Веб-страницы и веб-приложения. 235
Основные возможности Shell
Некоторые специальные команды
История команд
Управляющие структуры скриптов
Алиасинг
Xxx tt
Старт X Window
Инсталирование периферии на примере ленточного накопителя
Операции над файловой системой
После того как отработает конфигурационный скрипт, достаточно набрать make, потом make install и можно приступать к конфигурированию сервера
Следующие, решите вопросы по функциональности ресурса
Навигация
Инсталирование периферии на примере ленточного накопителя
Администрирование локальных сетей
374863
знака
43
таблицы
0
изображений
4.8 Инсталирование периферии на примере ленточного накопителя.
Прежде чем перейти к включению ленточного накопителя нужно убедится в том что его SCSI id не совпадает ни с одним из уже установленных устройств (диски, CD-ROM, …). После физического подключения накопителя к SCSI шине необходимо в ядро. В случае использования SAM для этого необходимо войти в раздел Kernel Configuration -> Drivers, в списке драйверов найти stape, и активировать его выбрав опцию Actions -> Add driver to Kernel. После выхода из окна конфигурации ядра SAM предложит перестроить я дро и перегрузить компьютер, также создаст все необходимые файлы устройств в каталоге /dev/rmt. Все тоже самое можно сделать используя командыв hpux как это было указано выше. В качестве имя драйвера нужно использовать stape.
# cd /stand/build
# /usr/lbin/sysadm/system_prep –v –s system
# vi system
# /usr/sbin/mk_kernel –s system
# mv /stand/system /stand/system.prev
# mv /stand/vmunix /stand/vmunix.prev
# mv /stand/build/system /stand/system.prev
# mv /stand/build/vmunix_test /stand/vmunix
# shutdown –r now
# ioscan –f –C tape
Class I H/W Path Driver S/W State H/W Type Description
================================================================
tape 0 2/0/1.3.0 stape CLAIMED DEVICE HP HP35480A
# lsdev | grep tape
205 -1 stape tape
# mkdir /dev/rmt
# cd /dev/rmt
# mknod 0m c 205 0x003000
# mknod 0mn c 205 0x003040
# mknod 0mnb c 205 0x0030c0
Примечание: младшие номера для файла устройств можно узнать из файла /usr/include/sys/mtio.h (раздел Masks for minor number bits )
4.9 Инсталирование софта
Для работы с программными пакетами существует целая серия команд. Эти команды носят название SD-UX команды. Приведем список основных из них:
swintsall инсталирование программных пакетов
swremove удаление программных пакетов
swlist список инсталированого програмного обеспечения
swacl просмотр и модификация прав для защиты программных компонент
Управление процессамиЧто такое процесс ?
Процесс это запущенная программа обслуживаемая такими компонентами ядра как планровщик задач и подсистемой управления памятью. Процесс состоит из сегмента кода, данных и стека. С процессом ассоциировано два стека – пользовательский и системный. В дополнение к этому роцесс идентифицируется
· програмными данными (переменные, массивы, записи …)
· номером процесса PID, номером процесса родителя PPID, и номером группы процессов PGID
· идентификатором пользователя и группы PID, GID
· информацией о открытых файлах
· текущей рабочей директорией
Взаимоотношения процессов
Процессы в системе постороены по иерархическому принципу родитель-потомок. Каждый процесс (за исключением init) имеет одного родителя, но каждый родитель может иметь несколько потомков. Процесс потомок наследует окружение родителя (переменные окружения, открытые файлы, рабочую директорию). Все процессы за исключением init, pagedaemon, и
swapper) принадлежат к группам процессов.
Процесс ID и родительский процесс ID.
Во время создания процесса HP-UX назначает ему уникальный номер известный как процесс ID (PID), именно по этому номеру ядро идентифицирует процесс при выполнении системных вызовов. Помомо PID процесс имеет параметр как PPID (PID родителя). Используя программу ps можно посмотреть эти параметры:
$ ps -f
UID PID PPID C STIME TTY TIME COMMAND
torry 3865 3699 2 13:35:43 ttyp3 0:00 ps -f
torry 3699 3698 0 12:58:21 ttyp3 0:00 ksh
Идентификаторы пользователя и группы. (реальные и эффективные)
Помимо PID и PPID процесс имеет еще ряд идентификационных номеров:
* реальный идентификатор пользователя (a real user ID)
* реальный идентификатор группы (a real group ID)
* эффективный идентификатор пользователя (effective user ID)
* эффективный идентификатор группы effective group ID.
Реальный идентификатор пользователя это целое число показывающее владельца процесса. Реальный идентификатор группы это целое число показывающее группу к которой принадлежал пользователь создатель процесса. Комманда id показывает оба этих значения.
%id
uid=513(torry) gid=20(users)
% grep 513 /etc/passwd
torry:EqqHevH:513:20:Torry Ho,[44MY],474-1969 ,:/home/torry:/usr/bin/csh
Эффективный идентификатор пользователя и группы процесса позволяет процессу получать доступ к файлам или выполнять программы как пользователь имеющим ID равным эффективному. Обычно реальный и эффективные идентификаторы процессов совпадают, но не всегда. Когда эффективный идентификатор равен нулю, процесс начинает выполнять системные вызовы как администратор системы.
Эффективный идентификатор пользователя и группы остаються установленными до:
* окончания процесса.
* пока они не заменяться при выполнении системного вызова exec() программы c
установленными битами setuid или setgid.
* пока эффективный, реальный или сохраненные идентификаторы группы и пользователя не будут установлены системными вызовами setuid(), setgid(), setresuid().
Группы процессов
Каждый процесс за исключением системных процессов таких как init и swapper принадлежат к группе процессов. Когда созхдается задание, шелл присваивает всем процессам в задании одну и туже группу процессов. Сигналы при этом могут распостраняться на все процессы в группе, в этом и заключается преимущество управления заданиями. Каждая группа процессов идентифицируется целым числом которое называется Process Group ID (PGID). PGID у группы процессов равен PID лидера группы – создателя группы. Все процессы в группе имеют одинаковый GID. PGID не может быть использован системой пока живет группа процессов. Время жизни группы процессов определяется как период времени между созданием группы и когда процесс покидает группу. Процесс покидает группу если:
* когда другой процесс вызывает wait() или waitpid() функции на неактивный процесс.
* при вызове setsid или setpgid системных вызовов.
Списки доступа группы
Каждый процесс имеет до NGROUPS_MAX списков групп к которым он может принадлежать.
NGROUPS_MAX определено в /usr/include/limits.h, и обычно равняется 20. Процессу разрешается получать доступ к файлам с групповымим правами любой из списка групп. Списки доступа. Групповые права доступа контролируются командой chgrp.
Сессии
Каждый процесс является членом сессии. Все процессы запущенные после логина принадлежат к одной сессии. Процесс принадлежит к той же сессии что и его родитель. Процесс может изменить сессию используя системный вызов setsid(), при этом этот процесс будет являться лидером сессии. Временем жизни сессии будет время с момента ее создания до момента завершения последнего процесса.
Процессы и терминальное взаимодействие.
Каждая сессия имеет управляющий терминал. Лидер сессии подключенный к управляющему терминалу называется еще контрольным процессом. Исключением являются процессы- демоны (cron, inetd, …) которые не имеют управляющего терминала. Все процессы принадлежащих к одной сессии используют управляющий терминал как стандартное устройство ввода, вывода и ошибок. В любой момент времени лишь одна группа процессов в сессии может находится не в фоновом выполнении и она имеет исключительные права на работу с управляющим терминалом.
Попытки чтения фоновой группой процессов
Если процесс из фоновой группы пытается читать из управляющего терминала, этой группе посылается сигнал SIGTTIN, который по умолчанию приостанавливает процесс. В любом случае системный вызов read() возвращает –1.
Попытки чтения фоновой группой процессов
Если процесс в фоновой группе пытается записать в управляющий терминал, группа процессов получает при этом сигнал SIGTTOU, который по умолчанию останавливает процесс.
Создание процессов
Один процесс может создать другой через:
* паралельное выполнение другой программы
* выполнение другой программы с ожиданием ее окончания
На системном уровне процесс создается во время вызова системного вызова fork() или vfork().
Системный вызов fork()
Этот системный вызов создает новый процесс путем клонирования существующего. В старых реализациях HP-UX, система копировала полностью сегмент данных процесса, что негативно сказывалось на скорости и эффективности работы системы. Сейчас реализуется механизм известный как copy-on-write (на самом деле HP-UX реализует механизм copy-on-access), который позволяет использовать общие страницы памяти до момента записи.
Системный вызов vfork()
Приложения которым нужно создать независимый процесс могут делать это более эффективно если вместо fork() будут использовать vfork().Использование vfork оправдано только когда процесс потомок сразуже выполняет exec() или _exit() системные вызовы. При использовании vfork, потомок использует виртуальное адресное пространство родителя, поэтому оба процесса не могут работать одновременно. Процесс родитель при этом засыпает.
Системный вызов exec()
Очень часто после вызова fork() процесс запускает exec() на выполнение другой программы, при этом происходит перезапись сегмента кода и данных новым процессом.
Открытые файлы
При системных вызовах fork() и vfork() происходит наследование процессом потомков всех открытых файловых дискрипторов. Для системных параметра определяют ограничение на количество открытых файлов на процесс: maxfiles и maxfiles_lim. Параметр maxfiles определяет мягкий лимит как много открытых файлов может иметь процесс. Мягкий лимит наследуется после вызовов fork() vfork(). Параметр maxfiles_lim опреджеляет жесткий лимит на количество открытых файлов на один процесс. maxfiles должен быть меньше или равен maxfiles_lim. Мягкий лимит процесс наследует от своего родителя, который может быть уменьшен или увеличен до жесткого лимита (такое может сделать только процесс с правами администратора) с использованием системного вызова setrlimit().
Завершение процессов
Процесс завершается если:
* Он успешно окончил свое выполнение
* Процесс завершил.себя вызвав системный вызов exit()
* Процесс получил сигнал на с фатальным действием
Когда процесс завершается все открытые файлы завершаются и все занятые ресурсы освобождаются, после чего процесс умирает.
Команды управления процессами.
Управлять процессами можно либо с использованием команд HP-UX либо с использованием утилиты SAM. Наиболее часто используемые команды будут описаны ниже.
Команда ps (process status)
Команда ps показывает следующие параметры процессов:
* идентификатор пользователя User ID
* идентификатор процесса Process ID
* идентификатор родительского процесса Parent process ID
* командную строку породившую процесс
* терминал с которого была запущена комманда
* время (rela time CPU) которое было затрачено процессором на выполнение процесса.
Запущенная без опций она показывает process ID, terminal ID (tty), real CPU time usage, имя команды которую запустил на выполнение пользователь. С ключем –f ps также показывает имя пользователя, PPID, и время с момента когда процесс был fork-нут.
$ ps -f
UID PID PPID C STIME TTY TIME COMMAND
torry 3286 2016 9 16:19:03 ttyp1 0:00 ps -f
torry 25705 25649 0 08:47:58 ttyp1 0:02 -ksh /home/torry [ksh]
torry 2016 25705 0 15:13:02 ttyp1 0:24 vi processes.tag
Опция –e приводит к выдаче информации о всех активных процессах в системе. Опция -l (long) дополнительно показывает состояние процесса (S), параметр nice (NI), адрес процесса в памяти (ADDR), приоритет (PRI), и размер в блоках (SZ) образа процесса.
$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME COMD
1 R 513 11009 7793 5 179 20 d6e200 16 ttyu4 0:00 ps
1 S 0 7792 133 15 154 20 e06100 13 214fb0 ttyu4 0:00 rlogind
1 S 513 7793 7792 16 168 20 df5a80 52 7ffe6000 ttyu4 0:00 csh
Относительные приоритеты процессов -- nice и renice
Все процессы имеют приоритет устанавливаемый на основе таких факторов как прльзователь запустивший процесс и в каком окружении запущен процесс: с разделением времени или в реального времени. Комманда nice может быть использована для запуска процесса с более низким чем по умолчанию приоритетом. nice не уменьшает приоритетов уже запущеных процессов.
Команда renice позволяет изменять приоритеты уже запущеных процессов.
Программы для мониторинга производительности системы
top
Периодически показывает информацию о процессах в системе в порядке убывания использования ресурсов. Суммирует состояние системы (среднюю загрузку), использование виртуальной памяти. В отличии от psкоторый дает лишь снимок текущего состояния системы top выдает информацию с периодичностью. На мультипроцессорных системах, top выдает состояние каждого процессора раздельно.
sar
Выдает суммированую статистику о системной активности включая загрузку CPU, активность буферов, количество опреций ввода-вывода, терминальную активность, число системных, активность свопинга и п.р.
vmstat
Выдает информацию об использовании виртуальной памяти и активность CPU.
iostat
Выдает информацию об дисковой активности ввода-вывода, терминальной активности статистику CPU.
Управление процессами и ядро системыПроцесс может иметь доступ на чтение и запись к своему сегменту данных и стеку но не к другим процессам (за исключением сегментов разделяемой памяти). Процесс обменивается данными с другими процессами либо через системные вызовы либо через разделяемую память.
Приоритеты процесса
Все процессы в HP-UX могут находится в двух режимах: пользовательский режим и режим ядра. Когда процесс переключается в режим ядра (например при системном вызове) он исполняет код ядра и пользуется стеком ядра. В зависимости от приоритета и наличия других процессов процесса планировцик процессов может выделять ему больше или меньше квантов процессорного времени.
Приоритеты можно разделить на две части: диапазон POSIX standard приоритетов и диапазхон HP-UXприоритетов. POSIX standard приоритеты всегда выше чем все другие HP-UX приоритеты. Процесс который имеет меньшее числовое значение приоритета имеет преимущество при выполнении над процессом с большим цифровым значением приоритета. Следующий список выводит по категориям диапазоны приоритетов от большого к маленькому:
1. POSIX standard приоритеты (системный параметр)
POSIX standard приоритеты, известные как RTSCHED приоритеты, являются самыми
высокими приоритетами. Количество RTSCHED приоритетов есть системный параметр
(rtsched_numpri), устанавливаемый между 32 и 512 (default 32).
2. приоритеты реального времени (0-127)
Зарезервированы для процессов SCHED_RTPRIO стартующих с системного вызова
rtprio()
3. Системные приоритеты (128-177)
Используются системными процессами.
4. Пользовательские приоритеты (178-255)
Устанавливаются пользовательским процессам.
Ядро может изменять приоритеты процессов разделения времени (128-255) но не процессов реального времени (0-127).
Состояние процесса
В процессе своей жизни процесс может менять несколько раз свое состояние.Процессы размиещаются в очередях выполнения планировщика процесса в соответствии с их состоянием как определено в файле /usr/include/sys/proc.h . События, такие как получение сигнала могут переводить процесс из одного состояния в другое.
Процесс может находится в одном из следующих состояний:
* idle – процесс простаивает в очереди выполнения планировщика.
* run - процесс выполняется в очереди планировщика либо в пользовательском режиме либо в режиме ядра.
* stopped – процесс остановлен сигналом либо процессом родителем.
* sleep – процесс не выполняется пока он находится в спящем состоянии в очереди
(например он ждет окончания операции ввода-вывода)
* zombie – процесс уже фактически не существует, но так как он оставил для родителя
некоторые непрочитанные данные о своем выполнении он не может осуществить завершение.
Когда программа запускает прооцесс, ядро выделяет для него сроку из своей таблицы процессов и процесс находится в idle состоянии. Затем после получения ресурсови попадания в очередь он находится в состоянии run. Если процесс получкает сигнал SIGSTOP или его переводлят в режи трассировки, он переходит в stop состояние. После получения сигнала SIGCONT signal, процесс возвращается в состояние run. Если запущеный процесс ждет освобождение какихто ресурсов (семафор) или завершения операции вво-да вывода – он переходит в спящее состояние. Спящий процесс может быть отсваплен в первую очередь.Как только процесс заканчивает свою работу он переходит в состояние zombie.
1. Файловая система HFS.
2. Менеджер логических дисков LVM
3. Особенности файловой системы VxFS
4. Операции над файловой системой
10. 1. Файловая система HFS.
Одной из испольуемых HP-UX файловых систем является High Performance File System (HPFS, HFS) известная также как MCKusic или BSD файловая система. Файловая система это структура данных существующая на дисковых устройствах позволяющая сохранять и получать доступ к информации хранящейся в ней в иерархическом виде. Существует ряд причин исходя из которых информацию хранящуюся на дисковых носителях приходится организовывать в виде нескольких файловых систем, к ним можнно отнестиЖ
· Если суммарный обьем данных превышает обьем поддерживаемый одной файловой системой
· Для увеличения производительности системы, разнося данные имеющие разную структуру (средний размер файла, наличия ограничения на дисковое пространство для пользователей) на разные файловые системы или данные к которым идет частый доступ разносятся на разные физические устройства.
· В целях системной безопасности (запрет запуска программ с файловых систем, ограничение дискового места для файловой системы, и.т.п)
В общих чертах файловую систему HP-UX состоит из дерева каталогов (директорий) расположеных иерархически с корневым каталогом в вершине. Все файловые системы имеют свойство “монтируемости” заключающееся в том что любая файловая система может быть смонтирована (прикреплена) к существующей директории. Любую смонтированную файловую систему кроме корневой можно размонтировать. Монтирование корневой файловой системы осуществляет ядро, сразу же после загрузки.
Структура файловой системы HFS
Все HFS файловые системы имеют в своем составе следующие структуры:
· Главный суперблок
· Набор групп цилиндров
Структуры данных используемые в файловой системе содержатся в файле /usr/include/sys/fs.h. Первичный суперблок это непрерывный блок данных размеров 8К размещающийся перед началом файловой системы который содержит статическую информацию о файловой системы в момент ее создания (или последнего расширения):
· Размер файловой системы
· Количество inodes которые может хранить файловая система
· Позиция свободного места на диске
· Количество групп цилинров
· Позиции суперблоков, крупп цилиндро, блоков inodes и блоков данных
· Размер блока и фрагмента
Главный суперблок
Помимо этого главный суперблок содержит вспомагательную информацию о том когда последний раз монтировалась, модифицировалась и проверялась файловая система. Потому что главный суперблок содержит исключительно важную информацию о файловой системе, HP-UX всегда хранит его копии в каждой группе цилиндров. Одна из копий загружается в память после загрузки. Главный суперблок размещается в самом начале файловой системы и каждая группа цилиндпров имеет имеет свою копию суперблока. Таким образом достигается резервирование критически важной информации. Суперблоки групп цилиндров на диске обновляются каждый раз когда выполняется команда sync или когда файловая система размонтируется. В файле /etc/sbtab присутствует запись положения всех суперблоков файловых систем.
Группы цилиндровГруппа цилиндров – это группа дисковых цилиндров идущих подряд. Цилиндр представляет собой совокупность треков каждый из которых размещен на одинаковом расстоянии от центра поверхности дискового носителя. Все треки в цилиндрк доступны за одну операцию чтения/записи дисковой головки. В целях повышения производительности, цилиндры группируются (по умолчанию 16 цилиндров) в группы цилиндров. Каждая группа цилиндров имеет свой набор inodes и свою карту свободного пространства в группе. Такая организация хранения позволяеет минимизировать время поиска данных файла в группе цилиндров. Приведем структуру группы цилиндров:
| Структура | Размер |
| Главный суперблок 1 | 8 Кб |
| Запасной суперблок | 8 Кб |
| Информация группы цилиндров | 1 блок (4 Кб или 8 Кб) |
| Таблица inodes | Переменный 2 |
| Блоки данных | 0 или более блоков 3 |
1 только для первой группы цилиндров
2 см. раздел inodes
3 см. раздел блоки данных
Раздел информации о группе цилиндров хранит динамические параметры группы цилиндров, такие как:
· Количество inodes и блоков данных в группе цилиндров
· Указатели на последний использованый блок, фрагмент и inode
· Количество свободных фрагментов
· Карту использованных inodes
· Карту свободных блоков
Информация о группе цилиндров занимет один блок (размер блока определяется присоздании файловой системы и обычно равен либо четырем либо восьми килобайтам).
Inodes
Кроме хранения информации о состоянии файловой системы, группы цилиндров хранят ключевую информацию о inodes файловой системы – индексам файлов данных (и директорий). Дисковая inode содержит следующую информацию о файле:
· Тип файла и атрибуты доступа
· Количество ссылок на файл
· Владельца и группу файла
· Размер файла в байтах
· Временные метки (время последнего обращения, последней модификации)
· Указатели на блоки файловой системы содержащих данные
Когда файл открыт процессом, информация о его inode находится в памяти ядра (in-core inode) в сочетании с доаполнительными атрибутами, такими как:
· Статус inode, включая факт блокировки inode, отличается ли in-core inode от дисковой inode в следствие модификации файла, является ли файл точкой монтирования файловой системы …
· Цифровой адрес файловой системы содержащий файл
· Указатель на другие in-core inodes выстроенные в виде списка.
Если inode указывает на специальный (не регулярный) файл, то с ним ассоциируются дополнительные параметры, такие как является ли файл FIFO или pipe, символьным или блочным устройством или же директорией. Когда создается файловая система (команда newfs), создаются inodes. Количество inodes ограничивает количество файлов в файловой системе. При создании файловой системы по умолчанию система подразумевает что в среднем на одну inode припадает 2048 байт данных, что в большинстве случаев является более чем достаточным количеством. Иногда, возможна ситуация когда ядро сигнализирует об ошибке переполнения таблицы in-core inodes (inode: table is full). В этом случае необходимо изменить размер этой таблицы увеличив системный параметр ядра ninode.
Блоки данных
После суперблока, данных о группе цилиндров и таблице inodes идет место зарезервированное под блоки данных. HP-UX поддерживает блоки размером 4,8,16,32 и 64Кб. Размер блока задается при создании файловой системы (команда newfs). Большой размер блока дает выиграш в скорости передачи данных при работе с большими файламино при этом является причиной неэффективного использования дискового пространства приработе с маленькими (которых большинство в HP-UX) файлами. Поэтому в целях экономии дискового пространства блок может быть разделен на несколько фрагментов (1,2 или 4Кб). Размер фрагмента также определяется при создании файловой системы и не может иметь размер меньше чем одна восьмая размера блока.
11.
|
|
|
|
|
|
|
|
|
|
| |||
Как было указано выше, inode содержит указатель на блоки данных. В зависимости от размера файла данные содержащиеся в файлах могут быть доступны напрямую через указатели содержащиеся в inode, либо через двойную или тройную ссылку. Первый уровень ссылок позволяет адресовать непосредственно из inode 12 блоков данных, если этого не достаточно для адресации файла соответствующего размера то 12-й блок используется для адресации второго уровня. Размер ссылки составляет 4 байта, поэтому при размере блока в 4096 байт он может адресовать 1024 блока данных. Аналогичным образом осуществляется адресация третьего уровня. При этом ограничение на максимальный размер файла практически снимается. Помимо указателя на блок, inode хранит указатель на фрагмент. Этот указатель может быть интерпретирован как ссылка на целый блок или оддин или несколько его фрагментов. Если обьем данных файла такой что последний блок остается не полностью заполненным то при этом используются фрагмент(ы). Рассмотрим этот случай на примере 20К файла хранимого в 8К блоках. Файл будет хранится в 2-х полных блоках и 4-х фрагментах. Этот случай изображен на рисунке:
Размер файла
8 15 24 31 40 43 46
1
2
блоки адреceсуемые 3
напрямую с inode
4
12
Когда для записи файла требуется блок или фрагмент, система начинает искать свободныйе блоки на диске. Когда файловая система заполненная, выполняется очень долгие линейные поиски для нахождения свободных блоков, и обычно находится блок соседний с тем котрый использовался при записи предыдущего файла. В конце концов это приводит к сильному падению производительности файловой системы. Поэтому для более быстрого поиска свободных блоков на файловой системе резервируется некоторая часть свободного места (minfree). Этот параметр задается при создании файловой системы и может быть изменен в дальнейшем. Как правило это 10% от всего места отведенного под файловую систему.
Распределение дискового места.
Свободное место на диске определяется через битовую карту ассоциированную с каждой группой цилиндров. Битовая карта содержит один бит для каждого фрагмента. Для определения свободен ли блок, система проверяет смежные фрагменты. Пример куска битовой карты для файловой системы использующей 1024-х байтные фрагменты и 8192-х байтные блоки показан ниже:
| Битовая карта | 00000000 | 00000011 | 11111100 | 11111111 |
| Номера фрагментов | 0-7 | 8-15 | 16-23 | 24-31 |
| Номера блоков | 0 | 1 | 2 | 3 |
Фрагменты с номерами 14-21 в этом примере сободны (отмечены 1), а фрагменты 0-13 и 22-23 уже заняты. Любые восемь подряд идущих фрагментов не могут составлять блок, только восемь фрагментов выровненных по границе блока могут составить блок. HP-UX пытается положить все все файлы находящиеся в одной директории в одну и туже группу цилиндров. Новосозданные директории помещаются в те группы цилиндров где наибольшее количество свободных inodes и наименьшее количество директорий. Если размер файла превішает порог определяемій параметром maxbpg (определяется при создании файловой системі и может меняться в дальнейшем) то HP-UX начинает выделять свободные блоки из другой группы цилиндров. Это позволяет более тесно группировать в одну группу цилиндров файлы находящиеся в одной директории путем размазывания больших файлов по нескольким группам цилинров.
Модификация файлов в HP-UX
Каждій раз когда происходит запись в файл, данные сначала записываются в буферный кэш находящийся в памяти. Физический диск обновляется ассинхронно по отношению к кэшу. Изменение данных на диске принадлежащие к определенной inode происходит позже, за исключерием если файл біл откріт в синхронном режиме (параметр O_SYNC O_SYNCIO в системных вызовах open() и fcntl()). Если система останавливается без сброса буферов на диск то файловая система приходит в сосотояние с нарушеной целостностью. В єтом случае необходимо ее восстановление утилитой fsck. Команда sync может быть использована для принудительного сброса буферов на диск в любой момент времени. Системній демон syncer выполняет периодический сброс буферов на диск. Приведем список изменений происходящих в фаловой системе при выполнении некоторых основных операций над ней:
Главный суперблок сбрасывается на диск при выполнениии команды
umount или команды sync при условии что файловая
система была модифицирована
Inodes в зависимости от параметра ядра fs_async информация
Обновляется либо синхронно либо ассинхронно по
Отношению к буферному кєшу
Блоки данных In-core блоки (директории, файлы, пайпы, симлинки,
FIFO) записываются на диск после модификации. Блоки данных файлов буферизируются. Физически запись на диск происходит когда выполняется команда sync или системный вызов fsync() или непосредственно после модификации если на файл при открытии установлен флаг O_SYNC.
Информация о группе эта информация сбрасывается на диск после цилиндров выполнения sync (fsync).
Замечание: команда reboot –n перегружает систему без сброса буферов на диск. Эту команду нужно использовать после выполнения проверки и устранения сбоев корневой файлой системы. Остальные файловые системы необходимо проверять только в отмонтированном состоянии.
Менджер логических дисков LVM
Перед появлением HP-UX 10.* управление дисками в сриях HP 800 и HP 700 осуществлялось различным образом. В серии 800 была возможность разбивки диска на жестко определенные партиции, а также управление через LVM. В серии 700 таких возможностей не было, и единственное что можно было использовать – так это использование целого диска для создания файловой системы. С появлением HP-UX 10.* ситуация радикально изменилась, LVM стал доступен на обеих сериях и является рекомендуемым инструментом для работы с файловыми системами. Он представляет собой псевдодрайвер ядра системы эмулирующий логические диски.
Что такое Logical Volumes и в каких случаях их следует использовать ?
Logical Volumes (LV) это набор дисковых участков с одного или более дисков организованных в таком виде, что операционная система видит их как один логический диск. Как и физические дискиони могут быть использованы для поддержки файловых систем, raw областей данных, swap или dump областей. Использование LV оправдано в случаях больших файловых систем которые не умещаются на одном диске и (или) нуждаются в последующем расширении а также в случаях когда необходимо организовать резервирование (зеркалирование) данных или когда к файловой системе предъявляются жесткие требования по производительности.
| |
| |
| |
(диски)
|
|
| ||||||||||
Volume Groups
(пул дисков)
Для использования LVM диски должны быть инициализированны как physical volumes. Physical volumes идентифицируются именами ссответствующих файлов-устройств дисков /dev/dsk/cntndn и /dev/rdsk/cntndn. Затем из одного или нескольких дисков собирается volume group. Один физический диск может принадлежать только к одной volume group. Максимальное число volume group которое может быть в системе определяется параметром maxvgs. Одна volume group может содержать не более 255 физических дисков. Дисковое пространство из volume group распределяется между одной или несколькими logical volumes. Дисковое пространство из logical volumes может быть использовано для создания файловой системы, под swap или dump области. LVM разбивает каждый диск на набор адресуемых блоков называемых physical extents. Их размер определяется во время создания volume group и одинаков для всех дисков входящих в volumes group. Размер physical extents варьируется от 1 до 256 Мб, по умолчанию он равен 4Мб. Базовым блоком для адресации logical volumes является logical extent, он напрямую отображается в physical extents. В HP-UX команды показывающие эти отображения имеют названия pvdisplay и lvdisplay:
# pvdisplay /dev/dsk/c0t5d0
--- Physical volumes ---
PV Name /dev/dsk/c0t5d0
VG Name /dev/vg00
PV Status available
Allocatable yes
VGDA 2
Cur LV 9
PE Size (Mbytes) 4
Total PE 511
Free PE 81
Allocated PE 430
Stale PE 0
IO Timeout (Seconds) default
# lvdisplay /dev/vg00/lvol1
--- Logical volumes ---
LV Name /dev/vg00/lvol1
VG Name /dev/vg00
LV Permission read/write
LV Status available/syncd
Mirror copies 0
Consistency Recovery MWC
Schedule parallel
LV Size (Mbytes) 48
Current LE 12
Allocated PE 12
Stripes 0
Stripe Size (Kbytes) 0
Bad block off
Allocation strict/contiguous
Если logical volumes используется для корневой (root) файловой системы, первичной swap области или dump области, physical extents должны распределяться методом contiguous. Это означает что между они должны следовать непрерывно на одном физическом диске и между ними не должно возникать прпомежутков. Другие logical volumes использующиеся для некорневых файловых систем могут не следовать этому ограничению.
Для определения требуемого объема logical volume необходимого для создания файловой системы можно использовать следующую диаграмму:
Управление Logical Volumes (LV)
Системная утилита SAM позволяет выполнять большинство но не все операции над LV. К тем задачам с которыми она справляется можно отнести:
· Создание и удаление volume groups.
· Добавление и удаление дисков из volume groups.
· Создание, удаление и модификация logical volumes.
· Создание и увеличение обьема файловых систем находящихся на logical volumes.
· Cоздание и модификация swap и dump logical volumes.
Для этого, после запуска SAM нужно войти в раздел “Disks and file systems” а затем в один из нужных подразделов. Все дальнейшие действия выполняются с использованием графической оболочки и являются интуитивно понятными. Все тоже самое можно выполнить используя команды HP-UX.
Создание physical volume (PV).
pvcreate /dev/rdsk/c0t6d0
Все данные имеющиеся на этом диске будут потерены, в качестве аргумента программы pvcreate необходимо использовать символьный (raw) файл-устройство диска. Послк инициализации, данный диск можно рассматривать как physical volume.
Помещение PV в одну из volume groups (VG)
Если необходимо создать новую VG, то в самом начале нужно сделать директорию для файлов-устройств отвечающих за данную VG:
mkdir /dev/vgnn
cd /dev/vgnn
Затем нужно создать необходимые файлы устройств:
mknod /dev/vgnn/group c 64 0xNN0000
В качестве старшего номера устройства всегда нужно использовать 64, 0xNN0000 является младшим номером устройств и NN представляет собой уникальный среди всех VG номер. Теперь можно приступать к созданию VG:
vgcreate /dev/vgnn /dev/dsk/c0t6d0 …
Вторым (третьим, четвертым …) аргументом этой команды должен быть файл-устройство блочного типа соответствующего physical volume который не является членом какойто из существующих VG.
Создание Logical Volume.
lvcreate /dev/vgNN
После чего появится блочные и символьные файлы устройств /dev/vgNN/lvoln и /dev/vgNN/rlvoln. LVM сам выберет подходящий номер n. Для создания LV с именем отличным от того что создается по умолчанию нужно воспользоваться опцией –n. Данный LV будет иметь нулевой размер, в дальнейшем его можно увеличить. Также указав опцию –L можно создать LV заранее необходимого размера (в Мб), при этом реальный размер LV будет округлен в большую сторону и кратен целому количеству physical extents.
Задачи котоые можно выполнить только с использованием комманд HP-UX
К ним можно отнести:
· Расширение LV за счет определенного диска
· Создание корневой (root) VG и корневого LV
· Резервное копирование и восстановление конфигурации VG
· Перемещение данных с одного LVM диска на другой
· Уменьшение размера LV
Расширение LV за счет определенного диска
Допустим имеется необходимость создать LV на 120Мб, причем первые 60 Мб необходимо взять с одного диска а оставшиеся 60 с другого. Так поступают часто в случаях когда необходимо повысить производительность файловой системы за счет паралельного использования нескольких дисков. Вначале создаем LV нулевого размера:
lvcreate –n lvol11 /dev/vg00
затем выполняем необходимые расширение ее обьема за счет определенных дисков:
lvextend –L 60 /dev/vg00/lvol11 /dev/dsk/c0t5d0
lvextend –L 60 /dev/vg00/lvol11 /dev/dsk/c0t6d0
Создание корневой VG и корневого LV
Корневой VG это VG который используется системой при загрузке. На нем размещается LV содержащий корневую файловую систему, первичный swap и dump области. Ниже приводятся этапы последовательного создания корневого VG. Во-первых создается PV на котором размещается LIF раздел в котором находятся загрузочные утилиты. Для этого в команде pvcreate используется опция -B:
pvcreate -B /dev/rdsk/c0t6d0
Создаем корневой LV:
vgcreate /dev/vgroot /dev/dsk/c0t6d0
Помещаем загрузочные утилиты в LIF область VG:
mkboot /dev/rdsk/c0t6d0
Записываем в LIF область AUTO файл:
mkboot –a “hpux (;0)/stand/vmunix” /dev/rdsk/c0t6d0
После выполнения всех этих действий корневая VG готова к созданию на ней LV. Корневой LV должен быть самым первым в этой VG, и следовать сразу за boot областью. Это значит что он должен начинаться с нулевого physical extent. Теперь можно переходить к созданию корневого LV, при его создании нужно включить опцию “смежный LV” (-C) и запретить перемещение bad блоков (-r):
lvcreate –C y –r n –n root /dev/vgroot
lvextend –L 160 /dev/vgroot/root /dev/dsk/c0t6d0
В конеце необходимо пометить сосзданный LV как корневой:
lvlnboot –r /dev/vgroot/root
Резервное копирование и свосстановление конфигурации Volume Groups
Для создания резервной копии конфигурации VG нужно воспользоваться командой vgcfgbackup. Пежде чем выполнять эту команду нужно убедится что все LV в данной VG находятся в состоянии available/syncd (для этого можно воспользоваться командой vgdisplay –v). По умолчанию команда vgcfgbackup сохраняет конфигурационый файл VG под именем /etc/lvmconf/volume_group_name.conf. Это имя можно переопределить задав опцию –f.
Восстановление конфигурации выполняется командой vgcfgrestore. Перед этим необходимо предварительно деактивировать данную VG командой vgchange. Например:
vgchange –a n /dev/vg01
vgcfgrestore –n /dev/vg01 /dev/rdsk/c0t6d0
Выполнение этих команд приведет к восстновлению информации о VG vg01 из файла /etc/lvmconf/vg01.conf . Затем необходимо активировать данную VG:
vgchange –a y /dev/vg01
Перемещение и переконфигурирование дисков
В жизни могут возникнуть ситуации при которых необходимо:
· Переместить диск входящий в состав VG на другое положение в пределах системы.
· Переместить целую VG с одной системы на другую.
Файл /etc/lvmtab содержит информацию о отображении LVM дисков на соответствующие VG. При любых изменениях связанных с дисками и VG в системе этот файл изменяется, однако это не текстовый файл и напрямую его редактировать нельзя. Вместо этого нужно пользоваться программами vgexport и vgimport.
Перемещение диска в системе.
Для перемещения диска в системе на новое место необходимо выполнить следующее:
· Создать резервную копию конфигурации VG в которую входит диск и данных хранящихся на диске
· Деактивировать VG в состав которой входит диск:
vgchange –a n /dev/vgxxx
· Удалить запись ассоциированную с этим диском из /etc/lmvtab а также файлы устройств из каталога /dev/vgxxx
vgexport /dev/vgxxx
· Создать заново VG, и добавить запись в /etc/lvmtab
mkdir /dev/vgxxx
mknod /dev/vgxxx/lvolN c 64 0x010000
vgimport /dev/vgxxx /dev/dsk/cntndn
· Активировать вньовь ипортированную VG
vgchange –a y /dev/vgxxx
· Создать резервную копию конфигурации VG
vgcfgbackup /dev/vgxxx
Перемещение диска между системами
Для перемещения диска с одного места на другое между двумя системами необходимо выполнить следующие действия:
· Деактивировать VG
vgchange –a n /dev/vgxxx
· Удалить информацио о VG из /etc/lvmtab указав имя map файла который будет содержать удаляемую информацию (он содержит также имена удаляемых LV из VG)
vgexport –p –v –m plan_map vgxxx
просмотрев map_file и убедившись в правильности можно выполнить реальное удаление
vgexport –v –m plan_map vgxxx
· Переносим map_file на новую систему, останавливаем старую систему, переносим диски на новую.
· На новой системе создаем VG
mkdir /dev/vgxxx
cd /dev/vgxxx
mknod /dev/vgxxx c 64 0x080000
· Импортируем новую конфигурацию. Для просмотра используется опция –p, для выполнения реального импорта она должна отстутствовать: (предполагается что в новую систему переносились диски которые распозхнались как /dev/dskc0t2d0 /dev/c0t3d0)
vgimport –p –v –m plan_map /dev/vgxxx /dev/dskc0t2d0 /dev/c0t3d0
· Активируем VG
vgchange –a y /dev/vgxxx
Перенос данных на другой physical volume.
Для переноса данных содержащихся в LV с одного диска на другой необходимо воспользоваться командой pvmove. Например для переноса данных из LV /dev/vg01/lvo1 с диска /dev/dsk/c0t0d0 на /dev/c0t1d0:
pvmove –n /dev/vg01/lvol1 /dev/dsk/c0t0d0 /dev/c0t1d0
Для полного переноса данных с одного диска на другой можно воспользоваться:
pvmove /dev/dsk/c0t0d0 /dev/c0t1d0
Уменьшение обьема Logical Volumes
Для уменьшения обьема LV используется команда lvreduce. Однако в этом случае данные хранящиеся в файловой системе на этом LV будут потеряны, поэтому необходимо предварительное резервное копирование. Также можно воспользоваться другой техникой – вначале удалить LV командой lvremove, а затем создать LV требуемого размера командой lvcreate.
3. Особенности файловой системы VxFSVxFS является HP-UX реализацией журнальной файловой системы известной как JFS на базе версии корпорации VERITAS. Прежние версии HP-UX (меньше 10.*) имели в своем арсенале лишь HFS, начиная с 10.01 появилась дополнительная опция на использование VxFS в качестве файловой системы. Однако VxFS не может быть использована как файловая система для раздела /stand из которого происходит зщагрузка ядра. В ранних версиях 10-го релиза HP-UX она так же не могла быть использована для корневой файловой системы. По сравнению с HFS имеет меньшее время восстановление при сбоях и имеет повышеную производительность на больших объемах данных, т.к. блок используемый ею может состоять из множества физических блоков. Т.к. это журнальная файловая система то она позволяет вести online backup. Однако в отличии от HFS она потребляет больше памяти.
В стандартной поставке HP-UX включены лишь базовые элементы VxFS. Дополнительные функциональные возможности возможны только при использовании отдельного пакета под названием HP OnlineJFS.
Похожие работы
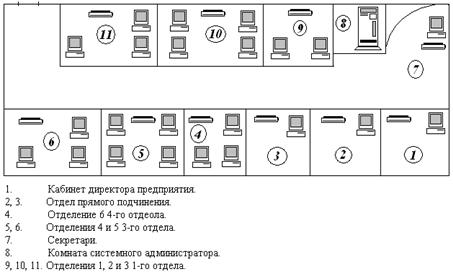
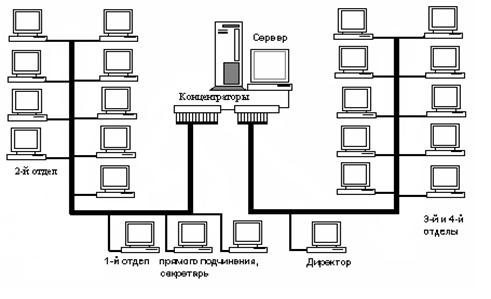
... доступа к информации. Поэтому очень важно, чтобы сети были защищены от постороннего вмешательства. Построение локальных сетей предусматривает создание программно-аппаратных решений с целью защиты информации от кражи. Для этого производится установка, настройка и обслуживание фаерволов, маршрутизаторов и коммутаторов. Обслуживание локальных компьютерных сетей должно проводиться непрерывно. ...
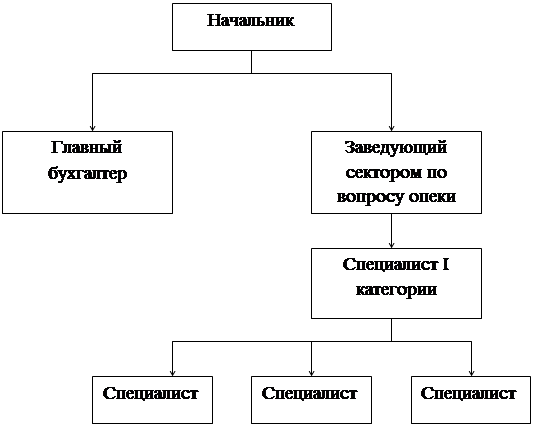
... надёжность системы, данный стандарт с успехом применяется в магистральных каналах связи. Сравнительный анализ существующих технологий представлен в Приложении А. 2. АНАЛИЗ И КОМПЛЕКС МЕРОПРИЯТИЙ ПО ОБСЛУЖИВАНЮ ЛОКАЛЬНОЙ СЕТИ СЛУЖБЫ ПО ДЕЛАМ ДЕТЕЙ СЕВЕРОДОНЕЦКОЙ ГОРОДСКОГО СОВЕТА 2.1 Административные, технические и программные характеристики Службы по делам детей Северодонецкой городской рады ...
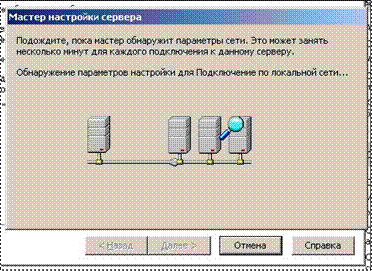
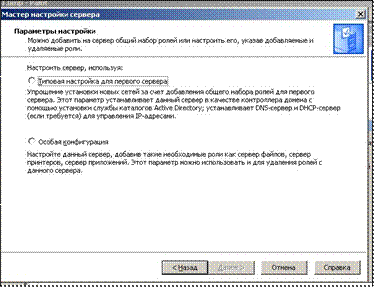
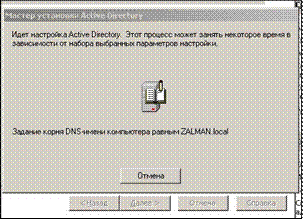
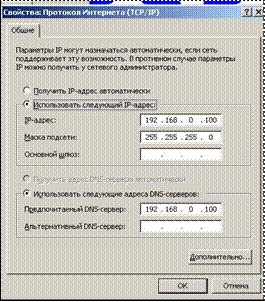
... концентратора, требуется также сетевой кабель, так называемый двужильный провод Ethernet RJ-45 (10BaseT или 100BaseT), который немного больше обычного телефонного кабеля. 3. Создание локальной сети 1. Обнаружение параметров сети. 2. Выбираем параметры настроек. 3. Задание корня DNS-имени ZALMAN. local. 4. Настраиваем IP-адрес и адрес DNS-сервера. 5. Локальные ...
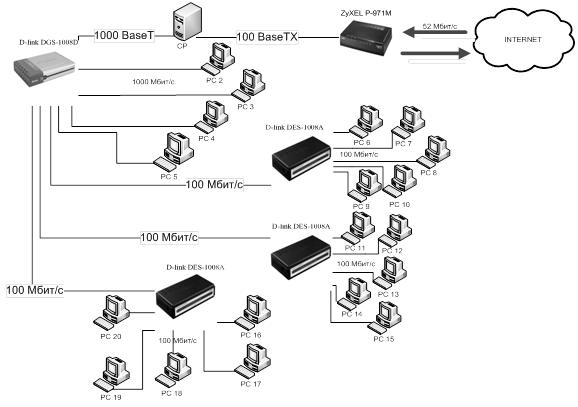




... разнообразием активного коммутационного оборудования, которое применяется для локальных и глобальных связей. В данном разделе были рассмотрены стандарты беспроводного доступа к сети Интернет. Так же был рассмотрен вопрос о назначении локальной сети. 2. Конструкторская часть 2.1 Выбор и обоснование технологий построения ЛВС Исходя из технического задания, для связи рабочих станций в ...
0 комментариев