Первый символ должен являться буквой или символом подчеркивания
Тело функции, представляющее собой коды, выполняемые при вызове функции
Выражение-приведения это пустой (null) указатель
Е1 является указателем, а Е2 - константой типа пустого указателя
Выражение-инремента выполняет приращения одного или нескольких цикловых счетчиков
Вызвать конструктор тем же образом, что и обычную функцию, нельзя. Вызов деструктора допустим только с полностью квалифицированным именем
Инициализатор конструктора (см. "инициализатор-конструктора" в описании синтаксиса декларатора класса в таблице
Или 16). Ноль означает по умолчанию десятичную
Мы будем обозначать все семейство математических сопроцессоров 80x87 термином "сопроцессор"
В режиме эмуляции 80Х87 циклический переход в регистрах, а также ряд других особенностей 80х87 не поддерживается
GrOk No error Нет ошибки
Кроме того, обратите внимание на то, что функция прерывания выполняет выход с помощью команды IRET (возврата из прерывания)
Как идентифицировать диагностические сообщения
Что происходит, когда доступ к компоненту объекта типа объединения происходит при помощи компонента другого типа
Печатаемые диагностические сообщения и поведение при завершении функции assert
Навигация
Или 16). Ноль означает по умолчанию десятичную
Turbo C++ Programer`s guide
668870
знаков
13
таблиц
0
изображений
10 или 16). Ноль означает по умолчанию десятичную
систему при выводе и правила С для литералов це-
лых чисел при вводе.
resetiosflags(long) ins>>resetiosflags(l) Очистка форматных битов outs<<resetiosflags(l) в ins или outs, заданных аргументом l
setiosflags(long) ins>>setiosflags(l) Установка форматных битов outs<<setiosflags(l) в ins или outs, заданных аргументом l
setfill(int) ins>>setfill(n) Установка символа-за-
полнителяouts<<setfill(n) в n
setprecision(int) ins>>setprecision(n) Установка точности представления outs<<setprecision(n) чисел с плавающей точкой равной n разрядам
setw(int) ins>>setw(n) Установка ширины поля
outs<<setw(n) в значение n
Не-параметризованные манипуляторы dec, hex и oct (объявленные в ios.h) непринимают никаких аргументови просто изменяют основание системы счисления при преобразовании (и оставляютэто изменение в силе):
int i = 36;
cout << dec << i << " "
<< hex << i << "
<< oct << i << endl;
// вывод на дисплей 36 24 44
Манипулятор endl вставляет символ новой строки и очищает поток. Можно также в любой момент очистить ostream, записав
ostream << flush;
Заполнители и дополнение вправо и влево
Символ-заполнитель и направление дополнения зависят от установок внутренних флагов, отвечающих за эти параметры.
По умолчанию символом-заполнителем является пробел. Изменить данное умолчание позволяет функция fill:
int i = 123;
cout.fill("*");
cout.width(6);
cout << i; // на дисплей будет выведено ***123
По умолчанию устанавливается выравнивание по правому краю (дополнение символами-заполнителями влево). Эти умолчания (а также прочие форматные флаги) можно изменять при помощи функций setf и unsetf:
int i = 56;
...
cout.width(6);
cout.fill('#');
cout.setf(ios::left,ios::adjustfield);
cout << i // на дисплей будет выведено 56####
Второй аргумент, ios::adjustfield, сообщает setf, какие биты должны быть установлены. Первый аргумент,ios::left, сообщает setf,в какие именно значения устанавливаютсяэти биты. Альтернативно можно использовать манипуляторы setfill, setiosflags иresetiosflags, которые позволяют модифицировать символ-заполнитель и направление дополненияпри форматировании (см. табл.3.1).
Вставки, определяемые пользователем
Вы можете писать собственныевставки для вывода своих собственных типов данных, перегружая для этого операцию<<. Предположим, у вас имеется тип
struct info (*
char *name;
double val;
char *units;
(*;
Вы можете перегрузить << следующим образом:
ostream& operator << (ostream& s, info& m)
(*
s << m.name << " " << m.val << " " << m.units;
*)
Операторы
info x;
...
// здесь инициализируется x
...
cout << x;
даст на выходе что-либо вроде "capacity 1.25 liters".
Ввод ----------------------------------------------
Ввод потоком аналогичен выводу, но использует перегруженную операцию сдвига вправо, >>, и называется операцией извлечения, или извлечением. Операция >> обеспечивает более компактную и читаемую альтернативу семейству функций scanf в stdio (она также лучше защищена от ошибок). Левый операнд >> представляет собой объект типа класса istream. Как и для вывода, правый операнд может быть любого типа, для которого определен вывод потоком.
Все встроенные типы, перечисленные вышедля вывода, также имеют предопределенные операции извлечения. Операция >> может быть такжеперегружена для ввода потоком ваших собственных типов данных. Операция >>,перегруженная для типа type, называется извлечением type. Например,
cin >> x;
вводит значение из cin (стандартный поток ввода, обычно направляемый с клавиатуры) в x. Функции преобразования и форматирования зависят от типа x, от того, каким образом определено извлечение, а также от установок флагов состояния формата.
По умолчанию >> опускает пробельные символы (как определено функцией isspace в ctype.h), а затем считывает символы, соответствующие типуобъекта ввода. Пропуск пробельных символов управляется флагом ios::skipws в перечислимой переменной состояний формата (см. "Форматирование вывода" на стр.170 оригинала). Флаг skipws обычно устанавливает пропуск пробельных символов. Очистка этогофлага (например, припомощиsetf)выключает пропуск пробельных символов. Отметим также специальныйманипулятор "приемника", ws, который позволяет игнорировать пробельные символы (см. таблицу 3.1).
Изменение извлечений
Как и в случае <<, операция >> обладает свойством ассоциативности слева и возвращает левый операнд. Левый операнд является ссылкой на объект istream, для которого была вызвана данная операция. Это позволяет объединятьв одном операторе несколько операций ввода. Рассмотрим следующий пример:
int i;
double d;
cin >> i >> d;
Последняя строка вызывает пропуск пробельных символов; цифры, считываемые со стандартного устройства ввода(по умолчаниюэто ваша клавиатура), преобразуются затем во внутренний двоичный формат и записываются в переменную i; затемснова пропускаются пробельные символы, и наконец считываетсячисло с плавающей точкой, преобразуется и записывается в переменную d.
Извлечения для встроенных типов
Извлечения для встроенных типов делятсяна три категории: интегральные,с плавающей точкой и строковые. Каждое из них описано ниже, в следующих разделах. Для всех числовых типов в случае, еслипервыйне-пробельный символ не является цифрой или знаком (или десятичной точкой для преобразований с плавающей точкой), поток вводит состояние ошибки (это описано на стр.177 оригинала) и вплоть до сброса состояния ошибки любой дальнейший ввод запрещен.
Интегральные извлечения
Для типов short, int и long (signed и unsigned) действие операции >> по умолчанию заключаетсяв пропуске не-пробельныхсимволов и преобразовании интегрального значения путем чтения символов ввода до тех пор, пока не встретится символ, который не может являться допустимой частью представления данного типа. Формат распознаваемых интегральных значений тот же, что и для целочисленных констант С++, заисключением целочисленных суффиксов. (См. стр.11 оригинала).
Предупреждение
Если вы задали преобразования типа hex, dec или oct, то именно такиерезультаты выи получите. 0x10 становится0 в десятичном или восьмеричном представлении; 010 становится 10 в десятичном представлении и 16 в шестнадцатиричном.
Извлечения с плавающей точкой
Для типов float и double действие операции >> состоит в пропуске пробельных символов и преобразовании значения с плавающей точкой путем чтения вводимых символов до тех пор, пока не встретится символ, который не может являться частью представлениячисла с плавающей точкой. Формат распознаваемых значений с плавающей точкой тот же, что и для констант с плавающей точкой С++, за исключением суффиксов. (См. стр.16 оригинала).
Символьные извлечения
Для типа char (signed или unsigned) действие операции >> состоит в пропускепробельных символов и записи следующего (не-пробельного) символа. Если вам требуетсяпрочесть следующий символ, неважно, является ли он пробельным или нет, то можно использовать одну из функций-компонентов get:
char ch;
cin.get(ch); // ch устанавливается на следующий символ потока // даже если это пробельный символ
Функции get для ввода играют ту же роль, что функции putдля вывода. Следующий вариант get позволяет управлять числом извлекаемых символов, их размещением и оконечным символом:
istream& istream::get(char *buf, int max, int term='\n');
Эта функция считывает символы из входного потока в символьный массив buf до тех пор, пока не будет считано max-1 символов, либо пока не встретится символ, заданный term, в зависимости от того, что произойдет раньше. Завершающийпустойсимволдобавляется автоматически. По умолчаниютерминатором (который не требуется задавать) является символ новой строки ('\n'). Сам терминатор в массив buf не считывается и из istream не удаляется. Массив buf должен иметь размер как минимум max символов.
По аналогии с функцией-компонентом ostream write (см. стр.170 оригинала) можно прочитать "сырые" двоичные данные следующим образом:
cin.read ( (char*)&x, sizeof(x) );
Для типа char* (рассматриваемого как строка) действие операции >> состоит в пропуске пробельныхсимволов и записи следующих (не-пробельных) символов до тех пор, пока не встретится следующий пробельный символ. Затем добавляется завершающий нулевой (0) символ.Следует предъявлятьосторожность и избегать "переполнения" строки. Ширина по умолчанию, равная нулю (означает, что предельное значение не задано), может быть изменена при помощи setw следующим образом:
char array[SIZE];
...
// инициализация массива
...
cin.width(sizrof(array));
cin >> array // позволяет избежать переполнения
В случае любого вводавстроенных типов, если конец ввода встретится ранее первого не-пробельного символа, вмишеньbuf ничего записано не будет, а состояние istream будет установлено равным "отказу". Таким образом, если мишень была не инициализирована, то она и останется не инициализированной.
Функция возвращения
Функция-компонент
istream istream::putback(char c);
возвратит обратно в istream один символ c; если этот символ не может быть помещен обратно, то устанавливается состояние потока "отказ". Следующая простая подпрограмма выполняет считывание идентификатора С++ со стандартного устройства ввода:
void getident (char *s /* сюда помещается идентификатор */ )
(*
char c = 0; // защита от конца файла
cin >> c; // пропуск пробельных символов
if (isalpha(c) \!\! c == '_')
do (*
*s++ = c;
c = 0; // защита от конца файла
cin.get(c);
*) while (isalnum(c) \!\! c =='_');
*s = 0; // терминатор строки
if (c)
cin.putback(c); // один символ всегда лишний
*)
Ввод типов, определяемых пользователем
Вы можете создавать извлечения для определенных вами типов такимже образом, как этоделается со вставками. Используя информацию о структуре, определенной выше, операция >> может быть перегружена следующим образом:
istream& operator >> (istream& s, info& m);
(*
s >> m.name >> m.val >> m.units;
return s;
*)
(В реальных прикладных программах, разумеется, вы можете добавить коды для проверки ошибок ввода). Для считывания строки ввода, такойкак "capacity 1.25 liters", можно использовать следующую запись:
cin >> m;
Инициализация потоков
Потоки cin, cout, cerr и clog инициализируются и открываются при загрузке программы и затем подключаются к соответствующим стандартным файлам. Инициализация (конструирование) потока означает ассоциирование его с буфером потока. Класс ostream имеет следующий конструктор:
ostream::ostream(streambuf*);
который инициализирует переменные состояния ios и ассоциирует буфер потока с объектом ostream. Конструктор istream работает аналогичным образом. В большинстве случаев вам не требуется специально рассматривать вопросами буферизации.
Библиотека iostream предлагает множество классов, производных от streambuf, ostream и istream, что дает широкий выбор методов создания потоков с различными источниками и приемниками, а также различными методами буферизации.
Следующие классы являются производными от класса streambuf:
filebuffilebuf поддерживает ввод/вывод через дескрипторы файлов. Функции-компонент класса поддерживают функции открытия, закрытия файлов и поиска.
stdiobufstdiobuf поддерживает ввод/вывод через структуры stdio FILE и предназначается исключительно для совместимости кодов С++ при их комбинировании с существующими программами С.
strstreambufstrstreambuf позволяет ввод и вывод символов из байтовых массивов в памяти. Два дополнительных класса, istrstream и ostrstream, обеспечивают ввод/ вывод с форматированием в памяти.
Специализированные классы для ввода/вывода в файл являются производными:
ifstream является производным от istream
ofstream является производным от ostream
fstream является производным от iostream
Эти триклассаподдерживают форматированный ввод/вывод в файлы при помощи буферов файлов (filebuf).
Простой ввод/вывод в файл
Класс ofstream наследует операции вставки отostream, а ifstream наследует операцииизвлечения отistream. Они также обеспечивают конструкторы и функции-компоненты для создании файлов и обработки ввода/вывода в этот файл. Следуетвключать fstream.h во все программы, где используются эти файлы. Рассмотрим следующий пример, в котором файл FILE_FROM копируется в FILE_TO:
#include fstream.h
...
char ch;
ifstream f1("file_from");
if (!f1) errmsg("Cannot open 'filr_from' for input");
ofstream f2("file_to");
if (!f2) errmsg("Cannot open 'filr_to' for output");
while ( f2 && f1.get(ch) ) f2.put(ch);
Ошибки, связанные с потоками, подробно обсуждаются на стр.181 оригинала.
Отметим, что если конструкторы ifstream или ofstream не могут открыть указанные файлы, то устанавливается соответствующее состояние ошибки потока.
Конструкторы позволяют объявить потокфайла без задания именованного файла. Затем вы можете ассоциировать данный поток файла с конкретным файлом:
ofstream ofile; // создание выходного потока файла
...
ofile.open("payroll"); // поток ofile ассоциируется с
// файлом payroll
// работа с некоторым паролем
ofile.close(); // payroll закрывается
ofile.open("employee"); // поток ofile можно использовать // повторно
По умолчанию файлы открываются в текстовом режиме.Это означает, что на вводе последовательность возврата каретки/перевода строки преобразуется в символ '\n'. На выводе символ '\n' преобразуется в последовательность возврат каретки/перевод строки. В двоичном режиме такие преобразования не выполняются.
Функциякомпонента ofstream::open объявляется следующим образом:
void open(char * name, int=ios::out, int prot=filуbuf:: openprot);
Аналогично, объявление ifstream::open имеет вид:
void open(char * name, int=ios::in, int
prot=filуbuf::openprot);
Второй аргумент, называемыйрежимом открытия, имеет показанные умолчания. Аргумент режима открытия (возможно, связанный операцией ИЛИ с несколькими битами режима)можно явно задать в следующей форме:
Бит режимаДействие
ios::appДобавление данных - запись всегда в конец файла ios::ateПоиск конца файла после первоначального открытия
ios::inОткрытие на ввод (подразумевается для ifstream) ios::outОткрытие на вывод (подразумевается для ofstream)
ios::truncУничтожение содержимого в случае, если файл существует (подразумевается, если ios::out задано, и ни ios::ate, ни ios::app не заданы)
ios::nocreateЕсли файл не существует, то open дает ошибку
ios::noreplace Если файл существует, open для файлов вывода дает ошибку, если не установлены ate или app
-----------------------------------------------------------
Мнемоника режима берется из перечислимого значения open _mode в ios:
class ios (*
public:
enum open_mode (* in, out, app, ate, nocreate, noreplace *);
*);
Оператор
ofstream ofile("data",ios::app\!ios::nocreate);
попытается открыть файл DATA на вывод в режиме append; если файл не существует, это приведет к неудаче. Информация об этой неудаче будет обозначена состоянием ошибки ofile. В случае удачного завершения поток ofile будет добавлен к файлу DATA. Класс fstream (производный от двух классов ifstream и ofsrtream) может использоваться для создания файлов, одновременно позволяющих и ввод, и вывод:
fstream inout("data:,ios::in\!ios::out);
inout << i;
...
inout >> j;
Для определения текущей позиции "get" или текущей позиции "put" файла можно воспользоваться функциями tellg и tellp; они определяют положение в потоке, гдебудет выполнена следующая операция вывода или ввода:
streampos cgp = inout.tellg(); // cgp - это текущая позиция get
где streampos это typedef в fstream.h. Функции-компоненты seekg и seekp могут сбрасывать значения текущей позиции get и put:
inout.seekg(cp); // установка в cp текущей позиции "put"
Варианты seekp и seekg позволяют получить искомые позиции в относительных смещениях:
inout.seekg(5,ios::beg); // перемещение cp на 5 байт от начала
inout.seekg(5,ios::cur); // перемещение cp на 5 байт вперед
inout.seekp(5,ios::end); // перемещение cp на 5 байт до конца
Вам может понадобиться распечатать и изучить комментированные файлызаголовка, чтобы узнать, как взаимосвязаны различные классы потоков и как объявляются их функции компоненты.
Состояния ошибки потока ввода/вывода
Каждый поток имеет связанное с ним состояние ошибки, т. е. набор битов ошибок, объявленный как перечислимое значение io_state в классе ios:
class ios (*
public:
...
// биты состояния потока
enum io_state (*
goodbit = 0x00,
eofbit = 0x01,
failbit = 0x02,
badbit = 0x04,
hardfail = 0x10
*);
...
*);
Отметим,что goodbit в действительности не является витом, а представляет собой нулевое значение, указывающее на то,что никакие биты ошибки не устанавливались.
Ошибки ввода/вывода потоком устанавливает соответствующий бит(ы), как указано в табл.3.2.
Биты ошибок ios Таблица 3.2
Бит состояния Его смысл
goodbit Если этот бит не установлен, то все в порядке.
eofbit "Конец файла": устанавливается, если istream не
имеет больше битов для извлечения. Последующие
попытки выполнить извлечение игнорируются.
failbit Устанавливается, если последняя операции ввода/
вывода (извлечение или преобразование) окончилась
неудачей. После сброса данного бита ошибки поток
готов к последующему использованию.
badbit Устанавливается, если последняя попытка ввода/
вывода являлась недопустимой. Поток может быть использован (не всегда) после сброса условия ошибки.
hardfail Устанавливается, если для данного потока встретилось невосстановимое состояние ошибки.
-----------------------------------------------------------
После того, как поток получил состояние ошибки, все попытки вставки или извлечения из данного потока будут игнорироваться до тех пор, пока не будет исправлено условие, вызвавшее состояние ошибки, а бит(ы) ошибки очищен(ы) (при помощи, например, функции компонента ios::clear(i). Функциякомпонент ios::clear(i) фактически устанавливает биты ошибки в соответствии с целочисленным аргументом i, так что ios::clear(0) очищает все биты ошибки, за исключением hardfail, который таким образом очищен быть не может.
Отметим, что операции вставки и извлечения не могут изменить состояния потока после того, как произошла ошибка. Из этого следует, что хорошей практикой является проверка состояния ошибки потока в соответствующих точках программы. В таблице 3.3 приведены функции-компоненты, позволяющие выполнять проверкуи установку битов ошибки.
Функции-компоненты для обработки текущего состояния потокаТаблица 3.3
Функция компонент Действие
int rdstate(); Возвращает текущее состояние ошибки
void clear(int i=0); Устанавливает биты ошибки в i. Например, код str.clear(ios::failbit\!str.rdstate());
устанавливает failbit потока str без разрушения прочих битов
int good(); Возвращает не-нулевое значение, если биты
ошибки не устанавливались; в противном случае
возвращает ноль
int eof(); Возвращает не-нулевое значение, если
установлен бит eofbit istream; в противном
случае возвращает ноль.
int fail(); Возвращает не-нулевое значение, если был
установлен один из битов failbit, badbit или
hardfail; в противном случае возвращает ноль.
int bad(); Возвращает не-нулевое значение, если был
установлен один из битов badbit или
hardfail; в противном случае возвращает ноль.
Вы можете также контролировать наличие ошибок, проверяя поток, как если бы он был логическим выражением:
if (cin >> x) return; // ввод в порядке
... // здесь восстановление в случае ошибки
if (!cout) errmsg("Ошибка вывода!");
Эти примеры подчеркивают элегантность С++. Класс ios имеет следующие объявления функции operator:
int operator! ();
operator void* ();
Операцияvoid*() определена как "преобразующая" поток в указатель, который будет равен 0 (ложь), если установлены failbit, badbit или hardfail, и не-нулевому значению в противном случае. (Отметим, что возвращаемый указатель должен использоваться только в логическихпроверках; другого практического применения он не имеет). Перегруженная операция "не" (!) определена как возвращающая не-нулевое значение (истина), если установлены биты ошибки потока failbit, badbit или hardfail; в противном случае она возвращает ноль (ложь).
Использование потоков прошлых версий
Хотя библиотеки stream версий 1.x и iostreamверсии2.0 разделяют многие имена классов и функцийи предлагают многие аналогичные средства, их структуры внекоторых важных областях несколько отличны друг отдруга.Turbo C++, следовательно, реализует два потока с разными библиотеками ифайлами заголовка. Для работы целиком со старыми кодами, использующими потоки, вы должны включить файл stream.h, избегать включения iostream.h и выполнять компоновку со старой библиотекой stream. Дополнительная информация о потоках версии 1.х находится в файле OLDSTR.DOC. Мы такжерекомендуем вам ознакомиться с объявлениями и комментариями в stream.h.
В зависимости от классов и средств, используемых вашими старыми работающими с потоками программами, не исключена их успешная компиляция и выполнение с использованием новой библиотеки iostream.
Рекомендации по переходу к потокам версии 2.0
Ключевое различие между старыми и новыми классами потоков состоит в том, чтокомпоненты public старого класса streambuf теперь, в новом классе streambuf, объявлены как protected. Если ваш старый код с потоками выполняет к таким компонентам прямые ссылки, либо если у вас имеются производные от streambuf классы, определенныена основаниитаких компонентов, то вы должны пересмотреть такие программы, прежде чем они пойдут сбиблиотекой iostream. Другой аспект, способныйповлиять на совместимость, состоит в том, что старый streambufпрямоподдерживал использование символьных массивов для форматирования в оперативной памяти. В случаеiostream эта поддержка предполагается в производном классе strstreambuf, объявляемом в strstream.h.
Старые конструкторы потока, запускающие буферы файлов, например
istream instream(дескриптор_файла)4
должны быть заменены на
ifstream instream(дескриптор_файла);
в программах с использованием iostream.
Старые и новыеклассы потоков по-разному взаимодействуют с stdio. Например, stream.h включает stdio.h, а старые istream и ostream поддерживаютуказатели на структуру stdio FILE. В случае iostream stdio поддерживается через специализированный класс stdiostream, объявленный в stdiostream.h.
В старой библиотеке stream предопределенные потоки cin, cout и cerr связаны непосредственно с файлами структуры FILE в stdio: stdin, stdout и stderr. Вслучаеiostream они подключаются к дескрипторам файлов и используют различные стратегии буферизации. Для того, чтобы избежать проблем с буферизацией при смешанном использовании кодов с stdout и cout, можно записать:
ios::sync_with_stdio();
где выполняется подключение предопределенных потоков к файлам stdio в режиме без буферизации. Отметим, однако, что такой способ значительно замедляет работу cin, cout и cerr, соответственно.
Старая библиотека stream позволяла непосредственно присваивать один поток другому; например,
ostream outs; outs = cout; // только для старых потоков
В случае iostream допустимо присвоение только потоку в левой части выражения присвоения; другими словами, типа istream_withassign или ostream_withassign. Если ваша программа содержит такие присвоения, то их можно либо переписать с использованием ссылок или указателей, либо изменить объявления:
ostream_withassign outs = cout; // только для новых потоков outs << i; // iostream
- 171 -
Глава 4 Модели памяти, операции с плавающей точкой и оверлеи
Данная глава рассматривает три основных вопроса:
- Модели памяти, от tiny до huge. Мы расскажем вам, что они из себя представляют, как выбрать модель памяти и зачем может понадобиться (или почему может не понадобиться) использовать ту или иную конкретную модель памяти.
- Опции операций с плавающей точкой. Как и когда использовать зти опции.
- Оверлеи. Как они работают, и как их использовать.
Модели памяти
Краткий обзор каждой модели памяти см. на стр.194 оригинала.
Turbo C++ предоставляетшесть моделейпамяти, каждая из которых соответствует определенномутипу программы и размеру кодов. Каждая модель памяти по-своему работает с памятью. Почему необходимо разбираться в моделях памяти? Для ответа на этот вопрос следует рассмотреть систему компьютера, с которой вы работаете. В основе блока центрального процессора системы лежит микропроцессор, принадлежащий к семейству микропроцессоров Intel iAPx86; это могут быть процессоры 8088 или 80286, на также и 8086, 80186, 80386или 80486. Пока будем обозначать процессор как 8086. Регистры 8086
Процессор 8086 содержит некоторый показанныйниже набор регистров. Существует, помимо того, еще один регистр - IP (указатель команд) - однако TurboC++ не имеетвозможности непосредственного к нему доступа, и потому он не показан.
Регистры общего назначения
| ------------- AX \! AH \! AL | ------------------ \! сумматор (матем.операции |
| BX \! BH \! BL | \! базовый регистр (индексация) |
| CX \! CH \! CL | \! счетчик (индексация) |
| DX \! DH \! DL ------------- | \! данные (содердит данные) ------------------ |
| Адресные сегментные | регистры |
CS \! \! указатель кодового сегмента
DS \! \! указатель сегмента данных
SS \! \! указатель сегмента стека
ES \! \! указатель вспомог. сегмента
Регистры специального назначения
| SP | \! | \! указатель стека |
| BP | \! | \! указатель базы |
| SI | \! | \! исходный индекс |
| DI | \! ------- | \! индекс назначения ------------------------ |
| Рис.4.1 | Регистры 8086 |
Регистры общего назначения
Регистрами общего назначения называются наиболее часто используемые для хранения и манипулирования данными регистры. Каждый из них имеет некоторуюспециальную функцию, свойственную только ему. Например,
- Некоторые математические операции могут быть выполнены только с помощью АХ.
- ВХ можно использовать как индексный регистр.
- СХ используется командой LOOP и некоторыми строковыми командами.
-DX неявно используется некоторыми математическими операциями.
Однако, существует множество операций, которые могут равно выполняться всеми этими регистрами; во многих случаяхони взаимозаменяемы.
Сегментные регистры
Сегментные регистры содержат начальные адреса каждого из четырех сегментов. Как будет описано в следующем разделе, 16-битовое значение в сегментном регисире сдвигается влево на 4 бита (т.е. умножается на 16), в результате чего получается 20-битовый адрес данного сегмента.
Регистры специального назначения
8086 имеет несколько регистров специального назначения:
- Регистры SI и DI могут выполнять многие функции регистров общего назначения, плюс они могут быть использованы в качесве индексных регистров.
- Регистр SP указывает на текущую вершину стека и часто содержит смещение для регистра стека.
- Регистр BP - это вторичный указатель стека, обычно используемый для индексирования стека с целью доступа к аргументам или динамическим локальным переменным.
Функции С используют в качестве базового адреса аргументов и динамических локальных переменных регистр - указательбазы (ВР). Параметры имеют положительные смещения относительно ВР, зависящие от модели памяти. ВР всегда указываетна предыдущеесохраненное значение ВР.Функции, не имеющие аргументов, не используют и не сохраняют ВР, если опция StandartStack Frame ("Стандартный стековый фрейм") находится в состоянии Off.
Динамические локальные переменные имеют отрицательные смещения относительно ВР. Смещения эти зависят от того, сколько памяти было уже распределено переменным этого типа.
Регистр флагов
16-битовый регистр флагов содержит всю необходимую информацию о состоянии 8086 и результатах выполнения последних команд.
виртуальный режим 8086
\! возобновление
\! \! вложенная задача
\! \! \! уровень защищенного
\! \! \! ввода/вывода
\! \! \! \! переполнение
\! \! \! \! \! признак
\! \! \! \! \! направления
\! \! \! \! \! \! прерывание
\! \! \! \! \! \! разрешено
\! \! \! \! \! \! \! внутреннее
\! \! \! \! \! \! \! прерывание
\! \! \! \! \! \! \! \! знак
\! \! \! \! \! \! \! \! \! ноль
\! \! \! \! \! \! \! \! \! \!перенос с
\! \! \! \! \! \! \! \! \! \!заемом
\! \! \! \! \! \! \! \! \! \!\! четность
\! \! \! \! \! \! \! \! \! \!\! \! перенос
\! \! \! \! \! \! \! \! \! \!\! \!\!
31 23 \! \!15\! \! \! \! \!\! 7 \!\! \!0
\! \! \! \! \! \! \! \! \! \! \! \! \! \! \!V\!R\! \!N\!IOP\!O\!D\!I\!T\!S\!Z\! \!A\! \!P\! \!C\!
-----------------------------------------------------------
\_____________________________/ \_____/ \_________________/
только 80386 80286 все процессоры 80х86
80386
Рис.4.2 Регистр флагов 8086
Например, вам понадобилось узнать, равен ли результат операции вычитания нулю; для этого вам достаточно проверить флаг нуля (бит Zрегистра флагов) непосредственно сразу же после выполнения команды; если данный флаг установлен, то результат действительнобыл равен нулю. Прочие флаги, такие как фоаги переноса или переполнения, аналогичным образом сообщают вам о результатах выполнения тех или иных математических или логических операций.
Прочие флаги контролируют режимы работы 8086. Флаг направления управляет направлением смещения строковых команд, а флаг прерываний управляет тем, разрешено ливнешним аппаратным устройствам, таким как клавиатура или модем, временно приостанавливать выполнение текущего кода для обслуживания возникающих у нихпотребностей. Флаг внутренних прерываний используется только программным обеспечением, предназначеннымдля отладки другого программного обеспечения.
Обычно регистр флагов не считываетсяи не модифицируется непосредственно. Обычно обращения к этому региструвыполняются посредством специальных ассемблерных команд (таких как CLD, STI и CMC), а такжепри помощи арифметических илогических команд, модифицирующих конкретные флаги. Подобным же образом, содержимое конкретных битов регистра флагов влияет на работу таких команд, как JZ, RCRи MOVSB. Регистр флагов фактическиникогда не используется как адрес памяти, а содержит данные о состоянии и управлении 8086.
Сегментация памяти
Микропроцессор Intel 8086 имеет сегментированную архитектуру памяти. Он имеет общий объем памяти 1 Мб, но позволяет одновременно адресовать только 64 Кб памяти. Такой участок памяти называется сегментом; отсюда и название "сегментированная архитектура памяти".
- 8086 позволяет работу с четырьмя различными сегментами: кодовым, данных, стека и вспомогательным. Кодовый сегмент содержит машинные команды программы; в сегменте данных хранится информация; сегмент стека имеет, разумеется, организацию и назначение стека; вспомогательный сегмент используется для хранения некоторых вспомогательных данных.
- 8086 имеет четыре 16-битовых сегментных регистра (один на каждый сегмент) с именами CS, DS, SS и ES; они указывают на кодовый сегмент, сенгмент данных, стека и вспомогательный сегмент, соответственно.
- Сегмент может располагаться в произвольном адресе памяти - практически везде. По причинам, которые станут вам ясны по мере ознакомления с материалом, сегмент должен располагаться в памяти, начиная с адреса, кратного 16 (десятичное).
Вычисление адреса
Полный адрес в8086 состоит из двух 16-битовых значений: адреса сегмента и смещения. Предположим, что адрес сегмента данных - т.е. значение в регистре DS -- равен 2F84 (шестнадцатиричное) и вы желаете вычислить фактический адрес некоторого элемента данных, который имеет значение 0532 (основание
16) от начала сегмента данных; как это сделать?
Вычисление адреса будет выполнено следующим образом: нужно сдвинуть влево значение сегментного регистра на 4 бита (это эквивалентно одной шестнадцатиричной цифре), а затем сложить с величиной смещения.
Полученное 20-битовое значениеи есть фактический адрес данных, как показано ниже:
регистр DS (после сдвига):0010 1111 1000 0100 0000 = 2F840 смещение: 0000 0101 0011 0010 = 00532
--------------------------------------------------------
Адрес:0010 1111 1101 0111 0010 = 2FD72
Участок памяти величиной 16 байт называетсяпараграфом, поэтому говорят, что сегмент всегда начинаетсяна границе параграфа.
Начальный адрес сегмента всегда является20-битовым числом, но сегментный регистр имеет всего 16 битов - поэтому младшие 4 бита всегда предполагаются равными нулю. Это означает - как было уже сказано - что начало сегмента можетнаходиться только в адресах памяти, кратных 16, т.е. адресах, в которых последние 4 бита (или один шестнадцатиричный разряд) равен нулю. Поэтому если регистр DS содержит значение 2F84, тофактически сегмент данных начинается в адресе 2F840.
Стандартная запись адреса имеет форму сегмент:смещение; например, предыдущий адрес можно записать как 2F84:0532. Отметим, что поскольку смещения могут перекрываться, данная пара сегмент:смещение неявляется уникальной; следующие адреса относятся к одной и той же точке памяти:
0000:0123
0002:0103
0008:00A3
0010:0023
0012:0003
Сегментымогут (но не должны) перекрываться. Например, все четыре сегмента могут начинаться с одного и того же адреса,что означает, что вся ваша программа в целом займет не более 64 Кб - но тогда в пределах этой памяти должны поместиться и коды программы, и данные, и стек.
Указатели
Какое отношение имеют указатели к моделям памяти и Turbo C++? Самое непосредственное. Тип выбранной вами модели памяти определяет тип по умолчанию указателей, используемых для кода и данных (хотявы можете явно объявить указатель или функцию как имеющие тот или иной конкретный тип, независимо от текущей модели памяти). Указатели бывают четырех разновидностей: near (16 битов), far (32 бита), huge (также 32 бита) и segment (16 битов).
Ближние указатели (near)
16-битовый (near) указатель для вычисления полного адреса связывается с одним из сегментных регистров; например, указатель функции складывает свое 16-битовоезначение со сдвинутым влево содержимым регистра кодового сегмента (CS). Аналогичным образом, ближний указатель данных содержит смещение в сегменте данных, адресуемом регистром сегмента данных (DS). С ближнимиуказателями легкоманипулировать, поскольку все арифметические операции с ним (например, сложение) можно выполнять безотносительно к сегменту.
Дальние указатели (far)
Дальний (32-битовый) указатель содержит не только смещение относительно регистра, но также и (в остальных 16 битах) адрес сегмента, который затем должен быть сдвинут влево и сложен со значением смещения. Использование дальних указателей позволяет иметьв программе несколько кодовых сегментов; это, в свою очередь, позволяет программе превышать 64К. Можно также адресовать более 64К данных.
При использовании дальних указателей для адресации данных вам следует учитывать некоторые потенциальные проблемы, которые могут возникать при манипулировании такими указателями. Какобъяснялось в разделе, посвященном вычислениямадреса, может существовать множество пар типа сегмент:смещение, адресующих одну и ту же точку памяти. Например, дальние указатели 0000:0120, 0010Ж0020 и 0012:0000 разрешаются к одному и тому же 2-битовому адресу. Однако, если у вас были бы три переменных типа дальнего указателя - a,b и c, содержащих соответственно три указанных значения, то следующие выражения все давали бы значение "ложь":
if (a == b) . . .
if (b == c) . . .
if (a == c) . . .
Аналогичная проблема возникает, когда вам требуется сравнивать дальние указатели при помощи операций >, >=, < и <=. В этих случаях в сравнении участвует только смещение (как unsigned); при указанных выше значениях a, b и cследующие выражения дадут значения "истина":
if (a > b) . . .
if (b > c) . . .
if (a > c) . . .
Операции равенства (==) и неравенства (!=) используют 32-битовые значения как unsigned long (а не в виде полного адреса памяти). Операции сравнения(<=, >=, < и >) используют только смещение.
Операции== и != требуют все 32 бита, что позволяет компьютеру выполнять сравнение с пустым (NULL) указателем (0000:0000). Если дляпроверки равенства использовалось только значение смещения, то любой указатель со смещением 0000 будет равен пустому указателю, что явно несовпадает с тем, что вы хотели получить.
Важное замечание
При сложении некоторого значения сдальним указателем изменяется только смещение. Если слагаемое настолько велико, что сумма превышает FFFF (максимально возможная для смещения величина), то указатель перейдет снова к началу сегмента. Например, если сложить 1 и 5031:FFFF, то результат будет равен 5031:0000 (а не 6031:0000). Подобным же образом, при вычитании 1 из 5031:0000 получится 5031:FFFF (а не 5030:000F).
Если вам понадобится выполнить сравнение указателей, то безопасный способ состоит в том, чтобы либо использовать для этого ближние указатели -все содним адресомсегмента - либо описываемые ниже указатели huge.
Указатели huge
Указатели huge также имеют размер 32 бита. как и указатели far, они содержат одновременно адрес сегмента и смещение. Однако, в отличие от дальних указателей, они нормализованы, что позволяет избежать проблем, связанных с дальними указателями.
Что такое нормализованный указатель? Это 32-битовый указатель, который содержитв своем адресе сегмента максимально возможное там значение. Поскольку сегмент может начинаться через каждые 16 байт (10 при основании 16), это означает, что величина смещения будет равна числу от 0 до 15 (от 0 до F с основанием 16).
Для нормализации указателя он преобразуется к20-битовому адресу, после чего правые 4 бита берутся в качестве смещения, а левые 16 битов - как адрес сегмента. Например, указатель 2F84:0532 можно сначала преобразовать к абсолютному адресу 2FD72, после чего получить нормализованный указатель2FD7:0002. Приведемеще ннесколько указателей с нормализованными значениями:
0000:01230012:0003
0040:00560045:0006
500D:9407594D:0007
7418:D03F811B:000F
Существует три причины, заставляющие всегда хранить указатель huge в нормализованном виде:
1. Поскольку в таком случае любому заданному адресу памяти соответствует только один возможный адрес в виде сегмент:смещение типа huge. Это означает, что для указателей huge операции == и != всегда будут возвращать правильное значение.
2. Кроме того, операции >, >=, < и <= работают с полным 32-битовым значением указателя huge. Нормализация гарантирует в данном случае корректность результата.
3. И наконец, вследствие нормализации смещение в указателе huge выполняет автоматический переход через 16 но вотличие от дальних указателей, переход затрагивает и сегмент. Например, при инкременте 811B:000Fрезультатбудет равен 811C: 0000; аналогичным образом, при декременте 800C:0000 получится 811B:000F. Эта особенность указателей huge позволяет манипулировать соструктурами данных сразмером более 64К. Гарантируется, например, что если у вас имеется массив структур типа huge, превышающий 64К, индексация этого массива и выбор поля структуры всегда будут выполняться правильно, независимо от размера структуры.
Использование указателей huge имеет свою цену: увеличение времени обработки. Арифметические операции с указателями huge выполняются при помощи обращений к специальным подпрограммам. Вследствие этого арифметические вычисления занимаютсущественно больше времени по сравнению с вычислениями для указателей far или near.
Шесть моделей памяти
Turbo C++ работает с шестью моделями памяти: tiny, small, medium, compact, large и huge. выбор модели памяти определяется требованиями вашей программы.Ниже приводятся краткие описания каждой из них:
Tiny
Эта модель памяти используется в тех случаях, когда абсолютным критериемдостоинства программыявляется размер ее звгрузочного кода.
Как вы уже поняли, это минимальная из моделей памяти.Все четыре сегментных регистра (CS, DS, SS и ES) устанавливаются на один и тот же адрес, что дает общий размер кода, данных и стека, равный 64К. Используютсяисключительноближние указатели. Программы с моделью памяти tuny могут быть преобразованы к формату .COM при компоновке с опцией /t.
Small
Эта модель хорошо подходит для небольших прикладных программ.
Сегменты кода и данных расположены отдельно друг от друга и не перекрываются, что позволяет иметь 64К кода программы и 64К данных и стека. Используются только ближние указатели.
Medium
Годится для больших программ,для которых не требуется держать в памяти большой объем данных.
Для кода, но не для данных используются дальние указатели. В результате данные плюс стек ограничены размером 64К, а код может занимать до 1 Мб.
Compact
Лучше всего использовать в тех случаях, когда размер кода невелик, но требуется адресация большого объема данных.
Ситуация, противоположная относительно модели Medium: дальние указатели используются для данных, но не для кода. Следовательно, код здесь ограничен 64К, а предельный размер данных - 1 Мб.
Large
Модели large иhuge применяются только в очень больших программах.
Дальние указатели используются как для кода,так идля данных, что дает предельный размер 1 Мб для обоих.
Huge
Дальние указатели используютсякак для кода, так и для данных. Turbo C++ обычно ограничиваетразмерстатических данных 64К;модельпамятиhuge отменяетэто ограничение, позволяя статическим данным занимать более 64К.
Для выбора любойиз этих моделей памяти вы должны либо воспользоваться соответствующей опцией меню интегрированной среды, либо ввести опцию при запуске компилятора командной строки.
Следующие иллюстрации(Рис.4.3 - 4.8) показывают,как выполняется распределение памяти для всех шести моделей памяти Turbo C++.
Сегментные регистры: Размер сегмента:
Младший ^ CS,DS,SS-----> --------------------------- адрес | / \! _TEXT класс 'CODE' \! \
| | \!код \! |
| | \!-------------------------\! |
| | \! _DATA класс 'DATA' \! |
| | \!инициализированные данные\! |
| | \!-------------------------\! |
| | \! _BSS класс 'BSS' \! |
|DGROUP/ \!неинициализирован. данные\! \ до 64К
|\ \!-------------------------\! /
| | \! куча| \! |
| | \!v \! |
| | \!-------------------------\! | Свободная
| | \! \!-|--область
|SP(TOS)--|->\!-------------------------\! | памяти
| | \!^ \! |
Старший | \ \! стек| \!/
адрес v Начало SP----> ---------------------------
Рис.4.3 Сегментация для модели памяти tiny
Сегментные регистры: Размер сегмента:
Младший ^ CS-----------> --------------------------- адрес | \! _TEXT класс 'CODE' \!
| \!код \! до 64К
| DS,SS--------> \!-------------------------\!
| / \! _DATA класс 'DATA' \!\
| | \!инициализированные данные\! |
| | \!-------------------------\! |
| | \! _BSS класс 'BSS' \! |
|DGROUP/ \!неинициализирован. данные\! \ до 64К
|\ \!-------------------------\! /
| | \! куча| \! |
| | \!v \! |
| | \!-------------------------\! | Свободная
| | \! \!-|--область
|SP(TOS)--|->\!-------------------------\! | памяти
| | \!^ \! |
| \ \! стек| \!/
| Начало SP----->\!--------------------------
| \! дальняя| \! До конца
| \! кучаv \! памяти
| \!-------------------------\! Свободная
Старший | \! \!----область
адрес v --------------------------- памяти
Рис.4.4 Сегментация для модели памяти small
Сегментные регистры: Размер сегмента:
Младший ^ ---------------------------
адрес | \! _TEXT класс 'CODE'\! до 64К
| \! sfileкод \!каждый sfile
| DS,SS--------> \!---/---------------------\!
| / \! / _DATA класс 'DATA' \!\
| Несколько __|__\!_/инициализирован. данные\! |
| --------- | \!-------------------------\! |
| \!sfile A\! | \! _BSS класс 'BSS' \! |
CS->\!sfile B\! | \!неинициализирован. данные\! \ до 64К | \! \! | \!-------------------------\! /
| \!sfile Z\! | \! куча| \! |
| --------- | \!v \! |
|DGROUP/ \!-------------------------\! | Свободная
|\ \! \!-|--область
|SP(TOS)--|->\!-------------------------\! | памяти
| | \!^ \! |
| \ \! стек| \!/
| Начало SP----->\!--------------------------
| \! дальняя| \! До конца
| \! кучаv \! памяти
| \!-------------------------\! Свободная
Старший | \! \!----область
адрес v --------------------------- памяти
Рис.4.5 Сегментация для модели памяти medium
CS указывает одновременно только на один sfile.
Сегментные регистры: Размер сегмента:
Младший ^ CS-----------> --------------------------- адрес | \! _TEXT класс 'CODE' \!
| \!код \! до 64К
| DS ----------> \!-------------------------\!
| / \! _DATA класс 'DATA' \!\
| | \!инициализированные данные\! |
|DGROUP/ \!-------------------------\! \ до 64К
|\ \! _BSS класс 'BSS' \! /
| | \!неинициализирован. данные\! |
| \ \! \!/
| SS ---------> \!-------------------------\! Свободная
| \! \!----область
|SP(TOS)---->\!-------------------------\! памяти
| \!^ \!
| \! стек| \! до 64К
| Начало SP----->\!--------------------------
| \! куча| \! До конца
| \!v \! памяти
| \!-------------------------\! Свободная
Старший | \! \!----область
адрес v --------------------------- памяти
Рис.4.6 Сегментация для модели памяти compact
Несколько
\!sfile A\!
CS->\!sfile B\!
\! \!
\!sfile Z\!<---
--------- \
\
\
\
\
Сегментные регистры: \ Размер сегмента:
Младший ^ ----\----------------------
адрес | \! \ _TEXT класс 'CODE'\! до 64К
| \! sfileкод \!каждый sfile
| DS ----------> \!-------------------------\!
| / \! _DATA класс 'DATA' \!\
| | \! инициализирован. данные\! |
|DGROUP/ \!-------------------------\! \ до 64К
|\ \! _BSS класс 'BSS' \! /
| | \!неинициализирован. данные\! |
| \ \! \!/
| SS ---------> \!-------------------------\! Свободная
| \! \!----область
|SP(TOS)---->\!-------------------------\! памяти
| \!^ \!
| \! стек| \! до 64К
| Начало SP----->\!--------------------------
| \! куча| \! До конца
| \!v \! памяти
| \!-------------------------\! Свободная
Старший | \! \!----область
адрес v --------------------------- памяти
Рис.4.7 Сегментация для модели памяти large
Несколько
\!sfile A\!
CS->\!sfile B\!
\! \!
\!sfile Z\!<---
--------- \
\
\
\
\
Сегментные регистры: \ Размер сегмента:
Младший ^ ----\----------------------
адрес | \! \ _TEXT класс 'CODE'\! до 64К
| \! sfileкод \!каждый sfile
| \!-------------------------\!
| Несколько \! \!
| --------- \! \!
| \!sfile A\! \! \!
| DS->\!sfile B\!<-\!sfile _DATA класс 'DATA' \! до 64К
| \! \! \!неинициализирован. данные\! каждый sfile
| \!sfile Z\! \! \!
| SS ---------> \!-------------------------\! Свободная
| \! \!----область
|SP(TOS)---->\!-------------------------\! памяти
| \!^ \!
| \! стек| \! до 64К
| Начало SP----->\!--------------------------
| \! куча| \! До конца
| \!v \! памяти
| \!-------------------------\! Свободная
Старший | \! \!----область
адрес v --------------------------- памяти
Рис.4.8 Сегментация для модели памяти huge
Таблица 4.1. суммирует различные модели, а также результаты их сравнения друг с другом. Эти модели часто группируются в соответствии с тем, насколько малы (64К) или велики (1М) размеры их модулей кода и данных; Эти группы соответствуют рядами колонкам табл. 4.1.
-----------------------------------------------------------
Размер \! Размер кода
данных \! ------------------------------------------------- \! 64 K \!1 Mb
----------------------------------------------------------- \! Tiny (данные, коды \!
64K\! перекрываются \!
\! максимальный размер 64К) \!
\! \!
\! Small (без перекрытия \! Medium (данные - small
\! максимальный размер 128К) \! коды - large)
\! \!
1Mb\! Compact ( данные - large \! Large ( данные и коды \! коды - small) \! large)
\! \!
\! \! Huge (также как и large,
\! \! но cтатические
\! \! данные >64 K )
Важно!
Когда Выкомпилируете модуль (исходный файл с некоторым количеством процедур в нем), то результирующий код для этого модуля не может превышать 64К, т.к. он должен вмещаться в один кодовый сегмент. Это остается правилом, даже если Вы используете один из больших кодовых модулей (medium, large, huge). Если ваши модули очень велики ( > 64К ), Вы должны разбить их на несколько маленьких исходных файлов, компилировать их раздельно, а потом собирать в один файл. Аналогичным образом, несмотря на то, что huge модель позволяет набору статических данных превышать размер 64 К, все равно он должен быть < 64K в каждом модуле.
Программирование с использованием различных моделей памяти: адресные модификаторы
Turbo C++ вводит 8 новых ключевых слов, не имеющихся в стандартном ANSI C ( near, far, huge, _cs, _ds, _es, _ss, _seg), которые могут использоваться в качестве модификаторов адресных указателей (а иногда и функций) с некоторыми ограничениями.
В Turbo C ++ вы можете модифицировать объявления функций и адресных указателей с помощью ключевых слов near, far, huge. Мы уже объяснили смыслуказателей near, far, huge ранее в этой главе. near-функции вызываются near-вызовами с последующим near-выходом из них. Аналогичным образом far-функции вызываются far-вызовами с последующим far-выходом из них. huge-функции аналогичны far-функциям,за исключением того,что huge-функции устанавливают регистр DS в новое значение.
Кроме того имеются четыре специальных near-указателей данных: _cs, _ds, _es, _ss. Это шестнадцатибитовые указатели, которые специально ассоциируются с соответствующими сегментными регистрами, например, если бы вы должны были объявитьуказатель равным:
char _ss *p;
то рсодержал бы в этом случае шестнадцатибитовое смещение в сегменте стека.
Существует некоторое ограничение на использование сегментных указателей:
- Выне можете делать инкремент и декремент с указателями сегментов. Когда выприбавляете или вычитаете целое из сегментного указателя, он автоматически преобразуетсяв far-указатель, а арифметическая операция выполняетсятак, как если бы целое было прибавлено или вычтено из far-указателя.
- Когда сегментные указатели используются в косвенном выражении они также преобразуются в far-указатели.
- Также как и расширениек двоичному + оператору, если сегментный указатель прибавляется к near-указателю, результатом будет far-указатель, который формируется путем взятия сегмента из сегментного указателя исмещения из near-указателя. Такая операция разрешается, только если оба указателя указывают на одинаковый тип, илиесли один из указателей указывает на тип void.
- Указатели сегментов можно сравнивать. Сравнение их выполняется таким образом, как если бы их значения имели целочисленный тип unsigned.
Функции и указатели в данной программе по умолчанию бывают ближними или дальними, в зависимости от выбранной модели памяти. Если функция или указатель являются ближними, то они автоматически связываются с регистром CS или DS.
В следующей таблице показано, как это происходит. Отметим, что размер указателя соответствует предельному размеру памяти, равному 64К (ближний, в пределах сегмента) или 1 Мб (дальний, содержит собственный адрес сегмента).
Типы указателей Таблица 4.2
Модель памяти Указатели функции Указатели данных
Tiny near, _csnear, _ds
Small near, _csnear, _ds
Medium farnear, _ds
Compact near, _csfar
Large farfar
Huge farfar
Указатели данных могут быть также объявлены с модификатором _seg. Это 16-битовые указатели сегмента.
Объявление ближних или дальних функций
В некоторых случаях вам может захотеться(или понадобиться) переопределить умолчание типа функции для модели памяти, показанное в таблице 4.1 (стр.198 оригинала).
Например, вы используете модель памяти large, и в программе имеется рекурсивная функция:
double power(double x,int exp)
(*
if (exp <= 0)
return(1);
else
return(x * power(x, exp-1));
*)
Каждый раз, когда power вызывает сама себя, она должна выполнить дальний вызов, причем используется большая область стека и число тактовых циклов. Объявив power как near, можно ускорить выполнение ее благодаря тому, чтовызовыэтой функции будут ближними:
double near power(double x,int exp)
Это гарантирует, что power может быть вызвана только из того кодоваго сегмента, в котором она компилировалась, и что все обращения к ней будут ближними.
Это означает, что при использовании большой модели памяти (medium, large или huge) power можно вызывать только из того модуля, в котором она определена.Прочиемодулиимеют свои собственные кодовые сегменты и не могут вызывать функции near из других модулей. Более того, ближняя функциядо первого кней обращения должна быть либоопределена, либо объявлена, иначе компилятор не знает о необходимости генерировать ближний вызов.
И наоборот, объявление функции как дальней означает генерированиедальнего возврата. В малых моделях кодовой памяти дальняя функция должна быть объявлена или определена до первого к ней обращения, что обеспечит дальний вызов.
Вернемся к примеру функции power. Хорошо также объявить power как static, поскольку предусматривается вызывать ее только из текущего модуля. Если функция будет объявлена как static, тоимя ее не будет доступно ни одной функции вне данного модуля.
Объявление указателей near, far или huge
Только что были рассмотрены случаи, в которых может понадобиться объявить функциюс другой моделью памяти, нежели остальная часть программы. Зачем то же самое может понадобиться для указателей? По тем же причинам, что и дляфункций: либодля улучшения характеристик быстродействия (объявив near там, где по умолчанию было бы far), либо для ссылки за пределы сегмента по умолчанию (объявив far илиhuge там, где по умолчанию бывает near).
Разумеется, при объявлении функций или указателей с другим типом, нежели по умолчанию, потенциально появляется возможность ошибок. Предположим, имеется следующий пример программы с моделью small:
void myputs(s)
char *s;
(*
int i;
for (i = 0; s[i] != 0; i++) putc(s[i]);
*)
main()
(*
char near *mystr;
mystr = "Hello, world\n";
myputs(mystr);
*)
Эта программа работаетудовлетворительно, хотя объявление mystr как near избыточно, поскольку все указатели, как кода, так и данных, будут near по умолчанию.
Однако, что произойдет, если перекомпилировать эту программу с моделью памяти compact (либо large или huge)? Указатель mystr в main останется ближним (16-битовым). Однако, указатель s в myputs теперь будет far, поскольку умолчанием теперь будет являться far. Это означает, что попытка создания дальнего указателяприведет к снятию со стека двух слов, и полученный таким образом адрес, безусловно, не будет являться адресом mystr.
Как избежать этой проблемы? Решение состоит втом, чтобы определить myputs в современном стиле С:
void myputs(char *s)
(*
/* тело myputs */
*)
Теперь при компиляции вашей программы Turbo C++ знает, что myputs ожидает указатель на char; и поскольку компиляция выполняется с моделью large, то известно, что указатель должен быть far. Вследствие этого Turbo C++ поместит в стек регистр сегмента данных (DS) и 16-битовоезначение mystr, образуя тем самым дальний указатель.
Если вы собираетесь явнообъявлять указатели как farили near,не забывайте использовать прототипы тех функций, которые могут использовать эти указатели.
Как быть в обратном случае: когда аргументы myputs объявлены как far, а компиляция выполняется с моделью памяти small? И в этом случае без прототипа функции у вас возникнут проблемы, поскольку main будет помещать в стек и смещение, и адрес сегмента, тогда как myputs будет ожидать приема только одного смещения. При наличии определений функций в прототипах main будет помещать в стек только смещение.
Создание указателя данного адреса сегмент:смещение
Как создать дальний указательна конкретный адрес памяти (конкретный адрессегмент:смещение)? Для этого можно воспользоваться встроеннойбиблиотечной подпрограммой MK_FP, которая в качестве аргументапринимает сегмент и смещение, и возвращает дальний указатель. Например,
MK_FP(segment_value, offset_value)
Имея дальний указательfp, вы можете получить компонент сегмента полного адреса с помощью FP_SEG(fp) и компонент смещения с помощью FP_OFF(fp). Более полную информацию об этих трех библиотечных функциях Turbo C++ см. в Справочнике по библиотеке.
Использование библиотечных файлов
Turbo C++ предлягает для каждой из шести моделей памяти собственную версию библиотеки стандартных подпрограмм. Turbo C++ при этом проявляет достаточно "интеллекта", чтобы при компоновке брать нужные библиотеки и в нужной последовательности, в зависимости от выбранной вами модели памяти. Однако,при непосредственном использовании компоновщика Turbo C++ TLINK (как автономного компоновщика) вы должны явно указывать используемые библиотеки. Более подробно это описано в разделе TLINK Главы 5Б "Утилиты", Руководства пользователя.
Компоновка смешанных модулей
Что произойдет,если вы компилируете один модуль с использованием модели памяти small, второй - модели large, и затем хотите скомпоновать их? Что при этом произойдет?
Файлы скомпонуются удовлетворительно, но при этом вы встретитесь с проблемами, которые будут аналогичны с описанными выше в разделе "Объявление функций как near или far". Если функция модуля с моделью small вызывает функцию в модуле с моделью large, она будет использовать при этом ближний вызов, что даст абсолютно неверные результаты.Кроме того, у вас возникнут проблемы с указателями, описанные в разделе "Объявление указателей как near, far или huge", поскольку функция в модуле small ожидает, что принимаемые и передаваемые ейуказатели будут near, тогдакак функция в модуле large ожидает рабрту с указателями far.
И снова решение заключается в использовании прототипов функций. Предположим, что вы поместили myputs в отдельный модуль и скомпилировали его с моделью памяти large. Затем вы создаете файл заголовка myputs.h (либо с любым другим именем и расширением .h), который содержит следующий прототип функции:
void far myputs(char far *s);
Теперь, если поместить main в отдельный модуль (MYMAIN.
C) и выполнить следующие установки:
#include <stdio.h>
#include "myputs.h"
main()
(*
char near *mystr;
mystr = "Hello, wirld\n";
myputs(mystr);
*)
то при компиляции данной программы Turbo C++ считает прототип функции из MYPUTS.H и увидит, что это дальняя функция, ожидающая дальний указатель. Вследствие этого даже при модели памяти small при компиляции будет сгенерирован правильный вызывающий код.
Что произойдет, если помимо этого вам требуется компоновка с библиотечными подпрограммами? Лучший подход здесь заключается в том, чтобы выбрать одну из библиотек с моделью large и объявить все как far. Для этого сделайте копии всех файлов заголовка, которые вы обычно включаете (таких, как stdio.h) и переименуйте эти копии (например, fstdio.h).
Затем отредактируйте копии прототипов функций таким образом, чтобы там было явно указано far, например:
int far cdecl printf(char far* format, ...);
Тем самым, не только вызовы подпрограмм будут дальними, но и передаваемые указатели также будут дальними.Модифицируйте вашу программу таким образом, чтобы она включала новый файл заголовка:
#include <fstdio.h>
main()
(*
char near *mystr;
mystr = "Hello, world\n";
printf(mystr);
*)
Скомпилируйте вашу программу при помощиTCC, затем скомпонуйте ее при помощью TLINK, указав библиотеки с моделью памяти large, напрмер CL.LIB. Смешиваниемодулей с разными моделями - вещь экстравагантная, но допустимая; будьте, однако, готовы к тому, чтолюбые неточности здесь приводят к ошибкам, которые очень трудно найти и исправиь при отладке.
Опции типа чисел с плавающей точкой
С работает с двумя числовыми типами:интегральным (int, short, long и т.д.) и с плавающей точкой (float double и long double). Процессор вашего компьютер легко справляется с обработкой чисел интегральных типов, однако числа с плавающей точкой отнимают больше времени и усилий.
Однако, семейство процессоров iAPx86 имеет сопутствующееему семейство математических сопроцессоров, 8087, 80287 и
Похожие работы


... к сожалению, обратное утверждение не верно. C++ Builder содержит инструменты, которые при помощи drag-and-drop действительно делают разработку визуальной, упрощает программирование благодаря встроенному WYSIWYG - редактору интерфейса и пр. Delphi — язык программирования, который используется в одноимённой среде разработки. Сначала язык назывался Object Pascal. Начиная со среды разработки Delphi ...
... ориентированы на 32 разрядные шинные архитектуры компьютеров с процессорами 80386, 80486 или Pentium. Фирма Novell также подготовила варианты сетевой ОС NetWare, предназначенные для работы под управлением многозадачных, многопользовательских операционных систем OS/2 и UNIX. Версию 3.12 ОС NetWare можно приобрести для 20, 100 или 250 пользователей, а версия 4.0 имеет возможность поддержки до 1000 ...
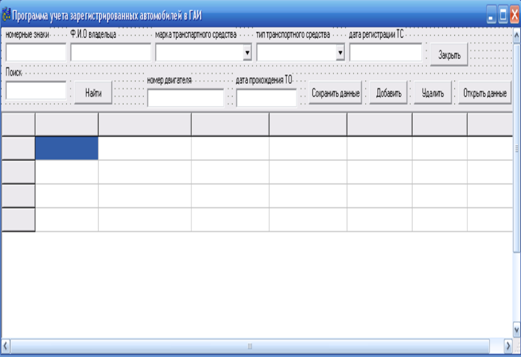
... завдання поширюється на розробку системи обліку зареєстрованих автомобілів в ДАІ, призначеної для збору, зберігання, а також полегшення для доступу та використання інформації. Програма з обліку зареєстрованих автомобілів в ДАІ, представляє собою, перехід від паперових носіїв інформації до електронних. Система обліку зареєстрованих автомобілів значно допоможе працівникам ДАІ з обліку, аналізу та ...


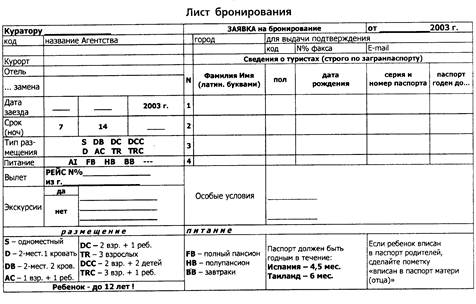
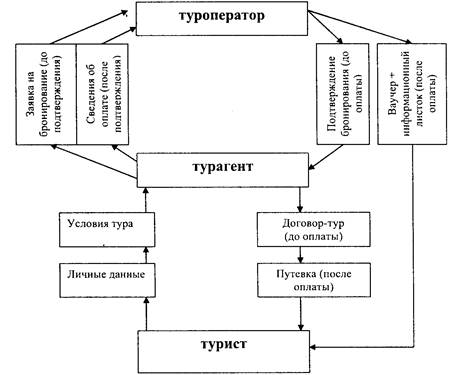
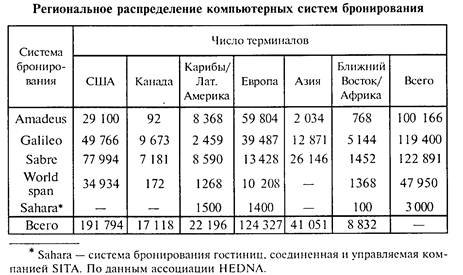
... меньше времени и ответ клиенту агентство может дать уже в день подачи заявки. Каждая турфирма разрабатывает индивидуальный образец листа бронирования. Согласно Федеральному Закону «Об основах туристской деятельности в Российской Федерации» (гл. IV, ст. 9) – это конкретный заказ туриста или лица, уполномоченного представлять группу туристов, туроператору на формирование туристского продукта. ...
0 комментариев