Навигация
2.7. Примеры.
Представляем несколько примеров использования реляционного исчисления кортежей для формулирования запросов.
Ø Определить имена поставщиков детали с номером ‘P2’
SX
WHERE EXISTS SPX (SPX.S# = SX.S# AND
SPX.P# = P# (‘P2’) )
Обратите внимание на использование имени переменной кортежа в прототипе кортежа. Этот пример является сокращённой записью следующего выражения.
(SX.S#, SX.NAME, SX.STATUS, SX.CITY)
WHERE EXISTS SPX (SPX.S# = SX.S# AND
SPX.P# = P# (‘P2’) )
Этот же пример решённый средствами реляционной алгебры выглядит так
( (SP JOIN S) WHERE P# =’P2’) {SNAME}
Ø Определить имена поставщиков по крайней мере одной красной детали
SX.SNAME
WHERE EXISTS SPX (SX.S# = SPX.S# AND
EXISTS PX (PX.P# = SPX.P# AND
PX.COLOR = COLOR (‘Red’) ) )
Этот же пример решённый средствами реляционной алгебры выглядит так
( ( ( P WHERE COLOR = COLOR (‘Red’) )
JOIN SP) {S#} JOIN S) {SNAME}
3. Сравнительный анализ реляционного исчисления и реляционной алгебры.
В начале утверждалось, что реляционная алгебра и реляционное исчисление в своей основе эквивалентны. Осудим это утверждение более подробно. Вначале Кодд показал, что алгебра по крайней мере мощнее исчисления. Он сделал это, придумав алгоритм, называемый алгоритмом редукции Кодда, с помощью которого любое выражение исчисления можно преобразовать в семантически эквивалентное выражение алгебры. Мы не станем приводить здесь этот алгоритм полностью, а ограничимся довольно сложным примером, иллюстрирующим в общих чертах, как он функционирует.
| S# | SNAME | STATUS | CITY |
| S1 | Smith | 20 | London |
| S2 | Jones | 10 | Paris |
| S3 | Black | 30 | Paris |
| S4 | Clark | 20 | London |
| S5 | Adams | 30 | Athens |
| S# | P# | J# | QTY |
| S1 | P1 | J1 | 200 |
| S1 | P1 | J4 | 700 |
| S2 | P3 | J1 | 400 |
| S2 | P3 | J2 | 200 |
| S2 | P3 | J3 | 200 |
| S2 | P3 | J4 | 500 |
| S2 | P3 | J5 | 600 |
| S2 | P3 | J6 | 400 |
| S2 | P3 | J7 | 800 |
| S2 | P5 | J2 | 100 |
| S3 | P3 | J1 | 200 |
| S3 | P4 | J2 | 500 |
| S4 | P6 | J3 | 300 |
| S4 | P6 | J7 | 300 |
| S5 | P2 | J2 | 200 |
| S5 | P2 | J4 | 100 |
| S5 | P5 | J5 | 500 |
| S5 | P5 | J7 | 100 |
| S5 | P6 | J2 | 200 |
| S5 | P1 | J4 | 100 |
| S5 | P3 | J4 | 200 |
| S5 | P4 | J4 | 800 |
| S5 | P5 | J4 | 400 |
| S5 | P6 | J4 | 500 |
| P# | PNAME | COLOR | WEIGHT | CITY |
| P1 | Nut | Red | 12.0 | London |
| P2 | Bolt | Green | 17.0 | Paris |
| P3 | Screw | Blue | 17.0 | Rome |
| P4 | Screw | Red | 14.0 | London |
| P5 | Cam | Blue | 12.0 | Paris |
| P6 | Cog | Red | 19.0 | London |
| J# | JNAME | CITY |
| J1 | Sorter | Paris |
| J2 | Display | Rome |
| J3 | OCR | Athens |
| J4 | Console | Athens |
| J5 | RAID | London |
| J6 | EDS | Oslo |
| J7 | Tape | London |
S-детали, P- поставщики, J- проекты, SPJ- поставки.
Рассмотрим теперь следующий запрос: «Получить имена поставщиков и названия городов, в которых находятся поставщики деталей по крайней мере для одного проекта в Афинах, поставляющих по крайней мере 50 штук каждой детали». Выражение реляционного исчисления для этого запроса следующее.
(SX.SNAME, SX.CITY) WHERE EXISTS JX FORALL PX EXISTS SPJX
( JX.CITY = ‘Athens’ AND
JX.J# = SPJX.J# AND
PX.P# = SPJX.P# AND
SX.S# = SPJX.S# AND
SPJX.QTY ≥ QTY (50) )
Здесь SX, PX, JX и SPJX ─ переменные кортежей, получающие свои значения из отношений S, P, J и SPJ соответственно. Теперь покажем, как можно вычислить это выражение, чтобы достичь требуемого результата.
Этап 1. Для каждой переменной кортежа выбираем её область значений (т.е. набор всех значений для переменной), если это возможно. Выражение «выбираем, если возможно» подразумевает, что существует условие выборки, встроенное в фразу WHERE, которую можно использовать, чтобы сразу исключить из рассмотрения некоторые кортежи. В нашем случае выбираются следующие наборы кортежей.
SX : Все кортежи отношения S 5 кортежей
PX : Все кортежи отношения P 6 кортежей
JX : Кортежи отношения J, в которых CITY = ‘Athens’ 2 кортежа
SPJX : Кортежи отношения SPJ, в которых CITY ≥ 50 24 кортежа
Этап 2. Строим декартово произведение диапазонов, выбранных на первом этапе. Вот результат.
| S# | SN | STA TUS | CITY | P# | PN | CO-LOR | WEIGHT | CITY | J# | JN | CITY | S# | P# | J# | QTY |
| S1 | Sm | 20 | Lon | P1 | Nt | Red | 12.0 | Lon | J3 | OR | Ath | S1 | P1 | J1 | 200 |
| S2 | Sm | 20 | Lon | P1 | Nt | Red | 12.0 | Lon | J3 | OR | Ath | S1 | P1 | J4 | 700 |
| .. | .. | .. | … | .. | .. | … | … | … | .. | .. | … | .. | .. | .. | … |
(И т.д.) Всё произведение содержит 5*6*2*24=1440 кортежей.
Замечание. Для экономии места здесь это отношение полностью не приводится. Мы также не переименовывали атрибуты (хотя это следовало бы сделать во избежание двусмысленности), просто расположили их в таком порядке, чтобы было видно, какой атрибут S# относится, например, к отношению S, а какой ─ к отношению SPJ. Это также сделано для сокращения изложения.
Этап 3. Осуществляем выборку из построенного на этапе 2 произведения в соответствии с частью «условие соединения» фразы WHERE. В нашем примере эта часть выглядит следующим образом.
JX.J# = SPJX.J# AND PX.P# = SPJX.P# AND SX.S# = SPJX.S#
Поэтому из произведения исключаются кортежи, для которых значение атрибута S# из отношения поставщиков не равно значению атрибута S# из отношения поставок, значение атрибута P# из отношения деталей не равно значению атрибута P# из отношения поставок, значение атрибута J# из отношения проектов не равно значению атрибута J# из отношения поставок. Затем получаем подмножество декартова произведения, состоящее (как оказалось) только из десяти кортежей.
| S# | SN | STA TUS | CI-TY | P# | PN | CO-LOR | WEIGHT | CITY | J# | JN | CI-TY | S# | P# | J# | QTY |
| S1 | Sm | 20 | Lon | P1 | Nt | Red | 12.0 | Lon | J4 | Cn | Ath | S1 | P1 | J4 | 700 |
| S2 | Jo | 10 | Par | P3 | Sc | Blue | 17.0 | Rom | J3 | OR | Ath | S2 | P3 | J3 | 200 |
| S2 | Jo | 10 | Par | P3 | Sc | Blue | 17.0 | Rom | J4 | Cn | Ath | S2 | P3 | J4 | 200 |
| S4 | Cl | 20 | Lon | P6 | Cg | Red | 19.0 | Lon | J3 | OR | Ath | S4 | P6 | J3 | 300 |
| S5 | Ad | 30 | Ath | P2 | Bt | Green | 17.0 | Par | J4 | Cn | Ath | S5 | P2 | J4 | 100 |
| S5 | Ad | 30 | Ath | P1 | Nt | Red | 12.0 | Lon | J4 | Cn | Ath | S5 | P1 | J4 | 100 |
| S5 | Ad | 30 | Ath | P3 | Sc | Blue | 17.0 | Rom | J4 | Cn | Ath | S5 | P3 | J4 | 200 |
| S5 | Ad | 30 | Ath | P4 | Sc | Red | 14.0 | Lon | J4 | Cn | Ath | S5 | P4 | J4 | 800 |
| S5 | Ad | 30 | Ath | P5 | Cm | Blue | 12.0 | Par | J4 | Cn | Ath | S5 | P5 | J4 | 400 |
| S5 | Ad | 30 | Ath | P6 | Cg | Red | 19.0 | Lon | J4 | Cn | Ath | S5 | P6 | J4 | 500 |
(Это отношение, конечно, представляет собой эквивалент результата операции соединения.)
Этап 4. Применяем кванторы в порядке справа налево следующим образом.
- Для квантора EXISTS RX (где RX ─ переменная кортежа, принимающая значение на некотором отношении r) проецируем текущий промежуточный результат, чтобы исключить все атрибуты отношения r.
- Для квантора FORALL RX делим текущий промежуточный результат на отношение «выбранной области значений», соответствующее RX, которое было получено выше. При выполнении этой операции также будут исключены все атрибуты отношения r.
Замечание. Под делением здесь подразумевается оригинальная операция деления Кодда.
В нашем примере имеем следующие кванторы.
EXISTS JX FORALL PX EXISTS SPJX
Значит, выполняются следующие операции.
1. (EXISTS SPJX) Проецируем, исключая атрибуты отношения SPJ (SPJ.S#,
SPJ.P#, SPJ.J# и SPJ.QTY). В результате получаем следующее.
| S# | SN | STA TUS | CI-TY | P# | PN | CO-LOR | WEIGHT | CITY | J# | JN | CI-TY |
| S1 | Sm | 20 | Lon | P1 | Nt | Red | 12.0 | Lon | J4 | Cn | Ath |
| S2 | Jo | 10 | Par | P3 | Sc | Blue | 17.0 | Rom | J3 | OR | Ath |
| S2 | Jo | 10 | Par | P3 | Sc | Blue | 17.0 | Rom | J4 | Cn | Ath |
| S4 | Cl | 20 | Lon | P6 | Cg | Red | 19.0 | Lon | J3 | OR | Ath |
| S5 | Ad | 30 | Ath | P2 | Bt | Green | 17.0 | Par | J4 | Cn | Ath |
| S5 | Ad | 30 | Ath | P1 | Nt | Red | 12.0 | Lon | J4 | Cn | Ath |
| S5 | Ad | 30 | Ath | P3 | Sc | Blue | 17.0 | Rom | J4 | Cn | Ath |
| S5 | Ad | 30 | Ath | P4 | Sc | Red | 14.0 | Lon | J4 | Cn | Ath |
| S5 | Ad | 30 | Ath | P5 | Cm | Blue | 12.0 | Par | J4 | Cn | Ath |
| S5 | Ad | 30 | Ath | P6 | Cg | Red | 19.0 | Lon | J4 | Cn | Ath |
2.(FORALL PX) Делим полученный результат на отношение P. В результате имеем следующее.
| S# | SN | STATUS | CITY | J# | JNAME | CITY |
| S5 | Adams | 30 | Athens | J4 | Console | Athens |
(Теперь у нас есть место, чтобы показать отношение полностью, без сокращений.)
1.(EXISTS JX) Проецируем, исключая атрибуты отношения J (J.J#, J.NAME и J.CITY). В результате получаем следующее.
| S# | SN | STATUS | CITY |
| S5 | Adams | 30 | Athens |
Этап 5. Проецируем результат этапа 4 в соответствии со спецификациями в прототипе кортежа. В нашем примере имеет следующий вид.
(SX.SNAME, SX.CITY)
Значит, конечный результат вычислений будет таков.
| SNAME | CITY |
| Adams | Athens |
Из сказанного выше следует, что начальное выражение исчисления семантически эквивалентно определённому вложенному алгебраическому выражению, и, если быть более точным, это проекция от проекции результата деления проекции выборки из произведения четырёх выборок (!).
И хотя многие подробности в пояснениях были упущены, этот пример вполне адекватно отражает общую идею работы алгоритма редукции.
Теперь моно объяснить одну из причин (и не только одну) определения Коддом ровно восьми алгебраических операторов. Эти восемь реляционных операторов образуют удобный целевой язык как средство возможной реализации реляционного исчисления. Другими словами, для заданного языка, построенного на основе реляционного исчисления (подобно языку QUEL), один из возможных подходов реализации заключается в том, что организуется получение запроса в том виде, в каком он представляется пользователем. По существу, он будет являться просто выражением реляционного исчисления, к которому затем можно будет применить определённый алгоритм редукции, чтобы получить эквивалентное алгебраическое выражение. Это алгебраическое выражение, конечно, будет включать набор алгебраических операций, которые по определению реализуемы по самой своей природе.
Также следует отметить, что восемь алгебраических операторов Кодда являются мерой оценки выразительной силы любого языка баз данных.
Некоторый язык принято называть реляционно полным, если он по своим возможностям по крайней мере не уступает реляционному исчислению. Иначе говоря, любое отношение, которое можно определить с помощью реляционного исчисления, можно определить и с помощью некоторого выражения рассматриваемого языка. («Реляционно полный» значит «не уступающий по возможностям реляционной алгебре», а не исчислению, но это одно и то же, как мы вскоре убедимся. По сути, из самого существования алгоритма редукции Кодда немедленно следует, что реляционная алгебра обладает реляционной полнотой.)
Реляционную полноту можно как основную меру выразительной силы языков баз данных в самом общем случае. В частности, так как реляционное исчисление и реляционная алгебра обладают реляционной полнотой, они могут служить основой для проектирования не уступающих им по выразительности языков без необходимости выполнять пересортировку для организации циклов. Это замечание особенно важно, если язык предназначается для конечных пользователей, хотя оно также существенно, если язык предназначается для использования прикладными программистами.
Далее, поскольку алгебра обладает реляционной полнотой, для доказательства того, что некоторый язык L также обладает реляционной полнотой, достаточно показать, что в языке L есть аналогии всех восьми алгебраических операций (на самом деле достаточно показать, что в нём есть аналоги пяти примитивных операций) и что операндами любой операции языка L могут быть любые выражения этого языка. Язык SQL ─ это пример языка, реляционную полноту которого можно доказать указанным способом. Язык QUEL ─ ещё один пример подобного языка. В действительности на практике часто проще показать то, что в языке есть эквиваленты операций реляционной алгебры, чем то, что в нём существуют эквиваленты выражений реляционного исчисления. Именно поэтому реляционная полнота обычно определяется в терминах алгебраических выражений, а не в терминах выражений реляционного исчисления.
При этом важно понимать, что реляционная полнота необязательно влечёт за собой полноту какого-либо другого рода. Например, желательно, чтобы язык также обеспечивал «вычислительную полноту», т.е. позволял вычислять результаты всех вычислимых функций. Заметим, что согласно нашему определению исчисление не обладает полнотой такого рода, хотя на практике подобная полнота для языка баз данных весьма желательна. Вычислительная полнота ─ это один из факторов, побудивших ввести в реляционную алгебру операции EXTEND и SUMMARIZE. В следующем разделе описано, как можно расширить реляционное исчисление, чтобы обеспечить в нём наличие аналогов этих операций.
Вернёмся к вопросу эквивалентности алгебры и исчисления. Мы на примере показали, что любое выражение исчисления можно преобразовать в его некоторый алгебраический эквивалент, а значит, алгебра по крайней мере не уступает по своей мощности исчислению. Можно показать обратное: каждое выражение реляционной алгебры можно преобразовать в эквивалентное выражение реляционного исчисления, а значит, исчисление по крайней мере не уступает по своей мощности реляционной алгебре. Отсюда следует, что реляционная алгебра и реляционное исчисление эквивалентны.
Похожие работы
... ) AND FORALL СОТР2 (СОТР1.СОТР_ЗАРП > СОТР2.СОТР_ЗАРП) Здесь мы имеем два связанных вхождения переменной СОТР2 с совершенно разным смыслом. 5.2.2. Целевые списки и выражения реляционного исчисления Итак, WFF обеспечивают средства формулировки условия выборки из отношений БД. Чтобы можно было использовать исчисление для реальной работы с БД, требуется еще один компонент, который определяет ...
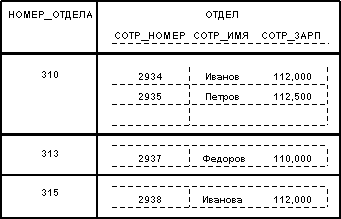
... 2935 Петров 144,000 310 2936 Сидоров 92,000 313 2937 Федоров 110,000 310 2938 Иванова 112,000 315 Нормализованные отношения составляют основу классического реляционного подхода к организации баз данных. Они обладают некоторыми ограничениями (не любую информацию удобно представлять в виде плоских таблиц), но существенно упрощают манипулирование данными. Рассмотрим, например, два ...
... , но не совпадающие понятия. Различия между отношениями и таблицами будут рассмотрены ниже. Термины, которыми оперирует реляционная модель данных, имеют соответствующие "табличные" синонимы: Реляционный термин Соответствующий "табличный" термин База данных Набор таблиц Схема базы данных Набор заголовков таблиц Отношение Таблица Заголовок отношения Заголовок таблицы Тело ...

... став вторичного ключа, не может принимать значение NULL. Перекрывающиеся ключи — сложные ключи, которые имеют один или несколько общих столбцов. Связанные отношения В реляционной модели данные представляются в виде совокупности взаимосвязанных таблиц. Подобное взаимоотношение между таблицами называется связью (rilationship). Таким образом, еще одним важным понятием реляционной модели является ...
0 комментариев