. е. произошел тройной сбой). Показать процесс обнаружения ошибки, если известно, что комбинации кода были образованы при помощи многочлена 101111.
Решение:
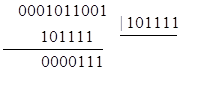
Остаток не нулевой, комбинация бракуется. Указать ошибочные разряды при трехкратных искажениях такие коды не могут.
III. Циклические коды, исправляющие две и большее количество ошибок, ![]()
Методика построения циклических кодов с ![]() отличается от методики построения циклических кодов с
отличается от методики построения циклических кодов с ![]() только в выборе образующего многочлена. В литературе эти коды известны как коды БЧХ (первые буквы фамилий Боуз, Чоудхури, Хоквинхем - авторов методики построения циклических кодов с
только в выборе образующего многочлена. В литературе эти коды известны как коды БЧХ (первые буквы фамилий Боуз, Чоудхури, Хоквинхем - авторов методики построения циклических кодов с ![]() ).
).
Построение образующего многочлена зависит, в основном, от двух параметров: от длины кодового слова п. и от числа исправляемых ошибок s. Остальные параметры, участвующие в построении образующего многочлена, в зависимости от заданных ![]() и
и ![]() могут быть определены при помощи таблиц и вспомогательных соотношений, о которых будет сказано ниже.
могут быть определены при помощи таблиц и вспомогательных соотношений, о которых будет сказано ниже.
Для исправления числа ошибок ![]() еще не достаточно условия, чтобы между комбинациями кода минимальное кодовое расстояние
еще не достаточно условия, чтобы между комбинациями кода минимальное кодовое расстояние ![]() . необходимо также, чтобы длина кода
. необходимо также, чтобы длина кода ![]() удовлетворяла условию
удовлетворяла условию
![]() (79)
(79)
при этом п всегда будет нечетным числом. Величина h определяет выбор числа контрольных символов ![]() и связана с
и связана с ![]() и s следующим соотношением:
и s следующим соотношением:
![]() (80)
(80)
С другой стороны, число контрольных символов определяется образующим многочленом и равно его степени. При больших значениях h длина кода п становится очень большой, что вызывает вполне определенные трудности при технической реализации кодирующих и декодирующих устройств. При этом часть информационных разрядов порой остается неиспользованной. В таких случаях для определения h удобно пользоваться выражением
![]() (81)
(81)
где ![]() является одним из сомножителей, на которые разлагается число п.
является одним из сомножителей, на которые разлагается число п.
Соотношения между ![]() , С и h могут быть сведены в следующую таблицу
, С и h могут быть сведены в следующую таблицу
| № п/п | h |
| C |
| 1 2 3 4 5 6 7 8 9 10 | 3 4 5 6 7 8 9 10 11 12 | 7 15 31 63 127 255 511 1023 2047 4095 | 1 5; 3 1 7; 3; 3 1 17; 5; 3 7; 3; 7 31; 11; 3 89; 23 3; 3; 5; 7; 13 |
Например, при h = 10 длина кодовой комбинации может быть равна и 1023 ![]() и 341 (С = 3), и 33 (С =31), и 31 (С = 33), понятно, что п не может быть меньше
и 341 (С = 3), и 33 (С =31), и 31 (С = 33), понятно, что п не может быть меньше ![]() Величина С влияет на выбор порядковых номеров минимальных многочленов, так как индексы первоначально выбранных многочленов умножаются на С.
Величина С влияет на выбор порядковых номеров минимальных многочленов, так как индексы первоначально выбранных многочленов умножаются на С.
Построение образующего многочлена ![]() производится при помощи так называемых минимальных многочленов
производится при помощи так называемых минимальных многочленов ![]() , которые являются простыми неприводимыми многочленами (см. табл. 2, приложение 9). Образующий многочлен представляет собой произведение нечетных минимальных многочленов и является их наименьшим общим кратным (НОК). Максимальный порядок
, которые являются простыми неприводимыми многочленами (см. табл. 2, приложение 9). Образующий многочлен представляет собой произведение нечетных минимальных многочленов и является их наименьшим общим кратным (НОК). Максимальный порядок ![]() определяет номер последнего из выбираемых табличных минимальных многочленов
определяет номер последнего из выбираемых табличных минимальных многочленов
![]() (82)
(82)
Порядок многочлена используется при определении числа сомножителей ![]() . Например, если s = 6, то
. Например, если s = 6, то ![]() . Так как для построения
. Так как для построения ![]() используются только нечетные многочлены, то ими будут:
используются только нечетные многочлены, то ими будут: ![]() старший из них имеет порядок
старший из них имеет порядок ![]() . Как видим, число сомножителей
. Как видим, число сомножителей ![]() равно 6, т. е. числу исправляемых ошибок. Таким образом, число минимальных многочленов, участвующих в построении образующего многочлена,
равно 6, т. е. числу исправляемых ошибок. Таким образом, число минимальных многочленов, участвующих в построении образующего многочлена,
![]() (83)
(83)
а старшая степень
![]() (84)
(84)
(![]() указывает колонку в таблице минимальных многочленов, из которой обычно выбирается многочлен для построения
указывает колонку в таблице минимальных многочленов, из которой обычно выбирается многочлен для построения ![]() ).
).
Степень образующего многочлена, полученного в результате перемножения выбранных минимальных многочленов,
![]() (85)
(85)
В общем виде
![]() (86)
(86)
Декодирование кодов БЧХ производится по той же методике, что и декодирование циклических кодов с ![]() . Однако в связи с тем, что практически все коды БЧХ представлены комбинациями с
. Однако в связи с тем, что практически все коды БЧХ представлены комбинациями с ![]() , могут возникнуть весьма сложные варианты, когда для обнаружения и исправления ошибок необходимо производить большое число циклических сдвигов. В этом случае для облегчения можно комбинацию, полученную после
, могут возникнуть весьма сложные варианты, когда для обнаружения и исправления ошибок необходимо производить большое число циклических сдвигов. В этом случае для облегчения можно комбинацию, полученную после ![]() -кратного сдвига и суммирования с остатком, сдвигать не вправо, а влево на
-кратного сдвига и суммирования с остатком, сдвигать не вправо, а влево на ![]() циклических сдвигов. Это целесообразно делать только при
циклических сдвигов. Это целесообразно делать только при ![]() .
.
ТЕМА 8. СЖАТИЕ ИНФОРМАЦИИ
Сжатие информации представляет собой операцию, в результате которой данному коду или сообщению ставится в соответствие более короткий код или сообщение[19].
Сжатие информации имеет целью - ускорение и удешевление процессов механизированной обработки, хранения и поиска информации, экономия памяти ЭВМ. При сжатии следует стремиться к минимальной неоднозначности сжатых кодов при максимальной простоте алгоритма сжатия. Рассмотрим наиболее характерные методы сжатия информации.
Сжатие информации делением кода на части, меньшие некоторой наперед заданной величины А, заключается в том, что исходный код делится на части, меньшие А, после чего полученные части кода складываются между собой либо по правилам .двоичной арифметики, либо по модулю 2. Например, исходный код 101011010110; A = 4
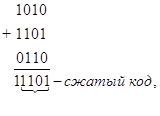
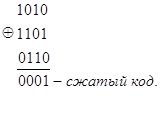
Сжатие информации с побуквенным сдвигом в каждом разряде [5], как и предыдущий способ, не предусматривает восстановления сжимаемых кодов, а применяется лишь для сокращения адреса либо самого кода сжимаемого слова в памяти ЭВМ.
Предположим, исходное слово «газета» кодируется кодом, в котором длина кодовой комбинации буквы l = 8:
Г - 01000111; а - 11110000; з - 01100011; е - 00010111; т - 11011000.
Полный код слова «Газета»
010001111111000001100011000101111101100011110000.
Сжатие осуществляется сложением по модулю 2 двоичных кодов букв сжимаемого слова с побуквенным сдвигом в каждом разряде.

Допустимое количество разрядов сжатого кода является вполне определенной величиной, зависящей от способа кодирования и от емкости ЗУ. Количество адресов, а соответственно максимальное количество слов в выделенном участке памяти машины определяется из следующего соотношения
![]() (88)
(88)
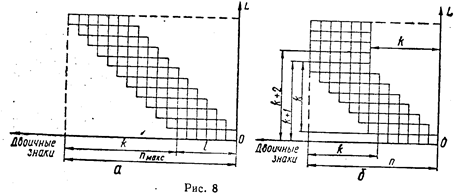
где ![]() - максимально допустимая длина (количество двоичных разрядов) сжатого кода; N - возможное количество адресов в ЗУ. Если представить процесс побуквенного сдвига в общем виде, как показано на рис. 1, а, то длина сжатого кода
- максимально допустимая длина (количество двоичных разрядов) сжатого кода; N - возможное количество адресов в ЗУ. Если представить процесс побуквенного сдвига в общем виде, как показано на рис. 1, а, то длина сжатого кода
![]()
где k - число побуквенных сдвигов; ![]() - длина кодовой комбинации буквы.
- длина кодовой комбинации буквы.
Так как сдвигаются все буквы, кроме первой, то и число сдвигов ![]() , где L - число букв в слове. Тогда
, где L - число букв в слове. Тогда
![]()
В русском языке наиболее длинные слова имеют 23 - 25 букв. Если принять ![]() , с условием осуществления побуквенного сдвига с каждым шагом ровно на один разряд, для n и l могут быть получены следующие соотношения
, с условием осуществления побуквенного сдвига с каждым шагом ровно на один разряд, для n и l могут быть получены следующие соотношения
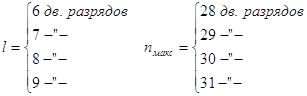
Если значение ![]() не удовлетворяет неравенству (88), можно конечные буквы слова складывать по модулю 2 без сдвига относительно предыдущей буквы, как это показано на рис 1, б.
не удовлетворяет неравенству (88), можно конечные буквы слова складывать по модулю 2 без сдвига относительно предыдущей буквы, как это показано на рис 1, б.
Например, если для предыдущего примера со словом “Газета” ![]() , сжатый код будет иметь вид:
, сжатый код будет иметь вид:
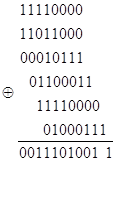
Метод сжатия информации на основе исключения повторения в старших разрядах последующих строк, массивов одинаковых элементов старших разрядов предыдущих строк массивов основан на том, что в сжатых массивах повторяющиеся элементы старших разрядов заменяются некоторым условным символом.
Очень часто обрабатываемая информация бывает представлена в виде набора однородных массивов, в которых элементы столбцов или строк массивов расположены в нарастающем порядке. Если считать старшими разряды, расположенные левее данного элемента, а младшими - расположенные правее, то можно заметить, что во многих случаях строки матриц отличаются друг от друга в младших разрядах. Если при записи каждого последующего элемента массива отбрасывать все повторяющиеся в предыдущем элементы, например в строке стоящие подряд элементы старших разрядов, то массивы могут быть сокращены от 2 до 10 и более разрядов [2].
Для учета выброшенных разрядов вводится знак раздела ![]() , который позволяет отделить элементы в свернутом массиве. В случае полного повторения строк записывается соответствующе количество
, который позволяет отделить элементы в свернутом массиве. В случае полного повторения строк записывается соответствующе количество ![]() . При развертывании вместо знака
. При развертывании вместо знака ![]() восстанавливаются все пропущенные разряды, которые были до элемента, стоящего непосредственно за
восстанавливаются все пропущенные разряды, которые были до элемента, стоящего непосредственно за ![]() в сжатом тексте.
в сжатом тексте.
Для примера рассмотрим следующий массив:
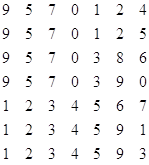
Свернутый массив будет иметь вид:
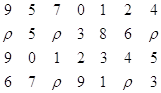
Расшифровка (развертывание) происходит с конца массива. Переход на следующую строку происходит по двум условиям: либо по заполнению строки, либо при встрече ![]() .
.
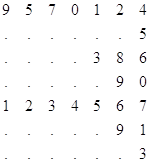
Пропущенные цифры заполняются автоматически по аналогичным разрядам предыдущей строки. Заполнение производится с начала массива. Этот метод можно развить и для свертывания массивов, в которых повторяющиеся разряды встречаются не только с начала строки. Если в строке один повторяющийся участок, то кроме ![]() добавляется еще один дополнительный символ К, означающий конец строки. Расшифровка ведется от К до К. Длина строки известна. Нужно, чтобы оставшиеся между K цифры вместе с пропущенными разрядами составляли полную строку. При этом нам все равно, в каком месте строки выбрасываются повторяющиеся разряды, лишь бы в строке было не более одного участка с повторяющимися разрядами. Например:
добавляется еще один дополнительный символ К, означающий конец строки. Расшифровка ведется от К до К. Длина строки известна. Нужно, чтобы оставшиеся между K цифры вместе с пропущенными разрядами составляли полную строку. При этом нам все равно, в каком месте строки выбрасываются повторяющиеся разряды, лишь бы в строке было не более одного участка с повторяющимися разрядами. Например:
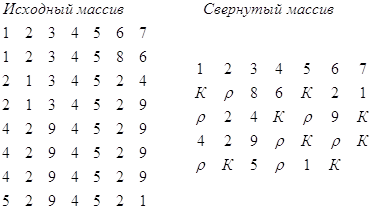
Если в строке есть два повторяющихся участка, то, используя этот метод, выбрасываем больший.
Процесс развертывания массива осуществляется следующим образом: переход на следующую строку происходит при встрече К
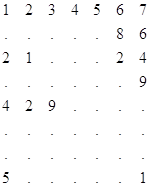
Пропущенные цифры заполняются по аналогичным разрядам предыдущей строки начиная с конца массива.
Если в строке массива несколько повторяющихся участков, то можно вместо ![]() вставлять специальные символы, указывающие на необходимое число пропусков.
вставлять специальные символы, указывающие на необходимое число пропусков.
Например, если обозначить количество пропусков, соответственно, Х - 2; Y - 3; Z - 5, то исходный и свернутый массивы будут иметь вид:
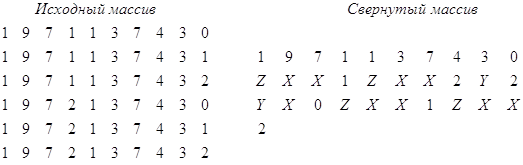
Процесс развертывания массива осуществляется следующим образом: длина строки известна, количество пропусков определяется символами X, Y, Z
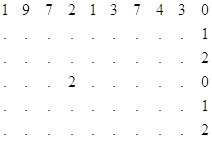
Пропущенные цифры заполняются по аналогичным разрядам предыдущей строки. Условием перехода на следующую строку является заполнение предыдущей строки.
Метод Г. В. Ливинского основан на том, что в памяти машины хранятся сжатые числа, разрядность которых меньше разрядности реальных чисел. Эффект сжатия достигается за счет того, что последовательности предварительно упорядоченных чисел разбиваются на ряд равных отрезков, внутри которых отсчет ведется не по их абсолютной величине, а от границы предыдущего отрезка. Разрядность чисел, получаемых таким образом, естественно, меньше разрядности соответствующих им реальных чисел [18, 21].
Для размещения в памяти ЭВМ М кодов, в которых наибольшее из кодируемых чисел равно N, необходим объем памяти
![]()
С ростом N длина кодовой комбинации будет расти как ![]() . Для экономии объема памяти Q, число
. Для экономии объема памяти Q, число ![]() , где выражение в скобках - округленное значение
, где выражение в скобках - округленное значение ![]() до ближайшего целого числа, разбивают на L равных частей. Максимальное число в полученном интервале чисел будет не больше
до ближайшего целого числа, разбивают на L равных частей. Максимальное число в полученном интервале чисел будет не больше ![]() . Величина
. Величина ![]() определяет разрядность хранимых чисел, объем памяти для их хранения будет не больше
определяет разрядность хранимых чисел, объем памяти для их хранения будет не больше ![]() . Если в памяти ЭВМ хранить адреса границ отрезков и порядковые номера хранимых чисел, отсчитываемых от очередной границы, то
. Если в памяти ЭВМ хранить адреса границ отрезков и порядковые номера хранимых чисел, отсчитываемых от очередной границы, то ![]() определяет разрядность чисел для выражения номера границы (в последнем интервале должно быть хотя бы одно число); объем памяти для хранения номеров границ будет
определяет разрядность чисел для выражения номера границы (в последнем интервале должно быть хотя бы одно число); объем памяти для хранения номеров границ будет ![]() где
где ![]() - число границ между отрезками (это число всегда на единицу меньше, чем число отрезков). Общий объем памяти при этом будет не больше
- число границ между отрезками (это число всегда на единицу меньше, чем число отрезков). Общий объем памяти при этом будет не больше
![]() (89)
(89)
Чтобы найти, при каких L выражение (89) принимает минимальное значение, достаточно продифференцировать его по L и, приравнять производную к нулю. Нетрудно убедиться, что ![]() будет при
будет при
![]() [20] (90)
[20] (90)
Если подставить значение ![]() в выражение (89), то получим. значение объема памяти при оптимальном количестве зон, на, которые разбиваются хранимые в памяти ЭВМ числа,
в выражение (89), то получим. значение объема памяти при оптимальном количестве зон, на, которые разбиваются хранимые в памяти ЭВМ числа,
![]() (91)
(91)
Для значений ![]() при вычислениях можно пользоваться приближенной формулой
при вычислениях можно пользоваться приближенной формулой
![]() (92)
(92)
При поиске информации в памяти ЭВМ прежде всего определяют значение ![]() и находят величину интервала между двумя границами
и находят величину интервала между двумя границами
![]()
Затем определяют, в каком именно из интервалов находится искомое число х
![]()
После этого определяется адрес искомого числа как разность между абсолютным значением числа и числом, которое является граничным для данного интервала.
[1] Первичный алфавит составлен из m1 символов (качественных признаков), при помощи которых записано передаваемое сообщение. Вторичный алфавит состоит из m2 символов, при помощи которых сообщение трансформируется в код.
[2] Строго говоря, объема информации не существует. Мы вкладываем в этот термин то, что привыкли под этим подразумевать, - количество элементарных символов в принятом (вторичном) сообщении.
[3] Суть взаимозависимости символов букв алфавита заключается в том, что вероятность появления i-й буквы в любом месте сообщения зависит от того, какие буквы стоят перед ней и после нее, и будет отличаться от безусловной вероятности pi, известной из статистических свойств данного алфавита.
' Рассмотрение семантической избыточности не входит в задачи теории информации.
[5] Здесь и далее под термином «оптимальный код» будем подразумевать коды с практически нулевой избыточностью, так как сравниваем длину кодовой комбинации с энтропией источника сообщений, не учитывая взаимозависимость символов. С учетом взаимозависимости символов эффективность кодирования никогда не будет 100 %, т. е.
Кроме того, являясь оптимальным с точки зрения скорости передачи информации, код может быть неоптимальным с течки зрения предъявляемых к нему требований помехоустойчивости.
[6] т—-число качественных признаков строящегося оптимального кода.
[7] С основной теоремой кодирования для каналов связи без шумов можно ознакомиться в работе К. Шеннона «Работы по теории информации и кибернетике* либо в популярном изложении в работах [18, 22].
[8] Рассмотренный принцип заложен в основу мажоритарного декодирования.-корректирующих кодов и известен как метод Бодо—Вердана.
[9] В какой-то мере исключением из этого правила являются рефлексные коды. В этих кодах последующая комбинация отличается от предыдущей одним символом. В таких, в общем-то безызбыточных кодах, одновременное изменение нескольких символов в принятом сообщении говорит о наличии ошибки. Однако обнаруживать ошибку такие коды могут только в том случае, если кодовые комбинации следуют строго друг за другом. На практике это возможно при передаче информации о плавно изменяющихся процессах.
[10] В обоих выражениях квадратные скобки означают, что берется округленное значение до ближайшего целого числа в большую сторону. Индекс при показывает количество исправляемых ошибок, а число в круглых скобках при индексе - число обнаруживаемых ошибок.
[11] Условие верхней и нижней границ для максимально допустимого числа информационных разрядов может быть записано следующим образом:
.
[12] ' Оптимальным корректирующим кодом для симметричного канала называется групповой код, при использовании которого вероятность ошибки не больше, чеу при использовании лю5ого другого кода с такими же п„ и Лц [1, 2, б]. У этих кодов критерий оптимальности не имеет ничего общего с критерием оптимальности ОНК.
[13] Практически», так как контрольные символы циклических кодов, построенных путем простого перемножения многочленов, могут оказаться в произвольном месте кодовой комбинации.
[14] Упрощенно, множество элементов принадлежит к одному полю, если над ними можно производить операции сложения и умножения по правилам данного поля, при этом сложение и умножение должны подчиняться дистрибутивному закону для всех и .
[15] О возможности представления линейного кода в виде единичной и некоторой дополнительной матрицы см., например, [22, с. 408, 409].
[16] Следует сказать, что не все циклические коды могут быть получены таким простым способом, однако не будем пока усложнять изложение.
[17] можно определять и по формуле
[18] Коды с d0 = 2, обнаруживающие одиночную ошибку, здесь сознательно не рассматриваются, так как они не имеют практического значения. В двоичных кодах всегда проще подобрать контрольный символ 0 или 1 таким образом, чтобы сумма единиц в кодовом слове была четной, чем строить циклический код для получения того же результата.
[19] Кодирование от сжатия отличается тем, что коды почти всегда длиннее кодируемых сообщений, так как число качественных признаков вторичного алфавита (кода) обычно не бывает больше числа качественных признаков первичного алфавита (кодируемых сообщений). Говоря «сжатый код», будем иметь в виду комбинацию, представляющую кодируемое понятие после процедуры сжатия.
[20] При M<100 следует братьболее точное выражение для , а именно:
Похожие работы
... , работавших в области электротехники, заинтересовалась возможностью создания технологии хранения данных, обеспечивающей более экономное расходование пространства. Одним из них был Клод Элвуд Шеннон, основоположник современной теории информации. Из разработок того времени позже практическое применение нашли алгоритмы сжатия Хаффмана и Шеннона-Фано. А в 1977 г. математики Якоб Зив и Абрахам Лемпел ...

... также невысока и обычно составляет около 100 кбайт/с. НКМЛ могут использовать локальные интерфейсы SCSI. Лекция 3. Программное обеспечение ПЭВМ 3.1 Общая характеристика и состав программного обеспечения 3.1.1 Состав и назначение программного обеспечения Процесс взаимодействия человека с компьютером организуется устройством управления в соответствии с той программой, которую пользователь ...
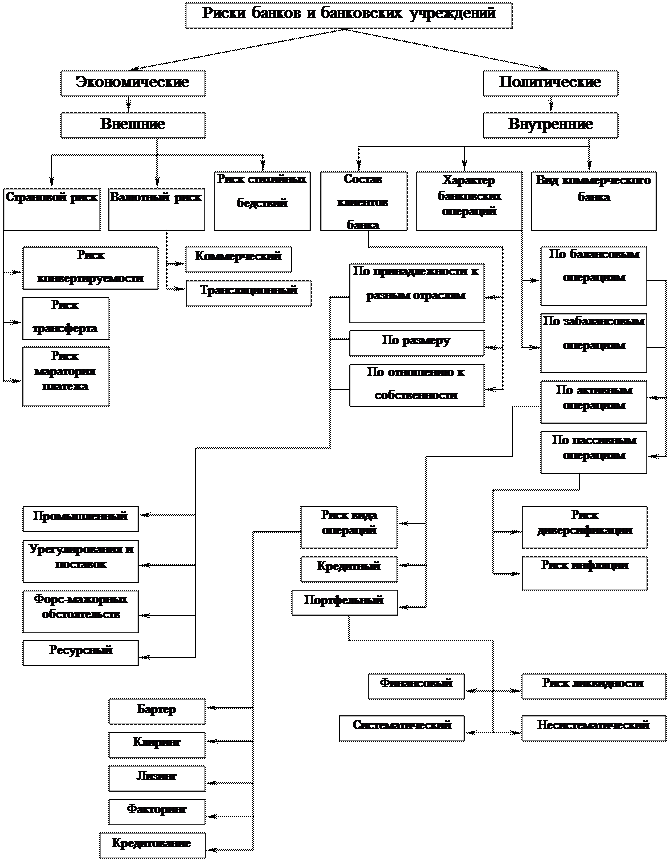

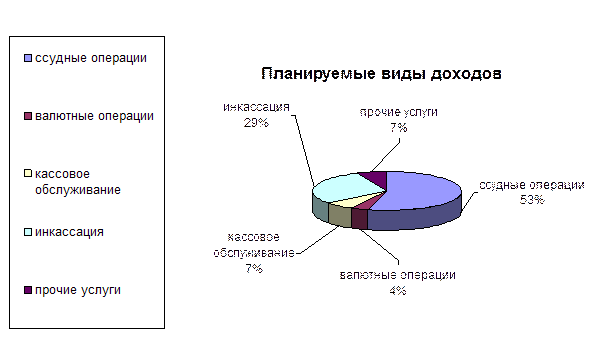

... анализ финансового состояния ЗАО КБ «Пятигорск», определить важнейшие его показатели. 2.3. Эффективность методики оценки кредитоспособности заемщика и ее совершенствование Сущность анализа финансового состояния во многом определяется его объектами, которые в коммерческом банке отражают содержание финансовой деятельности кредитного учреждения (См.: Рис. 2.3.). Объекты ...
... к ТС и технологическим процессам. Общие требования безопасности к ТС и технологическим процессам содержат: 1). инженерные (технические) требования, обеспечивающие надежность и безаварийность ТС и процессов; 2) гигиенические требования, обеспечивающие необходимые (или комфортные) условия жизнедеятельности и сохранения высокой работоспособности работающих; 3) антропометрические требования, ...
0 комментариев