Цифровое представление звуковых сигналов
Спецификация стандарта MIDI, его реализация на компьютере
Звуковые карты
Блок микшеpа. Осуществляет pегулиpование уpовней, коммутацию и сведение используемых на каpте аналоговых сигналов
Обзор современных технологий позиционирования звука в пространстве
Обзор применяемых форматов хранения цифровых аудио данных без и с потерей качества
Packetized Elementary Stream (PES) - разбивает звук и видео на пакеты
Навигация
Обзор современных технологий позиционирования звука в пространстве
Методы позиционирования и сжатия звука
461693
знака
14
таблиц
14
изображений
5. Обзор современных технологий позиционирования звука в пространстве
Звуковое сопровождение компьютера всегда находилось несколько на втором плане. Большинство пользователей более охотно потратят деньги на новейший акселератор 3D графики, нежели на новую звуковую карту. Однако за последний год производители звуковых чипов и разработчики технологий 3D звука приложили немало усилий, чтобы убедить пользователей и разработчиков приложений в том, что хороший 3D звук является неотъемлемой частью современного мультимедиа компьютера. Пользователей убедить в пользе 3D звука несколько легче, чем разработчиков приложений. Достаточно расписать пользователю то, как источники звука будет располагаться в пространстве вокруг него, т.е. звук будет окружать слушателя сов всех сторон и динамично изменяться, как многие потянутся за кошельком. С разработчиками игр и приложений сложнее. Их надо убедить потратить время и средства на реализацию качественного звука. А если звуковых интерфейсов несколько, то перед разработчиком игры встает проблема выбора. Сегодня есть два основных звуковых интерфейса, это DirectSound3D от Microsoft и A3D от Aureal. При этом если разработчик приложения предпочтет A3D, то на всем аппаратном обеспечении DS3D будет воспроизводиться 3D позиционируемый звук, причем такой же, как если бы изначально использовался интерфейс DS3D. Само понятие "трехмерный звук" подразумевает, что источники звука располагаются в трехмерном пространстве вокруг слушателя. Это основа. Далее, что бы придать звуковой модели реализм и усилить восприятие звука слушателем, используются различные технологии, обеспечивающие воспроизведение реверберации, отраженных звуков, окклюзии (звук прошедший через препятствие), обструкции (звук не прошел через препятствие), дистанционное моделирование (вводится параметр удаленности источника звука от слушателя) и масса других интересных эффектов. Цель всего этого, создать у пользователя реальность звука и усилить впечатления от видео ряда в игре или приложении. Не секрет, что слух это второстепенное чувство человека, именно поэтому, каждый индивидуальный пользователь воспринимает звук по-своему. Никогда не будет однозначного мнения о звучании той или иной звуковой карты или эффективности той или иной технологии 3D звука. Сколько будет слушателей, столько будет мнений. В данной статье мы попытались собрать и обобщить информацию о принципах создания 3D звука, а также рассказать о текущем состоянии звуковой компьютерной индустрии и о перспективах развития. Мы уделим отдельное внимание необходимым составляющим хорошего восприятия и воспроизведения 3D звука, а также расскажем о некоторых перспективных разработках. Некоторые данные в статье рассчитаны на подготовленного пользователя, однако, никто не мешает пропустить нудные формулы тем, кому это не интересно или давно надоело в институте.
Итак, наверняка почти все слышали, что для позиционирования источников звука в виртуальном 3D пространстве используются HRTF функции. Ну что же, попробуем разобраться в том, что такое HRTF и действительно ли их использование так эффективно.
Сколько раз происходило следующее: команда, отвечающая за звук, только что закончила встраивание 3D звукового интерфейса на базе HRTF в новейшую игру; все комфортно расселись, готовясь услышать "звук окружающий вас со всех сторон" и "свист пуль над вашей головой"; запускается демо версия игры и… и ничего подобного вы просто не слышите!
HRTF (Head Related Transfer Function) это процесс посредством которого наши два уха определяют слышимое местоположение источника звука; наши голова и туловище являются в некоторой степени препятствием, задерживающим и фильтрующим звук, поэтому ухо, скрытое от источника звука головой воспринимает измененные звуковые сигналы, которые при "декодировании" мозгом интерпретируются соответствующим образом для правильного определения местоположения источника звука. Звук, улавливаемый нашим ухом, создает давление на барабанную перепонку. Для определения создаваемого звукового давления необходимо определить характеристику импульса сигнала от источника звука, попадающего на барабанную перепонку, т.е. силу, с которой звуковая волна отlисточника звука воздействует на барабанную перепонку. Эту зависимость называют Head Related Impulse Response (HRIR), а ее интегральное преобразование по Фурье называется HRTF.
Правильнее характеризовать акустические источники скоростью распространяемых ими звуковых волн V(t), нежели давлением P(t) распространяемой звуковой волны. Теоретически, давление, создаваемой идеальным точечным источником звука бесконечно, но ускорение распространяемой звуковой волны есть конечная величина. Если вы достаточно удалены от источника звука и если вы находитесь в состоянии "free field" (что означает, что в окружающей среде нет ничего кроме, источника звука и среды распространения звуковой волны), тогда давление "free field" (ff) на расстоянии "r" от источника звука определяется по формуле
Pff(t) = Zo V(t - r/c) / r где Zo это постоянная называемая волновым сопротивлением среды (characteristic impedance of the medium), а "c" это скорость распространения звука в среде. Итак, давление ff пропорционально скорости в начальный период времени (происход "сдвиг" по времени, обусловленный конечной скоростью распространения сигнала. То есть возмущение в этой точке описывается скоростью источника в момент времени отстоящий на r/c - время которое затрачено на то, чтобы сигнал дошел до наблюдателя. В принципе не зная V(t) нельзя утверждать характера изменения скорости при сдвиге, т.е. произойдет замедление или ускорение) и давление уменьшается обратно пропорционально расстоянию от источника звука до пункта наблюдения.
С точки зрения частоты давление звуковой волны можно выразить так:
Pff(f) = Zo V(f) exp(- i 2 pi r/c) / r где "f" это частота в герцах (Hz), i = sqrt(-1), а V(f) получается в результате применения преобразования Фурье к скорости распространения звуковой волны V(t). Таким образом, задержки при распространении звуковой волны можно охарактеризовать "phase factor", т.е. фазовым коэффициентом exp(- i 2 pi r /c). Или, говоря словами, это означает, что функция преобразования в "free field" Pff(f) просто является результатом произведения масштабирующего коэффициента Zo, фазового коэффициента exp(- i 2 pi r /c) и обратно пропорциональна расстоянию 1/r. Заметим, что возможно более рационально использовать традиционную циклическую частоту, равную 2*pi*f чем просто частоту.
Если поместить в среду распространения звуковых волн человека, тогда
звуковое поле вокруг человека искажается за счет дифракции (рассеивания или иначе говоря различие скоростей распространения волн разной длины), отражения и дисперсии (рассредоточения) при контакте человека со звуковыми волнами. Теперь все тот же источник звука будет создавать несколько другое давление звука P(t) на барабанную перепонку в ухе человека. С точки зрения частоты это давление обозначим как P(f). Теперь, P(f), как и Pff(f) также содержит фазовый коэффициент, чтобы учесть задержки при распространении звуковой волны и вновь давление ослабевает обратно пропорционально расстоянию. Для исключения этих концептуально незначимых эффектов HRTF функция H определяется как соотношение P(f) и Pff(f). Итак, строго говоря, H это функция, определяющая коэффициент умножения для значение давления звука, которое будет присутствовать в центре головы слушателя, если нет никаких объектов на пути распространения волны, в давление на барабанную перепонку в ухе слушателя.
Обратным преобразованием Фурье функции H(f) является функция H(t), представляющая собой HRIR (Head-Related Impulse Response). Таким образом, строго говоря, HRIR это коэффициент (он же есть отношение давлений, т.е. безразмерен; это просто удобный способ загнать в одну букву в формуле очень сложный параметр), который определяет воздействие на барабанную перепонку, когда звуковой импульс испускается источником звука, за исключением того, что мы сдвинули временную ось так, что t=0 соответствует времени, когда звуковая волна в "free field" достигнет центра головы слушателя. Также мы масштабировали результаты таким образом, что они не зависят от того, как далеко источник звука расположен от человека, относительно которого производятся все измерения.
Если пренебречь этим временным сдвигом и масштабированием расстояния до источника звука, то можно просто сказать, что HRIR - это давление воздействующее на барабанную перепонку, когда источник звука является импульсным.
Напомним, что интегральным преобразованием Фурье функции HRIR является HRTF функция. Если известно значение HRTF для каждого уха, мы можем точно синтезировать бинауральные сигналы от монофонического источника звука (monaural sound source). Соответственно, для разного положения головы относительно источника звука задействуются разные HRTF фильтры. Библиотека HRTF фильтров создается в результате лабораторных измерений, производимых с использованием манекена, носящего название KEMAR (Knowles Electronics Manikin for Auditory Research, т.е. манекен Knowles Electronics для слуховых исследований) или с помощью специального "цифрового уха" (digital ear), разработанного в лаборатории Sensaura, располагаемого на голове манекена. Понятно, что измеряется именно HRIR, а значение HRTF получается путем преобразования Фурье. На голове манекена располагаются микрофоны, закрепленные в его ушах. Звуки воспроизводятся через акустические колонки, расположенные вокруг манекена и происходит запись того, что слышит каждое "ухо".
HRTF представляет собой необычайно сложную функцию с четырьмя переменными: три пространственных координаты и частота. При использовании сферических координат для определения расстояния до источников звука больших, чем один метр, считается, что источники звука находятся в дальнем поле (far field) и значение HRTF уменьшается обратно пропорционально расстоянию. Большинство измерений HRTF производится именно в дальнем поле, что существенным образом упрощает HRTF до функции азимута (azimuth), высоты (elevation) и частоты (frequency), т.е. происходит упрощение, за счет избавления от четвертой переменной. Затем при записи используются полученные значения измерений и в результате, при проигрывании звук (например, оркестра) воспроизводится с таким же пространственным расположением, как и при естественном прослушивании. Техника HRTF используется уже несколько десятков лет для обеспечения высокого качества стерео записей. Лучшие результаты получаются при прослушивании записей одним слушателем в наушниках.
Наушники, конечно, упрощают решение проблемы доставки одного звука к одному уху и другого звука к другому уху. Тем не менее, использование наушников имеет и недостатки. Например:
· Многие люди просто не любят использовать наушники. Даже легкие беспроводные наушники могут быть обременительны. Наушники, обеспечивающие наилучшую акустику, могут быть чрезвычайно неудобными при длительном прослушивании.
· Наушники могут иметь провалы и пики в своих частотных характеристиках, которые соответствуют характеристикам ушной раковины. Если такого соответствия нет, то восприятие звука, источник которого находится в вертикальной плоскости, может быть ухудшено. Иначе говоря, мы будем слышать преимущественно только звук, источники которого находится в горизонтальной плоскости.
· При прослушивании в наушниках, создается ощущение, что источник звука находится очень близко. И действительно, физический источник звука находится очень близко к уху, поэтому необходимая компенсация для избавления от акустических сигналов влияющих на определение местоположения физических источников звука зависит от расположения самих наушников.
Использование акустических колонок позволяет обойти большинство из этих проблем, но при этом не совсем понятно, как можно использовать колонки для воспроизведения бинаурального звука (т.е. звука, предназначенного для прослушивания в наушниках, когда часть сигнала предназначена для одного уха, а другая часть для другого уха). Как только мы подключим вместо наушников колонки, наше правое ухо начнет слышать не только звук, предназначенный для него, но и часть звука, предназначенную для левого уха. Одним из решений такой проблемы является использование техники cross-talk-cancelled stereo или transaural stereo, чаще называемой просто алгоритм crosstalk cancellation (для краткости CC).
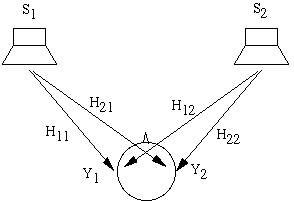
Идея CC просто выражается в терминах частот. На схемы выше сигналы S1 иS2 воспроизводятся колонками. Сигнал Y1 достигающий левого уха представляет собой смесь из S1 и "crosstalk" (части) сигнала S2. Чтобы быть более точными, Y1=H11 S1 + H12 S2, где H11 является HRTF между левой колонкой и левым ухом, а H12 это HRTF между правой колонкой и левым ухом. Аналогично Y2=H21 S1 + H22 S2. Если мы решим использовать наушники, то мы явно будем знать искомые сигналы Y1 и Y2 воспринимаемые ушами. Проблема в том, что необходимо правильно определить сигналы S1 и S2, чтобы получить искомый результат. Математически для этого просто надо обратить уравнение:

На практике, обратное преобразование матрицы не является тривиальной задачей.
· При очень низкой частоте звука, все функции HRTF одинаковы и поэтому матрица является вырожденной, т.е. матрицей с нулевым детерминантом (это единственная помеха для тривиального обращения любой квадратной матрицы). На западе такие матрицы называют сингулярными. (К счастью, в среде отражающей звук, т.е. где присутствует реверберация, низкочастотная информация не являются важной для определения местоположения источника звука).
· Точное решение стремиться к результату с очень длинными импульсными характеристиками. Эта проблема становится все более и более сложной, если в дальнейшем искомый источник звука располагается вне линии между двумя колонками, т.е. так называемый фантомный источник звука.
· Результат будет зависеть от того, где находится слушатель по отношению к колонкам. Правильное восприятие звучания достигается только в районе так называемого "sweet spot", предполагаемого месторасположения слушателя при обращении уравнения. Поэтому, то, как мы слышим звук, зависит не только от того, как была сделана запись, но и от того, из какого места между колонками мы слушаем звук.
При грамотном использовании алгоритмов CC получаются весьма хорошие результаты, обеспечивающие воспроизведение звука, источники которого расположены в вертикальной и горизонтальной плоскости. Фантомный источник звука может располагаться далеко вне пределов линейного сегмента между двумя колонками.
Давно известно, что для создания убедительного 3D звучания достаточно двух звуковых каналов. Главное это воссоздать давление звука на барабанные перепонки в левом и правом ушах таким же, как если бы слушатель находился в реальной звуковой среде.
Из-за того, что расчет HRTF функций сложная задача, во многих системах пространственного звука (spatial audio systems) разработчики полагаются на использование данных, полученных экспериментальным путем, например, данные получаются с помощью KEMAR. Тем не менее, основной причиной использования HRTF является желание воспроизвести эффект elevation (звук в вертикальной плоскости), наряду с азимутальными звуковыми эффектами. При этом восприятие звуковых сигналов, источники которых расположены в вертикальной плоскости, чрезвычайно чувствительно к особенностям каждого конкретного слушателя. В результате сложились четыре различных метода расчета HRTF:
· Использование компромиссных, стандартных HRTF функций. Такой метод обеспечивает посредственные результаты при воспроизведении эффектов elevation для некоторого процента слушателей, но это самый распространенный метод в недорогих системах. На сегодня, ни IEEE, ни ACM, ни AES не определили стандарт на HRTF, но похоже, что компании типа Microsoft и Intel создадут стандарт де-факто.
· Использование одной типа HRTF функций из набора стандартных функций. В этом случае необходимо определить HRTF для небольшого числа людей, которые представляют все различные типы слушателей, и предоставить пользователю простой способ выбрать именно тот набор HRTF функций, который наилучшим образом соответствует ему (имеются в виду рост, форма головы, расположение ушей и т.д.). Несмотря на то, что такой метод предложен, пока никаких стандартных наборов HRTF функций не существует.
· Использование индивидуализированных HRTF функций. В этом случае необходимо производить определение HRTF исходя из параметров конкретного слушателя, что само по себе сложная и требующая массы времени процедура. Тем не менее, эта процедура обеспечивает наилучшие результаты.
· Использование метода моделирования параметров определяющих HRTF, которые могут быть адаптированы к каждому конкретному слушателю. Именно этот метод сейчас применяется повсеместно в технологиях 3D звука.
На практике существуют некоторые проблемы, связанные с созданием базы HRTF функций при помощи манекена. Результат будет соответствовать ожиданиям, если манекен и слушатель имеют головы одинакового размера и формы, а также ушные раковины одинакового размера и формы. Только при этих условиях можно корректно воссоздать эффект звучания в вертикальной плоскости и гарантировать правильное определение местоположения источников звука в пространстве. Записи, сделанные с использованием HRTF называются binaural recordings, и они обеспечивают высококачественный 3D звук. Слушать такие записи надо в наушниках, причем желательно в специальных наушниках. Компакт диски с такими записями стоят существенно дороже стандартных музыкальных CD. Чтобы корректно воспроизводить такие записи через колонки необходимо дополнительно использовать технику CC. Но главный недостаток подобного метода - это отсутствие интерактивности. Без дополнительных механизмов, отслеживающих положение головы пользователя, обеспечить интерактивность при использовании HRTF нельзя. Бытует даже поговорка, что использовать HRTF для интерактивного 3D звука, это все равно, что использовать ложку вместо отвертки: инструмент не соответствует задаче.
Sweet Spot
На самом деле значения HRTF можно получить не только с помощью установленных в ушах манекена специальных внутриканальных микрофонов (inter-canal microphones). Используется еще и так называемая искусственная ушная раковина. В этом случае прослушивать записи нужно в специальных внутриканальных (inter-canal) наушниках, которые представляют собой маленькие шишечки, размещаемые в ушном канале, так как искусственная ушная раковина уже перевела всю информацию о позиционировании в волновую форму. Однако нам гораздо удобнее слушать звук в наушниках или через колонки. При этом стоит помнить о том, что при записи через inter-canal микрофоны вокруг них, над ними и под ними происходит искажение звука. Аналогично, при прослушивании звук искажается вокруг головы слушателя. Поэтому и появилось понятие sweet spot, т.е. области, при расположении внутри которой слушатель будет слышать все эффекты, которые он должен слышать. Соответственно, если голова слушателя расположена в таком же положении, как и голова манекена при записи (и на той же высоте), тогда будет получен лучший результат при прослушивании. Во всех остальных случаях будут возникать искажения звука, как между ушами, так и между колонками. Понятно, что необходимость выбора правильного положения при прослушивании, т.е. расположение слушателя в sweet spot, накладывает дополнительные ограничения и создает новые проблемы. Понятно, что чем больше область sweet spot, тем большую свободу действий имеет слушатель. Поэтому разработчики постоянно ищут способы увеличить область действия sweet spot.
Частотная характеристика
Действие HRTF зависит от частоты звука; только звуки со значениями частотных компонентов в пределах от 3 kHz до 10 kHz могут успешно интерпретироваться с помощью функций HRTF. Определение местоположения источников звуков с частотой ниже 1 kHz основывается на определении времени задержки прибытия разных по фазе сигналов до ушей, что дает возможность определить только общее расположение слева/справа источников звука и не помогает пространственному восприятию звучания. Восприятие звука с частотой выше 10 kHz почти полностью зависит от ушной раковины, поэтому далеко не каждый слушатель может различать звуки с такой частотой. Определить местоположение источников звука с частотой от 1 kHz до 3 kHz очень сложно. Число ошибок при определении местоположения источников звука возрастает при снижении разницы между соотношениями амплитуд (чем выше пиковое значение амплитуды звукового сигнала, тем труднее определить местоположение источника). Это означает, что нужно использовать частоту дискретизации (которая должна быть вдвое больше значения частоты звука) соответствующей как минимум 22050 Hz при 16 бит для реальной действенности HRTF. Дискретизация 8 бит не обеспечивает достаточной разницы амплитуд (всего 256 вместо 65536), а частота 11025 Hz не обеспечивает достаточной частотной характеристики (так как при этом максимальная частота звука соответствует 5512 Hz). Итак, чтобы применение HRTF было эффективным, необходимо использовать частоту 22050 Hz при 16 битной дискретизации.
Ушная раковина (Pinna)
Мозг человека анализирует разницу амплитуд, как звука, достигшего внешнего уха, так и разницу амплитуд в слуховом канале после ушной раковины для определения местоположения источника звука. Ушная раковина создает нулевую и пиковую модель звучания между ушами; эта модель совершенно разная в каждом слуховом канале и эта разница между сигналами в ушах представляет собой очень эффективную функциюдля определения, как частоты, так и местоположения источника звука. Но это же явление является причиной того, что с помощью HRTF нельзя создать корректного восприятия звука через колонки, так как по теории ни один из звуков, предназначенный для одного уха не должен быть слышимым вторым ухом.
Мы вновь вернулись к необходимости использования дополнительных алгоритмов CC. Однако, даже при использовании кодирования звука с помощью HRTF источники звука являются неподвижными (хотя при этом амплитуда звука может увеличиваться). Это происходит из-за того, что ушная раковина плохо воспринимает тыловой звук, т.е. когда источники звука находятся за спиной слушателя. Определение местоположения источника звука представляет собой процесс наложения звуковых сигналов с частотой, отфильтрованной головой слушателя и ушными раковинами на мозг с использованием соответствующих координат в пространстве. Так как происходит наложение координат только известных характеристик, т.е. слышимых сигналов, ассоциируемых с визуальным восприятием местоположения источников звука, то с течением времени мозг "записывает" координаты источников звука и в дальнейшем определение их местоположения может происходить лишь на основе слышимых сигналов. Но видим мы только впереди. Соответственно, мозг не может правильно расположить координаты источников звука, расположенных за спиной слушателя при восприятии слышимых сигналов ушной раковиной, так как эта характеристика является неизвестной. В результате, мозг может располагать координаты источников звука совсем не там, где они должны быть. Подобную проблему можно решить только при использовании вспомогательных сигналов, которые бы помогли мозгу правильно располагать в пространстве координаты источников звуков, находящихся за спиной слушателя.
Неподвижные источники звука
Все выше сказанное подвело нас к еще одной проблеме:
Если источники звука неподвижны, они не могут быть точно локализованы, как "статические" при моделировании, т.к. мозгу для определения местоположения источника звука необходимо наличие перемещения (либо самого источника звука, либо подсознательных микро перемещений головы слушателя), которое помогает определить расположение источника звука в геометрическом пространстве. Нет никаких оснований, ожидать, что какая-либо система на базе HRTF функций будет корректно воспроизводить звучание, если один из основных сигналов, используемый для определения местоположения источника звука, отсутствует. Врожденной реакцией человека на неожидаемый звук является повернуть голову в его сторону (за счет движения головы мозг получает дополнительную информацию для локализации в пространстве источника звука). Если сигнал от источника звука не содержит особую частоту, влияющую на разницу между фронтальными и тыловыми HRTF функциями, то такого сигнала для мозга просто не существует; вместо него мозг использует данные из памяти и сопоставляет информацию о местоположении известных источников звука в полусферической области.
Каково же будет решение?
Лучший метод воссоздания настоящего 3D звука это использование минимальной частоты дискретизации 22050 Hz при 16 битах и использования дополнительных тыловых колонок при прослушивании. Такая платформа обеспечит пользователю реалистичное воспроизведение звука за счет воспроизведение через достаточное количество колонок (минимум три) для создания настоящего surround звучания. Преимущество такой конфигурации заключается в том, что когда слушатель поворачивает голову для фокусировки на звуке какого-либо объекта, пространственное расположение источников звука остается неизменным по отношению к окружающей среде, т.е. отсутствует проблема sweet spot.
Есть и другой метод, более новый и судить о его эффективности пока сложно. Суть метода, который разработан Sensaura и называется MultiDrive, заключается в использовании HRTF функций на передней и на тыловой паре колонок (и даже больше) с применением алгоритмов CC. На самом деле Sensaura называет свои алгоритмы СС несколько иначе, а именно Transaural Cross-talk cancellation (TCC), заявляя, что они обеспечивают лучшие низкочастотные характеристики звука. Инженеры Sensaura взялись за решение проблемы восприятия звучания от источников звука, которые перемещаются по бокам от слушателя и по оси фронт/тыл. Заметим, что Sensaura для вычисления HRTF функций использует так называемое "цифровое ухо" (Digital Ear) и в их библиотеке уже хранится более 1100 функций. Использование специального цифрового уха должно обеспечивать более точное кодирование звука. Подчеркнем, что Sensaura создает технологии, а использует интерфейс DS3D от Microsoft.
Технология MultiDrive воспроизводит звук с использованием HRTF функций через четыре или более колонок. Каждая пара колонок создает фронтальную и тыловую полусферу соответственно.
Фронтальные и тыловые звуковые поля специальным образом смещены с целью взаимного дополнения друг друга и за счет применения специальных алгоритмов улучшает ощущения фронтального/тылового расположения источников звука. В каждом звуковом поле применяются собственный алгоритм cross-talk cancellation (CC). Исходя из этого, есть все основания предполагать, что вокруг слушателя будет плавное воспроизведение звука от динамично перемещающихся источников и эффективное расположение тыловых виртуальных источников звука. Так как воспроизводимые звуковые поля основаны на применении HRTF функций, каждое из создаваемых sweet spot (мест, с наилучшим восприятием звучания) способствует хорошему восприятию звучания от источников по сторонам от слушателя, а также от движущихся источников по оси фронт/тыл. Благодаря большому углу перекрытия результирующее место с наилучшим восприятием звука (sweet spot) покрывает область с гораздо большей площадью, чем конкурирующие четырех колоночные системы воспроизведения. В результате качество воспроизводимого 3D звука должно существенно повысится.
Если бы не применялись алгоритмы cross-talk cancellation (CC) никакого позиционирования источников звука не происходило бы. Вследствие использования HRTF функций на четырех колонках для технологии MultiDrive необходимо использовать алгоритмы CC для четырех колонок, требующие чудовищных вычислительных ресурсов. Из-за того, что обеспечить работу алгоритмов CC на всех частотах очень сложная задача, в некоторых системах применяются высокочастотные фильтры, которые срезают компоненты высокой частоты. В случае с технологией MultiDrive Sensaura заявляет, что они применяют специальные фильтры собственной разработки, которые позволяют обеспечить позиционирование источников звука, насыщенными высокочастотными компонентами, в тыловой полусфере. Хотя sweet spot должен расшириться и восприятие звука от источников в вертикальной плоскости также улучшается, у такого подхода есть и минусы. Главный минус это необходимость точного позиционирования тыловых колонок относительно фронтальных. В противном случае никакого толка от HRTF на четырех колонках не будет.
Стоит упомянуть и другие инновации Sensaura, а именно технологии ZoomFX и MacroFX, которые призваны улучшить восприятие трехмерного звука. Расскажем о них подробнее, тем более что это того стоит.
MacroFX
Как мы уже говорили выше, большинство измерений HRTF производятся в так называемом дальнем поле (far field), что существенным образом упрощает вычисления. Но при этом, если источники звука располагаются на расстоянии до 1 метра от слушателя, т.е. в ближнем поле (near field), тогда функции HRTF плохо справляются со своей работой. Именно для воспроизведения звука от источников в ближнем поле с помощью HRTF функций и создана технология MacroFX. Идея в том, что алгоритмы MacroFX обеспечивают воспроизведение звуковых эффектов в near-field, в результате можно создать ощущение, что источник звука расположен очень близко к слушателю, так, будто источник звука перемещается от колонок вплотную к голове слушателя, вплоть до шепота внутри уха слушателя. Достигается такой эффект за счет очень точного моделирования распространения звуковой энергии в трехмерном пространстве вокруг головы слушателя из всех позиций в пространстве и преобразование этих данных с помощью высокоэффективного алгоритма. Особое внимание при моделировании уделяется управлению уровнями громкости и модифицированной системе расчета задержек по времени при восприятии ушами человека звуковых волн от одного источника звука (ITD, Interaural Time Delay). Для примера, если источник звука находится примерно посередине между ушами слушателя, то разница по времени при достижении звуковой волны обоих ушей будет минимальна, а вот если источник звука сильно смещен вправо, эта разница будет существенной. Только MacroFX принимает такую разницу во внимание при расчете акустической модели. MacroFX предусматривает 6 зон, где зона 0 (это дистанция удаления) и зона 1 (режим удаления) будут работать точно так же, как работает дистанционная модель DS3D. Другие 4 зоны это и есть near field (ближнее поле), покрывающие левое ухо, правое ухо и пространство внутри головы слушателя.
Этот алгоритм интегрирован в движок Sensaura и управляется DirectSound3D, т.е. является прозрачным для разработчиков приложений, которые теперь могут создавать массу новых эффектов. Например, в авиа симуляторах можно создать эффект, когда пользователь в роли пилота будет слышать переговоры авиа диспетчеров так, как если бы он слышал эти переговоры в наушниках. В играх с боевыми действиями может потребоваться воспроизвести звук пролетающих пуль и ракет очень близко от головы слушателя. Такие эффекты, как писк комара рядом с ухом теперь вполне реальны и доступны. Но самое интересное в том, что если у вас установлена звуковая карта с поддержкой технологии Sensaura и с драйверами, поддерживающими MacroFX, то пользователь получит возможность слышать эффекты MacroFX даже в уже существующих DirectSound3D играх, разумеется, в зависимости от игры эффект будет воспроизводиться лучше или хуже. Зато в игре, созданной с учетом возможности использования MacroFX. Можно добиться очень впечатляющих эффектов.
Поддержка MacroFX будет включена в драйверы для карт, которые поддерживают технологию Sensaura.
ZoomFX
Современные системы воспроизведения позиционируемого 3D звука используют HRTF функции для создания виртуальных источников звука, но эти синтезированные виртуальные источники звука являются точечными. В реальной жизни звук зачастую исходит от больших по размеру источников или от композитных источников, которые могут состоять из нескольких индивидуальных генераторов звука. Большие по размерам и композитные источники звука позволяют использовать более реалистичные звуковые эффекты, по сравнению с возможностями точечных источников звука. Так, точечный источник звука хорошо применим при моделировании звука от большого объекта удаленного на большое расстояние (например, движущийся поезд). Но в реальной жизни, как только поезд приближается к слушателю, он перестает быть точечным источником звука. Однако в модели DS3D поезд все равно представляется, как точечный источник звука, а значит, страдает реализм воспроизводимого звука (т.е. мы слышим звук скорее от маленького поезда, нежели от огромного состава громыхающего рядом). Технология ZoomFX решает эту проблему, а также вносит представление о большом объекте, например поезде как собрание нескольких источников звука (композитный источник, состоящий из шума колес, шума двигателя, шума сцепок вагонов и т.д.).
Для технологии ZoomFX будет создано расширение для DirectSound3D, подобно EAX, с помощью которого разработчики игр смогут воспроизводить новые звуковые эффекты и использовать такой параметр источника звука, как размер. Пока эта технология находится на стадии завершения.
Компания Creative реализовала аналогичный подход, как в MultiDrive от Sensaura, в своей технологии CMSS (Creative Multispeaker Surround Sound) для серии своих карт SB Live!. Поддержка этой версии технологии CMSS, с реализацией HRTF и CC на четырех колонках, встроена в программу обновления LiveWare 2.x. По своей сути, технология CMSS является близнецом MultiDrive, хотя на уровне алгоритмов CC и библиотек HRTF наверняка есть отличия. Главный недостаток CMSS такой же, как у MultiDrive - необходимость расположения тыловых колонок в строго определенном месте, а точнее параллельно фронтальным колонкам. В результате возникает ограничение, которое может не устроить многих пользователей. Не секрет, что место для фронтальных колонок давно зарезервировано около монитора. Место для сабвуфера можно выбрать любым, обычно это где-то в углу и на полу. А вот тыловые колонки пользователи располагают там, где считают удобным для себя. Не каждый захочет расположить их строго за спиной и далеко не у всех есть свободное место для такого расположения.
Заметим, что главный конкурент Creative на рынке 3D звука, компания Aureal, использует технику панорамирования на тыловых колонках. Объясняется это именно отсутствием строгих ограничений на расположение тыловых колонок в пространстве.
Не стоит забывать и о больших объемах вычислений при расчете HRTF и Cross-talk Cancellation для четырех колонок
Еще один игрок на рынке 3D звука - компания QSound пока имеет сильные позиции только в области воспроизведения звука через наушники и две колонки. При этом свои алгоритмы для воспроизведения 3D звука через две колонки и наушники (в основе лежат HRTF) QSound создает исходя из результатов тестирования при прослушивании реальными людьми, т.е. не довольствуется математикой, а делает упор на восприятие звука конкретными людьми. И таких прослушиваний было проведено более 550000! Для воспроизведения звука через четыре колонки QSound использует панорамирование, т.е. тоже, что было в первой версии CMSS. Такая техника плохо показала себя в играх, обеспечивая слабое позиционирование источников звука в вертикальной плоскости.
Компания Aureal привнесла в технологии воспроизведения 3D звука свою технику Wavetracing. Мы уже писали об этой технологии, вкратце, это расчет распространения отраженных и прошедших через препятствия звуковых волн на основе геометрии среды. При этом обеспечивается полный динамизм восприятия звука, т.е. полная интерактивность.
Итак, подведем итоги. Однозначный вывод состоит в том, что если вы хотите получить наилучшее качество 3D звука, доступное на сегодняшний день, вам придется использовать звуковые карты, поддерживающие воспроизведение минимум через четыре колонки. Использование только двух фронтальных колонок - это конфигурация вчерашнего дня. Далее, если вы только собираетесь переходить на карты с поддержкой четырех и более колонок, то перед вами встает классическая проблема выбора. Как всегда единственная рекомендация состоит в том, чтобы вы основывали свой выбор на собственных ощущениях. Послушайте максимально возможно число разных систем и сделайте именно свой выбор.
Теперь посмотрим, с каким багажом подошли ведущие игроки 3D звукового рынка к сегодняшнему дню и что нас ждет в ближайшем будущем.
EAR
EAR - в текущей версии IAS 1.0 реализована поддержка воспроизведения DS3D, A3D 1.0 и EAX 1.0 через четыре и более колонок. За счет воспроизведения через четыре и более колонок, мозг слушателя получает дополнительные сигналы для правильного определения местоположения источников звука в пространстве.
Осенью ожидается выход IAS 2.0 с поддержкой DirectMusic, YellowBook, EAX 2.0
и A3D 2.0, force-feed back (мы сможем чувствовать звук, а именно давление звука, громкость и т.д.), декодирование в реальном времени MP3 и Dolby/DTS, будет реализована поддержка ".1" канала (сабвуфера). Кроме того, в IAS 2.0 будет реализовано звуковое решение, не требующее наличие звуковой карты (cardless audio solution) для использования с полностью цифровой системой воспроизведения звука, например с USB колонками или в тандеме с домашней системой Dolby Digital.
Главные достоинства IAS от EAR:
· Один интерфейс для любой многоколоночной платформы, обеспечивающий одинаковый результат вне зависимости от того, как воспроизводится звук при использовании специального API.
· Имеется поддержка воспроизведения через две колонки (для старых систем),
если многоколоночная конфигурация недоступна.
· Пользователь может подключить свой компьютер к домашней звуковой системе (Dolby Digital и т.д.) и IAS будет воспроизводить звук без необходимости какой-либо модернизации.
Итак, по сравнению с конкурентами, IAS работает на любой платформе и не
требует специального аппаратного обеспечения. При этом IAS использует любое доступное аппаратное обеспечение и обеспечивает пользователю наилучшее качество звука, которое доступно на его системе. Только вот остановит ли свой выбор пользователь на этой технологии, это большой вопрос. С другой стороны, для использования IAS не нужно покупать специальных звуковых карт.
Sensaura
Sensaura - компания занимающаяся созданием технологий. Производители звуковых чипов лицензируют разработки Sensaura и воплощают их в жизнь. В чипе Canyon3D от ESS будет реализована поддержка современных технологий Sensaura, которые должны обеспечить слушателем 3D звук на современном уровне, т.е. позиционируемый в пространстве и с воспроизведением через четыре и более колонок. За воспроизведение через четыре и более колонок отвечает технология MultiDrive, которая реализует HRTF и алгоритмы Cross-talk cancellation. Многообещающе выглядят технологии ZoomFX и MacroFX. Кроме того, Sensaura поддерживает воспроизведение реверберации через EAX от Creative, равно как и через I3DL2, а также эмулирует поддержку A3D 1.х через DS3D.
Первым звуковым чипов, который реализует технологию MultiDrive на практике, является Canyon3D от ESS Technology, Inc. Более подробную информацию о чипе Canyon3D можно найти на официальном сайте www.canyon3d.com.
Первая карта на базе чипа Canyon3D называется DMX и производит ее компания Terratec.
Как только эта карта попадет к нам на испытания, мы представим на ваш суд обзор. Заметим только, что на этой карте будут сразу оба типа цифровых выходов S/PDIF коаксиальный (RCA) и оптический (Toslink), и один цифровой вход. Так что продукт обещает быть очень интересным.
Creative
Creative - занимается совершенствованием своего движка реверберации. В итоге в свет выйдет EAX 3.0, который должен добавить больше реализма в воспроизводимый звук. Никто не спорит, что реверберация это хорошо, что именно она обеспечивает насыщенное и живое звучание. При этом Creative упорно не собирается вести разработки в области геометрии акустики. Кстати, Microsoft объявила о намерении включить EAX в состав DirectSound3D 8.0. С другой стороны, есть неподтвержденные слухи, что EAX 3.0 будет закрытым стандартом. Интересно, изменит ли Creative свою позицию со временем? Пока же в новых версиях EAX нам обещают больше реализма и гибкости в настройках реверберации и моделировании звуковой среды для конкретных объектов и помещений, плюс плавные переходы от одной заранее созданной звуковой среды к другой при движении слушателя в 3D мире. Будут улучшения в области воспроизведения эффектов окклюзии и обструкции. Обещают и поддержку отраженных звуков, но без учета геометрии и более продвинутую дистанционную модель. Вообще, я не удивлюсь, если Creative лицензирует MacroFX и ZoomFX у Sensaura. Что касается моделирования звука на основе физической геометрии среды, то Creative очень усиленно отрицает для себя возможность поддержки такого метода. Хотя, если поднять архивы и посмотреть первый пресс-релиз о будущем чипе Emu10k1, то вы будете удивлены. Там говорится именно об использовании физической геометрии среды при моделировании звука. Потом планы изменились. Кто помешает Creative вновь изменить планы? Особенно если учесть появление в ближайшее время движка реверберации от Aureal. Вряд ли Creative не сделает ответного хода.
QSound
QSound ведет работы по созданию новой технологии воспроизведения 3D звука через четыре и более колонок. Зная пристрастия QSound, можно предположить, что в основу новой технологии опять лягут результаты реальных прослушиваний. QSound, как и Sensaura занимается именно технологиями, которые воплощают в виде чипов другие компании. Так, чип Thunderbird128 от VLSI воплощает в себе все последние достижения QSound в области 3D звука, при этом Thunderbird128 это DSP, а значит, есть все основания ожидать последующей модернизации. Стоит упомянуть, что QSound, подобно Creative считает, что главное в 3D звуке это восприятие слушателем окружающей атмосферы игры. Поэтому QEM (QSound Environmental Modeling) совместима с EAX 1.0 от Creative. Следует ожидать, что QEM 2.0 будет совместима с EAX 2.0. Отметим, что QSound славится очень эффективными алгоритмами и грамотным распределением доступных ресурсов, неслучайно именно их менеджер ресурсов был лицензирован Microsoft и включен в DirectX.
Aureal
С Aureal все более-менее понятно. В ближайшем будущем нам обещают дальнейшее улучшение функциональности A3D, мощный движок реверберации, поддержку HRTF на четырех и более колонках.
Мы упомянули основные разработки в области 3D звука, которые применяются в компьютерном мире. Есть еще ряд фирм с интересными решениями, но они делают упор на рынок бытовой электроники, поэтому в данном материале yt рассказывается о них.
Обзорно изучив технологии, существующие на рынке позиционирования 3Д звука, попробуем рассмотреть их более пристально.
В видении компании Sensaura
Компания Sensaura более 10 лет занимается созданием звуковых технологий. Все разработки Sensaura ориентированы на работу через стандартный интерфейс DirectSound3D и его расширения. Часть технологий Sensaura уже применяются на практике, другие разработки мы скоро увидим в действие. По сути, Sensaura предлагает использовать производителям звуковых чипов и карт специальные алгоритмы, которые в паре со стандартным API DS3D и расширениями для него, должны обеспечить моделирование и воспроизведение качественного 3D звука.
Попробуем рассказать о том, что же предлагает Sensaura.
Digital Ear
Для корректного воспроизведения 3D звука через наушники или колонки необходимо использовать специальные алгоритмы, базирующиеся на использовании HRTF функций. Кроме того, при воспроизведении 3D звука через колонки необходимо использовать дополнительные алгоритмы Cross-talk Cancellation, вариант которых от Sensaura носит имя Transaural Cross-talk Cancellation (TCC).
Инженеры Sensaura пришли к выводу, что использование для формирования библиотек HRTF измерения, сделанные с помощью специального манекена или с приглашением реальных слушателей не могут обеспечить удовлетворить абсолютно всех слушателей. Дело в том, что какое бы большое число измерений не было сделано с использованием манекена, все полученные HRTF все равно будут усредненными. Все то же самое относится и к измерениям, сделанным с приглашением большого числа различных слушателей. Все равно есть небольшая часть людей, у которых совершенно отличные параметры слуха, а значит, при измерении у них получаются, совсем другие HRTF функции. В результате, какой бы большой и универсальной не была библиотека HRTF функций, часть людей не услышат ожидаемого 3D звука. Чтобы решить эту проблему, специалисты Sensaura разработали технологию Digital Ear (Цифровое ухо), ранее называвшуюся Virtual Ear. Суть идеи Digital Ear в том, что для измерения HRTF используется не просто манекен или приглашаются реальные слушатели, а используется чисто математический метод Ключевым элементом этого метода является математическая модель человеческого уха с изменяемыми параметрами. В основу математической модели положена концепция того, что сложные резонансные и дифракционные эффекты, являющиеся неотъемлемой частью любой HRTF функции могут независимо изменяться. В результате созданая дуплексная система, позволяющая изменять различные параметры в произвольном масштабе. Прежде чем была построена эта математическая модель было проведено масса исследований с целью точно смоделировать само ухо, точно определить, как оно реагирует на звуковые волны и как работает процесс человеческого слуха. Учитывались особенности восприятия мозгом различных звуков от источников, расположенных в разных точках пространства. Затем была создана модель уха из специального пластика, на нем были проведены измерения и отлажена математическая модель. Потом были получены базовые результаты измерения HRTF, на основе которых в дальнейшем с помощью специальных методов масштабирования стала формироваться библиотека HRTF. Использование математической модели гарантирует от наличия ошибок, которые возможны при физическом измерении HRTF с помощью манекена или реальных слушателей. Digital Ear можно настроить на огромное количество вариаций форм и размеров ушей реальных людей. В итоге получается обширная библиотека с возможностью очень гибко выбрать одну или несколько HRTF, которая наилучшим образом соответствует особенностям каждого конкретного слушателя. Кроме того, так как используется математическая модель, имеется возможность довольно простой модернизации алгоритмов и обновления библиотек HRTF без больших материальных затрат.
Между некоторыми параметрами Digital Ear существует зависимость, не мешающая масштабированию каждого из параметров в отдельности. Это позволяет построить простой интерфейс пользователя, позволяющий путем определения и задания в качестве данных некоторых физических параметров, описывающих голову и уши слушателя выбрать именно те HRTF функции из библиотеки, которые наилучшим образом отвечают особенностям конкретного слушателя. Вот эти параметры:
· Размер головы (Head Size) - влияет на изменение величины ITD (Interaural time delay) задержки по времени при восприятии ушами слушателя звука от одного источника
· Размер уха (Ear Size) - влияет на протяженность звукового спектра
· Глубина ушной раковины (Concha Depth) - влияет на величину сдвига звукового спектра
· Тип ушной раковины (Concha Type) - влияет на величину амплитуды звукового сигнала
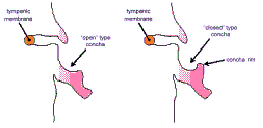
Слева неглубокая ушная раковина, справа – глубокая
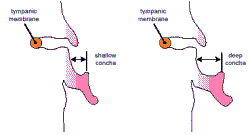
Слева ушная раковина открытого типа, справа - закрытого типа
В результате, каждый пользователь сможет настроить воспроизведения 3D звука с использованием технологии Digital Ear специально под себя. Пока технология Digital Ear не позволяет использовать гибкую настройку под конкретного слушателя и во всех дравейрах к звуковым картам, использующим технологии Sensaura задействуется универсальный набор HRTF функций, соответствующий среднему слушателю. Однако обещается, что уже в скором времени у пользователя появится возможность выбора HRTF под себя.
Смоделированный 3D звук мы можем слушать через наушники или через набор акустических колонок. При прослушивании через наушники используются только HRTF функции для воспроизведения эффектов 3D звука. Эта техника является традиционной и пока кардинально нового тут ничего не предвидится. За исключением шлифовки качества HRTF и предоставления пользователю возможности выбора HRTF конкретно под себя. При воспроизведении звука через две колонки также используется довольно традиционный метод комбинирования HRTF и алгоритмов cross-talk cancellation. Зато при вопсроизведении 3D звука через четыре и более колонок пока нет единого метода. Компания Sensaura разработала технологию MultiDrive, которая обеспечивает воспроизведение 3D звука с помощью более чем четырех колонок.
MultiDrive
Прежде всего начнем немного издалека. Зададимся вопросом, а зачем нам собственно слушать 3D звук через более чем одну пару колонок? Ну, в пользу мультиколоночных акустических систем можно сказать, что, во-первых у некоторых пользователей они уже есть, так почему бы их не использовать. Во-вторых, обычная ситема из двух колонок с использованием HRTF + CC имеет ряд ограничений при вопроизведении звуков от источников, расположенных в вертикальной плоскости и при движении источника звука по оси фронт/тыл. Итак, понятно, что, как минимум дополнительная пара колонок на тылах нам не повредит.
Есть и еще один момент. При использовании связки HRTF + CC могут возникнуть сложности корректного воспроизведения некоторых высокочастотных компонет звука выше величины в несколько kHz. Например, если на фоне звука взрывов нужно воспроизвести пение птахи. Причиной этого является невозможность реализовать идеально алгоритмы CC. Разные компании по разному борятся с этой проблемой, например, используются специальные фильтры высокой частоты, которые просто вырезают высокочастотные компоненты. В технологии MultiDrive применяются специальные фильтры, которые позволяют обеспечить воспроизведение звука, насыщенного высокочастотными компонентами.
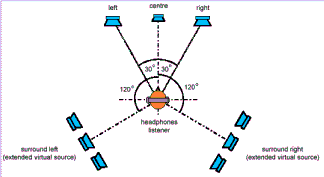
Кроме того, для наилучшего восприятия звука слушатель должен находится в границах sweet spot, т.е. участка пространства, в котором звук воспринимается наилучшим образом. Понятно, что чем больше площадь sweet spot, тем большая свобода у слушателя. Мы ведь не манекены и не можем долгое время сидеть, не меняя положения головы относительно пола. В настоящее время наиболее распространена конфигурация из 4 колонок (не считая сабвуфера), поэтому в дальнейшем мы будем говорить именно о такой конфигурации акустики.
Технология MultiDrive позволяет воспроизводить 3D звук с использованием API DS3D. Суть этой технологии заключается в использовании HRTF функций на всех парах колонок с применением алгоритмов Transaural Cross-talk Cancellation (TCC). Отличие TCC от стандартных алгоритмов CC заключается в том, что они обеспечивают лучшие низкочастотные характеристики звука. Кроме того, предусмотрена возможность для пользователя управлять работой TCC, настраивая звучание под себя.
Каждая пара колонок создает фронтальную и тыловую полусферу соответственно. Фронтальные и тыловые звуковые поля специальным образом смещены с целью взаимного дополнения друг друга и за счет применения специальных алгоритмов улучшает ощущения фронтального/тылового расположения источников звука и под управлением DS3D. В каждом звуковом поле применяются собственный алгоритм TCC. Исходя из этого, вокруг слушателя должно происходить плавное воспроизведение звука от динамично перемещающихся источников и эффективное расположение тыловых виртуальных источников звука. Благодаря большому углу перекрытия результирующее место с наилучшим восприятием звука (sweet spot) покрывает область с гораздо большей площадью, по сравнению, например, с двухколоночной конфигурацией.
Минусом использования HRTF + TCC на всех парах колонок является то, что для расчета TCC требуется масса вычислительных ресурсов и необходимость довольно точного позиционирования тыловых колонок относительно фронтальных. В противном случае никакого толка от HRTF + TCC на четырех колонках не будет.
Стоит добавить, что MultiDrive рассчитана на совместное использование с алгоритмами MacroFX и ZoomFX от Sensaura.
MacroFX
Мы уже говорили выше, что с помощью HRTF и TCC можно воспроизвести качественный 3D звук. Но есть один нюанс. Обычно большинство измерений HRTF производятся в так называемом дальнем поле (far field, на дистации более 1 метра до источника звука), т.к. это существенно упрощает вычисления да и в большинстве игр воспроизводится звук от источников, находящихся на расстоянии от 1 метра и больше от слушателя. При этом, если источник звука находится на расстоянии до 1 метра от слушателя, т.е. в ближнем поле (near field), тогда эффективность использования HRTF снижается. Дело в том, что для создания звучания от удаленного источника звука достаточно добавить к основному звуковому сигналу реверберацию. Иногда можно обойтись и без реверберации, сократив высокочастотные компоненты в основном звуковом сигнале. Если источник звука находится в ближнем поле, подобные решения не применимы. Но необходимость в воспроизведении звука от источников в ближнем боле нередки. Например, в игре типа RPG может возникнуть необходимость нашептать подсказку непосредственно в ухо игроку, а в FPS игре часто необходимо воспроизвести звук пролетающих рядом с головой игрока пуль. Все эти эффекты нельзя вопроизвести, если HRTF измерялись на дистанции от одного метра и более, т.е. в дальнем поле. Тем не менее, измерить HRTF для всей области ближнего поля очень сложно, а использование дискретных наборов HRTF, сделанных, например, для дистанций 1 м, 0.9 м, 0.9 м и т.д. не позволит сделать звук от движущегося объекта естественно плавным, он будет скачкообразным. Решением проблемы является использование единого набора универсальных HRTF для ближнего поля с использованием дополнительного алгоритма.
Этот алгоритм был создан Sensaura и получил имя MacroFX. В результате работы MacroFX можно создать ощущение, что источник звука расположен очень близко к слушателю, так, будто источник звука перемещается от колонок вплотную к голове слушателя и вплоть до шепота внутри уха слушателя. Достигается такой эффект за счет очень точного моделирования распространения звуковой энергии в трехмерном пространстве вокруг головы слушателя, преобразования этих данных в тесном взаимодействии с HRTF функциями. Особое внимание при моделировании уделяется управлению уровнями громкости и модифицированной системе расчета задержек по времени при восприятии ушами человека звуковых волн от одного источника звука (ITD, Interaural Time Delay). Для примера, если источник звука находится примерно посередине между ушами слушателя, то разница по времени при достижении звуковой волны обоих ушей будет минимальна, а вот если источник звука сильно смещен вправо, эта разница будет существенной. Только MacroFX принимает такую разницу во внимание при расчете акустической модели. Все эти вычисления происходят до начала работы алгоритмов TCC, но сразу после расчета HRTF для всех источников звука.
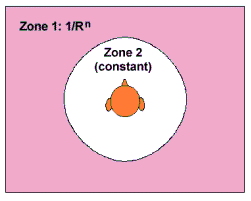
В DS3D предусмотрено три зоны (две из них показаны на рисунке слева). Зона 0 в ней располагаются сильно удаленные источники звука, которые имеют постоянную интенсивность, не зависящую от расстояния. Источники в этой зоне могут не приниматься во внимание, т.е. слушатель их не слышит, либо они используются для формирования реверберации. Зона 1 это т.н. дальнее поле, в ней располагаются источники на расстоянии более 1 метра от слушателя и до определяемой разработчиком границы. В этой зоне интенсивность источников звука обратно пропорциональна расстоянию до слушателя. В зоне 2 (ближнее поле, расстояние до 1 м от слушателя) все источники звука имеют постоянную интенсивность. Это сделано для того, чтобы уровень громкости не превысил допустимого барьера и с целью ограничения нагрузки на шину данных.
MacroFX предусматривает 6 зон, где зона 0 (это дистанция удаления) и зона 1 (дальнее поле) будут работать точно так же, как работает дистанционная модель DS3D. Другие 4 зоны это и есть near field (ближнее поле) в стиле MacroFX, покрывающие дистанцию рядом с головой слушателя, левое ухо, правое ухо и пространство внутри головы слушателя. При этом здесь также вводятся ограничение на дистанцию, чтобы сократить накладные расходы при вычислениях. Поэтому в зоне 2 используется стандартный алгоритм Near-Field FX, а в зонах 3, 4 и 5, которые начинают работать с расстояния в 20 см, используется как таковой алгоритм MacroFX. Эти три зоны рассчитаны на источники звука, расположенные очень близко к ушам пользователя (левому или правому). Если источник звука должен находится как бы в голове пользователя (например, переговоры авиадиспетчеров в авиасимуляторе), то для этого используется зона 5.
Алгоритм MacroFX полностью прозрачен для интерфейсов и игр. Это означает, что если у вас установлена звуковая карта, в драйвер которой встроена поддержка MacroFX, то вы услышите работу этой технологии во всех играх, где источники звука попадают в ближнее поле. Разумеется, в зависимости от конкретной игры эффект будет воспроизводиться лучше или хуже. Зато в игре, созданной с учетом возможности использования MacroFX можно добиться очень впечатляющих эффектов, например, писк комара прямо в ухе, свист ветра в ушах при езде на велосипеде и т.д.
ZoomFX
Современные системы воспроизведения позиционируемого 3D звука используют HRTF функции для создания виртуальных источников звука, являющихся точечными. В реальной жизни звук зачастую исходит от больших по размеру источников звука или от композитных источников, объединяющих собой сразу несколько источников звука. Большие по размерам и композитные источники звука позволяют использовать более реалистичные звуковые эффекты, по сравнению с возможностями точечных источников звука. Так, точечный источник звука хорошо применим при моделировании звука от большого объекта удаленного на большое расстояние (например, движущийся поезд). Но в реальной жизни, как только поезд приближается к слушателю, он перестает быть точечным источником звука. В реальной жизни, когда поезд проезжает рядом с нами, мы слышим стук колес, скрип рессор, звук от буферов и т.д. Тем не менее, при моделировании источника звука типа поезд с использованием интерфейса DS3D поезд представляется, как точечный источник звука. В результате звук получается ненатуральным, т.е. мы слышим звук скорее от маленького поезда, нежели от огромного состава громыхающего рядом. Технология ZoomFX решает эту проблему, за счет введения такого параметра источника звука, как размер и сложность. Если вспомнить про наш поезд, то он будет представлен в виде собрания нескольких источников звука, типа шума колес, шума двигателя, шума сцепок вагонов и т.д. Для представления большого по размеру объекта используется набор из нескольких точечных источников звука. Для того чтобы мы слышали отдельные составляющие композитного источника звука используется метод динамической декорреляции (Dynamic Decorrelation), позволяющий выделить отдельные источники, составляющие композитный источник звука.

На рисунке показано, как источник звука типа вертолет представляется в виде нескольких точеных источников. Когда вертолет далеко от нас, все четыре точечных источника формируют единый звуковой сигнал в виде гула. Этот основной звук можно снабдить дополнительными звуковыми сигналами в виде реверберации, чтобы пользователю было проще определить источник звука. Например, что вертолет летит на расстоянии 50 метров на фоне высотного здания из стеклобетона. Как только вертолет приблизится на достаточное расстояние к нам, так, что мы сможем легко его рассмотреть вполне логично ожидать, что мы сможем выделить звук от лопастей (как они рассекают воздух), звук от турбины и звук от хвостового винта. Именно для таких целей и предназначен ZoomFX. На практике все работает следующим образом. В качестве носителя звука вертолета может выступать обычный монофонический wav файл. Затем, когда возникает необходимость выделить составляющие источники звука, начинает работать динамический декоррелятор, который выделяет несколько вторичных звуков, которые затем подвергаются обработке HRTF фильтрами, затем происходит сложение соответствующих каналов (правые с правыми, левы с левыми и т.д.), затем сигнал обрабатывается алгоритмами TCC и воспроизводится через акустическую систему. К слову, возможность создания нескольких виртуальных источников звука с помощью ZoomFX может быть использована, например, для воспроизведения в наушниках многоканального звука типа Dolby Digital.
Технология ZoomFX в отличие от MacroFX не является прозрачной для интерфейсов и игр. Для ее поддержки будет создано расширение для DirectSound3D, подобно EAX, с помощью которого разработчики игр смогут воспроизводить новые звуковые эффекты и использовать такой параметр источника звука, как размер. Пока эта технология находится на стадии завершения.
EnvironmentFX
Технология EnvironmentFX создана для моделирования звука окружающей среды и рассчитана на использование со стандартными интерфейсам типа EAX и I3DL2. По сути, технология EnvironmentFX позволяет воспроизводить эффект реверберации, описывая то, как звуки достигают ушей слушателя в зависимости от параметров помещения. Помещением может быть и открытое пространство и маленькая келья монаха. Когда слушатель находится в помещении с истоником звука он сначала слышит звук, достигший его ушей по прямому пути, затем, чуть поздее, он сылшит ранние отражения (звуки несколько раз отразившиееся от стен или объектов) и в самый последний момент он слышит реверберацию, т.е. поле остаточных отраженных звуков, затухающее со временем.
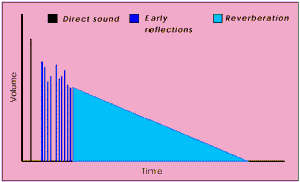
На иллюстрации слева показано распределение звуковых сигналов в зависимоти от уровня громкости и продолжительности во времени.
EnvironmentFX позволяет моделировать различные типы акустики за счет использования специальных алгоритмов, рассчитывающих ранние отражения и реверберацию. При этом истоник каждого из ранних отраженных звуков может позиционироваться индивидуально в 3D пространстве. Для того, чтобы переходы между различными помещениями (читай разными аустическими средами) были плавными и естественными предусмотрены специальные фильтры, причем алгоритм EnvironmentFX динамически переконфигурируется переключаясь на нужный. Имеется возможность динамического регулирования уровня интенсивности реверберации для каждого источника звука индивидуально. EnvironmentFX специально ориентирована на воспроизведение через мультиколоночную конфигурацию акустики с использованием технологии MultiDrive, но при этом допускается воспроизведение звука и через две колонки или наушники. Для моделирования различных акустических сред EnvironmentFX использует параметры самого истоника звука (интенсивность, расположение в пространстве) и параметры окружающей среды. Для воспроизведения звука вокруг пользователя EnvironmentFX использует следующие характеристики:
· Direct-to-reverberant sound ratio - соотношение уровней громкости основных звуков и реверберации. Уровень громкости основного звука становится интенсивнее при достижении ушей слушателя и становится тише, когда уходит на задний план. В тоже время уровень громкости реверберации приблизительно неизменен вне зависимости от расстояния между слушателем и источником звука. Сооношение уровней громкости основного звука и реверберации дает слушателю важную информацию для оценки расстояния до истоника звука.
· Room size - размеры помещения. В маленьком помещении, например холле, расстояние между отраженными звуковыми волнами мало, т.е. отраженные звуки близки друг к другу и довольно быстро формируют остаточную реверберацию. В большом помещении, например ангаре для самолетов, наоборот, отраженные волны преодолевают большие расстояния и для формирования реверберации требуется больше времени.
· High-frequency cut-off - отбрасывание высокочастотных компонент звука. Когда материал стен или объхектов отражает звук, не все частотные компоненты отражаются с одинаковой степенью. Большинство материалов поглащают частоты определенного значения, т.е отбрасывается часть высокочастотных компонент. Например в ванной комнате отражаются звуки с частотой вплоть до 14000 Гц, а вгостинной комнате с коврами на стенах отбрасываются все компоненты с частотой более 2000 Гц.
· Early reflection level - уровень интенсивности ранних отражений. Ранние отражения дают возможность пользователю определить наличие близких объектов и стен. Чем больше предметов и стен находится близко к пользователю тем большим будет процент ранних отражений в общей звуковой картине. Например, близкорасположенные стены из кирпича в коридоре формируют большое количество ранних отражений,а открытое трявяное поле не формирует ни одного раннего отраженного звука.
· Reverberation level - уровень интенсивности реверберации. Уровень громкости реверберации может варьироваться при смене одного помещения на другое.
· Reverberation decay time - время затухания реверберации. Это время, необходимое для того, чтобы реверберация была полностью поглощена воздухом и стенами в помещении. Например, в большом ангаре со звукоотражающими стенами время реверберации порядка 10 секунд, в палате со стенами из войлока очень хорошо поглощающих звук, время затухания реверберации около 0.2 секунды.
· High Frequency decay time - время затухания высокочастотных компонент звука. Время затухания высокочастотных компонент напрямую завист от свойств окружающих объектов и стен. Например мрамор хорошо отражает высокочастотные звуки, а под водой высокочастотные компоненты очень быстро затухают.
· Density - плотность. Плотность отраженных звуков зависит от числа объектов, от которых отражается звук. Чем выше плотность, тем быстрее отраженные звуки переходят в реверберацию. Закрытая комната со звукоотражающими стенами имеет очень высокую плотность отражений, по сравнению с открытым полем.
· Diffusion - рассеивание. Величина, показывающая с какой степенью звуковые волны совмещаются или разделяются при соприкосновении с поверхностями в помещении. Комната с разнообразными по форме объектами созадает высокую степень диффузии звука, чем простот пустая комната с голыми стенами. Многие концертные залы имеют такую форму, что возникает диффузная реверберация.
· Detuning - расстройка. Расстройка может использоваться для симуляции изменения тональности звука, которая возникает при отражении звука от движущихся поверхностей. Может изменяться как величина, так и глубина расстройки. Применяется, например, для симуляции плеска волн на ветру.
Нетрудно заметить, что хотя мы рассмотрели технологию EnvironmentFX самой последней в статье, она, несомненно самая важная из применяемых на практике разработок Sensaura.
В видении компании Aureal (Wavetracing)
Для создания полного ощущения погружения в игру, необходимо рассчитать акустическую среду окружения и ее взаимодействие с источниками звука. По мере распространения звуковой волны, она ослабляется, т.е. находится под воздействием среды, в которой она распространяется. При распространении звуковые волны достигают слушателя различными путями:
· Они могут следовать по прямому пути к слушателю (direct path).
· Один раз отразившись от объекта (путь первого отраженного звука -- first order reflected path).
· Отраженный дважды (путь вторично отраженного звука -- second order reflected path) и более раз.
· Звуки могут так же проходить сквозь объекты, такие, как вода или стены (occlusions или звук, прошедший сквозь препятствие).
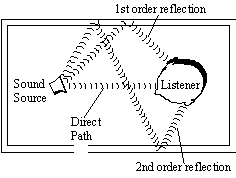
Алгоритмы обсчета путей распространения звуковых волн (wavetracing) компании Aureal воспроизводят эффект распространения звука в окружающей среде; причем это немалая работа с любой точки зрения. В документации с сайта Aureal алгоритмы wavetracing описываются так:
Технология Wavetracing компании Aureal анализирует геометрию описывающую трехмерное пространство для определения путей распространения звуковых волн в режиме реального времени, после того, как они отражаются и проходят сквозь пассивные акустические объекты в трехмерной окружающей среде.
Существуют три главных компонента: интерфейс A3D, geometry engine (геометрический движок, определяющий геометрию объектов в пространстве) и scene manager (менеджер сцены). Интерфейс A3D является основным компонентом. Один в отдельности он используется для реализации прямых путей распространения звука (direct path). Geometry engine является основным компонетом для обсчета отраженных и прошедших сквозь препятсвия акустических звуковых волн или для Acoustic Wavetracing. Менеджер сцены используется как геометрическим движком, так и интерфейсом A3D для управления сложными звуковыми сценами. Обработка каждого из этих компонетов будет производиться именно в таком порядке.
Взаимосвязь и функционирование менеджера сцены, геометрического движка и реализация прямых путей распространения звука показаны ниже:
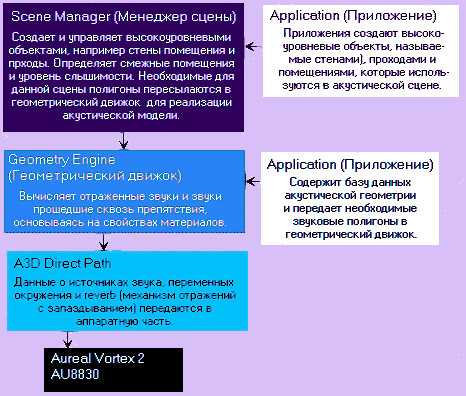
Прямые пути распространения A3D звука
Реализация прямых путей распространения A3D звука содержит 4 компонента: источник звука (Sound source), окружающая среда, в которой распространяется звук, слушатель (или приемное устройство) и отраженный звук с запаздыванием (late reflections).
Источник звука (Sound source)
Источник звука описывается на основе информации о его местоположении, направленности и угла конуса (угол между лучем слышимости и границей звука, распространяемого источником). Если источник звука динамичен, т.е. движется, то применяются дистанционная и допплеровская модели. Для эффективного распределения ресурсов, источники звука располагаются в соответствии с приоритетом.
Дистанционная модель: В дистанционной модели определяется масштабный коэффициент, который контролирует эффективность увеличения количества источников звука на расстоянии. В результате определяется минимальная дистанция для начала увеличения количества источников звука и максимальное расстояние, на котором этот процесс прекращается.
Допплеровская (Doppler) модель: В этой модели определяется скорость распространения звука, высота звука и масштабы применения эффекта Допплера (эффект Допплера заключается в том, что при движении источника волны относительно приемника изменяется длина волны. При приближении источника звука к приемнику длина волны уменьшается, а при удалении растет на величину, определяемую по специальной формуле).
Слушатель
Слушатель определяется свойствами, включающими местоположение, направленность и скорость перемещения.
Окружающая среда
Окружающая среда представляет вещество, окружающее распространяющийся звук. После начала распространения звуковой волны, она начинает проходить через окружающую среду, в которой с волной могут происходить разные вещи: она поглощается воздухом, причем степень поглощения зависит от частоты волны, наличия ветра (т.е. движения воздуха) и влажности воздуха.
В интерфейсе A3D 2.0 окружающая среда определяется свойствами и задается особым образом, описанным ниже. Эти переменные окружающей среды вероятно будут применяться ко всем источникам звука внутри сцены. С аппаратной точки зрения, чипсет Vortex 2 объединяет атмосферные фильтры внутри своего блока реализации A3D звука. По всей вероятности, ввод данных, основанных на переменных окружающей среды осуществляется с применением фильтров, которые должны имитировать различные изменения звука во время прохождения через разные атмосферные среды.
Свойства окружающей среды A3D звука
Заранее задаваемые свойства окружающей среды:
· Воздух и вода.
· Скорость распространения звука.
· Высчокочастотное затухание, зависящее от окружающей среды.
· Степень затухания звукового сигнала с увеличением расстояния от источника до приемника.
Звук, отраженный с запаздыванием (Late Reflections)
Использование отраженного звука предоставляет способ точно определить местоположение источников звука, а так же размер, форму и тип помещения или окружающей среды, в который мы находимся. Чипсет Vortex 2 имеет возможность оперировать до 64 трехмерными источниками отраженного звука. Это осуществляется благодяря использованию геометрического движка, который моделирует ранние отраженные звуки. Ранние отраженные звуки (early reflections) относятся к звукам, отраженным в первую очередь.
Запаздывающий отраженный (late order reflections) звуковой сигнал воспринимается как эхо или реверберация (reverberation). Вот разумное объяснение этому: человек имеет возможность индивидуально воспринимать первый отраженный звук, в то время как второй и все последующие отраженные звуки обычно смешиваются в форму поля запаздывающих отраженнных звуковых сигналов или просто эхо.
Лучше всего эхо проявляется на очень больших пространствах, когда требуется большое время для затухания сигнала. Хорошим примером является медленное перемещение внутри кафедрального собора или большой пещеры, когда при движении вы слышите долго длящееся эхо. От свойств окружающей среды зависят параметры, определяющие запаздывающий отраженный сигнал.
Переменные механизма расчета звуков, отраженных с запаздыванием (reverb):
· Варьирование уровней входного и выходного звукового сигнала, отраженного с запаздыванием.
· Предварительная задержка искусственного эха (reverb).
· Время затухания запаздывающего отраженного звукового сигнала.
· Ясность (четкая различимость) запаздывающего отраженного звука.
В настоящее время нет возможности использовать поле запаздывающего эха, но такая возможность будет доступна после модернизации драйверов, и, возможно, будет включена в интерфейсе A3D 2.1.
Механизм построения геометрических фигур в пространстве
Геометрический движок или geometry engine в интерфейсе A3D 2.0 это уникальный механизм по своей возможности моделирования отраженных и прошедших сквозь препятствия звуков.
В отличии от менеджера сцены, геометрический движок оперирует с данными на уровне геометрических примитивов: линий, треугольников и четырехугольников. Геометрия может быть определена в двумерном или трехмерном пространстве, соответственно, в случае 3D геометрии, вычисления могут быть очень интенсивными.
Геометрический движок может быть задействован приложением с помощью менеджера сцены или напрямую, для полного контроля над описанием путей распространения волн. В последнем случае, приложение содержит базу данных звуковой геометрии и передает только необходимые в данный момент звуковые полигоны в геометрический движок.
Геометрический движок использует полученные звуковые полигоны для построения системы координат, определяющей взаимное расположение слушателя и источников звука.
Звуковой полигон (audio polygon) имеет местоположение, размер, форму, а также свойства материала из которого он сделан. Форма полигона и его местоположение в пространстве связаны с источниками звука и слушателем, влияя на определение того, как каждый в отдельности звук отражается или проходит сквозь полигон. Свойства материала, из которого состоит полигон, могут изменяться от полностью прозрачного для звуков до полностью поглощающего или отражающего.
Очень важно иметь минимальную по размерам базу данных акустических полигонов, что бы минимизировать загрузку CPU. В играх должно быть задействовано около 50 звуковых полигонов в любой момент времени. Этого количества достаточно для описания сложной акустики и представления всех важнейших случаев прохождения звуков сквозь препятствия. Более того, звуковые полигоны должны быть так же точно определены, как и их эквиваленты в графике.
Материалы
Каждый раз, когда звук отражается от объекта, материал из которого сделан объект влияет на то, как сильно поглощается каждый частотный компонет звуковой волны и как много компонетов отражается обратно в окружающую среду. Материалы, используемые для звуковых полигонов могут быть определены в интерфейсе A3D 2.0.
Переменные материалов:
· Заранее определенные материалы: дерево, бетон, сталь, ковер.
· Отражающие свойства: меняются от полностью отражающих до совсем неотражающих звуки.
· Свойства звуковых преград: меняются от полностью прозрачных до непрозрачных для звуков.
После ввода всех необходимых данных, геометрический движок вычисляет ранние отраженные звуки и звуки прошедшие сквозь препятствия, основываясь на свойствах материалов. Уровень детализации звучания и режим реализации акустической модели могут быть установлены с помощью геометрического движка.
Звук прошедший через преграду (occlusions): геометрические алгоритмы вычисляющие то, как звук преодолевает преграду в виде поверхностей. Точность и качество реализации могут быть принесены в жертву скорости вычислений.
Один раз отраженные звуки: вновь, качество реализации может быть принесено в жертву скорости вычислений.
Менеджер сцены
Менеджер сцены использует высокоуровневую базу данных звуковой геометрии и управляет звуковыми полигонами, используемыми в сцене. Приложения создают высокоуровневые объекты, называемые стенами (walls), проходами (openings) и помещениями (rooms), которые могут быть использованы в акустической сцене. Обычно, программа загружает сцену и просто вызывает функцию реализации. Менеджер сцены использует акустическую сцену для определения соседства помещения (т.е. что смежно с помещением) и уровень слышимости. Слышны только те звуки, которые распространяются в помещении, где в данный момент находится слушатель, и звуки в смежных помещениях. Менеджер сцены определяет необходимые для данной сцены полигоны и пересылает их геометрическому движку для построения акустической модели.
Примеры высокоуровневых объектов:
· Стены: имеют свойства материала из которого они сделаны. Они могут двигаться и менять ориентацию в пространстве. Не все сцены должны отражать звук.
· Проходы: это отверстия в стенах; звук перемещается от одной стороны стены к другой стороне. Проходы могут быть открытыми и закрытыми.
· Помещение: это пространство, которое со всех сторон полностью окружено стенами.
· Сцена: это набор из помещений.
Менеджер сцены от Aureal описывет пути распространения звуковых волн для каждого уровня в форме упрощенных полигонов.
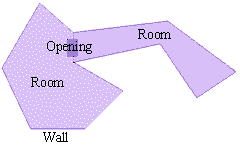
Использование технологии Wavetracing в играх
Реализация wavetracing весьма сложна. Существуют простые высокоуровневые способы доступа (через менеджер сцены и загрузчик сцены) для людей, которым нужен быстрый результат. Дополнительно, доступно управление на низком уровне для разработчиков, которые хотят "сделать акустику действительно ошеломляющей, т.е. совершенно на новом уровне".
Быстрый и простой способ расчета путей распространения звуковых волн
Быстрый и грубый способо добиться этого, это использовать менеджер сцены. По мнению Скипа Макилвейна (Skip McIlvaine) из Aureal, база данных графической геометрии может быть пропущена через конвертер, который преобразует все необходимые графические полигоны в звуковые полигоны за время загрузки уровня игры. Глобальные значения могут быть установлены для параметров объектов отражающих и препятствующих звуку. Кроме того, возможно произвести обработку базы данных графической геометрии заранее, прогнав алгоритм преобразования полигонов и храня базу данных звуковой геометрии в качестве отдельного файла-карты и подгружать этот файл во время загрузки уровня игры.
Тонкая регулировка wavetracing
Существует несколько способов, с помощью которых разработчик звукового оформления может тонко регулировать пути распространения звуковых волн для достижения лушей производительности и эффекта реалистичности:
· Индивидуально выбирать толщину стен и материал, из которого они сделаны.
· Заранее подготовить установки эха (reverb) для помещений.
· Оптимизировать акустическую геометрию с целью использования минимального набора полигонов.
Законченная картина
Результатом является последний шаг в сторону истинного реализма создаваемого звука: комбинация из 3D позиционируемого звука, акустики помещений и окружающей среды и точное представление звуковых сигналов для слушателя. Моделирование окружающей среды, реализованное Aureal, не имеет аналогов, даже EAX от Creative Labs не может сравниться по набору предоставляемых возможностей. Тем не менее, технология EAX более проста в реализации и меньше загружает CPU.
Технология Wavetracing не является быстро реализуемым эффектом, который может быть добавлен и так же легко использован, как запаздавшая мысль. Необходимо серьезное планирование перед реализацией. Первые несколько игр, которые будут использовать Wavetracing, возможно будут использовать все преимущества лишь на 50% от всего имеющегося потенциала. Но даже при этом, эти игры будут самыми передовыми, чем все остальные, созданные до них. Первые игры, сделанные с использованием технологии Wavetracing, появились уже в 1999 году. Они были поистине ошеломляющими. В любом случае, A3D 2.0 и Wavetracing были разработаны чтобы стать основными 3D технологиями, которые могут быть использованы всеми разработчиками, т.е. нечто вроде OpenGL для звука.
Печально, что такой перспективной наработке придется пропасть, либо исчезнуть в недрах конкурента. Недавно фирма Aureal. Ее тут же попытался купить основной конкурент – Creative Labs, но эта сделка по определенным причинам не состоялась. Дальнейшее будущее компании неизвестно. Будем надеяться, что потенциал инженеров и разработчиков не пропадет даром, благо опыт перерождения у них уже есть: в свое время с рынка исчезла достаточно известная компания Media Vision, а родилась – Aureal.
В видении компании EAR
Что такое Interactive Around-Sound (IAS)?
Проще говоря, IAS это новый звуковой движок (audio engine), который дает возможность на всех компьютерах (при наличии минимум Windows95 и DirectX5) создавать одинаковое 3D звучание вне зависимости от того, какое аппаратное обеспечение для воспроизведения и создания звука используется. Главный козырь IAS это поддержка воспроизведения звука на более чем через две акустические колонки (т.е. поддержка multi-point технологии воспроизведения звука).
IAS это тоже самое что и A3D или EAX?
Нет. IAS разработана с целью заменить A3D и EAX там, где имеется возможность воспроизведения звука через более чем две колонки, так как EAR считает, что A3D 1.0 и EAX 1.0 не могут полноценно использовать множество акустических колонок.
Будет ли IAS работать совместно с A3D или EAX?
Да. IAS поддерживает обе технологии A3D и EAX, создающие виртуальный 3D звук (т.е. трехмерный звук через две колонки).
Преимущества при использовании IAS вместо A3D или EAX
IAS не требует наличия специального аппаратного обеспечения. IAS обеспечит то звучание звука, которое заложено разработчиком приложения вне зависимости от того, какая звуковая карта используется. Это означает, что приложение созданное с помощью IAS будет воспроизводить звук при использовании звуковых картах от Guillemot, Diamond и ряда других, так же, как и при воспроизведении через Dolby, DTS и MP3 декодеры без необходимости какой-либо перекомпиляции. Кроме того, IAS может воспроизводить звук через две колонки (Phantom IAS), соответствующим образом накладывая звуковые каналы, если только такой вариант внешней акустики доступен. Это позволяет любому пользователю слушать 3D звук, создаваемый IAS движков независимо от аппаратного обеспечения, которое есть в наличии. Тот же интерфейс Phantom IAS позволяет получить 3D звук на системах не оснащенных аппаратным акселератором.
Microsoft не имеет стандарта на воспроизведение DirectSoun/DirectSound3D звука на более чем две колонки. Различные производители звуковых карт используют свои собственные алгоритмы воспроизведения DirectSound3D звука, причем расчет того, какой звук будет воспроизводиться из каждой колонки перекладывается на CPU. При этом каждый производитель использует собственную технику и в результате, одна и та же игра будет звучать по-разному на разных звуковых картах. Использование IAS устраняет эту проблему.
IAS работает на любой звуковой карте, которая работает через DirectX5. Некоторым звуковым картам требуется дополнительное программное обеспечение для того, чтобы была возможность использования более двух колонок при воспроизведении звука.
Заключив партнерское соглашение с Creative Labs, EAR теперь поддерживает все доступное в настоящее время аппаратное обеспечение от Creative, имеющее возможность воспроизводить звук через более чем две колонки.
Будет ли IAS работать с любой игрой?
Нет, игра должна быть написана с учетом поддержки звукового движка. Все, что использует DirectSound или работает под Windows95 можно портировать, т.е. встроить поддержку IAS.
Как работает IAS?
IAS использует систему наложения координат, которая интерполирует местоположение звукового события и конвертирует это местоположение с определенным уровнем затухания звука для каждой акустической колонки при заключительном микшировании. Независимо от того, как много колонок подключено один и тот же код используется для каждого варианта, а это означает, что звуковой движок очень мал и компактен по размерам, но при этом поддерживает множество разных аппаратных конфигураций. Этот "напиши один раз, исполняй потом везде" код делает решение от IAS очень привлекательным для разработчиков, многие из которых используют IAS и для интерактивных и для не интерактивных приложений.
Есть два аспекта индустрии персональных компьютеров, с которыми напрямую сталкивается пользователь: видео и звук. При оценке качества игры пользователь, прежде всего, смотрит на то, насколько реалистичны графические и звуковые эффекты, а не то, насколько быстро данные перекачиваются с CD или жесткого диска. Наряду с ростом вычислительной мощности процессоров для PC и емкости носителей информации, особое внимание всегда уделяется увеличению производительности видео акселераторов и скорости перекачки данных с CD/DVD/HDD, в то время как на долю звука остаются лишь избытки ресурсов. При такой философии разработчиков, развитие компьютерного звука долгое время оставалось на уровне стерео решений (воспроизведение через две акустические колонки). Еще год назад, широкое распространение получила технология воспроизведения 3D звук через две колонки с использованием алгоритмов HRTF, IAD, ITD и т.д.
К несчастью, для воспроизведения 3D звука требуется больше, чем просто алгоритмов создания эффекта окружающего звука (surround sound). Человеческое ухо может определять движение только при высокой частоте (около 10000 Гц). Однако типичная частота дискретизации, используемая при создании HRTF эффектов, находится ниже этого порога (частота дискретизации 11.025 kHz может обеспечить частоту звучания только на уровне 5000 Гц), что заставляет уши реагировать на другие звуковые компоненты для определения истинного положения источника звука. Из одиннадцати звуковых компонентов, используемых мозгом для определения местоположения звукового события, только до трех (включительно) моделируются в современных звуковых решениях. Это означает, что многие пользователи просто не услышат никаких 3D звуковых эффектов.
Есть два способа решения этой звуковой проблемы. Первый относится к управлению распределением ресурсов частоты дискретизации с целью сделать соответствующие частоты доступными для использования, чтобы помочь пользователю слышать эффекты 3D звука. Второй способ заключается в утверждение стандарта на использования тыловых колонок сзади пользователя для PC платформы. Так как управление ресурсами может быть реализовано в хорошем звуковом движке (например, IAS), главная забота это убедить пользователей в том, что использование "более двух акустических колонок" для воспроизведения звука это норма. Эта забота существенно упростилась с появлением звуковых карт, поддерживающих воспроизведение через четыре колонки и всевозможных компьютерных устройств и приставок (set-top-box, Living Room PC), рассчитанных на воспроизведение окружающего звука (surround sound) и даже AC-3.
Компания Extreme Audio Reality, Inc. (EAR) работает с разработчиками и производителями аппаратного обеспечения с целью достичь высококачественного звучания с учетом использования имеющихся ограниченных ресурсов. Результатом этого сотрудничество стало создание технологии Interactive Around-Sound (IAS), запатентованной техники для реализации воспроизведения 3D звука на всех доступных платформах. IAS позволяет разработчикам "write once, run anywhere" (написав один раз, запускать везде) получая трехмерный звук на любой платформе, путем определения какое аппаратное обеспечение доступно для использования. IAS была разработана для создания высококачественного, действительно интерактивного 3D звука без ущерба производительности всей системы в игре, т.е. получив 3D звук, вы не потеряете значений fps.
"Напиши и запускай"
Главная забота для разработчиков игр состоит в предоставлении пользователю высококачественного продукта с реалистичной графикой и звуком. Microsoft предлагает разработчикам использовать набор интерфейсов DirectX, в который входят API для создания видео и звука для игр. Однако, в DirectX уделяется слишком много внимания совместимости со старым аппаратным обеспечением и слишком мало современным технологиям, в результате чего разработчики получают неэффективное средство создания настоящего 3D звука (с каждой новой версией DirectX ситуация улучшается, но происходит это очень медленно). IAS была разработана для управления всеми звуковыми ресурсами необходимыми дизайнеру звука и включает в себя поддержку DirectSound, DirectSound3D и других реализаций surround sound. В результате программист может потратить больше времени на создание реалистичного взаимодействия с 3D звуком и меньше заботиться о буферизации, распределении потоков и совместимости с аппаратным обеспечением.
Любой дизайнер звука, который работал с DirectSound от Microsoft, знает, что имеется много мест, в которых можно улучшить то, как DS управляет звуком. Эти разработчики высоко оценят IAS, если встроят его звуковой движок в свою игру. EAR создала IAS для работы совместно с DirectSound, поэтому при использовании IAS корректируются многие недостатки DirectSound и в результате получается высококачественное звучание.
На уровне интерфейса IAS обеспечивает по настоящему раздельное, динамичное определение местоположения звуковых событий:
· Распределение ресурсов и управление буферизацией/потоками происходит автоматически
· Все вычисления, связанные с расположением источников 3D звука в пространстве и расчет скорости распространения звука осуществляются автоматически
· Автоматически вычисляются эффект Допплера, высота, удаленность, время задержки для звуков и другие управляющие факторы
· Любое звуковое событие можно разрешить или запретить для воспроизведения
· Все звуковые события полностью независимы от других звуковых событий
Плюс ко всему, звуковой движок автоматически конфигурирует выходные звуковые потоки с целью использовать все преимущества решений 3D звука:
· Специализированные звуковые карты, имеющие выход на тыловые колонки (т.е. поддерживающие воспроизведение через четыре колонки), поддерживаются в первую очередь. Через такие звуковые карты обеспечивается воспроизведение настоящего интерактивного surround звука.
· При наличии внешних декодеров, выходные потоки автоматически кодируется, для воспроизведения звука через системы Dolby Pro-Logic, AC-3, DTS и т.д.
· Решения типа SRS, Q3D и A3D поддерживаются на уровне интерфейса DirectSound
· При использовании звуковых карт, поддерживающих воспроизведение только через две колонки, реализована полная совместимость с DirectSound3D
Разработчику надо лишь один раз написать звуковой код, так как все звуковой аппаратное обеспечение, рассчитанное на Windows95/98 поддерживается через одинаковый интерфейс программирования. После чего игра будет звучать на любой звуковой карте, работающей через DirectX.
"Нужно услышать, чтобы поверить"
IAS от EAR имеет много преимуществ по сравнению с другими звуковыми решениями. Накладные расходы при использовании IAS очень маленькие, при этом звуковой движок всегда обеспечивает пользователю наилучшее звучание для доступной конфигурации. Технология IAS создавалась с целью быть вперед совместимой. Это означает, что разработчики, используя звуковой движок IAS при написании игр для сегодняшнего аппаратного обеспечения, могут быть уверены, что завтра, когда появится новое аппаратное обеспечение, звучание в игре все равно будет таким, каким оно задумывалось.
IAS создавалась и тестировалась людьми, чей опыт в качестве звуковых инженеров существенно превосходит их опыт работы в качестве компьютерных программистов. Это означает, что основное внимание было уделено на переносе работы на управление ресурсами, чтобы обеспечить наивысшее качество звучания на доступной системе, а не на попытке обеспечить низкокачественно звучание на "приемлемом" уровне. Плюс ко всему, основной упор был сделан на создание 3D звучания в играх. Звуковой движок был создан с целью воспроизведения истинного интерактивного "around-sound" (окружающего звука) через четыре или более акустических колонок, с возможностью воспроизведения через две колонки при необходимости. IAS уже сейчас поддерживает PC будущего, но при этом прекрасно работает на современных системах.
Кроме поддержки современных мультимедиа PC, EAR уделяет внимание новейшим Интернет технологиям (VRML, Indeo и т.д.), так что игры, созданные с использованием IAS автоматически совместимы с сетевыми вариантами. EAR поддерживает MIDI, DLS, S/P DIF, IEEE1395, USB и многие другие цифровые технологии передачи данных, что дает возможность разработчикам игр полностью использовать сегодняшние и завтрашние звуковые системы. Наш SDK обеспечивает полностью интуитивную возможность встраивания IAS в игру с помощью простых программ, которые могут помочь разработчику скомпилировать свое первое IAS приложение менее чем за десять минут.
Доступна техническая поддержка, чтобы помочь легко интегрировать технологию EAR в приложение.
Особенно важно то, что нет необходимости использовать другой звуковой движок в игре; IAS работает на любом существующем или будущем аппаратном обеспечении для 3D звука.
В видении компании Creative
EAX это API для создания звучания окружающей среды, созданный Creative. Цель EAX помочь разработчикам игр создавать ощущение реальности происходящего действия в игре с помощью звука. EAX это расширение DS3D, звукового API от Microsoft, являющегося частью среды для программистов DirectX. Оба интерфейса дополняют друг друга.
DS3D управляет позиционированием источников звука и ориентированием слушателя в виртуальном 3D пространстве игры. Например, разработчик может использовать DS3D для создания независимых источников звука для каждого персонажа в FPS игре, обеспечивая их различными голосами и звуками оружия с ясно различимой принадлежностью каждому персонажу. Эти источники звука могут перемещаться в 3D пространстве, также как и слушатель (игрок), который слышит звук. Разработчик игры может использовать DS3D для управления источниками звука, изменяя такие нюансы, как характер направленности (источник может распространять более громкий звук в одном направлении) и действие эффекта Допплера (увеличение высоты тональности при приближении источника звука к слушателю и снижение тональности при удалении).
EAX расширяет возможности DS3D за счет создания мира вокруг источников звука и слушателя - т.н. виртуальную звуковую среду окружения. Эта звуковая среда создается за счет моделирования отражения звуков и реверберации, исходящих со всех сторон от слушателя. Волны отраженных звуков и реверберация, достигая слушателя, дают ему возможность составить представление о природе окружающей его среды - размерах помещения, отражающих свойств стен и многое другое. Разработчики могут использовать EAX для простой установки различных типов свойств акустики для разных помещений и мест в игре. Например, играя в игру, поддерживающую EAX, игрок может слышать, как изменяется акустика при переходе их коридора в пещеру.
В дополнение к созданию звуковой окружающей среды, EAX 1.0 может также, внутри звуковой окружающей среды значительно усилить ощущения восприятия расстояния до различных источников звука: интерфейс автоматически подстраивает индивидуальные параметры источников реверберации, когда каждый источник звука изменяет свое местоположение в пространстве, т.е. расстояние до слушателя изменяется. При этом EAX находится в стадии развития: в следующей версии (EAX 2.0) будет сделан значительный шаг вперед с целью улучшения интерфейса программирования и акустической модели используемой для создания звуковой окружающей среды.
С точки зрения поддержки в приложениях аппаратного обеспечения от Creative и Emu, существует нечто большее. "Presets" (заранее сделанные установки EAX) в линейке звуковых карт Creative SB Live! дают возможность пользователю добавлять эффекты звука окружающей среды в самые популярные старые игры. Плюс к этому, аппаратное обеспечение Creative и Emu также поддерживает позиционирование источников звука в 3D пространстве, то, что используется любой игрой, написанной под DS3D.
EAX предоставляет очень эффективный интерфейс программирования, который очень интуитивен в использовании. Он предоставляет три различных типа управления:
1. Обширный выбор заранее сделанных установок звучаний окружающей среды ("presets"), который дает возможность очень просто выбрать требуемый тип окружающей акустики.
2. Набор параметров интерфейса, которые дают возможность делать собственные настройки для заранее установленной акустики окружающей среды, применяется к любому индивидуальному источнику звука или ко всем источникам звука одновременно.
3. Автоматическое изменение важнейших параметров в зависимости от местоположения источников звука. Когда источники звука двигаются относительно слушателя, EAX автоматически моделирует естественное поведение реверберации и отраженных звуков с целью улучшить восприятие того, что источник звука удаляется или приближается и правильного воспроизведения процесса перемещения источников звуков в акустической окружающей среде.
В результате продолжающихся разработок, в EAX будет добавляться больше возможностей по управлению акустикой окружающей среды, с целью обеспечить слушателю более богатые ощущения. Все улучшения, которые будут введены, можно разделить на две категории:
1. Расширенное управление акустикой окружающей среды. Программист может изменять размеры помещения и манипулировать параметрами ранних отраженных звуков отдельно от затухающей реверберации с запаздыванием. Это позволяет разработчикам создавать реалистичные и полные модели широкого диапазона акустики окружающей среды, начиная от полуоткрытых пространств (например, городской двор, улица и т.д.) и заканчивая узким коридором или маленьким тесным кабинетом.
2. Добавление эффектов окклюзии и обструкции и управления за ранними отраженными звуками для каждого источника звука. Эти эффекты или отраженные звуки могут подчиняться или не подчиняться правилам графического/физического описания виртуального мира - все зависит от мнения программиста, от его или ее виденья того, что нужно в игре и от эмоционального воздействия, которое должна оказывать игра.
Окклюзии и обструкции, как они улучшают ощущения от игр
EAX окклюзии (occlusions - звуки, проходящие через препятствия) применяются для моделирования источников звука, расположенных в другом помещении или в пространстве с другой стороны стены. Окклюзии имеют свойства, при изменении параметров которых меняются характеристики звукового сигнала, проходящего сквозь препятствия, в результате моделируются различные типы стен, состоящие из разных материалов и имеющие различную толщину. Например, если слушатель находится внутри дома, т.е. в помещении, а источник звука находится снаружи, тогда приложение может использовать свойства окклюзии для воспроизведения реалистичного звучания голоса или шума, так если бы они действительно слышались из-за двери или снаружи дома, в котором находится слушатель.
Использование свойств обструкции (obstruction, звук задерживается препятствием) позволяет моделировать дифракцию звука препятствием для создания ощущения, что источник звука находится в той же окружающей среде, что и слушатель, но закрыт от слушателя преградой. Возвращаясь к предыдущему примеру, использование свойства обструкции может сделать звучание голоса таким, будто его источник расположен за большой колонной в той же комнате, что и слушатель, при этом, звук не проходит сквозь колонну.
EAX
Модель распространения света, основанная на геометрии пространства, повсеместно используется в графическом мире и известна под названием "ray tracing" (распространение лучей), имеет акустический эквивалент. Для реализации геометрической акустики требуется компьютерная модель физического пространства: четкое определение того, какой объект и где расположен и какие звукоотражающие или звукопроводящие свойства имеет каждый объект. Затем рассчитывается количество слышимых пользователем звуков, отраженных от этих объектов для каждого источника акустики. Также, в расчет могут приниматься ослабление звукового сигнала во время прохождения сквозь стены или преграды на пути прямого распространения звуковых волн и каждого из отраженного звука. Ray tracing и другие модели распространения звуков на основе геометрии пространства - такие, как метод зеркальных источников звука - являются техниками, зависимыми от времени и широко применяются в качестве поддержки при вычислении акустики помещений в архитектурном дизайне. Подобная техника допускает, что звуковые волны отражаются в "зеркальной" форме, которая является аппроксимацией игнорируемых дифракции и диффузии звука. Совсем недавно, этот метод геометрического моделирования был адаптирован для воспроизведения 3D звука в некоторых экспериментальных интерактивных системах виртуальной реальности.
Модель распространения звука, основанная на геометрии пространства, такая, как ray tracing, может быть очень привлекательна для использования в API трехмерного звука. Разработчик просто определяет модель 3D звукового мира, располагает источники звука и слушателя в этом мире, а затем механизм ray tracing определяет пути распространения звуковых волн для завершения работы по созданию реалистичной акустической окружающей среды. На практике, тем не менее, такое применение геометрической модели в мире интерактивного компьютерного звука имеет несколько серьезных недостатков.
Полный расчет отражений от множества объектов для нескольких источников звука является сложной задачей. Не смотря на то, что физические принципы лежащие в основе геометрической модели просты (и обеспечивают лишь аппроксимацию реальных отражений звука) для ее расчета требуется серьезные вычислительные ресурсы. Главное следствие, в 3D играх, это то, что техника расчета распространения акустических волн (ray tracing) может оперировать лишь ограниченным числом отраженных звуков и не может быть использована для воспроизведения затухания запаздывающей реверберации. Чтобы понять, почему это так, рассмотрим источники звука в реальном мире.
Источники звука испускают звуковые волны, которые отражаются от первого объекта, которого достигнут, затем от второго объекта, затем от третьего, и т.д. В обычном помещении существует бесконечное число непрямых путей распространения звуковых волн от источника звука через отражение к слушателю. Когда эти отраженные звуковые волны достигают слушателя, запаздывающие отражения все больше и больше ослабляются, и следуют друг за другом все ближе и ближе по времени. Эти запаздывающие отраженные звуки быстро формируют континуум (сплошную среду), известный как "реверберация". Так как сложность полной модели увеличивается экспоненциально с течением времени, на практике моделирование геометрической акустики в реальном времени должно быть ограничено одним "отскоком" от препятствия ("первоочередные" ранние отраженные звуки) с целью экономии ресурсов CPU. Следовательно, механизм расчета распространения акустических волн в реальном времени не может использоваться для расчета затухания запаздывающей реверберации, которая является составной частью отраженных звуков в типичной акустической среде. В результате 3D звуковой окружающей среде не хватает живости и ощущения реалистичности. Это также приводит к несовместимости, так как первоочередной отраженный звук может стать явным, а затем исчезнуть, согласно физической модели - появляется чувство разочарования, потому что ожидаемого эффекта нет, так как нет запаздывающей реверберации для заполнения свободного акустического пространства, когда первоочередные отраженные звуки исчезают. Для избавления от этой проблемы, в интерфейсе EAX от Creative используется статичная модель распространение звуков, которая оперирует ранними отражениями и затуханием запаздывающей реверберации, и, следовательно, обеспечивает более полное и сильное ощущение звуковой окружающей среды.
Другая серьезная проблема с моделью распространения на основе геометрии пространства, применительно к звуку, состоит в том, что разработчик должен создать и манипулировать сложной моделью акустической окружающей среды для создания отраженных звуков. Поэтому, акустика, базирующаяся на геометрии пространства, может применяться для очень впечатляющих демонстрационных программ, но очень сложна для эффективного использования в реальных приложениях.
Создание эффективной акустической модели это не простая задача, как об этом могут говорить дизайнеры акустики в реальном мире. Дизайнер может потратить месяцы, и даже годы для создания холла с приемлемой акустикой, но даже тогда он может не добиться успеха. Разработчики игр оказались перед этой проблемой дизайна в виртуальном мире при использовании геометрической модели: правильно ли они определили коэффициент поглощения звука для этой стены? Достаточно ли прозрачен для звука этот объект? Им приходится произвести массу настроек, чтобы все было правильным, даже если геометрический API обеспечивает их списком материалов, из которых программист может выбирать. Кроме того, в дополнение к необходимости определения свойств материалов, обычно существует необходимость преобразования графической геометрической информации в форму, которую может использовать звуковой механизм (движок). И то и другое не является простой рутинной задачей.
Последнее и возможно самое важное замечание для игроков и разработчиков заключается в том, что геометрическое моделирование может создавать только конечный результат, который по своей природе является ограниченным, даже с точки зрения производящего сильное впечатление качества звука. Даже если геометрическая модель акустики сможет создать безупречную копию реальной звуковой сцены, эта форма реализма не всегда будет подходящей или эффективной для озвучивания, о чем хорошо осведомлены звукоинженеры киностудий. Слух является в большей степени чувством внутренних ощущений, чем зрение. Для создания наилучшего ощущения от звука, часто требуется использование звуковых эффектов, которые очень далеки от тех, которые могут существовать в физической реальности. Вот почему многие звуки в фильмах - от шуршания одежды до оружейных выстрелов - часто заменяются звуками, которые были "подправлены". Также на звуковых дорожках к фильмам часто записывают имитацию реверберации, подобно той, которую воспроизводится с помощью EAX.
Использование EAX реверберации позволяет создавать в играх виртуальную акустическую окружающую среду, которая отличается от среды, изображаемой на мониторе. В этой виртуальной акустической среде персонажи или объекты звучат так, будто они находятся ближе или дальше от слушателя, чем это выглядит на экране, т.е. плоскому изображению сообщается объем. API EAX создан с целью обеспечить именно такую форму звучания, в тоже время, все задачи по внедрению интерактивности в игру перекладываются на процесс звукового дизайна, т.е. это дело разработчика, как, и в каких объемах использовать и добиваться интерактивности звучания.
Разработчики игр, как и режиссеры фильмов, хотят управлять степенью выразительности и качеством своих 3D звуковых сред окружения, а значит, хотят найти соответствующий инструментарий в EAX. Их потребности не так просто удовлетворить в геометрических моделях, подобных ray tracing. Например, если вы решили увеличить время затухания реверберации для обеспечения более сильного ощущения благоговения при имитации кафедрального собора, в модели типа ray tracing не существует простой кнопки управления длительностью времени затухания reverb. Вместо этого вы можете увеличить размеры звуковой геометрической модели, отодвинув стены дальше от слушателя, чтобы добиться требуемого эффекта. Это сложно сделать и, что еще хуже, в результате получается модель акустики, отличная от графической модели, вследствие чего могут возникнуть проблемы, например, если вы начнете двигать источники звука и графические объекты внутри созданной модели. И даже если вы справитесь с этими проблемами, вы получите модель акустики, которая не будет соответствовать законам физики. Вы не можете добиться одновременно и психологического реализма и эмоциональности, чего разработчики игр, как и режиссеры фильмов, хотят от создаваемого звучания.
В двух словах, EAX обеспечивает разработчиков лучшими параметрами для звукового дизайна, чем для архитектурного дизайна. И EAX реалистично моделирует ранние отраженные звуки и затухание запаздывающей реверберации, которые создают виртуальные объекты или стены.
Мы думаем, что первый фактор, определяет труднообъяснимо быстрое принятие EAX разработчиками приложений. Как отмечалось выше, параметры для звукового дизайна дают возможность разработчикам игр легко (по сравнению с геометрическим моделированием) создавать убедительное и эмоционально красивое ощущение от окружающей слушателя акустики. В EAX, первый набор параметров управляет тем, как слушатель ощущает окружающую среду (помещение, в котором находится слушатель), а второй набор параметров позволяет регулировать эффекты акустической окружающей среды для каждого звука в отдельности. Эти параметры интуитивно понятны разработчику, он может легко манипулировать ими, изменять или усложнять эффекты акустики окружающей среды в любой модели игры или сценария. EAX не требуется наличия перспективы от первого лица (читай слушателя) или привязки источников звука к графическому представлению виртуального мира. С другой стороны, дизайнер звука, который хочет создать звуковую сцену, которая наиболее близко и реалистично совпадает с графической сценой, может легко сделать это, используя громадные возможности EAX по управлению ранними отраженными звуками, эффектами окклюзии и обструкции.
При создании этих эффектов, EAX использует метод статистического моделирования вместо метода геометрического моделирования. Статистическая модель EAX автоматически вычисляет параметры реверберации и отраженных звуков, в зависимости от расположения слушателя относительно источников звука, размеров помещения, направленности источников звука и в зависимости от дополнительного набора параметров, которые может изменять программист.
EAX более прост и более гибок в использовании для программистов, потому что статистическое моделирование не требует полного геометрического описания акустического мира вокруг слушателя. Вместо этого он работает, используя макроскопические параметры, начиная от таких как размер помещения и времени реверберации и заканчивая динамическим вычислением параметров важнейших отраженных звуков и реверберации. Статистическое моделирование также более эффективно использует CPU, чем геометрическое моделирование, но при этом все равно более эффективно моделирует ранние отраженные звуки и реверберацию с запаздыванием, обеспечивая реалистичное воспроизведение глубины акустической сцены. В игре в любой момент могут изменяться заранее сделанные установки окружающей звуковой среды и настраиваться отдельные параметры простым нажатием кнопок управления для создания убедительного ощущения реалистичности акустики, при перемещении слушателя и источников звука из одной части виртуального мира в другую, в зависимости от любого события по сценарию игры.
Среди будущих возможностей EAX будет набор для интуитивного управления, с помощью которого можно будет полностью и эффективно манипулировать ранними отраженными звуками, а также запаздывающей реверберацией. Этот набор также позволит устанавливать параметры окклюзии, обструкции и эффектов перспективы для создания очень четкого впечатления окружающего звучания, если это потребуется. EAX позволяет программистам настраивать или модифицировать полностью или частично автоматическое управление отраженными звуками и реверберацией с целью создать в точности такую акустическую среду окружения, как он или она хочет, или, чтобы наложить требуемый эффект на один конкретный звук. Если необходимо, этот метод позволяет программистам использовать их собственную геометрическую модель с целью контролировать не только эффекты окклюзии и обструкции, но также и ранние отраженные звуки, в зависимости от геометрии стен и препятствий.
Creative наряду с другими компаниями работает в IASIG (Interactive Audio Special Interest Group), разрабатывая новый стандарт 3D звука. Какова роль Creative в этих разработках?
IASIG пригласила Creative внести EAX в качестве вклада в IASIG "Level Two Guidelines" ("Принципы управления второго уровня"). Цель этих принципов установить промышленный стандарт на интерфейс звуковой окружающей среды для разработчиков мультимедиа и игр для PC. Creative согласилась сделать EAX 1.0 открытым для промышленного использования и принять во внимание предложения членов IASIG по расширению нашей первоначальной задачи.
Creative легко реализует поддержку стандарта от IASIG, когда он будет закончен (так как он полностью основана на механизме EAX) и будет поддерживать совместимость с EAX 1.0 в своих драйверах. В действительности, такой стандарт может рассматриваться в качестве некоторого представления "EAX 2.0". Более того, мы продолжаем расширять EAX, с целью получить дополнительные преимущества от использования возможностей продуктов семейства SoundBlaster Live! не только при использовании EAX 1.0 или стандарта IASIG. Будущая версия EAX будет работать без проблем в качестве расширенного набора стандартов EAX 1.0 и IASIG. Для разработчиков игр это означает, что EAX будет больше чем когда-либо, тем API, выбор которого будет гарантировать оптимальную производительность на наиболее распространенном оборудовании.
В видении компании Qsound
3D звук, что это?
Обычная печатная пресса, к сожалению, изрядно невежественна во многих вещах, в частности в вопросе 3D звука. Как результат, если речь заходит об играх, то вам ужасно повезет, если в обзоре игры упоминается звук как таковой, и уж гораздо реже можно встретить упоминание о 3D звуке. Если 3D звук все же упоминается, проверьте обзор на предмет комментариев от компаний, занимающихся трехмерным звуком, для оценки некоторых перспектив технологии, используемой в продукте и сделанных в обзоре выводах.
Терминология 3D звука
Половина всех дискуссий в ньюсгруппах посвящены вопросу что такое "3D" и что нет, вплоть до бессмысленной семантики. Для протокола, термин "stereophonic" означает трехмерный звук! (От Греческого "stereos", означающего "пространственный, трехмерный, непрерывный, сплошной, цельный", а если вы не представляете себе, что означает "phonic" (акустический, звуковой), то дальше не читайте).
На протяжении лет, рынок наводнялся различными видами технологий, которые расширяли возможности аппаратуры убедительно воспроизводить позиционируемый звук в пространстве на ограниченном количестве реальных акустических колонок, и каждый называл все это "3D".
Допустим, что существует нечто, называемое "3D графикой", причем повсеместно под этим термином понимается "визуализация в 2D пространстве 3D модели". Теперь представим, что существует технология, которая позволяет создать подлинное ощущение глубины изображения, и некоторые люди убеждены, что термин "3D", применительно к графике, должен быть зарезервирован для этой технологии. Я полагаю, что пока мы не имеем изображения, протяженностью 360 градусов с воспринимаемой глубиной, его нельзя по настоящему считать "трехмерным" ("3D.
Типы "3D audio" процессов
Очень важно видеть различия между типами технологий 3D звука, прежде всего по функциям (игнорируя в этот момент то, какого успеха достигли поставщики этих технологий на рынке).
В результате получаем следующее:
· Stereo Expansion (Расширение стерео): технология, которая оперирует с имеющейся избыточной стерео информацией, надлежащим образом расширяя кажущуюся ширину звукового поля (т.е. главным образом удобная для не-3D стерео произведений, таких как записанная музыка).
· Positional 3D Audio (Позиционируемый 3D звук): технология, которая оперирует с множеством индивидуальных звуковых потоков и пытается определить местоположение каждого из них индивидуально в 3D пространстве.
· Virtual Surround (Виртуальный окружающий звук): технология, которая оперирует с декодированными данными в формате surround с целью воспроизведения разнообразных каналов в их истинной перспективе с использованием ограниченного числа источников звука, например воспроизведение пятиканального звука на двух акустических колонках.
Stereo expansion и virtual surround главным образом удобны для применения в бытовой электронике, такой, как стерео системы, домашние кинотеатры и т.д. Однако так как некоторые из этих технологий пересекаются с рынком персональных компьютеров (прослушивание музыки с помощью CD-ROM проигрывателей или прямо из сети Интернет, просмотр фильмов DVD), их применение также допустимо.
Тем не менее, визитная карточка для компьютеров - это позиционируемый 3D звук.
Все эти технологии покрывают львиную долю потребительского рынка, каждая в своей соответствующей области применения. Следовательно, 3D звук это не шутка, это полезная и быстро развивающаяся технология для создания музыки, применения в бытовой электроники,в видеоиграх, и т.д. и т.д.
Что действительно смешно, так это количество дезинформации и слепо верящих в характеристики чего-то -- при этом большая часть информации почерпнута из рекламных проспектов различных продуктов, но сами верующие при этом в массе своей не имеют знаний о звуке, в особенности о 3D звуке.
В чем разница между 3D звуком и панорамированием?
В течение многих лет добавить звук в видео игру можно было только при условии использования панорамирования стерео (stereo panning). Это накладывало ограничение в том, что звук можно было поместить только где-то между акустическими колонками, неважно, где бы они ни находились, перед вами в вашей комнате или на вашей голове в виде головных телефонов.
В первом случае, все звуки слышаться где-то между колонками спереди от вас, а в последнем случае, звуки воспроизводятся внутри вашей головы -- что не имеет никаких аналогов с ощущениями в реальном мире.
Панорамирование стерео это просто управление уровнями левого/правого звуковых каналов, которое никогда не зависит от частоты звука и напрямую не влияет на его фазу или синхронизацию. Панорамирование на нескольких акустических колонках (Multi-speaker panning) обычно является развитием этой идеи, но при этом может содержать больше манипуляций с преобразованиями.
Преобразование звука в "3D" (т.е. трехмерный) -- не имеет значения, какой метод при этом используется -- включает дополнительную информацию в звуковой поток в форме амплитуды и разности фаз/задержек между выходными каналами. В этом случае часто присутствует зависимость от частоты звука, хотя некоторые простые эффекты создаются с использованием простых задержек по времени на всем протяжении спектра шумов.
3D звук совершенен?
Сегодня существуют несколько технологий, которые расширяют возможности разработчиков по размещению звука в уникальных местах относительно слушателя. Есть ли какое-то решение действительно совершенное? По-моему, такого решения нет. Означает ли это, что "3D звук" это бесполезная вещь? По-моему, это не так. Истина находится где-то между двумя крайностями.
Почему люди не могут прийти к какому-то общему мнению относительно действенности 3D звука?
Тот факт, что человеческий слух несовершенен, является корнем проблем. Два уха, расположенных по сторонам головы, для определения местоположения источника звука воспринимают большую часть из доступной информации в горизонтальной плоскости (т.е. по азимуту или "по углу компаса"), при этом мы плохо различаем звуки исходящие спереди и сзади, при отсутствии дополнительных данных.
Так как все мы являемся существами, живущими на поверхности земли, то мы определяем местоположение источника звука по смещению относительно азимута, так как наши жертвы и наши враги, все являются тоже наземными существами. Выходит, что наша возможность оценки положения звука в вертикальной плоскости и его удаленности от нас очень слаба и сильно зависит от ушных каналов, которые зачастую очень плохо развиты.
Таким образом, когда разработчик технологии говорит о "точном" расположении источников звука, относитесь к этому с осторожностью. Простая математика может создать целый набор хороших цифр, но реальные результаты это совершенно другой вопрос -- после всего, мы вновь начинаем с недостатков, парни.
Нравится это или нет, но для нормально видящих людей, зрение является основным чувством определения местоположения чего-либо, причем до такой степени, что нас легко одурачить без особых трудов, предоставив противоречивую звуковую информацию. Сколько раз мы смотрели телевизор со звуковым сопровождением, исходящим из паршивого маленького динамика, который мог быть вмонтирован даже не в переднюю панель телика? Волновало ли это нас? Ощущали ли мы большое несоответствие между происходящими на экране событиями и звуком сопровождавшим их? По-видимому, не сильно. Долгое время мы не имели стерео телевизоров и домашних кинотеатров, а популярность они приобрели лишь из-за существенно упавшей на них цены.
Действенность любой технологии позиционируемого звука полностью находится под влиянием таких факторов, связанных с областью применения:
· использование в качестве дополнительной поддержки, облегчающей визуальное восприятие
· сопровождение действия (скажем фильм, футбольный матч, игра)
· усиление интерактивности (например, звуковые эффекты при работе с меню)
· уместность применения
Интересно, что видео игры (или другие симуляторы окружающей среды) это единственные приложения с 3D звуком, в которых все эти факторы играют важную роль.
Если вы поместите кого-нибудь в затемненную комнату и проиграете ему незнакомые звуки, воспроизводя их из колонок, расположенных в произвольно выбранных местах помещения, вы увидите, что ни одна из существующих технологий не обеспечивает 100% эффективность -- даже близкую!
Теперь, скажем, у нас есть безэховая камера (т.е. помещение, в котором нет реверберации), поместим в нее слушателя, зафиксируем его голову в нужном (правильном) положении и повторим эксперимент. Есть все шансы, что результат будет лучше. Однако все это не относится к делу до тех пор, пока вы не начали всерьез планировать построить безэховую камеру у себя дома, тогда к чему все это?
Точно такая же технология, обеспечившая посредственные результаты в первом тесте на эффективность, при использовании в хорошо сделанном приложении, например, видео игре, заставит большинство людей поклясться всем святым в том, что она (технология) обеспечивает абсолютную возможность размещения источника звука в любом месте пространства, потому что они слышат звук исходящим именно из этих мест!
Это вторая самая большая проблема и одновременно обоснование того, что заявления типа "делайте так!" "так не делайте!" никогда не прекратятся до тех пор, пока участники тестов в слепую не подтвердят и не удостоверятся в том, что они одновременно и правы и не правы.
Нет ничего странного в том факте, что иллюзия или обман чувств используется в большинстве создаваемых приложениях. Это как раз то место, где на сцену выходит искусство. Тем не менее, очень важно отдать должное тому, что этого заслуживает. Если в игре нет эффективного использования 3D звука, это не означает, что виновата в этом технология и если звук звучит правдоподобно как в жизни, технология, сама по себе, лишь часть головоломки! Это должно быть так же очевидно, как в случае, если вам попался паршивый текстовый процессор, в этом нет вины компьютера, на котором он запущен, почему же в случае с 3D звуком люди все время строят свои выводы, не представляя точно, на чем основывается их мнение.
Далее, будем считать, что разные методы реализации имеют сильные и слабые стороны.
Получается, что наушники, в связке с соответствующим бинауральным процессом обработки звука (слишком часто называемым просто HRTF) относительно хорошо справляются с созданием ощущения, что звук расположен сзади нас или над нами. Тем не менее, я еще ни разу не слышал такого звучания (а слышал я все), где бы убедительно осуществлялось расположение источника звука справа и впереди слушателя. (Флойд Тул /Floyd Toole/, занимающийся 3D звуком в компании Harman International и в течение долгого времени проводящий исследованиями по этой теме, один из немногих людей, который обобщил и изложил эту проблему в печатном виде.)
Кстати, HRTF, конечно же, звучит по-особому для каждого слушающего, поэтому любая звуковая технология для массового рынка должна создавать усредненное звучание, воспроизводя потенциально компромиссный результат и тем самым, продолжая вносить все больше разногласий между слушателями.
При использовании двух акустических колонок, основная зона эффективного размещения источников звука (т.н. sweet spot) находится спереди от слушателя и покрывает пространство в 180 градусов по азимуту, т.е. в горизонтальной плоскости. Ощущения, что звук расположен сзади и над слушателем, очень слабые, если нет поддержки в виде дополнительных сигналов. Особо отметим то, что использование алгоритмов HRTF, обеспечивающих воспроизведение звука для бинаурального прослушивания (т.е. в наушниках) и алгоритмов cross-talk cancelation (или для краткости CC; технология позволяющая воспроизводить звук, например из левой колонки так, что бы слышно этот звук было только левым ухом) не является успешным решением проблемы, неважно как хорошо цифры выглядят на бумаге или как крута рекламная компания.
Применение множества акустических колонок это уже другой вид зверей, но они действительно являются частью доступного выбора возможностей, особенно для компьютерных игр. Панорамирование звука обеспечивает явные выгоды при расположении акустических колонок сзади слушателя. Это облегчает проблему выбора места с наилучшим звучанием для прослушивания, так называемый sweet spot. Однако само по себе панорамирование звука никогда не может обеспечить значительных результатов, с точки зрения позиционирования источников звука в вертикальной плоскости. Конечно, до тех пор, пока мы не перестанем размещать колонки только на полу, а не начнем их подвешивать под потолком.
API и Rendering Engine - это две разные вещи!
Играя в игры, вы используете API и rendering engine (рендерин энджин). API (application programming interface или, для краткости, интерфейс) это, по сути, просто набор команд, используемых разработчиком при написании игры -- это не технология 3D звука или чего-то другого.
Rendering engine или механизм воспроизведения звука (далее просто звуковой движок) представляет собой процесс взаимодействия алгоритмов 3D звука со звуковыми потоками с целью расположения источников акустики в пространстве. Если API (например, DS3D или наш QMDX) поддерживает множество звуковых движков, тогда в одном и том же приложении будет воспроизводиться звук немного отличающийся при использовании разных звуковых движков, почти так же, как и звуковая дорожка MIDI (другой набор команд) будет звучать немного иначе на разных аппаратных синтезаторах от различных производителей.
Так как различные звуковые движки и схемы реализации имеют разную степень эффективности соответствующий интерфейс позиционирования не должен ограничиваться возможностями какого-то одного звукового движка. В действительности, API говорит: "поместите этот звук здесь" и звуковой движок делает эту работу наилучшим способом, помещая звук в нужное место. При этом звуковой движок использует свои алгоритмы и имеющуюся конфигурацию воспроизведения звука (наушники, две колонки, 15 колонок, что угодно).
Люди, которые делаю заявления типа "эта игра поддерживает только DS3D" совершенно не понимают сути вещей. Если игра написана под интерфейс DS3D - это отлично! Она будет работать со всеми 3D звуковыми картами в любой последовательности. На каждой звуковой карте, игра будет использовать имеющийся звуковой движок, неважно, кем он сделан QSound, EMU, Aureal или кем-то еще.
Существует масса звуковых интерфейсов, таких, как DS3D, QMDX, QMixer, A3D 1.x и 2.0 и звуковые API третьих фирм, таких как HMI, EAR, Diamondware и другие. Если программист выбрал для использования интерфейс "Фирмы Х" (при этом он может также использовать более чем один API для конкретного приложения) это совсем не означает, что вы должны обязательно использовать аппаратное обеспечение "Фирмы Х" что бы все работало.
Что сбивает с толку, так это знание того, какой звуковой движок поддерживает данный API.
Лишь немногие API созданы для поддержки специфичных аппаратных возможностей, которые могут быть недоступны при использовании звуковых карт других производителей или они могут быть неспособными поддерживать основные функциональные возможности конкурирующих продуктов.
Хороший API должен поддерживать как можно больше аппаратного обеспечения и так много функциональных особенностей, насколько это возможно, так, чтобы разработчик игры мог использовать один интерфейс и получить хороший результат на всех звуковых платах.
Например, если кто-то купит игру, которая была написана в расчете на новейшую версию интерфейса QMixer, эта игра будет иметь отличные 3D звуковые эффекты даже на звуковой карте с поддержкой только обычного стерео звука. Если та же игра будет запущена на системе оснащенной 3D картой на чипсете от Aureal, игра все равно будет использовать чипсет Aureal для воспроизведения 3D звука, в итоге пользователь услышит то, за что он заплатил.
Большинство разработчиков убедились в очевидном преимуществе использования таких API, как DS3D, QMixer и QMDX, которые не являются зависимыми от производителя аппаратного обеспечения и, следовательно, будут прекрасно работать с любой 3D звуковой картой.
Что такое "Panning"?
Panning (панорамирование) -- этот термин происходит от простого устройства, изобретенного Лесом Полом (Les Paul) в далеких 50-х годах, которое использовалось для расположения моно фонических звуковых дорожек в явно определенное положение слева/справа в стерео звуковом поле.
"Panoramic Potentiometer" (или для краткости "Pan Pot", панорамный потенциометр) это нечто вроде регулятора баланса в стерео системе. В то время как регулятор баланса управляет всем входящим стерео сигналом и выдает отрегулированный стерео сигнал на выходе, pan pot управляет моно сигналом на входе, а на выходе выдает его разделенным на части, передавая их в выходные каналы, левый и правый.
Любой микшерский пульт стерео звука (использующийся в студии звукозаписи) имеет pan pot для каждого канала. Повернем ручку управления pan pot полностью влево и 100% сигнала (скажем в честь Леса, что это звук гитары) будет направлено в левую колонку. В результате, звук гитары будет явственно исходить из левой колонки. Повернем ручку управления pan pot полностью вправо и 100% сигнала будет исходить из правой колонки.
В любом месте между этими двумя крайними положениями, pan pot будет направлять порции моно сигнала в каждый канал, создавая иллюзию того, что источник звука находится где-то между двумя колонками.
Такая же концепция панорамирования использовалась на протяжении лет в видео играх, с целью динамического расположения источников звука слева/справа в звуковом стерео поле. (Ясно, что физически pan pot не использовался, а применялся его программные эквиваленты). Такой же принцип может быть распространен на любое количество колонок. Панорамирование, использующееся в обработке 3D звука, не изменяет звуковой сигнал (например, его фазу, частоту и т.д.) осуществляя лишь простое управление пропорциями передаваемого сигнала индивидуально в каждое физическое устройство воспроизведения.
Что такое "Voice Manager"?
Термином Voice Manager (менеджер голоса) называют стандартизованный механизм для управления на аппаратном уровне каналами в 3D звуковой карте. Раньше аппаратное обеспечение оперировало всего лишь 5 каналами 3D звука, сейчас стандартным является число в 8 каналов. Основной интерфейс 3D звука DirectSound3D перекладывает работу по распределению этих ограниченных ресурсов между самыми важными звуками (те, что должны звучать в данный конкретный момент) полностью на программиста. Это очень большой объем работы. Программисты обычно предпочитают задать много (20, 30 или больше) звуковых каналов, а затем просто манипулировать ими по своему усмотрению.
Voice manager работает на уровне драйвера аппаратной части. По существу он позволяет программе работать так, как если бы было больше звуковых каналов, чем в действительности поддерживается на аппаратном уровне. В соответствии с некоторыми схемами приоритета, определяемыми программистом, voice manager берет на себя управление процессом динамического распределения самых важных звуков между реально доступными на аппаратном уровне каналами.
Компании QSound и Aureal в свое время предусмотрели возможность управления распределением ресурсов в своих драйверах для звуковых карт, но это привело к ситуации, когда каждая игра должна была знать о каждом типе управления распределением ресурсов. Каждый производитель, который окончательно убедился, что это проблема, должен был создавать свою собственную систему управления распределением ресурсов со своими собственными вызовами команд API и т.д.
Поэтому, QSound предложила Microsoft, чтобы наша схема управления распределением ресурсов была адаптирована и распространялась в качестве стандартной с тем, чтобы любой производитель мог ее использовать (также как и DS3D). Microsoft согласилась с нашим предложением, немного упростила наш метод и стала распространять систему управления распределением ресурсов под именем Voice Manager.
В чем разница между QSound, DS3D и EAX?
Прежде всего, чрезвычайно важно понимать разницу между API (который всего лишь представляет собой набор команд) и звуковым движком (действительный 3D звуковой процессор). Люди путаются, потому что они думают, что API и звуковые движки это одно и тоже, а это совершенно неверно.
DS3D содержит:
· API
· низкоуровневый интерфейс, работающий в режиме реального времени, аппаратноог обеспечения 3D звука
· программный звуковой движок от Microsoft, работающий в режиме реального времени, носящий имя "Hardware Emulation Layer" (HEL, уровень эмуляции аппаратного обеспечения)
Идея в том, что разработчик программного обеспечения пишет приложение, используя API DS3D, который является всего лишь набором команд. Когда игра запускается, стандартная функция DS3D ищет аппаратный ускоритель (например, 3D звуковую карту). Если такая карта найдена в системе, DS3D передает вызовы 3D функций и звуковые потоки в звуковую карту для их исполнения и обработки.
Каждый отдельный производитель звуковых карт с поддержкой 3D звука, независимо от того, какая технология 3D звука используется QSound, EMU, Aureal, CRL и т.д. делает свои звуковые карты совместимыми с набором команд DS3D. Это означает, что игра, написанная под DS3D, будет производить базовое позиционирование 3D звука на любой 3D звуковой плате, используя тот звуковой движок, какой имеется. В этом прелесть DS3D; он является универсальным API, который поддерживает звуковые движки многих производителей.
Далее, если игра не нашла аппаратного обеспечения, т.е. 3D звуковой карты в данной системе, тогда DS3D использует свой собственный программный звуковой движок (HEL). Это одна из проблем DS3D; интерфейс DS3D функционален и универсален, но HEL медлителен (поглощая при этом огромное количество ресурсов CPU) и обеспечивает минимальные 3D звуковые эффекты, причем только через головные телефоны. Проблема с ресурсами центрального процессора означает, что при отсутствии аппаратного обеспечения 3D звука производительность может пострадать в такой же степени, как падает значение fps в играх при отсутствии графического акселератора.
Одним из продуктов компании QSound является звуковой движок для производителей звуковых карт. Этот звуковой движок, конечно же, совместим с интерфейсом DS3D. Конечно, процесс воспроизведения трехмерного звука гораздо сложнее, чем то, что может эмулировать DS3D HEL, но в принципе это верно для любой реально существующей на рынке технологии 3D звука. DS3D HEL никогда не был рассчитан на то, чтобы быть эквивалентом 3D звуковому движку, реализованному полностью на аппаратном уровне.
Компанией QSound также созданы комплекты для разработчиков (SDK), такие как QMDX и QMixer. Они похожи на DS3D, так как оба содержат API (набор команд) и модуль работающий в режиме реального времени, который обеспечивает программную обработку и воспроизведение стерео (QMDX) или 3D (QMixer) звука в системах не имеющих соответствующего аппаратного обеспечения. Работающий в режиме реального времени звуковой движок в обоих QM SDK оставляет DS3D HEL далеко позади с точки зрения производительности, поэтому в системах без аппаратного обеспечения для воспроизведения звука игры будут идти с хорошими значениями fps.
Тем не менее, также как и DS3D, вместе QMDX и QMixer поддерживают DS3D-совместимые ускорители, если какой-либо из них присутствует в системе. Оба эти API переводят команды напрямую в формат DS3D с тем, чтобы использовать имеющееся аппаратное обеспечение. Так, в системе с аппаратным ускорителем, интерфейсы QM больше чем просто оболочка DS3D, обеспечивающая удобное использование набора мощных функций и значительно облегчающая задачи программиста, но в то же время эти интерфейсы сохраняют универсальную поддержку аппаратного обеспечения рассчитанного только на DS3D. В действительности, наши интерфейсы идут на шаг дальше, потому что (как было показано выше) их собственные звуковые движки могут быть использованы в дополнение к имеющемуся аппаратному обеспечению, например, если 3D звуковая карта поддерживает слишком мало звуковых каналов.
QSound создала свой собственный движок реверберации звука, который совместим с интерфейсом EAX. Этот движок уже поставляется нашим OEM клиентам для использования в новых Q3D продуктах. Мы также добавили поддержку набора команд EAX в наши комплекты разработчиков (SDK): QMDX и QMixer.
Если QSound не использует HRTF, как вы можете обеспечить позиционирование 3D звука на двух колонках?
Прежде всего, вы должны понять, что любой 3D звуковой процесс это ничто иное, как алгоритм фильтрации. Допустим, что существует "идеальный" или "совершенный" алгоритм фильтрации для точного расположения источника звука в заданном месте в пространстве, однако вполне вероятно, что существует больше чем один способ попытаться создать такой фильтр. HRTF является одним из таких способов.
Если говорить о звуковых движках от QSound в общем (о Q3D, QSoft3D, QMixer и т.д.), то мы никогда не использовали обработку звука алгоритмами HRTF для воспроизведения 3D звука. HRTF обеспечивает превосходное восприятие для бинаурального 3D звука (т.е. рассчитанного на прослушивание в наушниках) и мы применили эти принципы при разработке наших звуковых движков, создающих звук для наушников. Тем не менее, реализация алгоритма cross-talk cancelation, необходимого для преобразования процесса HRTF для воспроизведения на колонках непрост, несовершенен и дорог в реализации. Единственная причина того, что HRTF столь популярный метод в том, что он является общедоступным! Использование в рекламе термина HRTF позволяет легко ввести в заблуждение при объяснении технологии и звучит термин так, что создает ощущение вещи, которая точно должна работать, а значит, продукт легче продавать.
Итак, при создании функций обработки звука, имелась возможность вывести средние и сбалансированные особенности восприятия многих слушателей, при воспроизведении звука через различные типы акустических колонок, а также при различных способах их расположения. Для лучшей оптимизации и перехода на следующий уровень (это явилось толчком к успеху в области профессионального звука) использовалась помощь лучших профессионалов, занимающихся звукозаписывающим бизнесом, поэтому алгоритмы не просто работают, но обеспечивают настолько натуральное звучание, насколько это возможно.
QSound выбрала, по моей искренней оценке, крайне хороший подход, результатом чего стала возможность располагать источники звука как минимум эквивалентно, а в большинстве случаев лучше, чем это позволяет сделать применение стандартной схемы HRTF+CC. Даже при едва различимых звуковых эффектах идущих со стороны, область хорошей слышимости (sweet spot) немного расширена, но самое главное, особенно для реальных пользовательских приложений, это значительно более низкая стоимость реализации технологии. Причина того, что подход обеспечил нам решение типа "кратчайшее расстояние между двумя точками" в том, что процессы HRTF+CC включают в себя гораздо больше вычислений, чем требуется для нашей технологии.
После того, как я сказал все это, могу ли я сказать, что существует значительная разница между тем, как слышится 3D звук при использовании технологии QSound и тем звучанием, которое создается при использовании HRTF+CC? Для того чтобы все работало и работало хорошо, были потрачены годы исследований и куча денег. Отложим на время мою шляпу "профессионала по звуку" и вот что я вам скажу. Я искренне считаю что, особенно в видео играх, средний слушатель не заметит большой разницы.
Единственная вещь, раздражающая меня, заключается в том, что некоторые поставщики 3D звуковых технологий базирующихся на HRTF+CC делают возмутительные заявления о производительности, не просто предполагая, а, твердо заявляя о том, что они могут располагать источники звука идеальным образом, в любом месте трехмерного пространства, например под вашим стулом. Это откровенная ложь. Очень плохо, что некоторые компании испытывают необходимость обманывать любителей поиграть в игры таким вот образом. Все что может обеспечить 3D звук это действительно здорово и гораздо лучше, чем обычное стерео звучание, но когда люди покупаю разрекламированные поделки, не обеспечивающие того результата, который обещал производитель, они начинают думать что 3D звук сам по себе это большой обман. Это удручает.
В чем разница между EAX и Wavetracing?
Кроме основной возможности по позиционированию источников звуков в 3D пространстве, другой уровень реализма может быть обеспечен за счет имитации воздействия окружающей среды на звуки, которые мы слышим. Поэтому, с развитием продуктов позиционирования 3D звука и с ростом мощности настольных компьютеров, мы наблюдаем появление поддержки этих возможностей в современных звуковых картах.
Когда звук распространяется в пространстве, наряду с достижением наших ушей напрямую, он может отражаться от стен и других поверхностей. Звук также может проходить сквозь стены, частично или полностью поглощаясь, и другие объекты. Все это влияет на то, что мы слышим. В обычном случае, отражения звуков на большом пространстве может в реальности создавать ясно различимые эха, но более часто, результатом является то, что мы называем "reverberation" (реверберация, т.е. многократно отраженные звуки) или "reverb" для краткости. Reverb это совмещение множества эхо в тесном пространстве так, что мы слышим их как единую последовательность или "tail", которая следует за исходным звуком и затухает, причем степень затухания напрямую зависит от свойств окружающего пространства, в котором распространяется звук.
Wavetracing и EAX дают разработчикам программного обеспечения два способа создавать звуковые эффекты, связанные со свойствами окружающей среды ("environmental") или виртуальной акустикой ("virtual acoustic"), для воспроизведения взаимодействия звуков с реальной окружающей средой.
Технология Wavetracing является частью API A3D 2.0 и основывается на использовании упрощенной версии геометрии графической сцены игры, передавая данные о геометрии сцены в звуковую карту на чипсете от Aureal. После того, как будут обсчитаны реальные пути распространения нескольких первых отраженных звуков (обычно вычисляют пути распространения лишь нескольких первых отраженных звуков), анализируется то, как звуки проходят сквозь препятствия, частично или полностью поглощаясь. Затем происходит рендеринг звуковой сцены, т.е. точное определение мест расположения источников звука в пространстве и расчет путей достижения звуков (прямых, отраженных и прошедших сквозь препятствие) ушей слушателя.
EAX это гораздо более простой интерфейс, который использует обобщенную модель реверберации, такого же типа, что используется в профессиональной музыке и звуковом сопровождении фильмов в течение многих лет. Это сокращает возможности по управлению reverb до ключевых параметров, которые могут быть использованы для сведения их свойств до значений синтезированной пространственной акустики в терминах размера, типа поверхности и т.д.
Сравнение, насколько качество реверберации влияет на ощущения от игры, по сравнению с качеством такого же важного фактора, как звуковой движок, по моему скромному мнению не выявит явного победителя. Другими словами, оба способа дают возможность создавать хорошие звуковые эффекты.
Самая большая разница между этими двумя способами заключается в интерфейсах, которые пользователь никогда не слышит, зато разработчик должен использовать какой-то из них, или оба сразу, для написания игры, чтобы задействовать звуковую карту!
Интерфейс EAX имеет преимущество в том, что он много, много проще в использовании и дает возможность для простой настройки и манипуляциями ("tweaking") параметрами reverb. Кроме того, EAX это открытый протокол, а это означает, что другие создатели 3D технологий, включая CRL/Sensaura и QSound будут поддерживать EAX одновременно и в своих API и в своих звуковых движках. Итак, с точки зрения разработчика приложений, желающих перейти на следующий уровень в воспроизведении 3D звука, EAX прост в использовании и имеет потенциал в более широкой аппаратной поддержки, чем запатентованная технология Wavetracing от Aureal.
В качестве API, EAX имеет несколько недостатков в своей первой версии, самый явный из которых это отсутствие механизма расчета прохождения звука сквозь препятствия. Правда, в EAX 2.0 этот недостаток должен быть устранен.
Промышленное объединение, называемое IASIG (в него входят QSound, Creative Labs, Aureal и другие поставщики 3D технологий, производители и т.д.) разрабатывает на основе EAX новую спецификацию. Основная идея разработки заключается в создании стандартного открытого интерфейса, который мы все сможем использовать. Есть все основания надеяться, что новый стандартный интерфейс даст разработчикам возможность так же легко создавать приложения, как это обстоит в случае с EAX. При этом новый стандартный интерфейс будет свободен от недостатков присущих EAX.
Aureal участвует в разработках IASIG, поэтому мы можем смело предполагать (или хотя бы надеяться!), что, в конечном счете, драйверы для чипсетов от Aureal будут создаваться совместимыми с новым открытым стандартом. Я ожидаю, что инженеры Aureal будут и в дальнейшем предлагать разработчикам приложений возможности по использованию геометрических расчетов для определения путей распространения звука.
Кстати, нет ничего особо исключительного в звуковых API. Очень много людей даже не представляют, что игра может использовать DS3D, EAX, A3D 2.0 или другие интерфейсы, равно как и то, что хорошее 3D звучание могут обеспечить большинство звуковых плат и лишь расширенные звуковые эффекты и нестандартные возможности будут использоваться только там, где они поддерживаются. Существующее положение вещей, когда разработчикам приходится выбирать, какой интерфейс использовать, создает массу проблем, поэтому разработки IASIG, по созданию открытого и универсального интерфейса очень важны.
Какая самая лучше схема воспроизведения: наушники, две колонки, четыре колонки...?
Лучшая схема воспроизведения звука та, что вам нравится; та, что дает вам необходимую полноту ощущений.
Каждая схема воспроизведения звука имеет сильные и слабые стороны. Наушники хороши для воспроизведения звука, источники которого расположены в вертикальной плоскости, сзади и с боков от слушателя. Однако головные телефоны слабы при воспроизведении фронтального звука, т.е. когда источники звука расположены спереди от слушателя. 3D звук на двух колонках хорошо воспроизводится при расположении источников звука спереди от слушателя и по бокам, но два динамика слабо справляются с воспроизведением звука, источники которого расположены сзади и в вертикальной плоскости. Панорамирование звука на множестве колонок хорошо справляется с расположением источников звука спереди и сзади от слушателя и слабо с боковым расположением, при этом нет воспроизведение звука исходящего из источников в вертикальной плоскости.
Главная прелесть DS3D видео игр в том, что они могут создаваться без особой заботы о том, какую схему воспроизведения вы выберете для прослушивания. До тех пор, пока игра не будет по глупости рассчитана на специальную технологию 3D звука и/или схему воспроизведения, вы сможете выбирать все, что вам угодно! В действительности, расчет звуковой сцены происходит в режиме реального времени в процессе игры, поэтому вы можете переключаться с одной схемы воспроизведения на другую, скажем с колонок на наушники, на лету, если конечно ваша звуковая карта поддерживает эту возможность.
Звуковые карты имеют много разных возможностей, из которых всего лишь одной является поддержка 3D звука. Делая выбор в пользу какой-то технологии или продукта, не забывайте о перспективах дальнейшего использования, и, что более важно, необходимо, чтобы выбор был вашим собственным, не поддавайтесь влиянию мнения ваших друзей.
Похожие работы
... данных - облегчение восстановления данных при их порче или потере; - Pat authenticity verification / Добавлять проверку достоверности -WinRAR будет помещать в каждом новом и скорректированном архиве информацию относительно создателя, последнего времени коррекции и архивного имени; - Delete files after archiving / Удалять файлы после их архивации - после перемещения в архив файлы будут удалены. ...
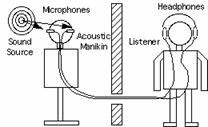
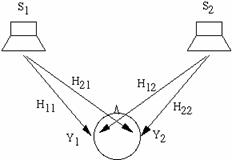
... октав, содержащая схему пpеобpазования воздействий в MIDI-сообщения и адаптеp с выходом MIDI Out. MIDI-клавиатура не способна звучать самостоятельно, она использует в качестве синтезатора звуковую карту компьютера. Иногда на MIDI-клавиатуре размещены некоторые дополнительные переключатели, например, глиссандо или вибрато. Большинство MIDI-клавиатур производится фирмой Fatar (под своей маркой их ...
... стало достижение цели систематизация и закрепление знаний и навыков в области создания фирменного стиля, полученных в процессе обучения, путем создания целостного визуального образа музыкального проекта „Tuum Fatum“ для позиционирования проекта на музыкальном рынке. Стоит отметить малое количество серьезных исследований и публикаций на данную тематику, поверхностную информацию данной темы, а ...
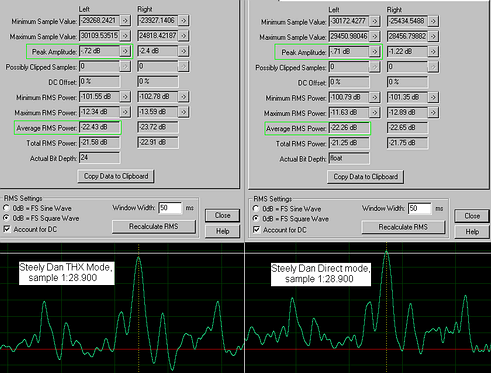
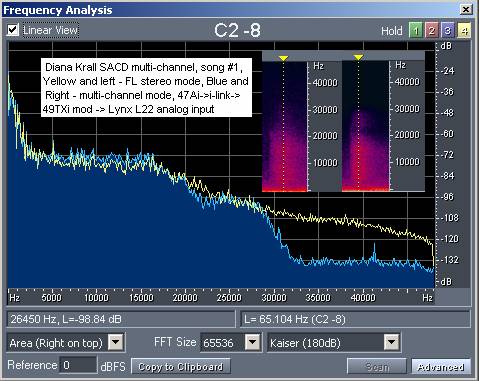
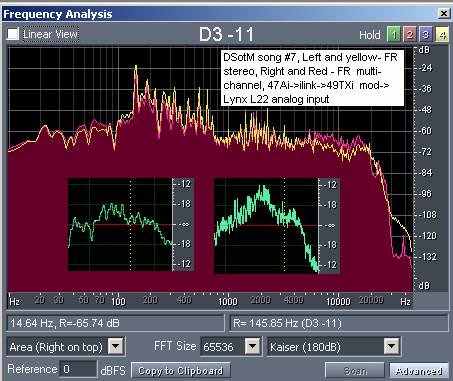
... что в самом близком будущем CD-DA переместится к область массового использования, к примеру, в область mp3, оставляя место в сфере любителей музыки для форматов DVD-A, SACD и WMA9 pro, поддерживающие 24 бита 96kHz многоканальное аудио, выдвинутое Microsoft. В случае корректного воспроизведения компакт-диска (поскольку это осуществлено в устройствах от некоторых Высококачественных изготовителей) и ...
0 комментариев