Навигация
ТИПЫ ИНФОРМАЦИОННЫХ МАССИВОВ И ЕДИНИЦЫ КОНТЕНТ-АНАЛИЗА
32608
знаков
1
таблица
0
изображений
1. ТИПЫ ИНФОРМАЦИОННЫХ МАССИВОВ И ЕДИНИЦЫ КОНТЕНТ-АНАЛИЗА
Основа контент-анализа – это подсчет встречаемости некоторых компонентов в анализируемом информационном массиве, дополняемый выявлением статистических взаимосвязей и анализом структурных связей между ними, а также снабжением их теми или иными иными количественными или качественными характеристиками. Отсюда понятно, что главная предпосылка контент-анализа – это выяснение того, что считать; иными словами, определение единиц анализа. Единицы эти в зависимости от целей анализа, типа информационного массива, а также ряда дополнительных причин могут быть (и реально бывают) весьма разнообразными. К ним предъявляются два естественных, но, к сожалению, обычно плохо совместимых требования. С одной стороны, они должны легко и по возможности однозначно идентифицироваться в тексте; в идеале хотелось бы, чтобы их выявление вообще могло быть алгоритмизовано. Понятно, что такому требованию лучше всего удовлетворяют формальные элементы текста или же элементы, имеющие четко выраженные и однозначные формальные соответствия, например слова. С другой стороны, от единиц контент-анализа чаще всего требуется некая субъективная, да к тому же еще и зависящая от контекста значимость, делающая их распределение и динамику такого распределения диагностичными для выявления изменений в индивидуальном и общественном сознании, системах убеждений и т.д. – иными словами, единицы должны быть интересными для последующей (политологической, культурологической, социологической и т.д.) интерпретации. Между тем такие единицы (например, темы) носят собственно содержательный характер, и упоминание их в тексте может осуществляться многими разнообразными способами. Их идентификация в общем случае предполагает семантический анализ текста, проблема автоматизации которого, несмотря на многолетние усилия лингвистов и программистов, далека от решения. Характеристику единиц контент-анализа необходимо предварить кратким соображением о природе анализируемого информационного массива. В самом определении метода контент-анализа нет ничего, что препятствовало бы применению его к отдельно взятому тексту; более того, примеры такого анализа известны. Тем не менее существует ряд причин, по которым объектом контент-аналитических проектов обычно является не отдельный текст, пусть даже значительный по объему, а именно информационный массив, или информационный поток, состоящий из большого количества текстов. Во-первых, статистические закономерности проявляются тем более отчетливо, чем больше объем выборки. Во-вторых, большинство целей контент-анализа предопределяют его тяготение к компаративности; аналитиков чаще всего интересуют не одномоментные срезы, а динамика изменений, а если и срезы, то, как правило, «пестрые», отражающие, например, различные СМИ или сознание различных социальных групп. Наконец, при всем разбираемом ниже разнообразии единиц контент-анализа наиболее популярными являются различные макроединицы: темы и/или проблемы, пропозиции, образы и идеологемы. Таковых в отдельно взятых текстах и особенно в небольших по объему текстах СМИ обычно немного, да и новые макроединицы появляются не столь часто, поэтому оценить их динамику можно лишь на большом временном промежутке или при широком «горизонтальном сопоставлении». Таким образом, идея контент-анализа предполагает анализ больших информационных массивов; с другой стороны, его относительная дешевизна и технологичность делают такой анализ принципиально возможным. Поэтому не приходится удивляться тому, что в истории контент-анализа имеются такие проекты, как анализ 427 школьных учебников, 481 частной беседы, 4022 рекламных слоганов, 8039 (в 1938) и 19 533 (в 1952) редакционных статей или 15 000 персонажей в 1000 часов телевизионного эфирного времени. Конкретное разнообразие единиц контент-анализа практически безгранично, однако среди них можно выделить несколько основных типов. (Классификация, приводимая ниже, построена с учетом типологии К.Криппендорфа, однако отличается от нее весьма существенно.)
1.1. «Физические» единицы. Под таковыми понимаются сущности с четко очерченными физическими, геометрическими или временными границами, как, скажем, экземпляры книги, номера газет, экземпляры плакатов или листовок, фотографии и т.п. Идентификация и подсчет их не составляют особого труда, однако необходимость в таком подсчете возникает достаточно редко; подсчет, скажем, листовок или книг чаще всего осуществляется с целью оценки представленности какой-то тематики или оценки, т.е. реально используются единицы других, характеризуемых ниже типов единиц – обычно концептуальных, пропозициональных или тематических.
1.2. Структурно-семиотические единицы. Под таковыми имеются в виду основные элементы семиотических систем (см. СЕМИОТИКА). В случае естественного языка это:
– лексика языка (слова и их эквиваленты, например выражение железная дорога или термин контент-анализ, т.е. то, что фиксируется в словарях) и
– грамматические показатели (например, отрицательные частицы или показатели таких категорий, как, скажем, отглагольные имена).
Количественный подсчет встречаемости слов в тексте – это, пожалуй, самый простой вариант контент-анализа, который, однако, зачастую способен давать небезынтересные результаты. Чаще всего, конечно, подсчитываются «интересные», или «ключевые» слова и/или словосочетания, например названия ценностных категорий типа свобода, стабильность, доверие, территориальная целостность; сценариев типа предательство или разочарование; достаточно однозначные обозначения тех или иных общественно значимых явлений, например коррупция, преступность или терроризм; значимые атрибуты наподобие жесткий, решительный; эмоционально окрашенная оценочная лексика типа разрушительный, неудержимый, подлый, кошмарный, человеконенавистнический; слова-пароли (тоже зачастую эмоционально окрашенные) типа патриоты, коммунофашисты, мондиалисты или белопридурки; слова, сильно активизированные в конкретный момент времени, вроде «Семья» или «Мабетекс» в начале осени 1999 или все та же «Семья» и «Медиа-Мост» в конце весны 2000 в России, терроризм во множестве стран мира осенью 2001 и т.д.
Контент-анализ грамматических категорий представляет собой достаточно редкое исследовательское начинание, стимулом к которому является гипотеза (весьма правдоподобная) о том, что употребление грамматических форм в меньшей степени, чем употребление лексики, контролируется автором текста и поэтому может послужить источником таких сведений о нем, которые он сам вовсе не собирался делать доступными своим читателям. В политической психологии существует специальная исследовательская методика, так называемый анализ когнитивной сложности, которая на основе фактически контент-аналитической процедуры позволяет делать выводы о том, насколько простым (или, напротив, сложным) является видение политической ситуации автором текста и как оно меняется со временем. Единицами контент-анализа, лежащего в основе оценки когнитивной сложности, являются, например, относимые обычно к служебной лексике категорические квантификаторы типа всегда, никогда, всякий, которым противостоят квантификаторы типа иногда, некоторый и т.п.; категорические (вроде знаменитого однозначно) оценки истинности в противоположность осторожным возможно или не исключено, что; языковые средства дифференцированного рассмотрения ситуации наподобие с одной стороны... с другой стороны; упоминания взаимодействия, баланса, взаимозависимости, компромисса и т.д. Известны и примеры контент-анализа чисто грамматических средств, например исследования соотношения глагольных форм, обозначающих, соответственно, процессы и результаты, исследование номинализованных (с отглагольными именами типа построение, усиление и т.п.) конструкций в языке партийных документов брежневского времени, отрицания в политическом тексте и др. Поскольку объектами контент-анализа могут быть не только вербальные (естественноязыковые), но и другие виды текстов (например, карикатуры, фотоснимки, рекламные клипы), постольку в числе структурно-семиотических единиц контент-анализа могут присутствовать визуальные и звуковые (чаще всего музыкальные) образы и символы, которые могут анализироваться на тех же основаниях, что и единицы естественного языка.
1.3. Понятийно-тематические единицы. В большинстве случаев контент-аналитик интересуется не словами как таковыми и тем более не грамматическими категориями, а стоящими за словами значимыми для него понятиями, темами, проблемами – иными словами, тем, что можно назвать понятийно-тематическими единицами. Исследователь, интересующийся тем, какое место в общественном сознании занимает, скажем, проблема преступности, обязан принимать во внимание не только присутствие в анализируемом информационном массиве слова преступность, но и упоминания заказных и всяких прочих убийств, бандитского беспредела, «крыши», «братков», авторитетов, власти криминала и проч. Тот, кого занимает проблема свободы, должен в своем анализе реагировать на упоминания давления на прессу, чиновничьего произвола, контролируемости СМИ, доступа к Internet и т.д. Интересующийся отношением общественного сознания к каким-то реалиям должен принимать во внимание самый широкий спектр позитивных, негативных и некоторых более конкретных оценок, которые могут быть даны этим реалиям, причем эти оценки вовсе не обязательно должны присутствовать в виде оценочных суждений.
1.4. Референциальные и квазиреференциальные единицы. К референциальным, точнее, конкретно-референциальным единицам относятся обозначения реальных личностей (как современных, так и исторических деятелей), событий, городов, стран, организаций и т.д.; это, так сказать, «энциклопедический» блок единиц анализа. Этот блок, особенно в части персоналий, весьма важен и диагностичен, поскольку позволяет определять личностные рейтинги и, что не менее существенно, оценивать идеологические системы с точки зрения присутствующих в них референтных «знаковых» фигур, своего рода «идеологических героев». Примером интересного исследования роли референтных фигур в российском оппозиционном дискурсе 1996–1997 может послужить работа А.В.Дуки. Способы обозначения в тексте конкретных фигур могут различаться (В.В.Жириновский, Владимир Вольфович, Вольфыч, Жирик, сын юриста, лидер ЛДПР, самый провосточный российский политик, главный либеральный демократ, либералиссимус), однако конкретно-референтная единица здесь во всех случаях одна. Квазиреференциальные единицы в политических текстах чаще всего бывают представлены обозначениями всякого рода «сил» – коллективных актеров политической сцены, референция которых может колебаться от реальной (типа КПРФ) через обобщенную (коммунисты, либералы, Запад, исламисты) к откровенно мифологизированной (мировая закулиса). Независимо от своей референции все эти персонажи присутствуют в идеологическом пространстве, им могут приписываться действия и оценки, и отношение к ним является немаловажным политико-идеологическим фактором. Грань между квазиреференциальными и некоторыми типами понятийно-тематических единиц размыта в силу того, что некоторые политические понятия способны и даже склонны (например, та же преступность) к метафорической персонификации. 1.5. Пропозициональные единицы и оценки. Их примеры приводились выше – Карфаген должен быть разрушен или Россия задыхается без инвестиций. Собственно говоря, это примеры высказываний, в основе которых лежат пропозиции – описания конкретных положений дел (ситуаций) безотносительно к их модальности (в первом примере – требование, во втором – констатация). Наряду с пропозициями для контент-анализа могут представлять (и очень часто представляют) большой интерес оценки (Это очень опасное решение). С логической точки зрения они обладают важными отличиями от пропозиций, однако для целей контент-анализа как собственно пропозиция, так и оценка могут рассматриваться как результат связывания некоторого объекта с некоторым атрибутом. Изучение динамики оценочных суждений, высказываемых в адрес тех или иных лиц, событий, институтов, – весьма распространенный тип контент-аналитического исследования.
1.6. Макроструктурные единицы. Под макроструктурными единицами понимаются достаточно сложные понятийные конструкции, образующие «верхние этажи» человеческих представлений о мире и, в частности, идеологических систем. Эти конструкции, как правило, носят характер сценариев и описывают стереотипные модели развития, с которыми сопряжены ожидания будущего, соображения о прошлом, эмоциональные ассоциации и т.д. Часто эти конструкции имеют литературные или фольклорные прототипы, что отражается в их названиях. Все они в очень сильной степени претендуют на объяснение действительности. Для обозначения таких конструкций чаще всего используется термин «идеологема»; в различных дисциплинах говорят также о мифологемах, кочующих образах и т.д. Среди подобного рода конструкций, присутствующих в общественном сознании современной России (и распределенных, порою причудливо, по разным идеологическим системам), имеются, например, следующие: Заговор, Оргия коррупции / Криминальная революция / Беспередел, Ограбление / Конверсия власти в собственность, Страна дураков / Город Глупов, «Нет, ребята, все не так», «Возвращение в цивилизацию» и др. Некоторые еще недавно значимые идеологемы (скажем, Борьба за власть, Естественный распад или Тотальная некомпетентность) в последние полтора-два года по различным причинам вышли из фокуса внимания средств массовой информации, а отчасти и населения.
1.7. Единицы, представляющие результаты концептуальных операций. Их довольно много, однако наибольший интерес для контент-анализа представляют метафоры, примеры и аналогии, которые в общем плане уже были охарактеризованы выше. Некоторые из метафор активно используются в политических текстах, и их использование считается диагностичным для характеристики как индивидуального сознания автора текста, так и состояния общественного сознания. Например, в политических текстах часто встречается упоминавшаяся «военная метафора» в варианте ПОЛИТИЧЕСКОЕ ПРОТИВОСТОЯНИЕ – ЭТО ВОЙНА, проявляющаяся в таких выражениях, как война с бедностью, удар по губернатору, атака со стороны оппозиции, разгромная публикация и т.д. При использовании такой метафоры политическое противостояние, независимо от того, в какой форме оно реально ведется, переживается как война, что может, кстати, иметь последствия и для реальных форм политического взаимодействия. Между тем «военная метафора» – это не единственный способ описания политического процесса (и, шире, жизни вообще); они могут описываться с помощью, например, «транспортной метафоры» и/или связанной с ней «метафоры пути» (Мы все вместе вступили на трудную дорогу), «архитектурной метафоры» (государственное строительство, выстраивание властной вертикали) и ряда других. Метафорика политических текстов достаточно подробно изучалась Дж.Лакоффом и его последователями, в том числе и в рамках контент-аналитической методологии (работы А.Н.Баранова); было показано, что, например, возрастание частотности военной метафоры является одним из коррелятов усиления напряженности в обществе.
Не менее диагностичным может быть исследование динамики примеров и аналогий – так, в российских политических текстах до недавнего времени настойчиво повторялась аналогия (принадлежащая В.Янову), в рамках которой Россия сравнивалась с Веймарской республикой.
1.8. «Поэтические» единицы. Под таковыми имеются в виду допускающие количественное измерение средства художественной выразительности – например, каламбуров, аллитераций и т.п.
2. ЧАСТОТНЫЕ И СИСТЕМНЫЕ ХАРАКТЕРИСТИКИ В КОНТЕНТ-АНАЛИЗЕ
2.1 Единицы, категории и признаки. При том, что контент-анализ является в своей основе количественным методом, в нем, как уже говорилось, почти всегда присутствует и значительная качественная составляющая. В принципе это верно уже постольку, поскольку единицы контент-анализа, как видно из предыдущего раздела, чаще всего все же являются содержательными и их выделение основывается на семантических (смысловых) критериях; многие из единиц представляют собой обобщенные категории (это относится прежде всего к темам и идеологемам). Иными словами, контент-аналитик занимается количественным анализом качественных категорий. Но этим дело не исчерпывается. Во многих контент-аналитических проектах осуществляется не только оценка степени представленности в тексте тех или иных единиц, но и одновременная оценка этих единиц по тем или иным градуированным качественным шкалам. В частности, это могут быть предложенные Ч.Осгудом шкалы абстрактности (фактически – трудности для восприятия) того или иного содержания; расстояния до индивидуума (какие-то содержательные компоненты могут непосредственно касаться читателя или читателей, а какие-то могут представлять лишь досужий интерес). В сочетании с результатами собственно контент-анализа оценка использованных единиц анализа (тематических) по указанным шкалам дает трехмерную схему типа, например, той, что была предложена французским культурологом А.Молем. Очевидно, что при анализе могут быть использованы и другие шкалы, кроме того, единицы контент-анализа могут объединяться в различные более широкие категории.
2.2 «Фронтальный» и «рейдовый» контент-анализ. Контент-аналитические исследования можно разделить на два больших класса, которые, пользуясь вышеупомянутой «военной метафорой», можно назвать фронтальными и рейдовыми. Задачей фронтального контент-аналитического исследования является составление максимально более полного представления об информационном потоке – либо на моментальном срезе, либо на протяжении некоторого периода с целью оценки динамики. Это, так сказать, попытка получить объективизированный ответ на вопрос «Что пишут?» Единицы такого анализа в принципе могут быть любыми, но чаще всего в таковом качестве выступают либо тематические единицы, либо ключевые слова, реже оценки и пропозиции и еще реже макроструктурные единицы. Такой анализ обычно носит сугубо прикладной характер и ведется в режиме мониторинга. Поскольку целью его является составление общего представления о содержании СМИ и через него – об общественном сознании, он должен в идеале стремиться к возможно более широкому охвату информационного потока. На практике, однако, полный охват чаще всего бывает невозможен, да зачастую и не нужен. Тем самым на повестку дня контент-аналитического исследования встает проблема составления репрезентативной выборки – традиционная проблема эмпирического социологического исследования, которая при неудачном решении может полностью дискредитировать его результаты. Решается она в случае контент-анализа традиционными социологическими методами.
Рейдовый анализ, в противоположность фронтальному, ориентирован на решение частных и порой довольно экзотических задач, вытекающих, как правило, из каких-то скорее исследовательских, нежели прикладных интересов, и применительно к нему проблема выборки решается в связи формулировкой этих исследовательских целей и определением единиц анализа. Обоснование выборки при этом производится с учетом стандартных социологических критериев, но может допускать и их нарушение; важно лишь, чтобы факт этого нарушения осознавался и необходимость нарушения специальным образом обосновывалась.
2.3 Обработка, презентация и интерпретация результатов. Кодирование данных при контент-анализе обычно осуществляется с помощью достаточно простых анкет или компьютерных программ, в которых фиксируется каждое появление в анализируемом тексте искомой единицы. (Проблема подготовки кодировщиков, очень важная в практическом плане, в настоящей статье не затрагивается.) Эта элементарная схема может быть усложнена многими разными способами. Прежде всего, наборы единиц с сопоставленными им количественными оценками, как правило, сопоставляются с другими количественными оценками тех же единиц. Это могут быть, например, результаты подсчета частотности упоминания одних и тех же тем для различных выпусков одного и того же печатного издания или одной и той же регулярно выходящей в эфир новостной программы (временные ряды); результаты аналогичного подсчета для различных изданий/программ или, скажем, обобщенных категорий изданий. Очевидно, что такие данные могут быть представлены с помощью разнообразных графических средств – диаграмм, графиков и т.д., обеспечивающих наглядность. Наглядность, следует заметить, важна не только для аналитика: наглядная диаграмма или впечатляющий график обладают большим потенциалом воздействия, особенно в обществе, привыкшем с почтением относиться к естественнонаучному инструментарию. Классификации зачастую бывают многомерными, и для представления это также могут использоваться различные формальные средства. На практике результаты контент-анализа чаще всего представляются рядами диаграмм, столбчатых или круговых, хотя понятно, что в распоряжении контент-аналитика имеется все разнообразие средств представления количественных данных. А также и качественных: для отображения отношений между единицами контент-анализа и результатов их категоризации используются такие стандартные средства отображения структур, как различные графы. Квантификация данных, естественно, создает необходимые предпосылки для применения к ним средств математического анализа. Помимо анализа частотного распределения, к ним относится анализ различного рода корреляций между переменными, ассоциаций, анализ сопряженности, кластерный анализ. Разумеется, весь этот инструментарий должен применяться корректно. Если при определении единиц контент-анализа и идентификации их в тексте добиться полной объективности возможно лишь в некоторых (как правило, не самых интересных) случаях, то при экспликации и обработке данных обеспечить следование строгим стандартам вполне возможно. Содержательная интерпретация результатов зависит от целей анализа; она является прежде всего творческим актом, результаты которого во многом предопределены политологической квалификацией и интуицией аналитиков. В ходе контент-аналитического исследования как для анализа текста, так и для последующей обработки его результатов может использоваться вычислительная техника. Второй тип использования не вызывает особых проблем: после квантификации, т.е. перевода данных в числовую форму, их математическая и, в частности, статистическая обработка может осуществляться многими разными программными средствами, в том числе стандартными статистическими пакетами типа SPSS. При анализе текста и последующем сохранении результатов этого анализа в базах данных могут использоваться специальные программы, предназначенные для целей лингвистических исследований. В частности, анализ метафорики в русских политических текстах велся с помощью разработанной в Институте русского языка РАН программы Dialex, способной осуществлять составление частотных словарей и конкордансов, а также поиск лексических единиц с их контекстами и сохранять его результаты в базе данных; в настоящее время завершается работа над более совершенной системой, предназначенной для решения тех же задач. Некоторая подсистема контент-анализа входит составной частью в отечественную систему прикладного анализа текстов ВААЛ. Имеется также ряд зарубежных контент-аналитических компьютерных систем, а также систем, потенциально применимых для целей контент-анализа – такова, в частности, система KEDS, разработанная Ф.Шродтом в Канзасском университете и используемая для анализа потока политических событий, отображаемых на ленте информационного агентства «Рейтер».
ЛИТЕРАТУРА
Моль А. Социодинамика культуры. М., 1973
Мангейм Дж., Б. Рич Р.К. [и др.]. Политология: методы исследования. М., 1997
Дука А.В. Политический дискурс оппозиции в современной России. – Журнал социологии и социальной антропологии. 1998, т. 1
Серио П. Русский язык и анализ советского политического дискурса: анализ номинаций. – Квадратура смысла: французская школа анализа дискурса. М., 1999
Баранов А.Н. Введение в прикладную лингвистику. М., 2000
Похожие работы
... не был упомянут. Прежде такое было бы немыслимо. В данной работе речь пойдет об использовании количественного контент-анализа в политико-социологических исследованиях. Конечно нельзя говорить о повсеместном использовании именно количественного контент-анализа. Вероятно, будет неразумно использовать данный метод в том случае, если мы имеем дело с уникальными документами, или же перед нами ...
... в социологическом исследовании. – Во второй главе дается характеристика контент-анализу, возможности его использования и технике проведения. – В третьей главе изучаются основные преимущества и недостатки контент-анализа по сравнению с опросом. При написании курсовой работы были изучены учебные материалы, монографии, публикации на страницах периодической печати. 1. Природа метода опроса в ...
... – это перевод в количественные, показатели массовой текстовой (или записанной на пленку) информации с последующей статистической ее обработкой. Его основные операции были разработаны американскими социологами X. Лассуэллом и Б. Берельсоном. Важный вклад в развитие процедур контент-анализа внесли российские и эстонские социологи, особенно А.Н. Алексеев, Ю. Вооглайд, П. Вихалемм, Б.Л. Грушин, Т.М. ...
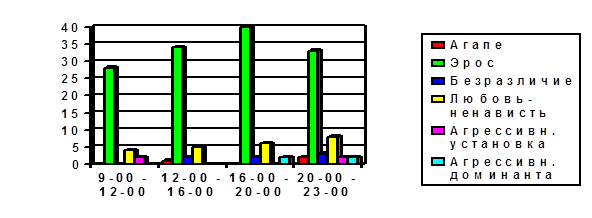
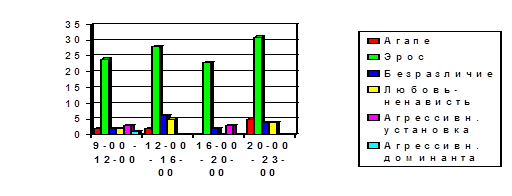
... в сферу педагогических исследований; 5. Контент-анализ не является универсальным средством получения информации и обладает как определенными достоинствами, так и ограничениями; 6. Контент-анализ вещания радиокорпорации «Авторадио» регистрирует ряд тенденций: а) наличие установок по шкале «Любовь-агрессия»; б) наличие установок по шкале «Толерантность – нонтолерантность» в сексуальной сфере, ...
0 комментариев