Навигация
1. Создание версий
Ведение истории работы над документом. Это дает возможность точно определить время, характер и автора изменений, внесенных в документ. Кроме того, к каждой версии документа могут быть добавлены произвольные заметки. Все сведения о версиях документа хранятся в самом документе, что избавляет от необходимости хранить несколько копий документа. Кроме того, можно установить режим автоматического сохранения текущей версии документа в конце каждого сеанса работы с ним. Это позволяет определить автора любой версии документа.
2. Слияние документов
Объединение всех изменений и примечаний, внесенных несколькими рецензентами, в один документ с помощью одной простой операции. Нескольким рецензентам можно предоставить для проверки отдельные копии документа, после чего все исправленные копии объединяются в итоговый документ. Или, например, можно унести домой копию документа, исправить ее там, а затем вернуть исправленную копию и автоматически объединить внесенные изменения с исходным документом.
3. Примечания и всплывающие подсказки
Быстрый просмотр на экране примечаний любых рецензентов непосредственно в документе без открытия отдельной области. Примечания легко обнаружить в документе — текст, снабженный примечанием, выделяется желтым цветом. При установке указателя на этот текст над ним появляется всплывающая подсказка, содержащая текст примечания и имя рецензента.
4. Панель рецензирования
Теперь все обычные средства рецензирования документа находятся на одной панели инструментов: запись и просмотр изменений, вставка и просмотр примечаний, выделение текста цветом, сохранение версий и отправка документа по электронной почте.
Многоязыковая поддержка
В Word 95 было реализовано автоматическое переключение шрифта и языка при переключении клавиатуры, что сделало возможным использование текста на нескольких языках в документе и некоторых диалоговых окнах. В Word 97 еще более упростились создание и просмотр документов, содержащих текст на различных европейских языках. Кроме того, предусмотрена возможность просмотра документов, созданных с помощью дальневосточных версий Word, в американской версии Word.
1. Переключение клавиатуры
Автоматическое переключение шрифтов в документе при переключении клавиатуры (набор используемых шрифтов определяется текущей раскладкой клавиатуры). Переключение клавиатуры вызывает также переключение языка и, следовательно, обеспечивает проверку текста на другом языке, например, греческом, средствами проверки именно этого языка.
2. Поддержка текстов на нескольких языках в диалоговых окнах
Стали возможными редактирование и просмотр текста на нескольких языках в локализованных версиях Word. Например, в качестве условия поиска файлов в диалоговом окне Поиск файлов можно указать греческое имя автора.
3. Открытие документов с текстом на нескольких языках в локализованной версии Word
Правильное отображение текста документа, созданного в локализованной версии Word, при наличии в системе соответствующих шрифтов. Например, документы, созданные в японской версии Word, можно открывать и просматривать в американской версии Word. Следует отметить, что эта возможность не распространяется на языки, в которых направление письма может меняться (иврит, арабский и т. п.).
4. Копирование и вставка текста в формате Unicode
Существует возможность копирования текста на греческом, русском или любом другом европейском языке из американской версии Word и вставка его в лист Microsoft Excel. Кроме того, допускается копирование и вставка текста в формате Unicode в поля некоторых диалоговых окон (Найти, Заменить и т. п.).
5. Сортировка
Существует возможность указать язык и, тем самым, порядок сортировки, который следует использовать при сортировке текста в документе. Например, двойные буквы венгерского языка, такие как “cz”, правильно сортируются в американской версии Word, если в качестве языка сортировки указан венгерский.
6. Вставка символов
Для получения возможности вставки символов и букв, используемых в конкретном языке, достаточно выбрать соответствующий набор символов шрифта Unicode в диалоговом окне Символ (меню Вставка). Например, чтобы вставить в текст русские буквы, следует выбрать набор “Кириллица”.
Рассмотрев Word, давайте сравним программы для распознавания текста.
В последние несколько лет стали очень популярны программы распознавания текста. Используются они не только в офисах для перевода документов в электронный вид, но и дома для распознавания различного вида текстов для написания рефератов и курсовых, что облегчает жизнь студентам и научным сотрудникам. Проблема выбора программного продукта для решения какой-либо задачи всегда стояла перед пользователем. Для того чтобы разрешить ее, необходимо было сравнить хотя бы несколько программ одного назначения. При этом тратились время и деньги, и достаточно часто выбор был далеко не оптимальным. На данный момент всего два программных продукта - Fine Reader 5.0 и Cuneiform 2000 - предлагают решение данной проблемы. Рассмотрим их.
|
Обе программы предлагают несколько дополнительных возможностей помимо распознавания текста:
проверка орфографии для различных языков; сканирование; сохранение в различных форматах и передача в другие программы распознанного документа; обработка картинок; пакетная обработка множества изображений; форматирование текста.Но нас интересуют не столько предлагаемые функции (они практически одинаковые), сколько отличия для пользователя в работе данных программ. Для этого мы проведем исследование по пунктам, которые являются основными для пользователя.
Скорость и качествоЭти характеристики являются одними из самых критичных в применении данных программ, т. к. распознавание должно экономить время, затраченное на страницу текста, а складывается оно в итоге из скорости и качества. Скорость - это время, необходимое самой программе на распознавание, а от качества зависит, придется ли вам исправлять полученный текст и насколько время исправления меньше времени набора того же самого текста. Как показывает опыт, качество напрямую зависит от исходного материала, а также от уровня интеллекта программы распознавания.
Для начала мы посмотрим, как программы будут распознавать страницу, не содержащую ничего, кроме обычного текста. Затем рассмотрим несколько вариантов различной сложности.
Для этого мы берем лист формата А4 с текстом, распечатанным на лазерном принтере, сканируем его в черно-белом режиме с разрешением 300 точек на дюйм и сохраняем в формате TIFF (с этими параметрами будут отсканированы и остальные образцы, взятые для тестов).
|
Теперь мы открываем это изображение в Fine Reader 5.0, выделяем область для распознавания и нажимаем кнопку "Распознать". На этот процесс у программы уходит около 4 с. Производим подобную операцию в Cuneiform 2000 и спустя 8 с получаем распознанный текст.
Таким образом, Fine Reader 5.0 работает быстрее, чем Cuneiform 2000. Теперь о качестве: первая программа совершила только одну ошибку (рис. 4), ну а вторая ошиблась только поставив ненужный пробел (рис. 5).
|
Теперь давайте посмотрим, какая картина будет, если мы возьмем для распознавания разворот учебника с формулами.
|
Производим распознавание и видим, что Fine Reader затратил около 43 с, а Cuneiform - порядка 18 с.
Интересно: Fine Reader здесь показал не лучший результат по скорости, но по качеству - у него преимущество. Судите сами: в основном ошибки распознавания оказались только в формулах, а Cuneiform умудрился совершить их и в тексте.
|
Другой не менее интересный тест на скорость и качество - распознавание ксерокса учебника, причем для него мы возьмем два варианта: хорошего и плохого качества.
При распознавании хорошего ксерокса (рис. 9) Fine Reader вновь оказался впереди - 4 с, а Cuneiform - 5 с.
|
Посмотрев на распознанный текст, можно сказать, что Fine Reader не на много, но все же лучше справился с задачей. Cuneiform не смог распознать правильно букву "Ц", а цифру ноль посчитала буквой "О".
|
Теперь давайте посмотрим, какие результаты у нас получатся, если распознавать ксерокс плохого качества.
|
Fine Reader - 1 мин 48 с, а Cuneiform - около 30 с. Тут явно проиграл Fine Reader. Посмотрим, что же удалось распознать нашим участникам. Картина явно меняется: Cuneiform за 30 с со всей страницы едва ли распознал правильно более одного-двух десятков слов. С Fine Reader, несмотря на плохое качество исходного материала, было получено максимальное количество распознанного текста, который, имея оригинал, можно было бы привести в нормальный вид. А пользователям Cuneiform пришлось бы набирать весь текст вручную. Тише едешь - дальше будешь.
|
Итак, показатель времени распознавания у программ совершенно разный, и сказать, какой из них быстрее, довольно сложно. Однако нельзя не заметить, что у Fine Reader 5.0 время распознавания напрямую зависит от качества оригинала: она старается распознать максимально много и поэтому затрачивает больше времени на распознавание изображения плохого качества. Ну а у Cuneiform 2000 время распознавания не настолько зависит от качества оригинала, поэтому распознавание занимает меньше времени, но из-за этого страдает качество. Вывод: Fine Reader 5.0 лучше всего использовать при распознавании как хорошего, так и плохого исходного материала. Ну, а Cuneiform 2000 в лучшем свете выглядит при распознавании среднего и чуть выше среднего качества оригиналов, т. к. при этом он тратит время на распознавание гораздо меньше, а качество лишь немного уступает победителю данного теста - Fine Reader.
Таблицы и формыНа этом этапе мы рассмотрим, насколько точно будет производиться определение таблиц и форм. Для того чтобы провести его более точно, мы возьмем два основных вида таблиц и один документ договора.
|
Для первого примера мы используем небольшую таблицу (рис. 15).
|
Таким образом, мы получили две идентичные таблицы (за исключением форматирования), недостатки которых в наших программах следующие: в Fine Reader 5.0 каждая ячейка заканчивается ненужным вводом (рис. 16), а Cuneiform 2000 (рис. 17) сохраняет разбивку на строки за счет вставки символа "конец строки" (Shift+Enter в MS Word).
Теперь можно взять более сложную таблицу (рис. 18).
|
При попытке разметить ее автоматически только Fine Reader нашла здесь какое-то подобие таблицы, ну а Cuneiform 2000 вообще решил, что здесь находится только текст. И только после того как вручную выделили табличный блок, программы решили распознавать таблицу.
Результаты распознавания мы видим на рис. 19, 20. Наиболее точно и близко к оригиналу у нас оказался Fine Reader 5.0, но все же не совсем так, как бы хотелось. Cuneiform 2000 вообще решил, что в таблице вся сетка должна быть полностью видимой - после таких распознаваний придется еще повозиться с таблицей достаточно основательно. Тем более Cuneiform 2000 еще не совсем точно распознал текст в самой таблице.
|
Для того чтобы хорошо и наиболее точно распознавалась таблица, можно самому отредактировать вертикальные и горизонтальные линии таблицы до распознавания текста. Это доступно в обеих программах.
Проведя исследование на распознавание таблиц, мы переходим к формам. Что же мы в данном случае под ними понимаем? А все очень просто: анкеты, договора и прочие документы, содержащие достаточно сложное оформление. Если у вас возникает вопрос, а зачем такое исследование проводить, то очень просто привести пример из жизни. Вам нужно изменить текст договора или анкеты имеющегося у вас образца, а в электронном виде его у вас нет. Время на набор и оформление ограничено, поэтому приходится использовать программу распознавания.
Итак, покончим с лирикой и возьмемся за дело. Образцом для нашего теста послужит стандартный договор найма.
При автоматической разметке страницы на блоки возникает примерно такая же ситуация, как при определении сложной таблицы, поэтому мы всю страницу определяем единым текстовым блоком вручную. Это приходится делать, поскольку в Fine Reader страница разделяется на три блока, а в Cuneiform 2000 - порядка пятнадцати.
В Fine Reader спустя 50 с мы получаем уже готовый договор, ну а в Cuneiform 2000 ждем всего 10 с, но документ в результате требует исправлений. Например, некоторые точки распознались запятыми, а вместо символа номер (№) получаем пару других символов, и точность распознавания самого текста немного страдает. Однако само форматирование договора в обеих программах сохранилось достаточно точно.
Результаты: при распознавании простой таблицы Cuneiform 2000 оказался лучше, чем Fine Reader 5.0.
При работе со сложной таблицей пришлось вручную определять блок таблицы, т. к. при автоматическом определении блоков обе программы ее не опознали вообще как таблицу. Когда это, наконец, произошло, обе полученные таблицы требовали довольно серьезной редакции, но все-таки Fine Reader показал лучший результат.
|
При распознавании договора (или формы) он же вышел на первое место, правда, при этом затратил в пять раз больше времени, чем Cuneiform 2000, зато распознал более точно, и нам меньше надо было бы править (достойное применение для работы этих программ).
БлокиНе последнее место при работе с программами распознавания занимает автоматическая разбивка на блоки. В автоматическом режиме на разбивку тратится несколько секунд, а в ручном - гораздо больше времени.
Для начала возьмем изображение нашего договора. Как уже говорилось, Cuneiform 2000 разбил этот единый документ на множество блоков, а Fine Reader только на 3 части, и в них не вошли лишь последние точки в документе (ей можно в принципе доверять). Для нормального распознавания в наших программах таблицы в тексте (тем более, если она не простая) лучше всего ее выделять самостоятельно. Ну а если она похожа на первый образец, то можно спокойно не обращать на нее внимание, т. к. она правильно определится обеими программами. И все-таки программа Fine Reader здесь тоже выходит на первое место: она наиболее точно определяет тип распознаваемых блоков и распределяет их тоже не плохо.
Для примера возьмем разворот учебника с картинками и посмотрим, как справятся наши программы с разбивкой на блоки.
|
Cuneiform 2000 нашел таблицу и около 30 текстовых блоков, причем некоторые выделяли область рисунков. После этого мы ожидали увидеть примерно такую же картину и в Fine Reader 5.0, но все иллюстрации были распознаны правильно (хотя и не совсем точны были определены границы), текстовые блоки были выделены тоже достаточно корректно, ну а мифических таблиц эта программа не обнаружила, т. к. их действительно не было.
Да, для того чтобы нормально распознать текст в Fine Reader, нужно всего лишь немного поправить границы блоков и удалить ненужные, а в Cuneiform 2000 лучше задавать их вручную.
Проведенное испытание показало, что иногда лучше самому расставить и определить блоки, т. к. программе может быть не совсем понятно к какому типу относить получившийся блок. Наши программы в принципе неплохо справились с задачей, особенно Fine Reader, который не совершил грубых ошибок при распознавании блоков.
Распознавание цветаРаньше программы распознавания требовали только черно-белых (1-битовых) изображений в разрешениях, близких к 300ґ300 dpi. Теперь программы фирм ABBYY и Cognitive Technologies Ltd., позволяют распознавать серые и цветные изображения с разрешениями от 200 до 600 dpi. Осталось только проверить, насколько хорошо они это делают.
Для проведения данного теста мы возьмем первую страницу цветной газеты, отсканируем ее в 24-битном режиме (16,5 млн цветов) и постепенно будем уменьшать цветность. В данном тесте нас будут интересовать результаты времени распознавания и качество, а также их зависимость от количества цветов.
|
Теперь полученный 23-мегабайтный файл загружаем в наши программы распознавания. Сначала разбиваем его на блоки автоматическим путем. Смотрим, что у нас получилось: Fine Reader без особого труда с маленьким недочетом (упустил одну букву) определил все блоки, причем правильно, а Cuneiform 2000 опять нашел несуществующую таблицу, но в целом все остальное определил неплохо.
Переходим ко второй стадии - распознаванию. Fine Reader - 34 с, Cuneiform - 52 с! Невероятно, но факт. Fine Reader, помимо высокой скорости, еще и очень качественно распознал данную страницу (совершив всего несколько ошибок, распознав даже белый текст на черном фоне), особенно по сравнению с Cuneiform, который не смог распознать большую часть текста. Кроме того, Fine Reader вырезал картинку без примеси текста! Таких результатов от Fine Reader мы не ожидали.
Теперь понижаем цветность с 16,5 млн до 256 цветов и смотрим, изменится ли картина распознавания. Для Fine Reader ситуация с определением блоков не изменилась, а вот у другой тестируемой программы проблема - она, похоже, не нашла текст. Будем считать, что программа Cuneiform 2000 провалила данный тест. Скорость распознавания у Fine Reader изменилась в сторону уменьшения: получилось около 27 с. Да, кстати, на этот раз программа вообще не ошиблась при определении блоков.
Ну и, наконец, последнее распознавание этого же изображения в режиме 256 градаций серого. С Cuneiform 2000 опять та же проблема - не находит текст, опять провал. А вот Fine Reader не ударил в грязь лицом и спокойно распределил блоки с той же точностью. Процесс распознавания занял всего 24 с - превосходный результат!
|
Ну а теперь можно подвести итоги проделанной работы. Бесспорным лидером нашего теста оказался Fine Reader 5.0 Pro, который победил почти во всех тестах программу Cuneiform 2000 Master. Качество распознавания у победителя бесспорно выше, особенно при плохих оригиналах. Скорость у него не сильно отстает, а иногда и превосходит своего конкурента. Как показали последние два теста, у Fine Reader отличная система распознавания блоков и цветного изображения.
Есть, конечно, и некоторые неудобства в обеих программах: надо проверять, а иногда и исправлять распознанные блоки, при больших объемах страниц. А в общем обе программы достаточно конкурентоспособны и еще будут бороться за первое место, но на данном этапе, как видите, Fine Reader лучше.
Заключение.
В настоящее время всё больше людей используют компьютеры в повседневной жизни, даже работа с текстами проходит через машины. А программы для работы с текстом улучшаются на глазах. Написав эту работу, я делаю вывод – что следует выбирать надежность и качество при выборе ПО для каждого компьютера и ни в коем случае не спешить с этим делом.
Похожие работы
... карточкам и журналам учета работы вычислительного центра. Результаты учета документов обобщаются службой документационного обеспечения и представляются руководству организации для выработки мер по совершенствованию работы с документами. В организациях создаются ИПС ручного типа, механизированные, автоматизированные. ИПС включает регистрацию и индексирование документов, создание на их основе ...
... включаются все документы, образующиеся в деятельности предприятия., кроме технической документации и печатных изданий. Номенклатура дел предприятия разрабатывается специалистом, ответственным за организацию работы с документами. Номенклатура дел составляется по установленной форме (приложение 2) и включает реквизиты: наименование предприятия; наименование вида документ; дату; индекс; место ...

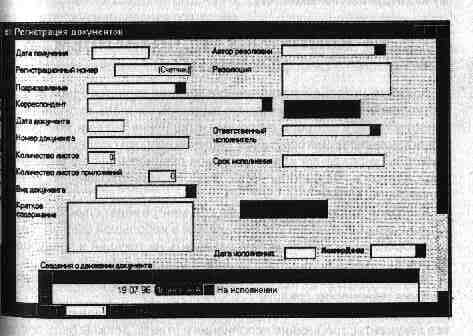
... случае, когда поступает очень незначительное количество документов. Во всех остальных случаях эта форма регистрации устарела48, так как затрудняет ведение контроля за исполнением документов и справочную работу по ним. Более удобной является карточная система регистрации документов. Форма карточки (РКК регистрационно-контрольной карточки) и расположение в ней реквизитов могут быть определены в ...
... а срочные - немедленно. Выставление контрольной карточки - исключительная прерогатива субъекта контроля. Субъекты контроля в подразделениях-исполнителях поручения осуществляют контроль в процессе непосредственного контакта с исполнителями по действующим в системе МВД России каналам прямой и обратной связи, позволяющим решать данные вопросы бездокументационным путем. Осуществляются следующие виды ...
0 комментариев