Протоколы
взаимодействия
Протокол
V.25bis
Записать текущий
профиль по
команде
AT&W
Информационные
сигналы
Процедуры
отвечающего
модема
Частотная
модуляция
Протокол V.23
Протоколы V.34,
V.34+, V.Fast
Факс-протоколы
модуляции
Протокол V.17
Протоколы ZyX,
ZyCELL
Протокол V.42
Сжатие данных
в протоколах
MNP
Протокол MNP7
Протокол XModem
Рекомендации
по выбору протокола
передачи файлов
Навигация
Протокол V.42
Классификация модемных протоколов
109528
знаков
17
таблиц
13
изображений
4.2. Протокол V.42
4.2.1. Основные характеристики
С
тандарт
V.42, принятый ITU-T
в ноябре 1988 года,
определяет
процедуру LAPM
(Link Access Procedure for Modems),
схожую по
возможностям
с MNP4. Преимущества
LAPM по сравнению
с MNP4 заключаются
в повышенной
скорости передачи
по плохим телефонным
каналам и хорошей
согласованности
с другими
стандартами,
основанными
на протоколе
HDLC. Процедура
LAPM
Рис. 4.1. Функции DCE без аппаратной коррекции ошибок
очень близка к процедурам LAPB и LAPD, применяемых в сетях Х.25 и в сетях интегрального обслуживания ISDN.
Согласно V.42 требуется реализация как процедуры LAPM, так и протокола MNP4, как альтернативного варианта повышения достоверности. Это означает, что модем V.42 может взаимодействовать с модемами типа MNP4. Однако при таком соединении не будут задействованы все возможности V.42. Во время установления связи модем V.42 проверяет, может ли удаленный модем работать согласно полного протокола V.42 или только по протоколу MNP4. При этом предпочтение отдается протоколу V.42. Таким образом, модем V.42 пытается использовать процедуры коррекции ошибок согласно V.42, и если это не получается, то производится попытка запустить MNP4. Если и эта попытка оказывается безуспешной, устанавливается связь без коррекции ошибок.
В отличие от аппаратуры канала данных без аппаратного исправления ошибок (рис. 4.1), рекомендация V.42 выделяет в функциональной схеме DCE дополнительный блок защиты от ошибок (рис. 4.2).
Согласно V.42 блок управления модема должен определять, поддерживает ли удаленная аппаратура функции исправления ошибок, и координировать согласование соответствующих процедур.
Блок защиты от ошибок предназначен для управления процедурами исправления ошибок. Именно он и реализует протокол связи LAPM.
Р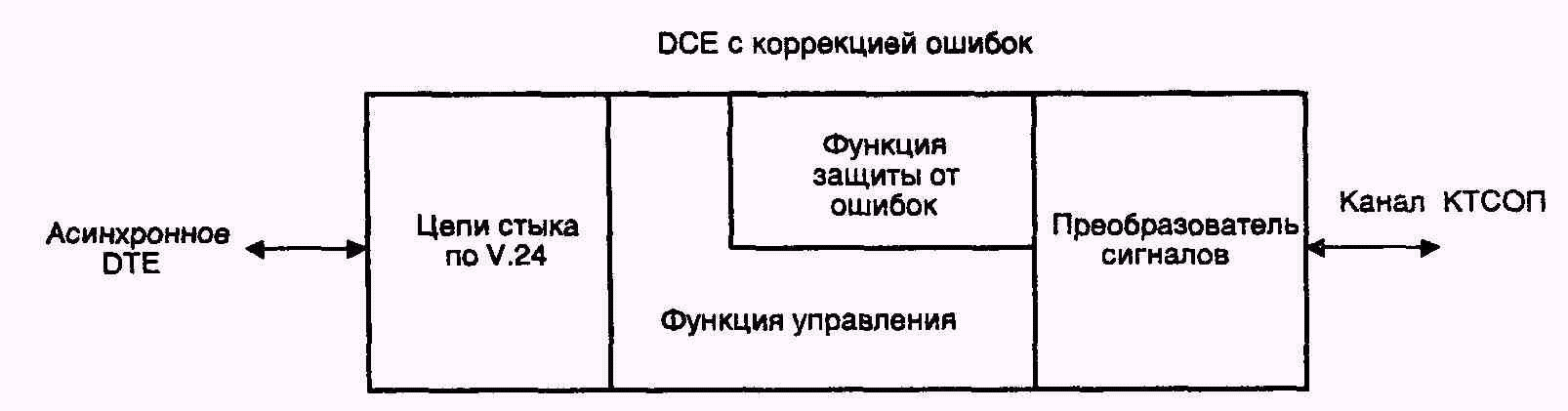
екомендация
V.42 регламентирует
также цепи
интерфейса
V.24, задействованные
в процессе
работы модемов
по протоколу
V.42 (рис. 4.3).
Рис. 4.2. Функции DCE согласно V.42
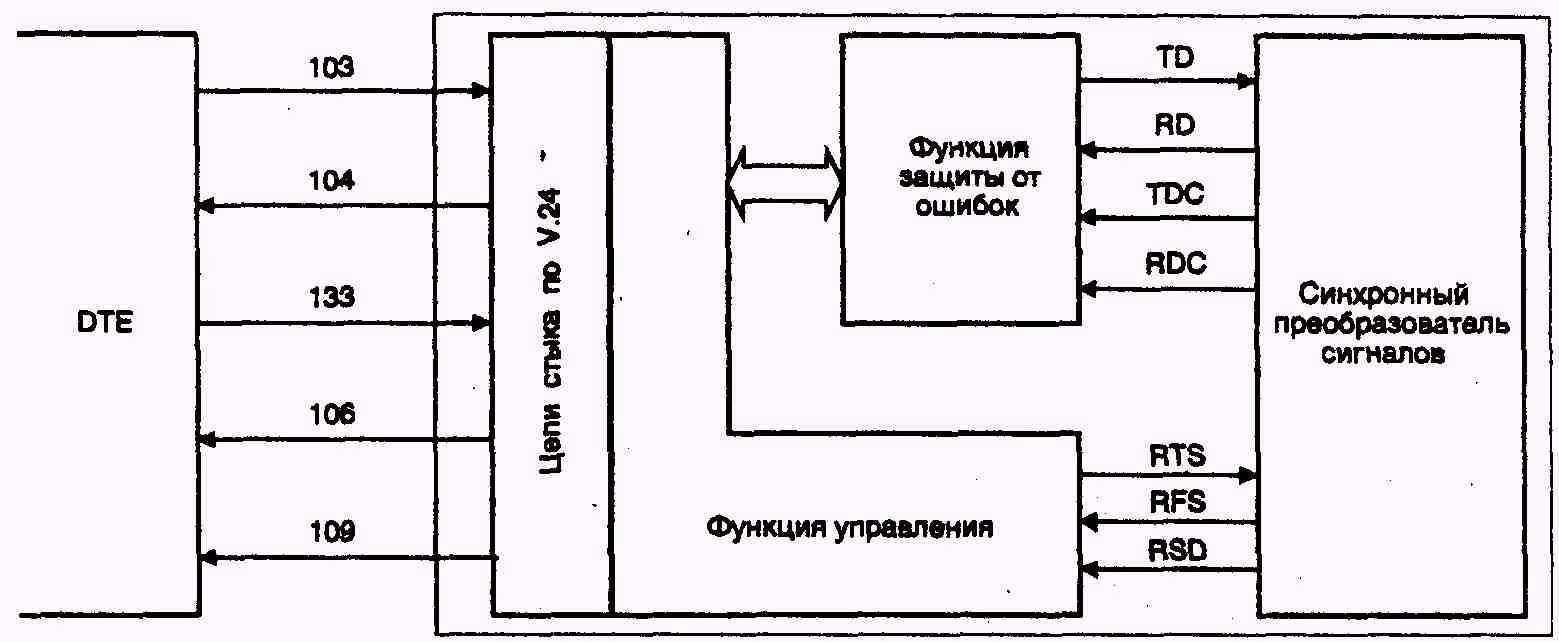
Рис. 4.3. Цепи, работающие при защите от ошибок, где TD — передаваемые данные; RD — принимаемые данные; TDC — синхронизация передаваемых данных; RDC — синхронизация принимаемых данных; RTS — запрос передачи; RFS — готовность к передаче; RSD — детектор принимаемого линейного сигнала из канала данных.
5 ПРОТОКОЛЫ СЖАТИЯ ДАННЫХ
5.1. Основные методы сжатия
Как известно, применение сжатия данных позволяет более эффективно использовать емкость дисковой памяти. Не менее полезно применение сжатия при передачи информации в любых системах связи. В последнем случае появляется возможность передавать значительно меньшие (как правило, в несколько раз) объемы данных и, следовательно, требуются значительно меньшие ресурсы пропускной способности каналов для передачи той же самой информации. Выигрыш может выражаться в сокращении времени занятия канала и, соответственно, в значительной экономии арендной платы.
Н![]()
аучной
предпосылкой
возможности
сжатия данных
выступает
известная из
теории информации
теорема кодирования
для канала без
помех, опубликованная
в конце 40-х годов
в статье Клода
Шеннона "Математическая
теория связи".
Теорема утверждает,
что в канале
связи без помех
можно так
преобразовать
последовательность
символов источника
(в нашем случае
DTE) в последовательность
символов кода,
что средняя
длина символов
кода может быть
сколь угодно
близка к энтропии
источника
сообщений Н(Х),
определяемой
как:
где p(xi) — вероятность появления конкретного сообщения xi из N возможных символов алфавита источника. Число N называют объемом алфавита источника.
Энтропия источника Н(Х) выступает количественной мерой разнообразия выдаваемых источником сообщений и является его основной характеристикой. Чем выше разнообразие алфавита Х сообщений и порядка их появления, тем больше энтропия Н(Х) и тем сложнее эту последовательность сообщений сжать. Энтропия источника максимальна, если априорные вероятности сообщений и вероятности их выдачи являются равными между собой. С другой стороны, Н(Х)=0, если одно из сообщений выдается постоянно, а появление других сообщений невозможно.
Единицей измерения энтропии является бит. 1 бит — это та неопределенность, которую имеет источник с равновероятной выдачей двух возможных сообщений, обычно символов "0" и "1".
Энтропия Н(Х) определяет среднее число двоичных знаков, необходимых для кодирования исходных символов (сообщений) источника. Так, если исходными символами являются русские буквы (N=32=2 ) и они передаются равновероятно и независимо, то Н(Х)=5 бит. Каждую буквы можно закодировать последовательностью из пяти двоичных символов, поскольку существуют 32 такие последовательности. Однако можно обойтись и меньшим числом символов на букву. Известно, что для русского литературного текста H(Х)=1,5 бит, для стихов Н(Х)=1,0 бит, а для текстов телеграмм Н(Х)=0,8 бит. Следовательно, возможен способ кодирования в котором в среднем на букву русского текста будет затрачено немногим более 1,5, 1,0 или даже 0,8 двоичных символов.
Если исходные символы передаются не равновероятно и не независимо, то энтропия источника будет ниже своей максимальной величины HMAX(Х)=log2N. В этом случае возможно более экономное кодирование. При этом на каждый исходный символ в среднем будет затрачено n*= Н(Х) символов кода. Для характеристики достижимой степени сжатия используется коэффициент избыточности RИЗБ= 1—Н(Х)/HMAX(Х). Для характеристики же достигнутой степени сжатия на практике применяют так называемый коэффициент сжатия Кcж. Коэффициент сжатия — это отношение первоначального размера данных к их размеру в сжатом виде, — обычно дается в формате К.сж:1 Путем несложных рассуждений можно получить соотношение RИЗБ ≥1—1 /Kcж.
Известные методы сжатия направлены на снижение избыточности, вызванной как неравной априорной вероятностью символов, так и зависимостью между порядком поступления символов. В первом случае для
кодирования исходных символов используется неравномерный код. Часто появляющиеся символы кодируются более коротким кодом, а менее вероятные (редко встречающиеся) — более длинным кодом.
Устранение избыточности, обусловленной корреляцией между символами, основано на переходе от кодирования отдельных символов к кодированию групп этих символов. За счет этого происходит укрупнение алфавита источника, так как число N тоже растет. Общая избыточность при укрупнении алфавита не изменяется. Однако уменьшение избыточности, обусловленной взаимными связями символов, сопровождается соответствующим возрастанием избыточности, обусловленной неравномерностью появления различных групп символов, то есть символов нового укрупненного алфавита. Происходит как бы конвертация одного вида избыточности в другой.
Таким образом, процесс устранения избыточности источника сообщений сводится к двум операциям — декорреляции (укрупнению алфавита) и кодированию оптимальным неравномерным кодом.
Сжатие бывает с потерями и без потерь. Потери допустимы при сжатии (и восстановлении) некоторых специфических видов данных, таких как видео и аудиоинформация. По мере развития рынка видеопродукции и систем мультимедиа все большую популярность приобретает метод сжатия с потерями MPEG 2 (Motion Pictures Expert Group), обеспечивающий коэффициент сжатия до 20:1. Если восстановленные данные совпадают с данными, которые были до сжатия, то имеем дело со сжатием без потерь. Именно такого рода методы сжатия применяются при передаче информации в СПД.
На сегодняшний день существует множество различных алгоритмов сжатия данных без потерь, подразделяющихся на несколько основных групп.
Кодирование повторов (Run-Length Encoding, RLE).
Этот метод является одним из старейших и наиболее простым. Он применяется в основном для сжатия графических файлов. Самым распространенным графическим форматом, использующим этот тип сжатия, является формат PCX. Один из вариантов метода RLE предусматривает замену последовательности повторяющихся символов на строку, содержащую этот символ, и число, соответствующее количеству его повторений. Применение метода кодирования повторов для сжатия текстовых или исполняемых (*.ехе, *.соm) файлов оказывается неэффективным. Поэтому в современных системах связи алгоритм RLE практически не используется.
Вероятностные методы сжатия
В основе вероятностных методов сжатия (алгоритмов Шеннона-Фано (Shannon Fano) и Хаффмена (Huffman)) лежит идея построения "дерева", положение символа на "ветвях" которого определяется частотой его появления. Каждому символу присваивается код, длина которого обратно пропорциональна частоте появления этого символа. Существуют две разновидности вероятностных методов, различающих способом определения вероятности появления каждого символа:
статические (static) методы, использующие фиксированную таблицу частоты появления символов, рассчитываемую перед началом процесса сжатия;
динамические (dinamic) или адаптивные (adaptive) методы, в которых частота появления символов все время меняется и по мере считывания нового блока данных происходит перерасчет начальных значений частот.
Статические методы характеризуются хорошим быстродействием и не требуют значительных ресурсов оперативной памяти. Они нашли широкое применение в многочисленных программах-архиваторах, например ARC, PKZIP и др., но для сжатия передаваемых модемами данных используются редко — предпочтение отдается арифметическому кодированию и методу словарей, обеспечивающим большую степень сжатия.
Арифметические методы
Принципы арифметического кодирования были разработаны в конце 70-х годов В результате арифметического кодирования строка символов заменяется действительным числом больше нуля и меньше единицы. Арифметическое кодирование позволяет обеспечить высокую степень сжатия, особенно в случаях, когда сжимаются данные, где частота появления различных символов сильно варьируется. Однако сама процедура арифметического кодирования требует мощных вычислительных ресурсов, и до недавнего времени этот метод мало применялся при сжатии передаваемых данных из-за медленной работы алгоритма. Лишь появление мощных процессоров, особенно с RISC-архитектурой, позволило создать эффективные устройства арифметического сжатия данных.
Метод словарей
Алгоритм, положенный в основу метода словарей, был впервые описан в работах израильских исследователей Якоба Зива и Абрахама Лемпеля, которые впервые опубликовали его в 1977 г. В последующем алгоритм был назван Lempel-Ziv, или сокращенно LZ. На сегодняшний день LZ-алгоритм и его модификации получили наиболее широкое распространение, по сравнению с другими методами сжатия. В его основе лежит идея замены наиболее часто встречающихся последовательностей символов (строк) в передаваемом потоке ссылками на "образцы", хранящиеся в специально создаваемой таблице (словаре). Алгоритм основывается на том, что по потоку данных движется скользящее "окно", состоящее из двух частей. В большей по объему части содержатся уже обработанные данные, а в меньшей помещается информация, прочитанная по мере ее просмотра. Во время считывания каждой новой порции информации происходит проверка, и если оказывается, что такая строка уже помещена в словарь ранее, то она заменяется ссылкой на нее.
Большое число модификаций метода LZ — LZW, LZ77, LZSS и др. — применяются для различных целей, Так, методы LZW и BTLZ (British Telecom Lempel-Ziv) применяются для сжатия данных по протоколу V.42bis, LZ77 — в утилитах Stasker и DoudleSpase, а также во многих других системах программного и аппаратного сжатия.
Похожие работы


... служит для безопасной передачи данных Рисунок 2.4 - Внешний модема типа ADSL 3. Экономический расчет Целью экономического расчета дипломного проекта является усовершенствование модема путем защиты передачи данных, определение величины экономического эффекта от использования разработанной программы защиты передачи данных "Северодонецкая автошкола" качественная и количественная оценка ...
... , этих программ оказалось достаточно много и они не всегда совместимы между собой. Практически каждый пpогpаммист способен создать подобный "почтовик" на базе которого можно было бы создать компьютерную сеть. 1.4. Международные стандарты модемов Наибольшее pаспpостpанение получили так называемые HAYES-совместимые модемы, по имени фирмы - производителя одного из первых модемов. Такие модемы ...
... и пуск в эксплуатацию средств вычислительной техники отечественного и зарубежного производства, гарантийное и послегарантийное обслуживание техники. Телекоммуникационные услуги предоставляются круглосуточно. 5.5. КОМПЬЮТЕРНАЯ СЕТЬ "COMPNET" a. АО "Селф" (г.Москва) и научно-производственное предприятие "БанкИнформСервис" (г.Владимир) обслуживают компьютерную сеть COMPNET. b. Сеть имеет ...
... , пеpиодическим изданиям (pефеpативные и польнотекстные), куpсовым pаботам, дипломным пpоектам, космосу, политике, споpту и т.д. Самой новой и наиболее пеpспективной фоpмой использования модемной связи и мощи компьютеpных сетей является электpонная биpжа. Это весьма надежный и быстpый путь поиска делового паpтнеpа, поставщика товаpов/сыpья, ...
0 комментариев