Навигация
РУКОВОДСТВО СИСТЕМНОГО ПРОГРАММИСТА 20
41873
знака
6
таблиц
6
изображений
8.1. РУКОВОДСТВО СИСТЕМНОГО ПРОГРАММИСТА 20
ЗАКЛЮЧЕНИЕ 22
ЛИТЕРАТУРА 23
ВВЕДЕНИЕ
Тема проекта – «Разработка подсистемы вывода в диагностической экспертной системе». Данная дипломная работа была выполнена на кафедре систем информатики в лаборатории искусственного интеллекта, Института Систем Информатики Сибирского Отделения Российской Академии Наук. (ИСИ СО РАН). Научный руководитель – Попов Иван Геннадьевич. Работа выполнялась с 1 сентября 1998 года по 30 мая 1999 года. Тип работы – инженерная; является плановой разработкой института.
Особенностью данной дипломной работы является возможность ее работы с нечеткими и неточными входными данными. При этом подсистема вывода будет использовать экспертные знания, также допускающие элементы нечеткости и неточности.
Работа является коллективной. В мою часть работы входит создание машины вывода диагностической экспертной системы.
Разработка данного дипломного проекта подразумевает выполнение следующих работ:
Разработка диагностической экспертной системы
Разработка машины вывода диагностической экспертной системы
Программная реализация машины вывода диагностической экспертной системы
Создание модуля для обработки входных данных,
как с клавиатуры, так и из файлов на диске.
ОПИСАНИЕ ПРЕДМЕТНОЙ ОБЛАСТИ
Данная дипломная работа разрабатывалась в лаборатории искусственного интеллекта. Рынок современных диагностических систем не сильно «балует» пользователей новыми поступлениями [1]. Поэтому мы решили написать программу, аналогичную уже имеющимся, выпущенным в 1990-1994 гг, но более современную, с эргономичным многоуровневым пользовательским интерфейсом, под Операционную систему Windows 95/98.
Аналогом данной экспертной системы послужила известная в свое время система Di-Gen, обеспечивающая медицинскую диагностику пациентов и техническую диагностику доменных печей.
Данная работа выполнялась в среде Borland Delphi 4, объектно-ориентированной среде программирования.
ЭКСПЕРТНЫЕ СИСТЕМЫ, ИХ НАЗНАЧЕНИЕ И СТРУКТУРА
По определению Комитета по Экспертным Системам Британского Компьютерного Общества, под экспертной системой понимается « воплощение в ЭВМ компонента опыта эксперта, основанного на знании, в такой форме, что машина может дать интеллектуальный совет или принять интеллектуальное решение относительно обрабатываемой функции». Желательная дополнительная характеристика (которую многие считают главной) - способность системы по требованию объяснить ход своих рассуждений понятным для спрашивающего образом [2].
Предметом теории экспертных систем служат методы и приемы конструирования систем, компетентных в некоторой узкоспециальной области. Эта компетентность состоит из знания конкретной области, понимания задач из этой области и из умения решать некоторые такие задачи. Знания, относящиеся к любой специальности, обычно существуют в двух видах: общедоступные и индивидуальные. Общедоступные знания - это факты, определения и теории, которые обычно изложены в учебниках и справочниках по данной области. Но, как правило, компетентность означает нечто большее, чем владение такими общедоступными сведениями. Специалисты в большинстве случаев обладают ещё и индивидуальными знаниями, которые отсутствуют в опубликованной литературе. Эти личные знания в значительной степени состоят из эмпирических правил - эвристик, которые позволяют экспертам при необходимости выдвигать разумные предположения, находить перспективные подходы к задачам и эффективно работать при зашумленных или неполных данных. Центральной задачей при построении экспертных систем является выявление и воспроизведение таких знаний.
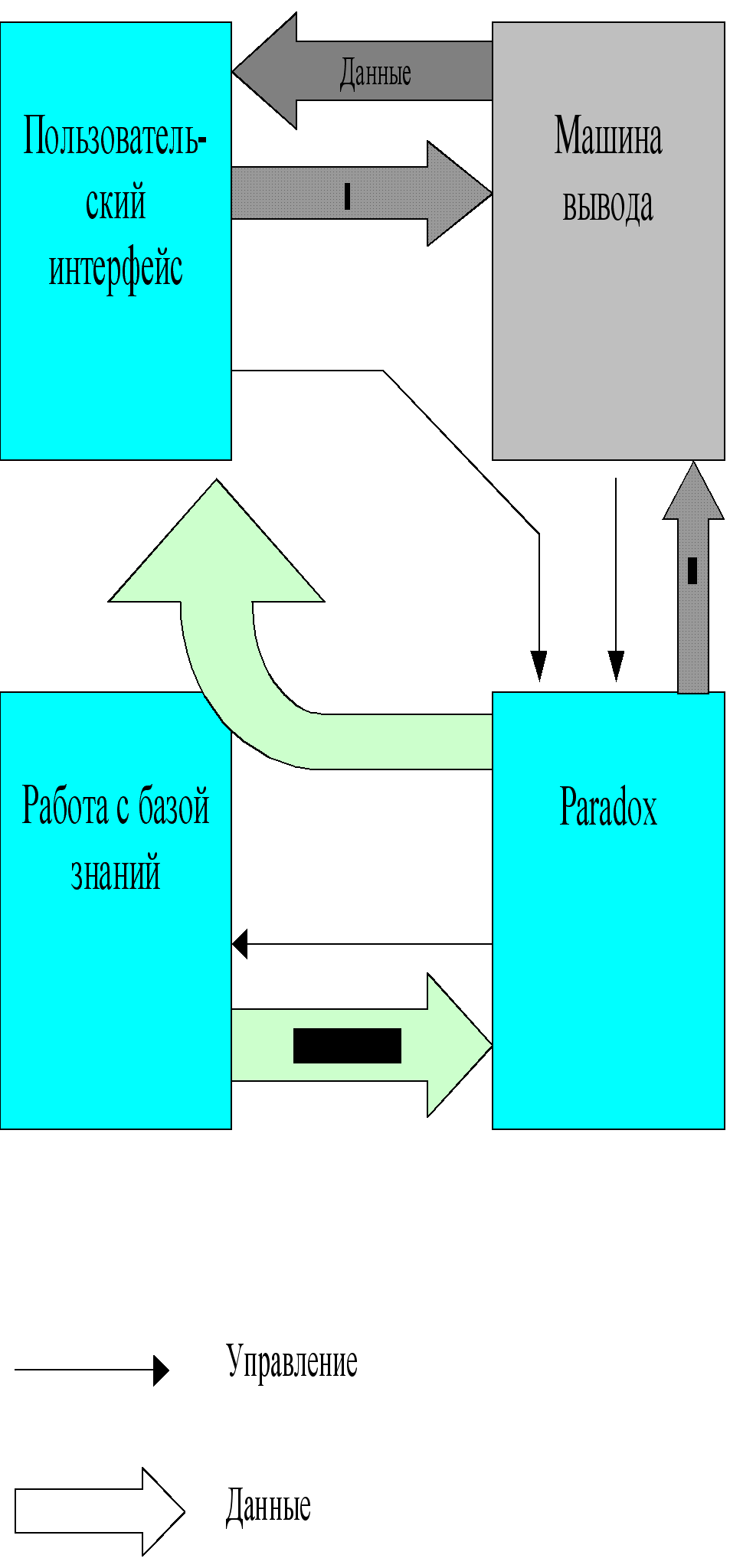
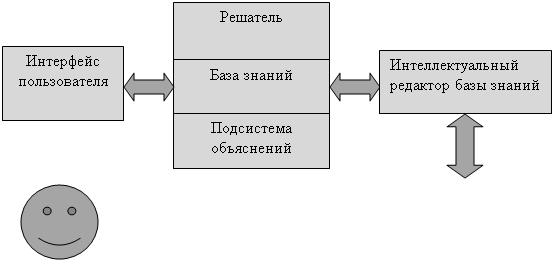
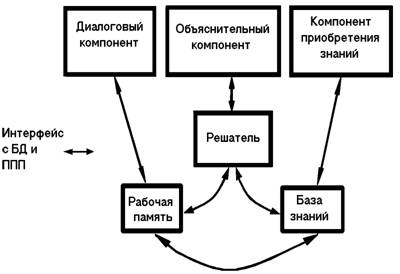
В архитектуре экспертной системы можно выделить три основных компонента: база знаний, машина вывода и интерфейс пользователя.
База знаний содержит факты, правила и эвристики, представляющие экспертные знания о предметной области.
Машина вывода содержит стратегии и управляющие структуры, используемые для применения знаний, содержащихся в базе знаний для решения поставленной проблемы.
Пользовательский интерфейс управляет взаимодействием с пользователем. Сюда входят и управление экраном, и организация диалога, и объяснительные способности системы.
ЗАДАЧИ ДИАГНОСТИКИ
Одной из типичных задач экспертной системы является задача диагностики [3].
Диагностика - это процесс поиска неисправностей в обследуемой системе (или определение стадии заболевания в живой системе), основанный на интерпретации данных, возможно зашумленных. Нахождение согласованных и корректных интерпретаций является основным требованием в этой задаче. Одно из необходимых условий достижения результата - понимание диагностом структурной организации обследуемой области и механизмов взаимодействия между различными подсистемами.
В задачах диагностики необходимо предположительное рассуждение. Во многих диагностических процедурах с успехом используются предположения относительно степени надежности датчиков, т.е. степени надежности вводимой информации. Так же, в задаче диагностики можно столкнуться с ситуацией, которая изменяется во времени по мере того, как происходит развитие болезни (или в связи с предпринимаемым лечением). И наконец данные, поступающие от датчиков, часто оказываются зашумленными. Это существенный момент в задаче диагностики, где рассуждения проводятся на основании результатов измерений.
К примеру, задача медицинской диагностики заключается в обнаружении заболеваний на основе интерпретации данных о текущем состоянии больного, которые получаются в результате анализа жалоб пациента, его объективного осмотра, результатов лабораторных обследований и анализов.
Среди задач диагностики наиболее сложными являются задачи дифференциальной диагностики. Их сложность определяется тем, что среди множества заболеваний, имеющих общие признаки, надо выбрать наиболее вероятные.
Для решения такого типа задач должна эффективно использоваться разрабатываемая оболочка.
ПРОЦЕСС ПРИОБРЕТЕНИЯ ЗНАНИЙ
Приобретение знаний - это процесс передачи и преобразования опыта по решению задач от некоторого источника знаний в программу.
Процесс создания диагностической экспертной системы можно разделить на следующие этапы:
Настройка оболочки на конкретную проблемную область, т.е. инженер знаний совместно с экспертом описывает основные термины, понятия; формирует иерархию понятий (типа общее - частное ); определяет структуру основных фреймов, области значения слотов, наследование свойств.
Наполнение оболочки предметными экспертными знаниями. Эксперт пополняет иерархию понятий конкретными фреймами; устанавливает взаимосвязи между ними; заполняет слоты фреймов.
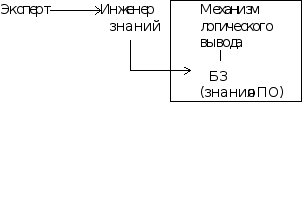
В нашем случае эксперт взаимодействует с экспертной системой непосредственно через интеллектуальную редактируемую программу. Т.е. вся работа инженера знаний на этих этапах уже должна быть заложена в программу.
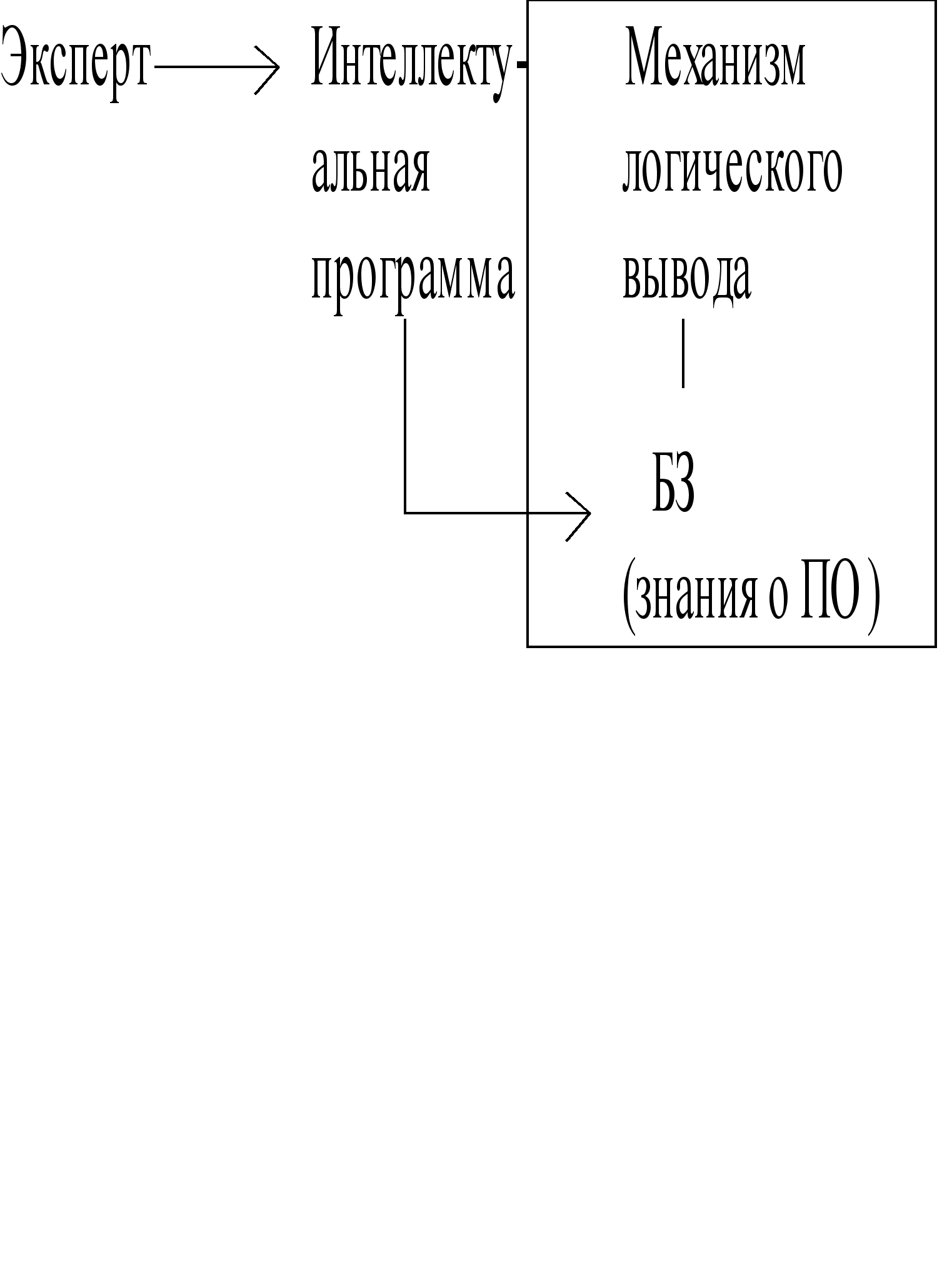
Машиной вывода можно назвать набор средств, реализующих тот или иной способ рассуждения, технологию поиска по базе знаний, обработку неопределенности и обработку ошибок.
Методы рассуждений.
Самые распространенные методы логического вывода - это прямая цепочка рассуждений (прямой вывод) и обратная цепочка рассуждений (обратный вывод).
При решении задач диагностики используется обратный вывод. Можно сказать, что обратный вывод белее эффективен, когда пользователь должен выбирать из набора возможных последствий как в случае медицинской или технической диагностики.
В разрабатываемой оболочке реализуется механизм смешанного вывода, который позволяет и прямой вывод от фактов к заключениям, и обратный - чтобы подтвердить или опровергнуть гипотезу.
Управление достоверностью.
Одной из важных особенностей экспертной системы является её способность работать с неполной, неточной, недоопределенной информацией.
Неточность в ЭС может возникать следующим образом:
Ненадежный источник информации
Несогласованность экспертов
Противоречивая информация.
Фактор уверенности предоставляет пользователю возможность указать степень уверенности в достоверности вводимой им информации. Так же фактор уверенности демонстрирует степень уверенности системы в достоверности сделанных ею логических заключений.
Нечеткие рассуждения подходят для решения проблем, в которых используются такие неопределенные характеристики, как примерно, возможно, близко к. Нечеткая переменная может одновременно иметь более одного значения, каждое со своим коэффициентом уверенности.
Важным свойством для экспертной системы является способность устанавливать порог уверенности. Машина вывода может работать таким образом, что будет рассматривать только те факты и гипотезы, которые имеют фактор достоверности выше установленного пользователем. Пользователь может ускорить процесс вывода, установив высокий порог достоверности и тем самым дать указание Машине вывода рассматривать только факты и гипотезы с высокой степенью достоверности.
Так же, следует обратить внимание на ситуацию, когда пользователь в ответ на вопрос отвечает неизвестно.
Основной принцип, который реализуется в оболочке, состоит в том, что все проблемные знания описываются экспертом в объектно-ориентированном стиле, а продукционное представление знаний, используемое на более низком уровне, генерируются автоматически и скрыто от эксперта.
Эти идеи и ложатся в основу технологических решений при конструировании оболочки.
НЕДООПРЕДЕЛЕННЫЕ МОДЕЛИ
Характерными особенностями знаний о сложных фрагментах действительности являются их неполнота, неоднозначность, отсутствие точности – свойства, которые существенно затрудняют (а иногда и делают невозможным) поиск адекватного решения задачи [4]. Любую модель надо строить с учетом принципиальной неполноты и принципиальной возможности ошибок и противоречий в написании задачи. Эти и другие так называемые НЕ-факторы отражают то обстоятельство, что в реальном мире существуют в основном объекты, которым присущи все эти свойства или хотя бы одно из них.
К настоящему времени наибольшее развитие получил НЕ-фактор, который известен, как недоопределенность конкретных знаний. Недоопределенность связана с неполнотой доступной в данный момент информации о моделируемом фрагменте реальности. Эта неполнота касается в первую очередь значений величин объектов (например, около двух часов – о времени), но может присутствовать и в случае неполноты информации о типах объектов (то ли окружность, то ли эллипс) и о существующих отношениях между объектами (то ли раньше, то ли позже).
Мы назовем значение переменной неопределенным, если о нем известно лишь то, что оно равно одному из элементов множества потенциальных значений. Значение считается определенным, если однозначно известен тот элемент множества потенциальных значений, которому оно равно.
Типичным состоянием изучаемого объекта целесообразно считать недоопределенность: бесспорный факт принадлежности его значения какому-то нетривиальному подмножеству области определения. При этом потенциальное совпадение с тем или иным элементом этого множества считается равновероятным.
Рассмотрим модель, которую будем называть обобщенной вычислительной моделью (ОВМ): M = (X,W,C,R),
Где множества X и R имеют такую же семантику, как и в обычных вычислительных моделях, W – множество функций присваивания, а C – множество функций проверки корректности. Функция присваивания определяет способ записи очередного значения в объект xX, а функция проверки корректности осуществляет контроль за правильностью вычисленных значений объекта x.
Пусть x – переменная с областью определения X. Обозначим через *X множество всех подмножеств X, без пустого. Элемент d*X, который содержит только одно значение из X, называется определенным. Все остальные элементы называются недоопределенными. Значение *x, соответствующее всему множеству X, будем называть полной неопределенностью.
ОВМ, в которой хотя бы один объект представлен недоопределенным типом данных, называется недоопределенной моделью (н-моделью) [5]. Рассмотрим систему из двух линейных уравнений с двумя целочисленными переменными:
x + y = 12
2*x = y
Для предоставления целых констант данной системы (2 и 12) естественно воспользоваться предопределенным типом integer. Если переменным x и y также сопоставить тип integer, то получим традиционную модель. Найти решение в данном случае можно, только применяя любой из методов решения систем линейных уравнений. Если же для представления переменных x и y воспользоваться недоопределенным типом (например, nint), то система уравнений становится н-моделью. Далее покажем внутреннее представление такой н-модели и алгоритм ее решения.
Множество Х содержит все объекты данной н-модели:
Х = {x,y:nint; 12,2:integer}.
Так как множество Х содержит две переменные и две неизменяющиеся константы, множество функций присваивания (W) и множество функций порверки корректности (С) содержат по два элемента:
W = { PRint(x), PRint(y) } PRint – имя функции присваивания.
C = { PRDint(x)< PRDint(y) } PRDint – имя функции проверки корректности.
Множество отношений (R) для данной системы уравнений содержит два отношения (plus и umn), связывающие между собой переменные типов nint и integer (здесь мы игнорируем дополнительные переменные, которые, возможно, появились бы в результате компиляции исходных уравнений):
R = { plus(12,x,y); umn(y,2,x) }.
Множество функций интерпретации отношений из R можно представить следующим образом (в комментариях приведены описания функций в обычной записи):
Plus: minus 3 #y, 12, *x; (*y:=12-x*) (1)
minus 3 #x, 12, *y; (*x:=12-y*) (2)
umn: umn 3 #y, x, 2; (*y:=x*2* ) (3)
del 3 #x, y, 2; (*x:=y/2* ) (4)
Напомним, что арифметические операции реализованы в соответствии с правилами интервальной математики.
Технология недоопределенных вычислительных моделей позволяет обрабатывать неточные значения.
ПОСТАНОВКА ЗАДАЧИ
В задачу данной дипломной работы входит разработка машины вывода диагностической экспертной системы. Особенностью разрабатываемой машины вывода является ее способность работать с неточными и нечеткими входными данными. При этом машина вывода будет использовать экспертные знания, также допускающие элементы нечеткости и неточности.
ФОРМУЛИРОВКА В ПОЛЬЗОВАТЕЛЬСКИХ ТЕРМИНАХ
Необходимо было разработать систему медицинской диагностики, которая позволяла бы на основе неполных данных ставить диагноз с некоторой точностью, и выдавать, насколько точно она определила болезнь.
ВХОДНЫЕ ДАННЫЕ
Входными данными моей части программы являются:
Ответы пользователя на вопросы системы.
База данных с описаниями симптомов
База данных с описанием болезней
Таблица соответствий между болезнями и симптомами
Таблица «весов» (вероятностей) симптомов для болезней
База данных с данными о пациентах.
Иначе говоря, входные данные можно разбить на два больших блока:
Данные, поступающие из пользовательского интерфейса (см. введение)
Сюда также входит и база данных о пациентах (их «больничные карточки»)
Содержимое базы знаний, заполненной экспертом. База знаний хранится на жестком диске в виде четырех файлов; ее структура описана подробно в разделе 4.
ВЫХОДНЫЕ ДАННЫЕ
Выходными данными программы является диагноз, построенный на основе наблюдаемых симптомов и базы знаний о болезнях. Этот диагноз выдается на экран в качестве окончательного ответа экспертной системы пользователю. Кроме того, информация об обнаруженной болезни и наблюдаемых симптомах заносится в карточку пациента.
В процессе работы система генерирует несколько рабочих версий окончательного диагноза, и в конце происходит «отсеивание» лишних гипотез, которые имеют вес, меньший, чем некоторое значение, заранее заданное системным программистом.
Например, в процессе работы сформировалось 5 версий с вероятностями от 67 до 98 %. Порог уверенности, заданный системным программистом – 75%. Тогда система выдаст все версии, вероятности которых больше 75%. Например, их 3.
Болезнь 1 – 94%
Болезнь 2 – 93%
Болезнь 3 – 87%
Болезнь 4 – 51%
Болезнь 5 – 67%
Система «отсеет» остальные болезни, кроме этих трех, и выдаст эти три в порядке убывания их вероятностей:
У вас, скорее всего, Болезнь 1. Вероятность – 94%
Вероятность Болезни 2 – 93%
Вероятность Болезни 3 – 87%
Также следует упомянуть, что система ведет регистрацию больных, их болезней, и ведет статистику заболеваний:
Какая болезнь встречается чаще вообще,
Какая болезнь встречается чаще всего, например, в летний период,
В каком возрасте люди чаще обращаются к врачу,
Люди какого пола чаще обращаются к врачу,
И тому подобное.
СПЕЦИАЛЬНЫЕ ТРЕБОВАНИЯ
Программные требования
Операционная система Windows 95/98, NT
BDE (Borland Database Engine)
Аппаратные требования
Компьютер IBM PC, или совместимые 486 и выше
Манипулятор «Мышь»
Свободное дисковое пространство не менее 3 Мб.
SVGA Монитор
Требования к квалификации пользователя
Для установки Borland DBE и правильной калибровки программного средства желательно присутствие системного программиста.
Для заполнения базы знаний необходимо присутствие эксперта, осуществляющего интеллектуальное заполнение базы знаний.
МЕТОДЫ И АЛГОРИТМЫ РЕШЕНИЯ ЗАДАЧИ
МЕТОДЫ И ОПРЕДЕЛЕНИЯ
База знаний – Совокупность трех реляционных баз данных в формате Paradox 7.0:
База данных с описаниями болезней.
База данных с описаниями симптомов.
Таблица соответствий симптомов и болезней.
Таблица весов симптомов для болезней.
Вес – Вероятность той или иной болезни в процентах.
Недоопределенная спецификация – Набор данных, на основе которого невозможно принять окончательное решение.
Фактор уверенности – Фактор уверенности демонстрирует степень уверенности системы в достоверности сделанных ею логических заключений.
Порог уверенности – число, заранее определенное пользователем, означающее максимальный вес болезни в данном случае, ниже которого гипотезы просто не рассматриваются.
СТРУКТУРЫ ДАННЫХ Структуры данных данного программного средства – 4 таблицы формата Paradox 7.0 (работу с этими таблицами обеспечивает DBE и DBD, которые как раз поставляются в комплект с Borland Delphi с целью «безпроблемной» работы с базами данных практически любого формата). Таблица клиентов
| № П. П. | Наименование поля | Тип | Длина | Краткое описание |
| 1. | Num_kard | Numeric | Номер карточки | |
| 2. | Name | Character | 10 | Имя |
| 3. | Last_name | Character | 15 | Фамилия |
| 4. | Otchestvo | Character | 15 | Отчество |
| 5. | Fotokard | Character | 12 | Файл фотокарточки |
| 6. | Sex | Logic | 1 | Пол |
| 7. | Date_bd | Date | Дата рождения | |
| 8. | Date_create | Date | Дата регистрации | |
| 9. | Date_change | Date | Дата последнего обследования |
Что касается пункта 5. (fotokard), то для этого специально был разработан модуль для работы со сканером, чтобы можно было ввести фотокарточку пациента в его медицинскую карту.
Таблица Болезней
| № П. П. | Наименование поля | Тип | Длина | Краткое описание |
| 1. | Num | Numeric | Идентификационный номер болезни | |
| 2. | Name | Character | 15 | Наименование болезни |
| 3. | File_name | Character | 12 | Имя файла с рекомендация-ми |
| 4. | Work | Numeric | Поле используется для внутренних нужд |
Таблица симптомов
| № П. П. | Наименование поля | Тип | Длина | Краткое описание |
| 1. | Num | Numeric | Идентификационный номер | |
| 2. | Name_s | Character | 15 | Наименование симптома |
| 3. | File_name | Character | 12 | Имя файла с реккомендациями |
| 4. | Work | Numeric | Поле используется для внутренних нужд |
Таблица соответствий
| S[1] | … | S[max] | |
| N[1] | |||
| … | Numeric | ||
| N[max] |
Все значения таблицы – numeric. Число в пересечении колонок есть «указатель» на ту болезнь, на которую указывает определенный симптом, либо на тот симптом, на который указывает определенная болезнь.
Таблица весов
| S[1] | … | S[max] | |
| B[1] | |||
| … | Numeric | ||
| B[max] |
Таблица размером [Кол-во болезней]х[Кол-во симптомов]. Число в пересечении колонок – Вес данного симптома для данной болезни.
АЛГОРИТМ РЕШЕНИЯ ЗАДАЧИ
Работа программы начинается с функции инициализации, которая ответственна за присвоение данным начального значения. После чего управление получает процедура “Главного меню”. Далее, в зависимости от действий пользователя, происходит вызов одной из нижеперечисленных процедур:
Работа с базами знаний;
Работа с базой пациентов;
Непосредственный запуск экспертной системы;
Настройки;
Контекстно-зависимая справочная система.
В мою часть входила обработка следующих пунктов:
Работа с текущей базой знаний:
Считывание данных из файлов на диске.
Использование имеющейся там информации согласно нижеприведенному описанию.
Обработка поступающей информации.
Принятие решения и выдача окончательного результата.
На каждом шаге алгоритма у системы есть откат, т.е. у пользователя есть возможность, если он что-то забыл, вернуться в предыдущее состояние системы, нажав кнопку «Назад». Если же ему захочется все начать сначала, то, нажав кнопку «Отмена», система вернется в первоначальное состояние.
На вход системы (данные, введенные пользователем с клавиатуры) изначально поступает неполная информация, вследствие чего система не может однозначно поставить диагноз. Для решения данной проблемы используется следующий алгоритм:
Сбор предварительной информации.
Первоначальный шаг. При входе в систему пользователь видит перед собой список всех симптомов, имеющихся в базе. Напротив выборочных пунктов списка симптомов пользователь выставляет “галочки” (те симптомы, которые он у себя наблюдает). Нажав кнопку “Далее” система переходит к следующему пункту.
Составление первоначального списка болезней, к которым подходит данный набор симптомов.
После ввода пользователя некоторых первоначальных симптомов, система анализирует, к каким болезням принадлежат данные симптомы.
Алгоритм определения первоначального списка болезней:
Открываем таблицу соответствий
Для всех k=1 до максимального числа симптомов:
Берем k-тый симптом из первоначального списка;
Смотрим в таблицу соответствий: простым циклом делаем полный перебор всех элементов (болезней), стоящих в столбце данного симптома;
Делаем проверку:
5.1) Если данная болезнь уже имеется в списке, то переходим к п.6;
5.2) Если элемент таблицы =0, то болезнь в список не включаем;
Увеличиваем k на 1;
Если все симптомы (k) перебраны, то первоначальный список болезней сформирован;
Закрываем таблицу соответствий.
Каждый симптом может принадлежать сразу нескольким болезням, поэтому в первоначальном списке болезней болезней будет не столько же, сколько симптомов. Следует также учесть, что симптомы есть значимые и незначимые, т.е. вес симптома по отношению к какой-либо болезни либо большой, либо малый. Данный процесс регулируется системой, поэтому никак не зависит от пользователя.
Уточнение информации.
Имея начальный список болезней, система проводит их дифференциацию. Далее система начинает проводить “рассуждения”.
Самые распространенные методы логического вывода - это прямая цепочка рассуждений (прямой вывод) и обратная цепочка рассуждений (обратный вывод). В основном, при решении задач диагностики используется обратный вывод. Можно сказать, что обратный вывод более эффективен, когда пользователь должен выбирать из набора возможных последствий как в случае медицинской или технической диагностики. В разрабатываемой системе реализуется механизм смешанного вывода, который позволяет и прямой вывод от фактов к заключениям , и обратный - чтобы подтвердить или опровергнуть гипотезу.
В процессе уточнения информации система, задавая пользователю вопросы, проводит «отсеивание» лишних гипотез, имеющих малый вес. Для просчета веса гипотез система открывает данные из файла на диске, а именно таблицу весов. Таблица весов размером [Кол-во болезней] на [Кол-во симптомов] имеет в пересечении клеток число, равное весу данного симптома для данной болезни; порог уверенности заранее задается в настройках.
Рекомендации и сбор дополнительной информации.
Если пользователь не смог ответить на некоторые вопросы на этапе первоначального опроса, то система дает рекомендации, как можно собрать эти данные, (сдать анализы, провести ЭКГ) и на основе этого собирает дополнительные данные. Рекомендации система дает только на гипотезы, имеющие большой вес (чтобы подтвердить их весомость, и чтобы пациенту не стоило сдавать лишних анализов).
Принятие окончательного решения.
В процессе предыдущих шагов выявляется несколько версий окончательного результата, которые система распределяет по порядку возрастания вероятности той или иной болезни.
Вероятности болезней также считаются по таблице весов.
Алгоритм подсчитывания веса:
Выбирается болезнь из списка болезней, сформированного на предыдущих этапах.
Система просматривает, какие симптомы из списка симптомов имеют отношение к данной болезни.
Происходит суммирование весов всех симптомов, имеющих отношение к данной болезни (опять же по таблице весов).
Запоминание конечного веса болезни.
После подсчета весов всех болезней выбирается болезнь, имеющая максимальный вес, и происходит нормировка весов болезней (чтобы они были в пределах от 1 до 100)
Далее система выбирает те болезни, вероятности которых находятся в некоторых рамках, заранее определенных системным программистом (так называемый “порог уверенности”). Значение порога уверенности можно задать в настройках программы.
Формула для подсчета веса болезни: ves_b(j) = [tab_ves(ves(i,j))]*k(i)
То есть, для конечного подсчета вероятности не применяется умножение веса на коэффициенты, а идет суммирование всех элементов таблицы весов (tab_ves(ves(i,j)) имеющих отношение к болезни. Далее происходит нормировка всех конечных вероятностей с целью “укладывания” их в промежуток от 1..100. (Чтобы окончательный ответ измерялся в процентах). k(i) – коэффициент присутствия симптома (равен либо «0», либо «1»).
Пример:
| Голова болит | Провалы памяти | Частые припадки | В ухе стреляет | Челюсть сводит | Внутриче-репное давление | |
| Склероз | 10 | 106 | 64 | 55 | 20 | 43 |
Например, в процессе работы были выбраны симптомы 2,4 и 6. Система будет суммировать вес:
Ves_b("склероз")=10*0+106*1+64*0+55*1+20*0+43*1=204. Далее:
У всех болезней таким образом будет вычислен вес.
Выберется максимальный вес болезни из списка болезней.
J=-1; // отрицательное значение для начала.
For i=1 to 15 do
( if j>max(ves_b(i)) // если j больше максимального значения,
j=max(ves_b(i)); // то j=max.
Допустим, максимальный вес = 300.
Веса всех болезней разделятся на 300 (нормируются), чтобы быть в пределах от 0 до 1.
Таким образом, вес болезни “склероз” = 204/300=0.68 (т.е. 68%). Это и есть конечный итог.
Выдача конечного результата.
Система выдает те болезни, которые были выбраны в предыдущем пункте в порядке процентного убывания, на экран.
Пример:
У вас, скорее всего, Склероз. Вероятность – 94%
Вероятность физического повреждения мозга – 93%
Вероятность простой потери памяти – 87%
В данном случае, порог уверенности, установленный системный программистом, составляет 92%, поэтому все болезни, имеющие веса, не превышающие планки 92%, просто отсеиваются.
СПЕЦИАЛЬНЫЙ ИНСТРУМЕНТАРИЙ Для разработки данной программы была выбрана программная среда Borland Delphi 4.0. Для создания баз данных была использована разработка фирмы Borland - DBD (Database Desktop). Среда Borland Delphi была выбрана не случайным образом: Было решено, что разрабатываемая система, в отличие от ее предшественника, системы Di-Gen, будет функционировать в операционных системах Windows 95/98 или NT, имеющих наиболее широкое распространение.
Кроме того, Borland Delphi предоставляет достаточно высокий уровень для создания стандартного пользовательского интерфейса в операционной системе Windows.
В стандартную поставку Borland Delphi входит Borland DBD, позволяющая создавать и редактировать базы данных практически любого формата.
СХЕМА ФУНКЦИОНИРОВАНИЯ ПРОГРАММНОГО СРЕДСТВА
Похожие работы

... ресурсы и на последнем этапе проведена оценка эффективности прототипа ИС, которая показала, что внедрение проекта целесообразно. Заключение Целью дипломного проекта являлась разработка подсистемы учета гематологических анализов для КДЛ ГБСМП-2 г. Ростова. Первым этапом дипломного проекта являлась определение цели и задач дипломного проекта. Был проведен анализ существующих систем. В первом ...
... специалистов, обладающих указанной совокупностью знаний и выполняющих функции “посредников” между экспертами в предметной области и компьютерными (экспертными) системами. Они получили название инженеры знаний (в оригинале - knowledge engineers), а сам процесс разработки ЭС и других интеллектуальных программ, основанных на представлении и обработке знаний - инженерией знаний (knowledge engineering ...
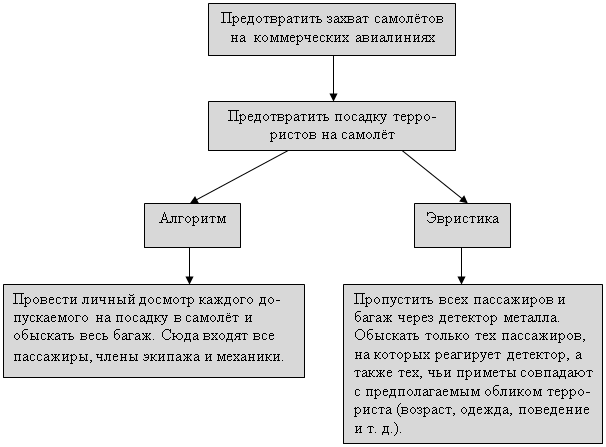
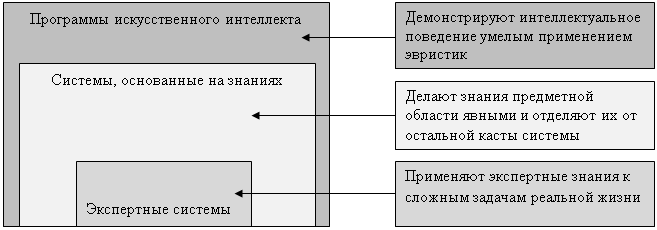
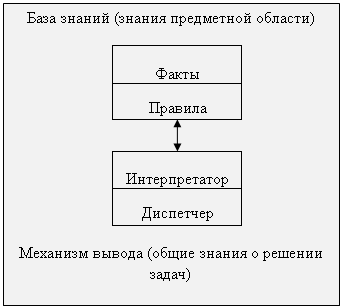

... в экспертной системе с необходимостью должны быть сложными либо в смысле сложности каждого правила, либо в смысле их обилия. Экспертные системы, как правило, работают с предметными областями реального мира, а не с тем, что специалисты в области искусственного интеллекта называют игрушечными предметными областями. В предметной области реального мира тот, кто решает задачу, применяет фактическую ...


... и аппаратной реализации, выполненные на этом языке описания, переводятся на более подходящие языки другого уровня. 4. Экспертные системы (ЭС), их структура и классификация. Инструментальные средства построения ЭС. Технология разработки ЭС 4.1 Назначение экспертных систем В начале восьмидесятых годов в исследованиях по искусственному интеллекту сформировалось самостоятельное направление ...
0 комментариев