Московская Государственная Академия Приборостроения и Информатики
ДИПЛОМНАЯ РАБОТА
по информационным экономическим системам
«Биокомпьютеры»
Выполнил: Пяров Тимур Р
ЭФ2, 2 курс, 35.14
2002
Москва
Оглавление
Полностью био. 3
В Германии создан первый в мире нейрочип, сочетающий электронные элементы и нервные клетки 4
Биология in silico. 5
Инфузорное программирование. 8
Биоалгоритмика. 11
Биочипы как пример индустриальной биологии. 17
Первый биокомпьютер
Группе учёных из мюнхенского Института биохимии имени Макса Планка удалось создать первый в мире нейрочип. Микросхема, изготовленная Питером Фромгерцом и Гюнтером Зеком, сочетает в себе электронные элементы и нервные клетки.
Главной проблемой при создании нейрочипов всегда была сложность фиксации нервных клеток на месте. Когда клетки начинают образовывать соединения друг с другом, они неизбежно смещаются. На этот раз учёным удалось избежать этого.
Взяв нейроны улитки, они закрепили их на кремниевом чипе при помощи микроскопических пластмассовых держателей (на фото). В итоге каждая клетка оказалась соединена как с соседними клетками, так и с чипом. Подавая через чип на определённую клетку электрические импульсы, можно управлять всей системой.
Сочетание биологических и компьютерных систем таит в себе огромный потенциал. По мнению специалистов, нейрочипы позволят создать более совершенные, способные к обучению компьютеры, а также протезы для замены повреждённых участков мозга и высокочувствительные биосенсоры.
Как заявил недавно знаменитый британский физик Стивен Хокинг, если мы хотим, чтобы биологические организмы по-прежнему превосходили электронные, нам придётся поискать способ объединить компьютеры и человеческий мозг, либо попытаться искусственным путём усовершенствовать собственные гены. (Подробнее об этом рассказывается здесь)
Впрочем, такие проекты пока остаются фантастикой. До их реализации пока ещё очень далеко, а пока главным предназначением устройств, подобных созданной в Мюнхене нейросхеме, является изучение механизмов работы нервной системы и человеческой памяти.
Группа ученых из Вейцмановского Института (Weizmann Institute), Израиль, удалось создать первый в мире компьютер, все обрабатываемые данные и компоненты которого, включая "железо", программы и систему ввода-вывода, умещаются в одной стеклянной пробирке. Фокус заключается в том, что вместо традиционных кремниевых чипов и металлических проводников новый компьютер состоит из набора биомолекул - ДНК, РНК и некоторых ферментов. При этом ферменты (или, по-другому, энзимы) выступают в роли "железа", а программы и данные зашифрованы собой парами молекул, формирующих цепочки ДНК (на иллюстрации).
По словам руководителя проекта профессора Эхуда Шапиро (Ehud Shapiro), биокомпьютер пока может решать лишь самые простые задачи, выдавая всего два типа ответов: "истина" или "ложь". При этом в одной пробирке помещается одновременно до триллиона элементарных вычислительных модулей, которые могут выполнять до миллиарда операций в секунду. Точность вычислений при этом составит 99,8%. Для проведения вычислений необходимо предварительно смешать в пробирке вещества, соответствующие "железу", "программному обеспечению" и исходным данным, при этом ферменты, ДНК и РНК провзаимодействуют таким образом, что в результате образуется молекула, в которой зашифрован результат вычислений.
Комментируя новое достижение Шапиро сообщил, что природа предоставила человеку превосходные молекулярные машины для кодирования и обработки данных, и, хотя ученые еще не научились синтезировать такие машины самостоятельно, использование достижений природы уже в скором будущем позволит решить эту проблему. В будущем молекулярные компьютеры могут быть внедрены в живые клетки, чтобы оперативно реагировать на негативные изменения в организме и запускать процессы синтеза веществ, способных противостоять таким изменениям. Кроме этого, благодаря некоторым своим особенностям, биокомпьютеры смогут вытеснить электронные машины из некоторых областей науки.
 Группе учёных из мюнхенского Института биохимии имени Макса Планка удалось создать первый в мире нейрочип. Микросхема, изготовленная Питером Фромгерцом и Гюнтером Зеком, сочетает в себе электронные элементы и нервные клетки.
Группе учёных из мюнхенского Института биохимии имени Макса Планка удалось создать первый в мире нейрочип. Микросхема, изготовленная Питером Фромгерцом и Гюнтером Зеком, сочетает в себе электронные элементы и нервные клетки.
Главной проблемой при создании нейрочипов всегда была сложность фиксации нервных клеток на месте. Когда клетки начинают образовывать соединения друг с другом, они неизбежно смещаются. На этот раз учёным удалось избежать этого.
Взяв нейроны улитки, они закрепили их на кремниевом чипе при помощи микроскопических пластмассовых держателей. В итоге каждая клетка оказалась соединена как с соседними клетками, так и с чипом. Подавая через чип на определённую клетку электрические импульсы, можно управлять всей системой.
Сочетание биологических и компьютерных систем таит в себе огромный потенциал. По мнению специалистов, нейрочипы позволят создать более совершенные, способные к обучению компьютеры, а также протезы для замены повреждённых участков мозга и высокочувствительные биосенсоры.
Как заявил недавно знаменитый британский физик Стивен Хокинг, если мы хотим, чтобы биологические организмы по-прежнему превосходили электронные, нам придётся поискать способ объединить компьютеры и человеческий мозг, либо попытаться искусственным путём усовершенствовать собственные гены. (Подробнее об этом рассказывается здесь)
Впрочем, такие проекты пока остаются фантастикой. До их реализации пока ещё очень далеко, а пока главным предназначением устройств, подобных созданной в Мюнхене нейросхеме, является изучение механизмов работы нервной системы и человеческой памяти.
| Источник: |
Автор: Михаил Гельфанд, gelfand@integratedgenomics.ru
Дата публикации:21.09.2001
 Вычислительная биология, она же биоинформатика, она же компьютерная генетика - молодая наука, возникшая в начале 80-х годов на стыке молекулярной биологии и генетики, математики (статистики и теории вероятности) и информатики, испытавшая влияние лингвистики и физики полимеров. Толчком к этому послужило появление в конце 70-х годов быстрых методов секвенирования* последовательностей ДНК*. Нарастание объема данных происходило лавинообразно (рис. 2) и довольно скоро стало ясно, что каждая полученная последовательность не только представляет интерес сама по себе (например, для целей генной инженерии и биотехнологии), но и приобретает дополнительный смысл при сравнении с другими. В 1982 году были организованы банки данных нуклеотидных последовательностей - GenBank в США и EMBL в Европе. Первоначально данные переносились в банки из статей вручную, однако, когда этот процесс начал захлебываться, все ведущие журналы стали требовать, чтобы последовательности, упоминаемые в статье, были помещены в банк самими авторами. Более того, поскольку секвенирование уже давно стало рутинным процессом, который выполняют роботы или студенты младших курсов на лабораторных работах, многие последовательности сейчас попадают в банки без публикации. Банки постоянно обмениваются данными и, в этом смысле, практически равноценны, однако средства работы с ними, разрабатываемые в Центре биотехнологической информации США и Европейском институте биоинформатики, различны. Пожалуй, первым биологически важным результатом, полученным при помощи анализа последовательностей, было обнаружение сходства вирусного онкогена v-sis и нормального гена фактора роста тромбоцитов, что привело к значительному прогрессу в понимании механизма рака. С тех пор работа с последовательностями стала необходимым элементом лабораторной практики.
Вычислительная биология, она же биоинформатика, она же компьютерная генетика - молодая наука, возникшая в начале 80-х годов на стыке молекулярной биологии и генетики, математики (статистики и теории вероятности) и информатики, испытавшая влияние лингвистики и физики полимеров. Толчком к этому послужило появление в конце 70-х годов быстрых методов секвенирования* последовательностей ДНК*. Нарастание объема данных происходило лавинообразно (рис. 2) и довольно скоро стало ясно, что каждая полученная последовательность не только представляет интерес сама по себе (например, для целей генной инженерии и биотехнологии), но и приобретает дополнительный смысл при сравнении с другими. В 1982 году были организованы банки данных нуклеотидных последовательностей - GenBank в США и EMBL в Европе. Первоначально данные переносились в банки из статей вручную, однако, когда этот процесс начал захлебываться, все ведущие журналы стали требовать, чтобы последовательности, упоминаемые в статье, были помещены в банк самими авторами. Более того, поскольку секвенирование уже давно стало рутинным процессом, который выполняют роботы или студенты младших курсов на лабораторных работах, многие последовательности сейчас попадают в банки без публикации. Банки постоянно обмениваются данными и, в этом смысле, практически равноценны, однако средства работы с ними, разрабатываемые в Центре биотехнологической информации США и Европейском институте биоинформатики, различны. Пожалуй, первым биологически важным результатом, полученным при помощи анализа последовательностей, было обнаружение сходства вирусного онкогена v-sis и нормального гена фактора роста тромбоцитов, что привело к значительному прогрессу в понимании механизма рака. С тех пор работа с последовательностями стала необходимым элементом лабораторной практики.
|
Количество статей по молекулярной биологии в библиографической базе данных PubMed (красные ромбы) и количество фрагментов нуклеотидных последовательностей в базе данных GenBank (синие квадраты) по состоянию на 1982-2000 годы. Шкала - логарифмическая, так что рост количества последовательностей - экспоненциальный. Объем базы в нуклеотидах тоже растет экспоненциально. |
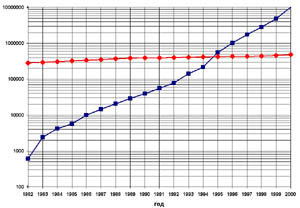 Рис. 2.
Рис. 2. В 1995 году был секвенирован первый бактериальный геном*, в 1997 - геном дрожжей. В 1998 было объявлено о завершении секвенирования генома первого многоклеточного организма - нематоды 1. По состоянию на 1 сентября 2001 года доступны 55 геномов бактерий, геном дрожжей, практически полные геномы Arabidopsis thaliana (растения, родственного горчице), нематоды, мухи дрозофилы - все это стандартные объекты лабораторных исследований. Уже два раза (весной 2000 и зимой 2001 года) было объявлено о практическом завершении секвенирования генома человека - имеющиеся фрагменты действительно покрывают его более чем на 90%. Количество геномов, находящихся в распоряжении фармацевтических и биотехнологических компаний, оценить трудно, хотя, по-видимому, оно составляет многие десятки и даже сотни. Ясно, что подавляющее большинство генов в этих геномах никогда не будет исследовано экспериментально. Поэтому компьютерный анализ и становится основным средством изучения.
Все это привело к тому, что биоинформатика стала чрезвычайно модной областью науки, спрос на специалистов в которой очень велик. Следует отметить, что одним из неприятных последствий возникшего шума стало то, что биоинформатикой называют всё, где есть биология и компьютеры 2. В то же время многие области уже пережили такие моменты (например, теория информации 3), и хочется надеяться, что за пеной ажиотажа не пропадет то действительно интересное, что делается в настоящей биоинформатике.
Традиционно к биоинформатике относится:
- статистический анализ последовательностей ДНК;
- предсказание функции по последовательности (распознавание генов в последовательности ДНК, поиск регуляторных сигналов, предсказание функций белков - некоторые из этих задач рассмотрены в следующей статье);
- анализ пространственной структуры белков и нуклеиновых кислот, в том числе предсказание структуры белка по последовательности, - здесь биоинформатика граничит с биофизикой и физикой полимеров;
- теория молекулярной эволюции и систематика.
Следует отметить, что многие задачи из разных областей решаются сходными алгоритмами, один из примеров этого приводится в статье М. А. Ройтберга.
В последние годы возник ряд новых задач, связанных с прогрессом в области автоматизации не только секвенирования, но и других экспериментальных методов: масс-спектрометрии, анализа белок-белковых взаимодействий, исследования работы генов в различных тканях и условиях (см. статью И. А. Григорян и В. Ю. Макеева в этом номере). При этом не только возникает необходимость создавать и заимствовать из других областей новые алгоритмы (например, для обработки результатов экспериментов в области протеомики* широко применяются методы анализа изображений), но и происходит распространение биоинформатических подходов на смежные области, например популяционную и медицинскую генетику. Существенно при этом, что роль биоинформатики не сводится к обслуживанию экспериментаторов, как это было еще несколько лет назад: у нее появились собственные задачи. Более подробно об этом можно прочитать в обзоре (М. С. Гельфанд, А. А. Миронов. Вычислительная биология на рубеже десятилетий. Молекулярная биология. 1999, т. 33, № 6, с. 969-984); можно упомянуть также сборник статей (Математические методы для анализа последовательностей ДНК. М. С. Уотермен, ред. - М.: Мир, 1999). Проект курса по биоинформатике, перечисляющий основные направления. Основные журналы по биоинформатике - «Bioinformatics», «Journal of Computational Biology» и «Briefings in Bioinformatics», конференции - ISMB (Intellectual Systems for Molecular Biology) и RECOMB (International Conference on Computational Biology).
Словарь
[i41320]
1 (обратно к тексту) - Вопрос о том, что такое полностью секвенированный геном многоклеточного организма, нетривиален. В частности, значительную его часть (несколько процентов) составляют повторы, которые и вообще крайне сложны для секвенирования. В таких областях находится мало генов, и поэтому их обычно оставляют «на потом». Текущее же состояние генома человека напоминает рассыпанную мозаику, часть элементов которой отсутствует, а кроме того, подмешаны фрагменты других мозаик (посторонние последовательности).
2 (обратно к тексту) - В плане одного академического института на 2001 год в разделе «биоинформатика» можно было встретить, например, компьютерное моделирование сокращений сердечной мышцы - это очень интересная и уважаемая, но совершенно отдельная тема. А в университетском курсе биоинформатики предлагается изучать «Возможный механизм пунктурной терапии».
3 (обратно к тексту) - См. очень поучительную заметку Клода Шеннона «The Bandwagon» (Trans. IRE, 1956, ИТ-2 (1), 3, русский перевод в: К. Шеннон. Работы по теории информации и кибернетике. - М.: Изд-во иностранной литературы, 1963). Вот цитата: «Сейчас теория информации, как модный опьяняющий напиток, кружит голову всем вокруг. Для всех, кто работает в области теории информации, такая популярность несомненно приятна и стимулирует их работу, но в то же время и настораживает… Здание нашего несколько искусственно созданного благополучия слишком легко может рухнуть, как только в один прекрасный день окажется, что при помощи нескольких магических слов, таких как информация, энтропия, избыточность… нельзя решить всех нерешенных проблем… На понятия теории информации очень большой, даже, может быть, слишком большой спрос. Поэтому мы сейчас должны обратить особое внимание на то, чтобы исследовательская работа в нашей области велась на самом высоком научном уровне, который только возможно обеспечить».
Словарь
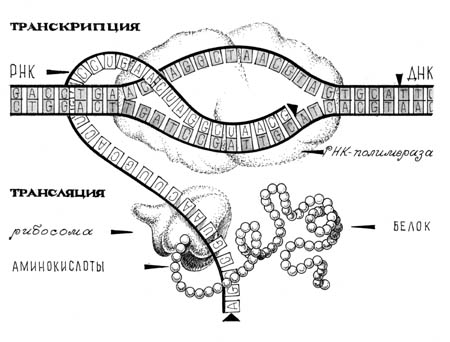
ДНК (дезоксирибонуклеиновая кислота) - полимерная молекула, элементарными единицами которой являются четыре нуклеотида: A, C, G, T. Ген - участок ДНК, кодирующий один белок. Белок - полимер, в построении которого принимают участие 20 аминокислот (на самом деле больше, но другие аминокислоты появляются в результате дополнительной химической модификации). Белки играют основную роль в жизни клетки - формируют ее скелет, катализируют химические реакции, выполняют регуляторные и транспортные функции. В живой клетке каждая молекула белка имеет сложную пространственную структуру (см. рис. 1).
|
Рис. 1. Схема биосинтеза белка. РНК-полимераза синтезирует РНКовую копию (мРНК) фрагмента ДНК (транскрипция). Рибосома транслирует мРНК и осуществляет синтез белка, присоединяя аминокислоты в соответствии с таблицей генетического кода (см. рис. 1 к следующей статье). Затем белок сворачивается в пространственную структуру (об этом подробнее см. в КТ #398). |
Геном - совокупность всех генов организма или, шире, полная последовательность ДНК. Размер генома человека - 3 миллиарда нуклеотидов, кодирующих 35-40 тысяч генов 1, генома бактерий - от 600 тысяч нуклеотидов/600 генов (внутриклеточные паразиты) до 6-8 миллионов нуклеотидов/5-6 тысяч генов (свободно живущие бактерии). Упражнение: в скольких выпусках журнала «Компьютерра» можно будет опубликовать бактериальный геном, если посвящать этому половину каждого номера?
Секвенирование - определение последовательности нуклеотидов во фрагменте ДНК. Именно это имеется в виду, когда в газетах пишут о «расшифровке генома человека». Исследование работы генов в масштабе целых организмов, а также эволюция геномов составляют предмет геномики, а анализ полного набора белков в клетке и их взаимодействий друг с другом - предмет протеомики 2.
Инфузорное программирование Во второй декаде сентября в Праге прошла 6-я «Европейская конференция по искусственной жизни» - междисциплинарный форум, на который собираются ученые, изучающие природу и перенимающие в своих исследованиях ее «творческий опыт».
Во второй декаде сентября в Праге прошла 6-я «Европейская конференция по искусственной жизни» - междисциплинарный форум, на который собираются ученые, изучающие природу и перенимающие в своих исследованиях ее «творческий опыт».
Например, исследователи из голландского «Центра природных вычислений» при Лейденском университете полагают, что, освоив некоторые приемы генетических манипуляций, заимствованные у простейших одноклеточных организмов - ресничных инфузорий, человечество сможет воспользоваться гигантским вычислительным потенциалом, скрытым в молекулах ДНК.
Ресничные обитают на Земле, по меньшей мере, два миллиарда лет, их обнаруживают практически повсюду, даже в самых негостеприимных местах. Директор Центра Гжегож Розенберг (Grzegorz Rozenberg), называет эти инфузории «одним из наиболее успешных организмов на Земле». Ученые объясняют такую «удачливость» чрезвычайно эффективными механизмами манипуляции собственной ДНК, позволяющими инфузориям приспосабливаться практически к любой среде обитания.
Уникальность ресничных в том, что их клетка имеет два ядра - одно большое, «на каждый день», где в отдельных нитях хранятся копии индивидуальных генов; и одно маленькое, хранящее в клубке используемую при репродукции единственную длинную нить ДНК со всеми генами сразу. В ходе размножения «микроядро» используется для построения «макроядра» нового организма. В этом ключевом процессе и происходят чрезвычайно интересные для ученых «нарезание» ДНК микроядра на короткие сегменты и их перетасовка, гарантирующие то, что в макроядре непременно окажутся нити с копиями всех генов.
Розенбергом и его коллегами установлено, что способ, с помощью которого создаются эти фрагменты, удивительно напоминает технику «связных списков», издавна применяемую в программировании для поиска и фиксации связей между  массивами информации. Более глубокое изучение репродуктивной стратегии ресничных инфузорий при сортировке ДНК открывает новые и интересные методы «зацикливания», сворачивания, исключения и инвертирования последовательностей.
массивами информации. Более глубокое изучение репродуктивной стратегии ресничных инфузорий при сортировке ДНК открывает новые и интересные методы «зацикливания», сворачивания, исключения и инвертирования последовательностей.
Напомним, что в 1994 году Леонардом Эдлманом (Leonard Adleman) экспериментально было продемонстрировано, как с помощью молекул ДНК в единственной пробирке можно быстро решать классическую комбинаторную «задачу про коммивояжера» (обход вершин графа по кратчайшему маршруту), «неудобную» для компьютеров традиционной архитектуры. Результаты же экспериментов ученых из лейденского центра дают основания надеяться, что в недалеком будущем ресничные инфузории можно будет использовать для реальных ДНК-вычислений.
А вот английские исследователи из компании British Telecom пришли к выводу, что изучение поведения колоний бактерий дает ключ к решению сложнейшей задачи упорядочивания коммуникационных сетей.
Для описания ближайшего будущего компьютеров сегодня все чаще привлекают популярную концепцию «всепроникающих вычислений» - идею о гигантской совокупности микрокомпьютеров, встроенных во все предметы быта и незаметно взаимодействующих друг с другом. В этой единой беспроводной сети будет увязано все: кухонная техника, бытовая электроника, следящие за микроклиматом сенсоры в комнатах, радиомаяки на детях и домашних животных… Список этот можно увеличивать бесконечно. Но сейчас добавление каждой новой «умной штучки» отнимает массу времени, чтобы взаимно подстроить работу этого устройства и уже сформировавшейся конфигурации. В концепции же будущего, поскольку хозяева дома, по определению, не обладают ни временем, ни знаниями для настройки совместной работы всей этой армии бесчисленных «разумных вещей», изначально предполагается способность системы к самоорганизации. Поэтому достаточно  естественно, что взгляд ученых устремился к природе, где подобные задачи решены давно и успешно. В частности, эксперименты исследователей British Telecom показали, что их система, имитирующая поведение колонии бактерий в строматолитах 1, способна поддерживать работу сети из нескольких тысяч устройств, автоматически управляя большими популяциями отдельных элементов.
естественно, что взгляд ученых устремился к природе, где подобные задачи решены давно и успешно. В частности, эксперименты исследователей British Telecom показали, что их система, имитирующая поведение колонии бактерий в строматолитах 1, способна поддерживать работу сети из нескольких тысяч устройств, автоматически управляя большими популяциями отдельных элементов.
Для симуляции функционирования такой колонии британскими учеными была создана сеть из трех тыс. узлов. Основой самоорганизации стало присвоение различных приоритетов рассылаемым по сети пакетам данных. Например, высший приоритет получили «информационные» пакеты, доносящие послания от одного узла к другому (кроме них в системе рассылаются еще «управляющие», «конфигурирующие» и прочие пакеты), поэтому ими занимаются устройства, имеющие в данный момент наилучшие связи с максимальным числом элементов сети.
В British Telecom полагают, что воплощение экспериментальной концепции в реальных продуктах можно ожидать уже через пять-шесть лет.
Еще одна любопытная разработка была представлена на конференции бельгийскими исследователями под руководством профессора Марко Дориго (Marco Dorigo). Они продемонстрировали, что программы, имитирующие стратегию поведения муравьиного сообщества, могут успешно управлять работой сложных компьютерных сетей.
Рыская в поисках корма, муравьи-разведчики оставляют за собой меченую феромонами дорожку. При этом зачастую к одному источнику пищи прокладывается сразу несколько троп, но разведчик, открывший самую короткую тропинку, возвращается быстрее и уводит за собой соплеменников. Выделяемые ими феромоны делают  тропку более пахучей, чем остальные - в результате самая выгодная тропа быстро становится самой популярной. Учёные взяли эту тактику на вооружение: созданные ими программные агенты случайным образом «прозванивают» каналы связи между различными узлами сети и метят «тропинки» цифровыми «феромонами», на основании чего определяют оптимальный маршрут для передачи пакетов данных из одной точки в другую.
тропку более пахучей, чем остальные - в результате самая выгодная тропа быстро становится самой популярной. Учёные взяли эту тактику на вооружение: созданные ими программные агенты случайным образом «прозванивают» каналы связи между различными узлами сети и метят «тропинки» цифровыми «феромонами», на основании чего определяют оптимальный маршрут для передачи пакетов данных из одной точки в другую.
Практические испытания проводились в сетях Национального научного фонда США и японской корпорации NTT. Синтетические «муравьи» должны были, ничего не зная о конфигурации сети, отыскать кратчайшую дорогу от одного узла к другому. Быстро исследовав сеть, агенты определили её строение и вскоре уже могли «подсказать» любому информационному пакету к какому следующему узлу ему нужно направиться, чтобы достичь своей цели быстрее. Иначе говоря, был реализован механизм высококачественного интеллектуального роутинга, причем при возникновении различных «заторов» в сети «искусственные муравьи» реконфигурировали схему роутинга быстрее, чем традиционные решения.
Как считают авторы, их разработка может использоваться и для выполнения других неординарных задач, например динамической организации снабжения товаром в сложной торговой сети.
Биоалгоритмика Эта заметка посвящена разделу биоинформатики, который можно назвать «биоалгоритмикой», - алгоритмам анализа первичных структур (последовательностей) биополимеров. Биоалгоритмика находится на стыке прикладной теории алгоритмов и теоретической молекулярной биологии и, подобно другим разделам биоинформатики, бурно развивалась в течение 70-х - 90-х годов XX века 1.
Эта заметка посвящена разделу биоинформатики, который можно назвать «биоалгоритмикой», - алгоритмам анализа первичных структур (последовательностей) биополимеров. Биоалгоритмика находится на стыке прикладной теории алгоритмов и теоретической молекулярной биологии и, подобно другим разделам биоинформатики, бурно развивалась в течение 70-х - 90-х годов XX века 1.
Алгоритмы анализа символьных последовательностей и связанные с ними алгоритмы сортировки и алгоритмы на графах активно изучались и разрабатывались, начиная со второй половины 50-х годов. Алгоритмический бум 60-х - 70-х годов был связан как с разработкой теоретических моделей вычислений (конечные автоматы и их варианты с различными видами памяти), так и с появлением компьютеров и, следовательно, реальной потребностью в обработке значительных (по тем временам) объемов данных. Своеобразными итогами этого периода стали многотомное «Искусство программирования» Д. Кнута (1968-1973) и «Построение и анализ вычислительных алгоритмов» А. Ахо, Дж. Хопкрофта и Дж. Ульмана (1976). Анализ достижений этого замечательного этапа в развитии теории алгоритмов есть также в книге: В. А. Успенский, А. Л. Семенов. Теория алгоритмов: основные открытия и приложения. - М.: Наука, 1987.
Таким образом, к моменту создания первых баз данных последовательностей ДНК и белков - началу 80-х годов - алгоритмический аппарат был, в значительной степени, готов. При этом специалисты в области алгоритмов рассматривали биологические приложения в одном ряду с техническими, одни и те же алгоритмы применялись, например, для сравнения («выравнивания») биологических последовательностей и для поиска сбоев при хранении файлов. Характерно название первого сборника работ по биоалгоритмике - «Time Warps, String Edits, and Macromolecules: The Theory and Practice of Sequence Comparison» (Sankoff, D and Kruskal, JB, eds, 1983).
Впрочем, довольно скоро выяснилось, что анализ биологических последовательностей имеет свою специфику - прежде всего с точки зрения постановок задач. Вот, например, задача о распознавании «вторичной» структуры РНК. Она очень важна для молекулярной биологии и впервые была рассмотрена еще в конце 70-х годов. Молекула рибонуклеиновой кислоты (РНК) - однонитевой полимер, состоящий из четырех видов мономеров-нуклеотидов (аденин, гуанин, урацил, цитозин). А-У и, соответственно, Г-Ц могут образовывать водородные связи, стабилизирующие молекулу. Однако образование одних связей из-за стереохимических соображений делает невозможным образование других, то есть не все комбинации межнуклеотидных связей в молекуле РНК допустимы (правила конфликтов между связями известны). Требуется для данной нуклеотидной последовательности найти наиболее стабильную вторичную структуру, т. е. допустимый набор межнуклеотидных связей, содержащий наибольшее возможное количество элементов (рис. 1). Эта задача может быть переформулирована как задача построения графа (точнее - гиперграфа, см. ниже) специального вида с максимально возможной суммой весов ребер (вершины соответствуют нуклеотидам, ребра - установленным связям) и решена с помощью метода динамического программирования (Ruth Nussinov и соавт., 1978; также см. гл. 7 в книге М. Уотермена). Однако появляющиеся ограничения на вид графа весьма экзотичны с точки зрения небиологических приложений. Другой пример задачи, не имеющей смысла вне биологического контекста, -распознавание кодирующих фрагментов ДНК, рассмотренное в статье Михаила Гельфанда.
|
Рис. 1. Вторичная структура участка бактериофага Qb (231 основание). Сплошные линии проведены между парами оснований, связанных водородными связями. |
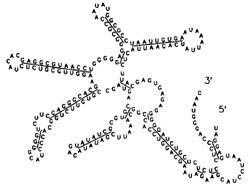
Возвращаясь к задаче распознавания наиболее стабильной «вторичной» структуры РНК, отметим следующие обстоятельства, характерные для многих важных задач биоалгоритмики:
- в описанной выше модели правильнее считать не количество связей, а их суммарную энергию, энергия каждой возможной пары считается известной. С алгоритмической точки зрения задача практически не меняется;
- модель, положенная в основу описанной выше задачи, - упрощенная и во многих случаях не согласуется с экспериментом. Полезно учитывать и вклад нуклеотидов, не участвующих в образовании водородных связей. Ограничения на множество допустимых наборов связей, принятые в задаче (а), слишком строгие. Различные формальные постановки задач, лучше отражающие биологическую реальность, приводят к существенному усложнению алгоритма;
- в реальности молекула РНК может принимать не ту структуру, которой мы приписали оптимальную энергию, а несколько иную, например, из-за того, что мы не знаем точных значений энергетических параметров. Поэтому полезно не искать одну «оптимальную» структуру, а проанализировать все возможные структуры и оценить вероятность образования каждой отдельной связи («статистический вес» связи). Это также можно решить методом динамического программирования.
- многие авторы пытаются выяснить вторичную структуру РНК, не сводя ее к какой-либо алгоритмической оптимизационной задаче, а путем моделирования реального процесса «сворачивания» молекулы РНК (т. е. установления и исчезновения водородных связей).
Специфика биоалгоритмики, однако, проявляется не только в задачах, которые «по определению» не могли встретиться вне анализа биологических последовательностей. Показательна самая старая и, наверное, самая популярная задача анализа биологических последовательностей - их выравнивание. Выравнять две последовательности - это изобразить их друг над другом, вставляя в обе пробелы так, чтобы сделать их длины равными. Вот, например, как можно выровнять слова ПОДБЕРЕЗОВИК и ПОДОСИНОВИК (cм. врезку).
Такой способ изображения последовательностей широко распространен в молекулярной биологии. Предполагается, что выравнивание отражает эволюционную историю, то есть стоящие друг под другом символы соответствуют одному и тому же символу последовательности-предка. К сожалению, мы не знаем, как именно шла эволюция последовательностей. Поэтому в качестве «правильного» обычно выбирается выравнивание, оптимальное относительно некоторой функции качества. Но как мы можем контролировать правильность выбора этой функции? Есть ли у нас (пусть приблизительные) «эталоны»? К счастью, да. В качестве эталонных можно взять выравнивания, соответствующие наилучшему возможному совмещению их пространственных структур (такие структуры известны для нескольких сотен белков). Это связано с тем, что функционирование белка в клетке определяется прежде всего его пространственной структурой и можно ожидать, что аминокислоты, лежащие в сходных местах трехмерной структуры, соответствуют одним и тем же аминокислотам предкового белка.
В «добиологическом» анализе последовательностей (например, при сравнении файлов) использовалось понятие редактирующего расстояния. При этом фиксируется набор редактирующих операций (например, замена символа, вставка символа и удаление символа) и для каждой операции фиксируется цена. Тогда каждое выравнивание получает свою цену, определяемую как сумма цен отдельных операций.
Лучшим считается то, которое имеет наименьшую цену. Например, при цене замены 1 и цене вставки/удаления 3, лучшими в примере во врезке 2 будут третье и четвертое выравнивания, а при цене замены 10 и той же цене вставки/удаления, лучшим будет пятое.
Довольно скоро выяснилось, что для выравнивания биологических последовательностей в эту естественную схему необходимо внести ряд важных изменений. Дело в том, что разные аминокислоты различны по-разному. Например, аланин и валин очень похожи по своим свойствам (и цена замены аланина на валин должна быть небольшой), и они оба совершенно не похожи на триптофан. Более того, даже одинаковые аминокислоты «одинаковы по-разному». Так, триптофан - редок, и сопоставление двух триптофанов более ценно, чем сопоставление весьма распространенных аланинов.
Поэтому вместо «цены замены символа» в схеме редактирующего расстояния при сравнении белков используется весовая матрица замен, где каждой паре символов соответствует вес (положительный - для похожих, отрицательный для непохожих), а выравниванию в целом - вес W=R-G, где R - суммарный вес сопоставлений символов (в соответствии с выбранной весовой матрицей замен), G - суммарный штраф за удаления и вставки символов. Таким образом, оптимальное выравнивание - это выравнивание, имеющее наибольший вес (в то время как цена требовалась наименьшая). Например, пусть вес совпадения для гласных букв +2, вес совпадения для согласных букв +1, вес сопоставления двух различных гласных или двух различных согласных -1, вес сопоставления гласной и согласной -2. Далее, пусть штраф за удаление или вставку символа -5. Тогда, например, третье выравнивание имеет вес -3, а четвертое - +1. Таким образом, оптимальное выравнивание слов ПОДБЕРЕЗОВИК и ПОДОСИНОВИК (при выбранных матрице замен и штрафе за удаление/вставку) - четвертое. Переход от минимизации цены к максимизации качества, - это не только технический трюк. На языке максимизации качества естественно ставится задача о поиске оптимального локального сходства. Эта задача соответствует сравнению двух белков, которые в ходе эволюции стали совсем непохожи - везде, кроме относительно короткого участка.
Алгоритм построения оптимального выравнивания основан на методе динамического программирования, введенном в широкую практику Ричардом Беллманом в 1957. Идея метода состоит в следующем: чтобы решить основную задачу, нужно придумать множество промежуточных и последовательно их решить (в каком порядке - отдельный вопрос). При этом очередная промежуточная задача должна «легко» решаться, исходя из уже известных решений ранее рассмотренных задач. Множество промежуточных задач удобно представлять в виде ориентированного ациклического графа. Его вершины соответствуют промежуточным задачам, а ребра указывают на то, результаты решений каких промежуточных задач используются для основной. Таким образом, исходная задача сводится к поиску оптимального пути в графе 2 (подробнее о методе динамического программирования см. книгу Ахо, Хопкрофта и Ульмана, а также статью Finkelstein A.V., Roytberg M.A. Computation of biopolymers: a general approach to different problems. Biosystems.1993; 30 (1-3): 1-19.). Аналогично можно переформулировать различные варианты задач выравнивания, предсказания вторичной структуры РНК и белков, поиска белок-кодирующих областей ДНК и других важных проблем биоинформатики.
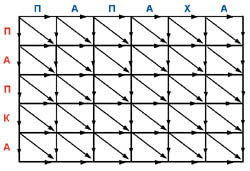
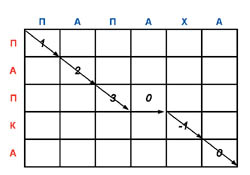
При построении оптимального выравнивания (мы рассматриваем простейший случай, когда удаление и вставка отдельных символов штрафуются независимо) промежуточные задачи - это построение оптимальных выравниваний начальных фрагментов исходных последовательностей. При этом задачи нужно решать в порядке возрастания длин фрагментов. Граф зависимости между промежуточными решениями для сравнения слов «ПАПКА» и «ПАПАХА», а также последовательность промежуточных шагов, приводящих к оптимальному выравниванию, показаны на рис. 2.
Рис. 2.
|
| (a) Граф зависимостей между промежуточными задачами для выравнивания слов ПАПКА и ПАПАХА. Каждая вершина соответствует паре начальных фрагментов указанных слов. Диагональное ребро, входящее в вершину, соответствует сопоставлению последних букв сравниваемых начальных фрагментов (случай 1), горизонтальное ребро - удалению буквы в слове ПАПАХА, вертикальное ребро - удалению буквы в слове ПАПКА (случаи 2 и 3). Правая верхняя вершина - начальная и соответствует выравниванию пустых слов, левая нижняя вершина - конечная, соответствует выравниванию полных слов ПАПКА и ПАПАХА. |
|
| (b) Оптимальное выравнивание слов ПАПКА и ПАПАХА при следующих параметрах: вес совпадения букв: 1, штраф за замену гласной на гласную или согласной на согласную: 1, штраф за замену гласной на согласную или согласной на гласную: 2, штраф за удаление символа: 3. |
|
| (c) Траектория, соответствующая оптимальному выравниванию. В клетках указаны веса промежуточных оптимальных выравниваний. Например, вес оптимального выравнивания для «ПАП» и «ПАПА» равен 0, а для «ПАПК» и «ПАПАХ» равен -1. |

На двух примерах - распознавания вторичной структуры РНК (бегло) и выравнивания белковых последовательностей (более подробно) мы проследили за эволюцией постановок задач в биоалгоритмике. Упомянем кратко еще несколько аспектов. Пожалуй, с практической точки зрения самым важным является поиск в базах данных последовательностей, сходных с изучаемой. Определяющую роль начинают играть проблемы вычислительной эффективности, решаемые, в частности, с применением алгоритмов хеширования. Для предсказания пространственной структуры белков важны алгоритмы выравнивания последовательности со структурой (при этом используется тот факт, что из-за разницы физико-химических свойств аминокислоты встречаются с разной частотой на поверхности белка и в структурном ядре). Наконец, мы полностью оставили в стороне задачи построения эволюционных деревьев по белковым последовательностям. Подчеркнем, что во всех случаях происходит интенсивная «притирка» постановок задач - как с биологической (большая адекватность), так и с алгоритмической (возможность построения более эффективных алгоритмов) точки зрения.
Врезка 1
Врезка 2
Врезка 3: Алгоритм оптимального выравнивания (набросок)
1 (обратно к тексту) - Последняя монография - Pavel A. Pevzner. Computational Molecular Biology. An Algorithmic Approach. The MIT Press. Cambridge, MA, 2000, из книг на русском языке укажем М. С. Уотермен (ред). Математические методы для анализа последовательностей ДНК.-М.: Мир, 1999.
2 (обратно к тексту) - Иногда (например, в упоминавшейся задаче о построении оптимальной вторичной структуры РНК) приходится рассматривать не графы, а гиперграфы. Гиперграф отличается от графа тем, что вместо ребер на множестве вершин задаются гиперребра. Ребро в (ориентированном) графе сопоставляет начальной вершине одну конечную вершину. Гиперребро сопоставляет начальной вершине множество вершин (не обязательно одноэлементное). Аналогом пути в гиперграфе является гиперпуть - объект, похожий на дерево.
| ПОДБЕРЕЗОВИК | (1) |
| ПОДБЕРЕЗОВИК | (2) |
| ПОДБЕРЕЗОВИК | (3) |
| ПОДБЕРЕЗОВИК | (4) |
| ПОДБЕРЕЗ----ОВИК | (5) |
С точки зрения алгоритма построения оптимального выравнивания введение весовых матриц ничего не меняет. Однако оказывается, что нельзя рассматривать удаление одного символа как отдельное эволюционное событие. Вес нужно приписывать удалению целого фрагмента, и этот вес должен зависеть от длины фрагмента. Ограничения на выбор функции G(L) штрафов за удаление фрагментов (L - длина удаляемого фрагмента) влияют на эффективность построения оптимального выравнивания. В простейшем случае посимвольных замен (этот случай соответствует функции G(L)=k•L, где k - штраф за удаление одного символа) время работы квадратично зависит от длины сравниваемых слов (считаем, что их длины примерно равны), а в случае допустимости произвольных штрафных функций порядок роста времени работы соответствующего алгоритма - кубический. Компьютерные эксперименты показали, что разумным компромиссом служат линейные функции вида G(L)=k•L+s, где s - штраф за начало удаления/вставки, где k и L имеют тот же смысл, что и раньше. Для таких функций можно построить квадратичный по времени работы алгоритм построения оптимального выравнивания (хотя и с большей константой пропорциональности).
Алгоритм оптимального выравнивания (набросок)Пусть нам нужно найти оптимальное выравнивание последовательностей U=Xa и W=Yb (здесь a - последняя буква U, b - последняя буква W, последовательности X и Y - получаются соответственно из U и W отбрасыванием последней буквы. Для оптимального выравнивания возможны ровно три альтернативы:
- последние буквы слов U и W сопоставлены друг другу;
- последняя буква слова U удалена, последняя буква слова W - нет;
- последняя буква слова W удалена, последняя буква слова U - нет.
В первом случае вес оптимального выравнивания равен
S1 = S(X, Y)+m(a, b).
Здесь S(X, Y) - вес оптимального выравнивания последовательностей X и Y (оно уже построено ранее, т. к. пара (X, Y) рассмотрена до текущей пары (U, W)), m(a, b) - вес сопоставления символов a и b.
Во втором и третьем случае аналогично получаем формулы:
S2 = S(X, Yb)+g,
S3 = S(Xa, Y)+g.
Здесь g - штраф за удаление символа, S(X, Yb) и S(Xa, Y) - веса оптимальных выравниваний для пар последовательностей (X и Yb = W) и (Xa=U и Y) соответственно. Оптимальные выравнивания для этих пар последовательностей тоже построены ранее. Таким образом, чтобы найти вес S(U, W) оптимального выравнивания последовательностей U и W и само это выравнивание, достаточно найти наибольшее из чисел S1 , S2 , S3. Очевидно, каждое из этих чисел можно вычислить за конечное (не зависящее от длин исходных последовательностей) время. Поэтому общее время построения оптимального выравнивания двух последовательностей пропорционально количеству промежуточных задач, т. е. произведению длин этих последовательностей.
Биочипы как пример индустриальной биологии Живые организмы устроены крайне сложно и содержат большое количество взаимодействующих систем. Основную роль в управлении жизнедеятельностью играют гены - участки молекулы ДНК, в которых хранится информация об устройстве молекул, вовлеченных в различные процессы в живой клетке. Считается, что ген работает, когда с него считывается информация.
Живые организмы устроены крайне сложно и содержат большое количество взаимодействующих систем. Основную роль в управлении жизнедеятельностью играют гены - участки молекулы ДНК, в которых хранится информация об устройстве молекул, вовлеченных в различные процессы в живой клетке. Считается, что ген работает, когда с него считывается информация.
Биологам и медикам необходимо знать реакцию больших каскадов взаимозависимых и взаимообуславливающих генов на то или иное изменение внешних условий, например в ответ на введенное лекарство.
Полное число генов измеряется величинами порядка 103 (6200 у дрожжей) - 104 (38 000 по последним данным у человека), при этом базовые жизненные процессы регулируются сотнями генов. До последнего времени в значительной степени отсутствовали возможности для получения, хранения и обработки столь значительных массивов данных. Благодаря прогрессу компьютерной индустрии были созданы как технологии для одновременного экспериментального получения информации о работе большого числа генов в клетке, так и методы обработки этой информации, позволяющие сделать на ее основе простые и однозначные выводы (например, поставить точный диагноз какого-либо заболевания).
Возникла индустриальная молекулярная биология, в которой применение компьютерных технологий является необходимым условием и предусматривается уже на стадии планирования эксперимента. Формирование этой области совершенно изменило взгляд на роль вычислительных устройств в биологической науке - то, что раньше было дополнительным, необязательным и вспомогательным фактором, неожиданно стало играть определяющую роль. Таким образом, оказалось, что прогресс биотехнологии нереален без разработки специализированных аппаратных, алгоритмических и программных средств, а соответствующая отрасль кибернетики вошла в состав биоинформатики.
Современная экспериментальная техника позволяет создать анализирующую матрицу (называемую также биочипом) размером несколько сантиметров, при помощи которой можно получить данные о состоянии всех генов организма. Для создания эффективной методики необходимы совместные усилия специалистов в области молекулярной биологии, физики, химии, микроэлектроники, программирования и математики.
История развития технологии биочипов относится к началу девяностых годов, при этом российская наука сыграла не последнюю роль. Здесь уместно пояснить, что биочипы по природе нанесенного на подложку материала делятся на  «олигонуклеотидные» (см. «КТ» № 370, Рубен Ениколопов, «Биочипы»), когда наносятся короткие фрагменты ДНК, обычно принадлежащие к одному и тому же гену, и биочипы на основе кДНК, когда робот наносит длинные фрагменты генов (длиной до 1000 нуклеотидов).
«олигонуклеотидные» (см. «КТ» № 370, Рубен Ениколопов, «Биочипы»), когда наносятся короткие фрагменты ДНК, обычно принадлежащие к одному и тому же гену, и биочипы на основе кДНК, когда робот наносит длинные фрагменты генов (длиной до 1000 нуклеотидов).
Наиболее популярны в настоящее время биочипы на основе кДНК, ставшие по-настоящему революционной технологией в биомедицине. Остановимся подробнее на их приготовлении, а также на получении и обработке данных с их помощью. Определяющей технологической идеей стало применение стеклянной подложки для нанесения генетического материала, что сделало возможным помещать на нее ничтожно малые его количества и очень точно определять местоположение конкретного вида тестируемой ДНК. Для приготовления биочипов стали использоваться роботы, применяемые прежде в микроэлектронике для создания микросхем (рис. 1). Молекулы ДНК каждого типа создаются в достаточном количестве копий с помощью процесса, называемого амплификацией; этот процесс также может быть автоматизирован, для чего используется специальный робот - умножитель. После этого полученный генетический материал наносится в заданную точку на стекле (на жаргоне такой процесс называется «печать») и химически к стеклу пришивается (иммобилизация). Для иммобилизации генетического материала необходима первичная обработка стекла, а также обработка напечатанного биочипа ультрафиолетом, стимулирующим образование химических связей между стеклом и молекулами ДНК (рис. 2).
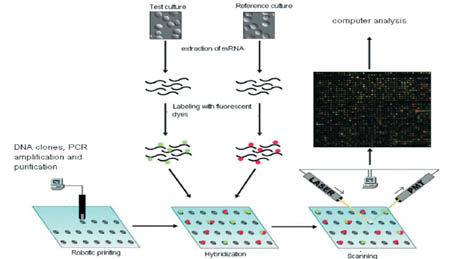
Грубо говоря, из клетки выделяется смесь продуктов работы генов, т. е. РНК различных типов, производимых в определенных условиях. Результатом эксперимента и является знание того, продукты каких именно генов появляются в клетке в условиях, интересующих исследователя. Молекулы каждого типа РНК связываются (в лучшем случае) с единственным типом молекул из иммобилизованных на биочипе. Те молекулы, которые не связались, можно смыть, а для определения того, к каким из иммобилизованных на чипе молекул нашлись «партнеры» в исследуемой клетке, экспериментальная и контрольная РНК метится флуоресцирующими красителями.
Таким образом, следующим этапом в получении результата на приготовленном биочипе является биохимическая реакция, в процессе которой один или несколько образцов ДНК или РНК, полученные из клеток, ткани или органа, метятся одним или  несколькими флуоресцентными красителями и гибридизуются (связываются) с материалом, напечатанным на биочипе.
несколькими флуоресцентными красителями и гибридизуются (связываются) с материалом, напечатанным на биочипе.
После того как флуоресцирующие образцы прореагировали с биочипом, чип сканируют лазером, освещая поочередно точки нанесения ДНК каждого конкретного типа и следя за интенсивностью сигнала флуоресценции (рис. 3).
Изготовление одного биочипа занимает от трех до шести недель, при условии, что в распоряжении исследователя есть генетический материал для нанесения на чип. Сам эксперимент - гибридизация и снятие данных - занимает один-два дня, а при традиционной технологии такая же группа исследователей потратила бы годы на последовательное проведение всех экспериментов, включенных в один биочип.
Сигналы лазерного сканирования должны быть обработаны и проанализированы. Гены на стекле дают сигналы различной интенсивности, кроме того, всегда есть некоторое фоновое излучение от метки, не смывшейся со стекла, которое также неоднородно. Необходимо автоматически выделить из шума сигналы разной интенсивности, несущие различную информацию.
На следующем этапе гены, которые дают в одинаковых условиях одинаковый сигнал, объединяются в группы. Это также делается автоматически, с помощью алгоритмов кластерного анализа. Кластеры генов, ведущих себя схожим образом в разных условиях или в разные моменты времени, служат исходной точкой для заключений биологического характера.
В Советском Союзе была создана замечательная школа по разработке алгоритмов распознавания изображений, в первую очередь для анализа изображений, поступающих с искусственных спутников Земли. Наше математическое образование на протяжении многих десятилетий было одним из лучших в мире, поэтому наши прикладники, инженеры и алгоритмисты всегда легко разрабатывали оригинальные специализированные методы анализа данных. Неудивительно, что выходцы из нашего Отечества трудятся во многих фирмах, работающих на переднем крае возникающей на наших глазах индустрии. Наши бывшие соотечественники являются организаторами одной из наиболее известных фирм, предоставляющих методы обработки, - Informax, акции которой являются ценообразующими во всех биотехнологических биржевых индексах.
Однако создание биохимической технологии, в подавляющей степени, - заслуга американских фирм и научных центров. Mногие фирмы делают на заказ сами биочипы. Самые известные из них - это Affymetrix и Clontech. Incyte - самая мощная на сегодняшний день компания - кроме изготовления биочипа на заказ и продажи генетического материала для печати на чип, сама выполняет и гибридизацию, а заказчику предоставляет только готовые данные. Развитие индустрии зашло настолько далеко, что возник прибыльный рынок приготовления специально обработанных стекол для приготовления биочипов в условиях отдельной молекулярно-биологической лаборатории. К таким фирмам относится, например, Corning.
Какие же задачи под силу подобной непростой технологии, имеющей дело с сотнями тысяч генов одновременно? Сразу хотелось бы сделать оговорку, что на сегодняшний момент имеется тенденция перехода от чипов с тысячами генов к чипам с сотнями генов, отобранных специально для решения конкретной задачи. Поясним на примере. Исследователями Массачусетсского технологического института была сделана работа по использованию чипов для диагностики различных подклассов острого лейкоза человека. Точная диагностика двух подтипов острого лейкоза (острый миелоидный и острый лимфобластный) имеет определяющее значение при выборе курса терапии. Первоначально был использован олигонуклеотидный чип из 6000 генов. Используя в качестве пробы РНК из клеток костного мозга, исследователям удалось выделить и подготовить к реальному использованию в качестве подчипа набор из 50 генов, сильное различие по экспрессии которых позволяет однозначно определить тип опухоли 1 (рис. 4). Мы полагаем, что нет нужды доказывать необходимость диагностических чипов, поэтому учитывая небольшое количество аналитических ячеек на чипе, а значит меньшую себестоимость, существует реальная возможность их разработки и производства у нас в стране.
Что же до классической науки, то тут возможности применения чипов безграничны. Группа исследователей из Иллинойского университета под руководством Андрея Гудкова, используя кДНК-чипы, нашла и сравнила спектры генов, отвечающих за реакцию клетки на радиационные воздействия различной природы. Под воздействием радиации, которое клетка воспринимает как стресс, активируются гены, известные как каскад зависимых от р53 генов (р53 - белок, одна из главных функций которого - защищать клетку от любых неблагоприятных воздействий). Многие из этих белков могут рассматриваться как кандидаты на использование в химиотерапии раковых опухолей и для защиты нормальных клеток организма от противоопухолевых агентов, таких как радиационное облучение и химиотерапевтические препараты.
Интересную по практическому приложению работу сделали ученые из лаборатории радиобиологии в Хельсинки. Используя чипы, они попытались выяснить, какие гены меняют свою активность под влиянием радиосигнала с частотой 900 МГц, который дают всеми нами любимые сотовые телефоны. Человеческие клетки из первичного подкожного слоя были выдержаны в культуре под этим сигналом в течение одного часа, после чего РНК из этих клеток и из клеток контрольной серии была пущена в качестве пробы на чип. Гены, активность которых существенным образом изменилась в течение этого эксперимента, относятся к генам стресс-ответа, таким как р53, hsp27, изменение активности которых во многих случаях говорит о том, что клетка или целый организм подвергаются неблагоприятным воздействиям. По-видимому, можно говорить (хотя и очень осторожно) о том, что получены прямые доказательства стрессогенного воздействия электромагнитного поля, а также данные о биохимических основах его биологического действия. Так что не исключено, что люди, меньше говорящие в течение дня по сотовому телефону или использующие специальные наушники, меньше устают в конце рабочего дня.
Судя по всему, мы присутствуем при возникновении нового метода получения и использования информации о живой природе. Данные будут собираться автоматически и на промышленной основе. Планирование и подготовка таких экспериментов, вероятно, со временем также будет осуществляться автоматически. В пользу этого свидетельствует опыт развития компьютерных технологий, где создание микропроцессора автоматизировано в значительной степени уже на ранних стадиях проектирования, все же дальнейшие стадии разработки и внедрения в производство во всё большей степени происходят практически без участия, да и без контроля человека. На «входе» будет ставиться задача крайне общего вида, например: найти три характерных гена, отвечающие за реакцию клетки на такие-то нестандартные внешние условия, и не работающие ни в каких нормальных условиях. Автоматическая система будет сама осуществлять подбор биологического материала, подготовку, постановку и интерпретацию биологического эксперимента, а также формулировку наиболее вероятного решения поставленной задачи. На долю исследователя останется только тестирование полученных результатов и выработка инструкций для применения полученного нового знания в медицине или биотехнологии.
Более того, изменится, вероятно, сама идея биологического эксперимента. Поскольку заключение о работе той или иной живой системы будет выноситься с помощью компьютерного анализа данных, биологический эксперимент будет часто ставиться не с целью непосредственной проверки той или иной идеи, как сейчас, но с целью расшивки «узких мест» в работе автоматизированной системы хранения и обработки информации. Что-то подобное мы уже наблюдаем в физике высоких энергий, где эксперименты на ускорителях ставятся с учетом существующих приближенных методов вычислений в физических теориях, с целью более точного определения оценочных параметров, в наибольшей степени влияющих на точность вычисляемых физических величин.
Хотелось бы надеяться, что в российских условиях можно будет включиться в серьезную работу по созданию программного обеспечения индустриальной биомедицины. Работа в этой области не требует больших затрат, характерных для биологических исследований (на оборудование, реактивы и т. д.) Дорогие суперкомпьютеры тоже в общем-то не необходимы - в большинстве научно-исследовательских центров в США используются кластеры ПК. Необходимы изобретательность, упорство и фантазия, а также хорошее владение современными математическими методами статистического анализа, что всегда составляло наши сильные стороны.
По-видимому, единственной организацией в России, серьезно занимающейся технологией биочипов, является Институт молекулярной биологии РАН им. В. А. Энгельгардта. В этом институте создаются также микрочипы с ячейками, содержащими различные зонды для проведения химических и ферментативных реакций с анализируемыми образцами (см. «Инфобизнес», №151 - Л. Л.-М.).
Разработка технологии биологических микрочипов начата в ИМБ РАН в 1989 году и с тех пор продолжается усиленными темпами, в последние годы в сотрудничестве с США. ИМБ РАН принадлежит 15 международных и множество российских патентов. Более подробно с исследованиями, проводимыми в ИМБ РАН, можно ознакомиться на сайте http://www.biochip.ru/.
Похожие работы
... типов биокомпьютеров, которые базируются на разных биологических процессах. Это, в первую очередь, находящиеся в стадии разработки ДНК- и клеточные биокомпьютеры. 1. Биокомпьютеры или живые компьютеры 1.1. ДНК-компьютеры Как известно, в живых клетках генетическая информация закодирована в молекуле ДНК (дезоксирибонуклеиновой кислоты). ДНК - это полимер, состоящий из субъединиц, ...
... изучения других таксономически значимых признаков, например, ферментативных реакций новых видов. (Oren, 1994). К сожалению, на сегодняшний день генетические и биохимические исследования архебактерий, и в частности, галобактерий отличает заметная "однобокость" - большинство полученных и охарактеризованных мутантов, а также клонированных структурных и регуляторных участков генов так или иначе ...
... геномах растений, вызываемые с помощью ФПУ-трансформированной человеческой речи, которая резонансно взаимодействует с хромосомной ДНК in vivo [25,29]. Этот результат, осмысленный нами с позиций семиотико-волновой составляющей генетического кода, имеет существенное методологическое значение и для анализа таких суперзнаковых объектов, как тексты ДНК, и для генома в целом. Открываются принципиально ...
... той и другой культуре и определенной отрешенности от обеих12. * * * Заключая разговор о двух великих интеллектуальных традициях Востока, сделаем основные выводы, существенные для замысла этой книги. Обратившись лицом к китайской философской мысли, современная философия может найти в ней совершенно иную модель развития философского умозрения, породившего дискурс, сохранивший исходную модель ...
0 комментариев