IP - сети с поддержкой базового набора услуг по передаче данных с единой политикой нумерации и маршрутизации, работающим сервисом имен DNS
Практическая часть
Www.real.ulan-ude.ru
ДАННЫЕ ОБЩЕЙ ОБРАБОТКИ (позиции 0-7)
ЗАГОЛОВОК - ИМЯ / ЗАГЛАВИЕ
Примечание об использовании имени или заглавия в качестве заголовка (не в качестве предметной рубрики)
Примечание об использовании имени или заглавия в качестве заголовка (не в качестве предметной рубрики)
ФОРМИРОВАНИЕ ССЫЛКИ “СМ.” - НАИМЕНОВАНИЕ ОРГАНИЗАЦИИ
ФОРМИРОВАНИЕ ССЫЛКИ "СМ. ТАКЖЕ" - НАИМЕНОВАНИЕ ОРГАНИЗАЦИИ
ДЕСЯТИЧНАЯ КЛАССИФИКАЦИЯ ДЬЮИ (ДК ДЬЮИ)
ИНДЕКСЫ ДРУГИХ КЛАССИФИКАЦИЙ
Навигация
Www.real.ulan-ude.ru
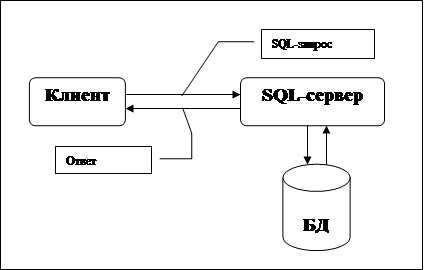
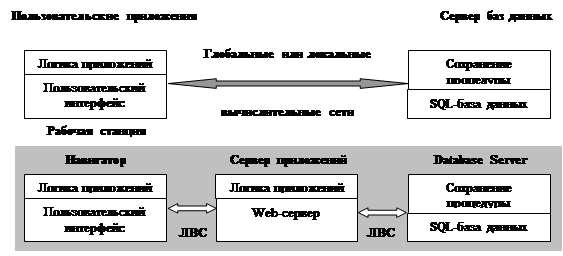
Организация доступа к базам данных в Интернет
194681
знак
23
таблицы
7
изображений
195.161.69.170 www.real.ulan-ude.ru
195.161.69.171 www.real2.ulan-ude.ru
Этим Вы создадите виртуальных хост со следующими свойствами:
Имя - serv1
Доступен по адресу http://serv1 (или http://195.161.69.171).
Расположен, соответственно, в директории f:/home/serv1.
Директория для хранения документов - f:/home/serv1/www, доступная по адресу http://serv1.
Директория для CGI - f:/home/serv1/www/cgi, доступная по адресу http://serv1/cgi/
Файлы журналов хранятся в f:/home/serv1/log
Ну вот, мы создали один виртуальный хост! Если будет необходимо сделать второй, нужно просто проделать аналогичные действия, заменив параметры, связанные с расположением хоста на диске. Главное, не забудьте в этом случае указать другой IP-адрес (лучше всего указывать их последовательно, начиная с 195.161.69.170, затем 195.161.69.171 и т.д. - в этом случае все работает корректно). Желательно также для этих целей не указывать IP-адрес http://195.161.69.169, так как это - адрес главного сервера.
Кстати, необходимо заметить, что главный хост (невиртуальный, тот, который мы создали в разделах 1 и 2) по-прежнему доступен по адресу http://195.161.69.169 или http://www.real.ulan-ude.ru. Более того, его директория cgi-bin "видна" всем созданным виртуальным хостам, так что Вы можете ее использовать.
Установка PerlЭто совсем просто, за исключением, может быть, выбора директории для Perl. А именно, Вы ДОЛЖНЫ разместить Perl. Замечу, что это очень важно, так как Perl требует, чтобы в каждом скрипте первой строкой стоял путь к Perl-интерпретатору; например, эта строка может выглядеть так:
#!/usr/local/bin/perl
Эту же строку можно было бы написать и так:
#!/usr/local/bin/perl.exe
или даже так:
#!f:\usr\local\bin\perl.exe
Это заставляет искать Perl-интерпретатор в директории f:/usr/local/bin/ (если диск f: не указан, это означает, что он совпадает с диском, на котором расположен Apache). Ясно, что если установить Perl не в такую же директорию, Вам придется каждый раз менять эту самую первую строку во всех скриптах при закачке их на сервер. Итак, далее буду считать, что эта директория такова, как на большинстве Apache-серверов:
f:/usr/local/bin
ВНИМАНИЕ: очень распространенной ошибкой является установка Perl не в ту директорию или не на тот диск. Еще раз обращаю внимание на то, где должен быть расположен транслятор.
Если все же по какой-то необъяснимой причине не придерживаетесь моего совета, то проверьте первую строку в скрипте. Она должна указывать не на директорию с Perl, а на исполнимый файл perl.exe. Напоминаю, что #!/usr/local/bin/perl заставляет искать Perl-интерпретатор perl.exe в директории f:/usr/local/bin/, а не в f:/usr/local/bin/perl
Если все же установлен путь неправильно, Apache выдаст непонятное сообщение об ошибке, а в errors.log появится сообщение: couldn't spawn child process.
Вот шаги, приводящие к цели:
Первым делом создайте директорию
f:/usr/local/bin
Затем скачайте дистрибутив Perl - файл с именем perl_setup.exe (436.137 байт), желательно в только что созданную директорию. Это саморазворачивающийся архив, Вам нужно будет просто его запустить, чтобы разархивировать в текущую директорию.
Теперь настроим сервер. Найдите в файле конфигурации Apache conf/httpd.conf строчку
AddHandler cgi-script .bat .exe
Замените ее на
AddHandler cgi-script .bat .exe .pl .cgi
Как это ни странно, но эту директиву AddHandler иногда указывать не обязательно. Однако лучше перестраховаться...
Вот, собственно, и все. Можете пользоваться Perl-транслятором. Для проверки его работоспособности используйте такой скрипт (помещенный, разумеется, в директорию cgi-bin или аналогичную):
#!/usr/local/bin/perl
print "Content-type: text/html\n\n";
print "It works!<br>\n";
system("dir");
Настройка и установка Apache Jserv v 1.1Устанвка
Установка Jserv также проста как и установкм самого веб-сервера Apache. Для это нужно естественно имет файл установки ApacheJServ-1.1.2-2.exe (14).
Запустив файл установки нужно указать дирикторию куда будет установлены все нужные файлы для работы Jserv`а. После чего программа установки попрости указать путь до виртуальной машины Java, она должна быть уже установлена.
Виртуальная машина Java можно скачать с веб сайта фирмы Microsoft - SDKJava40.exe. Поле того как программе установки будет указан правельный путь до JVM, он попросит указать путь до Java Servlet Devolopment Kit 2 (JSDK), после чего будет запрошен путь до конфигурационного файла httpd.conf веб-сервера. Вот собственно и вся установка.
Настройка
А теперь нужно рассказать про настройку Jserv`а что бы он мог работать вместе с веб-сервером. Для того что бы Jserv запускался вместе с веб-сервером нужно все что находится в файле jserv.conf перенести в файл настройка веб-сервера Apache httpd.conf, желательно в конец.
Разберем синтаксис. Первый параметр это LoadModule.
Его синтаксис очень прост LoadModule [имя модуля в нашем случае это - jserv_module] [путь до модуля "./ApacheModuleJServ.dll"]. В конечном итоге эта строчка должна выглядить так: LoadModule jserv_module "./ApacheModuleJServ.dll"
Следующая интересующий нас параметр это - ApJServManual он говорит веб-серверу о том как запускать Jserv on=вручную off=автозапуск.
Далее идет параметр ApJServProperties "./conf/jserv.properties" это путь до файла настроек Jservs.
2.4. Использование языка Perl 2.4.1. Основные особенности PerlPerl - интерпретируемый язык, приспособленный для обработки произвольных текстовых файлов, извлечения из них необходимой информации и выдачи сообщений. Perl также удобен для написания различных системных программ. Этот язык прост в использовании, эффективен, но про него трудно сказать, что он элегантен и компактен. Perl сочитает в себе лучшие черты C, shell, sed и awk, поэтому для тех, кто знаком с ними, изучение Perl-а не представит особого труда. Cинтаксис выражений Perl-а близок к синтаксису C. В отличие от большинства утилит ОС UNIX Perl не ставит ограничений на объем обрабатываемых данных и если хватает ресурсов, то весь файл обрабатывается как одна строка. Рекурсия может быть произвольной глубины. Хотя Perl приспособлен для обработки текстовых файлов, он может обрабатывать так же двоичные данные и создавать .dbm файлы, подобные ассоциативным массивам. Perl позволяет использовать регулярные выражения, создавать объекты, вставлять в программу на С или C++ куски кода на Perl-е, а также позволяет осуществлять доступ к базам данных, в том числе Oracle.
Этот язык часто используется для написания CGI-модулей, которые, в свою очередь, могут обращаться к базам данных. Таким образом может осуществляться доступ к базам данных через WWW.(5,6)
2.5 Использование языка Java 2.5.1 Основные особенности
Развитие Internet и World Wide Web заставляет совершенно по-новому рассматривать процессы разработки и распределения программного обеспечения. Для того, чтобы выжить в мире электронного бизнеса и распространения данных, язык Java должен быть
безопасным, высокопроизводительным, надежным.Работа на различных платформах гетерогенных сетей отбрасывает традиционную схему распределения ПО, версий ПО, модификации ПО, объединения ПО и т.д. Для решения проблем гетерогенных сред язык должен быть
нейтральным к архитектуре, переносимым, динамически подстраиваемым.Разработчики Java с самого начала хорошо понимали, что язык, предназначенный для решения проблем гетерогенных сред, также должен быть
простым - его должны с легкостью использовать все разработчики ясным - разработчики должны без больших усилий выучить Java объектно-ориентированным - он использует все преимущества современных методологий разработки ПО и подходит для написания распределенных клиент-серверных приложений многопоточным - для обеспечения высокой производительности приложений, выполняющих одновременно много действий (например, в мультимедийных системах) интерпретируемым - для переносимости и большей динамичностиНеобходимо более подробно рассмотреть перечисленные характеристики Java.
Простота
Простота языка входит в ключевые характеристики Java: разработчик не должен длительное время изучать язык, прежде чем он сможет на нем программировать. Фундаментальные концепции языка Java быстро схватываются и программисты с самого начала могут вести продуктивную работу. Разработчиками Java было принято во внимание, что многие программисты хорошо знакомы с языком С++, поэтому Java, насколько это возможно, приближен к С++.
В Java не включены некоторые редко используемые, плохо понимаемые и усложняющие работу возможности С++, которые приносят больше проблем, чем преимуществ. Пришлось отказаться от
перегрузки операторов (но перегрузка методов в Java осталась), множественного наследования, автоматического расширяющего приведения типов.Добавилась автоматическая сборка мусора, упрощающая процесс программирования, но несколько усложняющая систему в целом. В С и С++ управление памятью вызывало всегда массу проблем, теперь же об этом не придется много заботиться.
Объектно-ориентированность
Язык Java с самого начала проектировался как объектно-ориентированный. Задачам распределенных систем клиент-сервер отвечает объектно-ориентированная парадигма: использование концепций инкапсуляции, наследования и полиморфизма. Java предоставляет ясную и действенную объектно-ориентированную платформу разработки.
Программисты на Java могут использовать стандартные библиотеки объектов, обеспечивающие работу с устройствами ввода/вывода, сетевые функции, методы создания графических пользовательских интерфейсов. Функциональность объектов этих библиотек может быть расширена.
Надежность
Платформа Java разработана для создания высоконадежного прикладного программного обеспечения. Большое внимание уделено проверке программ на этапе компиляции, за которой следует второй уровень - динамическая проверка (на этапе выполнения).
Модель управления памятью предельно проста: объекты создаются с помощью оператора new. В Java, в отличие от С++, механизм указателей исключает возможность прямой записи в память и порчи данных: при работе с указателями операции строго типизированы, отсутствуют арифметические операции над указателями. Работа с массивами находится под контролем управляющей системы. Существует автоматическая сборка мусора.
Данная модель управления памятью исключает целый класс ошибок, так часто возникающих у программистов на С и С++. Программы на Java можно писать, будучи уверенным в том, что машина не "повиснет" из-за ошибок при работе с динамически выделенной памятью.
Безопасность
Java разработана для оперирования в распределенных средах, это означает, что на первом плане должны стоять вопросы безопасности. Средства безопасности, встроенные в язык, и система исполнения Java позволяют создавать приложения, на которые невозможно "напасть" извне. В сетевых средах приложения, написанные на Java, защищены от вторжения неавторизованного кода, пытающегося внедрить вирус или разрушить файловую систему.
Независимость от архитектуры
Java разработан для поддержки приложений, внедряемых в гетерогенные сетевые среды. В подобных средах приложения должны исполняться на различных аппаратных архитектурах, под управлением различных операционных систем и во взаимодействии с интерфейсами различных языков программирования. Для обеспечения платформо-независимости программ компилятор Java генерирует байт-код - архитектурно-нейтральный промежуточный формат программы, создаваемый для эффективной передачи кода на различные аппаратные и программные платформы. При выполнении программы байт-код интерпретируется исполняющей машиной Java. Один и тот же Java-байткод будет исполняться на любой платформе.
Переносимость
Архитектурная независимость - лишь составная часть переносимости. В отличие от С или С++ в Java не существует понятия "зависимости от реализации", когда речь идет о размерности базовых типов. Форматы типов данных и операции над ними четко определены. Тем самым, программы остаются неизменными на любой платформе - не существует несовместимости типов данных на аппаратных и программных архитектурах.
Архитектурная независимость и переносимость программного обеспечения Java обеспечивается виртуальной машиной Java (Java Virtual Mashine - JVM) - абстрактной машиной, для которой компилятор Java генерирует код. Специальные реализации JVM для конкретных аппаратных и программных платформ предоставляют уже конкретную виртуальную машину. JVM базируется на стандарте интерфейса переносимых операционных систем (POSIX).
Высокая производительность
Производительность всегда заслуживает особого внимания. Java достигает высокой производительности благодаря специально оптимизированному байт-коду, легко переводимому в машинный код. Автоматическая сборка мусора выполняется как фоновый поток с низким приоритетом, обеспечивая высокую вероятность доступности требуемой памяти, что ведет к увеличению производительности. Приложения, требующие больших вычислительных ресурсов, могут быть спроектированы так, чтобы те части, которые требуют интенсивных вычислений, были написаны на языке ассемблера и взаимодействовали с Java платформой. В основном, пользователи ощущают, что приложения взаимодействуют быстро, несмотря на то, что они являются интерпретируемыми.
Интерпретируемость
Java-интерпретатор может выполнять Java байт-код на любой машине, на которой установлен интерпретатор и система выполнения. На интерпретирующей платформе фаза сборки программы является простой и пошаговой, поэтому процесс разработки существенно ускоряется и упрощается, отсутствуют традиционные трудные этапы компиляции, сборки, тестирования.
Многопоточность
Большинству современных сетевых приложений обычно необходимо осуществлять несколько действий одновременно. В Java реализован механизм поддержки легковесных процессов-потоков (нитей). Многопоточность Java предоставляет средства создания приложений с множеством одновременно активных потоков.
Для эффективной работы с потоками в Java реализован механизм семафоров и средств синхронизации потоков: библиотека языка предоставляет класс Thread, а система выполнения предоставляет средства диспетчеризации и средства, реализующие семафоры. Важно, что работа параллельных потоков с высокоуровневыми системными библиотеками Java не вызовет конфликтов: функции, предоставляемые библиотеками, доступны любым выполняющимся потокам.
Динамичность
По ряду соображений Java более динамичный язык, чем С++. Он был разработан специально для подстройки под изменяющееся окружение. В то время как компилятор Java на этапе компиляции и статических проверок не допускает никаких отклонений, процесс сборки и выполнения сугубо динамический. Классы связываются только тогда, когда в этом есть необходимость. Новые программные модули могут подключаться из любых источников, в том числе, поставляться по сети. В случае с браузером HotJava и другими подобными приложениями интерактивный выполняемый код может быть загружен откуда угодно, что позволяет производить прозрачные модификации приложений. В результате возможно создание интерактивных служб, безболезненно модифицируемых, обслуживающих большое количество клиентов и обеспечивающих развитие электронного бизнеса через Internet.
Вывод
Если описанные выше характеристики рассматривать по отдельности, то их можно найти во многих программных платформах. Радикальное новшество заключается в способе, предлагаемом Java и системой выполнения, который сочетает в себе все характеристики для предоставления гибкой и мощной системы программирования.
Разработка приложений на Java приводит к получению программного обеспечения, которое:
переносимо на разные архитектуры, операционные системы и графические пользовательские интерфейсы безопасно высокопроизводительноБлагодаря Java работа по разработке программного обеспечения значительно упрощается, все старания направлены на достижение конечной цели: вовремя получить передовой продукт, опирающийся на солидную основу Java. За более полной информацией об языке можно обратится на сайт разработчиков (9,10) .
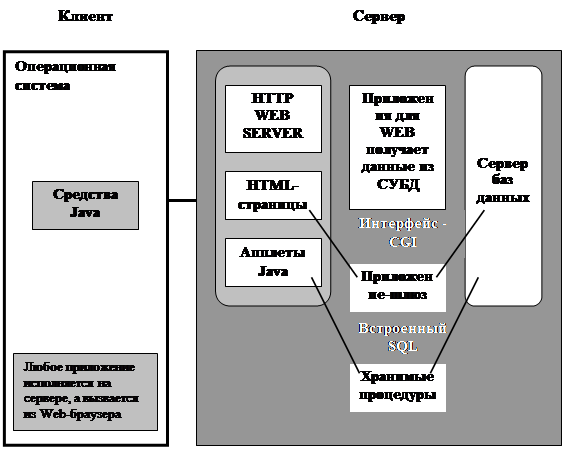
2.5.2. Взаимодействие с СУБДПлатформа Java с ее принципом "Write Once, Run AnywhereТМ" ("Пишем один раз - используем везде") представляет собой безопасное гибкое многоплатформное решение для разработки мощных Java-приложений, работающих в Интернет и внутрикорпоративных интрасетях. Открытые расширяемые интерфейсы прикладного программирования (Java Platform API) позволяют разработчикам создавать приложения и апплеты Java. Набор интерфейсов для предприятия Java Enterprise API позволяет поддерживать единообразное, стандартное, беспрепятственное сопряжение и взаимодействие с информационными массивами предприятия.
Сопряжение Java с базами данных (Java Database Connectivity - JDBCТМ) представляет собой платформно-независимый промышленный стандарт совместимости Java с самыми разными базами данных. JDBC поддерживает интерфейс API на уровне вызовов для доступа к базам данных, работающим с языком SQL. JDBC позволяет разработчикам Java использовать принцип "Пишем один раз - используем везде" в приложениях, требующих доступа к корпоративным данным (7).
2.6. Реализация доступа к базе данных 2.6.1. Общее описание
Поисковая программа (SearchEngein.class) написана на языке Java с использованием технологии Java servlets (17) на базе веб сервера Apache (16). Чтобы программа работала в системе, под управлением операционной системой Windows NT должны присутствовать следующие компанеты приведенные в списке:
1. Веб сервер Apache, по архитектуру Win32;
2. Apache Java server, так же под архитектуру Win32;
3. Виртуальная Java машина (JVM) также под архитектуру Win32;
4. Java Servlet Development Kit (JSDK) 2.0
Настройка и установка этих команентов была описана выше. Тонкости настройки для правильной работы программы буду описаны ниже.
Ограничении по применению программы практически не существует кроме аппаратного обеспечения, минимальная конфигурация системы должна быть такой:
Процессор с тактовой чистатой 266 или выше.
Память не меньше 64 мегабайт, чем больше, тем лучше.
Жесткий диск любой.
Остальное оборудование по усмотрению администратора сервера.
Выше было сказано, что ограничений нет, уточняю почему, так как программа откомпилирована в аппаратно-независимый код (байт-код) оно с легкостью может быть перенесена на другую платформу MacOS или Unix-система. Нужно будет всего лишь переписать файлы классы на диск, естественно настроив систему соответствующим образом.
2.6.2. Описание алгоритмаАлгоритм основан на методе перебора каждой записи всего массива и сравнении введенной строки запроса с полями записи прочитанной из массива. После того как запись и запрос совпали запить выдается в нужном формате для отображения в браузере. Пока весь массив не будет прочитан последовательно, сессия с пользователем не будет закончена.
А теперь более детально остановимся на алгоритме, ниже приведен формат одной отдельно взятой записи из базы данных в формате RUSMARC (см. Приложение 1).
00878nam 22002537 45000010000000330050003300172450005002442600029400153000030900096500031800636500038
10045653004260024653004500019653004690016020004850010091004950008092005030017090005200008852005280022852005500011040005610014041005750008008005830041 BOOK00000876 BOOK00000001 ‑19981027165203.0 ‑00aАктуальные вопросы преподавания хореографического искусстваnВып. 7bМатериалы межвуз. науч.-метод. конф. "Современные технологии обучения в гуманитарном вузе"cСанкт-Петербургский гуманитарный ун-т профсоюзов; Редкол. А.С.Запесоцкий и др. ‑0 aСПб.c1994 ‑ a22с.‑ aВысшая школаxМетодика преподаванияxМатериалы конференции‑ aХореографическое искусствоxПреподавание‑ aТехнологии обучения‑ aФормы обучения‑ aКонференция‑ c2.100‑ aЩ32‑ a14.35.09a18‑ cЩ32‑ bч/зt2hЩ32iА437‑ bаб.t3‑ aВСГАКИ-10‑ arus‑950614s1990 rur 00000 rus d‑
А теперь этаже запись только уже с пояснениями:
00878nam 22002537 4500 – Маркер 24 символа
– словарь 12 символов 1) Метка поля – 3 символа полный список всех меток приведен в Приложении 1.
2) Начальная позиция относительна начала записи -5 символов
3) Размер поля – 4 символа
1 - 001 00000 0033
2 - 005 00033 0017
3 - 245 00050 0244
4 - 260 00294 0015
5 - 300 00309 0009
6 - 650 00318 0063
7 - 650 00381 0045
8 - 653 00426 0024
9 - 653 00450 0019
10- 653 00469 0016
11- 020 00485 0010
12- 091 00495 0008
13- 092 00503 0017
14- 090 00520 0008
15- 852 00528 0022
16- 852 00550 0011
17- 040 00561 0014
18- 041 00575 0008
19- 008 00583 0041
Поля с данными
1 - ‑ BOOK00000876 BOOK00000001
2 - ‑19981027165203.0
3 - ‑00aАктуальные вопросы преподавания хореографического искусстваnВып. 7bМатериалы межвуз. науч.-метод. конф. "Современные технологии обучения в гуманитарном вузе"cСанкт-Петербургский гуманитарный ун-т профсоюзов; Редкол. А.С.Запесоцкий и др.
4 - ‑0 aСПб.c1994
5 - ‑ a22с.
6 - ‑ aВысшая школаxМетодика преподаванияxМатериалы конференции
7 - ‑ aХореографическое искусствоxПреподавание
8 - ‑ aТехнологии обучения
9 - ‑ aФормы обучения
10- ‑ aКонференция
11- ‑ c2.100
12- ‑ aЩ32
13- ‑ a14.35.09a18
14- ‑ cЩ32
15- ‑ bч/зt2hЩ32iА437
16- ‑ bаб.t3
17- ‑ aВСГАКИ-10
18- ‑ arus
19- ‑950614s1990 rur 00000 rus d
‑
Программа начинает работать после того когда от клиента приходит запрос на страницу по определенному URL (например: http://www.real.ulan-.ude.ru/serv/SearchEngein), для выполнения запроса пользователя веб-сервер запускает JServ, который в свою очередь обрабатывает запрос и определяет какой именно сервлет требуется запустить и в какой зоне он находится. Информацию о зонах размещения всех сервлетов Jserv считывает из файла настройки. Чтобы сервлет начал выполняться JServ предварительно запускает виртуальную Java машину и только после этого начинает работать сервлет это значит что запрос пользователя будет обработан и пользователь получит запрошенную страничку. Что же происходит на стороне сервера в этот момент когда пользователь ждет пока загрузится страница. А происходит вот что, управление по отображению всей информации в окне браучера переходит сервлету, программе написанной на Java. Рассмотрим это более детально. Сервлет инициализируется и начинает передачу данных в формате HTML пользователю. Первое что увидит пользователь это будет поисковая форма (см. рис. 6) .
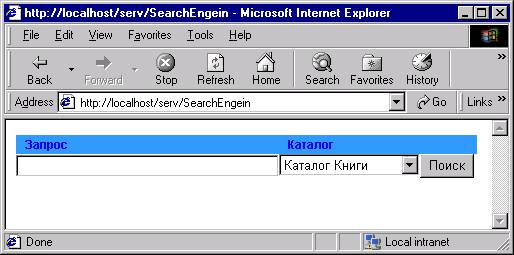
Рис. 6
Поисковая форма
Программный код поисковой формы выглядит так:
out.println("<form method=\"get\" action=\"/serv/SearchEngein\">"+
"<table width=\"461\" border=\"0\" cellpadding=\"0\" cellspacing=\"0\">"+
"<tr bgcolor=\"#3399FF\"> "+
"<td width=\"266\" class=\"text\"> Запрос</td>"+
"<td width=\"135\" class=\"text\"> Каталог</td> "+
"<td width=\"207\"> </td>"+
"</tr>"+
"<tr>"+
"<td width=\"266\" valign=\"top\"> "+
"<input type=\"text\" name=\"Query\" maxlength=\"100\" size=\"38\" value=\"\">"+
"</td>"+
"<td width=\"135\" valign=\"top\"> "+
"<select name=\"select\" size=\"1\">"+
"<option value=\"MARCFILE.Book\" selected>"+ConvertISO(getINIVar("KATALOG.Book"))+"</option>"+
"<option value=\"MARCFILE.Stat\">"+ConvertISO(getINIVar("KATALOG.Stat"))+"</option>"+
"<option value=\"MARCFILE.Periud\">"+ConvertISO(getINIVar("KATALOG.Periud"))+"</option>"+
"<option value=\"MARCFILE.Podpis\">"+ConvertISO(getINIVar("KATALOG.Podpis"))+"</option>"+
"<option value=\"MARCFILE.Ucheb\">"+ConvertISO(getINIVar("KATALOG.Ucheb"))+"</option>"+
"</select>"+
"</td>"+
"<td width=\"207\" valign=\"top\"> "+
"<input type=\"submit\" name=\"Start\" value=\"Поиск\">"+
"</td>"+
"</tr>"+
"</table>"+
"</form>");
Рассмотрим код более пристально.
В тэге <form> присутствуют параметры metod и action.
1) метод (metod) говорит браузеру о том что данные(запрос) будет отправлены серверу;
2) действие (action) – в этом параметре находится путь к программе на старое сервера которая примет отправленный запрос для обработки.
Следующий интересующий нас неотъемлемый компонент это тэг <input>, который тоже имеет несколько параметров type, name, value. Этот тэг является строкой ввода, рассмотрим его параметры.
1) тип (type) равный “text” говорит о том что это строка ввода;
2) имя (name) название запроса т.е. имя которое присваивается тексту введенному в строку ввода, в моей программе это Query;
3) значение (value) значение строки по умолчанию при начальной загрузке.
Еще один значимый тэг формы <select> - это список для выбора базы в которой будет производится поиск. Данный тэг имеет свое имя которое указано в параметре name. Сам же список последовательно указан в тэге <option> относящимся к тэгу <select>. Каждая из строк начинающихся тэгом <option> является элементом списка для выбора. У тэга <option> есть параметр value в котором указан псевдоним выбранного пункта из списка – это нужно для определения какой пункт из списка выбран.
И наконец последний значимый тэг <input>, в отличии от первого тэга <input> у этого тэга параметр тип(type) равен “submit” - это значит что это кнопка отправки запроса обработчику который указан в тэге <form>. У кнопки тоже есть имя (name) и значение (value) кнопка называется Start. Последним тэгом, всегда является закрывающий тэг </form>.
После того как пользователь ввел запрос и нажал на кнопку “Поиск” в адресная строка браузера приобретет примерно вид :
http://localhost/serv/SearchEngein?Query=%E1%A8%E1%E2%A5%AC%A0&select=MARCFILE.Stat&Start=%8F%AE%A8%E1%AA
К ссылке на сервлет прибавилось три параметра отделенные от адреса сервлета вопросительным знаком первый параметр это Query (запрос), второй select говорящий сервлету в какой базе производить поиск.
Первое что делает программа - это считывает файл настройки db.ini – который находится в папке c:\www\db. В данном файле находятся данные о место нахождении интересующей базы данных или говоря проще локальный путь к базе данных. Определив интересующую базу данных и установив ее место нахождения, программа начинает процесс поиска всех удовлетворяющих запросу данных (библиографических описаний).
Программа считывает всю запись в массив, после чего начинается определение места нахождения полей и их длинны. Разберем код процедуры.
public void dbFileRead(String dbNamePath, PrintStream out, String query) {
Сперва производится инициализация всех переменных используемых при работе процедуры.
Первый блок. Переменные для занесения значений полей
String mAvtor = null; // 100
String msAvtor = null; // 700
String mName = null; // 245
String mPrinter = null; // 260
String mSize = null; // 300
String mKey = null; // 653
String mSeria = null; // 490
String mRubrika = null; // 650
String mBBK = null; // 91
String mKaIndex = null; // 90
Второй блок. Файловые переменные для перемещения по файлу
long fPosMarker = 0, // Позиция относительно начала
fPosData = 0; // Начальная позиция данных
boolean done = false;
Третий блок. Перемнный для работы с данными
int mC =0, // Счетчик прочитанных записей
mE =0; // Счетчик найденых соответствий
byte Jumper[] = new byte[5]; // Размер запяси - символьный
int JIndex = 0, // Размер запяси - числовой
JTemp = 0, // Размер данных + словарь
MIndex = 0, // Счетчик для массива
MTemp = 0; // Счетчик полей
Начало выполнени поика. Сперва проверяется имеет ли запрос query занчение неравное пусто, если условие выполняется и запрос имеет не нуливое занчение устанавливается связь с файлом данных. Начальная позиция чтения равна нулю.
if (query != null){
try { RandomAccessFile dbfile = new RandomAccessFile(dbNamePath,"r");
// Цикл чтения файла по маркерам
while (fPosMarker != dbfile.length()) {
try { mC++;
dbfile.seek(fPosMarker);
dbfile.read(Jumper);
String jBuf = new String(Jumper);
JIndex = Integer.parseInt(jBuf,10);
int b = 0;
Прочитав начальный блок из 5 символов говорящий о длине записи он преобразуется из символьного значенья в числовое. Затем определяется длинная словаря которая равна 12*n, где n – равно количеству заполненных полей в одной записи.
// Поиск конца словаря
while ( b != MD){
dbfile.seek(fPosMarker+24+MIndex);
b = dbfile.read();
MTemp++;
MIndex = MTemp;
}
MTemp= MTemp - 1;
Определив конечную позицию словаря производится считывание в массив блока состоящего из данных - метка поля; начальная позиция поля, относительно конца словаря; длинная поля и символах.
// чтение Словаря из файла в отдельный массив
byte Dic[] = new byte[MTemp];
dbfile.seek(fPosMarker+24);
dbfile.read(Dic);
// чтение полей данных из файла в массив
fPosData = fPosMarker+24+MTemp;
String sDic = new String(Dic);
int DI2 = 0,
DI3 = 0,
DI4 = 0,
DI5 = 0,
PNum = 0, // Номер поля числовой
PLength = 0, // Длинна поля числовая
PStart = 0; // Начальная позиция поля чиловая
Получив данные в результате преобразований, это строка, начинается последовательное вычитание метки поля, начальной позиции, размера поля.
// сканирование номеров полей
while ( DI2 != MTemp){
DI3=DI2+3;
String DStr = sDic.substring(DI2,DI3);// Номер поля
DI4=DI3+5;
String DStr2 = sDic.substring(DI3,DI4);// Начальная позиция
DI5=DI4+4;
String DStr3 = sDic.substring(DI4,DI5);// Длинна поля
DI2=DI2+12;
PLength = Integer.parseInt(DStr3,10);// Узнаем длинну поля
PStart = Integer.parseInt(DStr2,10);// Узнаем начало поля
PNum = Integer.parseInt(DStr,10);// Код
byte Pole[] = new byte[PLength];
Как только первая запись о первом поле разобрана на составляющие проверяется его метка , которая говорить относится или нет, поле к тому списку полей который нас интересует. Если да то производится считывание его из файла. После того как поле считано над значением поля производится ряд преобразований, таких как, вычитание из поля служебной информации относящейся к формату MARC.
// Чтение поля из файла
switch (PNum) {
case 100 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mAvtor = TagRemove(Pol.substring(5));break;}
case 700 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
msAvtor = TagRemove(Pol.substring(5));break;}
case 245 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mName = TagRemove(Pol.substring(5));break;}
case 490 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mSeria = TagRemove(Pol.substring(5));break;}
case 91 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mBBK = TagRemove(Pol.substring(5));break;}
case 90 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mKaIndex = TagRemove(Pol.substring(5));break;}
case 260 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mPrinter = TagRemove(Pol.substring(5));break;}
case 300 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mSize = TagRemove(Pol.substring(5));break;}
case 653 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mKey = TagRemove(Pol.substring(5));break;}
default : {}
}// switch
}// конец проверки полей
Получив все данные которые нас интересовали, создается запись состоящая из нескольких полей.
if ( mAvtor == null) mAvtor=" ";
if ( msAvtor == null) msAvtor=" ";
if ( mName == null) mName=" ";
if ( mPrinter == null) mPrinter=" ";
if ( mSize == null) mSize=" ";
if ( mKey == null) mKey=" ";
if ( mKaIndex == null) mKaIndex=" ";
if ( mBBK == null) mBBK=" ";
if ( mSeria == null) mSeria=" ";
Это собственно самая запись
MarcRecord Rec = new MarcRecord( mAvtor,
msAvtor,
mName,
mPrinter,
mSize,
mKey,
mSeria,
mBBK,
mKaIndex);
Данные которые занесены в запись теперь осуществляется сравнивание их с запросом. Сравнение осуществляется после преобразование к одному регистру, это нужно для того чтобы найти полный список всех имеющихся записей относящихся к веденному запросу.
String q = toLow(query);
String p01 = toLow(Rec.rAvtor);
String p02 = toLow(Rec.rsAvtor);
String p03 = toLow(Rec.rName);
String p04 = toLow(Rec.rKey);
Затем распознанные данные сравниваются с запросом, сравнивание производится только с несколькими полями. Список полей приведен ниже:
100 – Автор
700 – Второй автор
245 – Название произведения
653 – Ключевые слова
if ( p01.indexOf(q) != -1 ||
p02.indexOf(q) != -1 ||
p03.indexOf(q) != -1 ||
p04.indexOf(q) != -1)
{ mE++;
При совпадении запись сразу же отправляется браузеру для отображения в читабельной для пользователя форме.
out.println("<table width=\"461\" border=\"0\" cellpadding=\"0\" cellspacing=\"0\">"+
"<tr bgcolor=\"#3399FF\">"+
"<td colspan=\"3\" class=\"text\"> Автор: "+
"<font color=\"#000000\">"+
Rec.rAvtor+" "+
Rec.rsAvtor+
"</font></td></tr><tr>"+
"<td colspan=\"3\" valign=\"top\" class=\"bodytext\">"+mE+". "+mC+
" <b>Название:</b> "+
Rec.rName+"<br>"+
Rec.rPrinter+" "+
Rec.rSize+"<br>"+
Rec.rBBK+" "+
Rec.rKaIndex+" "+
Rec.rSeria+
"</td></tr></table>");
}
В конце обработки одной записи независимо соответствовала она запросу или нет производится переход к следующей записи.
fPosMarker = fPosMarker+JIndex;
MTemp = 0;
MIndex = 0;
}
В случае ошибки (исключительной ситуации) цыкал обработки записи, прерывается и выдается сообщение об ошибки.
catch (IOException e) {
out.println("Ошибка!!!"+"<br>");
done=true; }
}
}
Если же файл отсутствует то программа выдаст сообщение о том что файл базы данных отсутствует на сервере.
catch (IOException e) { out.println("Ошибка доступа к "+dbNamePath); }
}
if (mE == 0) {
out.println("Запос: "+query+" не найден");
} // end If
}
После того как проведено сравнение запроса и данных имеющихся в поле, при совпадении запись преобразуются в формат HTML. Преобразуются только несколько полей, список полей которые выдаются по запросу в случае совпадений приведен ниже:
100 – Автор
700 – Второй автор
245 – Название произведения
490 – Серия
91 – Индекс ББК
90 – Каталожный индекс
260 - Издательство
300 – Объем, размер
653 – Ключевые слова
Код вывода в HTML формате выглядит так:
out.println("<table width=\"461\" border=\"0\" cellpadding=\"0\" cellspacing=\"0\">"+
"<tr bgcolor=\"#3399FF\">"+
"<td colspan=\"3\" class=\"text\"> Автор: "+
"<font color=\"#000000\">"+
Rec.rAvtor+" "+
Rec.rsAvtor+
"</font></td></tr><tr>"+
"<td colspan=\"3\" valign=\"top\" class=\"bodytext\">"+mE+". "+mC+
" <b>Название:</b> "+
Rec.rName+"<br>"+
Rec.rPrinter+" "+
Rec.rSize+"<br>"+
Rec.rBBK+" "+
Rec.rKaIndex+" "+
Rec.rSeria+
"</td></tr></table>");
После чего программа производит считывание и обработку следующей записи. Более детально алгоритм расписан в листинге программы (см. прил.3), а результаты теста программы (см. прил. 4)
Заключение
Глобальная информатизация общества приводит к тому, что потребность в информации, растет с каждым новым пользователем сети. При этом задачей специалистов в области информационных технологий обеспечить пользователей полной и достоверной информацией путем простого и удобного для пользователей доступа к накопленным массивам данных.
Главной задачей данной дипломной работы было создание программного интерфейса к существующей библиографической базе данных. Применение передовых технологии программирования позволили разработать программу, позволяющую производить поиск интересующей информации в базе данных не только по отдельно взятым ключевым словам, но и полному названию документа. Тестирование программы на массиве из 8366 записей показало, что поиск документа в конце массива занимает 2 минуты 16 секунд. Естественно, что при увеличении количества записей время обработки также будет увеличиваться. Массив данных, на котором проводилось тестирование, является реальной базой данных библиотеки ВСГАКиИ. Для того чтобы программа могла работать стабильно и с минимальными затратами времени на обработку запроса, нужно использовать ее на машине, обладающей большим быстродействием. Тестирование производилось на компьютере с такой конфигурацией: AMD K6-233, ОЗУ 64 Mb, Жесткий диск 2 Gb, под управлением операционной системы Windows NT 4.0 с установленным SP6a. Развитие направления связанного с поиском информации в массивах данных библиотек очень эффективно, так как потребность в этой информации через сеть Интернет возрастает с каждым новым пользователем.
Практическая реализация поставленной задачи показала правильность выбранного подхода. Тем не менее, работа требует дальнейше доработаки для организации постоянного доступа читателей к библиографическим ресурсам библиотекам города через Интернет.
Литература
1. Глушаков С.В., Ломотьков Д.В. Базы данных: Учебный курс. – К.: Абрис, 2000. -504с.
2. Джейсон Мейнджер. Java: основы программирования :Пер. с англ. - К.: Издательская группа BHV,1997.-320с.
3. Пригорьев Ю.А. Проблемы выбора доступа к данным при проектировании информационных систем на основе СУБД//Информационные технологии. - 1999 - №5. С. 4-10.
4. Симкин Стив, Бартлет Нейл, Лесли Алекс. Программирование на Java. Путеводитель :Пер. с англ. – К. НИПФ «ДиаСофт Лтд», 1996. 736 с.
5. Кристиансен Т., Торкингтон Н. Perl: Библиотека программиста :Пер. с англ.- СПб.: Издательство «Питер», 2000. – 736с.: ил.
6. Холзнер Стивен. Perl: специальный справочник :Пер. с анг. – СПб.: Питер, 2000. – 496с.: ил.
7. Хейл, Бернард Ван. JDBC: Java и базы данных :Пер. с англ. М.,1999.-320с.
8. Эферган М. Java: справочник. – СПб.: Питер, 1998. -448с.: ил.
9. http://www.java.sun.com
10. http://www.sun.ru/java/start/intro/history.html
11. http://www.logos.com/marc/
12. http://www.rba.ru:8101/rusmarc/
13. http://httpd.apache.org/dist/httpd/binaries/win32/old/apache_1_3_14_win32_r2.exe
14. http://java.apache.org/jserv/dist/ApacheJServ-1.1.2-2.exe
15. http://www.netcraft.com/Survey
16. http://www.apache.org
17. http://java.apache.org
18. http://www.ruslibnet.ru/
Приложение 1
Спецификация формата RUSMARC
РОССИЙСКИЙ КОММУНИКАТИВНЫЙ ФОРМАТ
ОФИЦИАЛЬНАЯ ИНФОРМАЦИЯ
Российский коммуникативный формат официально включен Постоянным комитетом по формату UNIMARC в список национальных адаптаций формата UNIMARC(11). Международный код Российского коммуникативного формата: RUSMARC(12).
Российский коммуникативный формат разработан по заказу Министерства культуры в рамках программы LIBNET (18) под эгидой Российской Библиотечной ассоциации. Утвержден Приказом Министра Культуры РФ № 45 от 27.01.98 в качестве обязательного формата при обмене библиографическими записями среди библиотек сети Министерства Культуры.
Формат предназначен быть посредником при осуществлении обмена библиографическими записями и способствовать решению следующих задач:
а. Улучшению доступности библиографической информации
б. Созданию сводных каталогов
в. Сокращению затрат при каталогизации
А теперь перейдем к самому формату.
МАРКЕР ЗАПИСИ
Определение
Область записи, содержащая данные о записи, необходимые системе для обработки записи. Маркер записи формируется в соответствии с положениями стандарта ISO 2709 и располагается в начале каждой записи.
Наличие
Является обязательным.
Не повторяется.
Метка, индикаторы и подполя
Маркер записи не имеет метки, индикаторов и идентификаторов подполей.
Элементы данных фиксированной длины
Маркер записи представляет собой набор элементов данных фиксированной длины. Элементы данных идентифицируются позицией внутри маркера. Маркер имеет длину в 24 символа. Позиции символов нумеруются от 0 до 23:
Маркер записи. Таблица 2.
|
| Наименование элемента данных | Кол-во символов | Позиции символов |
| (1) | Длина записи | 5 | 0-4 |
| (2) | Статус записи | 1 | 5 |
| (3) | Коды применения | 4 | 6-9 |
| (4) | Длина индикатора | 1 | 10 |
| (5) | Длина идентификатора подполя | 1 | 11 |
| (6) | Базовый адрес данных | 5 | 12-16 |
| (7) | Дополнительное определение записи | 3 | 17-19 |
| (8) | План справочника | 4 | 20-23 |
(1) Длина записи (позиции символов 0-4)
Длина записи - количество символов в записи, включая маркер записи, справочник, поля переменной длины, разделитель записи. Выражается десятичным числом из пяти цифр, при необходимости выравниваемых вправо ведущими нулями (не 546, а 00546). Определяется автоматически, когда запись окончательно сформирована для обмена.
(2) Статус записи (позиция символа 5)
Используются следующие коды, обозначающие статус обработки записи:
n - новая запись
Запись, подготовленная для использования в библиографирующем учреждении-создателе записи или для обмена.
d - исключенная запись
Запись, участвующая в обмене для указания, что другая запись (авторитетная / нормативная, ссылочная или справочная запись), имеющая соответствующий контрольный номер, не действительна. Для авторитетной / нормативной записи это означает следующее: запись удалена из файла в связи с тем, что заголовок, записанный в поле блока 2--, решено в дальнейшем не использовать - вместо него решено использовать другой заголовок (заголовки), новый или уже существовавший в системе, для которого существовала или создается отдельная авторитетная / нормативная запись. Заголовок исключенной записи может включаться в поля блока 4-- в запись (записи) для заголовка (заголовков), которые решено использовать вместо исключенного.
Запись может содержать только маркер, справочник и поле 001 (контрольный номер записи) или может содержать все поля в записи. В любом случае поле 830 "Общее примечание каталогизатора" может использоваться для объяснения причины исключения записи.
с - откорректированная запись
Запись, участвующая в обмене для указания, что данная запись должна заместить другую, имеющую соответствующий контрольный номер. Запись вводит дополнительно и (или) заменяет, и (или) исключает некоторые элементы данных в ранее введенной записи. При этом имеются в виду любые исправления - любая редакция любого поля записи (соответственно меняется идентификатор версии в поле 005). Исправления могут быть связаны или не связаны с изменением уровня кодирования с частичной на полную запись.
(3) Коды применения (позиции символов 6-9):
Коды в позициях 6-9 определяются не стандартом ISO 2709, а особенностями конкрет-ного применения формата.
(а) Тип записи (позиция символа 6)
Используются следующие коды, обозначающие тип записи:
x = авторитетная / нормативная запись
y = ссылочная запись
z = справочная запись
(б) Не определено (позиции символов 7-9). Три пробела (###).
(4) Длина индикатора (позиция символа 10)
Одна десятичная цифра.
Содержит 2.
(5) Длина идентификатора подполя (позиция символа 11)
Одна десятичная цифра.
Содержит 2.
(6) Базовый адрес данных (позиции символов 12-16)
Пять десятичных цифр, выровненных вправо ведущими нулями (не 546, а 00546), указы-вающие начальную символьную позицию первого поля данных относительно начала за-писи. Это число включает общее количество символов в маркере и справочнике записи, включая разделитель поля в конце справочника. В справочнике начальная позиция сим-волов для каждого поля задается относительно первого символа первого поля данных, которое является полем 001, а не от начала записи. Генерируется системой.
(7) Дополнительное определение записи (позиции символов 17-19)
Три позиции символов, содержащие коды, которые дают дополнительные сведения, не-обходимые для обработки записи:
(а) Уровень кодирования (позиция символа 17)
Односимвольный код, указывающий степень полноты машиночитаемой записи.
# (пробел) = полная запись
Запись содержит все необходимые данные, включая ссылки, правила их формирования и примечания (если правила формирования ссылок и примечания необходимы). Запись подготовлена для использования в библиографирующем учреждении или для обмена. В записи заполнены все поля и подполя со статусом обязательный и условно-обязательный.
3 = частичная
Запись содержит не все данные, т.к. не выполнена необходимая справочная работа и по-сле ее выполнения, в случае необходимости, могут быть дополнены ссылки "см." и "см. также" и справочные примечания.
Примечание:
(1) Уровень кодирования не связан с кодом статуса заголовка (100/8). И полная, и частичная запись могут содержать в поле блока 2-- как нормативный заголовок (код статуса a - нормативный), так и заголовок предварительный (код статуса c - предварительный), т.е. заголовок, который не принят в качестве нор-мативного и может быть пересмотрен. Различие между полной и частичной за-писями связано с тем, насколько полно в записи представлена необходимая ин-формация, связанная с заголовком.
(2) После того, как уровень кодирования приобретает значение # (пробел - полная запись), даты всех последующих модификаций (изменений) записи фикси-руются в поле 801 со значением второго индикатора 2 (организация модифици-рующая).
(б) Не определено (позиции символов 18-19). Два пробела (##).
(8) План справочника (позиции символов 20-23).
(а) Длина компонента "Длина поля" каждой статьи справочника(позиция символа 20).
Одна десятичная цифра. Значение - 4.
(б) Длина компонента "позиция начального символа" каждой статьи справочника (позиция символа 20).
Одна десятичная цифра. Значение - 5.
(в) Не определено (позиции символов 22-23). Два пробела (##).
СПРАВОЧНИКОпределение
Справочник записи состоит из набора элементов данных фиксированной длины - статей справочника. Каждая статья справочника определяет одно поле (в случае повторяющихся полей - одно повторение поля) записи. Статьи справочника формируются в соответствии со стандартом ISO 2709 и состоят из трех компонентов: метка поля, длина поля, позиция начального символа. Количество символов в компонентах "длина поля" и "позиция начального символа" определяется в маркере (позиции 20 и 21 соответственно). Справочник включается в запись непосредственно после маркера, начиная с позиции 24. Статьи справочника располагаются в порядке возрастания метки поля.
Наличие
Обязательное.
Не повторяется.
Метка, индикаторы и подполя
Метка, индикаторы и подполя отсутствуют.
Компоненты статьи справочника
(1) Метка поля (позиции 0-2)
Метка поля - три последовательных символа, идентифицирующих поля.
(2) Длина поля (позиции 3-6)
Четыре цифры, указывающие длину поля, определяемого данной статьей справочника. Длина поля определяется с учетом индикаторов, идентификаторов подполей, данных, разделителя поля. В случае, если длина поля меньше четырех цифр, длина поля выравнивается вправо с добавлением ведущих нулей.
(3) Позиция начального символа (позиции 7-11)
Пять цифр, определяющие позицию первого символа поля, определяемого данной статьей справочника, относительно базового адреса данных (маркер, позиции 12-16). В случае, если позиция начального символа меньше пяти цифр, позиция начального символа выравнивается вправо с добавлением ведущих нулей.
0 - БЛОК ИДЕНТИФИКАЦИИБлок содержит номера, идентифицирующие запись и / или содержащиеся в ней данные. Поля блока идентификации заполняются автоматически.
Определены следующие поля:
001 Идентификатор записи
005 Идентификатор версии
015 Международный стандартный номер авторитетных/нормативных записей (зарезервировано)
001 ИДЕНТИФИКАТОР ЗАПИСИ
Определение
Поле содержит набор символов, однозначно идентифицирующий запись, а именно контрольный номер записи, присвоенный учреждением, подготовившим запись.
Наличие
Обязательное.
Не повторяется.
Индикаторы
Индикаторы отсутствуют.
Примечание к содержанию поля
Решение о форме идентификатора записи принимается библиографирующим учреждением, создающимей запись.
005 ИДЕНТИФИКАТОР ВЕРСИИ
Определение
Поле содержит 16 символов, указывающих дату и время последней редакции записи (4 символа обозначают год, 2 символа - месяц, 2 - день, 2 - час, 2 - минуты, 2 - секунды, 2 - десятые доли секунды, включая точку).
Наличие
Обязательное.
Не повторяется.
Индикаторы
Индикаторы отсутствуют.
Взаимосвязанные поля
Похожие работы
... можно получить: · используя программу Gopher - клиена; · используя систему шлюров Gopher - mail; · используя программу WWW - клиена. Вопрос №2. Поиск информации в Интернет. Основные системы и средства. "Всемирная паутина" в Интернет - это миллионы документов с неструктурированной текстовой информацией (а также с графикой, аудио, видео). Чтобы найти нужную информацию ...

... Java, JavaScript и встроенные в сервер средства LiveConnect. Более мощными реляционными возможностями доступа к базе данных и более эффективным выполнением виртуальной Java-машины будут расширены услуги разработки приложений, обеспечиваемых в Enterprise Server 2.0,. Сервис управления. В дополнение к использованию встроенной машины каталога LDAP Enterprise Server 2.0 будет управляем через общие ...
... потом обновляется через определённый промежуток времени через интернет. Это позволяет достаточно оперативно отслеживать последние изменения в законодательстве и принимать решения, основанные на самых последних законах. Поиск как по базам данных в интернет, так и на компакт-дисках осуществляется по примерно одинаковым параметрам. Для того, чтобы найти интересующий вас документ, необходимо указать ...
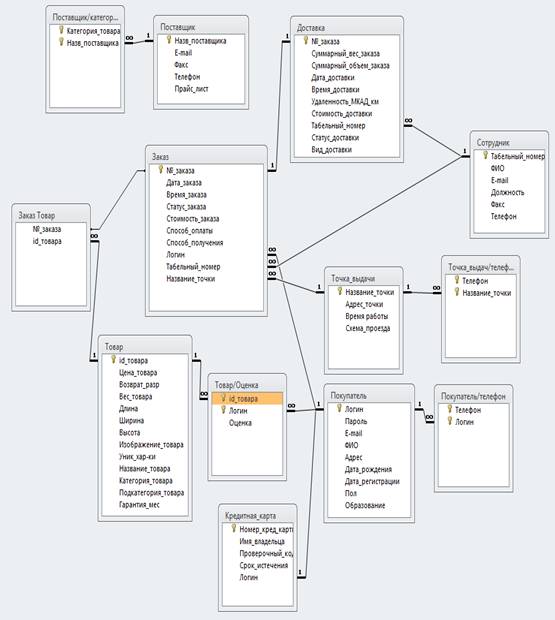
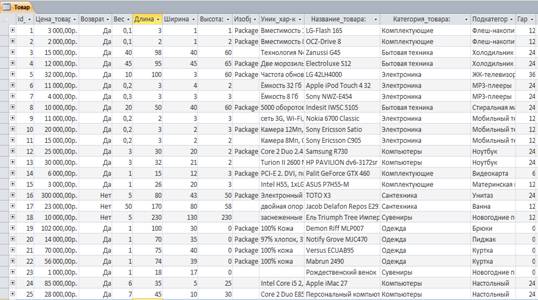
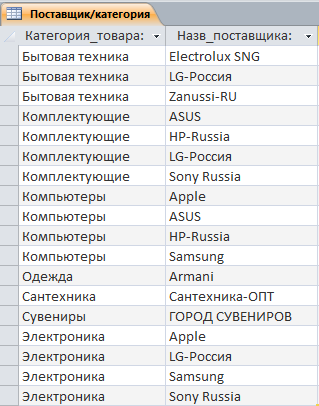
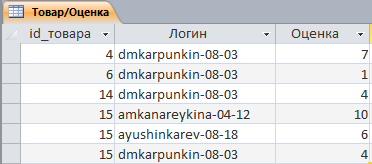
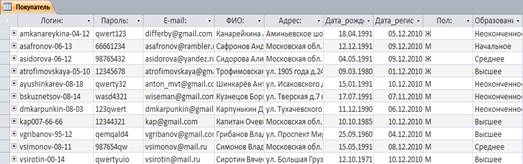
... Цена Сумма 10) Отчет по точкам выдачи (для сайта) Точки выдачи Название точки Адрес точки Время работы 2. Выбор средств/методологии проектирования и СУБД При проектировании базы данных интернет-магазина после описания предметной области необходимо выбрать метод построения инфологической модели (ER-модели) и СУБД, в которой будет реализован проект. ...
0 комментариев