Навигация
Методы оценки близости допредельных и предельных распределений статистик
19566
знаков
0
таблиц
1
изображение
Рассматривается проблема оценки близости предельных распределений статистик и распределений, соответствующих конечным объемам выборок. При каких объемах выборок уже можно пользоваться предельными распределениями? Каков точный смысл термина "можно" в предыдущей фразе? Основное внимание уделяется переходу от точных формул допредельных распределений к пределу и применению метода статистических испытаний (Монте-Карло). Обсуждаются "подводные камни" на пути исследователя в рассматриваемой области.
1. Асимптотическая математическая статистика
и практика анализа статистических данных
Как мы обычно подходим к обработке реальных данных в конкретной прикладной задаче? Первым делом строим статистическую модель. Если мы хотим перенести выводы с совокупности результатов наблюдений на более широкую совокупность, например, предсказать что-либо, то рассматриваем, как правило, вероятностно-статистическую модель. Например, традиционную модель выборки, в которой результаты наблюдений - реализации независимых (в совокупности) одинаково распределенных случайных величин. Очевидно, любая модель лишь приближенно соответствует реальности. В частности, естественно ожидать, что распределения результатов наблюдений несколько отличаются друг от друга, а сами результаты связаны между собой, хотя и слабо. И эти ожидания во многих конкретных случаях оправдываются (в терминах конкретной прикладной ситуации см. об этом, например, в монографии [1]).
Итак, первый этап - переход от реальной ситуации к математической модели. Далее - неожиданность: на настоящем этапе своего развития математическая теория статистики зачастую не позволяет провести необходимые исследования для имеющихся объемов выборок. Более того, отдельные математики пытаются оправдать свой отрыв от практики соображениями о структуре этой теории, на первый взгляд убедительными. Неосторожная давняя фраза Б. В. Гнеденко и А. Н. Колмогорова: "Познавательная ценность теории вероятностей раскрывается только предельными теоремами" [2] взята на вооружение и более близкими к нам по времени авторами. Так, И. А. Ибрагимов и Р. З. Хасьминский пишут: "Решение неасимптотических задач оценивания, хотя и весьма важное само по себе, как правило, не может являться объектом достаточно общей математической теории. Более того, соответствующее решение часто зависит от конкретного типа распределения, объема выборки и т. д. Так, теория малых выборок из нормального закона будет отличаться от теории малых выборок из закона Пуассона" [3, с.7].
Согласно цитированным и подобным им авторам, основное содержание математической теории статистики - предельные теоремы, полученные в предположении, что объемы рассматриваемых выборок стремятся к бесконечности. Эти теоремы опираются на предельные соотношения теории вероятностей, типа Закона Больших Чисел и Центральной Предельной Теоремы. Ясно, что сами по себе подобные утверждения относятся к математике, т. е. к сфере чистой абстракции, и не могут быть непосредственно применены для анализа реальных данных. Их использование опирается на важное предположение: "При данном объеме выборки достаточно точными являются асимптотические формулы. "
Конечно, в качестве первого приближения представляется естественным воспользоваться асимптотическими формулами, не тратя сил на анализ их точности. Но это - лишь начало долгой цепи исследований. Как же обычно преодолевают разрыв между результатами асимптотической математической статистики и потребностями практики статистического анализа данных? Какие "подводные камни" подстерегают на этом пути? Обсуждению этих вопросов и посвящена настоящая статья.
2. Точные формулы и асимптотика
Начнем с наиболее продвинутой в математическом плане ситуации, когда для статистики известны как предельное распределение, так и распределения при конечных объемах выборки.
Примером является двухвыборочная односторонняя статистика Н.В.Смирнова. Рассмотрим две независимые выборки объемов m и n из непрерывных функций распределения F(x) и G(x) соответственно. Для проверки гипотезы однородности двух выборок
H0 : F(x) = G(x) для всех действительных чисел x
в 1939 г. Н.В.Смирнов в статье [4] предложил использовать статистику
D+(m,n) = sup ( Fm(x) - Gn(x) ) ,
где супремум берется по всем действительным числам x. Для обсуждения проблемы соотношения точных и предельных результатов ограничимся случаем равных объемов выборок, т.е. m = n. Положим
H(n, t) = P ( D+(n,n) $ t n - 1/2) .
В цитированной статье [4] Н,В. Смирнов показал, что при безграничном возрастании объема выборки n вероятность H(n, t) стремится к exp ( - t 2 ).
В работе [5] 1951 г. Б.В.Гнеденко и В.С.Королюк показали, что при целом с = t n1/2 (именно при таких t вероятность H(n, t) как функция t имеет скачки, поскольку статистика Смирнова D+(n,n) кратна 1/ n ) рассматриваемая вероятность H(n, t) выражается через биномиальные коэффициенты, а именно,
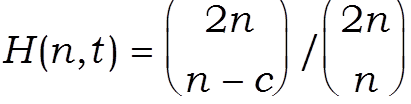 (1).
(1).
К сожалению, непосредственные расчеты по формуле (1) возможны лишь при сравнительно небольших объемах выборок, поскольку величина n!.уже при n=100 имеет более 200 цифр и не может быть без преобразований использована в вычислениях. Следовательно, наличие точной формулы для интересующей нас вероятности не снимает необходимости использования предельного распределения и изучения точности приближения с его помощью.
Широко известная формула Стирлинга для гамма-функции и, в частности, для факториалов позволяет преобразовать последнее выражение в асимптотическиое разложение, т.е. построить бесконечный степенной ряд (по степеням n ) такой что каждая следующая частичная сумма дает все более точное приближение для интересующей нас вероятности H(x, t) . Это и было сделано в работе А.А.Боровкова [6], опубликованной в 1962 г. Большое количество подобных разложений для различных статистических задач приведено в работах [7-9] В.М.Калинина и О.В. Шалаевского в конце 60-х - начале 70-х годов. (Интересно отметить, что асимптотические разложения в ряде случаев расходятся, т.е. остаточные члены имеют нетривиальную природу.)
В наших работах конца семидесятых годов была сделана попытка теоретически оценить остаточный член второго порядка. Итоги подведены в статье [10] и монографии [11, § 2.2, с.37-45]. Справедливо равенство
H(n, t) = exp ( - t 2 ).(1 + f(t)/n + g(n,t)/ n2 ),
где
f(t) = t2 (1/2 - t2/ / 6 ).
Целью указанных работ было получение равномерных по n, t оценок остаточного члена второго порядка g(n,t) сверху и снизу в области, задаваемой условиями
Похожие работы
... ПО “Уралмаш”, “АвтоВАЗ”, МИИТ, Казахского политехнического института, Донецкого государственного университета и многих других. Затем Институт в качестве Лаборатории эконометрических исследований разрабатывал эконометрические методы анализа нечисловых данных, а также процедуры расчета и прогнозирования индекса инфляции и валового внутреннего продукта. Институт высоких статистических технологий и ...
... М. В. Неоклассическая модель чистой монополии. М.: ИМЭМО, АН СССР, 1990. 3. Лейбенстайн X. Аллокативная эффективность в сравнении с "Х-эффективностью" // Теория фирмы. С. 477—506. 4. Маленво Э. Лекции... Гл. III. § 9. С. 80—85. 5. Робинсон Дж. Экономическая теория... Гл. 3—5. С. 88—130. 6. Стиглер Дж. Совершенная конкуренция: исторический ракурс // Теория фирмы. С. 299—328. 7. Самуэльсон П. ...

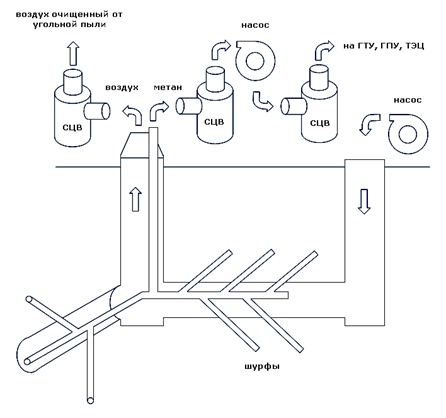
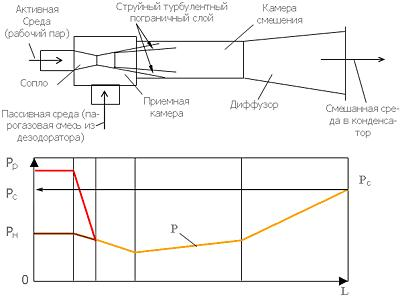
... . В вентиляционных выбросах угольных шахт содержится малоконцентрированный шахтный метан в количестве 0,5…2% от вентиляционного воздуха[11]. Утилизация метана является актуальной задачей, особенно для угольных регионов с шахтной добычей угля, таких как Кузбасс. Малоконцентрированный шахтный метан можно использовать в системах подачи воздуха в топочных устройствах. Достаточно обоснованных ...
0 комментариев